
- 1人工智能在日常农业种植中的应用_人工智能技术在种植技术中的应用
- 2瑞吉外卖(部署维护篇)_瑞吉外卖的sh脚本如何修改
- 3【深度学习】yolov5训练自定义目标检测模型并进行验证_yolov5增加长目标检测曾
- 4Unity3D - 使用天空盒子(Using Skyboxes)_unity 天空盒带远景
- 5【技术分享】使用Matlab对含分布式电源的33节点配电网进行潮流计算与节点电压分析_matlab 节点电压计算
- 6【笔记】项目领导力培训笔记_shock anger rejection acceptance
- 7IDEA 2024 mac + linux + windows安装_mac 安装 idea
- 8c#使用OleDb库更改Access数据库的密码
- 9拾旧梦!向未来!趁现在还不晚
- 10李洪强漫谈iOS开发[C语言-010] - C语言简要复习
Transformer平替!Mamba系列论文整理分享_swintransformer和mamba
赞
踩
来源: AINLPer公众号(每日干货分享!!)
编辑: ShuYini
校稿: ShuYini
时间: 2024-3-9
引言
今年ICLR204,得分为8/8/6/3的Mamba论文被拒,其主要原因是ICLR 2024的审稿人认为该篇文章还存在重大的缺陷,在实验评估方法上面存在一定的争议。
虽说被拒,但是Mamba确实一种新型的选择性状态空间模型方法,在语言建模方面可以媲美Transformer,并且目前已经有了很多结合Mamba的研究成果。那么,今天作者就整理了几篇与Mamba相关的文章。获取方式,GZ: AINLPer公众号 回复:mamba论文
Mamba原文

Transformer 模型中自注意力机制的计算量会随着上下文长度的增加呈平方级增长,比如上下文增加 32 倍时,计算量可能会增长 1000 倍,计算效率非常低。

在这篇论文中,研究者提出了一种新的架构—「选择性状态空间模型( selective state space model)」。它在多个方面改进了先前的工作。
实验结果表明,「Mamba」在语言建模方面可以媲美甚至击败 Transformer。而且,它可以随上下文长度的增加实现线性扩展,其性能在实际数据中可提高到百万 token 长度序列,并实现 5 倍的推理吞吐量提升。
MoE-Mamba

状态空间模型(SSM)是近来一种备受关注的 Transformer 替代技术,其优势是能在长上下文任务上实现线性时间的推理、并行化训练和强大的性能。而基于选择性 SSM 和硬件感知型设计的 Mamba 更是表现出色,成为了基于注意力的 Transformer 架构的一大有力替代架构。

近日,本文给出的研究成果是 MoE-Mamba,即将 Mamba 和混合专家层组合起来的模型。MoE-Mamba 能同时提升 SSM 和 MoE 的效率。而且该团队还发现,当专家的数量发生变化时,MoE-Mamba 的行为是可预测的。
Mamba前世今生

文中,作者首先介绍了一类具有众多表征和属性的模型,概括了标准深度序列模型(如循环神经网络和卷积神经网络)的优势。然而,作者表明计算这些模型可能具有挑战性,并开发了在当前硬件上运行非常快速的新型结构化状态空间,无论是在扩展到长序列时还是在自回归推理等其他设置中都是如此。
最后,作者提出了一个用于对连续信号进行增量建模的新颖数学框架,该框架可与状态空间模型相结合,为其赋予原则性的状态表示,并提高其对长程依赖关系的建模能力。总之,这一类新方法为机器学习模型提供了有效而多用途的构建模块,特别是在大规模处理通用序列数据方面。
Vision Mamba

本文作者提出了Vision Mamba,在 ImageNet 分类任务、COCO 对象检测任务和 ADE20k 语义分割任务上,与 DeiT等成熟的视觉 Transformers 相比,Vim 实现了更高的性能,同时还显著提高了计算和内存效率。例如,在对分辨率为 1248×1248 的图像进行批量推理提取特征时,Vim 比 DeiT 快 2.8 倍,并节省 86.8% 的 GPU 内存。
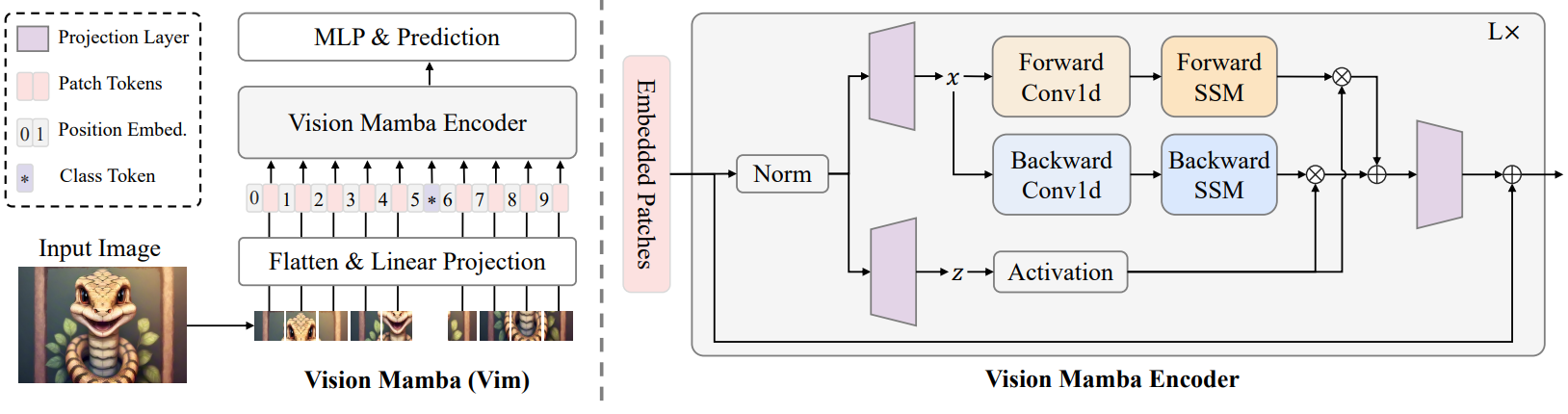
结果表明,Vim 能够克服对高分辨率图像执行 Transformer 式理解时的计算和内存限制,并且具有成为视觉基础模型的下一代骨干的巨大潜力。
VMamba

卷积神经网络(CNN)和视觉Transformer(ViT)是视觉表示学习的两种最流行的基础模型。 虽然 CNN 表现出卓越的可扩展性和线性复杂度。 尽管在图像分辨率方面,ViT 的拟合能力超过了它们,但其复杂性却是二次方。 观察发现,ViT 通过结合全局感受野和动态权重,实现了卓越的视觉建模性能。

受 Mamba 模型的启发,研究者设计出一种在线性复杂度下同时具有这两种优秀性质的模型,即 Visual State Space Model(VMamba)。大量的实验证明,VMamba 在各种视觉任务中表现卓越。如下图所示,VMamba-S 在 ImageNet-1K 上达到 83.5% 的正确率,比 Vim-S 高 3.2%,比 Swin-S 高 0.5%。
SSM + Transformer
SSM 最初是为连续信号而设计的,现已在视觉和音频等众多任务中表现出卓越的性能。 然而,SSM 在语言建模任务中的性能仍然落后于 Transformer。
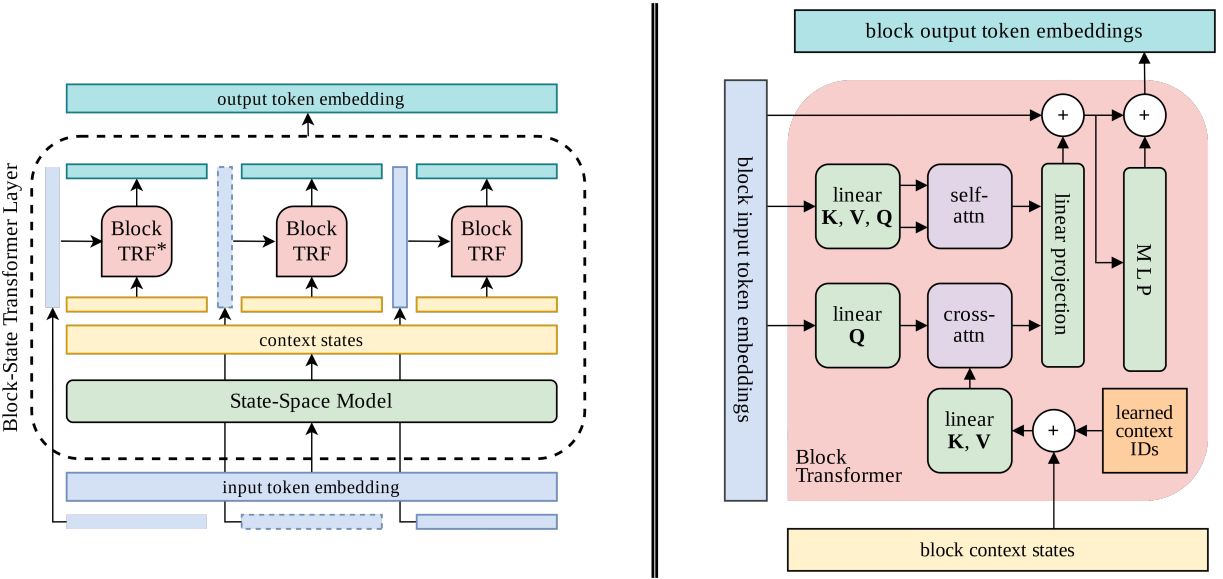
为此,本文作者提出了一个名为块状态Transformer(BST)的混合层,它在内部结合了用于远程上下文化的 SSM 子层和用于序列短期表示的块变换器子层。 本文研究了三种不同的、完全可并行的变体,它们都集成了 SSM 和块式注意力。
实验表明,本文模型在语言建模复杂性方面优于类似的基于 Transformer 的架构,并且可以推广到更长的序列。 此外,当采用模型并行化时,与块循环Transformer相比,块状态Transformer在层级别的速度提高了十倍以上。

