
热门标签
热门文章
- 1加入UOS开发者网站,探索编程世界的无限可能_uosdn
- 2LlamaIndex 和 LangChain 对比,应该选择哪个 RAG 框架?_dify为什么不使用 llamaindex
- 3利用 Python 和 IPIDEA:跨境电商与数据采集的完美解决方案
- 4华为OD面试手撕代码最新:最大子数组和_面试 最大数组和
- 5人工智能-基础篇05篇-人工智能中AI,AIGC,AGI,AI Agent名词解释
- 6comfyui (AI绘图+设计)安装教程_comfyul
- 7图像处理与视觉感知复习--概述_灰度级数通常取l=
- 8️ LangChain +Streamlit+ Llama :将对话式人工智能引入您的本地设备(下篇)
- 9SpringCloud-Gateway动态路由之Nacos_springcloudgateway动态路由 nacos
- 10普通人的第一个Linux发行版-安装Deepin20.5_deepin全盘安装好吗
当前位置: article > 正文
llamafactory-llama3微调中文数据集_llama3 数据集
作者:繁依Fanyi0 | 2024-08-05 01:43:23
赞
踩
llama3 数据集
一、定义
https://github.com/SmartFlowAI/Llama3-Tutorial/tree/main
- 基准模型测试
- opencompass 离线测评
- 数据准备
- 微调训练
- 合并
- 测试
- 人工审核对比
二、实现
- 基准模型测试
基准模型 llama3-8b
https://zhuanlan.zhihu.com/p/694818596?
https://github.com/SmartFlowAI/Llama3-Tutorial/blob/main/docs/opencompass.md
https://github.com/InternLM/Tutorial/blob/camp2/data_fine_tuning/data_fine_tuning.md
CUDA_VISIBLE_DEVICES=0 llamafactory-cli eval \
--model_name_or_path /home/Meta-Llama-3-8B-Instruct \
--template llama3 \
--task triviaqa \
--split validation \
--lang en \
--n_shot 5 \
--batch_size 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
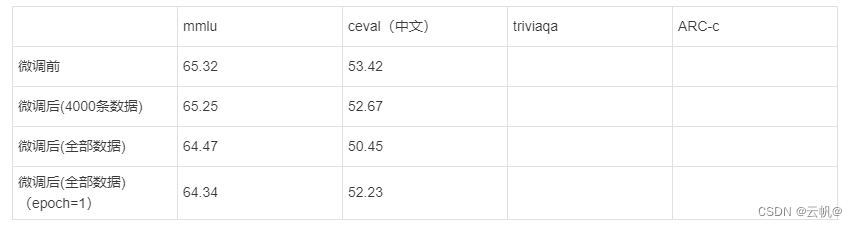
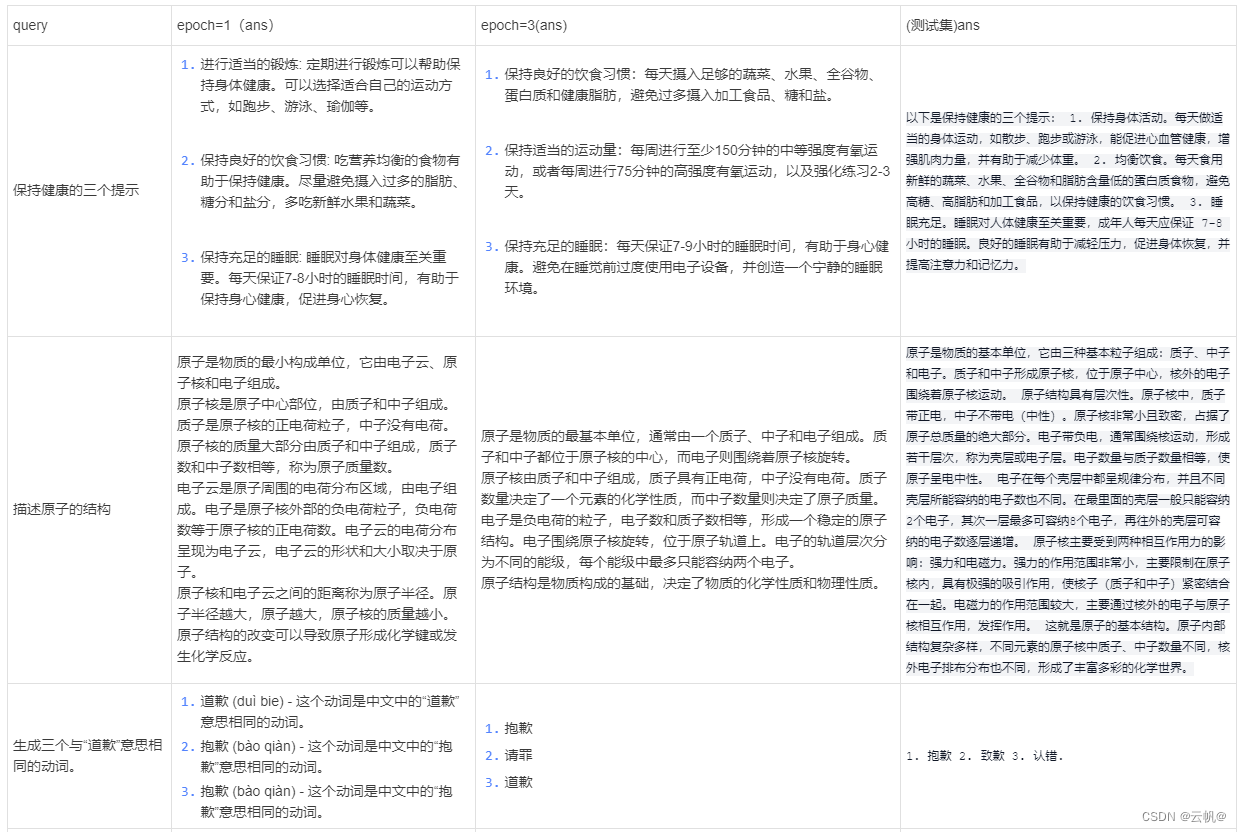
个人认为,虽然epoch=1 在标准指标中中文评估能力大于epoch=3,但人工审核过程中,epoch =3 在中文表达上更满足人的需求。随着训练轮次的增加,模型更倾向于表达中文。
- opencompass 离线测评
部署见opencompass 配置篇
from mmengine.config import read_base with read_base(): from .datasets.mmlu.mmlu_gen_4d595a import mmlu_datasets datasets = [*mmlu_datasets] from opencompass.models import HuggingFaceCausalLM batch_size = 20 # 指定评测模型 model_name_or_paths = [ #可以多个模型 '/home/Meta-Llama-3-8B-Instruct' ] models = [] #模型以及配置放于列表中 for model_name_or_path in model_name_or_paths: abbr = model_name_or_path.split('/')[-1] model = dict( type=HuggingFaceCausalLM, abbr=abbr, path=model_name_or_path, tokenizer_path=model_name_or_path, tokenizer_kwargs=dict(padding_side='left', truncation_side='left', use_fast=False, trust_remote_code=True ), max_out_len=1024, max_seq_len=2048, batch_size=batch_size, model_kwargs=dict(device_map='auto', trust_remote_code=True), batch_padding=False, # if false, inference with for-loop without batch padding run_cfg=dict(num_gpus=2, num_procs=2), ) models.append(model) # python run.py configs/eval_llama3_8b_demo.py

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 数据准备
https://github.com/InternLM/Tutorial/blob/camp2/data_fine_tuning/data_fine_tuning.md
https://modelscope.cn/datasets/baicai003/Llama3-Chinese-dataset/summary
https://huggingface.co/datasets/m-a-p/COIG-CQIA
import datasets
data=datasets.load_dataset("llamafactory/alpaca_gpt4_zh")
data=data["train"]
res=[]
for i in range(len(data)):
res.append(data[i])
import json
with open('alpaca_gpt4_zh.json', 'w',encoding="utf8") as file:
# 使用缩进格式化输出 JSON 数据
json.dump(res, file, indent=4,ensure_ascii=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
#42677 "alpaca_gpt4_zh_local": { "file_name": "alpaca_gpt4_zh.json" } #16493 "Llama3-Chinese-dataset_local": { "file_name": "Llama3-Chinese-dataset.json" } #11262 "COIG-CQIA_local": { "file_name": "COIG-CQIA.json" } #51983 "alpaca_gpt4_en_local": { "file_name": "alpaca_gpt4_en.json" }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 微调训练
#lora 双卡微调 CUDA_VISIBLE_DEVICES=0,1 nohup llamafactory-cli train \ --stage sft \ --do_train \ --model_name_or_path /home/Meta-Llama-3-8B-Instruct \ --dataset alpaca_gpt4_zh_local,Llama3-Chinese-dataset_local,COIG-CQIA_local,alpaca_gpt4_en_local \ --dataset_dir ./data \ --template llama3 \ --finetuning_type lora \ --output_dir ./saves/LLaMA3-8B/lora/sft \ --overwrite_cache \ --overwrite_output_dir \ --cutoff_len 1024 \ --preprocessing_num_workers 16 \ --per_device_train_batch_size 4 \ --per_device_eval_batch_size 2 \ --gradient_accumulation_steps 8 \ --lr_scheduler_type cosine \ --logging_steps 50 \ --warmup_steps 20 \ --save_steps 100 \ --eval_steps 50 \ --evaluation_strategy steps \ --load_best_model_at_end \ --learning_rate 5e-5 \ --num_train_epochs 3.0 \ --val_size 0.1 \ --plot_loss \ --fp16> output.log 2>&1 &
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
#3 个epoch 有些过拟合,采用1个epoch CUDA_VISIBLE_DEVICES=0,1 nohup llamafactory-cli train \ --stage sft \ --do_train \ --model_name_or_path /home/Meta-Llama-3-8B-Instruct \ --dataset alpaca_gpt4_zh_local,Llama3-Chinese-dataset_local,COIG-CQIA_local,alpaca_gpt4_en_local \ --dataset_dir ./data \ --template llama3 \ --finetuning_type lora \ --output_dir ./saves/LLaMA3-8B/lora/sft_1 \ --overwrite_cache \ --overwrite_output_dir \ --cutoff_len 1024 \ --preprocessing_num_workers 16 \ --per_device_train_batch_size 4 \ --per_device_eval_batch_size 2 \ --gradient_accumulation_steps 8 \ --lr_scheduler_type cosine \ --logging_steps 50 \ --warmup_steps 20 \ --save_steps 100 \ --eval_steps 50 \ --evaluation_strategy steps \ --load_best_model_at_end \ --learning_rate 5e-5 \ --num_train_epochs 1.0 \ --val_size 0.1 \ --plot_loss \ --fp16> output.log 2>&1 &
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 合并
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export \
--model_name_or_path /home/Meta-Llama-3-8B-Instruct \
--adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \
--template llama3 \
--finetuning_type lora \
--export_dir megred-model-path-1 \
--export_size 2 \
--export_device cpu \
--export_legacy_format False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 测试
微调后:
CUDA_VISIBLE_DEVICES=0 llamafactory-cli chat \
--model_name_or_path megred-model-path \
--template llama3
- 1
- 2
- 3



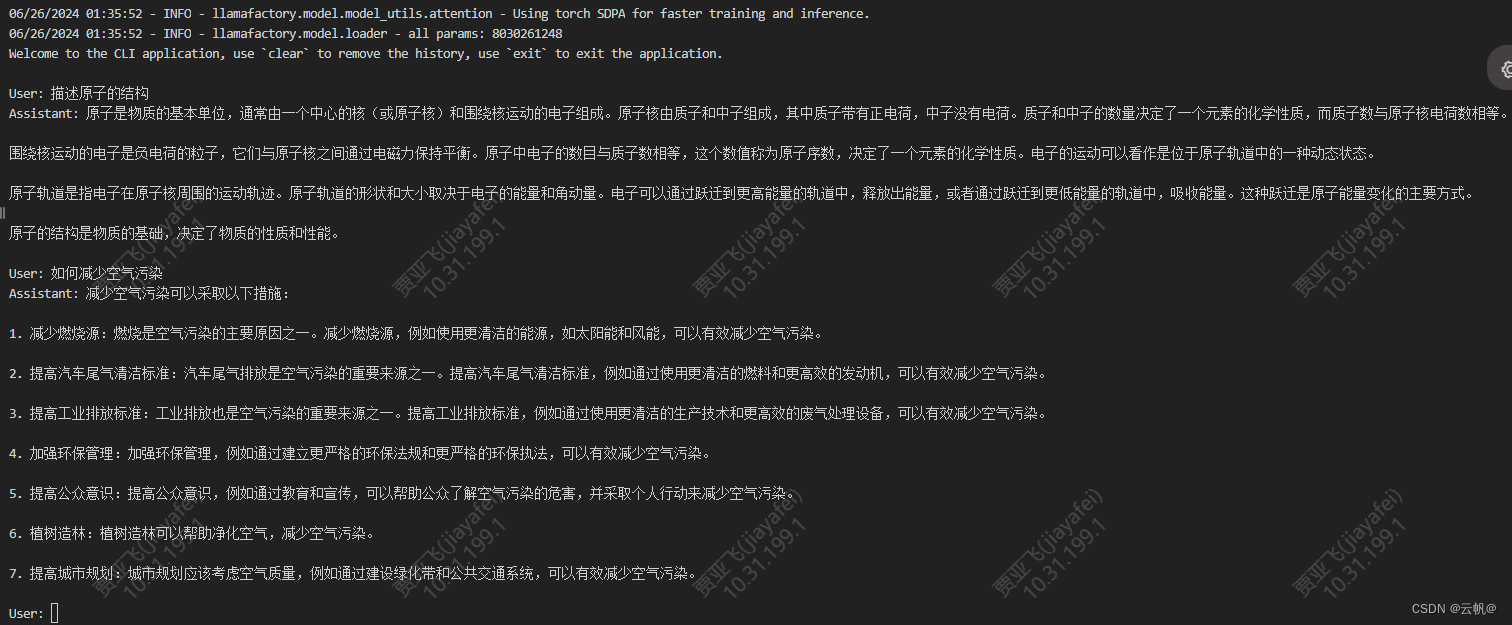
微调前:

CUDA_VISIBLE_DEVICES=0 llamafactory-cli eval \
--model_name_or_path megred-model-path \
--template llama3 \
--task mmlu \
--split validation \
--lang en \
--n_shot 5 \
--batch_size 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

7. 人工审核对比

声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

