
随心玩玩(十二)通义千问——LLM大模型微调_通义千问模型训练
赞
踩
写在前面:使劲的摸鱼,摸到的鱼才是自己的~
简介
参考资料:
https://github.com/QwenLM/Qwen/blob/main/README_CN.md
https://www.bilibili.com/video/BV16a4y1z7LY
https://modelscope.cn/models/qwen/Qwen-1_8B-Chat-Int4/summary
什么是通义千问?
通义千问(Tongyi Qianwen)是由阿里巴巴集团旗下的云端运算服务的科技公司阿里云开发的聊天机器人。它能够与人互动、回答问题及协作创作。这个名字来源于两个方面:“通义”意味着该模型具有广泛的知识和普适性,可以理解和回答各种领域的问题。作为一个大型预训练语言模型,“通义千问”在训练过程中学习了大量的文本数据,从而具备了跨领域的知识和语言理解能力。“千问”代表了模型可以回答各种问题,包括常见的、复杂的甚至是少见的问题。
什么是LLM?
LLM(Large Language Model)是一种语言模型,以其实现通用语言理解和生成的能力而闻名。LLM通过在计算密集型的自监督和半监督训练过程中从文本文档中学习统计关系来获得这些能力。例如,OpenAI的GPT模型(例如,用于ChatGPT的GPT-3.5和GPT-4),Google的PaLM(用于Bard),Meta的LLaMA,以及BLOOM,Ernie 3.0 Titan和Anthropic的Claude 2等都是LLM的例子。
LLM模型的架构由多个因素决定,如特定模型设计的目标、可用的计算资源以及LLM要执行的语言处理任务的类型。LLM的一般架构包括许多层,如前馈层、嵌入层、注意力层。一个嵌入在内部的文本被协同起来生成预测。
环境配置
要求(Requirements)
python 3.8及以上版本
pytorch 2.0及以上版本
建议使用CUDA 11.4及以上(GPU用户、flash-attention用户等需考虑此选项)
我选择的环境是python=3.9,创建环境名字light
conda create --name light python=3.9
conda activate light
可以到这个网站https://pytorch.org/get-started/previous-versions/,CTRL+F搜索CUDA 11/12找自己版本对应的pytorch安装pytorch
以我的CUDA 11.7为例子,pip进行安装:
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
进入到工作目录,安装Qwen项目,
注:如果网络不好,可以选择ZIP压缩包下载方式下载
git clone https://github.com/QwenLM/Qwen.git
进入到项目根目录,安装所需要的环境
cd Qwen/
pip install -r requirements.txt
requirements.txt:
transformers==4.32.0
accelerate
tiktoken
einops
transformers_stream_generator==0.0.4
scipy
- 1
- 2
- 3
- 4
- 5
- 6
我后面还报了几个错误,需要装这几个库,总之报错了根据提示装上就好
pip install optimum
pip install auto-gptq
Optimum是huggingface开源的模型加速项目。
auto-gptq是一个基于 GPTQ 算法,简单易用且拥有用户友好型接口的大语言模型量化工具包。
pip install modelscope
类似hugging face,我们可在平台上下载模型
pip install deepspeed
deepspeed框架-大模型分布式训练与推理
参考资料:https://www.bilibili.com/video/BV1LC4y1Y7tE/
conda install mpi4py
mpi4py 是一个用于在 Python 中进行并行计算的 MPI(Message Passing Interface)的接口库
模型加载
参考资料:https://github.com/QwenLM/Qwen
稍等几分钟等模型下载,因为用的modelscope中国源下载会快一点。
本博客下的是qwen/Qwen-1_8B-Chat-Int4作为示例,因为比较小比较好下载,看者可以根据自己需要选择注释的模型下载
模型下载默认地址会在~/.cache/modelscope/hub/qwen/Qwen-1_8B-Chat-Int4/
from modelscope import snapshot_download from transformers import AutoModelForCausalLM, AutoTokenizer # Downloading model checkpoint to a local dir model_dir # model_dir = snapshot_download('qwen/Qwen-7B') # model_dir = snapshot_download('qwen/Qwen-7B-Chat') # model_dir = snapshot_download('qwen/Qwen-14B') # model_dir = snapshot_download('qwen/Qwen-14B-Chat') model_dir = snapshot_download('qwen/Qwen-1_8B-Chat-Int4') # Loading local checkpoints # trust_remote_code is still set as True since we still load codes from local dir instead of transformers tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True) model = AutoModelForCausalLM.from_pretrained( model_dir, device_map="auto", trust_remote_code=True ).eval()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
模型下载好后,有一个问题就是我们不能每次都用.py运行来调试,因为模型加载过程十分耗费时间,因此我们需要用jupyter notebook帮助我们快速开发。
jupyter远程配置
参考资料:https://blog.csdn.net/MrR1ght/article/details/98227629
安装jupyter
pip install jupyter
生成配置文件
jupyter notebook --generate-config
设置远程登陆Jupyter Notebook的密码
执行以下命令输入密码即可
jupyter notebook password
编辑Jupyter Notebook的配置文件
vim ~/.jupyter/jupyter_notebook_config.py
在jupyter_notebook_config.py文件最末端添加以下代码:
c.NotebookApp.ip = '*' # 允许访问此服务器的 IP,星号表示任意 IP
c.NotebookApp.open_browser = False # 运行时不打开本机浏览器
c.NotebookApp.port = 8369 # 使用的端口,随意设置
c.NotebookApp.enable_mathjax = True # 启用 MathJax
c.NotebookApp.allow_remote_access = True #允许远程访问
c.NotebookApp.notebook_dir = '/home/work/' # 设置默认工作目录
- 1
- 2
- 3
- 4
- 5
- 6
Jupyter NoteBook 更改Kernel,由于jupyter notebook访问的时候,默认使用了anaconda的base环境,这里就需要更换环境。
python -m ipykernel install --user --name 要添加的环境 --display-name "jupyter中显示的kernel名字"
例如:
python -m ipykernel install --user --name light --display-name "light"
终端输入命令 启动服务,这里是用后台启动
nohup jupyter notebook &
本机设置:
win+r开启cmd,
使用以下命令将本地端口与服务器端相映射:
ssh -L [本地端口]:localhost:[远程端口] [远程用户名]@[远程IP] -p [ssh连接端口]
例如:
ssh -L 8369:localhost:8369 root@172.31.224.191 -p 22
输入密码连接即可
本地浏览器输入
127.0.0.1:8369
默认让你使用密码登录的方式。 输入密码登录即可

回到pycharm,新建一个.ipynb,配置URL地址127.0.0.1:8369

shift+enter自动启动服务后切换kenerl
把之前的代码复制过来,运行,这样就可以开始快乐的运行调试了。
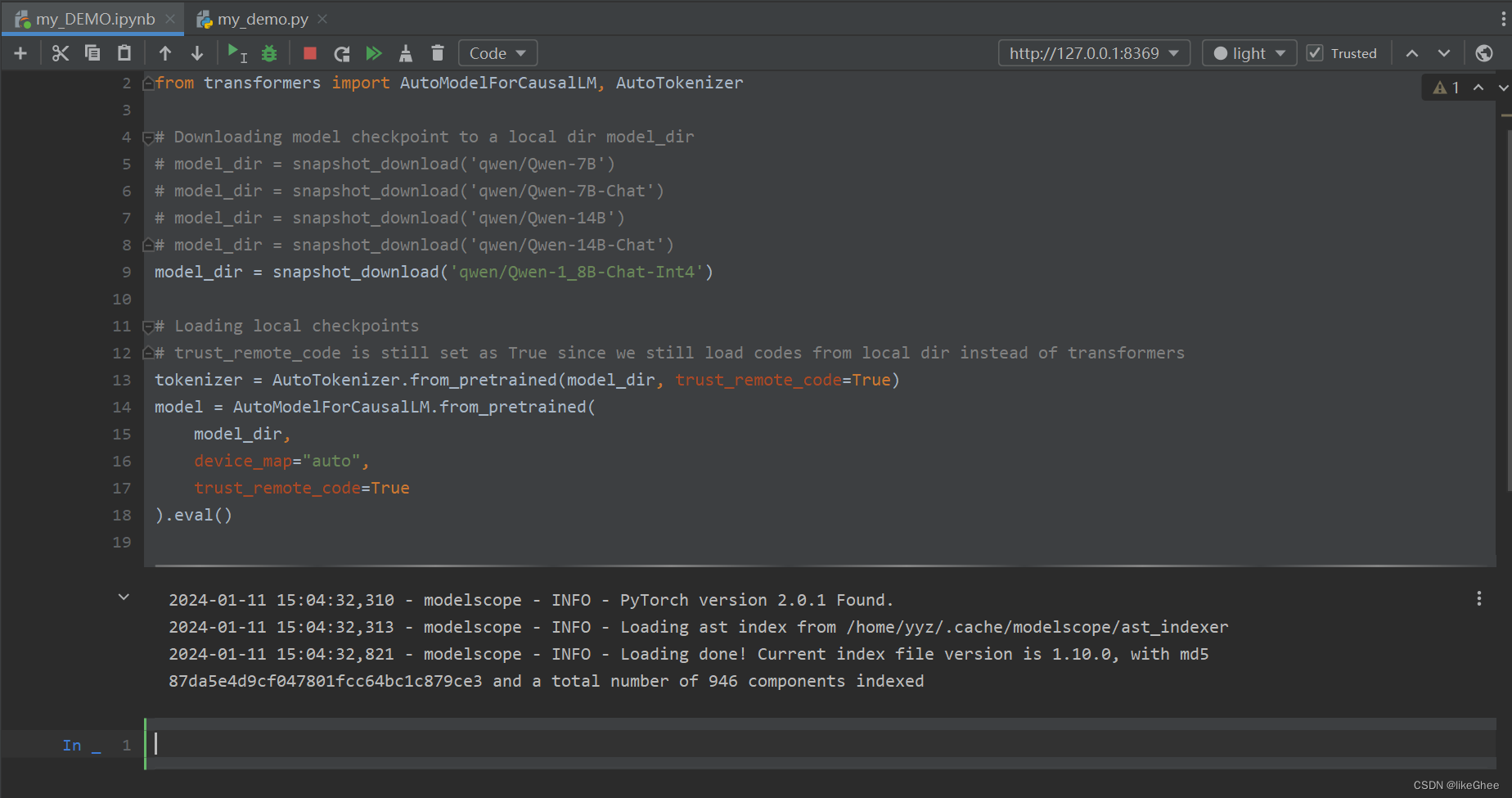
等一会,我们就能加载好模型了。下面将介绍如何使用模型
快速使用
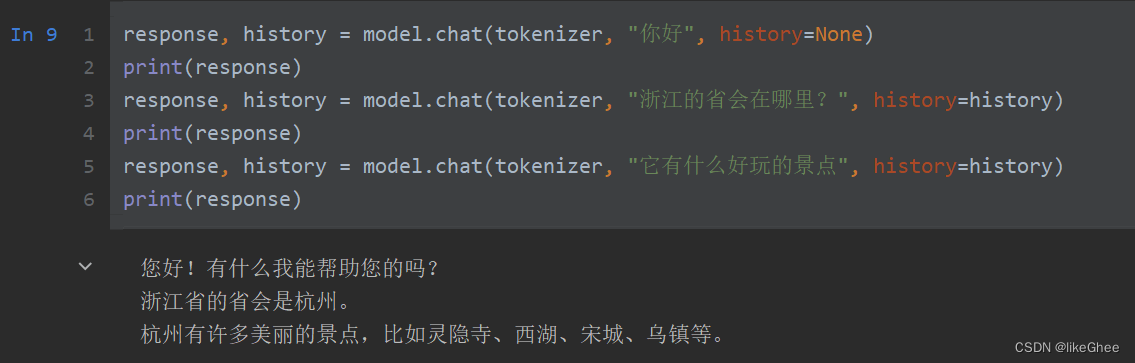
上面我们加载好了模型。我们可以使用model.chat进行对话,下面是例子:
response, history = model.chat(tokenizer, "你好", history=None)
print(response)
response, history = model.chat(tokenizer, "浙江的省会在哪里?", history=history)
print(response)
response, history = model.chat(tokenizer, "它有什么好玩的景点", history=history)
print(response)
- 1
- 2
- 3
- 4
- 5
- 6
更多参考资料请参考:https://github.com/QwenLM/Qwen/blob/main/README_CN.md
微调示例
参考资料:
https://www.bilibili.com/video/BV16a4y1z7LY
https://github.com/owenliang/qwen-sft
详细讲解见视频BV16a4y1z7LY
prompt工程和微调数据集生成:
# 生成样本 import random import json import time # 城市数据 with open('city.txt','r',encoding='utf-8') as fp: city_list=fp.readlines() city_list=[line.strip().split(' ')[1] for line in city_list] # prompt模板 prompt_template=''' 给定一句话:“%s”,请你按步骤要求工作。 步骤1:识别这句话中的城市和日期共2个信息 步骤2:根据城市和日期信息,生成JSON字符串,格式为{"city":城市,"date":日期} 请问,这个JSON字符串是: ''' Q_arr=[] A_arr=[] # 问题模板 Q_list=[ ('{city}{year}年{month}月{day}日的天气','%Y-%m-%d'), ('{city}{year}年{month}月{day}号的天气','%Y-%m-%d'), ('{city}{month}月{day}日的天气','%m-%d'), ('{city}{month}月{day}号的天气','%m-%d'), ('{year}年{month}月{day}日{city}的天气','%Y-%m-%d'), ('{year}年{month}月{day}号{city}的天气','%Y-%m-%d'), ('{month}月{day}日{city}的天气','%m-%d'), ('{month}月{day}号{city}的天气','%m-%d'), ('你们{year}年{month}月{day}日去{city}玩吗?','%Y-%m-%d'), ('你们{year}年{month}月{day}号去{city}玩么?','%Y-%m-%d'), ('你们{month}月{day}日去{city}玩吗?','%m-%d'), ('你们{month}月{day}号去{city}玩吗?','%m-%d'), ] train_data = [] # 生成样例 # 生成一批"1月2号"、"1月2日"、"2023年1月2号", "2023年1月2日", "2023-02-02", "03-02"之类的话术, 教会它做日期转换 for i in range(1000): Q=Q_list[random.randint(0,len(Q_list)-1)] city=city_list[random.randint(0,len(city_list)-1)] year=random.randint(1990,2025) month=random.randint(1,12) day=random.randint(1,28) time_str='{}-{}-{}'.format(year,month,day) date_field=time.strftime(Q[1],time.strptime(time_str,'%Y-%m-%d')) Q=Q[0].format(city=city,year=year,month=month,day=day) # 问题 A=json.dumps({'city':city,'date':date_field},ensure_ascii=False) # 回答 example={ 'id':'identity_{}'.format(i), 'conversations':[ {'from':'user','value':prompt_template%(Q,)}, {'from':'assistant','value':A} ] } Q_arr.append(prompt_template%(Q,)) A_arr.append(A) train_data.append(example) import pandas as pd with open('train.txt','w',encoding='utf-8') as fp: fp.write(json.dumps(train_data)) df=pd.DataFrame({'Prompt':Q_arr,'Completion':A_arr}) df.to_excel('train.xlsx')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
进到项目根目录,在根目录创建微调启动脚本ft.sh:
这里我们使用qlora,进行部分参数训练
什么是qlora?
QLoRA是一种高效的微调方法,可以减少内存使用,足以在单个48GB GPU上微调65B参数模型,同时保留完整的16位微调任务性能。QLoRA通过冻结的4位量化预训练语言模型反向传播梯度到低秩适配器(LoRa)
#!/bin/bash
project_root=/home3/likeghee/python/Qwen
bash $project_root/finetune/finetune_qlora_single_gpu.sh -m /home/likeghee/.cache/modelscope/hub/qwen/Qwen-1_8B-Chat-Int4 -d $project_root/train.txt
- 1
- 2
- 3
- 4
- 5
ft.sh解释:
定义项目的根目录
project_root=/home3/likeghee/python/Qwen
调用了Fine-tuning脚本 (finetune_qlora_single_gpu.sh)
-
-m /home/likeghee/.cache/modelscope/hub/qwen/Qwen-1_8B-Chat-Int4: 指定预训练模型的路径或标识符。 -
-d $project_root/train.txt: 指定训练数据的路径或文件。
启动微调脚本bash ft.sh
等待训练完成…
微调好的模型会生成在项目主目录下的output_qwen
生成好的微调模型文件夹内容:

使用AutoPeftModelForCausalLM加载微调后的模型
from peft import AutoPeftModelForCausalLM
model = AutoPeftModelForCausalLM.from_pretrained(
'output_qwen', # path to the output directory
device_map="auto",
trust_remote_code=True
).eval()
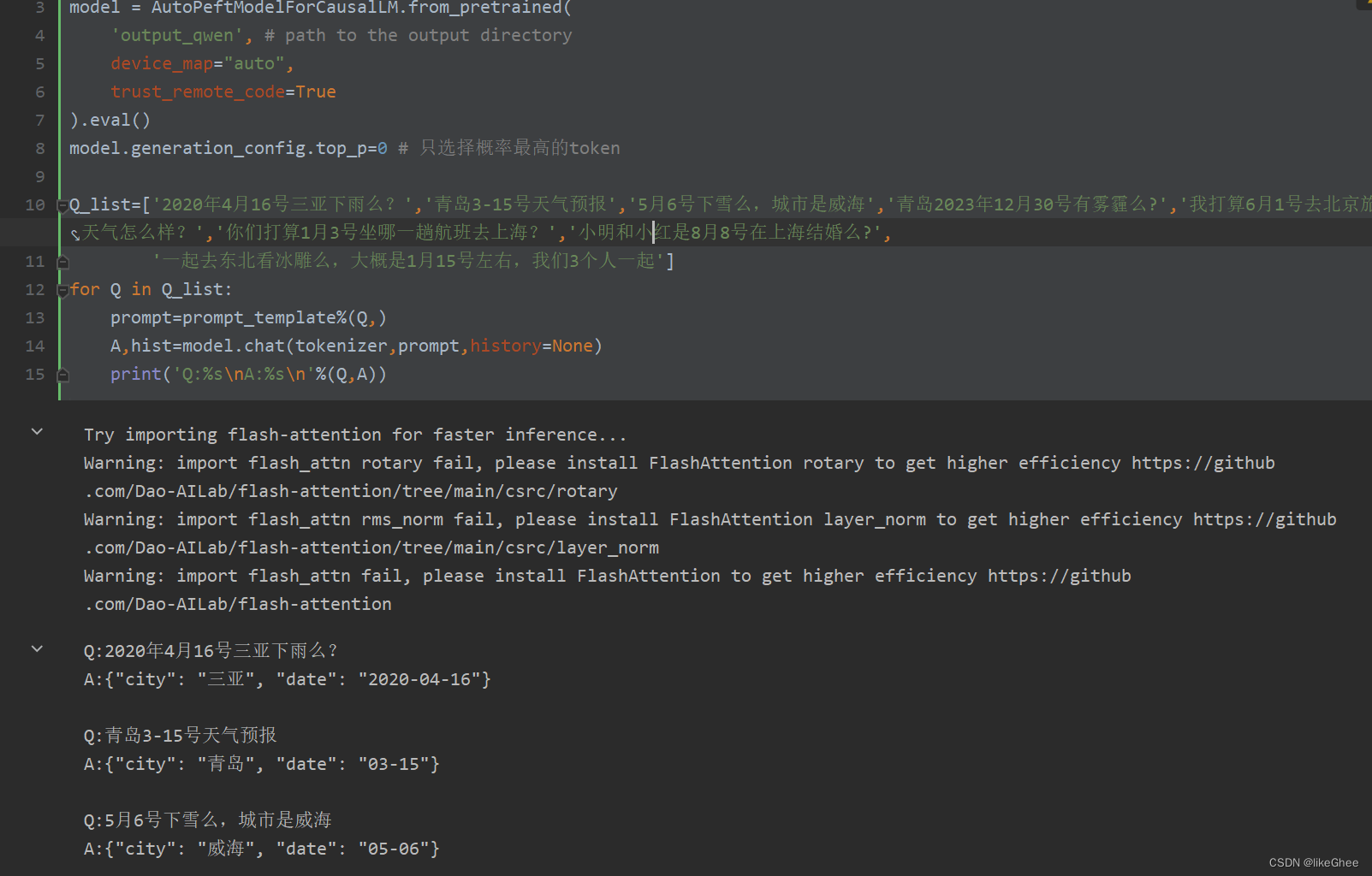
model.generation_config.top_p=0 # 只选择概率最高的token
Q_list=['2020年4月16号三亚下雨么?','青岛3-15号天气预报','5月6号下雪么,城市是威海','青岛2023年12月30号有雾霾么?','我打算6月1号去北京旅游,请问天气怎么样?','你们打算1月3号坐哪一趟航班去上海?','小明和小红是8月8号在上海结婚么?',
'一起去东北看冰雕么,大概是1月15号左右,我们3个人一起']
for Q in Q_list:
prompt=prompt_template%(Q,)
A,hist=model.chat(tokenizer,prompt,history=None)
print('Q:%s\nA:%s\n'%(Q,A))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
微调结果测试来看非常稳定
部署方案
参考资料:https://github.com/QwenLM/Qwen/blob/main/README_CN.md
部署部分
vLLM部署方案
不展开
总结
LLM大模型问题,返回值的不稳定,这时候我们就可以自己微调。
prompt工程可以参考范例react_prompt.md(强推!)
附录: ReAct Prompting 示例
本文档将介绍如何用 ReAct Prompting 技术命令千问使用工具。
本文档主要基本的原理概念介绍,并在文末附上了一些具体实现相关的 FAQ,但不含被调用插件的实际实现。如果您更喜欢一边调试实际可执行的代码、一边理解原理,可以转而阅读整合了 LangChain 常用工具的这个 ipython notebook。
此外,本文档和前述的 ipython notebook 都仅介绍单轮对话的实现。如果想了解多轮对话下的实现,可参见 react_demo.py。
准备工作一:样例问题、样例工具
假设我们有如下的一个适合用工具处理的 query,以及有夸克搜索、通义万相文生图这两个工具:
query = '现在给我画个五彩斑斓的黑。' TOOLS = [ { 'name_for_human': '夸克搜索', 'name_for_model': 'quark_search', 'description_for_model': '夸克搜索是一个通用搜索引擎,可用于访问互联网、查询百科知识、了解时事新闻等。', 'parameters': [{ 'name': 'search_query', 'description': '搜索关键词或短语', 'required': True, 'schema': { 'type': 'string' }, }], }, { 'name_for_human': '通义万相', 'name_for_model': 'image_gen', 'description_for_model': '通义万相是一个AI绘画(图像生成)服务,输入文本描述,返回根据文本作画得到的图片的URL', 'parameters': [{ 'name': 'query', 'description': '中文关键词,描述了希望图像具有什么内容', 'required': True, 'schema': { 'type': 'string' }, }], }, ]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
准备工作二:ReAct 模版
我们将使用如下的 ReAct prompt 模版来激发千问使用工具的能力。
TOOL_DESC = """{name_for_model}: Call this tool to interact with the {name_for_human} API. What is the {name_for_human} API useful for? {description_for_model} Parameters: {parameters} Format the arguments as a JSON object.""" REACT_PROMPT = """Answer the following questions as best you can. You have access to the following tools: {tool_descs} Use the following format: Question: the input question you must answer Thought: you should always think about what to do Action: the action to take, should be one of [{tool_names}] Action Input: the input to the action Observation: the result of the action ... (this Thought/Action/Action Input/Observation can be repeated zero or more times) Thought: I now know the final answer Final Answer: the final answer to the original input question Begin! Question: {query}"""
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
步骤一:让千问判断要调用什么工具、生成工具入参
首先我们需要根据 ReAct prompt 模版、query、工具的信息构建 prompt:
tool_descs = [] tool_names = [] for info in TOOLS: tool_descs.append( TOOL_DESC.format( name_for_model=info['name_for_model'], name_for_human=info['name_for_human'], description_for_model=info['description_for_model'], parameters=json.dumps( info['parameters'], ensure_ascii=False), ) ) tool_names.append(info['name_for_model']) tool_descs = '\n\n'.join(tool_descs) tool_names = ','.join(tool_names) prompt = REACT_PROMPT.format(tool_descs=tool_descs, tool_names=tool_names, query=query) print(prompt)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
打印出来的、构建好的 prompt 如下:
Answer the following questions as best you can. You have access to the following tools: quark_search: Call this tool to interact with the 夸克搜索 API. What is the 夸克搜索 API useful for? 夸克搜索是一个通用搜索引擎,可用于访问互联网、查询百科知识、了解时事新闻等。 Parameters: [{"name": "search_query", "description": "搜索关键词或短语", "required": true, "schema": {"type": "string"}}] Format the arguments as a JSON object. image_gen: Call this tool to interact with the 通义万相 API. What is the 通义万相 API useful for? 通义万相是一个AI绘画(图像生成)服务,输入文本描述,返回根据文本作画得到的图片的URL Parameters: [{"name": "query", "description": "中文关键词,描述了希望图像具有什么内容", "required": true, "schema": {"type": "string"}}] Format the arguments as a JSON object. Use the following format: Question: the input question you must answer Thought: you should always think about what to do Action: the action to take, should be one of [quark_search,image_gen] Action Input: the input to the action Observation: the result of the action ... (this Thought/Action/Action Input/Observation can be repeated zero or more times) Thought: I now know the final answer Final Answer: the final answer to the original input question Begin! Question: 现在给我画个五彩斑斓的黑。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
将这个 prompt 送入千问,并记得设置 “Observation” 为 stop word (见本文末尾的 FAQ)—— 即让千问在预测到要生成的下一个词是 “Observation” 时马上停止生成 —— 则千问在得到这个 prompt 后会生成如下的结果:
Thought: 我应该使用通义万相API来生成一张五彩斑斓的黑的图片。
Action: image_gen
Action Input: {"query": "五彩斑斓的黑"}
- 1
- 2
- 3
在得到这个结果后,调用千问的开发者可以通过简单的解析提取出 {"query": "五彩斑斓的黑"} 并基于这个解析结果调用文生图服务 —— 这部分逻辑需要开发者自行实现,或者也可以使用千问商业版,商业版本将内部集成相关逻辑。
步骤二:让千问根据插件返回结果继续作答
让我们假设文生图插件返回了如下结果:
{"status_code": 200, "request_id": "3d894da2-0e26-9b7c-bd90-102e5250ae03", "code": null, "message": "", "output": {"task_id": "2befaa09-a8b3-4740-ada9-4d00c2758b05", "task_status": "SUCCEEDED", "results": [{"url": "https://dashscope-result-sh.oss-cn-shanghai.aliyuncs.com/1e5e2015/20230801/1509/6b26bb83-469e-4c70-bff4-a9edd1e584f3-1.png"}], "task_metrics": {"TOTAL": 1, "SUCCEEDED": 1, "FAILED": 0}}, "usage": {"image_count": 1}}
- 1
接下来,我们可以将之前首次请求千问时用的 prompt 和 调用文生图插件的结果拼接成如下的新 prompt:
Answer the following questions as best you can. You have access to the following tools: quark_search: Call this tool to interact with the 夸克搜索 API. What is the 夸克搜索 API useful for? 夸克搜索是一个通用搜索引擎,可用于访问互联网、查询百科知识、了解时事新闻等。 Parameters: [{"name": "search_query", "description": "搜索关键词或短语", "required": true, "schema": {"type": "string"}}] Format the arguments as a JSON object. image_gen: Call this tool to interact with the 通义万相 API. What is the 通义万相 API useful for? 通义万相是一个AI绘画(图像生成)服务,输入文本描述,返回根据文本作画得到的图片的URL Parameters: [{"name": "query", "description": "中文关键词,描述了希望图像具有什么内容", "required": true, "schema": {"type": "string"}}] Format the arguments as a JSON object. Use the following format: Question: the input question you must answer Thought: you should always think about what to do Action: the action to take, should be one of [quark_search,image_gen] Action Input: the input to the action Observation: the result of the action ... (this Thought/Action/Action Input/Observation can be repeated zero or more times) Thought: I now know the final answer Final Answer: the final answer to the original input question Begin! Question: 现在给我画个五彩斑斓的黑。 Thought: 我应该使用通义万相API来生成一张五彩斑斓的黑的图片。 Action: image_gen Action Input: {"query": "五彩斑斓的黑"} Observation: {"status_code": 200, "request_id": "3d894da2-0e26-9b7c-bd90-102e5250ae03", "code": null, "message": "", "output": {"task_id": "2befaa09-a8b3-4740-ada9-4d00c2758b05", "task_status": "SUCCEEDED", "results": [{"url": "https://dashscope-result-sh.oss-cn-shanghai.aliyuncs.com/1e5e2015/20230801/1509/6b26bb83-469e-4c70-bff4-a9edd1e584f3-1.png"}], "task_metrics": {"TOTAL": 1, "SUCCEEDED": 1, "FAILED": 0}}, "usage": {"image_count": 1}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
用这个新的拼接了文生图插件结果的新 prompt 去调用千问,将得到如下的最终回复:
Thought: 我已经成功使用通义万相API生成了一张五彩斑斓的黑的图片。
Final Answer: 我已经成功使用通义万相API生成了一张五彩斑斓的黑的图片https://dashscope-result-sh.oss-cn-shanghai.aliyuncs.com/1e5e2015/20230801/1509/6b26bb83-469e-4c70-bff4-a9edd1e584f3-1.png。
- 1
- 2
虽然对于文生图来说,这个第二次调用千问的步骤显得多余。但是对于搜索插件、代码执行插件、计算器插件等别的插件来说,这个第二次调用千问的步骤给了千问提炼、总结插件返回结果的机会。
FAQ
怎么配置 “Observation” 这个 stop word?
通过 chat 接口的 stop_words_ids 指定:
react_stop_words = [
# tokenizer.encode('Observation'), # [37763, 367]
tokenizer.encode('Observation:'), # [37763, 367, 25]
tokenizer.encode('Observation:\n'), # [37763, 367, 510]
]
response, history = model.chat(
tokenizer, query, history,
stop_words_ids=react_stop_words # 此接口用于增加 stop words
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如果报错称不存在 stop_words_ids 此参数,可能是因为您用了老的代码,请重新执行 from_pretrained 拉取新的代码和模型。
需要注意的是,当前的 tokenizer 对 \n 有一系列较复杂的聚合操作。比如例子中的:\n这两个字符便被聚合成了一个 token。因此配置 stop words 需要非常细致地预估 tokenizer 的行为。
对 top_p 等推理参数有调参建议吗?
通常来讲,较低的 top_p 会有更高的准确度,但会牺牲回答的多样性、且更易出现重复某个词句的现象。
可以按如下方式调整 top_p 为 0.5:
model.generation_config.top_p = 0.5
- 1
特别的,可以用如下方式关闭 top-p sampling,改用 greedy sampling,效果上相当于 top_p=0 或 temperature=0:
model.generation_config.do_sample = False # greedy decoding
- 1
此外,我们在 model.chat() 接口也提供了调整 top_p 等参数的接口。
有解析Action、Action Input的参考代码吗?
有的,可以参考:
def parse_latest_plugin_call(text: str) -> Tuple[str, str]:
i = text.rfind('\nAction:')
j = text.rfind('\nAction Input:')
k = text.rfind('\nObservation:')
if 0 <= i < j: # If the text has `Action` and `Action input`,
if k < j: # but does not contain `Observation`,
# then it is likely that `Observation` is ommited by the LLM,
# because the output text may have discarded the stop word.
text = text.rstrip() + '\nObservation:' # Add it back.
k = text.rfind('\nObservation:')
if 0 <= i < j < k:
plugin_name = text[i + len('\nAction:'):j].strip()
plugin_args = text[j + len('\nAction Input:'):k].strip()
return plugin_name, plugin_args
return '', ''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
此外,如果输出的 Action Input 内容是一段表示 JSON 对象的文本,我们建议使用 json5 包的 json5.loads(...) 方法加载。

