
开源网络负载测试工具-基准测试_开源免费网络测试工具
赞
踩
译者注:在上一篇《开源网络负载测试工具测评》文章中,我以我微薄的翻译功底向大家展现了Ragnar Lönn先生对当前主流开源负载测试工具的一些看法。Ragnar Lönn先生主要以测试工具性能,功能性,可拓展性,可继承性,可操作性这五个方面来评价了他选取的负载测试工具(说真的我觉得老外对一个工具不好是真的会从头喷到尾)。如果翻译有疏漏还请指出。
本篇译文在经过Ragnar Lönn先生的授权允许下,翻译Ragnar Lönn先生他选取的主流网络负载测试工具在基于同样标准下的基准测试结果。我相信译文中选评的很多工具的性能都是大家比较关心的。我会尽量在保持原文态度的情况下对齐完整的翻译并在适当的时候加上译者在实际测试过程中的理解。
引言
我们在最近的一篇博客中详细分析了当前主流的开源负载测试工具。在该博客中我们还承诺会分享我们在幕后为这些开源负载测试工具所做的基准测试。本篇文章我们将分享这些基准测试的结果,以便你能更加具体的了解我们如何为所选的开源负载工具所进行的性能评估。
还请记住,我们所选取的基准测试工具缩小到我们认为最受欢迎的开源负载测试工具,这些工具如下:
- Jmeter
- Gatling
- Locust
- The Grinder
- Apachebench
- Artillery
- Tsung
- Vegeta
- Siege
- Boom
- Wrk
开源负载测试工具 - 基准测试准备
系统配置
以下是我们进行基准测试时所使用的系统配置的详细信息。我们使用两个四核服务器,服务器处于同一个网段,两台测试服务器均使用千兆以太网卡。
压力机(负载生成器):
- Intel Core2 Q6600 Quad-core CPU @2.40Ghz
- Ubuntu 14.04 LTS (GNU/Linux3.13.0-93-generic x86_64)
- 4GB RAM
- Gigabit ethernet
服务端(负载接收器):
- Intel Xeon X3330 Quad-core CPU @2.66Ghz
- Ubuntu 12.04 LTS (GNU/Linux3.2.0-36-generic x86_64)
- 8GB RAM
- Gigabit ethernet
- Target web server: Nginx 1.1.19
因为被测物是比较各个压测工具的性能,所以在服务端我们没有对操作系统的内核参数做任何更改(以免影响其性能)。在压力端按照如下更改进行了内核参数配置。
压力机(负载生成器)系统优化:
我们使用了以下系统优化配置来运行我们的基准测试。(我们从Gatling的文档中借用了性能调参表)
net.core.somaxconn = 40000 net.core.wmem_default = 8388608 net.core.rmem_default = 8388608 net.core.rmem_max = 134217728 net.core.wmem_max = 134217728 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_max_syn_backlog = 40000 net.ipv4.tcp_sack = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_fin_timeout = 15 net.ipv4.tcp_keepalive_intvl = 30 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_mem = 134217728 134217728 134217728 net.ipv4.tcp_rmem = 4096 277750 134217728 net.ipv4.tcp_wmem = 4096 277750 134217728 net.ipv4.ip_local_port_range=1025 65535

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
但请注意:这些优化系统性能参数对我们整个测试结果没有明显的影响。我们在压力端(负载生成端)使用和不使用这些系统优化参数并不会对结果带来任何差异。添加这些内核配置参数主要是为了增加TCP内存缓冲区并允许系统建立更多的并发链接。但是我们在进行基准测试的过程之中最多只有1000个并发链接,并且也没有大量的断开与重连链接。因此进行压力端(负载生成端)的系统优化对我们做基准测试并没有多大帮助。有一些系统默认配置的有关网络的内核参数我们仍保持其默认值,例如TCP窗口缩放。
被测工具版本
以下是我们进行基准测试的每个开源负载工具确切版本号:
- Siege 3.0.5
- Artillery 1.5.0-15
- Gatling 2.2.2
- Jmeter 3.0
- Tsung 1.6.0
- Grinder 3.11
- Apachebench 2.3
- Locust 0.7.5
- Wrk 4.0.2 (epoll)
- Boom(Hey) snapshot 2016-09-16

容器化对性能影响
我们注意到,在Docker容器内运行基准测试和在物理机上使用相同的负载工具进行基准测试的性能相比,每秒请求速率降低了大约40%。所有的负载工具都会受到Docker的性能影响,因此我们没有尝试在Docker中对基准测试进行优化。在同样的基准测试中使用同样的指标进行比对,可以发现在Docker内和物理机内运行测试所带来的性能损耗。例如:wrk工具在同样的运行参数下,物理环境中可以达到105,000-110,000左右的RPS,而在Docker容器内使用同样的参数大概只能产生约60,000RPS。Apachbench同样从物理环境的60,000RPS到了Docker环境中下降到了35,000RPS。
接下来需要考虑的是,Docker环境是否会影响基准测试的响应时间指标。看起来Docker没有明显的增加最小响应时间,但可能会响应时间的正态分布。
如何运行基准测试
-
首先使用个别工具来进行探索性实验
我们首先使用工具所能提供任何可以控制并发的参数来手动的运行负载测试工具。每个工具控制并发量的参数不尽一致,其中包括并发/Virtual User,线程等。通过手动测试我们想要实现两个目标。
第一:我们希望看到是否可以将服务端完全饱和,并以这种方式找到服务端所能承载的最大容量(即目标服务器可以响应的每秒请求数(RPS))。
第二:通过手动的运行这些负载测试工具,我们还想了解这些负载测试工具大致哪个是最好的,哪个是最差的。负载测试工具对多核的利用程度怎样。以及每个负载测试工具大概能够到一个什么量级的RPS。 -
对比负载测试工具
在这里我们尝试使用尽可能相似的参数运行所有需要测试的负载测试工具。但很遗憾的是,对于所有的负载测试工具其运行参数不可能是完全相同的。对于负载测试工具而言,不同的工作模式可以配置不同的参数。为了方便统一对比,我们决定控不同测试工具在压力端并发量使之分级,控制请求在服务端的响应时间使之分级
- Zero-latency, very low VU test: 20 VU @ ~0.1ms network RTT
- Low-latency, very low VU test: 20 VU @ ~10ms network RTT
- Medium-latency, low-VU test: 50 VU @ ~50ms network RTT
- Medium-latency, low/medium-VU test: 100 VU @ ~50ms network RTT
- Medium-latency, medium-VU test: 200 VU @ ~50ms network RTT
- Medium-latency, medium/high-VU test: 500 VU @ ~50ms network RTT
- Medium-latency, high-VU test: 1000 VU @ ~50ms network RTT
请注意,如果要模拟最终用户的流量,一开始定义的两个测试参数可能不太能够实现。最终场景下服务端很难只用20个并发/VU来实现10ms的响应时延,同样20个并发/VU也很难实现0.1ms响应时延的高流量场景。但是这些参数对于微服务而言是可以作为负载测试指标的。
探索性测试
首先我们要做的是手动来跑测试工具。按照我们刚才所说的模型,在保证尽可能低的网络延迟(~0.1ms)以不同数量级的并发观察工具所能达到最大的RPS。
我们一开始在服务端的服务器上加载了一个大约2KB大小的图像文件,使用GET请求来访问服务器上的图像文件。我们可以看到使用Wrk和Apachebench所能够达到的最大RPS大概在50,000RPS左右。但是在使用测试工具压测的过程中压力端系统CPU没有被完全使用并且负载不高,同样的服务端系统的CPU负载也没过高。我们意识到50,000 * 2KB几乎是千兆网卡1Gbps所能达到的物理网络带宽极限。由于我们测试目的是对各个测试工具在不同级别时延下所能达到的最大RPS感兴趣。我们将服务端的图像文件更换为了一个100字节左右的CSS文件。这样1Gbps的带宽应该能够传输每秒钟100万次的请求。更改之后再使用Wrk进行压测,发现wrk现在可以输出100,000RPS的结果。
在对Wrk和Apachebench不同并发级别的进行探索性测试之后,我们发现使用Apachebench开启20个并发(-c 20)可以达到将近60-70,000RPS。而Wrk设置为12个线程(-t 12)和96个链接(-c 96)可以得到将近105-110,000RPS。Apachebench在执行压测的过程中压力端系统CPU负载在100%(这说明了Apachebench没有利用压力机多核的优势,只使用了一个内核),而Wrk使用了压力端的两个CPU(CPU利用率达到了200%,说明两个CPU接近饱和)
我们假设Wrk所测试的110,000RPS是服务端所能承受的最大RPS速率。这样有助于你对标其他测试工具。假如其他测试工具只能测出20,000RPS。这样你可以确信,是测试工具在压力端生成压力不够而导致的。无关于服务端的性能瓶颈和网络的性能瓶颈。需要注意的以上的测试数据是在物理机运行Wrk和Apachebench所测得的结果。正如之前提到的,如果你在Docker容器内运行负载测试工具,那样会导致负载测试工具的性能损耗。这样在Docker中运行基准测试的绝对值会低于在物理环境上运行基准测试的结果。
不同工具参数调整测试
测试工具对比中最重要是要模拟同等数量级的并发,在同等并发量下查看RPS数值。有几个因素会并发量和我们最后对比指标RPS。
首先是网络时延,由于有请求时延的存在,我们无法在单个TCP链接中获得无限大的RPS值(至少我确定HTTP/1.1协议下是无法做到的)。如果压力端与服务端的网络延迟为10ms并且你只使用单个TCP链接来传输请求(HTTP/1.1),那么能看到的最大RPS为1/0.01=100RPS。这个RPS无关乎你的网络带宽和系统的CPU负载。
在基准测试中,我们首先控制压测工具以20的并发连接数,发送请求。控制网络要是在0.1ms到10ms之间。来大致了解各种压测工具所能产生的最大RPS。然后我们进行高并发高时延下的测试,将并发级别提升到50-1000,网络时延控制在50ms。这次我们测试各个工具并发性能的好坏。
如果我们关注RPS的性能我们就能知道并发对其的重要性。假设我们只用单个TCP链接(并发连接数为:1),网络时延为10ms,那么我们能够传输的最大RPS只能为100。然而当并发级别提升到20(有20个并发TCP链接),意味着我们测试所能得到的RPS高于单个TCP链接时的20倍(20*100=2000RPS)。在许多情况下这也意味着测试工具能够更为充分的使用压力端CPU资源往往能够产生更多的流量。
在我们进行基准测试的实验中,实验室压力端到服务端的实际网络延迟大约为0.1ms(即100us,微秒)。这意味着我们每个TCP链接的理论最大RPS速率大约为1/0.0001=10,000RPS。如果我们在这种情况下使用20个并发链接,我们总共可以支持200,000RPS。在我们前连个基准测试中,我们使用了0.1ms的网络延迟和10ms的人工延迟。在这个范围内的延迟,我们称之为“零延迟”。使用低并发低延迟的环境测试,其主要目的是看在不同压测工具中可以获得多大的RPS。
在这种“低延迟,低并发”环境下物理硬件往往不会成为其性能瓶颈。主要是为了观察测试工具在正常条件下是否会提供稳定的测试结果,每次测试RPS结果不会产生较大误差。另外一个目的是比较测试工具响应时延。如果网络延迟为10ms而工具A报告的测试结果中响应时延只是稍微大于10ms而另一个工具B报告的响应时间为50ms。我们就知道工具B内部存在低效代码导致请求时延增加。
另一方面,测试“低延迟,低并发”的场景我们可以获得当前并发下最大的RPS值。这足以发挥压测工具和服务端的性能。当我们增大压测工具压力时,RPS会有什么变化。(译者注:这里原文主要想表达,低延时下增大并发会增大RPS值,随着并发的增大是否会达到压测工具的瓶颈)
并发连接数配置
这里主要介绍每个工具配置什么参数会增大并发连接数。在不同的工具中配置参数有不同的称呼。有些工具参数直接为“并发连接数”,有些工具则使用VU(虚拟用户)而又会有另外的工具使用线程来描述。
- Apachebench
支持“-t concurrency”来控制并发,即“一次执行多个请求”。 - Boom/Hey
支持“-c concurrent”来控制并发,即“测试开始时建立多少并发链接” - Wrk
支持“-t threads”来设置测试是要使用的线程数以及“-c connections”=“来设置测试时要保持打开的连接”。 我们将两个选项设置为相同的值,以使wrk每个线程负责一个并发链接。 - Artillery
支持“-r rate”=“来设置每秒的请求数”。 我们在JSON配置文件中设置该参数它而不是在命令行中设置该参数。 我们在JSON配置文件中配置一个循环,每个VU以固定速率访问URL。因此我们设置到达阶段为1秒,并将到达速率设置为我们想要速率,这样控制住了并发。VU将在1秒内启动,然后建立链接发送请求。 - Vegeta
vegeta要想保持固定的并发连接数很难。我们最初认为可以使用“- connections”参数来控制并发。但是随着测试开始vegeta更具实际的网络延时自动调整了并发链接数,并产生了很高的RPS速率。事实证明,vegeta的并发链接参数只是一个起始值。vegeta会更具设定请求速率来适时的改变并发连接数。最终的结果就是我们根本没有办法控制vegeta的并发连接数。这意味要对vegeta进行基准测试需要做更多的准备工作。因此我们在测试工具基准测试中跳过了这个工具。对于那些对vegeta感兴趣的人,我们探索性测试表明vegeta在性能方面表现的中规中矩。它似乎比Gatling略高,但性能略低于Grinder,Tsung和Jmeter。(译者注:这可能是测试RPS极限值最好的工具,没有之一。至少在我用到的工具中还没有见过比这好使的。) - Siege
支持“-c concurrent”表明当前用户数。 - Tsung
与Artillery类似,Tsung允许在XML文件中定义一定时长的“到达阶段”。在此期间,一定数量的模拟用户“到达”。 就像Artillery一样,我们定义了一个长度为1秒的阶段,我们所有的VU都会建立链接。 在建立起并发之后,用户以一定的访问速率访问目标URL,直到测试完成为止。 - Jmeter
与Tsung相同:XML配置定义了1秒的到达阶段,在此阶段我们所有VU都建立。然后VU经历指定次数的循环,每次迭代都访问目标URL一次,直到测试完成。 - Gatling
Scala配置指定Gatling应该生成多少用户(atOnceUsers(X))并且每个用户在测试的持续时间内执行循环访问一次URL的请求。 - Locust
支持“-c NUM_CLIENTS”指定并发客户端数。 还有一个“-r HATCH_RATE”指定客户端每秒的访问速率。 我们假设-c选项设置了当前出于链接的并发链接数。但是实际测试中并不是100%清楚这个-c是否真的有用。 - Grinder
Grinder有一个grinder.properties文件,您可以在其中指定“grinder.processes”和“grinder.threads”。 我们设置grinder.processes = 1。然后指定grinder.threads =我们想要的的并发连接数
需要注意的一点是,有些测试工具允许你将设置并发连接数与所使用的线程数来分开控制。这样带来的一个好处就是你可以分配CPU的线程和线程所对应的的链接数,达到最佳的配比。
大多数的工具只能对建立的并发连接数做控制(而Vegeta则根本没有并发连接数的对应控制)。这可能会导致这类压测工具会使用太多操作系统线程从而导致大量的上下文切换降低了性能。或者只使用了较少的并发链接,抑制了RPS负载的生成从而限制了RPS负载。
设置测试时间:300秒
大多数压测工具可以允许你设置测试时间,但是不是所有的工具都能提供这个选项。这些工具一般会设置一个请求总数,当访问量达到这个请求总数时则停止测试。这要求我们通过请求总数和请求速率来控制测试的时间。最重要的是我们要尽可能将测试时间控制,如果该测试工具允许我们配置测试时间,我们就将测试时间设置为300秒。如果不能配置测试时间,我们则配置测试工具访问的请求总量,尽可能将测试时间控制在300秒左右。
设置请求数量
在基准测试中我们同样想控制所有测试工具在测试时间内的请求总数。当然这并不是所有的测试工具都能允许设置请求总数,所以并不要求所有的测试工具执行完全相同的请求数量。如果一个测试工具允许我们配置压测执行的请求总数,我们将该数字设置为至少500,000。
(译者注:既想控制测试时间又想控制请求总数,这意味着RPS的速率被控制了。如果这个测试工具还能设置RPS岂不是要上天了?很显然这不太可能。)
关于测试时间的注意事项
很多时候在进行性能测试时,300秒的测试时间可能不足以获得稳定的性能测试结果。但是如果你准备的实验环境变量因素可控(在实验室环境下,除开测试引入的变量之外没有其他不可控变量的引入),你仍可以在运行较短的时间内获得稳定的测试结果。我们对压测工具重复多次的进行300秒的基准测试,每次测试结果只能看到很微小的变化。因此我们相信在实验室中所获得的测试结果是真实有效的。
我们非常欢迎您搭建自己的实验环境设置与我们相同的测试条件进行测试。并见结果我们所获得的的结果进行比较。我们将我们所做的测试和Docker镜像上传到Github上,你可以直接访问Github来进行测试环境的快速搭建。
开源负载测试工具 - 基准测试结果
请注意测试结果的精度会稍有不同。因为一些负载测试工具的结果报告会比另外一些负载测试工具的结果报告要更为精确。我们使用了工具本身的结果报告来进行统计。未来更好统计结果的方式是使用网络流量监控来统计RPS和请求的响应时延。
Zero-latency, very low VU test结果报告
0.1ms的网络延时意味着这个测试过程中RPS的速率很快。每个压测工具在300秒左右的时间生成了500,000-1,000,000的请求。不同的压测工作生产的压力有所不同。几乎所有的压测工具会报告响应时延的中位数值(siege除外,因为它报告的响应时延不精确,所以没有办法准确告诉我们响应时延)。有几种工具不报告最低响应时延,Apachebench不报告最大响应时延。大部分工具横向对比在75%,90%和95%百分位的响应时延都有所不同。
我们可以从大部分工具获得平均响应时延,第50%百分位的响应时延,第99%百分位的响应时延和RPS结果。
详细测试执行参数与结果报告
-
网络时延:~0.1ms
-
测试时间:300s
-
并发链接数:20
-
最高理论限速RPS值:200,000RPS
-
在Docker容器内运行其RPS有40%性能衰减

正如我们所看到的,wrk在生成负载上非常出色。除开wrk之外,还可以看到Apachebench,Boom,Jmeter都有着不错的表现。在性能测试第三梯队排着的是Tsung,Grinder,Sige和Gatling。他们的性能表现只能用“OK”来形容。我们改变一下延时量,让我们看看在Low-latency, very low VU test的测试场景中网络延迟的测试RPS的速率是什么表现。
Low-latency, very low VU test结果报告
这里我们将时延增加到了10ms,这意味着请求速率比上一个测试中的理想请求速率慢了大约100倍。
Low-latency, very low VU test详细配置及结果
- 网络时延:~10ms
- 测试时间:~300s
- 并发连接数:20
- 最大理论请求速率:2000RPS
- 在Docker容器中进行基准测试其所有被测工具的RPS均有40%的下降

这里我们通过模拟网络延迟和限制并发链接的手段,来限制测试工具所能发挥的极限性能。可以看到大部分的测试工具RPS表现非常相似。wrk和Apachebench工具再次拿到了非常优异的结果。但仅管如此wrk和Apachebench与Jmeter,Boom,Gatling,Tsung,Grinder工具的性能表现差异也是非常之小。
在给网络加载了一定时延情况下出现了一格有趣的变化,Siege的性能也有了较大的衰减。Siege的RPS性能被限制在了1000左右。

在之前环境设置中提到过,我们在此次测试中添加了10ms的模拟网络时延。确切地说,总网络延时大约为10.1ms左右。从时延测试报告中可以看到wrk在事物的响应时间上只增加了0,2ms左右。(可能实际上wrk测试工具内部增加的时延更短,因为我们没有确切的去测试HTTP服务器响应一个请求的时间,但是HTTP处理响应请求的时间可能不会比内核响应ICMP的请求更快。)
我们可以看到大多数测试工具内部增加的响应时间很短。这说明这些测试工具的代码运行没有造成过多的时延,所以在极限的RPS测试中表现会很好。但是Artiller和Locust工具在此测试场景下为每个请求增加了很多的响应时延。Siege在相应时间上增加了10ms(大约增加了一倍),这就是我们在RPS的测试图表中看到Siege只能产生略低于1000RPS的原因。但是Siege并没有发挥它最大的流量生产能力,Siege似乎发生了一些奇怪的事情(在后面会有详细的介绍)。
Medium-latency报告结果
在Medium-latency测试场景中,我们模拟50ms的网络时为每个TCP链接或者说每个VU创建更为更为逼真RPS速率。Medium-latency测试不是为了查看各个测试工具模拟的并发/VU的能力。
在Medium测试场景中对接收端系统有了其他的性能需求。因为接收端必须要处理更多的TCP并发链接,这样会导致更高的内存消耗。我们在Medium的测试中设置了四组并发(VU)变量,分别是:100VU,200VU,500VU,1000VU。
在Medium测试场景中,我们再次将测试时间设定为300S。每个工具当设置100并发(VU)时产生的请求大约是150,000个。模拟1000并发(VU)时产生的请求总数大概是5,000,000。我们在这100并发(VU)到1000并发(VU)的区间(请求总数在150,000到5,000,000内进行基准测试)。通常来说更多的并发(VU)能带来更好的RPS结果,知道其他的限制因素被引入。例如VU线程频繁的上下文切换。在不考虑系统因素只看跑在系统上不同的测试工具来看,这通常意味着这个测试工具的瓶颈。
Medium-latency详细配置及结果
- 网络时延:~50ms
- 测试时间:300s
- 并发连接数:100/200/500/1000VU
- 理论最大请求速率:2,000 / 4,000 / 10,000 / 20,000 RPS
- 在Docker容器中进行基准测试其所有被测工具的RPS均有40%的下降

测试结果中我们可以看到,当保持并发在500(VU)或者更低,大部分的工具性能表现非常相似。然而在1,000并发(VU)时,wrk和Apachebench的性能再次脱颖而出并且表现的非常相似。然后我们看到Gatling,Boom,Tsung,Jmeter,Grinder的性能稳步下降。
Siege在500并发(VU)时已经达到其性能瓶颈。在1000并发(VU)时的性能会比其在500时的要差。随着并发(VU)从500提升到1000,Siege会偶尔出现崩溃的情况。这使得再对Siege进行基准测试非常困难。我们尝试手动的将并发(VU)级别调整到2,000,但是最终还是放弃了,因为Siege会在该并发(VU)级别100%崩溃。
Artillery和Locust的表现并没有惊艳的表现。
除了RPS速率指标之外,我们还对各种测试工具在测量HTTP响应时延上的差异表现感兴趣。我们推测不同工具的精度可能会有很大的差异:测试工具会在生成的测试报告中报告时延有误,这具体取决于测试工具的I/O处理方式(事件驱动,轮询等),所使用的高精度时间模块,执行的计算类型。这些方面的原因导致的误差可能很大也可能很小。除开测试工具因素之外,压力机的负载程度也可能导致时延的变化。例如当CPU为100%负载时会比CPU只有50%负载时提供更差的响应时延测量。每个测试工具的测量时延误差因素是确定的,每个因素如何影响工具时延也是确定的。
下面的图表表示了不同工具在四个不同并发(VU)级别上的平均HTTP响应时延。请注意我们这里所说的RTT指的是调用HTTP响应时间“RTT”(Round Trip Time),不是网络的RTT,请不要混淆。当我们写"RTT"时,值得是HTTP响应时间:

正如我们所看到的,表现最差的工具的时延结果完全扭曲了图表规模。因此很难看出Siege,Artillery和Locust之外测试工具的时延响应区别。
Locust测试工具的请求响应时间很长。我们需要知道Locust的响应时间表现是否一直如此,还是说在不同的压力下响应时间会有不同的表现。我们在保持50ms的测试环境时延不变的情况下,开启5个并发(VU)进行了几次测试。我们确保产生了足够的流量,Locust测试会报告怎样的响应时间。
结果是70-80的RPS,Locust报告平均响应时间是54毫秒。54ms的时延看起来不错但是RPS值不太行。这意味着在5并发(VU)非常低的负载上,Locust平均响应时间只因为程序本身增加了3-4ms的额外时延。然而在100并发(VU)时,平均响应时延突然飙升到了180ms。这意味着100并发,Locust程序内部会额外增加了130ms的时延。
测试结论是:Locust的响应时延测量应该用小并发负载来进行测试。但大多数情况下,Locust给出的响应时延与真实系统反应的响应的时延可能完全没有关系。
我们将Locust工具的响应时延从这整个测试工具响应时延对比表中剔除,结果如下:

现在我们可以看到其他测试工具的响应时延差异,但是仍然不够明显。Siege和Artillery仍然在高并发(VU)上的时延表现不佳。所以整个图响应时延的数量级因为Siege和Artillery的存在导致仍然不在同一个数量级。
像Locust一样,Artillery在增加大负载并发下,任然会增加测量时延的误差。我们使用Artillery在5并发(VU)下进行负载测试,Artillery报告平均RTT在51ms左右。将负载增加到100并发(VU),Artillery的请求RTT上升到了75ms(相比于5并发(VU)下增加了25ms的时延),而在500并发(VU)下,Artillery的响应时延到了200ms(增加了150ms)。
另一方面,Siege表现了一种奇怪的现象。我们可能会在后续的测试中进行调查。当在50ms时延的网络环境中,模拟了5并发(VU)的情况,Siege报告平均响应时延为100ms。在100并发(VU)情况下,Siege报告平均响应时延仍然为100ms。200并发(VU),500并发(VU)的情况下平均响应时延亦是如此。知道我们将负载量提升到了1,000并发(VU),HTTP请求的平均响应时延才开始上升到了300ms。但是为什么Siege在除开1000并发(VU)之外的负载量上报告平均响应时延都是100ms呢?100ms看起来像是一个可疑的偶数,也是我们模拟网络时延的两倍。当我们尝试更改测试环境网络时延时,我们发现Siege报告的平均响应时延始终是网络时延的2倍。
这实在是太奇怪了。如果我们只测试Siege而没有测试其他工具。我们可能首先要怀疑的是模拟的网络延迟有问题。我们在双向上都添加了50ms的时延,总共是100ms。但是显然这不是我们模拟网络延迟的问题,因为其他高性能工具报告的请求平均时延均接近50ms。但是Siege报告的最低响应时延还小于50ms。如果请求在网络往返时间高于100ms,那么Siege的报告结果没有一个是准的。
我们可能会对Siege报告的时延问题进行研究,但也只想找到到底是什么原因引发了这个问题。现在暂且认为Siege的测量结果不可靠。(我们没有在服务接收端的URL上设置重定向)。
让我们从测试结果中删除Siege和Artillery,来看看别的测试工具具体表现:
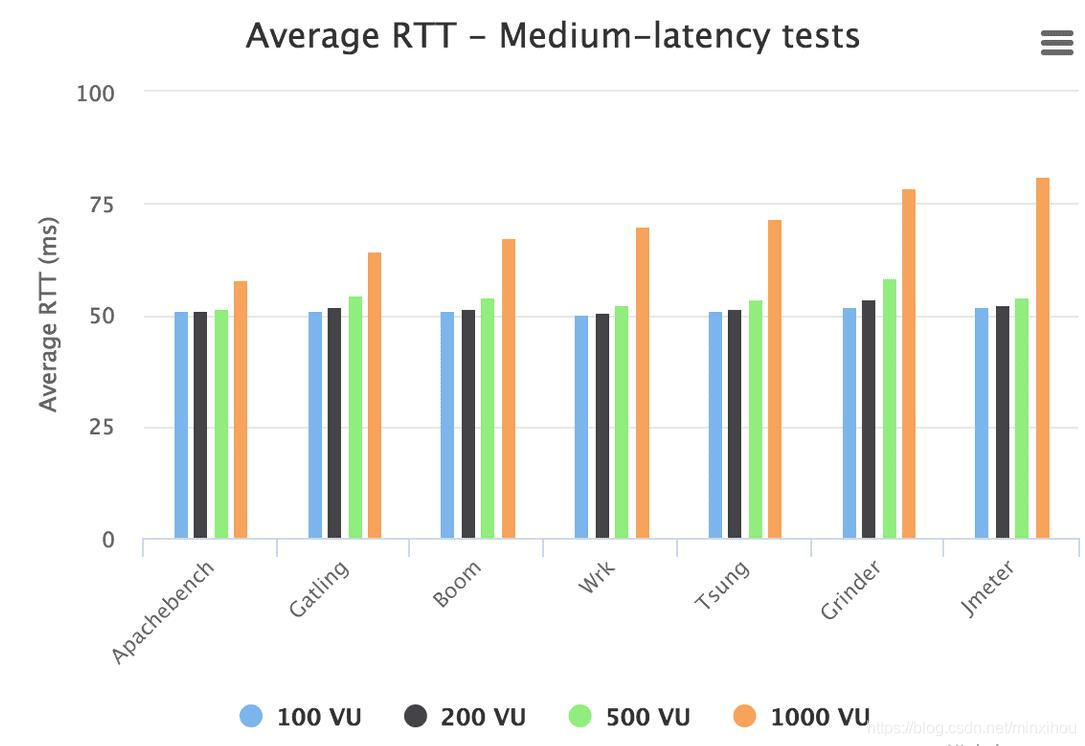
我们可以看到,并发量在100-500VU级别,其余的剩余工具的平均响应时延没有太大的差别。但是我们将并发(VU)提升到1000,图中不同测试工具的平均响应时延差异就看出来了。(请记住,50ms是最好的响应时延,因为这是设置给网络的延迟。这意味着如果一个测试工具反馈50ms的时延,则说明该测试工具没有对请求增加额外的时延)。
该图可以看到,Jmeter和Grinder在1000并发(VU)时,平均响应时延对比其他工具有上升。在1000并发(VU)下,Apachebench获得了很低的平均响应时延。wrk在100-500的并发(VU)上表现也很出色,但是在1000并发(VU)级别上,它可能反应的也是当前图表中的一个平均水平了。我们在测试wrk上,使用了1,000个并发线程,这可能会导致程序有大量的上下文切换从而降低性能。其他工具可能没有使用这么多线程,而是通过较少的线程分配1,000个TCP并发链接。
Medium-latency测试场景下压力机内存使用情况
最后,我们想看一下各测试工具在压力机的内存使用情况。每个测试工具使用多少内存决定着压力机可以发多少负载。如果CPU耗尽,你的测试结果将会有误差,但是负载测试可以继续进行。如果你的内存耗尽了,整个测试就崩了。
测试工具所消耗的内存不单单是生成负载所需的内存开销,还有测试工具收集测量数据所需要花费的开销。有些测试工具会在测试结束后对收集的测量结果进行计算。这意味着在此时工具会占用大量的额外内存。如果此时内存不足,这可能会导致应用程序崩溃。因为拿不到测试结果会使你的整个测试运行毫无价值。解决这类问题的一种方法是,将结果收集汇总与负载生成器进行分离。使负载生成器专门对被测物加载压力,而收集结果交给另外的程序(组件)来处理。
虽然测量内存在基准测试报告中作为辅助参数给出很有用。但是峰值一般非常短暂,很难精确的收集到峰值内存数据。此外,正如上段我们提到的,如果说在测试结束后因为整理汇总测试结果而产生大量的内存。这种峰值内存对人们来说可接受程度是因人而异的。因此我们出报告选择整个测试中平均内存使用量来衡量。这样方便我们给出每个工具模拟一定数量并发(VU)大概需要多少内存。
我们使用“top”命令以每隔1秒的时间间隔采样内存使用情况。然后计算整个测试过程中内存使用的平均值:

在内存对比的测试中,我们终于找到了Siege和Locust的优点。Siege和Locust的内存使用率非常低。这将允许你在有限的物理设备上模拟更多的并发(VU)。当然高并发会引发Siege崩溃。而Locust在高并发下虽然内存不会成为问题,但是CPU可能会先耗尽。
在这里我们再次看到wrk和Apachebench在内存方面所表现的优势。因为这两个工具不需要占用大量的内存和CPU资源。Jmeter是最大的内存占用压测工具(请注意,这个结果反映的只是测试过程中的平均值,不是峰值内存。我们在Artillery在结束测试运行之前会占据大量的内存,所以它可能是最大的消耗内存大户)。
开源负载测试工具基准测试总结
当你阅读文中的测试结果和原始评论时,你会发现:
- 性能方面wrk和Apachebench独占鳌头。
- Gatling,Jmeter,Grinder,Tsung和Boom都具有良好的性能,准确性和可靠性。
- Artillery,Locust和Siege在性能,准确性和可靠性方面存在各种各样的问题。
- 所有的测试工具在单个机器上模拟数千并发(VU),会显著降低测试精度。
如果你想亲进行尝试来进行基准测试对比,我们非常欢迎,有关环境构造的信息请参考一下链接:
- Github上负载测试工具基准测试的测试工具集成:https://github.com/loadimpact/loadgentesth3
- 涵盖有基准测试工具的Docker镜像运行方法:docker run -it --cap-add=NET_ADMIN loadimpact/loadgentest

