
- 1【Vue框架系列】Vue框架快速入门(基于Vue2)_vue2框架
- 2指向结构体的指针p++与p = p->next的区别_p->next和p++
- 3python s append_详细介绍pandas的DataFrame的append方法使用
- 4MFC 如何实现edit框内只能输入数字包括负号_mfc编辑框 正负数
- 5【详解】Spring Security 之 SecurityContext
- 6bootstrap modal填充数据_Bootstrap使用模态框modal实现表单提交弹出框
- 7html折叠导航菜单,JS实现移动端可折叠导航菜单(现代都市风)
- 8一次高并发下生成js随机数的实践_js new date().gettime()高并发
- 9阿里云ecs环境搭建—— 六、七 tomcat和nginx
- 10借用GitHub将typora图片文件快速上传CSDN
LeetCode-题目详解:排序【高频题:6、中频题:27、低频题:29】_有一队人想要在一个地方碰面,他们希望
赞
踩
一、高频题
1、高频题(共6题)
1.1、56-合并区间 【中等】
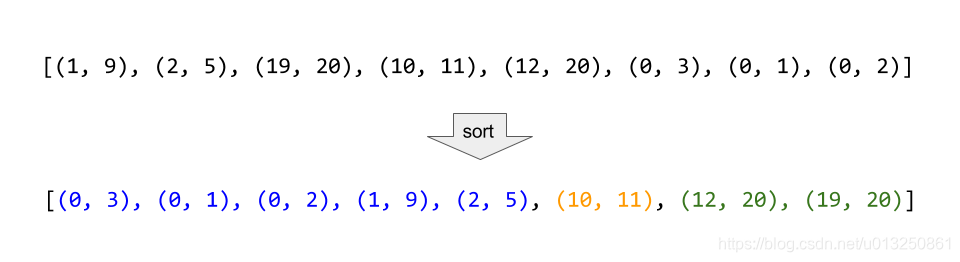
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间。
示例 1:
输入:intervals = [[1,3],[2,6],[8,10],[15,18]]
输出:[[1,6],[8,10],[15,18]]
解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
- 1
- 2
- 3
示例 2:
输入:intervals = [[1,4],[4,5]]
输出:[[1,5]]
解释:区间 [1,4] 和 [4,5] 可被视为重叠区间。
- 1
- 2
- 3
提示:
- 1 < = i n t e r v a l s . l e n g t h < = 1 0 4 1 <= intervals.length <= 10^4 1<=intervals.length<=104
- intervals[i].length == 2
- 0 < = s t a r t i < = e n d i < = 1 0 4 0 <= start_i <= end_i <= 10^4 0<=starti<=endi<=104
class Solution:
def merge(self, intervals: List[List[int]]) -> List[List[int]]:
intervals.sort(key=lambda x: x[0])
merged = []
for interval in intervals:
# 如果列表为空,或者当前区间与上一区间不重合,直接添加
if not merged or merged[-1][1] < interval[0]:
merged.append(interval)
else:
# 否则的话,我们就可以与上一区间进行合并
merged[-1][1] = max(merged[-1][1], interval[1])
return merged
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
1.2、179-最大数 【中等】
给定一组非负整数 nums,重新排列每个数的顺序(每个数不可拆分)使之组成一个最大的整数。
注意:输出结果可能非常大,所以你需要返回一个字符串而不是整数。
示例 1:
输入:nums = [10,2]
输出:"210"
- 1
- 2
示例 2:
输入:nums = [3,30,34,5,9]
输出:"9534330"
- 1
- 2
示例 3:
输入:nums = [1]
输出:"1"
- 1
- 2
示例 4:
输入:nums = [10]
输出:"10"
- 1
- 2
提示:
- 1 <= nums.length <= 100
- 0 < = n u m s [ i ] < = 1 0 9 0 <= nums[i] <= 10^9 0<=nums[i]<=109
方法一:选择排序
class Solution:
def largestNumber(self, nums: List[int]) -> str:
n=len(nums)
nums=list(map(str,nums))
for i in range(n):
for j in range(i+1,n):
if nums[i]+nums[j]<nums[j]+nums[i]:
nums[i],nums[j]=nums[j],nums[i]
return str(int("".join(nums)))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
方法二:快速排序
class Solution: def largestNumber(self, nums: List[int]) -> str: def quick_sort(left , right): if left >= right: return i, j = left, right while i < j: while i < j and strs[j] + strs[left] <= strs[left] + strs[j]: j -= 1 while i < j and strs[i] + strs[left] >= strs[left] + strs[i]: i += 1 strs[i], strs[j] = strs[j], strs[i] strs[i], strs[left] = strs[left], strs[i] quick_sort(left, i - 1) quick_sort(i + 1, right) strs = [str(num) for num in nums] quick_sort(0, len(strs) - 1) res = ''.join(strs) if res[0] == '0': res = '0' return res

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
方法三:内置函数 cmp_to_key
from typing import List from functools import cmp_to_key class Solution: # 先把nums中的所有数字转化为字符串,形成字符串数组 nums_str # 比较两个字符串x,y的拼接结果x+y和y+x哪个更大,从而确定x和y谁排在前面;将nums_str降序排序 # 把整个数组排序的结果拼接成一个字符串,并且返回 def largestNumber(self, nums: List[int]) -> str: print("原始数据:nums = ", nums) nums_str = list(map(str, nums)) print("转为字符串后:nums_str = ", nums_str) compare = lambda x, y: 1 if x + y < y + x else -1 nums_str.sort(key=cmp_to_key(compare)) print("按照自定义规则排序后:nums_str = ", nums_str) res = ''.join(nums_str) if res[0] == '0': res = '0' return res nums = [3, 30, 34, 5, 9] solution = Solution() result = solution.largestNumber(nums=nums) print("result = ", result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
原始数据:nums = [3, 30, 34, 5, 9]
转为字符串后:nums_str = ['3', '30', '34', '5', '9']
按照自定义规则排序后:nums_str = ['9', '5', '34', '3', '30']
result = 9534330
Process finished with exit code 0
- 1
- 2
- 3
- 4
- 5
- 6
1.3、148-排序链表 【中等】
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例 1:

输入:head = [4,2,1,3]
输出:[1,2,3,4]
- 1
- 2
示例 2:

输入:head = [-1,5,3,4,0]
输出:[-1,0,3,4,5]
- 1
- 2
示例 3:
输入:head = []
输出:[]
- 1
- 2
提示:
- 链表中节点的数目在范围 [ 0 , 5 ∗ 1 0 4 ] [0, 5 * 10^4] [0,5∗104] 内
- − 1 0 5 < = N o d e . v a l < = 1 0 5 -10^5 <= Node.val <= 10^5 −105<=Node.val<=105
进阶:你可以在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序吗?
方法一:快速排序(没有随机化,超时)
# Definition for singly-linked list. # class ListNode: # def __init__(self, x): # self.val = x # self.next = None class Solution: def sortList(self, head: ListNode) -> ListNode: if head is None: return head # 分成三个链表,分别是比轴心数小,相等,大的数组成的链表 big = None small = None equal = None cur = head while cur is not None: t = cur cur = cur.next if t.val < head.val: t.next = small small = t elif t.val > head.val: t.next = big big = t else: t.next = equal equal = t # 拆完各自排序即可,equal 无需排序 big = self.sortList(big) small = self.sortList(small) ret = ListNode(None) cur = ret # 将三个链表组合成一起,这一步复杂度是 o(n) # 可以同时返回链表的头指针和尾指针加速链表的合并。 for p in [small, equal, big]: while p is not None: cur.next = p p = p.next cur = cur.next cur.next = None return ret.next
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
方法二:归并排序
class Solution: # 归并排序 def sortList(self, head: ListNode) -> ListNode: if not head or not head.next: return head left_end = self.find_mid(head) mid = left_end.next left_end.next = None left, right = self.sortList(head), self.sortList(mid) return self.merged(left, right) # 快慢指针查找链表中点 def find_mid(self, head): if head is None or head.next is None: return head slow,fast = head, head.next while fast is not None and fast.next is not None: slow=slow.next fast=fast.next.next return slow # 合并有序链表 def merged(self, left, right): res = ListNode() h = res while left and right: if left.val < right.val: h.next, left = left, left.next else: h.next, right = right, right.next h = h.next h.next = left if left else right return res.next
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
方法三:堆排序
# Definition for singly-linked list. # class ListNode: # def __init__(self, val=0, next=None): # self.val = val # self.next = next class Solution: def sortList(self, head: ListNode) -> ListNode: from queue import PriorityQueue ptr = head p_queue = PriorityQueue() while ptr != None: p_queue.put(ptr.val) ptr = ptr.next ptr = head while not p_queue.empty(): ptr.val = p_queue.get() ptr = ptr.next return head
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
1.4、面试题 17.14-最小K个数 【中等】
设计一个算法,找出数组中最小的k个数。以任意顺序返回这k个数均可。
示例:
输入: arr = [1,3,5,7,2,4,6,8], k = 4
输出: [1,2,3,4]
- 1
- 2
提示:
- 0 <= len(arr) <= 100000
- 0 <= k <= min(100000, len(arr))
方法一:快速排序(随机化处理)
class Solution: def partition(self, nums, l, r): pivot = nums[r] i = l - 1 for j in range(l, r): if nums[j] <= pivot: i += 1 nums[i], nums[j] = nums[j], nums[i] nums[i + 1], nums[r] = nums[r], nums[i + 1] return i + 1 def randomized_partition(self, nums, l, r): i = random.randint(l, r) nums[r], nums[i] = nums[i], nums[r] return self.partition(nums, l, r) def randomized_selected(self, arr, l, r, k): pos = self.randomized_partition(arr, l, r) num = pos - l + 1 if k < num: self.randomized_selected(arr, l, pos - 1, k) elif k > num: self.randomized_selected(arr, pos + 1, r, k - num) def smallestK(self, arr: List[int], k: int) -> List[int]: if k == 0: return list() self.randomized_selected(arr, 0, len(arr) - 1, k) return arr[:k]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
方法二:堆
class Solution:
def smallestK(self, arr: List[int], k: int) -> List[int]:
if k == 0:
return list()
hp = [-x for x in arr[:k]]
heapq.heapify(hp)
for i in range(k, len(arr)):
if -hp[0] > arr[i]:
heapq.heappop(hp)
heapq.heappush(hp, -arr[i])
ans = [-x for x in hp]
return ans
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
方法三:直接调用排序函数
class Solution:
def smallestK(self, arr: List[int], k: int) -> List[int]:
arr.sort()
return arr[:k]
- 1
- 2
- 3
- 4
1.5、剑指 Offer 45-把数组排成最小的数 【中等】
输入一个非负整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。
示例 1:
输入: [10,2]
输出: "102"
- 1
- 2
示例 2:
输入: [3,30,34,5,9]
输出: "3033459"
- 1
- 2
提示:0 < nums.length <= 100
说明:
- 输出结果可能非常大,所以你需要返回一个字符串而不是整数
- 拼接起来的数字可能会有前导 0,最后结果不需要去掉前导 0
方法一:快速排序
class Solution: def minNumber(self, nums: List[int]) -> str: def quick_sort(l , r): if l >= r: return i, j = l, r while i < j: while strs[j] + strs[l] >= strs[l] + strs[j] and i < j: j -= 1 while strs[i] + strs[l] <= strs[l] + strs[i] and i < j: i += 1 strs[i], strs[j] = strs[j], strs[i] strs[i], strs[l] = strs[l], strs[i] quick_sort(l, i - 1) quick_sort(i + 1, r) strs = [str(num) for num in nums] quick_sort(0, len(strs) - 1) return ''.join(strs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
方法二:内置函数 cmp_to_key
class Solution:
def minNumber(self, nums: List[int]) -> str:
def sort_rule(x, y):
a, b = x + y, y + x
if a > b: return 1
elif a < b: return -1
else: return 0
strs = [str(num) for num in nums]
strs.sort(key = functools.cmp_to_key(sort_rule))
return ''.join(strs)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1.6、147-对链表进行插入排序 【中等】
对链表进行插入排序。
插入排序的动画演示如上。从第一个元素开始,该链表可以被认为已经部分排序(用黑色表示)。
每次迭代时,从输入数据中移除一个元素(用红色表示),并原地将其插入到已排好序的链表中。
插入排序算法:
- 插入排序是迭代的,每次只移动一个元素,直到所有元素可以形成一个有序的输出列表。
- 每次迭代中,插入排序只从输入数据中移除一个待排序的元素,找到它在序列中适当的位置,并将其插入。
- 重复直到所有输入数据插入完为止。
示例 1:
输入: 4->2->1->3
输出: 1->2->3->4
- 1
- 2
示例 2:
输入: -1->5->3->4->0
输出: -1->0->3->4->5
- 1
- 2
方法一:插入排序
class Solution: def insertionSortList(self, head: ListNode) -> ListNode: if not head: return head dummyHead = ListNode(0) dummyHead.next = head lastSorted = head curr = head.next while curr: if lastSorted.val <= curr.val: lastSorted = lastSorted.next else: prev = dummyHead while prev.next.val <= curr.val: prev = prev.next lastSorted.next = curr.next curr.next = prev.next prev.next = curr curr = lastSorted.next return dummyHead.next
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
2、中频题
2.1、349-两个数组的交集
给定两个数组,编写一个函数来计算它们的交集。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2]
- 1
- 2
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[9,4]
- 1
- 2
说明:
- 输出结果中的每个元素一定是唯一的。
- 我们可以不考虑输出结果的顺序。
2.2、164-最大间距
给定一个无序的数组,找出数组在排序之后,相邻元素之间最大的差值。
如果数组元素个数小于 2,则返回 0。
示例 1:
输入: [3,6,9,1]
输出: 3
解释: 排序后的数组是 [1,3,6,9], 其中相邻元素 (3,6) 和 (6,9) 之间都存在最大差值 3。
- 1
- 2
- 3
示例 2:
输入: [10]
输出: 0
解释: 数组元素个数小于 2,因此返回 0。
- 1
- 2
- 3
说明:
- 你可以假设数组中所有元素都是非负整数,且数值在 32 位有符号整数范围内。
- 请尝试在线性时间复杂度和空间复杂度的条件下解决此问题。
2.3、767-重构字符串
给定一个字符串S,检查是否能重新排布其中的字母,使得两相邻的字符不同。
若可行,输出任意可行的结果。若不可行,返回空字符串。
示例 1:
输入: S = "aab"
输出: "aba"
- 1
- 2
示例 2:
输入: S = "aaab"
输出: ""
- 1
- 2
注意:
S 只包含小写字母并且长度在[1, 500]区间内。
2.4、242-有效的字母异位词
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
示例 1:
输入: s = "anagram", t = "nagaram"
输出: true
- 1
- 2
示例 2:
输入: s = "rat", t = "car"
输出: false
- 1
- 2
说明:你可以假设字符串只包含小写字母。
进阶:如果输入字符串包含 unicode 字符怎么办?你能否调整你的解法来应对这种情况?
2.5、976-三角形的最大周长
给定由一些正数(代表长度)组成的数组 A,返回由其中三个长度组成的、面积不为零的三角形的最大周长。
如果不能形成任何面积不为零的三角形,返回 0。
示例 1:
输入:[2,1,2]
输出:5
- 1
- 2
示例 2:
输入:[1,2,1]
输出:0
- 1
- 2
示例 3:
输入:[3,2,3,4]
输出:10
- 1
- 2
示例 4:
输入:[3,6,2,3]
输出:8
- 1
- 2
提示:
- 3 <= A.length <= 10000
- 1 <= A[i] <= 10^6
2.6、315-计算右侧小于当前元素的个数
给定一个整数数组 nums,按要求返回一个新数组 counts。数组 counts 有该性质: counts[i] 的值是 nums[i] 右侧小于 nums[i] 的元素的数量。
示例:
输入:nums = [5,2,6,1]
输出:[2,1,1,0]
解释:
5 的右侧有 2 个更小的元素 (2 和 1)
2 的右侧仅有 1 个更小的元素 (1)
6 的右侧有 1 个更小的元素 (1)
1 的右侧有 0 个更小的元素
- 1
- 2
- 3
- 4
- 5
- 6
- 7
提示:
- 0 < = n u m s . l e n g t h < = 1 0 5 0 <= nums.length <= 10^5 0<=nums.length<=105
- − 1 0 4 < = n u m s [ i ] < = 1 0 4 -10^4 <= nums[i] <= 10^4 −104<=nums[i]<=104
2.7、493-翻转对
给定一个数组 nums ,如果 i < j 且 nums[i] > 2*nums[j] 我们就将 (i, j) 称作一个重要翻转对。
你需要返回给定数组中的重要翻转对的数量。
示例 1:
输入: [1,3,2,3,1]
输出: 2
- 1
- 2
示例 2:
输入: [2,4,3,5,1]
输出: 3
- 1
- 2
注意:
- 给定数组的长度不会超过50000。
- 输入数组中的所有数字都在32位整数的表示范围内。
2.8、350-两个数组的交集 II
给定两个数组,编写一个函数来计算它们的交集。
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2]
输出:[2,2]
- 1
- 2
示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4]
输出:[4,9]
- 1
- 2
说明:
- 输出结果中每个元素出现的次数,应与元素在两个数组中出现次数的最小值一致。
- 我们可以不考虑输出结果的顺序。
进阶:
- 如果给定的数组已经排好序呢?你将如何优化你的算法?
- 如果 nums1 的大小比 nums2 小很多,哪种方法更优?
- 如果 nums2 的元素存储在磁盘上,内存是有限的,并且你不能一次加载所有的元素到内存中,你该怎么办?
2.9、1353-最多可以参加的会议数目
给你一个数组 events,其中 events[i] = [startDayi, endDayi] ,表示会议 i 开始于 startDayi ,结束于 endDayi 。
你可以在满足 startDayi <= d <= endDayi 中的任意一天 d 参加会议 i 。注意,一天只能参加一个会议。
请你返回你可以参加的 最大 会议数目。
示例 1:

输入:events = [[1,2],[2,3],[3,4]]
输出:3
解释:你可以参加所有的三个会议。
安排会议的一种方案如上图。
第 1 天参加第一个会议。
第 2 天参加第二个会议。
第 3 天参加第三个会议。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
示例 2:
输入:events= [[1,2],[2,3],[3,4],[1,2]]
输出:4
- 1
- 2
示例 3:
输入:events = [[1,4],[4,4],[2,2],[3,4],[1,1]]
输出:4
- 1
- 2
示例 4:
输入:events = [[1,100000]]
输出:1
- 1
- 2
示例 5:
输入:events = [[1,1],[1,2],[1,3],[1,4],[1,5],[1,6],[1,7]]
输出:7
- 1
- 2
提示:
- 1 < = e v e n t s . l e n g t h < = 1 0 5 1 <= events.length <= 10^5 1<=events.length<=105
- events[i].length == 2
- 1 < = e v e n t s [ i ] [ 0 ] < = e v e n t s [ i ] [ 1 ] < = 1 0 5 1 <= events[i][0] <= events[i][1] <= 10^5 1<=events[i][0]<=events[i][1]<=105
2.10、452-用最少数量的箭引爆气球
在二维空间中有许多球形的气球。对于每个气球,提供的输入是水平方向上,气球直径的开始和结束坐标。由于它是水平的,所以纵坐标并不重要,因此只要知道开始和结束的横坐标就足够了。开始坐标总是小于结束坐标。
一支弓箭可以沿着 x 轴从不同点完全垂直地射出。在坐标 x 处射出一支箭,若有一个气球的直径的开始和结束坐标为 xstart,xend, 且满足 xstart ≤ x ≤ xend,则该气球会被引爆。可以射出的弓箭的数量没有限制。 弓箭一旦被射出之后,可以无限地前进。我们想找到使得所有气球全部被引爆,所需的弓箭的最小数量。
给你一个数组 points ,其中 points [i] = [xstart,xend] ,返回引爆所有气球所必须射出的最小弓箭数。
示例 1:
输入:points = [[10,16],[2,8],[1,6],[7,12]]
输出:2
解释:对于该样例,x = 6 可以射爆 [2,8],[1,6] 两个气球,以及 x = 11 射爆另外两个气球
- 1
- 2
- 3
示例 2:
输入:points = [[1,2],[3,4],[5,6],[7,8]]
输出:4
- 1
- 2
示例 3:
输入:points = [[1,2],[2,3],[3,4],[4,5]]
输出:2
- 1
- 2
示例 4:
输入:points = [[1,2]]
输出:1
- 1
- 2
示例 5:
输入:points = [[2,3],[2,3]]
输出:1
- 1
- 2
提示:
- 0 < = p o i n t s . l e n g t h < = 1 0 4 0 <= points.length <= 10^4 0<=points.length<=104
- points[i].length == 2
- − 2 31 < = x s t a r t < x e n d < = 2 31 − 1 -2^{31} <= x_{start} < x_{end} <= 2^{31} - 1 −231<=xstart<xend<=231−1
2.11、1370-上升下降字符串
给你一个字符串 s ,请你根据下面的算法重新构造字符串:
- 从 s 中选出 最小 的字符,将它 接在 结果字符串的后面。
- 从 s 剩余字符中选出 最小 的字符,且该字符比上一个添加的字符大,将它 接在 结果字符串后面。
- 重复步骤 2 ,直到你没法从 s 中选择字符。
- 从 s 中选出 最大 的字符,将它 接在 结果字符串的后面。
- 从 s 剩余字符中选出 最大 的字符,且该字符比上一个添加的字符小,将它 接在 结果字符串后面。
- 重复步骤 5 ,直到你没法从 s 中选择字符。
- 重复步骤 1 到 6 ,直到 s 中所有字符都已经被选过。
在任何一步中,如果最小或者最大字符不止一个 ,你可以选择其中任意一个,并将其添加到结果字符串。
请你返回将 s 中字符重新排序后的 结果字符串 。
示例 1:
输入:s = "aaaabbbbcccc"
输出:"abccbaabccba"
解释:第一轮的步骤 1,2,3 后,结果字符串为 result = "abc"
第一轮的步骤 4,5,6 后,结果字符串为 result = "abccba"
第一轮结束,现在 s = "aabbcc" ,我们再次回到步骤 1
第二轮的步骤 1,2,3 后,结果字符串为 result = "abccbaabc"
第二轮的步骤 4,5,6 后,结果字符串为 result = "abccbaabccba"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
示例 2:
输入:s = "rat"
输出:"art"
解释:单词 "rat" 在上述算法重排序以后变成 "art"
- 1
- 2
- 3
示例 3:
输入:s = "leetcode"
输出:"cdelotee"
- 1
- 2
示例 4:
输入:s = "ggggggg"
输出:"ggggggg"
- 1
- 2
示例 5:
输入:s = "spo"
输出:"ops"
- 1
- 2
提示:
- 1 <= s.length <= 500
- s 只包含小写英文字母。
2.12、75-颜色分类
给定一个包含红色、白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
此题中,我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
示例 1:
输入:nums = [2,0,2,1,1,0]
输出:[0,0,1,1,2,2]
- 1
- 2
示例 2:
输入:nums = [2,0,1]
输出:[0,1,2]
- 1
- 2
示例 3:
输入:nums = [0]
输出:[0]
- 1
- 2
示例 4:
输入:nums = [1]
输出:[1]
- 1
- 2
提示:
- n == nums.length
- 1 <= n <= 300
- nums[i] 为 0、1 或 2
进阶:
你可以不使用代码库中的排序函数来解决这道题吗?
你能想出一个仅使用常数空间的一趟扫描算法吗?
2.13、253-会议室 II
给你一个会议时间安排的数组 intervals ,每个会议时间都会包括开始和结束的时间 intervals[i] = [starti, endi] ,为避免会议冲突,同时要考虑充分利用会议室资源,请你计算至少需要多少间会议室,才能满足这些会议安排。
示例 1:
输入:intervals = [[0,30],[5,10],[15,20]]
输出:2
- 1
- 2
示例 2:
输入:intervals = [[7,10],[2,4]]
输出:1
- 1
- 2
提示:
- 1 < = i n t e r v a l s . l e n g t h < = 1 0 4 1 <= intervals.length <= 10^4 1<=intervals.length<=104
- 0 < = s t a r t i < e n d i < = 1 0 6 0 <= starti < endi <= 10^6 0<=starti<endi<=106
2.14、1122-数组的相对排序
给你两个数组,arr1 和 arr2,
- arr2 中的元素各不相同
- arr2 中的每个元素都出现在 arr1 中
对 arr1 中的元素进行排序,使 arr1 中项的相对顺序和 arr2 中的相对顺序相同。未在 arr2 中出现过的元素需要按照升序放在 arr1 的末尾。
示例:
输入:arr1 = [2,3,1,3,2,4,6,7,9,2,19], arr2 = [2,1,4,3,9,6]
输出:[2,2,2,1,4,3,3,9,6,7,19]
- 1
- 2
提示:
- 1 <= arr1.length, arr2.length <= 1000
- 0 <= arr1[i], arr2[i] <= 1000
- arr2 中的元素 arr2[i] 各不相同
- arr2 中的每个元素 arr2[i] 都出现在 arr1 中
2.15、220-存在重复元素 III
给你一个整数数组 nums 和两个整数 k 和 t 。请你判断是否存在 两个不同下标 i 和 j,使得 abs(nums[i] - nums[j]) <= t ,同时又满足 abs(i - j) <= k 。
如果存在则返回 true,不存在返回 false。
示例 1:
输入:nums = [1,2,3,1], k = 3, t = 0
输出:true
- 1
- 2
示例 2:
输入:nums = [1,0,1,1], k = 1, t = 2
输出:true
- 1
- 2
示例 3:
输入:nums = [1,5,9,1,5,9], k = 2, t = 3
输出:false
- 1
- 2
提示:
- 0 < = n u m s . l e n g t h < = 2 ∗ 1 0 4 0 <= nums.length <= 2 * 10^4 0<=nums.length<=2∗104
- − 231 < = n u m s [ i ] < = 2 31 − 1 -231 <= nums[i] <= 2^{31} - 1 −231<=nums[i]<=231−1
- 0 < = k < = 1 0 4 0 <= k <= 10^4 0<=k<=104
- 0 < = t < = 2 31 − 1 0 <= t <= 2^{31} - 1 0<=t<=231−1
2.16、57-插入区间
给你一个 无重叠的 ,按照区间起始端点排序的区间列表。
在列表中插入一个新的区间,你需要确保列表中的区间仍然有序且不重叠(如果有必要的话,可以合并区间)。
示例 1:
输入:intervals = [[1,3],[6,9]], newInterval = [2,5]
输出:[[1,5],[6,9]]
- 1
- 2
示例 2:
输入:intervals = [[1,2],[3,5],[6,7],[8,10],[12,16]], newInterval = [4,8]
输出:[[1,2],[3,10],[12,16]]
解释:这是因为新的区间 [4,8] 与 [3,5],[6,7],[8,10] 重叠。
- 1
- 2
- 3
示例 3:
输入:intervals = [], newInterval = [5,7]
输出:[[5,7]]
- 1
- 2
示例 4:
输入:intervals = [[1,5]], newInterval = [2,3]
输出:[[1,5]]
- 1
- 2
示例 5:
输入:intervals = [[1,5]], newInterval = [2,7]
输出:[[1,7]]
- 1
- 2
提示:
- 0 < = i n t e r v a l s . l e n g t h < = 1 0 4 0 <= intervals.length <= 10^4 0<=intervals.length<=104
- intervals[i].length == 2
- 0 < = i n t e r v a l s [ i ] [ 0 ] < = i n t e r v a l s [ i ] [ 1 ] < = 1 0 5 0 <= intervals[i][0] <= intervals[i][1] <= 10^5 0<=intervals[i][0]<=intervals[i][1]<=105
- intervals 根据 intervals[i][0] 按 升序 排列
- newInterval.length == 2
- 0 < = n e w I n t e r v a l [ 0 ] < = n e w I n t e r v a l [ 1 ] < = 1 0 5 0 <= newInterval[0] <= newInterval[1] <= 10^5 0<=newInterval[0]<=newInterval[1]<=105
2.17、327-区间和的个数
给你一个整数数组 nums 以及两个整数 lower 和 upper 。求数组中,值位于范围 [lower, upper] (包含 lower 和 upper)之内的 区间和的个数 。
区间和 S(i, j) 表示在 nums 中,位置从 i 到 j 的元素之和,包含 i 和 j (i ≤ j)。
示例 1:
输入:nums = [-2,5,-1], lower = -2, upper = 2
输出:3
解释:存在三个区间:[0,0]、[2,2] 和 [0,2] ,对应的区间和分别是:-2 、-1 、2 。
示例 2:
输入:nums = [0], lower = 0, upper = 0
输出:1
- 1
- 2
提示:
- 1 < = n u m s . l e n g t h < = 1 0 4 1 <= nums.length <= 10^4 1<=nums.length<=104
- − 2 31 < = n u m s [ i ] < = 2 31 − 1 -2^{31} <= nums[i] <= 2^{31} - 1 −231<=nums[i]<=231−1
- − 3 ∗ 1 0 4 < = l o w e r < = u p p e r < = 3 ∗ 1 0 4 -3 * 10^4 <= lower <= upper <= 3 * 10^4 −3∗104<=lower<=upper<=3∗104
提示:最直观的算法复杂度是 O(n2) ,请在此基础上优化你的算法。
2.18、面试题 16.16-部分排序
给定一个整数数组,编写一个函数,找出索引m和n,只要将索引区间[m,n]的元素排好序,整个数组就是有序的。注意:n-m尽量最小,也就是说,找出符合条件的最短序列。函数返回值为[m,n],若不存在这样的m和n(例如整个数组是有序的),请返回[-1,-1]。
示例:
输入: [1,2,4,7,10,11,7,12,6,7,16,18,19]
输出: [3,9]
- 1
- 2
提示:0 <= len(array) <= 1000000
2.19、973-最接近原点的 K 个点
我们有一个由平面上的点组成的列表 points。需要从中找出 K 个距离原点 (0, 0) 最近的点。
(这里,平面上两点之间的距离是欧几里德距离。)
你可以按任何顺序返回答案。除了点坐标的顺序之外,答案确保是唯一的。
示例 1:
输入:points = [[1,3],[-2,2]], K = 1
输出:[[-2,2]]
解释:
(1, 3) 和原点之间的距离为 sqrt(10),
(-2, 2) 和原点之间的距离为 sqrt(8),
由于 sqrt(8) < sqrt(10),(-2, 2) 离原点更近。
我们只需要距离原点最近的 K = 1 个点,所以答案就是 [[-2,2]]。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
示例 2:
输入:points = [[3,3],[5,-1],[-2,4]], K = 2
输出:[[3,3],[-2,4]]
(答案 [[-2,4],[3,3]] 也会被接受。)
- 1
- 2
- 3
提示:
- 1 <= K <= points.length <= 10000
- -10000 < points[i][0] < 10000
- -10000 < points[i][1] < 10000
2.20、1235-规划兼职工作
你打算利用空闲时间来做兼职工作赚些零花钱。
这里有 n 份兼职工作,每份工作预计从 startTime[i] 开始到 endTime[i] 结束,报酬为 profit[i]。
给你一份兼职工作表,包含开始时间 startTime,结束时间 endTime 和预计报酬 profit 三个数组,请你计算并返回可以获得的最大报酬。
注意,时间上出现重叠的 2 份工作不能同时进行。
如果你选择的工作在时间 X 结束,那么你可以立刻进行在时间 X 开始的下一份工作。
示例 1:

输入:startTime = [1,2,3,3], endTime = [3,4,5,6], profit = [50,10,40,70]
输出:120
解释:
我们选出第 1 份和第 4 份工作,
时间范围是 [1-3]+[3-6],共获得报酬 120 = 50 + 70。
- 1
- 2
- 3
- 4
- 5
示例 2:
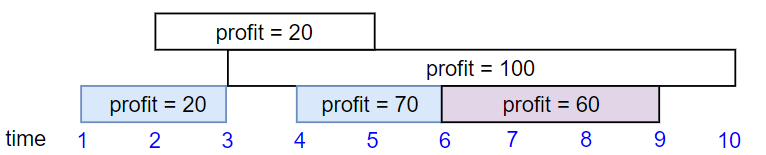
输入:startTime = [1,2,3,4,6], endTime = [3,5,10,6,9], profit = [20,20,100,70,60]
输出:150
解释:
我们选择第 1,4,5 份工作。
共获得报酬 150 = 20 + 70 + 60。
- 1
- 2
- 3
- 4
- 5
示例 3:

输入:startTime = [1,1,1], endTime = [2,3,4], profit = [5,6,4]
输出:6
- 1
- 2
提示:
- 1 < = s t a r t T i m e . l e n g t h = = e n d T i m e . l e n g t h = = p r o f i t . l e n g t h < = 5 ∗ 1 0 4 1 <= startTime.length == endTime.length == profit.length <= 5 * 10^4 1<=startTime.length==endTime.length==profit.length<=5∗104
- 1 < = s t a r t T i m e [ i ] < e n d T i m e [ i ] < = 1 0 9 1 <= startTime[i] < endTime[i] <= 10^9 1<=startTime[i]<endTime[i]<=109
- 1 < = p r o f i t [ i ] < = 1 0 4 1 <= profit[i] <= 10^4 1<=profit[i]<=104
2.21、1030-距离顺序排列矩阵单元格
给出 R 行 C 列的矩阵,其中的单元格的整数坐标为 (r, c),满足 0 <= r < R 且 0 <= c < C。
另外,我们在该矩阵中给出了一个坐标为 (r0, c0) 的单元格。
返回矩阵中的所有单元格的坐标,并按到 (r0, c0) 的距离从最小到最大的顺序排,其中,两单元格(r1, c1) 和 (r2, c2) 之间的距离是曼哈顿距离,|r1 - r2| + |c1 - c2|。(你可以按任何满足此条件的顺序返回答案。)
示例 1:
输入:R = 1, C = 2, r0 = 0, c0 = 0
输出:[[0,0],[0,1]]
解释:从 (r0, c0) 到其他单元格的距离为:[0,1]
- 1
- 2
- 3
示例 2:
输入:R = 2, C = 2, r0 = 0, c0 = 1
输出:[[0,1],[0,0],[1,1],[1,0]]
解释:从 (r0, c0) 到其他单元格的距离为:[0,1,1,2]
[[0,1],[1,1],[0,0],[1,0]] 也会被视作正确答案。
- 1
- 2
- 3
- 4
示例 3:
输入:R = 2, C = 3, r0 = 1, c0 = 2
输出:[[1,2],[0,2],[1,1],[0,1],[1,0],[0,0]]
解释:从 (r0, c0) 到其他单元格的距离为:[0,1,1,2,2,3]
其他满足题目要求的答案也会被视为正确,例如 [[1,2],[1,1],[0,2],[1,0],[0,1],[0,0]]。
- 1
- 2
- 3
- 4
提示:
- 1 <= R <= 100
- 1 <= C <= 100
- 0 <= r0 < R
- 0 <= c0 < C
2.22、274-H 指数
给定一位研究者论文被引用次数的数组(被引用次数是非负整数)。编写一个方法,计算出研究者的 h 指数。
h 指数的定义:h 代表“高引用次数”(high citations),一名科研人员的 h 指数是指他(她)的 (N 篇论文中)总共有 h 篇论文分别被引用了至少 h 次。且其余的 N - h 篇论文每篇被引用次数 不超过 h 次。
例如:某人的 h 指数是 20,这表示他已发表的论文中,每篇被引用了至少 20 次的论文总共有 20 篇。
示例:
输入:citations = [3,0,6,1,5]
输出:3
解释:给定数组表示研究者总共有 5 篇论文,每篇论文相应的被引用了 3, 0, 6, 1, 5 次。
由于研究者有 3 篇论文每篇 至少 被引用了 3 次,其余两篇论文每篇被引用 不多于 3 次,所以她的 h 指数是 3。
- 1
- 2
- 3
- 4
提示:如果 h 有多种可能的值,h 指数是其中最大的那个。
2.23、922-按奇偶排序数组 II
给定一个非负整数数组 A, A 中一半整数是奇数,一半整数是偶数。
对数组进行排序,以便当 A[i] 为奇数时,i 也是奇数;当 A[i] 为偶数时, i 也是偶数。
你可以返回任何满足上述条件的数组作为答案。
示例:
输入:[4,2,5,7]
输出:[4,5,2,7]
解释:[4,7,2,5],[2,5,4,7],[2,7,4,5] 也会被接受。
- 1
- 2
- 3
提示:
- 2 <= A.length <= 20000
- A.length % 2 == 0
- 0 <= A[i] <= 1000
2.24、524-通过删除字母匹配到字典里最长单词
给定一个字符串和一个字符串字典,找到字典里面最长的字符串,该字符串可以通过删除给定字符串的某些字符来得到。如果答案不止一个,返回长度最长且字典顺序最小的字符串。如果答案不存在,则返回空字符串。
示例 1:
输入:
s = "abpcplea", d = ["ale","apple","monkey","plea"]
输出:
"apple"
- 1
- 2
- 3
- 4
- 5
示例 2:
输入:
s = "abpcplea", d = ["a","b","c"]
输出:
"a"
- 1
- 2
- 3
- 4
- 5
说明:
- 所有输入的字符串只包含小写字母。
- 字典的大小不会超过 1000。
- 所有输入的字符串长度不会超过 1000。
2.25、面试题 16.21-交换和
给定两个整数数组,请交换一对数值(每个数组中取一个数值),使得两个数组所有元素的和相等。
返回一个数组,第一个元素是第一个数组中要交换的元素,第二个元素是第二个数组中要交换的元素。若有多个答案,返回任意一个均可。若无满足条件的数值,返回空数组。
示例:
输入: array1 = [4, 1, 2, 1, 1, 2], array2 = [3, 6, 3, 3]
输出: [1, 3]
- 1
- 2
示例:
输入: array1 = [1, 2, 3], array2 = [4, 5, 6]
输出: []
- 1
- 2
提示:1 <= array1.length, array2.length <= 100000
2.26、1647-字符频次唯一的最小删除次数
如果字符串 s 中 不存在 两个不同字符 频次 相同的情况,就称 s 是 优质字符串 。
给你一个字符串 s,返回使 s 成为 优质字符串 需要删除的 最小 字符数。
字符串中字符的 频次 是该字符在字符串中的出现次数。例如,在字符串 “aab” 中,‘a’ 的频次是 2,而 ‘b’ 的频次是 1 。
示例 1:
输入:s = "aab"
输出:0
解释:s 已经是优质字符串。
- 1
- 2
- 3
示例 2:
输入:s = "aaabbbcc"
输出:2
解释:可以删除两个 'b' , 得到优质字符串 "aaabcc" 。
另一种方式是删除一个 'b' 和一个 'c' ,得到优质字符串 "aaabbc" 。
- 1
- 2
- 3
- 4
示例 3:
输入:s = "ceabaacb"
输出:2
解释:可以删除两个 'c' 得到优质字符串 "eabaab" 。
注意,只需要关注结果字符串中仍然存在的字符。(即,频次为 0 的字符会忽略不计。)
- 1
- 2
- 3
- 4
提示:
- 1 < = s . l e n g t h < = 1 0 5 1 <= s.length <= 10^5 1<=s.length<=105
- s 仅含小写英文字母
2.27、1502-判断能否形成等差数列
给你一个数字数组 arr 。
如果一个数列中,任意相邻两项的差总等于同一个常数,那么这个数列就称为 等差数列 。
如果可以重新排列数组形成等差数列,请返回 true ;否则,返回 false 。
示例 1:
输入:arr = [3,5,1]
输出:true
解释:对数组重新排序得到 [1,3,5] 或者 [5,3,1] ,任意相邻两项的差分别为 2 或 -2 ,可以形成等差数列。
- 1
- 2
- 3
示例 2:
输入:arr = [1,2,4]
输出:false
解释:无法通过重新排序得到等差数列。
- 1
- 2
- 3
提示:
- 2 <= arr.length <= 1000
- − 1 0 6 < = a r r [ i ] < = 1 0 6 -10^6 <= arr[i] <= 10^6 −106<=arr[i]<=106
3、低频题
3.1、1691-堆叠长方体的最大高度
给你 n 个长方体 cuboids ,其中第 i 个长方体的长宽高表示为 cuboids[i] = [widthi, lengthi, heighti](下标从 0 开始)。请你从 cuboids 选出一个 子集 ,并将它们堆叠起来。
如果 widthi <= widthj 且 lengthi <= lengthj 且 heighti <= heightj ,你就可以将长方体 i 堆叠在长方体 j 上。你可以通过旋转把长方体的长宽高重新排列,以将它放在另一个长方体上。
返回 堆叠长方体 cuboids 可以得到的 最大高度 。
示例 1:

输入:cuboids = [[50,45,20],[95,37,53],[45,23,12]]
输出:190
解释:
第 1 个长方体放在底部,53x37 的一面朝下,高度为 95 。
第 0 个长方体放在中间,45x20 的一面朝下,高度为 50 。
第 2 个长方体放在上面,23x12 的一面朝下,高度为 45 。
总高度是 95 + 50 + 45 = 190 。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
示例 2:
输入:cuboids = [[38,25,45],[76,35,3]]
输出:76
解释:
无法将任何长方体放在另一个上面。
选择第 1 个长方体然后旋转它,使 35x3 的一面朝下,其高度为 76 。
- 1
- 2
- 3
- 4
- 5
示例 3:
输入:cuboids = [[7,11,17],[7,17,11],[11,7,17],[11,17,7],[17,7,11],[17,11,7]]
输出:102
解释:
重新排列长方体后,可以看到所有长方体的尺寸都相同。
你可以把 11x7 的一面朝下,这样它们的高度就是 17 。
堆叠长方体的最大高度为 6 * 17 = 102 。
- 1
- 2
- 3
- 4
- 5
- 6
提示:
- n == cuboids.length
- 1 <= n <= 100
- 1 <= widthi, lengthi, heighti <= 100
3.2、面试题 17.08-马戏团人塔
有个马戏团正在设计叠罗汉的表演节目,一个人要站在另一人的肩膀上。出于实际和美观的考虑,在上面的人要比下面的人矮一点且轻一点。已知马戏团每个人的身高和体重,请编写代码计算叠罗汉最多能叠几个人。
示例:
输入:height = [65,70,56,75,60,68] weight = [100,150,90,190,95,110]
输出:6
解释:从上往下数,叠罗汉最多能叠 6 层:(56,90), (60,95), (65,100), (68,110), (70,150), (75,190)
- 1
- 2
- 3
提示:height.length == weight.length <= 10000
3.3、296-最佳的碰头地点
有一队人(两人或以上)想要在一个地方碰面,他们希望能够最小化他们的总行走距离。
给你一个 2D 网格,其中各个格子内的值要么是 0,要么是 1。
1 表示某个人的家所处的位置。这里,我们将使用 曼哈顿距离 来计算,其中 distance(p1, p2) = |p2.x - p1.x| + |p2.y - p1.y|。
示例:
输入:
1 - 0 - 0 - 0 - 1
| | | | |
0 - 0 - 0 - 0 - 0
| | | | |
0 - 0 - 1 - 0 - 0
输出: 6
解析: 给定的三个人分别住在(0,0),(0,4) 和 (2,2):
(0,2) 是一个最佳的碰面点,其总行走距离为 2 + 2 + 2 = 6,最小,因此返回 6。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3.4、1054-距离相等的条形码
在一个仓库里,有一排条形码,其中第 i 个条形码为 barcodes[i]。
请你重新排列这些条形码,使其中两个相邻的条形码 不能 相等。 你可以返回任何满足该要求的答案,此题保证存在答案。
示例 1:
输入:[1,1,1,2,2,2]
输出:[2,1,2,1,2,1]
- 1
- 2
示例 2:
输入:[1,1,1,1,2,2,3,3]
输出:[1,3,1,3,2,1,2,1]
- 1
- 2
提示:
- 1 <= barcodes.length <= 10000
- 1 <= barcodes[i] <= 10000
3.5、1727-重新排列后的最大子矩阵
给你一个二进制矩阵 matrix ,它的大小为 m x n ,你可以将 matrix 中的 列 按任意顺序重新排列。
请你返回最优方案下将 matrix 重新排列后,全是 1 的子矩阵面积。
示例 1:

输入:matrix = [[0,0,1],[1,1,1],[1,0,1]]
输出:4
解释:你可以按照上图方式重新排列矩阵的每一列。
最大的全 1 子矩阵是上图中加粗的部分,面积为 4 。
- 1
- 2
- 3
- 4
示例 2:

输入:matrix = [[1,0,1,0,1]]
输出:3
解释:你可以按照上图方式重新排列矩阵的每一列。
最大的全 1 子矩阵是上图中加粗的部分,面积为 3 。
- 1
- 2
- 3
- 4
示例 3:
输入:matrix = [[1,1,0],[1,0,1]]
输出:2
解释:由于你只能整列整列重新排布,所以没有比面积为 2 更大的全 1 子矩形。
- 1
- 2
- 3
示例 4:
输入:matrix = [[0,0],[0,0]]
输出:0
解释:由于矩阵中没有 1 ,没有任何全 1 的子矩阵,所以面积为 0 。
- 1
- 2
- 3
提示:
- m == matrix.length
- n == matrix[i].length
- 1 < = m ∗ n < = 1 0 5 1 <= m * n <= 10^5 1<=m∗n<=105
- matrix[i][j] 要么是 0 ,要么是 1 。
3.6、1481-不同整数的最少数目
给你一个整数数组 arr 和一个整数 k 。现需要从数组中恰好移除 k 个元素,请找出移除后数组中不同整数的最少数目。
示例 1:
输入:arr = [5,5,4], k = 1
输出:1
解释:移除 1 个 4 ,数组中只剩下 5 一种整数。
- 1
- 2
- 3
示例 2:
输入:arr = [4,3,1,1,3,3,2], k = 3
输出:2
解释:先移除 4、2 ,然后再移除两个 1 中的任意 1 个或者三个 3 中的任意 1 个,最后剩下 1 和 3 两种整数。
- 1
- 2
- 3
提示:
- 1 < = a r r . l e n g t h < = 1 0 5 1 <= arr.length <= 10^5 1<=arr.length<=105
- 1 < = a r r [ i ] < = 1 0 9 1 <= arr[i] <= 10^9 1<=arr[i]<=109
- 0 <= k <= arr.length
3.7、710-黑名单中的随机数
给定一个包含 [0,n) 中不重复整数的黑名单 blacklist ,写一个函数从 [0, n) 中返回一个不在 blacklist 中的随机整数。
对它进行优化使其尽量少调用系统方法 Math.random() 。
提示:
- 1 <= n <= 1000000000
- 0 <= blacklist.length < min(100000, N)
- [0, n) 不包含 n ,详细参见 interval notation 。
示例 1:
输入:
["Solution","pick","pick","pick"]
[[1,[]],[],[],[]]
输出:[null,0,0,0]
- 1
- 2
- 3
- 4
示例 2:
输入:
["Solution","pick","pick","pick"]
[[2,[]],[],[],[]]
输出:[null,1,1,1]
- 1
- 2
- 3
- 4
示例 3:
输入:
["Solution","pick","pick","pick"]
[[3,[1]],[],[],[]]
输出:[null,0,0,2]
- 1
- 2
- 3
- 4
示例 4:
输入:
["Solution","pick","pick","pick"]
[[4,[2]],[],[],[]]
输出:[null,1,3,1]
- 1
- 2
- 3
- 4
输入语法说明:输入是两个列表:调用成员函数名和调用的参数。Solution的构造函数有两个参数,n 和黑名单 blacklist。pick 没有参数,输入参数是一个列表,即使参数为空,也会输入一个 [] 空列表。
3.8、324-摆动排序 II
给你一个整数数组 nums,将它重新排列成 nums[0] < nums[1] > nums[2] < nums[3]… 的顺序。
你可以假设所有输入数组都可以得到满足题目要求的结果。
示例 1:
输入:nums = [1,5,1,1,6,4]
输出:[1,6,1,5,1,4]
解释:[1,4,1,5,1,6] 同样是符合题目要求的结果,可以被判题程序接受。
- 1
- 2
- 3
示例 2:
输入:nums = [1,3,2,2,3,1]
输出:[2,3,1,3,1,2]
- 1
- 2
提示:
- 1 <= nums.length <= 5 * 104
- 0 <= nums[i] <= 5000
- 题目数据保证,对于给定的输入 nums ,总能产生满足题目要求的结果
进阶:你能用 O(n) 时间复杂度和 / 或原地 O(1) 额外空间来实现吗?
3.9、1640-能否连接形成数组
给你一个整数数组 arr ,数组中的每个整数 互不相同 。另有一个由整数数组构成的数组 pieces,其中的整数也 互不相同 。请你以 任意顺序 连接 pieces 中的数组以形成 arr 。但是,不允许 对每个数组 pieces[i] 中的整数重新排序。
如果可以连接 pieces 中的数组形成 arr ,返回 true ;否则,返回 false 。
示例 1:
输入:arr = [85], pieces = [[85]]
输出:true
- 1
- 2
示例 2:
输入:arr = [15,88], pieces = [[88],[15]]
输出:true
解释:依次连接 [15] 和 [88]
- 1
- 2
- 3
示例 3:
输入:arr = [49,18,16], pieces = [[16,18,49]]
输出:false
解释:即便数字相符,也不能重新排列 pieces[0]
- 1
- 2
- 3
示例 4:
输入:arr = [91,4,64,78], pieces = [[78],[4,64],[91]]
输出:true
解释:依次连接 [91]、[4,64] 和 [78]
- 1
- 2
- 3
示例 5:
输入:arr = [1,3,5,7], pieces = [[2,4,6,8]]
输出:false
- 1
- 2
提示:
- 1 <= pieces.length <= arr.length <= 100
- sum(pieces[i].length) == arr.length
- 1 <= pieces[i].length <= arr.length
- 1 <= arr[i], pieces[i][j] <= 100
- arr 中的整数 互不相同
- pieces 中的整数 互不相同(也就是说,如果将 pieces 扁平化成一维数组,数组中的所有整数互不相同)
3.10、1403-非递增顺序的最小子序列
给你一个数组 nums,请你从中抽取一个子序列,满足该子序列的元素之和 严格 大于未包含在该子序列中的各元素之和。
如果存在多个解决方案,只需返回 长度最小 的子序列。如果仍然有多个解决方案,则返回 元素之和最大 的子序列。
与子数组不同的地方在于,「数组的子序列」不强调元素在原数组中的连续性,也就是说,它可以通过从数组中分离一些(也可能不分离)元素得到。
注意,题目数据保证满足所有约束条件的解决方案是 唯一 的。同时,返回的答案应当按 非递增顺序 排列。
示例 1:
输入:nums = [4,3,10,9,8]
输出:[10,9]
解释:子序列 [10,9] 和 [10,8] 是最小的、满足元素之和大于其他各元素之和的子序列。但是 [10,9] 的元素之和最大。
- 1
- 2
- 3
示例 2:
输入:nums = [4,4,7,6,7]
输出:[7,7,6]
解释:子序列 [7,7] 的和为 14 ,不严格大于剩下的其他元素之和(14 = 4 + 4 + 6)。因此,[7,6,7] 是满足题意的最小子序列。注意,元素按非递增顺序返回。
- 1
- 2
- 3
示例 3:
输入:nums = [6]
输出:[6]
- 1
- 2
提示:
- 1 <= nums.length <= 500
- 1 <= nums[i] <= 100
3.11、1288-删除被覆盖区间
给你一个区间列表,请你删除列表中被其他区间所覆盖的区间。
只有当 c <= a 且 b <= d 时,我们才认为区间 [a,b) 被区间 [c,d) 覆盖。
在完成所有删除操作后,请你返回列表中剩余区间的数目。
示例:
输入:intervals = [[1,4],[3,6],[2,8]]
输出:2
解释:区间 [3,6] 被区间 [2,8] 覆盖,所以它被删除了。
- 1
- 2
- 3
提示:
- 1 <= intervals.length <= 1000
- 0 < = i n t e r v a l s [ i ] [ 0 ] < i n t e r v a l s [ i ] [ 1 ] < = 1 0 5 0 <= intervals[i][0] < intervals[i][1] <= 10^5 0<=intervals[i][0]<intervals[i][1]<=105
- 对于所有的 i != j:intervals[i] != intervals[j]
3.12、252-会议室
给定一个会议时间安排的数组 intervals ,每个会议时间都会包括开始和结束的时间 intervals[i] = [starti, endi] ,请你判断一个人是否能够参加这里面的全部会议。
示例 1:
输入:intervals = [[0,30],[5,10],[15,20]]
输出:false
- 1
- 2
示例 2:
输入:intervals = [[7,10],[2,4]]
输出:true
- 1
- 2
提示:
- 0 <= intervals.length <= 104
- intervals[i].length == 2
- 0 <= starti < endi <= 106
3.13、1856-子数组最小乘积的最大值
一个数组的 最小乘积 定义为这个数组中 最小值 乘以 数组的 和 。
- 比方说,数组 [3,2,5] (最小值是 2)的最小乘积为 2 * (3+2+5) = 2 * 10 = 20 。
给你一个正整数数组 nums ,请你返回 nums 任意 非空子数组 的最小乘积 的 最大值 。由于答案可能很大,请你返回答案对 109 + 7 取余 的结果。
请注意,最小乘积的最大值考虑的是取余操作 之前 的结果。题目保证最小乘积的最大值在 不取余 的情况下可以用 64 位有符号整数 保存。
子数组 定义为一个数组的 连续 部分。
示例 1:
输入:nums = [1,2,3,2]
输出:14
解释:最小乘积的最大值由子数组 [2,3,2] (最小值是 2)得到。
2 * (2+3+2) = 2 * 7 = 14 。
- 1
- 2
- 3
- 4
示例 2:
输入:nums = [2,3,3,1,2]
输出:18
解释:最小乘积的最大值由子数组 [3,3] (最小值是 3)得到。
3 * (3+3) = 3 * 6 = 18 。
- 1
- 2
- 3
- 4
示例 3:
输入:nums = [3,1,5,6,4,2]
输出:60
解释:最小乘积的最大值由子数组 [5,6,4] (最小值是 4)得到。
4 * (5+6+4) = 4 * 15 = 60 。
- 1
- 2
- 3
- 4
提示:
- 1 <= nums.length <= 105
- 1 <= nums[i] <= 107
3.14、1057-校园自行车分配
在由 2D 网格表示的校园里有 n 位工人(worker)和 m 辆自行车(bike),n <= m。所有工人和自行车的位置都用网格上的 2D 坐标表示。
我们需要为每位工人分配一辆自行车。在所有可用的自行车和工人中,我们选取彼此之间曼哈顿距离最短的工人自行车对 (worker, bike) ,并将其中的自行车分配給工人。如果有多个 (worker, bike) 对之间的曼哈顿距离相同,那么我们选择工人索引最小的那对。类似地,如果有多种不同的分配方法,则选择自行车索引最小的一对。不断重复这一过程,直到所有工人都分配到自行车为止。
给定两点 p1 和 p2 之间的曼哈顿距离为 Manhattan(p1, p2) = |p1.x - p2.x| + |p1.y - p2.y|。
返回长度为 n 的向量 ans,其中 a[i] 是第 i 位工人分配到的自行车的索引(从 0 开始)。
示例 1:

输入:workers = [[0,0],[2,1]], bikes = [[1,2],[3,3]]
输出:[1,0]
解释:
工人 1 分配到自行车 0,因为他们最接近且不存在冲突,工人 0 分配到自行车 1 。所以输出是 [1,0]。
- 1
- 2
- 3
- 4
示例 2:

输入:workers = [[0,0],[1,1],[2,0]], bikes = [[1,0],[2,2],[2,1]]
输出:[0,2,1]
解释:
工人 0 首先分配到自行车 0 。工人 1 和工人 2 与自行车 2 距离相同,因此工人 1 分配到自行车 2,工人 2 将分配到自行车 1 。因此输出为 [0,2,1]。
- 1
- 2
- 3
- 4
提示:
- 0 <= workers[i][j], bikes[i][j] < 1000
- 所有工人和自行车的位置都不相同。
- 1 <= workers.length <= bikes.length <= 1000
3.15、1152-用户网站访问行为分析
为了评估某网站的用户转化率,我们需要对用户的访问行为进行分析,并建立用户行为模型。日志文件中已经记录了用户名、访问时间 以及 页面路径。
为了方便分析,日志文件中的 N 条记录已经被解析成三个长度相同且长度都为 N 的数组,分别是:用户名 username,访问时间 timestamp 和 页面路径 website。第 i 条记录意味着用户名是 username[i] 的用户在 timestamp[i] 的时候访问了路径为 website[i] 的页面。
我们需要找到用户访问网站时的 『共性行为路径』,也就是有最多的用户都 至少按某种次序访问过一次 的三个页面路径。需要注意的是,用户 可能不是连续访问 这三个路径的。
『共性行为路径』是一个 长度为 3 的页面路径列表,列表中的路径 不必不同,并且按照访问时间的先后升序排列。
如果有多个满足要求的答案,那么就请返回按字典序排列最小的那个。(页面路径列表 X 按字典序小于 Y 的前提条件是:X[0] < Y[0] 或 X[0] == Y[0] 且 (X[1] < Y[1] 或 X[1] == Y[1] 且 X[2] < Y[2]))
题目保证一个用户会至少访问 3 个路径一致的页面,并且一个用户不会在同一时间访问两个路径不同的页面。
示例:
输入:username = ["joe","joe","joe","james","james","james","james","mary","mary","mary"], timestamp = [1,2,3,4,5,6,7,8,9,10], website = ["home","about","career","home","cart","maps","home","home","about","career"] 输出:["home","about","career"] 解释: 由示例输入得到的记录如下: ["joe", 1, "home"] ["joe", 2, "about"] ["joe", 3, "career"] ["james", 4, "home"] ["james", 5, "cart"] ["james", 6, "maps"] ["james", 7, "home"] ["mary", 8, "home"] ["mary", 9, "about"] ["mary", 10, "career"] 有 2 个用户至少访问过一次 ("home", "about", "career")。 有 1 个用户至少访问过一次 ("home", "cart", "maps")。 有 1 个用户至少访问过一次 ("home", "cart", "home")。 有 1 个用户至少访问过一次 ("home", "maps", "home")。 有 1 个用户至少访问过一次 ("cart", "maps", "home")。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
提示:
- 3 <= N = username.length = timestamp.length = website.length <= 50
- 1 <= username[i].length <= 10
- 0 <= timestamp[i] <= 10^9
- 1 <= website[i].length <= 10
- username[i] 和 website[i] 都只含小写字符
3.16、1244-力扣排行榜
新一轮的「力扣杯」编程大赛即将启动,为了动态显示参赛者的得分数据,需要设计一个排行榜 Leaderboard。
请你帮忙来设计这个 Leaderboard 类,使得它有如下 3 个函数:
- addScore(playerId, score):
假如参赛者已经在排行榜上,就给他的当前得分增加 score 点分值并更新排行。
假如该参赛者不在排行榜上,就把他添加到榜单上,并且将分数设置为 score。 - top(K):返回前 K 名参赛者的 得分总和。
- reset(playerId):将指定参赛者的成绩清零(换句话说,将其从排行榜中删除)。题目保证在调用此函数前,该参赛者已有成绩,并且在榜单上。
请注意,在初始状态下,排行榜是空的。
示例 1:
输入: ["Leaderboard","addScore","addScore","addScore","addScore","addScore","top","reset","reset","addScore","top"] [[],[1,73],[2,56],[3,39],[4,51],[5,4],[1],[1],[2],[2,51],[3]] 输出: [null,null,null,null,null,null,73,null,null,null,141] 解释: Leaderboard leaderboard = new Leaderboard (); leaderboard.addScore(1,73); // leaderboard = [[1,73]]; leaderboard.addScore(2,56); // leaderboard = [[1,73],[2,56]]; leaderboard.addScore(3,39); // leaderboard = [[1,73],[2,56],[3,39]]; leaderboard.addScore(4,51); // leaderboard = [[1,73],[2,56],[3,39],[4,51]]; leaderboard.addScore(5,4); // leaderboard = [[1,73],[2,56],[3,39],[4,51],[5,4]]; leaderboard.top(1); // returns 73; leaderboard.reset(1); // leaderboard = [[2,56],[3,39],[4,51],[5,4]]; leaderboard.reset(2); // leaderboard = [[3,39],[4,51],[5,4]]; leaderboard.addScore(2,51); // leaderboard = [[2,51],[3,39],[4,51],[5,4]]; leaderboard.top(3); // returns 141 = 51 + 51 + 39;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
提示:
- 1 <= playerId, K <= 10000
- 题目保证 K 小于或等于当前参赛者的数量
- 1 <= score <= 100
- 最多进行 1000 次函数调用
3.17、1498-满足条件的子序列数目
给你一个整数数组 nums 和一个整数 target 。
请你统计并返回 nums 中能满足其最小元素与最大元素的 和 小于或等于 target 的 非空 子序列的数目。
由于答案可能很大,请将结果对 10^9 + 7 取余后返回。
示例 1:
输入:nums = [3,5,6,7], target = 9
输出:4
解释:有 4 个子序列满足该条件。
[3] -> 最小元素 + 最大元素 <= target (3 + 3 <= 9)
[3,5] -> (3 + 5 <= 9)
[3,5,6] -> (3 + 6 <= 9)
[3,6] -> (3 + 6 <= 9)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
示例 2:
输入:nums = [3,3,6,8], target = 10
输出:6
解释:有 6 个子序列满足该条件。(nums 中可以有重复数字)
[3] , [3] , [3,3], [3,6] , [3,6] , [3,3,6]
- 1
- 2
- 3
- 4
示例 3:
输入:nums = [2,3,3,4,6,7], target = 12
输出:61
解释:共有 63 个非空子序列,其中 2 个不满足条件([6,7], [7])
有效序列总数为(63 - 2 = 61)
- 1
- 2
- 3
- 4
示例 4:
输入:nums = [5,2,4,1,7,6,8], target = 16
输出:127
解释:所有非空子序列都满足条件 (2^7 - 1) = 127
- 1
- 2
- 3
提示:
- 1 < = n u m s . l e n g t h < = 1 0 5 1 <= nums.length <= 10^5 1<=nums.length<=105
- 1 < = n u m s [ i ] < = 1 0 6 1 <= nums[i] <= 10^6 1<=nums[i]<=106
- 1 < = t a r g e t < = 1 0 6 1 <= target <= 10^6 1<=target<=106
3.18、1508-子数组和排序后的区间和
给你一个数组 nums ,它包含 n 个正整数。你需要计算所有非空连续子数组的和,并将它们按升序排序,得到一个新的包含 n * (n + 1) / 2 个数字的数组。
请你返回在新数组中下标为 left 到 right (下标从 1 开始)的所有数字和(包括左右端点)。由于答案可能很大,请你将它对 10^9 + 7 取模后返回。
示例 1:
输入:nums = [1,2,3,4], n = 4, left = 1, right = 5
输出:13
解释:所有的子数组和为 1, 3, 6, 10, 2, 5, 9, 3, 7, 4 。将它们升序排序后,我们得到新的数组 [1, 2, 3, 3, 4, 5, 6, 7, 9, 10] 。下标从 le = 1 到 ri = 5 的和为 1 + 2 + 3 + 3 + 4 = 13 。
- 1
- 2
- 3
示例 2:
输入:nums = [1,2,3,4], n = 4, left = 3, right = 4
输出:6
解释:给定数组与示例 1 一样,所以新数组为 [1, 2, 3, 3, 4, 5, 6, 7, 9, 10] 。下标从 le = 3 到 ri = 4 的和为 3 + 3 = 6 。
- 1
- 2
- 3
示例 3:
输入:nums = [1,2,3,4], n = 4, left = 1, right = 10
输出:50
- 1
- 2
提示:
- 1 < = n u m s . l e n g t h < = 1 0 3 1 <= nums.length <= 10^3 1<=nums.length<=103
- nums.length == n
- 1 <= nums[i] <= 100
- 1 <= left <= right <= n * (n + 1) / 2
3.19、1366-通过投票对团队排名
现在有一个特殊的排名系统,依据参赛团队在投票人心中的次序进行排名,每个投票者都需要按从高到低的顺序对参与排名的所有团队进行排位。
排名规则如下:
- 参赛团队的排名次序依照其所获「排位第一」的票的多少决定。如果存在多个团队并列的情况,将继续考虑其「排位第二」的票的数量。以此类推,直到不再存在并列的情况。
- 如果在考虑完所有投票情况后仍然出现并列现象,则根据团队字母的字母顺序进行排名。
给你一个字符串数组 votes 代表全体投票者给出的排位情况,请你根据上述排名规则对所有参赛团队进行排名。
请你返回能表示按排名系统 排序后 的所有团队排名的字符串。
示例 1:
输入:votes = ["ABC","ACB","ABC","ACB","ACB"]
输出:"ACB"
解释:A 队获得五票「排位第一」,没有其他队获得「排位第一」,所以 A 队排名第一。
B 队获得两票「排位第二」,三票「排位第三」。
C 队获得三票「排位第二」,两票「排位第三」。
由于 C 队「排位第二」的票数较多,所以 C 队排第二,B 队排第三。
- 1
- 2
- 3
- 4
- 5
- 6
示例 2:
输入:votes = ["WXYZ","XYZW"]
输出:"XWYZ"
解释:X 队在并列僵局打破后成为排名第一的团队。X 队和 W 队的「排位第一」票数一样,但是 X 队有一票「排位第二」,而 W 没有获得「排位第二」。
- 1
- 2
- 3
示例 3:
输入:votes = ["ZMNAGUEDSJYLBOPHRQICWFXTVK"]
输出:"ZMNAGUEDSJYLBOPHRQICWFXTVK"
解释:只有一个投票者,所以排名完全按照他的意愿。
- 1
- 2
- 3
示例 4:
输入:votes = ["BCA","CAB","CBA","ABC","ACB","BAC"]
输出:"ABC"
解释:
A 队获得两票「排位第一」,两票「排位第二」,两票「排位第三」。
B 队获得两票「排位第一」,两票「排位第二」,两票「排位第三」。
C 队获得两票「排位第一」,两票「排位第二」,两票「排位第三」。
完全并列,所以我们需要按照字母升序排名。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
示例 5:
输入:votes = ["M","M","M","M"]
输出:"M"
解释:只有 M 队参赛,所以它排名第一。
- 1
- 2
- 3
提示:
- 1 <= votes.length <= 1000
- 1 <= votes[i].length <= 26
- votes[i].length == votes[j].length for 0 <= i, j < votes.length
- votes[i][j] 是英文 大写 字母
- votes[i] 中的所有字母都是唯一的
- votes[0] 中出现的所有字母 同样也 出现在 votes[j] 中,其中 1 <= j < votes.length
3.20、1387-将整数按权重排序
我们将整数 x 的 权重 定义为按照下述规则将 x 变成 1 所需要的步数:
- 如果 x 是偶数,那么 x = x / 2
- 如果 x 是奇数,那么 x = 3 * x + 1
比方说,x=3 的权重为 7 。因为 3 需要 7 步变成 1 (3 --> 10 --> 5 --> 16 --> 8 --> 4 --> 2 --> 1)。
给你三个整数 lo, hi 和 k 。你的任务是将区间 [lo, hi] 之间的整数按照它们的权重 升序排序 ,如果大于等于 2 个整数有 相同 的权重,那么按照数字自身的数值 升序排序 。
请你返回区间 [lo, hi] 之间的整数按权重排序后的第 k 个数。
注意,题目保证对于任意整数 x (lo <= x <= hi) ,它变成 1 所需要的步数是一个 32 位有符号整数。
示例 1:
输入:lo = 12, hi = 15, k = 2
输出:13
解释:12 的权重为 9(12 --> 6 --> 3 --> 10 --> 5 --> 16 --> 8 --> 4 --> 2 --> 1)
13 的权重为 9
14 的权重为 17
15 的权重为 17
区间内的数按权重排序以后的结果为 [12,13,14,15] 。对于 k = 2 ,答案是第二个整数也就是 13 。
注意,12 和 13 有相同的权重,所以我们按照它们本身升序排序。14 和 15 同理。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
示例 2:
输入:lo = 1, hi = 1, k = 1
输出:1
- 1
- 2
示例 3:
输入:lo = 7, hi = 11, k = 4
输出:7
解释:区间内整数 [7, 8, 9, 10, 11] 对应的权重为 [16, 3, 19, 6, 14] 。
按权重排序后得到的结果为 [8, 10, 11, 7, 9] 。
排序后数组中第 4 个数字为 7 。
- 1
- 2
- 3
- 4
- 5
示例 4:
输入:lo = 10, hi = 20, k = 5
输出:13
- 1
- 2
示例 5:
输入:lo = 1, hi = 1000, k = 777
输出:570
- 1
- 2
提示:
- 1 <= lo <= hi <= 1000
- 1 <= k <= hi - lo + 1
3.21、1356-根据数字二进制下 1 的数目排序
给你一个整数数组 arr 。请你将数组中的元素按照其二进制表示中数字 1 的数目升序排序。
如果存在多个数字二进制中 1 的数目相同,则必须将它们按照数值大小升序排列。
请你返回排序后的数组。
示例 1:
输入:arr = [0,1,2,3,4,5,6,7,8]
输出:[0,1,2,4,8,3,5,6,7]
解释:[0] 是唯一一个有 0 个 1 的数。
[1,2,4,8] 都有 1 个 1 。
[3,5,6] 有 2 个 1 。
[7] 有 3 个 1 。
按照 1 的个数排序得到的结果数组为 [0,1,2,4,8,3,5,6,7]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
示例 2:
输入:arr = [1024,512,256,128,64,32,16,8,4,2,1]
输出:[1,2,4,8,16,32,64,128,256,512,1024]
解释:数组中所有整数二进制下都只有 1 个 1 ,所以你需要按照数值大小将它们排序。
- 1
- 2
- 3
示例 3:
输入:arr = [10000,10000]
输出:[10000,10000]
- 1
- 2
示例 4:
输入:arr = [2,3,5,7,11,13,17,19]
输出:[2,3,5,17,7,11,13,19]
- 1
- 2
示例 5:
输入:arr = [10,100,1000,10000]
输出:[10,100,10000,1000]
- 1
- 2
提示:
- 1 <= arr.length <= 500
- 0 <= arr[i] <= 10^4
3.22、280-摆动排序
给你一个无序的数组 nums, 将该数字 原地 重排后使得 nums[0] <= nums[1] >= nums[2] <= nums[3]…。
示例:
输入: nums = [3,5,2,1,6,4]
输出: 一个可能的解答是 [3,5,1,6,2,4]
- 1
- 2
3.23、1636-按照频率将数组升序排序
给你一个整数数组 nums ,请你将数组按照每个值的频率 升序 排序。如果有多个值的频率相同,请你按照数值本身将它们 降序 排序。
请你返回排序后的数组。
示例 1:
输入:nums = [1,1,2,2,2,3]
输出:[3,1,1,2,2,2]
解释:'3' 频率为 1,'1' 频率为 2,'2' 频率为 3 。
- 1
- 2
- 3
示例 2:
输入:nums = [2,3,1,3,2]
输出:[1,3,3,2,2]
解释:'2' 和 '3' 频率都为 2 ,所以它们之间按照数值本身降序排序。
- 1
- 2
- 3
示例 3:
输入:nums = [-1,1,-6,4,5,-6,1,4,1]
输出:[5,-1,4,4,-6,-6,1,1,1]
- 1
- 2
提示:
- 1 <= nums.length <= 100
- -100 <= nums[i] <= 100
3.24、1491-去掉最低工资和最高工资后的工资平均值
给你一个整数数组 salary ,数组里每个数都是 唯一 的,其中 salary[i] 是第 i 个员工的工资。
请你返回去掉最低工资和最高工资以后,剩下员工工资的平均值。
示例 1:
输入:salary = [4000,3000,1000,2000]
输出:2500.00000
解释:最低工资和最高工资分别是 1000 和 4000 。
去掉最低工资和最高工资以后的平均工资是 (2000+3000)/2= 2500
- 1
- 2
- 3
- 4
示例 2:
输入:salary = [1000,2000,3000]
输出:2000.00000
解释:最低工资和最高工资分别是 1000 和 3000 。
去掉最低工资和最高工资以后的平均工资是 (2000)/1= 2000
- 1
- 2
- 3
- 4
示例 3:
输入:salary = [6000,5000,4000,3000,2000,1000]
输出:3500.00000
- 1
- 2
示例 4:
输入:salary = [8000,9000,2000,3000,6000,1000]
输出:4750.00000
- 1
- 2
提示:
- 3 <= salary.length <= 100
- 10^3 <= salary[i] <= 10^6
- salary[i] 是唯一的。
- 与真实值误差在 10^-5 以内的结果都将视为正确答案。
3.25、1424-对角线遍历 II
给你一个列表 nums ,里面每一个元素都是一个整数列表。请你依照下面各图的规则,按顺序返回 nums 中对角线上的整数。
示例 1:
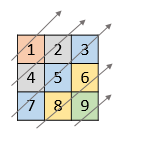
输入:nums = [[1,2,3],[4,5,6],[7,8,9]]
输出:[1,4,2,7,5,3,8,6,9]
- 1
- 2
示例 2:
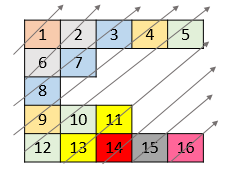
输入:nums = [[1,2,3,4,5],[6,7],[8],[9,10,11],[12,13,14,15,16]]
输出:[1,6,2,8,7,3,9,4,12,10,5,13,11,14,15,16]
- 1
- 2
示例 3:
输入:nums = [[1,2,3],[4],[5,6,7],[8],[9,10,11]]
输出:[1,4,2,5,3,8,6,9,7,10,11]
- 1
- 2
示例 4:
输入:nums = [[1,2,3,4,5,6]]
输出:[1,2,3,4,5,6]
- 1
- 2
提示:
- 1 < = n u m s . l e n g t h < = 1 0 5 1 <= nums.length <= 10^5 1<=nums.length<=105
- 1 < = n u m s [ i ] . l e n g t h < = 1 0 5 1 <= nums[i].length <= 10^5 1<=nums[i].length<=105
- 1 < = n u m s [ i ] [ j ] < = 1 0 9 1 <= nums[i][j] <= 10^9 1<=nums[i][j]<=109
- nums 中最多有 10^5 个数字。
3.26、1305-两棵二叉搜索树中的所有元素
给你 root1 和 root2 这两棵二叉搜索树。
请你返回一个列表,其中包含 两棵树 中的所有整数并按 升序 排序。.
示例 1:

输入:root1 = [2,1,4], root2 = [1,0,3]
输出:[0,1,1,2,3,4]
- 1
- 2
示例 2:
输入:root1 = [0,-10,10], root2 = [5,1,7,0,2]
输出:[-10,0,0,1,2,5,7,10]
- 1
- 2
示例 3:
输入:root1 = [], root2 = [5,1,7,0,2]
输出:[0,1,2,5,7]
- 1
- 2
示例 4:
输入:root1 = [0,-10,10], root2 = []
输出:[-10,0,10]
- 1
- 2
示例 5:
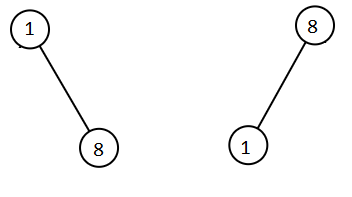
输入:root1 = [1,null,8], root2 = [8,1]
输出:[1,1,8,8]
- 1
- 2
提示:
- 每棵树最多有 5000 个节点。
- 每个节点的值在 [ − 1 0 5 , 1 0 5 ] [-10^5, 10^5] [−105,105] 之间。
3.27、1710-卡车上的最大单元数
请你将一些箱子装在 一辆卡车 上。给你一个二维数组 boxTypes ,其中 boxTypes[i] = [numberOfBoxesi, numberOfUnitsPerBoxi] :
- numberOfBoxesi 是类型 i 的箱子的数量。
- numberOfUnitsPerBoxi 是类型 i 每个箱子可以装载的单元数量。
整数 truckSize 表示卡车上可以装载 箱子 的 最大数量 。只要箱子数量不超过 truckSize ,你就可以选择任意箱子装到卡车上。
返回卡车可以装载 单元 的 最大 总数。
示例 1:
输入:boxTypes = [[1,3],[2,2],[3,1]], truckSize = 4
输出:8
解释:箱子的情况如下:
- 1 个第一类的箱子,里面含 3 个单元。
- 2 个第二类的箱子,每个里面含 2 个单元。
- 3 个第三类的箱子,每个里面含 1 个单元。
可以选择第一类和第二类的所有箱子,以及第三类的一个箱子。
单元总数 = (1 * 3) + (2 * 2) + (1 * 1) = 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
示例 2:
输入:boxTypes = [[5,10],[2,5],[4,7],[3,9]], truckSize = 10
输出:91
- 1
- 2
提示:
- 1 <= boxTypes.length <= 1000
- 1 <= numberOfBoxesi, numberOfUnitsPerBoxi <= 1000
- 1 <= truckSize <= 106
3.28、969-煎饼排序
给你一个整数数组 arr ,请使用 煎饼翻转 完成对数组的排序。
一次煎饼翻转的执行过程如下:
- 选择一个整数 k ,1 <= k <= arr.length
- 反转子数组 arr[0…k-1](下标从 0 开始)
例如,arr = [3,2,1,4] ,选择 k = 3 进行一次煎饼翻转,反转子数组 [3,2,1] ,得到 arr = [1,2,3,4] 。
以数组形式返回能使 arr 有序的煎饼翻转操作所对应的 k 值序列。任何将数组排序且翻转次数在 10 * arr.length 范围内的有效答案都将被判断为正确。
示例 1:
输入:[3,2,4,1]
输出:[4,2,4,3]
解释:
我们执行 4 次煎饼翻转,k 值分别为 4,2,4,和 3。
初始状态 arr = [3, 2, 4, 1]
第一次翻转后(k = 4):arr = [1, 4, 2, 3]
第二次翻转后(k = 2):arr = [4, 1, 2, 3]
第三次翻转后(k = 4):arr = [3, 2, 1, 4]
第四次翻转后(k = 3):arr = [1, 2, 3, 4],此时已完成排序。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
示例 2:
输入:[1,2,3]
输出:[]
解释:
输入已经排序,因此不需要翻转任何内容。
请注意,其他可能的答案,如 [3,3] ,也将被判断为正确。
- 1
- 2
- 3
- 4
- 5
提示:
- 1 <= arr.length <= 100
- 1 <= arr[i] <= arr.length
- arr 中的所有整数互不相同(即,arr 是从 1 到 arr.length 整数的一个排列)
3.29、853-车队
N 辆车沿着一条车道驶向位于 target 英里之外的共同目的地。
每辆车 i 以恒定的速度 speed[i] (英里/小时),从初始位置 position[i] (英里) 沿车道驶向目的地。
一辆车永远不会超过前面的另一辆车,但它可以追上去,并与前车以相同的速度紧接着行驶。
此时,我们会忽略这两辆车之间的距离,也就是说,它们被假定处于相同的位置。
车队 是一些由行驶在相同位置、具有相同速度的车组成的非空集合。注意,一辆车也可以是一个车队。
即便一辆车在目的地才赶上了一个车队,它们仍然会被视作是同一个车队。
会有多少车队到达目的地?
示例:
输入:target = 12, position = [10,8,0,5,3], speed = [2,4,1,1,3]
输出:3
解释:
从 10 和 8 开始的车会组成一个车队,它们在 12 处相遇。
从 0 处开始的车无法追上其它车,所以它自己就是一个车队。
从 5 和 3 开始的车会组成一个车队,它们在 6 处相遇。
请注意,在到达目的地之前没有其它车会遇到这些车队,所以答案是 3。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
提示:
- 0 < = N < = 1 0 4 0 <= N <= 10 ^ 4 0<=N<=104
- 0 < t a r g e t < = 1 0 6 0 < target <= 10 ^ 6 0<target<=106
- 0 < s p e e d [ i ] < = 1 0 6 0 < speed[i] <= 10 ^ 6 0<speed[i]<=106
- 0 <= position[i] < target
- 所有车的初始位置各不相同。

