
- 1【机器学习实战1】泰坦尼克号:灾难中的机器学习(一)数据预处理_泰坦尼克数据预处理
- 2opencv-python——通过cv2.distanceTransform()函数将距离转换成热力图
- 3sklearn.neighbors.KNeighborsClassifier()函数解析_kneighborsclassifier函数是干什么的
- 4【windows|008】DNS服务详解
- 5vscode 快捷键 在终端 和工作区 切换_vscode切换工作区
- 6C++11常用特性_c++11 常用特性有哪些
- 7linux磁盘管理(永久挂载)_linux磁盘管理永久挂载
- 8ASIC&FPGA&SOC_fpga asic soc
- 9Sharding-JDBC之ComplexKeysShardingAlgorithm(复合分片算法)
- 10vscode中使用终端响应卡顿_vscode终端卡住了怎么办
Hadoop(入门) -- 第三天_hadoop入门
赞
踩
HDFS
一、分布式存储
1、分布式的基础架构
大数据体系中,分布式的调度主要有2类架构模式:
①去中心化模式:没有明确的中心。众多服务器之间基于特地规则进行同步协跳
②中心化模式(主从模式):有一个中心节点(服务器)来统筹其他服务器的工作,统一指挥,统一调派,避免混乱
注:Hadoop框架,就是一个典型的主从模式(中心化模式)架构的技术框架。
二、HDFS的基础架构
1、HDFS概述
HDFS是Hadoop三大组件(HDFS、MapReduce、YARN)之一。
- 全称是:Hadoop Distributed File System(Hadoop分布式文件系统)
- 是Hadoop技术栈内提供的分布式数据存储解决方案
- 可以在多台服务器上构建存储集群,存储海量的数据
HDFS是一个典型的主从模式架构
2、HDFS的基础架构
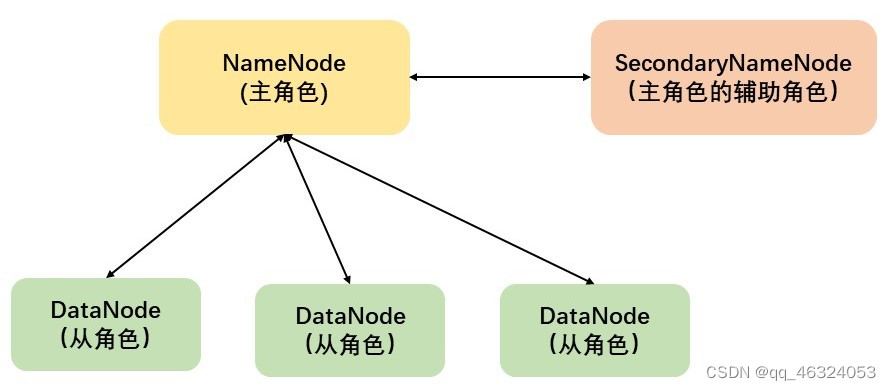
①NameNode:HDFS系统的主角色,是一个独立的进程,负责管理HDFS整个文件系统,负责管理DataNode
②DataNode:HDFS系统的从角色,是一个独立进程,主要负责数据的存储,即存入数据和取出数据
③SecondaryNameNode:NameNode的辅助,是一个独立进程,主要帮助NameNode完成元数据整理工作(打杂)
注:一个典型的HDFS集群,就是由1个DataNode加若干个(至少一个)DataNode组成
三、HDFS集群环境部署
具体步骤省略
补充点:
1、Hadoop安装包目录结构
各个文件夹含义如下
• bin ,存放 Hadoop 的各类程序(命令)• etc ,存放 Hadoop 的配置文件• include , C 语言的一些头文件• lib ,存放 Linux 系统的动态链接库( .so 文件)• libexec ,存放配置 Hadoop 系统的脚本文件( .sh 和 .cmd )• licenses-binary ,存放许可证文件• sbin ,管理员程序( super bin )share,存放二进制源码(Ja2\va jar包)
2、查看HDFS WEBUI
例:http://node1:9870,即可查看到hdfs文件系统的管理网页。
四、HDFS的Shell操作
1、进程启停管理
①一键启停HDFS集群
$HADOOP_HOME/sbin/start(stop)-dfs.sh
②单进程启停
$HADOOP_HOME/sbin/hadoop-daemon.sh
此脚本可以单独控制所在机器的进程的启停
$HADOOP_HOME/bin/hdfs --daemon
此程序也可以单独控制所在机器的进程的启停
2、文件系统操作命令
①HDFS文件系统基本信息
HDFS作为分布式存储的文件系统,有其对数据的路径表达方式。
HDFS同Linux系统一样,均是以/作为根目录的组织形式
如何区分?
- Linux:file:///
- HDFS:hdfs://namenode:port/
如上路径:
- Linux:file:///usr/local/hello.txt
- HDFS:hdfs://node1:8020/usr/local/hello.txt
协议头file:///或hdfs://node1:8020/可以省略
- 需要提供Linux路径的参数,会自动识别为file://
- 需要提供HDFS路径的参数,会自动识别为hdfs://
除非明确需要写或不写会有BUG,否则一般不用写协议头
②命令的基本形式
hadoop命令(老版本用法):hadoop fs [generic options]
hdfs命令(新版本用法):hdfs fs [generic options]
③创建文件夹
hadoop fs -mkdir [-p] <path> ...
hdfs dfs -mkdir [-p] <path> ...
path:为待创建的目录
-p:与Linux mkdir -p一致,它会沿着路径创建父目录
④查看指定目录下内容
hadoop fs -ls [-h] [-R] [<path> ...]
hdfs dfs -ls [-h] [-R] [<path> ...]
path:指定目录路径
-h:人性化显示文件size
-R:递归查看指定目录及其子目录
⑤上传文件到HDFS指定目录下
hadoop fs -put [-f] [-p] <localsrc> ... <dst>
hdfs dfs -put [-f] [-p] <localsrc> ... <dst>
-f:覆盖目标文件(已存在下)
-p:保留访问和修改时间,所有权和权限
localsrc:本地文件系统(客户端所在机器)
dst:目标文件系统(HDFS)
⑥查看HDFS
读取指定文件全部内容,显示在标准输出控制台
hadoop fs -cat <src> ...
hdfs dfs -cat <src> ...
读取大文件可以使用管道符配合more
hadoop fs -cat <src> | more
hdfs dfs -cat <src> | more
⑦下载HDFS文件
hadoop fs -get [-f] [-p] <src> ... <localdst>
hdfs dfs -get [-f] [-p] <src> ... <localdst>
下载文件到本地文件系统指定目录,localdst必须是目录
-f:覆盖目标文件(已存在下)
-p:保留访问和修改时间,所有权和权限。
⑧拷贝HDFS文件
hadoop fs -cp [-f] <src> ... <src>
hdfs dfs -cp [-f] <src> ... <src>
-f:覆盖目标文件(已存在下)
⑨追加数据到HDFS文件中
hadoop fs -appendToFile <localsrc> ... <dst>
hdfs dfs -appendToFile <localsrc> ... <dst>
将所有给定本地文件的内容追加到给定dst文件
dst如果文件不存在,将创建该文件
如果<localsrc>为-,则输入为从标准输入中读取
⑩HDFS数据移动操作
hadoop fs -mv <src> ... <dst>
hdfs dfs -mv <src> ... <dst>
移动文件到指定文件夹下
可以使用该命令移动数据,重命名文件的名称
⑪HDFS数据删除操作
hadoop fs -rm -r [-skipTrash] URI [URI ...]
hdfs dfs -rm -r [-skipTrash] URI [URI ...]
删除指定路径的文件夹
-skipTrash跳过回收站,直接删除
注:回收站功能默认关闭,如果要开启需要在core-site.xml内配置
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>120</value>
</property>
无需重启集群,在哪个机器配置的,在哪个机器执行命令就生效。回收站默认位置在:/user/用户名(hadoop)/.Trash
HDFS shell其他命令
3、HDFS权限
①HDFS文件系统使用和Linux一样逻辑的权限控制体系
②Linux的超级用户是root
HDFS文件系统的超级用户:是启动namenode的用户
③修改权限
- 修改所属用户和组
hadoop fs -chown [-R] root:root /xxx.txt
hdfs dfs -chown [-R] root:root /xxx.txt
- 修改权限
hadoop fs -chmod [-R] 777 /xxx.txt
hdfs dfs -rm -r [-skipTrash] URI [URI ...]
五 、HDFS的存储原理
1、存储原理
①分布式文件存储:每个服务器(节点)存储文件的一部分
②HDFS设定统一的管理单位--block块(HDFS最小的存储单位,每个256MB,可修改大小),来解决文件大小不一,不利于统一管理的问题
③在HDFS上,数据block块可以有多个副本,来提高数据的安全性
2、fsck命令

- 除了配置文件外,还可以在上传文件的时候,临时决定被上传文件以多少个副本存储,
hadoop fs -D dfs.replication=2 -put test.txt /tmp/
如上命令,就可以在上传test.txt的时候,临时设置其副本数为2
- 对于已经存在HDFS的文件,修改dfs.replication属性不会生效,如果要修改已存在文件可以通过命令
hadoop fs -setrep [-R] 2 path
如上命令,指定path的内容将会被修改为2个副本存储
-R: 可选,使用-R表示对子目录也生效
- 检查文件的副本数
hdfs fsck path [-files [-blocks [-location]]]
fsck可以检查指定路径是否正常
-files: 可以列出路径内的文件状态
-files -blocks: 输出文件块报告(有几个块,多少副本)
-files -blocks -locations : 输出每一个block块的详情
- block配置
hdfs默认设置为256MB一个块,也就是1GB文件会被划分为4个block存储

3、NameNode元数据
- edits文件
NameNode基于一批edits和一个fsimage文件的配合完成整个文件系统的管理和维护
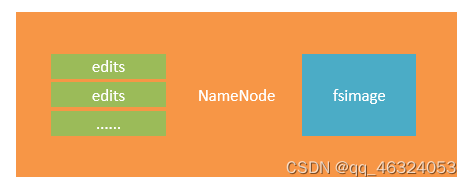
edits文件: 是一个流水账文件,记录了hdfs中的每一次操作,以及本次操作影响的文件其对应的block
- faimage文件: 将全部的edits文件,合并为最终结果,即可得到一个FSImage文件
- NameNode元数据管理维护
NameNode基于edits和FSInage的配合,完成整个文件系统文件的管理
①每次对HDFS的操作,均被edits文件记录
②edits达到大小上线后,开启新的edits记录
③定期进行edits的合并操作
如当前没有fsimage文件,将全部的edits合并为第一个fsimage
如当前已存在fsimage文件,将全部edits和已存在的fsimage进行合并,形成新的fsimage
- 元数据合并控制参数
对于元数据的合并,是一个定时过程,基于:
dfs.namenode.checkpoint.period, 默认3600(秒)即1小时
dfs.namenode.checkpoint.txns, 默认1000000,即100W次事务
只要有一个达到条件就执行
检查是否达到条件,默认60秒检查一次,基于:
dfs.namenode.checkpoint.check.period, 默认60(秒),来决定
- SecondaryNameNode的作用
SecondaryNameNode会通过http从NameNode拉取数据(edits和fsimage),然后合并完成后提供给NameNode使用.
总结:
1、NameNode基于---edits记录每次操作、fsimage记录某一个时间节点前的当前文件系统全部文件的状态和信息,维护整个文件系统元数据
2、edits文件会被合并到fsimage中,这个合并由SecondaryNameNode来操作
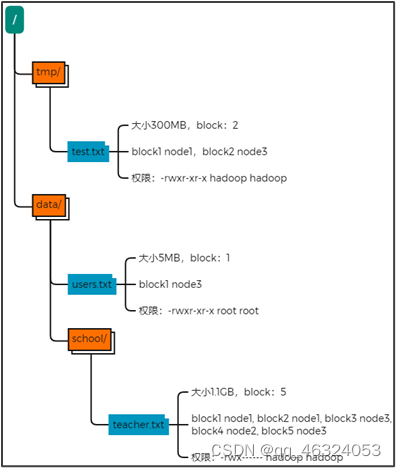
3、fsimage记录的内容是:
4、HDFS数据的读写流程
①数据写入流程
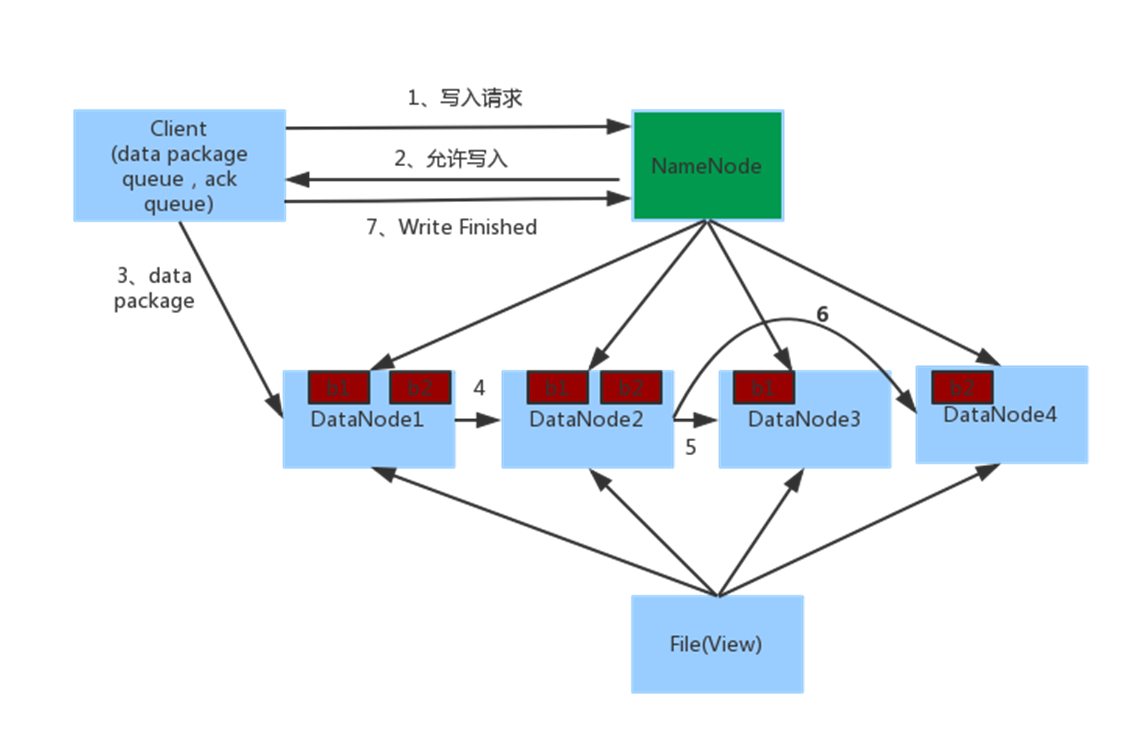
步骤:
1、客户端向NameNode发起请求
2、NameNode审核权限、剩余空间后,满足条件允许写入,并告知客户端写入的DataNode地址
3、客户端向指定的DataNode发送数据包
4、被写入数据的DataNode同时完成数据副本的复制工作,将其接收的数据分发给其它DataNode
5、如上图,DataNode1复制给DataNode2,然后基于DataNode2复制给Datanode3和DataNode4
6、写入完成客户端通知NameNode,NameNode做元数据记录工作
关键信息点:
- NameNode不负责数据写入,只负责元数据记录和权限审批
- 客户端直接向1台DataNode写数据,这个DataNode一般是离客户端最近(网络距离)的那一个
- 数据块副本的复制工作,由DataNode之间自行完成(构建一个PipLine,按顺序复制分发,如图1给2, 2给3和4)
②数据读取流程
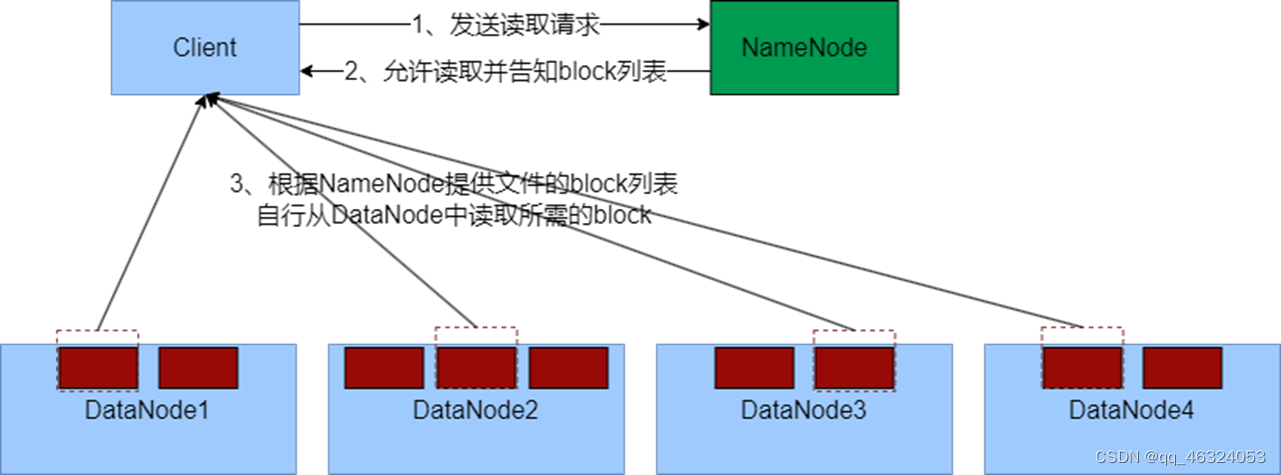
步骤:
1、客户端向NameNode申请读取某文件
2、 NameNode判断客户端权限等细节后,允许读取,并返回此文件的block列表
3、客户端拿到block列表后自行寻找DataNode读取即可
关键点:
-
数据同样不通过NameNode提供
-
NameNode提供的block列表,会基于网络距离计算尽量提供离客户端最近的,这是因为1个block有3份,会尽量找离客户端最近的那一份让其读取
注:
最近的距离就是在同一台机器,其次就是同一个局域网(交换机),再其次就是跨越交换机,再其次就是跨越数据中心
HDFS内置网络距离计算算法,可以通过IP地址、路由表来推断网络距离

