
- 1艾媒金榜|2023年中国信创数据库企业TOP15_信创国产数据库名录
- 2chat gpt论文写作(ai人工智能写作免费)_gpt免费写论文网址
- 3Xms Xmx PermSize MaxPermSize 区别_?ref=br2rq9qya7a
- 4Python计算机视觉编程——第8章 图像内容分类_计算机视觉第8章
- 5数据库国产化应用改造实践_应用系统国产化适配方案
- 6python飞机大战,感受python的乐趣(详细中文解读,含完整代码)_python人马大战csdn
- 7virtualbox mac (免费) 安装 centOS8 (含支持屏幕分辨率设置的VirtualBox增强功能安装)_virtualbox centos8屏幕
- 8在《糖豆人》身上,我们看到了竞技游戏火爆的六大因素_糖豆人开发成本
- 9JVM学习笔记
- 10【转】基于知识图谱的推荐系统(KGRS)综述_基于知识图谱的推荐算法
Kafka 痛点专题|AutoMQ 如何解决 Kafka 冷读副作用_mq冷读
赞
踩
背景
Apche Kafka (下文简称 Kafka)作为一款成功的流处理平台已经在各行各业中有广泛的应用,并且具备极其强大的软件生态。但是,其一些缺点也给使用者带来了很大的挑战。AutoMQ 是基于云原生架构实现的新一代 Kafka ,与 Kafka 100% 完全兼容。致力于解决 Kafka 原有的迁移复制低效、缺乏弹性、成本高昂等缺点,成为新一代云原生 Kafka 解决方案。
为了让读者更好地理解 AutoMQ 相比 Kafka 的优势,我们推出了 《Kafka 痛点专题》 这个系列,帮助读者更好地理解当前 Kafka 存在的痛点问题以及 AutoMQ 是如何解决这些问题的。今天主要分享的是 Kafka 中冷读(也可称追赶读,即 Catch-up Read )副作用的产生原理,以及 AutoMQ 是如何通过云原生的架构设计来避免原 Kafka 冷读带来的副作用的。
冷读是如何产生的
在消息和流系统中,冷读是常见且具有重要价值的场景,包括以下几点:
• 保证削峰填谷的效果: 消息系统通常用于业务解耦和削峰填谷。在削峰填谷场景中,消息队列可暂时保存上游数据,以便下游逐步消费。这些数据通常不在内存中,而是需要进行冷读取。因此,优化冷读效率对于提高削峰填谷的效果至关重要。
• 批处理场景广泛应用: 在与大数据分析结合时,Kafka 通常用于处理批处理场景。在这种情况下,任务需要从几个小时甚至一天前的数据开始扫描计算。冷读的效率直接影响了批处理的时效性。
• 故障恢复效率: 在实际生产环境中,消费者由于逻辑问题或业务 BUG 导致故障宕机是常见问题。消费者恢复后,需要快速消费堆积的历史数据。提高冷读效率可以帮助业务更快从消费者宕机故障中恢复,减少中断时间。
• Kafka 分区迁移时数据复制引发冷读: Kafka 在扩容时需要迁移分区数据,这时候也会引发冷读。
冷读是 Kafka 中实际应用中必然需要面临的正常需求。对于 AutoMQ 而言,我们并不会去尝试消除冷读,而是重点在于解决好 Kafka 冷读本身带来的副作用。
冷读带来的副作用
接下来我们会分析 Kafka 冷读具体会带来哪些副作用,以及为什么 Kafka 没有办法解决这些问题。
硬盘 I/O 争抢问题
Kafka 运维中的一个重要挑战是处理冷读时对硬盘 I/O 的大量占用。硬盘或云盘的单盘 IOPS 和吞吐能力有限。冷读会导致从硬盘大量读取数据,当某些分区数据在节点上分布不均时,容易造成热点访问。对大量数据的分区进行冷读会快速占用单盘的 IOPS 和吞吐资源,直接影响节点上其他 Topic 分区数据的读写性能。
Kafka 没法解决该副作用的主要原因是其本身存储实现强依赖本地存储。Kafka 的数据全部存储在 Broker 的本地磁盘上,冷读时消耗大量磁盘 I/O 导致其他读写请求需要访问磁盘时性能受限。即使像 Kafka 商业化公司 Confluent 实现了 KIP-405 所描绘的分层存储,该问题仍然没有得到彻底的解决。在 Kafka 分层存储的实现中,Kafka 仍然要求分区的最后一个 LogSegment 必须在本地磁盘上,Broker 和本地存储仍然是强依赖的。因此,Kafka 冷读时则并不能完全从 S3 或者内存从读取数据,其必然有请求需要从分区的最后一个 LogSegment 中读取数据。当 LogSegment 的数据比较大时,硬盘 I/O 的争抢问题也将会更加严重。总的来说,Kafka 采用分层存储试图一定程度去降低冷读副作用的影响,但是并没有在根本上解决问题。

Page Cache 污染
Kafka 冷读时,从磁盘加载大量数据经过 Page Cache 供消费者读取,会造成 Page Cache 的数据污染。Page Cache 的大小是比较有限的,由于本质是个缓存,当新的对象需要加入 Page Cache 时,如果其容量不足,就会驱逐一些旧的对象。
Kafka 没有做冷热隔离,当冷读发生时,大量冷数据的读取会迅速抢占 Page Cache 的容量,将其中其他 Topic 的数据驱逐出去。当其他 Topic 的消费者需要从 Page Cache 读取数据的时候就会发生 Cache Miss,进而必须从硬盘中读取数据,此时读取的延迟将会大大增加。在这种情况下,由于从硬盘加载数据,整体的吞吐性能也会快速退化。Kafka 利用 Pache Cache 结合 sendfile 系统调用在没有发生冷读时有很好的性能表现,但是一旦发生冷读,其对吞吐和读写延迟的影响将会令人非常头疼。
Kafka 没法很好的解决该问题主要还是因为其读写模型本身设计上强依赖 Page Cache 来兑现其强大的性能和吞吐的。
Zero Copy 在冷读时阻塞网络请求
Kafka 采用零拷贝技术sendfile 来避免内核态和用户态交互的开销来提升性能一直以来被大家津津乐道。但是不可否认的是, sendfile 在冷读时,会带来额外的副作用。
在 Kafka 的网络线程模型中,读写请求会共享一个网络线程池来处理网络请求。在没有冷读的理想场景下,网络线程经过 Kafka 的处理后,需要向网络返回数据时,直接从 Page Cache 加载数据返回,整个请求响应在几微秒内可以完成,整个读写流程是非常高效的。
但是如果产生了冷读,Kafka 网络线程向网络的内核发送缓冲区写数据时,调用 sendfile 需要先将磁盘加载到 Page Cache 中,然后再写到网络的内核发送缓冲区。在这个零拷贝过程中,Linux 内核态从磁盘加载数据到 Page Cache 的过程中是个同步的系统调用,因此网络线程只能同步等待其关联的数据从磁盘加载数据完成,才可以继续去处理别的工作。
Kafka 的网络线程池是被 Client 的读写网络请求共享的。冷读时,Kafka 网络线程池中大量网络线程在同步等待系统调用返回,这会阻塞新的网络请求被处理,同时也使得消费者消费的延迟进一步增加。下图演示了冷读时, sendfile 是如何影响网络线程的处理从而进一步拖慢整体的生产和消费效率的。

根据上文的原理分析可知,Kafka 之所以没办法很好的解决这个问题主要还是受限于其线程模型的设计。在 Kafka 的读写线程模型中,读写共享网络线程池,冷读时 sendfile 的慢操作没有与读写核心流程异步解耦导致了其在冷读时网络线程成为瓶颈,进而造成明显的吞吐性能下降。
AutoMQ 如何解决冷读副作用
冷热隔离
对象存储是云上最具规模化、成本和技术红利的云服务。我们可以看到,像 Confluent, Snowflake 都在基于云对象存储重塑自己的软件服务来给用户提供更低成本、更稳定和弹性的存储能力。基于云对象存储重新设计基础软件也成为当前 Infra 领域软件设计的新风尚。AutoMQ 作为一款真正意义上的云原生软件,在设计之初就确定需要将对象存储作为其主存,从而设计了流场景中,面向对象存储的流存储库 S3Stream 。该流存储库在 Github 上也已开源,可以搜索 automq-for-kafka 关注。
AutoMQ 使用对象存储作为主存储,不仅带来了极致的成本和弹性优势,另外一个非常重要的益处就是有效隔离了冷热数据,从根源上解决了 Kafka 硬盘 I/O 争抢的问题。在 AutoMQ 的读写模型中,冷读时数据会直接从对象存储上加载数据,而不是从本地磁盘上读取数据,这样就天然的隔离了冷读,自然也就不会抢占本地磁盘的 I/O 了。
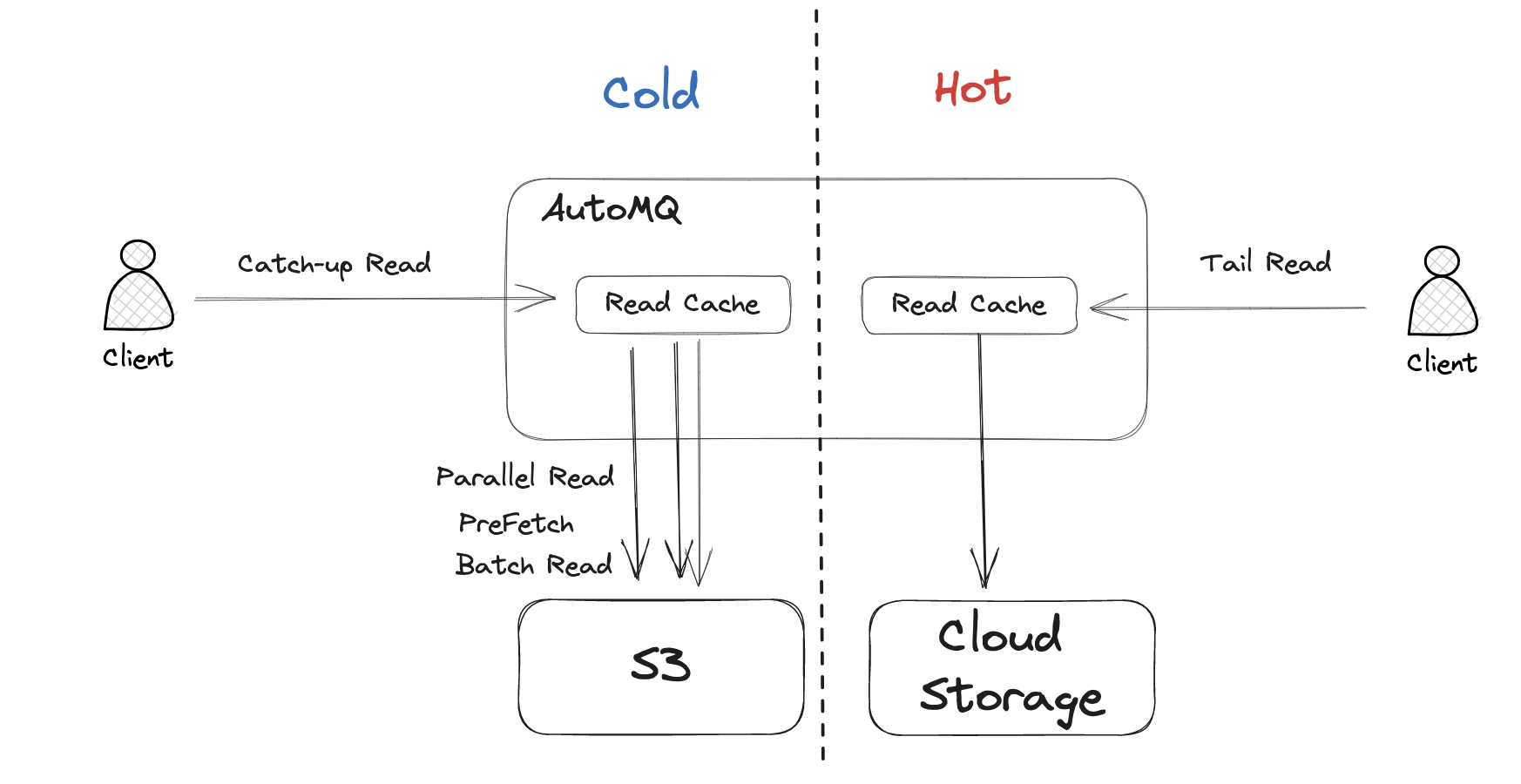
此外,AutoMQ 基于对象存储实现的冷读隔离是不会有性能上的副作用的。通过并发、预读和批量读取等技术优化措施,在冷读时的吞吐性能上可以完全匹敌 Kafka。
自主管理内存不依赖 Page Cache
AutoMQ 的读写模型中并没有依赖 Page Cache,因此也自然不会有 Kafka Page Cache 污染的副作用。虽然摒弃了使用 Page Cache,但是 AutoMQ 在性能上并没有妥协,主要是因为采取了如下一系列的技术手段。
使用 Direct I/O 读写裸设备 AutoMQ 绕过文件系统,通过 Direct I/O 直接读写裸设备。这带来的好处主要是:
• 避免 Page Cache 污染: 绕过文件系统自然也就不存在 Page Cache 污染了
• 减少数据复制: 使用 Direct I/O 直接读取裸设备,数据只有一次复制,从硬件直接拷贝到应用程序的用户态。
• 减少文件系统开销: 文件系统一般需要写 Journal,管理 Metadata,在写入上会相比实际写入消耗更多的带宽以及 IOPS,写入路径也更长,所以性能上会比裸设备差。
• 更快的容灾恢复速度: AutoMQ 的 WAL 数据会保留在云盘上,然后异步刷出到对象存储。当计算实例宕机时,云盘会自动漂移挂载到其他可用的机器上,由 AutoMQ 完成容灾操作,即将其云盘上剩余的 WAL 刷出到对象存储然后再删除云盘。在这个容灾过程中,由于直接操作的裸设备,可以避免文件系统恢复的时间开销,提升容灾的时效性。
• 避免 Kafka 数据丢失: AutoMQ 需要将数据持久化到云盘才返回给客户端成功响应。在 Kafka 的默认推荐配置中,为了保证性能一般都是异步持久化数据的。当机房断电这种场景时,文件系统残留脏页会丢失导致数据丢失。
自主管理堆外内存
利用文件系统的 Page Cache 提升性能是一种比较取巧的方式。对于 Kafka 而言,意味着其无需自身实现一套内存 Cache,也不用担心其 JVM 的对象开销和 GC 问题。不得不说,在非冷读场景下,这种方式确实是有着不错的表现。但是一旦出现冷读,Kafka 用户态对 Page Cache 的默认行为干预能力就很有限,没法做一些精细化的管理。因此,像 Kafka 冷读时 Page Cache 的污染就很难处理。
AutoMQ 在设计之初就是充分考虑到了使用 Page Cache 的利弊,在自研的 S3Strean 流存储库中,实现了 JVM 堆外内存的高效自主管理。通过设计冷热隔离的缓存 BlockCache 和 LogCache,可以保证在各种场景下均可以完成高效的内存读写。在未来的迭代中,AutoMQ 也可以根据流场景对内存读写进行更加精细化地管理和优化。
异步 I/O 响应网络层
Kafka 的线程模型本质上是围绕 Page Cache 和零拷贝技术来设计的。前文也指出了其核心问题是在冷读时,网络线程同步等待磁盘读取,导致整个读写流程受阻,影响了性能。
AutoMQ 没有出现的问题也是得益于其自主实现的内存管理机制。由于没有依赖 Page Cache,AutoMQ 存储层实现时会异步加载完数据再响应到网络层,因此读写请求不会同步等待 磁盘 I/O 完成才去处理别的工作。这使得整体的读写处理变得更加高效。
冷读的性能
冷读是 Kafka 中的常见应用场景,AutoMQ 在处理 Kafka 冷读副作用时,不仅做到了冷热隔离,同时也考虑到了确保冷读性能不受影响的重要性。
AutoMQ 通过以下几种技术手段保证了冷读时的性能:
• 对象存储读取性能优化: 通过预读、并发和缓存等手段直接从对象存储读取数据,保证了整体上优异的吞吐性能。
• 云原生的存储层实现,减少网络开销: AutoMQ 利用了云盘底层的多副本机制保证了数据的可靠性,因此在 Broker 层面可以减少副本复制的网络延迟开销。从而相比 Kafka 有更好的延迟、总体吞吐表现。
以下表格的结果来自于 AutoMQ vs Kafka 的实测性能对比报告,显示在相同负载和机型下相比 Kafka,AutoMQ 冷读时可以保证不影响写入吞吐和延迟的情况下,拥有和 Kafka 相同水准的冷读性能。
|
对比项 |
追赶读过程中发送耗时 |
追赶读过程中对发送流量影响 |
追赶读峰值吞吐 |
AutoMQ |
小于3ms |
读写隔离,维持800 MiB/s |
2500-2700MiB/s |
|
Apache Kafka |
大约800ms |
相互影响, 下跌到150 MiB/s |
2600-3000MiB/s (牺牲写入) |
总结
本文着重剖析了 Kafka 在冷读时产生问题的原理,以及 AutoMQ 的解法。下一篇 《Kafka 痛点专题》我们将探讨 Kafka 痛点中的 No.1 ,即弹性,敬请期待。
END
关于我们
我们来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

