
- 1风电控制器,包含DSP控制板,主板的原理图和PCB的源文件_风力发电机 单片机接线图
- 2nuxt.js之SSR服务端内存泄漏导致CPU过高的解决过程_nuxt 会导致cpu占用高
- 3[Unity3D热更框架] LuaMVC之XLua_xlua框架mvc
- 4js拦截所有请求_js 拦截请求
- 5C++学习——指针篇_c++指针全解
- 6【21天算法挑战赛】查找算法——二分查找_【问题描述】依照二分查找,在数据类型为int的递增集合中查找比较二次就成功的元素
- 7高通及安卓及QNX常用缩写_qnx pbl
- 8SD(Stable Diffusion) 简易教程来啦!_电脑sd
- 9《数据库》表整行数据去重LISTAGG函数_listagg函数的用法去重
- 10【vue3|第1期】路由router.push的使用以及问题分析与处理
走近智算 | 开源大模型Llama 3.1技术分析_llama 3.1 数学
赞
踩
大家好,欢迎来到《走近智算》,今天和大家分享Meta近期发布的参数量最大的开源大模型Llama 3.1。

本分享包括三部分内容,第一部分Llama 3.1的介绍;第二部分是从数据、模型结构、预训练和后训练的角度对模型的技术分析;第三部分是对大模型产业发展的思考。
首先我们通过官网来了解Llama 3.1模型的情况。Llama 3.1提供了8B的轻量级模型、70B的高成效比模型和405B的旗舰基础模型 3种参数规模的大模型,3个大模型都已经开放给用户下载。

在模型关键能力方面,展示了包括模型使用工具、多语言翻译、复杂场景推理及代码生成等功能。模型能根据用户Prompt,调用三方库处理CSV表格数据,生成图表;根据图文内容,把故事内容从英文翻译为西班牙语;根据用户的描述和需求,分析用户旅游时带的衣物是否足够;根据用户需求描述,生成迷宫程序代码等。
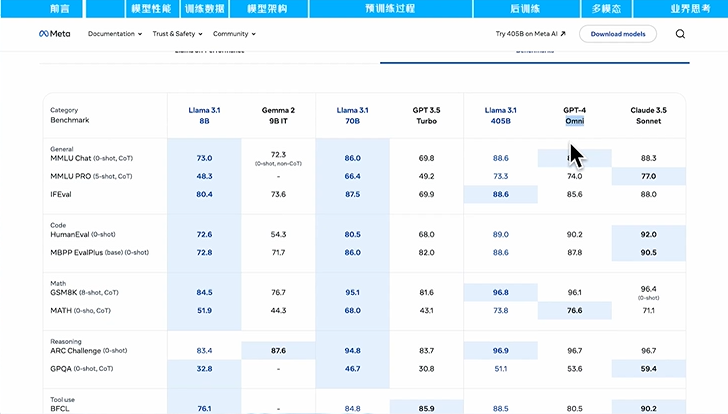
从官网提供的评测来看,各种Benchmark的得分都比较不错,尤其是70B模型,各方面的得分都保持了领先。不过这类评测,厂家在选择评测条件和基准时,会挑选对自家模型有利的条件,实际效果还有待市场的检验。

关于Llama 3.1模型的情况,我们这里做一个总结。Llama 3.1提供了8B、70B和405B 3种规格的版本,其中405B为目前最大的开源模型,其在部分评测场景得分超过了GPT4模型。模型的微调版本,使用SFT和DPO来对齐可用性和安全偏好。支持128K Token长上下文,能满足大部分复杂任务场景。支持多语言输入和输出,增加了模型通用性和适用范围。模型在解决复杂数学问题和内容生成方面的能力表现突出。

接下来,结合官网和论文,我们从数据、模型结构、预训练和后训练的角度对模型进行技术解读。

模型预训练使用了超过15万亿Token的数据,其中50%为常识知识、25%为数学和推理、17%为代码数据和任务、8%为多语言数据。同时支持英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语8种语言。模型微调使用了公开可用的指令数据集和超过2500万个高质量的合成数据。

Llama 3.1模型整体结构使用了传统的Transformer架构,但对部分算法进行了改造。归一化层使用了均方根归一化算法,简化了Layer Norm并降低了计算时间;改进了多头注意力机制,使用分组查询注意力GQA,在效率和模型表达能力间进行平衡;位置编码使用了旋转式位置编码RoPE,综合了绝对位置编码和相对位置编码的优点;使用SwiGLU作为前馈神经网络的激活函数,结合了Swish和GLU两种激活函数的特点。

介绍完了模型结构,我们再来梳理下预训练过程,Llama 3.1预训练过程分为4个步骤。
第1步是常规的预训练,通过大规模数据训练模型的生成能力。
第2步是在预训练的后期,采用长文本数据对长序列进行训练,从8K分6阶段逐渐扩展到128K,支持最大128K Token上下文窗口。
第3步是退火,预训练最后4000万个Token,线性地将学习率退火至0,同时保持上下文长度为128K,调整数据混合配比,增加数学、代码、逻辑等高质量训练数据。
最后一步是将退火期间得到的若干个模型权重的Checkpoint求平均值,得到最终的预训练模型。
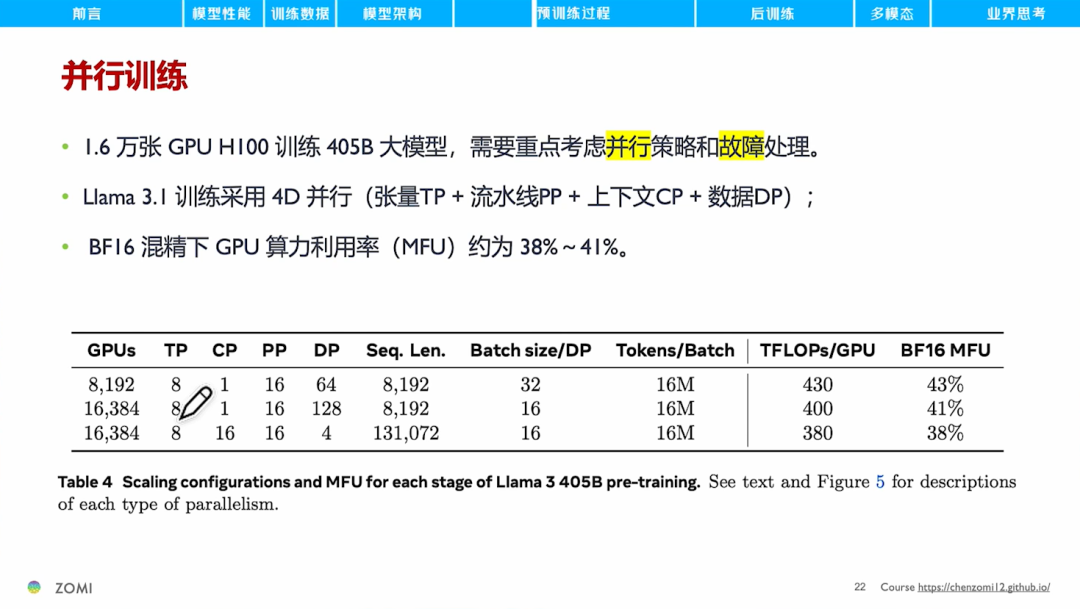
接着再来看下模型的训练集群和并行训练的情况。Meta训练Llama 3.1 405B模型使用了1.6万张H100,并重点考虑并行策略和故障处理。训练过程综合使用了张量并行、流水线并行、上下文并行和数据并行4种并行模式。BF16混合精度下,GPU算力利用率约为38%至41%。
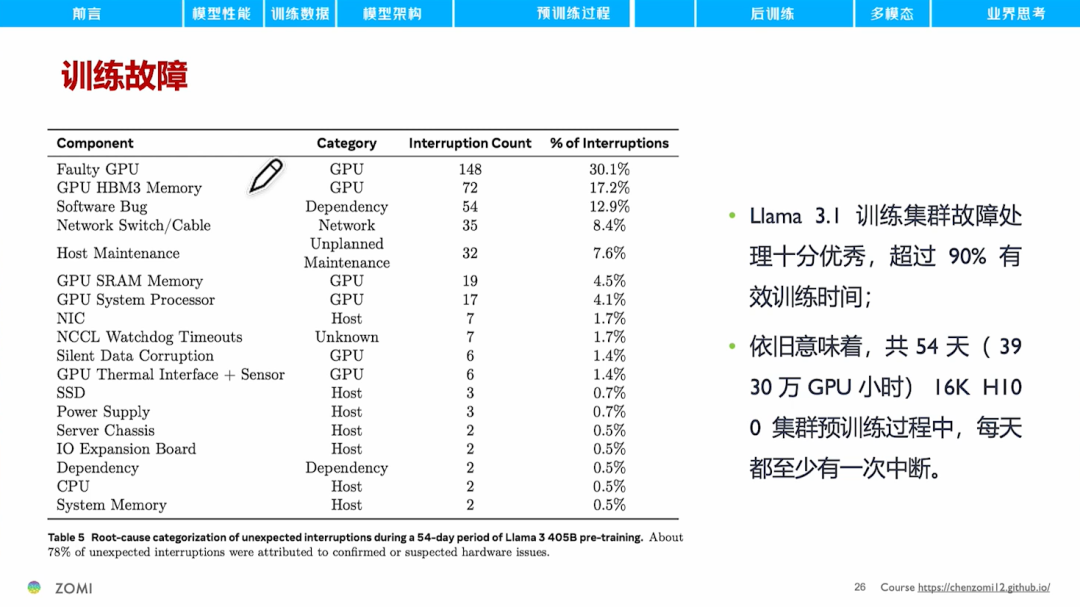
训练故障率方面,Llama 3.1训练集群的故障处理十分优秀,在54天的训练时间里,有超过90%的有效训练时间。整个训练共发生419次意外中断故障,其中与GPU硬件相关的故障约占78%。虽然有这么多故障,但得益于完善的自动化运维能力,大部分的故障都被系统自动处理了,整个训练过程中,只有3次故障需要人工介入。
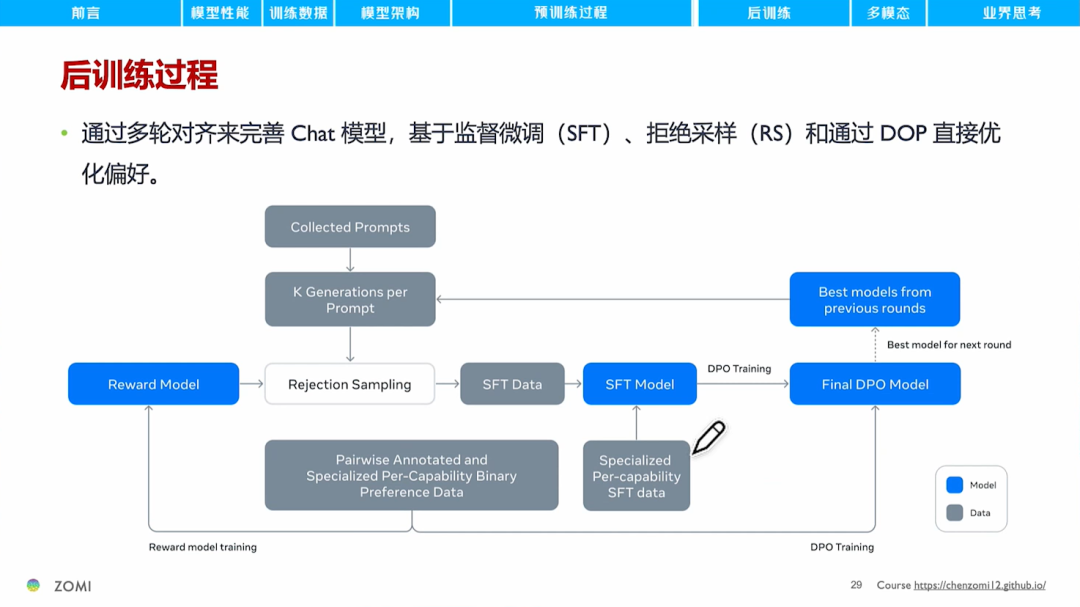
后训练阶段,主要通过监督微调SFT、拒绝采样RS和直接偏好优化DPO来完善对话模型。
监督微调首先通过人工标注的数据训练奖励模型,用奖励模型来评价模型“问答对”数据的质量。
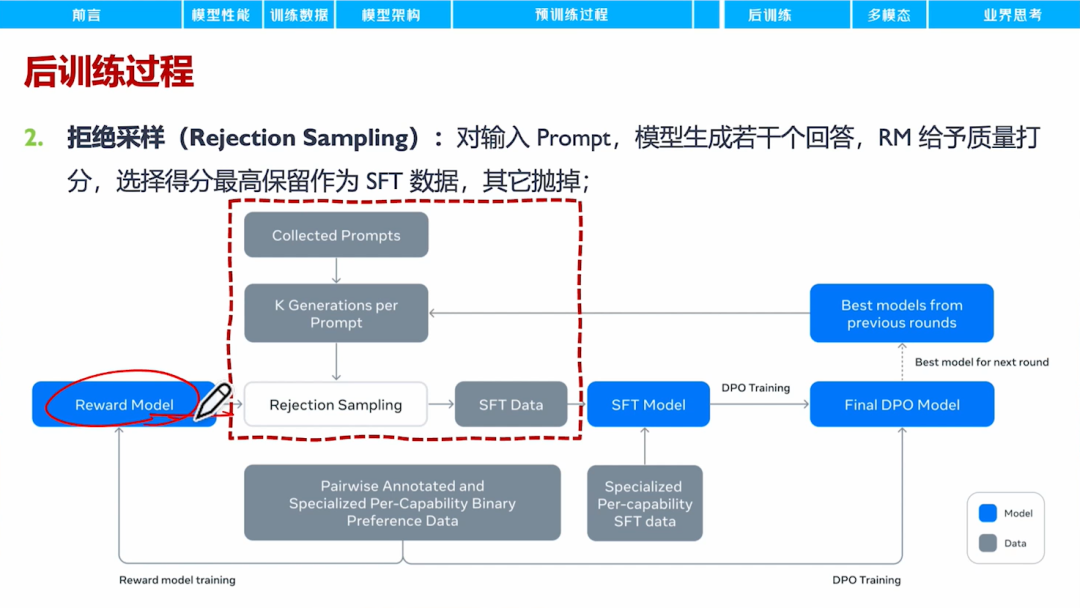
拒绝采样RS,是指对模型生成的问答对,使用奖励模型进行打分,选择得分高的结果作为SFT数据。
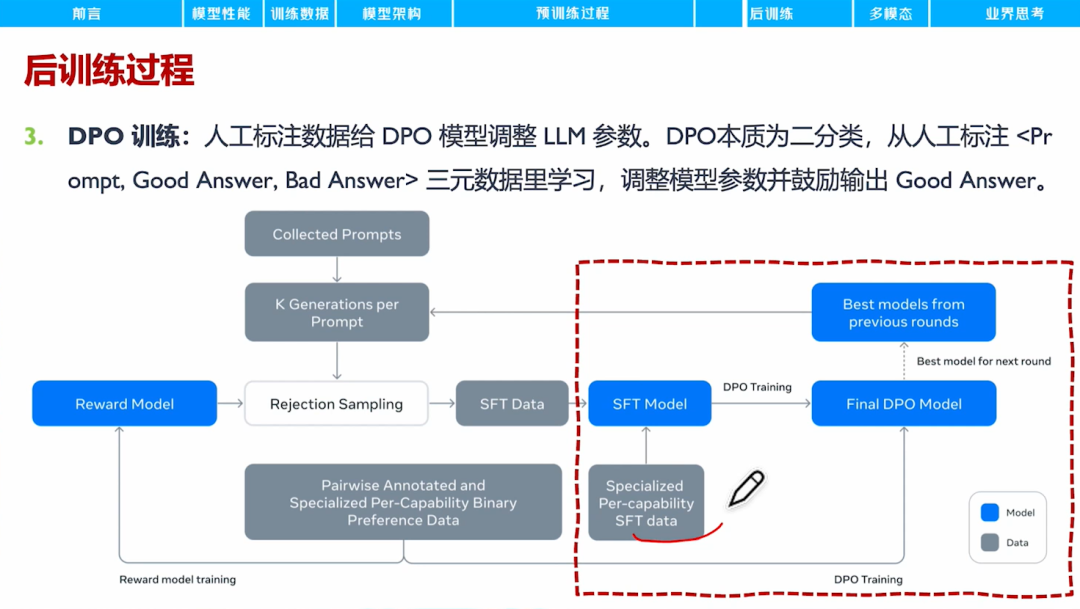
直接偏好优化DPO,是指让模型学习人工标注的Prompt、Good Answer、Bad Answer三元组数据,调整模型参数以鼓励模型输出Good Answer。
最后,我们来聊聊对大模型产业发展的思考。

第一个是对模型结构的思考。大模型是选择Transformer稠密模型还是MOE稀疏模型更好呢?其实它们各有优缺点,MOE结构的训练和推理成本更低,但是训练不够稳定,推理需要大内存存储模型参数;而Transformer结构在用户量大、请求多时,推理成本更高。这里需要注意的是,模型的效果和使用哪种结构没有直接关系。

第二个是数据枯竭的问题。当前大模型训练将很快用尽互联网上公开的可用数据,以后怎么办?其实不用担心,当前合成数据已经进入实用阶段,尤其是后训练阶段,合成数据已经成为主要训练数据,Llama 3.1和Gemma2也证明了SFT阶段,合成数据的质量并不比人工标注数据差。

最后一个是大模型能力上限的问题,随着Llama 3.1成为最大的开源大模型,未来模型效果还能继续提升吗,上限在哪里?我们认为Scaling Law还没有达到上限,通过扩大模型规模和增加数据规模,以及提高训练数据的质量和优化数据配比,未来模型的能力还能继续提升。
零基础如何学习大模型 AI
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型实际应用案例分享
①智能客服:某科技公司员工在学习了大模型课程后,成功开发了一套基于自然语言处理的大模型智能客服系统。该系统不仅提高了客户服务效率,还显著降低了人工成本。
②医疗影像分析:一位医学研究人员通过学习大模型课程,掌握了深度学习技术在医疗影像分析中的应用。他开发的算法能够准确识别肿瘤等病变,为医生提供了有力的诊断辅助。
③金融风险管理:一位金融分析师利用大模型课程中学到的知识,开发了一套信用评分模型。该模型帮助银行更准确地评估贷款申请者的信用风险,降低了不良贷款率。
④智能推荐系统:一位电商平台的工程师在学习大模型课程后,优化了平台的商品推荐算法。新算法提高了用户满意度和购买转化率,为公司带来了显著的增长。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段

二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。

三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。


如果二维码失效,可以点击下方链接,一样的哦
【CSDN大礼包】最新AI大模型资源包,这里全都有!无偿分享!!!
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

