- 1智能车电磁组——环岛处理_智能车电磁环岛处理方法
- 2数模笔记-马尔可夫预测
- 3Net 6.0 中断性变更 Microsoft.AspNetCore.Http.Features 导致 IFormFile 无法引用_microsoft.aspnetcore.http 弃用
- 4MAC MINI 2012安装Montery折腾笔记_macmini2012升级最高系统
- 5【无标题】pytorch构建利用迁移学习MNIST数据集的加法器实验_手写数字加法机
- 6自然语言处理课程期末总结_自然语言处理期末报告
- 7基于MATLAB的SI/SIS传染病模型仿真与模拟_sis传染病模型matlab代码
- 8Springboot整合FastDFS_fastdfsclient
- 9Spring Boot 启动性能优化实践_springboot 项目启动优化
- 10【全国计算机二级】python的jieba模块,你真的了解吗?_python二级用到的模块
id3决策树_信息熵、信息增益和决策树(ID3算法)
赞
踩
决策树算法:
优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关的特征数据。
缺点:可能会产生过度匹配问题。
适用数据类型:数值型和标称型。
算法原理:
决策树是一个简单的为输入值选择标签的流程图。这个流程图由检查特征值的决策节点和分配标签的子叶节点组成。为输入值选择标签,我们以流程图的初始决策节点(即根节点)开始。此节点包含一个条件,检查输入值的特征之一,基于该特征的值选择一个分支。沿着这个描述我们输入值的分支,我们到到了一个新的决策节点,有一个关于输入值的特征的新条件。我们继续沿着每个节点的条件选择的分支,直到到达叶节点,它为输入值提供了一个标签。
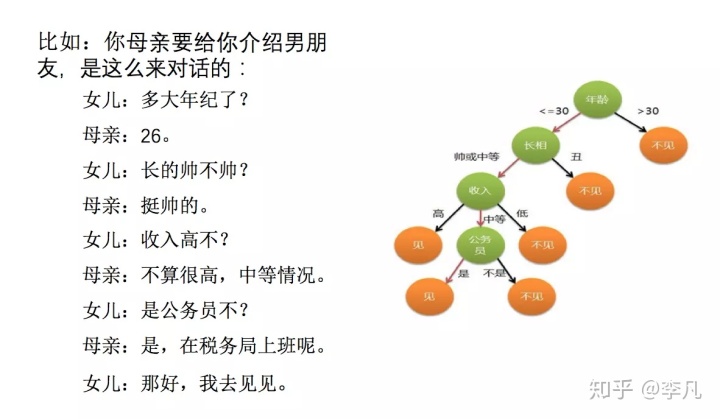
image.png
算法流程:
收集数据:即建立训练测试数据集。
准备数据:决策树构造算法只适用于标称型数据,因此数值型数据必须是离散化的。
分析数据:建立构造树,构造树完成后我们检查图形是否符合预期。
训练数据:完善构造树的数据结构。
测试数据:使用经验树计算。
使用算法:对实际数据进行预测。
ID3算法:
ID3算法(Iterative Dichotomiser 3,迭代二叉树3代)是一种贪心算法,用来构造决策树。ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例。
为了实现ID3算法我们还需要了解这个高富帅提出的三个概念:信息、信息熵和信息增益。

ID3算法
并且由上面的公式我们可以看出其实信息熵就是信息的期望值,所以我们可知,信息熵越小,信息的纯度越高,也就是信息越少,在分类领域来讲就是里面包含的类别越少,所以我们可以得出,与初始信息熵的差越大分类效果越好。
下面我们来举个例子:
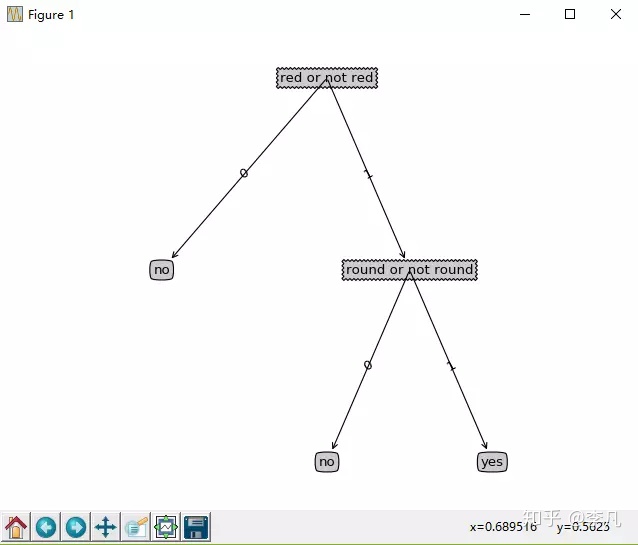
买苹果的时候,从外观上评判一个苹果甜不甜有两个依据:红不红 和 圆不圆 (原谅我浅薄的挑苹果经验吧。。。)
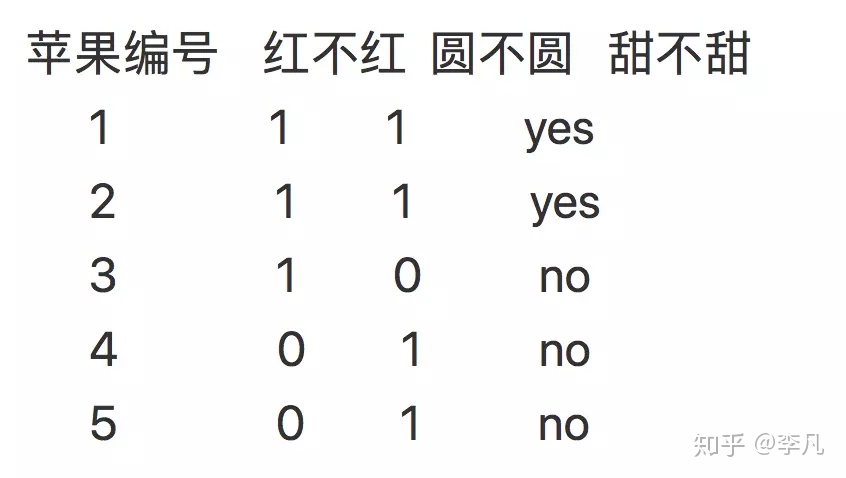
挑苹果
下面来算一下啊这5个苹果是不是好苹果的信息熵(只看结果值):

信息熵
下面给出python求信息熵的代码
- def calcShannonEnt(dataSet):
- numEntries = len(dataSet) #数据集大小
- labelCounts = {}
- for featVec in dataSet:
- currentLabel = featVec[-1] #获取分类标签
- if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0
- labelCounts[currentLabel] += 1 #每个类中数据个数统计
- shannonEnt = 0.0
- for key in labelCounts: #信息熵计算
- prob = float(labelCounts[key])/numEntries
- shannonEnt -= prob * log(prob,2)
- return shannonEnt
我们来用程序求一下我们这个小例子的结果:
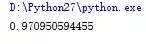
小例子的结果
接下来我们要寻找怎么分类比较好也就是决策树的叉,我们的例子中可以按两个方式分类,红不红和圆不圆。。到的按哪个分更好一点呢,这下就用到信息增益了:
def 按红不红分类的各项数据结果
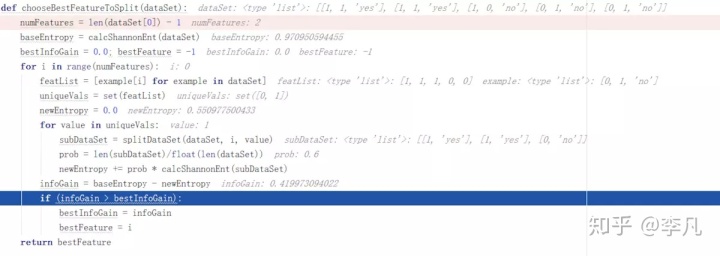
红不红分类
计算方法为:总的信息熵 - 红不红的信息熵

红不红的信息增益
我们可以看出,这种分类的信息熵是0.5509775,它的信息增益是0.419973
如果按照圆不圆来分类:
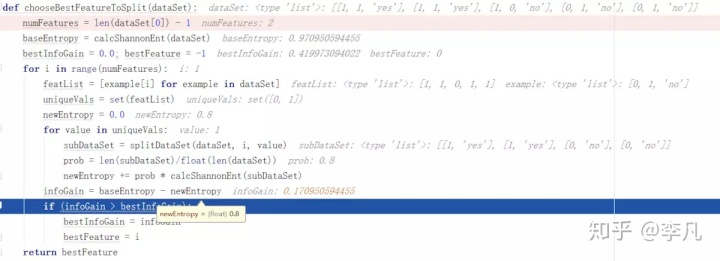
圆不圆分类
我们可以看出,这种分类的信息熵是0.8,它的信息增益是0.17095
显然第一种分类的信息增益较大
我们来看一下啊两个划分的结果集:

两个划分的结果集
确实第一种方法划分的较好。
这样我们的决策树也就构建好了: