
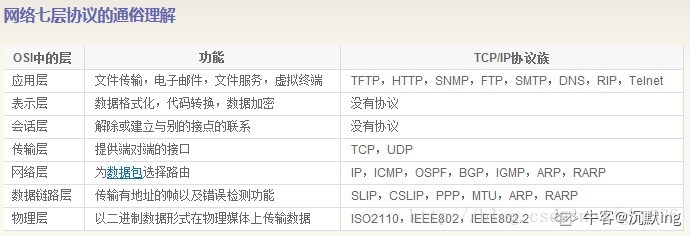
- 1自定义注解对bean中属性的注入和ConvertUtils动态转化String_javabean传输redis字段转string类型的注解
- 2目标检测-yolov50-火灾识别可视化_yolov火灾
- 3How Twitter Uses Redis To Scale - 105TB RAM, 39MM QPS, 10,000+ Instances
- 4React-Native Android 修改包名_react native android修改包名
- 5AI一键生成短视频_ai生成视频 开源
- 6kafka系列(09):SpringBoot 中使用@KafkaListener详解与使用_springboot kafkalistener
- 7Linux下删除文件命令_linux删除文件命令
- 8FL Studio2024破解版注册机及使用教程_fl studio注册機
- 922_OpenCV中求解方程的一系列cv::solve...()函数
- 10消息认证码--数字签名--证书_ipv4消息认证码
Java初级面试题
赞
踩
1、请你谈谈大O符号(big-O notation)并给出不同数据结构的例子
大O符号描述了当数据结构里面的元素增加的时候,算法的规模或者是性能在最坏的场景下有多么好。 大O符号也可用来描述其他的行为,比如:内存消耗。因为集合类实际上是数据结构,我们一般使用大O符号基于时间,内存和性能来选择最好的实现。大O符号可以对大量数据的性能给出一个很好的说明。
同时,大O符号表示一个程序运行时所需要的渐进时间复杂度上界。
其函数表示是:
对于函数f(n),g(n),如果存在一个常数c,使得f(n)<=c*g(n),则f(n)=O(g(n));
大O描述当数据结构中的元素增加时,算法的规模和性能在最坏情景下有多好。
大O还可以描述其它行为,比如内存消耗。因为集合类实际上是数据结构,因此我们一般使用大O符号基于时间,内存,性能选择最好的实现。大O符号可以对大量数据性能给予一个很好的说明。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2、请你讲讲数组(Array)和列表(ArrayList)的区别?什么时候应该使用Array而不是ArrayList?
Array和ArrayList的不同点:
Array可以包含基本类型和对象类型,ArrayList只能包含对象类型。
Array大小是固定的,ArrayList的大小是动态变化的。
ArrayList提供了更多的方法和特性,比如:addAll(),removeAll(),iterator()等等。
对于基本类型数据,集合使用自动装箱来减少编码工作量。但是,当处理固定大小的基本数据类型的时候,这种方式相对比较慢。
- 1
- 2
- 3
- 4
- 5
3、请你解释什么是值传递和引用传递?
值传递是对基本型变量而言的,传递的是该变量的一个副本,改变副本不影响原变量.
引用传递一般是对于对象型变量而言的,传递的是该对象地址的一个副本, 并不是原对象本身。所以对引用对象进行操作会同时改变原对象.
- 1
- 2
4、请你解释为什么会出现4.0-3.6=0.40000001这种现象
考察点:计算机基础
参考回答:
原因简单来说是这样:2进制的小数无法精确的表达10进制小数,计算机在计算10进制小数的过程中要先转换为2进制进行计算,这个过程中出现了误差。
出现0.40000001的情况可以使用BigDecimal类解决,其实浮点数基本上都不精确,BigDecimal使用String来解决的
- 1
- 2
- 3
- 4
- 5
5、请你讲讲一个十进制的数在内存中是怎么存的?
补码的形式
- 1
6、请你说说Lamda表达式的优缺点
优点:
1. 简洁。
2. 非常容易并行计算。
3. 可能代表未来的编程趋势。
缺点:
4. 若不用并行计算,很多时候计算速度没有比传统的 for 循环快。(并行计算有时需要预热才显示出效率优势)
5. 不容易调试。
6. 若其他程序员没有学过 lambda 表达式,代码不容易让其他语言的程序员看懂。
菜鸟教程有Lambda表达式的知识点,就是把匿名内部类简写了,lambda表达式要通过代码来看,纯文字很难表示清楚
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
7、你知道java8的新特性吗,请简单介绍一下
1、Lambda 表达式 − Lambda允许把函数作为一个方法的参数(函数作为参数传递进方法中。
2、方法引用− 方法引用提供了非常有用的语法,可以直接引用已有Java类或对象(实例)的方法或构造器。与lambda联合使用,方法引用可以使语言的构造更紧凑简洁,减少冗余代码。
3、默认方法− 默认方法就是一个在接口里面有了一个实现的方法。
4、新工具− 新的编译工具,如:Nashorn引擎 jjs、 类依赖分析器jdeps。
5、Stream API −新添加的Stream API(java.util.stream) 把真正的函数式编程风格引入到Java中。
6、Date Time API − 加强对日期与时间的处理。
7、Optional 类 − Optional 类已经成为 Java 8 类库的一部分,用来解决空指针异常。
8、Nashorn, JavaScript 引擎 − Java 8提供了一个新的Nashorn javascript引擎,它允许我们在JVM上运行特定的javascript应用。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
8、请你说明符号“==”比较的是什么
“==”对比两个对象基于内存引用,如果两个对象的引用完全相同(指向同一个对象)时,“==”操作将返回true,
否则返回false。“==”如果两边是基本类型,就是比较数值是否相等。
- 1
- 2
9、请你解释Object若不重写hashCode()的话,hashCode()如何计算出来的
考点:基础
参考回答:
Object 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法直接返回对象的 内存地址。
- 1
- 2
- 3
- 4
10、请你解释为什么重写equals还要重写hashcode
HashMap中,如果要比较key是否相等,要同时使用这两个函数!因为自定义的类的hashcode()方法继承于Object类,其hashcode码为默认的内存地址,这样即便有相同含义的两个对象,比较也是不相等的。HashMap中的比较key是这样的,先求出key的hashcode(),比较其值是否相等,若相等再比较equals(),若相等则认为他们是相等的。若equals()不相等则认为他们不相等。如果只重写hashcode()不重写equals()方法,当比较equals()时只是看他们是否为同一对象(即进行内存地址的比较),所以必定要两个方法一起重写。HashMap用来判断key是否相等的方法,其实是调用了HashSet判断加入元素 是否相等。重载hashCode()是为了对同一个key,能得到相同的Hash Code,这样HashMap就可以定位到我们指定的key上。重载equals()是为了向HashMap表明当前对象和key上所保存的对象是相等的,这样我们才真正地获得了这个key所对应的这个键值对。
- 1
11、请你介绍一下map的分类和常见的情况
java为数据结构中的映射定义了一个接口java.util.Map;它有四个实现类,分别是HashMap Hashtable LinkedHashMap 和TreeMap. Map主要用于存储健值对,根据键得到值,因此不允许键重复(重复了覆盖了),但允许值重复。 Hashmap 是一个最常用的Map,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随机的。 HashMap最多只允许一条记录的键为Null;允许多条记录的值为 Null;HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。如果需要同步,可以用 Collections的synchronizedMap方法使HashMap具有同步的能力,或者使用ConcurrentHashMap。 Hashtable与 HashMap类似,它继承自Dictionary类,不同的是:它不允许记录的键或者值为空;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了 Hashtable在写入时会比较慢。 LinkedHashMap 是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.也可以在构造时用带参数,按照应用次数排序。在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会比 LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。 TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。 一般情况下,我们用的最多的是HashMap,在Map 中插入、删除和定位元素,HashMap 是最好的选择。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。如果需要输出的顺序和输入的相同,那么用LinkedHashMap 可以实现,它还可以按读取顺序来排列. HashMap是一个最常用的Map,它根据键的hashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。HashMap最多只允许一条记录的键为NULL,允许多条记录的值为NULL。 HashMap不支持线程同步,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致性。如果需要同步,可以用Collections的synchronizedMap方法使HashMap具有同步的能力。 Hashtable与HashMap类似,不同的是:它不允许记录的键或者值为空;它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtable在写入时会比较慢。 LinkedHashMap保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的。 在遍历的时候会比HashMap慢TreeMap能够把它保存的记录根据键排序,默认是按升序排序,也可以指定排序的比较器。当用Iterator遍历TreeMap时,得到的记录是排过序的。

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
12、请你谈谈关于Synchronized和lock
synchronized是Java的关键字,当它用来修饰一个方法或者一个代码块的时候,能够保证在同一时刻最多只有一个线程执行该段代码。JDK1.5以后引入了自旋锁、锁粗化、轻量级锁,偏向锁来有优化关键字的性能。
Lock是一个接口,而synchronized是Java中的关键字,synchronized是内置的语言实现;synchronized在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生;而Lock在发生异常时,如果没有主动通过unLock()去释放锁,则很可能造成死锁现象,因此使用Lock时需要在finally块中释放锁;Lock可以让等待锁的线程响应中断,而synchronized却不行,使用synchronized时,等待的线程会一直等待下去,不能够响应中断;通过Lock可以知道有没有成功获取锁,而synchronized却无法办到。
13、请你介绍一下volatile
volatile关键字是用来保证有序性和可见性的。这跟Java内存模型有关。比如我们所写的代码,不一定是按照我们自己书写的顺序来执行的,编译器会做重排序,CPU也会做重排序的,这样的重排序是为了减少流水线的阻塞的,引起流水阻塞,比如数据相关性,提高CPU的执行效率。需要有一定的顺序和规则来保证,不然程序员自己写的代码都不知带对不对了,所以有happens-before规则,其中有条就是volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作;有序性实现的是通过插入内存屏障来保证的。可见性:首先Java内存模型分为,主内存,工作内存。比如线程A从主内存把变量从主内存读到了自己的工作内存中,做了加1的操作,但是此时没有将i的最新值刷新会主内存中,线程B此时读到的还是i的旧值。加了volatile关键字的代码生成的汇编代码发现,会多出一个lock前缀指令。Lock指令对Intel平台的CPU,早期是锁总线,这样代价太高了,后面提出了缓存一致性协议,MESI,来保证了多核之间数据不一致性问题。
14、请你介绍一下Syncronized锁,如果用这个关键字修饰一个静态方法,锁住了什么?如果修饰成员方法,锁住了什么
synchronized修饰静态方法以及同步代码块的synchronized (类.class)用法锁的是类,线程想要执行对应同步代码,需要获得类锁。
synchronized修饰成员方法,线程获取的是当前调用该方法的对象实例的对象锁。
15、请解释Java中的概念,什么是构造函数?什么是构造函数重载?什么是复制构造函数?
当新对象被创建的时候,构造函数会被调用。每一个类都有构造函数。在程序员没有给类提供构造函数的情况下,Java编译器会为这个类创建一个默认的构造函数。
Java构造函数重载和方法重载很相似。可以为一个类创建多个构造函数。每一个构造函数必须有它自己唯一的参数列表。
Java不支持像C++中那样的复制构造函数,这个不同点是因为如果你不自己写构造函数的情况下,Java不会创建默认的复制构造函数。
16、请说明Query接口的list方法和iterate方法有什么区别?
① list()方法无法利用一级缓存和二级缓存(对缓存只写不读),它只能在开启查询缓存的前提下使用查询缓存;iterate()方法可以充分利用缓存,如果目标数据只读或者读取频繁,使用iterate()方法可以减少性能开销。
② list()方法不会引起N+1查询问题,而iterate()方法可能引起N+1查询问题
list()和iterate()区别
1、返回的类型不同,list()返回List,iterate()返回Iterator
2、获取方式不同,list会一次性将数据库中的信息全部查询出,iterate会先把所有数据的id查询出来,然后真正要遍历某个对象的时候先到缓存中查找,如果找不到,以id为条件再发送一条sql到数据库,这样如果缓存中没有数据,则查询数据库的次数为n+1
3、iterate会查询2级缓存,list只会查询一级缓存
4、list中返回的List中每个对象都是原本的对象,iterate中返回的对象是***对象。(debug可以发现)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
17、请你谈一下面向对象的"六原则一法则"
- 单一职责原则:一个类只做它该做的事情。(单一职责原则想表达的就是"高内聚",写代码最终极的原则只有六个字"高内聚、低耦合",所谓的高内聚就是一个代码模块只完成一项功能,在面向对象中,如果只让一个类完成它该做的事,而不涉及与它无关的领域就是践行了高内聚的原则,这个类就只有单一职责。另一个是模块化,好的自行车是组装车,从减震叉、刹车到变速器,所有的部件都是可以拆卸和重新组装的,好的乒乓球拍也不是成品拍,一定是底板和胶皮可以拆分和自行组装的,一个好的软件系统,它里面的每个功能模块也应该是可以轻易的拿到其他系统中使用的,这样才能实现软件复用的目标。)
- 开闭原则:软件实体应当对扩展开放,对修改关闭。(在理想的状态下,当我们需要为一个软件系统增加新功能时,只需要从原来的系统派生出一些新类就可以,不需要修改原来的任何一行代码。要做到开闭有两个要点:①抽象是关键,一个系统中如果没有抽象类或接口系统就没有扩展点;②封装可变性,将系统中的各种可变因素封装到一个继承结构中,如果多个可变因素混杂在一起,系统将变得复杂而换乱,如果不清楚如何封装可变性,可以参考《设计模式精解》一书中对桥梁模式的讲解的章节。)- 依赖倒转原则:面向接口编程。(该原则说得直白和具体一些就是声明方法的参数类型、方法的返回类型、变量的引用类型时,尽可能使用抽象类型而不用具体类型,因为抽象类型可以被它的任何一个子类型所替代,请参考下面的里氏替换原则。)
- 里氏替换原则:任何时候都可以用子类型替换掉父类型。(关于里氏替换原则的描述,Barbara Liskov女士的描述比这个要复杂得多,但简单的说就是能用父类型的地方就一定能使用子类型。里氏替换原则可以检查继承关系是否合理,如果一个继承关系违背了里氏替换原则,那么这个继承关系一定是错误的,需要对代码进行重构。例如让猫继承狗,或者狗继承猫,又或者让正方形继承长方形都是错误的继承关系,因为你很容易找到违反里氏替换原则的场景。需要注意的是:子类一定是增加父类的能力而不是减少父类的能力,因为子类比父类的能力更多,把能力多的对象当成能力少的对象来用当然没有任何问题。)
- 接口隔离原则:接口要小而专,绝不能大而全。(臃肿的接口是对接口的污染,既然接口表示能力,那么一个接口只应该描述一种能力,接口也应该是高度内聚的。例如,琴棋书画就应该分别设计为四个接口,而不应设计成一个接口中的四个方法,因为如果设计成一个接口中的四个方法,那么这个接口很难用,毕竟琴棋书画四样都精通的人还是少数,而如果设计成四个接口,会几项就实现几个接口,这样的话每个接口被复用的可能性是很高的。Java中的接口代表能力、代表约定、代表角色,能否正确的使用接口一定是编程水平高低的重要标识。)
- 合成聚合复用原则:优先使用聚合或合成关系复用代码。(通过继承来复用代码是面向对象程序设计中被滥用得最多的东西,因为所有的教科书都无一例外的对继承进行了鼓吹从而误导了初学者,类与类之间简单的说有三种关系,Is-A关系、Has-A关系、Use-A关系,分别代表继承、关联和依赖。其中,关联关系根据其关联的强度又可以进一步划分为关联、聚合和合成,但说白了都是Has-A关系,合成聚合复用原则想表达的是优先考虑Has-A关系而不是Is-A关系复用代码,原因嘛可以自己从百度上找到一万个理由,需要说明的是,即使在Java的API中也有不少滥用继承的例子,例如Properties类继承了Hashtable类,Stack类继承了Vector类,这些继承明显就是错误的,更好的做法是在Properties类中放置一个Hashtable类型的成员并且将其键和值都设置为字符串来存储数据,而Stack类的设计也应该是在Stack类中放一个Vector对象来存储数据。记住:任何时候都不要继承工具类,工具是可以拥有并可以使用的,而不是拿来继承的。)
- 迪米特法则:迪米特法则又叫最少知识原则,一个对象应当对其他对象有尽可能少的了解。再复杂的系统都可以为用户提供一个简单的门面,Java Web开发中作为前端控制器的Servlet或Filter不就是一个门面吗,浏览器对服务器的运作方式一无所知,但是通过前端控制器就能够根据你的请求得到相应的服务。调停者模式也可以举一个简单的例子来说明,例如一台计算机,CPU、内存、硬盘、显卡、声卡各种设备需要相互配合才能很好的工作,但是如果这些东西都直接连接到一起,计算机的布线将异常复杂,在这种情况下,主板作为一个调停者的身份出现,它将各个设备连接在一起而不需要每个设备之间直接交换数据,这样就减小了系统的耦合度和复杂度。
18 、请说明如何通过反射获取和设置对象私有字段的值?
可以通过类对象的getDeclaredField()方法字段(Field)对象,然后再通过字段对象的setAccessible(true)将其设置为可以访问,接下来就可以通过get/set方法来获取/设置字段的值了。下面的代码实现了一个反射的工具类,其中的两个静态方法分别用于获取和设置私有字段的值,字段可以是基本类型也可以是对象类型且支持多级对象操作,例如ReflectionUtil.get(dog, “owner.car.engine.id”);可以获得dog对象的主人的汽车的引擎的ID号。
import java.lang.reflect.Method;
class MethodInvokeTest {
public static void main(String[] args) throws Exception {
String str = "hello";
Method m = str.getClass().getMethod("toUpperCase");
System.out.println(m.invoke(str)); // HELLO
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
19、请判断,两个对象值相同(x.equals(y) == true),但却可有不同的hash code,该说法是否正确,为什么?
不对,如果两个对象x和y满足x.equals(y) == true,它们的哈希码(hash code)应当相同。Java对于eqauls方法和hashCode方法是这样规定的:
- 1、如果两个对象相同(equals方法返回true),那么它们的hashCode值一定要相同;
- 2、如果两个对象的hashCode相同,它们并不一定相同。当然,你未必要按照要求去做,但是如果你违背了上述原则就会发现在使用容器时,相同的对象可以出现在Set集合中,同时增加新元素的效率会大大下降(对于使用哈希存储的系统,如果哈希码频繁的冲突将会造成存取性能急剧下降)。
两个对象的HashCode相同,并不一定表示两个对象就相同,即equals()不一定为true,只能说明这两个对象在一个散列存储结构中。
20、请说明内部类可以引用他包含类的成员吗,如果可以,有没有什么限制吗?
一个内部类对象可以访问创建它的外部类对象的内容,内部类如果不是static的,那么它可以访问创建它的外部类对象的所有属性内部类如果是sattic的,即为nested class,那么它只可以访问创建它的外部类对象的所有static属性一般普通类只有public或package的访问修饰,而内部类可以实现static,protected,private等访问修饰。当从外部类继承的时候,内部类是不会被覆盖的,它们是完全独立的实体,每个都在自己的命名空间内,如果从内部类中明确地继承,就可以覆盖原来内部类的方法。
21、请判断当一个对象被当作参数传递给一个方法后,此方法可改变这个对象的属性,并可返回变化后的结果,那么这里到底是值传递还是引用传递?
是值传递。Java 编程语言只有值传递参数。当一个对象实例作为一个参数被传递到方法中时,参数的值就是对该对象的引用。对象的内容可以在被调用的方法中改变,但对象的引用是永远不会改变的。
22、请你说说Static Nested Class静态内部类 和 Inner Class内部类的不同
Static Nested Class静态内部类可以在不创建实例的条件下直接创建,因为它只访问静态方法和成员,它和类直接绑定,并且不能访问任何非静态类型的方法和成员变量。但是Inner class内部类是和实例绑定的,他可以访问实例的成员变量和方法,所以在创建他之前必须先创建一个实例,然后通过实例创建它才行。
23、请你谈谈如何通过反射创建对象?
- 方法1:通过类对象调用newInstance()方法,例如:String.class.newInstance()
- 方法2:通过类对象的getConstructor()或getDeclaredConstructor()方法获得构造器(Constructor)对象并调用其newInstance()方法创建对象,例如:String.class.getConstructor(String.class).newInstance(“Hello”);
24、请你说明是否可以在static环境中访问非static变量?
static变量在Java中是属于类的,它在所有的实例中的值是一样的。当类被Java虚拟机载入的时候,会对static变量进行初始化。如果你的代码尝试不用实例来访问非static的变量,编译器会报错,因为这些变量还没有被创建出来,还没有跟任何实例关联上。
25、请解释一下extends 和super 泛型限定符
1)泛型中上界和下界的定义
上界<? extend Fruit>
下界<? super Apple>
- 1
- 2
- 3
2)上界和下界的特点
上界的list只能get,不能add(确切地说不能add出除null之外的对象,包括Object)
下界的list只能add,不能get
- 1
- 2
- 3
3)示例代码
import java.util.ArrayList; import java.util.List; class Fruit {} class Apple extends Fruit {} class Jonathan extends Apple {} class Orange extends Fruit {} public class CovariantArrays { public static void main(String[] args) { //上界 List<? extends Fruit> flistTop = new ArrayList<Apple>(); flistTop.add(null); //add Fruit对象会报错 //flist.add(new Fruit()); Fruit fruit1 = flistTop.get(0); //下界 List<? super Apple> flistBottem = new ArrayList<Apple>(); flistBottem.add(new Apple()); flistBottem.add(new Jonathan()); //get Apple对象会报错 //Apple apple = flistBottem.get(0); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
4)上界<? extend Fruit> ,表示所有继承Fruit的子类,但是具体是哪个子类,无法确定,所以调用add的时候,要add什么类型,谁也不知道。但是get的时候,不管是什么子类,不管追溯多少辈,肯定有个父类是Fruit,所以,我都可以用最大的父类Fruit接着,也就是把所有的子类向上转型为Fruit。
下界<? super Apple>,表示Apple的所有父类,包括Fruit,一直可以追溯到老祖宗Object 。那么当我add的时候,我不能add Apple的父类,因为不能确定List里面存放的到底是哪个父类。但是我可以add Apple及其子类。因为不管我的子类是什么类型,它都可以向上转型为Apple及其所有的父类甚至转型为Object 。但是当我get的时候,Apple的父类这么多,我用什么接着呢,除了Object,其他的都接不住。
所以,归根结底可以用一句话表示,那就是编译器可以支持向上转型,但不支持向下转型。具体来讲,我可以把Apple对象赋值给Fruit的引用,但是如果把Fruit对象赋值给Apple的引用就必须得用cast。
限定通配符总是包括自己
上界类型通配符:add方法受限
下界类型通配符:get方法受限
- 1
- 2
如果你想从一个数据类型里获取数据
使用 ? extends 通配符
- 1
如果你想把对象写入一个数据结构里
使用 ? super 通配符
- 1
如果你既想存,又想取
那就别用通配符
- 1
不能同时声明泛型通配符上界和下界
上不存下不取
- 1
<? extend A>表明这个集合中存的都是A或者A的子类,所以用A或者Object是都可以接到的,但是add的话,万一add传了一个A的父类进去,就破坏了上界的目的,里面的数据类型也不符合预期了,所以干脆编译阶段就不能传任何类型进去。
<? super A>表明这个集合中存的都是A或者A的父类,没有规定一个最大的父类,所以只能用Obejct可以接到(按照上不存下不取的目的,其实这里也不应该取,但是取不会破坏数据,存会,所以这里没做限制,也是因为java中有个共同父类存在)。至于add,因为里面存的都是>=A的类,所以可以add任何<=A的类进去,add一个非A或者非A子类的类进去,还是会报错(可以理解为对add比get要严格)。
26、请说明静态变量存在什么位置?
方法区
- 1
27、请说明String是否能能继承?
不能,char数组用final修饰的。
- 1
28、请列举你所知道的Object类的方法并简要说明。
Object()默认构造方法。clone() 创建并返回此对象的一个副本。equals(Object obj) 指示某个其他对象是否与此对象“相等”。finalize()当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法。getClass()返回一个对象的运行时类。hashCode()返回该对象的哈希码值。 notify()唤醒在此对象监视器上等待的单个线程。 notifyAll()唤醒在此对象监视器上等待的所有线程。toString()返回该对象的字符串表示。wait()导致当前的线程等待,直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法。wait(long timeout)导致当前的线程等待,直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者超过指定的时间量。wait(long timeout, int nanos) 导致当前的线程等待,直到其他线程调用此对象的 notify() 方法或 notifyAll() 方法,或者其他某个线程中断当前线程,或者已超过某个实际时间量。
29、请说明类和对象的区别
- 1.类是对某一类事物的描述,是抽象的;而对象是一个实实在在的个体,是类的一个实例。
比如:“人”是一个类,而“教师”则是“人”的一个实例。
- 2.对象是函数、变量的集合体;而类是一组函数和变量的集合体,即类是一组具有相同属性的对象集合体。
30、请你讲讲wait方法的底层原理
wait即object的wait()和notify()或者notifyall()一起搭配使用
wait方法会将当前线程放入wait set等待被唤醒
- 1
- 2
1.将当前线程封装成objectwaiter对象node
2.通过objectmonitor::addwaiter方法将node添加到_WaitSet列表中
3.通过ObjectMonitor:exit方法释放当前的ObjectMonitor对象,这样其他竞争线程就可以获取该ObjectMonitor对象
4.最终底层的park方法会挂起线程
notiry方法就是随机唤醒等待池中的一个线程
31、请判断List、Set、Map是否继承自Collection接口?
List、Set 是,Map 不是。Map是键值对映射容器,与List和Set有明显的区别,而Set存储的零散的元素且不允许有重复元素(数学中的集合也是如此),List是线性结构的容器,适用于按数值索引访问元素的情形。
32、请说明Collection 和 Collections的区别。
Collection是集合类的上级接口,继承与他的接口主要有Set 和List.
Collections是针对集合类的一个帮助类,他提供一系列静态方法实现对各种集合的搜索、排序、线程安全化等操作。
- 1
- 2
33、请你说明HashMap和HashTable的区别?
1、HashMap和Hashtable都实现了Map接口,因此很多特性非常相似。但是,他们有以下不同点:
2、HashMap允许键和值是null,而Hashtable不允许键或者值是null。
3、Hashtable是同步的,而HashMap不是。因此,HashMap更适合于单线程环境,而Hashtable适合于多线程环境。
4、HashMap提供了可供应用迭代的键的集合,因此,HashMap是快速失败的。另一方面,Hashtable提供了对键的列举(Enumeration)。
一般认为Hashtable是一个遗留的类。
- 1
- 2
- 3
- 4
- 5
34、请说说快速失败(fail-fast)和安全失败(fail-safe)的区别?
Iterator的安全失败是基于对底层集合做拷贝,因此,它不受源集合上修改的影响。java.util包下面的所有的集合类都是快速失败的,而java.util.concurrent包下面的所有的类都是安全失败的。快速失败的迭代器会抛出ConcurrentModificationException异常,而安全失败的迭代器永远不会抛出这样的异常。

35、请简单说明一下什么是迭代器?
Iterator提供了统一遍历操作集合元素的统一接口, Collection接口实现Iterable接口,
每个集合都通过实现Iterable接口中iterator()方法返回Iterator接口的实例, 然后对集合的元素进行迭代操作.
有一点需要注意的是:在迭代元素的时候不能通过集合的方法删除元素, 否则会抛出ConcurrentModificationException 异常. 但是可以通过Iterator接口中的remove()方法进行删除.
Vector 每次扩容请求其大小的 2 倍(也可以通过构造函数设置增长的容量),而 ArrayList 是 1.5 倍。
扩展:Collection接口实现Iterable接口?接口能实现接口吗?
类和接口的关系:
类和类:类继承类,单继承,多层继承
类和接口:类实现接口,可实现多个接口,接口名之间用逗号隔开
接口和接口:接口继承接口,多继承,为了弥补java中类的单继承特点
- 1
- 2
- 3
36、请解释为什么集合类没有实现Cloneable和Serializable接口?
克隆(cloning)或者是序列化(serialization)的语义和含义是跟具体的实现相关的。因此,应该由集合类的具体实现来决定如何被克隆或者是序列化。
实现Serializable序列化的作用:将对象的状态保存在存储媒体中以便可以在以后重写创建出完全相同的副本;按值将对象从一个从一个应用程序域发向另一个应用程序域。
实现 Serializable接口的作用就是可以把对象存到字节流,然后可以恢复。所以你想如果你的对象没有序列化,怎么才能进行网络传输呢?要网络传输就得转为字节流,所以在分布式应用中,你就得实现序列化。如果你不需要分布式应用,那就没必要实现实现序列化。
37、请说明Java集合类框架的基本接口有哪些?
集合类接口指定了一组叫做元素的对象。集合类接口的每一种具体的实现类都可以选择以它自己的方式对元素进行保存和排序。有的集合类允许重复的键,有些不允许。
Java集合类提供了一套设计良好的支持对一组对象进行操作的接口和类。
Java集合类里面最基本的接口有:
Collection:代表一组对象,每一个对象都是它的子元素。
Set:不包含重复元素的Collection。
List:有顺序的collection,并且可以包含重复元素。
Map:可以把键(key)映射到值(value)的对象,键不能重复。
- 1
- 2
- 3
- 4
38、请你说明一下ConcurrentHashMap的原理?
ConcurrentHashMap 类中包含两个静态内部类 HashEntry 和 Segment。HashEntry 用来封装映射表的键 / 值对;Segment 用来充当锁的角色,每个 Segment 对象守护整个散列映射表的若干个桶。每个桶是由若干个 HashEntry 对象链接起来的链表。一个 ConcurrentHashMap 实例中包含由若干个 Segment 对象组成的数组。HashEntry 用来封装散列映射表中的键值对。在 HashEntry 类中,key,hash 和 next 域都被声明为 final 型,value 域被声明为 volatile 型。
static final class HashEntry<K,V> {
final K key; // 声明 key 为 final 型
final int hash; // 声明 hash 值为 final 型
volatile V value; // 声明 value 为 volatile 型
final HashEntry<K,V> next; // 声明 next 为 final 型
HashEntry(K key, int hash, HashEntry<K,V> next, V value) {
this.key = key;
this.hash = hash;
this.next = next;
this.value = value;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
在ConcurrentHashMap 中,在散列时如果产生“碰撞”,将采用“分离链接法”来处理“碰撞”:把“碰撞”的 HashEntry 对象链接成一个链表。由于 HashEntry 的 next 域为 final 型,所以新节点只能在链表的表头处插入。 下图是在一个空桶中依次插入 A,B,C 三个 HashEntry 对象后的结构图:
图1、插入三个节点后桶的结构示意图:

注意:由于只能在表头插入,所以链表中节点的顺序和插入的顺序相反。
Segment 类继承于 ReentrantLock 类,从而使得 Segment 对象能充当锁的角色。每个 Segment 对象用来守护其(成员对象 table 中)包含的若干个桶。
39、请解释一下TreeMap?
TreeMap是一个有序的key-value集合,基于红黑树(Red-Black tree)的 NavigableMap实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator进行排序,具体取决于使用的构造方法。
TreeMap的特性:
1、根节点是黑色
2、每个节点都只能是红色或者黑色
3、每个叶节点(NIL节点,空节点)是黑色的。
4、如果一个节点是红色的,则它两个子节点都是黑色的,也就是说在一条路径上不能出现两个红色的节点。
5、从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
- 1
- 2
- 3
- 4
- 5
40、请说明ArrayList是否会越界?
ArrayList是实现了基于动态数组的数据结构,而LinkedList是基于链表的数据结构2. 对于随机访问get和set,ArrayList要优于LinkedList,因为LinkedList要移动指针;ArrayList并发add()可能出现数组下标越界异常。
41、请你说明concurrenthashmap有什么优势以及1.7和1.8区别?
Concurrenthashmap线程安全的,1.7是在jdk1.7中采用Segment + HashEntry的方式进行实现的,lock加在Segment上面。1.7size计算是先采用不加锁的方式,连续计算元素的个数,最多计算3次:
1、如果前后两次计算结果相同,则说明计算出来的元素个数是准确的;
2、如果前后两次计算结果都不同,则给每个Segment进行加锁,再计算一次元素的个数;
1.8中放弃了Segment臃肿的设计,取而代之的是采用Node + CAS + Synchronized来保证并发安全进行实现,1.8中使用一个volatile类型的变量baseCount记录元素的个数,当插入新数据或则删除数据时,会通过addCount()方法更新baseCount,通过累加baseCount和CounterCell数组中的数量,即可得到元素的总个数;
42、请你说明一下TreeMap的底层实现?
TreeMap 的实现就是红黑树数据结构,也就说是一棵自平衡的排序二叉树,这样就可以保证当需要快速检索指定节点。
红黑树的插入、删除、遍历时间复杂度都为O(lgN),所以性能上低于哈希表。但是哈希表无法提供键值对的有序输出,红黑树因为是排序插入的,可以按照键的值的大小有序输出。红黑树性质:
性质1:每个节点要么是红色,要么是黑色。
性质2:根节点永远是黑色的。
性质3:所有的叶节点都是空节点(即 null),并且是黑色的。
性质4:每个红色节点的两个子节点都是黑色。(从每个叶子到根的路径上不会有两个连续的红色节点)
性质5:从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
43、请你说明ConcurrentHashMap锁加在了哪些地方?
加在每个Segment 上面。
- 1
44、请你解释HashMap的容量为什么是2的n次幂?
负载因子默认是0.75, 2^n是为了让散列更加均匀,例如出现极端情况都散列在数组中的一个下标,那么hashmap会由O(1)复杂退化为O(n)的。
- 1
45、请你简单介绍一下ArrayList和LinkedList的区别,并说明如果一直在list的尾部添加元素,用哪种方式的效率高?
ArrayList采用数组数组实现的,查找效率比LinkedList高。LinkedList采用双向链表实现的,插入和删除的效率比ArrayList要高。一直在list的尾部添加元素,LinkedList效率要高。
- 1
46、如果hashMap的key是一个自定义的类,怎么办?
使用HashMap,如果key是自定义的类,就必须重写hashcode()和equals()。
- 1
47、请你解释一下hashMap具体如何实现的?
Hashmap基于数组实现的,通过对key的hashcode & 数组的长度得到在数组中位置,如当前数组有元素,则数组当前元素next指向要插入的元素,这样来解决hash冲突的,形成了拉链式的结构。put时在多线程情况下,会形成环从而导致死循环。数组长度一般是2n,从0开始编号,所以hashcode & (2n-1),(2n-1)每一位都是1,这样会让散列均匀。需要注意的是,HashMap在JDK1.8的版本中引入了红黑树结构做优化,当链表元素个数大于等于8时,链表转换成树结构;若桶中链表元素个数小于等于6时,树结构还原成链表。因为红黑树的平均查找长度是log(n),长度为8的时候,平均查找长度为3,如果继续使用链表,平均查找长度为8/2=4,这才有转换为树的必要。链表长度如果是小于等于6,6/2=3,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。还有选择6和8,中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
48、请你说明一下Map和ConcurrentHashMap的区别?
hashmap是线程不安全的,put时在多线程情况下,会形成环从而导致死循环。CoucurrentHashMap是线程安全的,采用分段锁机制,减少锁的粒度。
- 1
49、如何保证线程安全?
通过合理的时间调度,避开共享资源的存取冲突。另外,在并行任务设计上可以通过适当的策略,保证任务与任务之间不存在共享资源,设计一个规则来保证一个客户的计算工作和数据访问只会被一个线程或一台工作机完成,而不是把一个客户的计算工作分配给多个线程去完成。
50、请你解释一下什么是线程池(thread pool)?
在面向对象编程中,创建和销毁对象是很费时间的,因为创建一个对象要获取内存资源或者其它更多资源。在Java中更是如此,虚拟机将试图跟踪每一个对象,以便能够在对象销毁后进行垃圾回收。所以提高服务程序效率的一个手段就是尽可能减少创建和销毁对象的次数,特别是一些很耗资源的对象创建和销毁,这就是”池化资源”技术产生的原因。线程池顾名思义就是事先创建若干个可执行的线程放入一个池(容器)中,需要的时候从池中获取线程不用自行创建,使用完毕不需要销毁线程而是放回池中,从而减少创建和销毁线程对象的开销。
Java 5+中的Executor接口定义一个执行线程的工具。它的子类型即线程池接口是ExecutorService。要配置一个线程池是比较复杂的,尤其是对于线程池的原理不是很清楚的情况下,因此在工具类Executors面提供了一些静态工厂方法,生成一些常用的线程池,如下所示:
-
newSingleThreadExecutor:创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
-
newFixedThreadPool:创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
-
newCachedThreadPool:创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
-
newScheduledThreadPool:创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
-
newSingleThreadExecutor:创建一个单线程的线程池。此线程池支持定时以及周期性执行任务的需求。
51、请问当一个线程进入一个对象的synchronized方法A之后,其它线程是否可进入此对象的synchronized方法B?
不能。其它线程只能访问该对象的非同步方法,同步方法则不能进入。因为非静态方法上的synchronized修饰符要求执行方法时要获得对象的锁,如果已经进入A方法说明对象锁已经被取走,那么试图进入B方法的线程就只能在等锁池(注意不是等待池哦)中等待对象的锁。
52、请简述一下线程的sleep()方法和yield()方法有什么区别?
①sleep()方法给其他线程运行机会时不考虑线程的优先级,因此会给低优先级的线程以运行的机会;yield()方法只会给相同优先级或更高优先级的线程以运行的机会;
② 线程执行sleep()方法后转入阻塞(blocked)状态,而执行yield()方法后转入就绪(ready)状态;
③ sleep()方法声明抛出InterruptedException,而yield()方法没有声明任何异常;
④ sleep()方法比yield()方法(跟操作系统CPU调度相关)具有更好的可移植性。
sleep你可以理解为让出多少时间,yield这一次运行机会让出(yield主动让出CPU给其他线程执行)
- 1
- 2
- 3
- 4
- 5
- 6
53、请回答以下几个问题: 第一个 问题:Java中有几种方法可以实现一个线程? 第二个问题:用什么关键字修饰同步方法? 第三个问题:stop()和suspend()方法为何不推荐使用,请说明原因?
有两种实现方法,分别是继承Thread类与实现Runnable接口用synchronized关键字修饰同步方法,反对使用stop(),是因为它不安全。它会解除由线程获取的所有锁定,而且如果对象处于一种不连贯状态,那么其他线程能在那种状态下检查和修改它们。结果很难检查出真正的问题所在。suspend()方法容易发生死锁。调用suspend()的时候,目标线程会停下来,但却仍然持有在这之前获得的锁定。此时,其他任何线程都不能访问锁定的资源,除非被”挂起”的线程恢复运行。对任何线程来说,如果它们想恢复目标线程,同时又试图使用任何一个锁定的资源,就会造成死锁。所以不应该使用suspend(),而应在自己的Thread类中置入一个标志,指出线程应该活动还是挂起。若标志指出线程应该挂起,便用 wait()命其进入等待状态。若标志指出线程应当恢复,则用一个notify()重新启动线程。
54、请分别说明一下多线程和同步有几种实现方法,并且这些实现方法具体内容都是什么?
多线程有两种实现方法,分别是继承Thread类与实现Runnable接口同步的实现方面有两种,分别是synchronized,wait与notify。
public class ThreadTest1 { private int j; public static void main(String args[]) { ThreadTest1 tt = new ThreadTest1(); Inc inc = tt.new Inc(); Dec dec = tt.new Dec(); for (int i = 0; i < 2; i++) { Thread t = new Thread(inc); t.start(); t = new Thread(dec); t.start(); } } private synchronized void inc() { j++; System.out.println(Thread.currentThread().getName() + "-inc:" + j); } private synchronized void dec() { j--; System.out.println(Thread.currentThread().getName() + "-dec:" + j); } class Inc implements Runnable { public void run() { for (int i = 0; i < 100; i++) { inc(); } } } class Dec implements Runnable { public void run() { for (int i = 0; i < 100; i++) { dec(); } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
55、请详细描述一下线程从创建到死亡的几种状态都有哪些?
1. 新建( new ):新创建了一个线程对象。
2. 可运行( runnable ):线程对象创建后,其他线程(比如 main 线程)调用了该对象 的 start ()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获 取 cpu 的使用权 。
3. 运行( running ):可运行状态( runnable )的线程获得了 cpu 时间片( timeslice ) ,执行程序代码。
4. 阻塞( block ):阻塞状态是指线程因为某种原因放弃了 cpu 使用权,也即让出了 cpu timeslice ,暂时停止运行。直到线程进入可运行( runnable )状态,才有 机会再次获得 cpu timeslice 转到运行( running )状态。阻塞的情况分三种:
(一). 等待阻塞:运行( running )的线程执行 o . wait ()方法, JVM 会把该线程放 入等待队列( waitting queue )中。
(二). 同步阻塞:运行( running )的线程在获取对象的同步锁时,若该同步锁 被别的线程占用,则 JVM 会把该线程放入锁池( lock pool )中。
(三). 其他阻塞: 运行( running )的线程执行 Thread . sleep ( long ms )或 t . join ()方法,或者发出了 I / O 请求时, JVM 会把该线程置为阻塞状态。 当 sleep ()状态超时、 join ()等待线程终止或者超时、或者 I / O 处理完毕时,线程重新转入可运行( runnable )状态。
5. 死亡( dead ):线程 run ()、 main () 方法执行结束,或者因异常退出了 run ()方法,则该线程结束生命周期。死亡的线程不可再次复生。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

56、请列举一下启动线程有哪几种方式,之后再说明一下线程池的种类都有哪些?
①启动线程有如下三种方式:
一、继承Thread类创建线程类
1)定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务。因此把run()方法称为执行体。
2)创建Thread子类的实例,即创建了线程对象。
3)调用线程对象的start()方法来启动该线程。
- 1
- 2
- 3
- 4
- 5
代码:
package com.thread; public class FirstThreadTest extends Thread{ int i = 0; //重写run方法,run方法的方法体就是现场执行体 public void run() { for(;i<100;i++){ System.out.println(getName()+" "+i); } } public static void main(String[] args) { for(int i = 0;i< 100;i++) { System.out.println(Thread.currentThread().getName()+" : "+i); if(i==20) { new FirstThreadTest().start(); new FirstThreadTest().start(); } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
重写run方法,run方法的方法体就是现场执行体`
package com.thread; public class RunnableThreadTest implements Runnable { private int i; public void run() { for(i = 0;i <100;i++) { System.out.println(Thread.currentThread().getName()+" "+i); } } public static void main(String[] args) { for(int i = 0;i < 100;i++) { System.out.println(Thread.currentThread().getName()+" "+i); if(i==20) { RunnableThreadTest rtt = new RunnableThreadTest(); new Thread(rtt,"新线程1").start(); new Thread(rtt,"新线程2").start(); } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
上述代码中Thread.currentThread()方法返回当前正在执行的线程对象。GetName()方法返回调用该方法的线程的名字。
二、通过Runnable接口创建线程类
1)定义runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。
2)创建 Runnable实现类的实例,并依此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。
3)调用线程对象的start()方法来启动该线程。
- 1
- 2
- 3
代码:
package com.thread; public class RunnableThreadTest implements Runnable { private int i; public void run() { for(i = 0;i <100;i++) { System.out.println(Thread.currentThread().getName()+" "+i); } } public static void main(String[] args) { for(int i = 0;i < 100;i++) { System.out.println(Thread.currentThread().getName()+" "+i); if(i==20) { RunnableThreadTest rtt = new RunnableThreadTest(); new Thread(rtt,"新线程1").start(); new Thread(rtt,"新线程2").start(); } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
三、通过Callable和Future创建线程
1)创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。
2)创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。
3)使用FutureTask对象作为Thread对象的target创建并启动新线程。
4)调用FutureTask对象的get()方法来获得子线程执行结束后的返回值
- 1
- 2
- 3
- 4
代码:
package com.thread; import java.util.concurrent.Callable; import java.util.concurrent.ExecutionException; import java.util.concurrent.FutureTask; public class CallableThreadTest implements Callable<Integer> { public static void main(String[] args) { CallableThreadTest ctt = new CallableThreadTest(); FutureTask<Integer> ft = new FutureTask<>(ctt); for(int i = 0;i < 100;i++) { System.out.println(Thread.currentThread().getName()+" 的循环变量i的值"+i); if(i==20) { new Thread(ft,"有返回值的线程").start(); } } try { System.out.println("子线程的返回值:"+ft.get()); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } } @Override public Integer call() throws Exception { int i = 0; for(;i<100;i++) { System.out.println(Thread.currentThread().getName()+" "+i); } return i; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
②线程池的种类有:
Java通过Executors提供四种线程池,分别为:
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
- 1
- 2
- 3
- 4
- 5
57、请简要说明一下JAVA中cyclicbarrier和countdownlatch的区别分别是什么?
CountDownLatch和CyclicBarrier都能够实现线程之间的等待,只不过它们侧重点不同:
CountDownLatch一般用于某个线程A等待若干个其他线程执行完任务之后,它才执行;
而CyclicBarrier一般用于一组线程互相等待至某个状态,然后这一组线程再同时执行;
另外,CountDownLatch是不能够重用的,而CyclicBarrier是可以重用的。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
58、请说明一下线程池有什么优势?
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能执行。
第三:提高线程的可管理性,线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。
- 1
- 2
- 3
- 4
- 5
59、请回答一下Java中有几种线程池?并且详细描述一下线程池的实现过程
1、newFixedThreadPool创建一个指定工作线程数量的线程池。每当提交一个任务就创建一个工作线程,如果工作线程数量达到线程池初始的最大数,则将提交的任务存入到池队列中。
2、newCachedThreadPool创建一个可缓存的线程池。这种类型的线程池特点是:
1).工作线程的创建数量几乎没有限制(其实也有限制的,数目为Interger. MAX_VALUE), 这样可灵活的往线程池中添加线程。
2).如果长时间没有往线程池中提交任务,即如果工作线程空闲了指定的时间(默认为1分钟),则该工作线程将自动终止。终止后,如果你又提交了新的任务,则线程池重新创建一个工作线程。
3、newSingleThreadExecutor创建一个单线程化的Executor,即只创建唯一的工作者线程来执行任务,如果这个线程异常结束,会有另一个取代它,保证顺序执行(我觉得这点是它的特色)。单工作线程最大的特点是可保证顺序地执行各个任务,并且在任意给定的时间不会有多个线程是活动的 。
4、newScheduleThreadPool创建一个定长的线程池,而且支持定时的以及周期性的任务执行,类似于Timer。(这种线程池原理暂还没完全了解透彻)
- 1
- 2
- 3
- 4
- 5
- 6
60、请列举一下创建线程的方法,并简要说明一下在这些方法中哪个方法更好,原因是什么?
需要从Java.lang.Thread类派生一个新的线程类,重载它的run()方法;
实现Runnalbe接口,重载Runnalbe接口中的run()方法。
实现Runnalbe接口更好,使用实现Runnable接口的方式创建的线程可以处理同一资源,从而实现资源的共享.
- 1
- 2
- 3
- 4
- 5
61、请简短说明一下你对AQS的理解。
AQS其实就是一个可以给我们实现锁的框架
内部实现的关键是:先进先出的队列、state状态
定义了内部类ConditionObject
拥有两种线程模式独占模式和共享模式。
在LOCK包中的相关锁(常用的有ReentrantLock、 ReadWriteLock)都是基于AQS来构建,一般我们叫AQS为同步器。
- 1
- 2
- 3
- 4
- 5
62、请简述一下线程池的运行流程,使用参数以及方法策略等
线程池主要就是指定线程池核心线程数大小,最大线程数,存储的队列,拒绝策略,空闲线程存活时长。当需要任务大于核心线程数时候,就开始把任务往存储任务的队列里,当存储队列满了的话,就开始增加线程池创建的线程数量,如果当线程数量也达到了最大,就开始执行拒绝策略,比如说记录日志,直接丢弃,或者丢弃最老的任务。
63、线程,进程,然后线程创建有很大开销,怎么优化?
使用线程池
- 1
64、请介绍一下什么是生产者消费者模式?

生产者消费者问题是线程模型中的经典问题:生产者和消费者在同一时间段内共用同一存储空间,生产者向空间里生产数据,而消费者取走数据。
优点:支持并发、解耦。
- 1
生产者消费者模型的优点:
- 1、解耦
假设生产者和消费者分别是两个类。
如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。
将来如果消费者的代码发生变化, 可能会影响到生产者。而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合也就相应降低了。 - 2、支持并发
由于生产者与消费者是两个独立的并发体,他们之间是用缓冲区作为桥梁连接,生产者只需要往缓冲区里丢数据,
就可以继续生产下一个数据,而消费者只需要从缓冲区了拿数据即可,这样就不会因为彼此的处理速度而发生阻塞。 - 3、支持忙闲不均
缓冲区还有另一个好处。如果制造数据的速度时快时慢,缓冲区的好处就体现出来了。
当数据制造快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中。 等生产者的制造速度慢下来,消费者再慢慢处理掉。
65、请简述一下实现多线程同步的方法?
可以使用synchronized、lock、volatile和ThreadLocal来实现同步。
- 1
66、如何在线程安全的情况下实现一个计数器?
可以使用加锁,比如synchronized或者lock。也可以使用Concurrent包下的原子类。
- 1
67、多线程中的i++线程安全吗?请简述一下原因?
不安全。i++不是原子性操作。i++分为读取i值,对i值加一,再赋值给i++,执行期中任何一步都是有可能被其他线程抢占的。
- 1
68、请你简述一下synchronized与java.util.concurrent.locks.Lock的相同之处和不同之处?
- 主要相同点:Lock能完成synchronized所实现的所有功能
- 主要不同点:Lock有比synchronized更精确的线程语义和更好的性能。synchronized会自动释放锁,而Lock一定要求程序员手工释放,并且必须在finally从句中释放。
69、JAVA中如何确保N个线程可以访问N个资源,但同时又不导致死锁?
使用多线程的时候,一种非常简单的避免死锁的方式就是:指定获取锁的顺序,并强制线程按照指定的顺序获取锁。因此,如果所有的线程都是以同样的顺序加锁和释放锁,就不会出现死锁了。
预防死锁,预先破坏产生死锁的四个条件。互斥不可能破坏,所以有如下三种方法:
-
1.破坏请求和保持条件,进程必须等所有要请求的资源都空闲时才能申请资源,这种方法会使资源浪费严重(有些资源可能仅在运行初期或结束时才使用,甚至根本不使用). 允许进程获取初期所需资源后,便开始运行,运行过程中再逐步释放自己占有的资源,比如有一个进程的任务是把数据复制到磁盘中再打印,前期只需获得磁盘资源而不需要获得打印机资源,待复制完毕后再释放掉磁盘资源。这种方法比第一种方法好,会使资源利用率上升。
-
2.破坏不可抢占条件,这种方法代价大,实现复杂。
-
3.破坏循坏等待条件,对各进程请求资源的顺序做一个规定,避免相互等待。这种方法对资源的利用率比前两种都高,但是前期要为设备指定序号,新设备加入会有一个问题,其次对用户编程也有限制。
70、请说明一下锁和同步的区别。
-
用法上的不同:
synchronized既可以加在方法上,也可以加载特定代码块上,而lock需要显示地指定起始位置和终止位置。
synchronized是托管给JVM执行的,lock的锁定是通过代码实现的,它有比synchronized更精确的线程语义。 -
性能上的不同:
lock接口的实现类ReentrantLock,不仅具有和synchronized相同的并发性和内存语义,还多了超时的获取锁、定时锁、等候和中断锁等。
在竞争不是很激烈的情况下,synchronized的性能优于ReentrantLock,竞争激烈的情况下synchronized的性能会下降的非常快,而ReentrantLock则基本不变。 -
锁机制不同:
synchronized获取锁和释放锁的方式都是在块结构中,当获取多个锁时,必须以相反的顺序释放,并且是自动解锁。而Lock则需要开发人员手动释放,并且必须在finally中释放,否则会引起死锁。
71、请说明一下synchronized的可重入怎么实现。
每个锁关联一个线程持有者和一个计数器。当计数器为0时表示该锁没有被任何线程持有,那么任何线程都都可能获得该锁而调用相应方法。当一个线程请求成功后,JVM会记下持有锁的线程,并将计数器计为1。此时其他线程请求该锁,则必须等待。而该持有锁的线程如果再次请求这个锁,就可以再次拿到这个锁,同时计数器会递增。当线程退出一个synchronized方法/块时,计数器会递减,如果计数器为0则释放该锁。
72、请讲一下非公平锁和公平锁在reetrantlock里的实现过程是怎样的。
如果一个锁是公平的,那么锁的获取顺序就应该符合请求的绝对时间顺序,FIFO。对于非公平锁,只要CAS设置同步状态成功,则表示当前线程获取了锁,而公平锁还需要判断当前节点是否有前驱节点,如果有,则表示有线程比当前线程更早请求获取锁,因此需要等待前驱线程获取并释放锁之后才能继续获取锁。
73、Java中的LongAdder和AtomicLong有什么区别?
JDK1.8引入了LongAdder类。CAS机制就是,在一个死循环内,不断尝试修改目标值,直到修改成功。如果竞争不激烈,那么修改成功的概率就很高,否则,修改失败的的概率就很高,在大量修改失败时,这些原子操作就会进行多次循环尝试,因此性能就会受到影响。 结合ConcurrentHashMap的实现思想,应该可以想到对一种传统AtomicInteger等原子类的改进思路。虽然CAS操作没有锁,但是像减少粒度这种分离热点的思想依然可以使用。将AtomicInteger的内部核心数据value分离成一个数组,每个线程访问时,通过哈希等算法映射到其中一个数字进行计数,而最终的计数结果,则为这个数组的求和累加。热点数据value被分离成多个单元cell,每个cell独自维护内部的值,当前对象的实际值由所有的cell累计合成,这样热点就进行了有效的分离,提高了并行度。
74、请说明一下JAVA中反射的实现过程和作用分别是什么?
JAVA语言编译之后会生成一个.class文件,反射就是通过字节码文件找到某一个类、类中的方法以及属性等。反射的实现主要借助以下四个类:Class:类的对象,Constructor:类的构造方法,Field:类中的属性对象,Method:类中的方法对象。
作用:反射机制指的是程序在运行时能够获取自身的信息。在JAVA中,只要给定类的名字,那么就可以通过反射机制来获取类的所有信息。
75、什么是Java虚拟机?为什么Java被称作是“平台无关的编程语言”?
Java虚拟机是一个可以执行Java字节码的虚拟机进程。
Java源文件被编译成能被Java虚拟机执行的字节码文件。
Java被设计成允许应用程序可以运行在任意的平台,而不需要程序员为每一个平台单独重写或者是重新编译。Java虚拟机让这个变为可能,因为它知道底层硬件平台的指令长度和其他特性。
76、jvm最大内存限制多少?
-
1)堆内存分配
JVM初始分配的内存由-Xms指定,默认是物理内存的1/64;JVM最大分配的内存由-Xmx指定,默认是物理内存的1/4。默认空余堆内存小 于40%时,JVM就会增大堆直到-Xmx的最大限制;空余堆内存大于70%时,JVM会减少堆直到-Xms的最小限制。因此服务器一般设置-Xms、 -Xmx相等以避免在每次GC后调整堆的大小。
-
2)非堆内存分配
JVM使用-XX:PermSize设置非堆内存初始值,默认是物理内存的1/64;由XX:MaxPermSize设置最大非堆内存的大小,默认是物理内存的1/4。
-
3)VM最大内存
首先JVM内存限制于实际的最大物理内存,假设物理内存无限大的话,JVM内存的最大值跟操作系统有很大的关系。简单的说就32位处理器虽 然可控内存空间有4GB,但是具体的操作系统会给一个限制,这个限制一般是2GB-3GB(一般来说Windows系统下为1.5G-2G,Linux系 统下为2G-3G),而64bit以上的处理器就不会有限制了。
-
4)下面是当前比较流行的几个不同公司不同版本JVM最大堆内存:
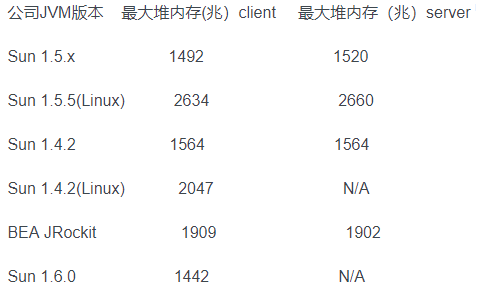
77、jvm是如何实现线程的?
线程是比进程更轻量级的调度执行单位。线程可以把一个进程的资源分配和执行调度分开。一个进程里可以启动多条线程,各个线程可共享该进程的资源(内存地址,文件IO等),又可以独立调度。线程是CPU调度的基本单位。
主流OS都提供线程实现。Java语言提供对线程操作的同一API,每个已经执行start(),且还未结束的java.lang.Thread类的实例,代表了一个线程。
Thread类的关键方法,都声明为Native。这意味着这个方法无法或没有使用平台无关的手段来实现,也可能是为了执行效率。
实现线程的方式
使用内核线程实现内核线程(Kernel-Level Thread, KLT)就是直接由操作系统内核支持的线程。 内核来完成线程切换 内核通过调度器Scheduler调度线程,并将线程的任务映射到各个CPU上 程序使用内核线程的高级接口,轻量级进程(Light Weight Process,LWP) 用户态和内核态切换消耗内核资源 使用用户线程实现 系统内核不能感知线程存在的实现 用户线程的建立、同步、销毁和调度完全在用户态中完成 所有线程操作需要用户程序自己处理,复杂度高 用户线程加轻量级进程混合实现 轻量级进程作为用户线程和内核线程之间的桥梁
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
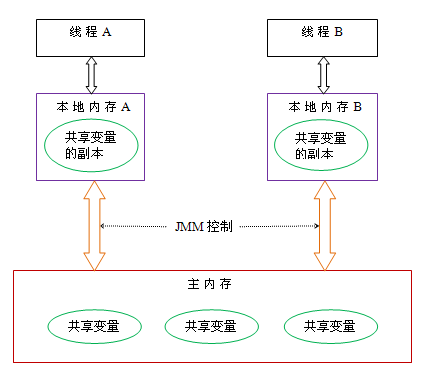
78、请问什么是JVM内存模型?
Java内存模型(简称JMM),JMM决定一个线程对共享变量的写入何时对另一个线程可见。从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读/写共享变量的副本。
本地内存是JMM的一个抽象概念,并不真实存在。它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器优化。其关系模型图如下图所示:
79、请列举一下,在JAVA虚拟机中,哪些对象可作为ROOT对象?
虚拟机栈中的引用对象
方法区中类静态属性引用的对象
方法区中常量引用对象
本地方法栈中JNI引用对象
- 1
- 2
- 3
- 4
- 5
- 6
- 7
【扩展】
1. 虚拟机栈中的引用对象
2. 本地方法栈中JNI引用对象
3. 方法区中类静态属性引用的对象
4. 方法区中常量引用对象(如字符串常量池)
5. 被同步锁持有的对象
6. 内部引用(如基本数据类型对应的class对象、常驻的异常对象NullPointerException等、系统类加载器)
7. 反映java虚拟机内部情况的JMXBean、JVMT中注册的回调,本地代码缓存等。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
80、请说明一下JAVA虚拟机的作用是什么?
解释运行字节码程序消除平台相关性。
jvm将java字节码解释为具体平台的具体指令。一般的高级语言如要在不同的平台上运行,至少需要编译成不同的目标代码。而引入JVM后,Java语言在不同平台上运行时不需要重新编译。Java语言使用模式Java虚拟机屏蔽了与具体平台相关的信息,使得Java语言编译程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。Java虚拟机在执行字节码时,把字节码解释成具体平台上的机器指令执行。
假设一个场景,要求stop the world时间非常短,你会怎么设计垃圾回收机制?
绝大多数新创建的对象分配在Eden区。
在Eden区发生一次GC后,存活的对象移到其中一个Survivor区。
在Eden区发生一次GC后,对象是存放到Survivor区,这个Survivor区已经存在其他存活的对象。
一旦一个Survivor区已满,存活的对象移动到另外一个Survivor区。然后之前那个空间已满Survivor区将置为空,没有任何数据。
经过重复多次这样的步骤后依旧存活的对象将被移到老年代。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
81、为什么Java被称作是“平台无关的编程语言”?
Java虚拟机可以理解为一个特殊的“操作系统”,只是它连接的不是硬件,而是一般的操作系统和java程序。
正是因为有这样一层操作系统与程序之间的连接,Java程序就能在一台机子上编译后到处都能运行——只要有对应不同系统的Java虚拟机就可以了。因此Java被称为“平台无关”。
82、实现线程的方式
主流OS都提供线程实现。Java语言提供对线程操作的同一API,每个已经执行start(),且还未结束的java.lang.Thread类的实例,代表了一个线程。
Thread类的关键方法,都声明为Native。这意味着这个方法无法或没有使用平台无关的手段来实现,也可能是为了执行效率。
1 使用内核线程实现
1)内核线程(Kernel-Level Thread, KLT)就是直接由操作系统内核支持的线程。
2)内核来完成线程切换
3)内核通过调度器Scheduler调度线程,并将线程的任务映射到各个CPU上
4)程序使用内核线程的高级接口,轻量级进程(Light Weight Process,LWP)–>(!!!名字是进程,实际是线程)
5)用户态和内核态切换消耗内核资源
- 1
- 2
- 3
- 4
- 5
2 使用用户线程实现
1)系统内核不能感知线程存在的实现
2)用户线程的建立、同步、销毁和调度完全在用户态中完成
3)所有线程操作需要用户程序自己处理,复杂度高
- 1
- 2
- 3
3 用户线程加轻量级进程混合实现
1)轻量级进程作为用户线程和内核线程之间的桥梁
- 1
83、minor gc运行的很频繁可能是什么原因引起的?
1、 产生了太多朝生夕灭的对象导致需要频繁minor gc
2、 新生代空间设置的比较小
- 1
- 2
84、minor gc运行的很慢有可能是什么原因引起的?
1、 新生代空间设置过大。
2、 对象引用链较长,进行可达性分析时间较长。
3、 新生代survivor区设置的比较小,清理后剩余的对象不能装进去需要移动到老年代,造成移动开销。
4、 内存分配担保失败,由minor gc转化为full gc
5、 采用的垃圾收集器效率较低,比如新生代使用serial收集器
- 1
- 2
- 3
- 4
- 5
85、请问java中内存泄漏是什么意思?什么场景下会出现内存泄漏的情况?
Java中的内存泄露,广义并通俗的说,就是:不再会被使用的对象的内存不能被回收,就是内存泄露。如果长生命周期的对象持有短生命周期的引用,就很可能会出现内存泄露。
86、请问运行时异常与受检异常有什么区别?
异常表示程序运行过程中可能出现的非正常状态,运行时异常表示虚拟机的通常操作中可能遇到的异常,是一种常见运行错误,只要程序设计得没有问题通常就不会发生。受检异常跟程序运行的上下文环境有关,即使程序设计无误,仍然可能因使用的问题而引发。Java编译器要求方法必须声明抛出可能发生的受检异常,但是并不要求必须声明抛出未被捕获的运行时异常。异常和继承一样,是面向对象程序设计中经常被滥用的东西,在Effective Java中对异常的使用给出了以下指导原则:
- 不要将异常处理用于正常的控制流(设计良好的API不应该强迫它的调用者为了正常的控制流而使用异常)
- 对可以恢复的情况使用受检异常,对编程错误使用运行时异常
- 避免不必要的使用受检异常(可以通过一些状态检测手段来避免异常的发生)
- 优先使用标准的异常
- 每个方法抛出的异常都要有文档
- 保持异常的原子性
- 不要在catch中忽略掉捕获到的异常
- 1
- 2
- 3
- 4
- 5
- 6
- 7
【扩展】
1、异常表示程序运行过程中可能出现的非正常状态
2、运行时异常,表示程序代码在运行时发生的异常,程序代码设计的合理,这类异常不会发生
3、受检异常跟程序运行的上下文环境有关,即使程序设计无误,仍然可能因使用的问题而引发
4、Java编译器要求方法必须声明抛出可能发生未被捕获的受检异常,不要求必须声明抛出运行时异常
- 1
- 2
- 3
- 4
87、请问java中有几种类型的流?JDK为每种类型的流提供了一些抽象类以供继承,请说出他们分别是哪些类?
字节流,字符流。字节流继承于InputStream OutputStream,字符流继承于InputStreamReader OutputStreamWriter。在java.io包中还有许多其他的流,主要是为了提高性能和使用方便。
88、请说明一下Java中的异常处理机制的原理以及如何应用。
当JAVA 程序违反了JAVA的语义规则时,JAVA虚拟机就会将发生的错误表示为一个异常。违反语义规则包括2种情况。一种是JAVA类库内置的语义检查。例如数组下标越界,会引发IndexOutOfBoundsException;访问null的对象时会引发NullPointerException。另一种情况就是JAVA允许程序员扩展这种语义检查,程序员可以创建自己的异常,并自由选择在何时用throw关键字引发异常。所有的异常都是 java.lang.Thowable的子类。
85、请问你平时最常见到的runtime exception是什么?
NullPointerException - 空指针异常
ClassCastException - 类转换异常
IndexOutOfBoundsException - 下标越界异常
ArithmeticException - 计算异常
IllegalArgumentException - 非法参数异常
NumberFormatException - 数字格式异常
UnsupportedOperationException 操作不支持异常
ArrayStoreException - 数据存储异常,操作数组时类型不一致
BufferOverflowException - IO 操作时出现的缓冲区上溢异常
NoSuchElementException - 元素不存在异常
InputMismatchException - 输入类型不匹配异常
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
86、请问error和exception有什么区别?
error 表示恢复不是不可能但很困难的情况下的一种严重问题。比如说内存溢出。不可能指望程序能处理这样的情况。
exception 表示一种设计或实现问题。也就是说,它表示如果程序运行正常,从不会发生的情况。
- 1
- 2
- 3
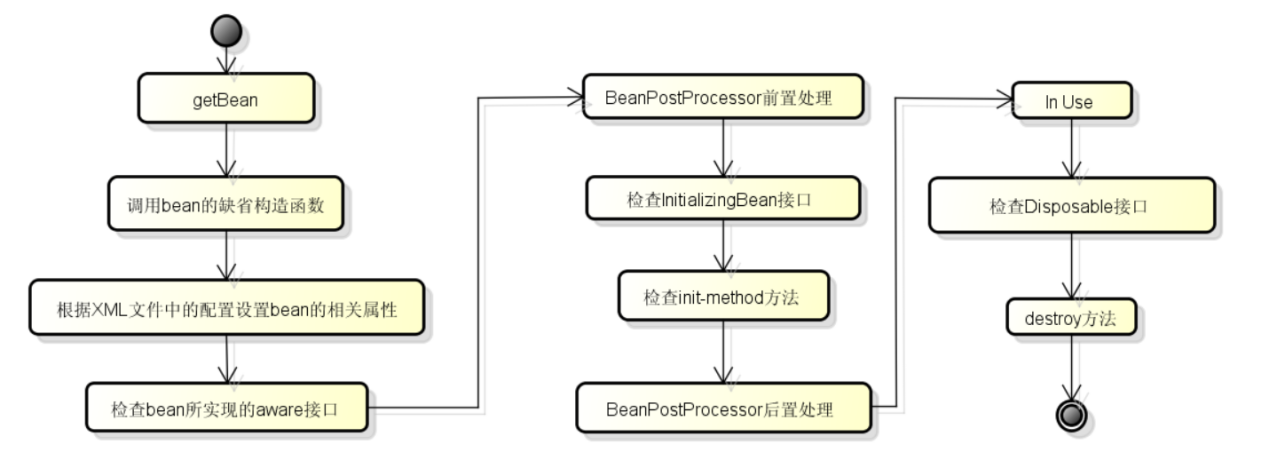
87、请介绍一下bean的生命周期
88、请问Spring支持的事务管理类型有哪些?以及你在项目中会使用哪种方式?
Spring支持编程式事务管理和声明式事务管理。许多Spring框架的用户选择声明式事务管理,因为这种方式和应用程序的关联较少,因此更加符合轻量级容器的概念。声明式事务管理要优于编程式事务管理,尽管在灵活性方面它弱于编程式事务管理,因为编程式事务允许你通过代码控制业务。
事务分为全局事务和局部事务。全局事务由应用服务器管理,需要底层服务器JTA支持(如WebLogic、WildFly等)。局部事务和底层采用的持久化方案有关,例如使用JDBC进行持久化时,需要使用Connetion对象来操作事务;而采用Hibernate进行持久化时,需要使用Session对象来操作事务。
这些事务的父接口都是PlatformTransactionManager。Spring的事务管理机制是一种典型的策略模式,PlatformTransactionManager代表事务管理接口,该接口定义了三个方法,该接口并不知道底层如何管理事务,但是它的实现类必须提供getTransaction()方法(开启事务)、commit()方法(提交事务)、rollback()方法(回滚事务)的多态实现,这样就可以用不同的实现类代表不同的事务管理策略。使用JTA全局事务策略时,需要底层应用服务器支持,而不同的应用服务器所提供的JTA全局事务可能存在细节上的差异,因此实际配置全局事务管理器是可能需要使用JtaTransactionManager的子类,如:WebLogicJtaTransactionManager(Oracle的WebLogic服务器提供)、UowJtaTransactionManager(IBM的WebSphere服务器提供)等。
89、你如何理解AOP中的连接点(Joinpoint)、切点(Pointcut)、增强(Advice)、引介(Introduction)、织入(Weaving)、切面(Aspect)这些概念?
- a. 连接点(Joinpoint):程序执行的某个特定位置(如:某个方法调用前、调用后,方法抛出异常后)。一个类或一段程序代码拥有一些具有边界性质的特定点,这些代码中的特定点就是连接点。Spring仅支持方法的连接点。
- b. 切点(Pointcut):如果连接点相当于数据中的记录,那么切点相当于查询条件,一个切点可以匹配多个连接点。Spring AOP的规则解析引擎负责解析切点所设定的查询条件,找到对应的连接点。
- c. 增强(Advice):增强是织入到目标类连接点上的一段程序代码。Spring提供的增强接口都是带方位名的,如:BeforeAdvice、AfterReturningAdvice、ThrowsAdvice等。
- d. 引介(Introduction):引介是一种特殊的增强,它为类添加一些属性和方法。这样,即使一个业务类原本没有实现某个接口,通过引介功能,可以动态的未该业务类添加接口的实现逻辑,让业务类成为这个接口的实现类。
- e. 织入(Weaving):织入是将增强添加到目标类具体连接点上的过程,AOP有三种织入方式:①编译期织入:需要特殊的Java编译期(例如AspectJ的ajc);②装载期织入:要求使用特殊的类加载器,在装载类的时候对类进行增强;③运行时织入:在运行时为目标类生成代理实现增强。Spring采用了动态代理的方式实现了运行时织入,而AspectJ采用了编译期织入和装载期织入的方式。
- f. 切面(Aspect):切面是由切点和增强(引介)组成的,它包括了对横切关注功能的定义,也包括了对连接点的定义。
90、请问AOP的原理是什么?
-
AOP(Aspect Orient Programming),指面向方面(切面)编程,作为面向对象的一种补充,用于处理系统中分布于各个模块的横切关注点,比如事务管理、日志、缓存等等。AOP实现的关键在于AOP框架自动创建的AOP代理,AOP代理主要分为静态代理和动态代理,静态代理的代表为AspectJ;而动态代理则以Spring AOP为代表。通常使用AspectJ的编译时增强实现AOP,AspectJ是静态代理的增强,所谓的静态代理就是AOP框架会在编译阶段生成AOP代理类,因此也称为编译时增强。
-
Spring AOP中的动态代理主要有两种方式,JDK动态代理和CGLIB动态代理。JDK动态代理通过反射来接收被代理的类,并且要求被代理的类必须实现一个接口。JDK动态代理的核心是InvocationHandler接口和Proxy类。
-
如果目标类没有实现接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。CGLIB(Code Generation Library),是一个代码生成的类库,可以在运行时动态的生成某个类的子类,注意,CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
91、请问aop的应用场景有哪些?
Authentication 权限 ,Caching 缓存 ,Context passing 内容传递 ,Error handling 错误处理 ,Lazy loading 懒加载 ,Debugging 调试 ,logging, tracing, profiling and monitoring 记录跟踪、优化、校准,Performance optimization 性能优化 ,Persistence 持久化 ,Resource pooling 资源池 ,Synchronization 同步,Transactions 事务。
92、请简单谈一下spring框架的优点都有哪些?
Spring是一个轻量级的DI和AOP容器框架,在项目的中的使用越来越广泛,它的优点主要有以下几点:
Spring是一个非侵入式框架,其目标是使应用程序代码对框架的依赖最小化,应用代码可以在没有Spring或者其他容器的情况运行。
Spring提供了一个一致的编程模型,使应用直接使用POJO开发,从而可以使运行环境隔离开来。
Spring推动应用的设计风格向面向对象及面向接口编程转变,提高了代码的重用性和可测试性。
Spring改进了结构体系的选择,虽然作为应用平台,Spring可以帮助我们选择不同的技术实现,比如从Hibernate切换到其他的ORM工具,从Struts切换到Spring MVC,尽管我们通常不会这么做,但是我们在技术方案上选择使用Spring作为应用平台,Spring至少为我们提供了这种可能性的选择,从而降低了平台锁定风险。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
93、请阐述一下实体对象的三种状态是什么?以及对应的转换关系是什么?
最新的Hibernate文档中为Hibernate对象定义了四种状态(原来是三种状态,面试的时候基本上问的也是三种状态),分别是:瞬时态(new, or transient)、持久态(managed, or persistent)、游状态(detached)和移除态(removed,以前Hibernate文档中定义的三种状态中没有移除态),如下图所示,就以前的Hibernate文档中移除态被视为是瞬时态。
瞬时态:当new一个实体对象后,这个对象处于瞬时态,即这个对象只是一个保存临时数据的内存区域,如果没有变量引用这个对象,则会被JVM的垃圾回收机制回收。这个对象所保存的数据与数据库没有任何关系,除非通过Session的save()、saveOrUpdate()、persist()、merge()方法把瞬时态对象与数据库关联,并把数据插入或者更新到数据库,这个对象才转换为持久态对象。
持久态:持久态对象的实例在数据库中有对应的记录,并拥有一个持久化标识(ID)。对持久态对象进行delete操作后,数据库中对应的记录将被删除,那么持久态对象与数据库记录不再存在对应关系,持久态对象变成移除态(可以视为瞬时态)。持久态对象被修改变更后,不会马上同步到数据库,直到数据库事务提交。
游离态:当Session进行了close()、clear()、evict()或flush()后,实体对象从持久态变成游离态,对象虽然拥有持久和与数据库对应记录一致的标识值,但是因为对象已经从会话中清除掉,对象不在持久化管理之内,所以处于游离态(也叫脱管态)。游离态的对象与临时状态对象是十分相似的,只是它还含有持久化标识。
94、请说明一下锁机制的作用是什么?并且简述一下Hibernate的悲观锁和乐观锁机制是什么?
有些业务逻辑在执行过程中要求对数据进行排他性的访问,于是需要通过一些机制保证在此过程中数据被锁住不会被外界修改,这就是所谓的锁机制。
Hibernate支持悲观锁和乐观锁两种锁机制。悲观锁,顾名思义悲观的认为在数据处理过程中极有可能存在修改数据的并发事务(包括本系统的其他事务或来自外部系统的事务),于是将处理的数据设置为锁定状态。悲观锁必须依赖数据库本身的锁机制才能真正保证数据访问的排他性,乐观锁,顾名思义,对并发事务持乐观态度(认为对数据的并发操作不会经常性的发生),通过更加宽松的锁机制来解决由于悲观锁排他性的数据访问对系统性能造成的严重影响。最常见的乐观锁是通过数据版本标识来实现的,读取数据时获得数据的版本号,更新数据时将此版本号加1,然后和数据库表对应记录的当前版本号进行比较,如果提交的数据版本号大于数据库中此记录的当前版本号则更新数据,否则认为是过期数据无法更新。Hibernate中通过Session的get()和load()方法从数据库中加载对象时可以通过参数指定使用悲观锁;而乐观锁可以通过给实体类加整型的版本字段再通过XML或@Version注解进行配置。
使用乐观锁会增加了一个版本字段,很明显这需要额外的空间来存储这个版本字段,浪费了空间,但是乐观锁会让系统具有更好的并发性,这是对时间的节省。因此乐观锁也是典型的空间换时间的策略。
95、请简述一下Hibernate常见优化策略。
①制定合理的缓存策略(二级缓存、查询缓存)。
② 采用合理的Session管理机制。
③ 尽量使用延迟加载特性。
④ 设定合理的批处理参数。
⑤ 如果可以,选用UUID作为主键生成器。
⑥ 如果可以,选用基于版本号的乐观锁替代悲观锁。
⑦ 在开发过程中, 开启hibernate.show_sql选项查看生成的SQL,从而了解底层的状况;开发完成后关闭此选项。
⑧ 考虑数据库本身的优化,合理的索引、恰当的数据分区策略等都会对持久层的性能带来可观的提升,但这些需要专业的DBA(数据库管理员)提供支持。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
96、如何理解Hibernate的延迟加载机制?在实际应用中,延迟加载与Session关闭的矛盾是如何处理的?
延迟加载就是并不是在读取的时候就把数据加载进来,而是等到使用时再加载。Hibernate使用了虚拟代理机制实现延迟加载,我们使用Session的load()方法加载数据或者一对多关联映射在使用延迟加载的情况下从一的一方加载多的一方,得到的都是虚拟代理,简单的说返回给用户的并不是实体本身,而是实体对象的代理。代理对象在用户调用getter方法时才会去数据库加载数据。但加载数据就需要数据库连接。而当我们把会话关闭时,数据库连接就同时关闭了。
延迟加载与session关闭的矛盾一般可以这样处理:
① 关闭延迟加载特性。这种方式操作起来比较简单,因为Hibernate的延迟加载特性是可以通过映射文件或者注解进行配置的,但这种解决方案存在明显的缺陷。首先,出现"no session or session was closed"通常说明系统中已经存在主外键关联,如果去掉延迟加载的话,每次查询的开销都会变得很大。
② 在session关闭之前先获取需要查询的数据,可以使用工具方法Hibernate.isInitialized()判断对象是否被加载,如果没有被加载则可以使用Hibernate.initialize()方法加载对象。
③ 使用拦截器或过滤器延长Session的生命周期直到视图获得数据。Spring整合Hibernate提供的OpenSessionInViewFilter和OpenSessionInViewInterceptor就是这种做法。
- 1
- 2
- 3
97、请问Hibernate中Session的load方法和get方法的区别是什么?
主要有以下三项区别:
① 如果没有找到符合条件的记录,get方法返回null,load方法抛出异常。
② get方法直接返回实体类对象,load方法返回实体类对象的代理。
③ 在Hibernate 3之前,get方法只在一级缓存中进行数据查找,如果没有找到对应的数据则越过二级缓存,直接发出SQL语句完成数据读取;load方法则可以从二级缓存中获取数据;从Hibernate 3开始,get方法不再是对二级缓存只写不读,它也是可以访问二级缓存的。
- 1
- 2
- 3
对于load()方法Hibernate认为该数据在数据库中一定存在可以放心的使用代理来实现延迟加载,如果没有数据就抛出异常,而通过get()方法获取的数据可以不存在。
98、Hibernate中SessionFactory和Session是线程安全的吗?这两个线程是否能够共享同一个Session?
SessionFactory对应Hibernate的一个数据存储的概念,它是线程安全的,可以被多个线程并发访问。SessionFactory一般只会在启动的时候构建。对于应用程序,最好将SessionFactory通过单例模式进行封装以便于访问。Session是一个轻量级非线程安全的对象(线程间不能共享session),它表示与数据库进行交互的一个工作单元。Session是由SessionFactory创建的,在任务完成之后它会被关闭。Session是持久层服务对外提供的主要接口。Session会延迟获取数据库连接(也就是在需要的时候才会获取)。为了避免创建太多的session,可以使用ThreadLocal将session和当前线程绑定在一起,这样可以让同一个线程获得的总是同一个session。Hibernate 3中SessionFactory的getCurrentSession()方法就可以做到。
99、请说明一下Hibernate如何实现分页查询?
通过Hibernate实现分页查询,开发人员只需要提供HQL语句(调用Session的createQuery()方法)或查询条件(调用Session的createCriteria()方法)、设置查询起始行数(调用Query或Criteria接口的setFirstResult()方法)和最大查询行数(调用Query或Criteria接口的setMaxResults()方法),并调用Query或Criteria接口的list()方法,Hibernate会自动生成分页查询的SQL语句。
100、请简述一下Hibernate的一级缓存、二级缓存以及查询缓存分别是什么?
Hibernate的Session提供了一级缓存的功能,默认总是有效的,当应用程序保存持久化实体、修改持久化实体时,Session并不会立即把这种改变提交到数据库,而是缓存在当前的Session中,除非显示调用了Session的flush()方法或通过close()方法关闭Session。通过一级缓存,可以减少程序与数据库的交互,从而提高数据库访问性能。
SessionFactory级别的二级缓存是全局性的,所有的Session可以共享这个二级缓存。不过二级缓存默认是关闭的,需要显示开启并指定需要使用哪种二级缓存实现类(可以使用第三方提供的实现)。一旦开启了二级缓存并设置了需要使用二级缓存的实体类,SessionFactory就会缓存访问过的该实体类的每个对象,除非缓存的数据超出了指定的缓存空间。
一级缓存和二级缓存都是对整个实体进行缓存,不会缓存普通属性,如果希望对普通属性进行缓存,可以使用查询缓存。查询缓存是将HQL或SQL语句以及它们的查询结果作为键值对进行缓存,对于同样的查询可以直接从缓存中获取数据。查询缓存默认也是关闭的,需要显示开启。
101、请问MyBatis中的动态SQL是什么意思?
对于一些复杂的查询,我们可能会指定多个查询条件,但是这些条件可能存在也可能不存在,需要根据用户指定的条件动态生成SQL语句。如果不使用持久层框架我们可能需要自己拼装SQL语句,还好MyBatis提供了动态SQL的功能来解决这个问题。MyBatis中用于实现动态SQL的元素主要有:
- if
- choose / when / otherwise
- trim
- where
- set
- foreach
102、请说明一下MyBatis中命名空间(namespace)的作用是什么?
在大型项目中,可能存在大量的SQL语句,这时候为每个SQL语句起一个唯一的标识(ID)就变得并不容易了。为了解决这个问题,在MyBatis中,可以为每个映射文件起一个唯一的命名空间,这样定义在这个映射文件中的每个SQL语句就成了定义在这个命名空间中的一个ID。只要我们能够保证每个命名空间中这个ID是唯一的,即使在不同映射文件中的语句ID相同,也不会再产生冲突了。
103、请问JAVA应用服务器都有那些?
BEA WebLogic Server,
IBM WebSphere Application Server,
Oracle9i Application Server
jBoss,
Tomcat
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
104、在什么情况下回使用assert?
assertion (断言)在软件开发中是一种常用的调试方式,很多开发语言中都支持这种机制。在实现中,assertion就是在程序中的一条语句,它对一个 boolean表达式进行检查,一个正确程序必须保证这个boolean表达式的值为true;如果该值为false,说明程序已经处于不正确的状态下,系统将给出警告或退出。一般来说,assertion用于保证程序最基本、关键的正确性。assertion检查通常在开发和测试时开启。为了提高性能,在软件发布后,assertion检查通常是关闭的。
105、1分钟之内只能处理1000个请求,你怎么实现,手撕代码?
限流的几种方法:计数器,滑动窗口、漏桶法、令牌桶
1分钟之内只能处理1000个请求,你怎么实现,手撕代码?
a) 对所有用户访问的次数计数。 定义一个计时器,单位为一分钟。
如果超出次数,就拒绝该请求。 一分钟后, 次数刷新值为0。
private Map<String, List> map = new ConcurrentHashMap<>();
在单位计数中判断List中数量是否超出限制即可。
b) 使用aop实现请求的限制, 在需要限制的请求方法上加上aop逻辑。
自定义注解类 实现 请求限制的拦截逻辑, 在需要限制的方法上使用注解,超出限制后拒绝处理请求。
- 1
- 2
- 3
- 4
- 5
- 6
106、请问如何在链接里不输入项目名称的情况下启动项目?
可在taomcat配置虚拟目录。
- 1
107、请说明一下JSP中的静态包含和动态包含的有哪些区别?
静态包含是通过JSP的include指令包含页面,动态包含是通过JSP标准动作jsp:forward包含页面。静态包含是编译时包含,如果包含的页面不存在则会产生编译错误,而且两个页面的"contentType"属性应保持一致,因为两个页面会合二为一,只产生一个class文件,因此被包含页面发生的变动再包含它的页面更新前不会得到更新。动态包含是运行时包含,可以向被包含的页面传递参数,包含页面和被包含页面是独立的,会编译出两个class文件,如果被包含的页面不存在,不会产生编译错误,也不影响页面其他部分的执行。
例如:<%-- 静态包含 --%>
<%@ include file="..." %>
<%-- 动态包含 --%>
<jsp:include page="...">
<jsp:param name="..." value="..." />
</jsp:include>
- 1
- 2
- 3
- 4
- 5
- 6
108、请说一下表达式语言(EL)的隐式对象以及该对象的作用
EL的隐式对象包括:pageContext、initParam(访问上下文参数)、param(访问请求参数)、paramValues、header(访问请求头)、headerValues、cookie(访问cookie)、applicationScope(访问application作用域)、sessionScope(访问session作用域)、requestScope(访问request作用域)、pageScope(访问page作用域)。
109、请谈一谈JSP有哪些内置对象?以及这些对象的作用分别是什么?
JSP有9个内置对象:
- request:封装客户端的请求,其中包含来自GET或POST请求的参数;
- response:封装服务器对客户端的响应;
- pageContext:通过该对象可以获取其他对象;
- session:封装用户会话的对象;
- application:封装服务器运行环境的对象;
- out:输出服务器响应的输出流对象;
- config:Web应用的配置对象;
- page:JSP页面本身(相当于Java程序中的this);
- exception:封装页面抛出异常的对象。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如果用Servlet来生成网页中的动态内容无疑是非常繁琐的工作,另一方面,所有的文本和HTML标签都是硬编码,即使做出微小的修改,都需要进行重新编译。JSP解决了Servlet的这些问题,它是Servlet很好的补充,可以专门用作为用户呈现视图(View),而Servlet作为控制器(Controller)专门负责处理用户请求并转发或重定向到某个页面。基于Java的Web开发很多都同时使用了Servlet和JSP。JSP页面其实是一个Servlet,能够运行Servlet的服务器(Servlet容器)通常也是JSP容器,可以提供JSP页面的运行环境,Tomcat就是一个Servlet/JSP容器。第一次请求一个JSP页面时,Servlet/JSP容器首先将JSP页面转换成一个JSP页面的实现类,这是一个实现了JspPage接口或其子接口HttpJspPage的Java类。JspPage接口是Servlet的子接口,因此每个JSP页面都是一个Servlet。转换成功后,容器会编译Servlet类,之后容器加载和实例化Java字节码,并执行它通常对Servlet所做的生命周期操作。对同一个JSP页面的后续请求,容器会查看这个JSP页面是否被修改过,如果修改过就会重新转换并重新编译并执行。如果没有则执行内存中已经存在的Servlet实例。
110、说说weblogic中一个Domain的缺省目录结构?比如要将一个简单的helloWorld.jsp放入何目录下,然后在浏览器上就可打入主机?
端口号//helloword.jsp就可以看到运行结果了? 又比如这其中用到了一个自己写的javaBean该如何办?
Domain 目录服务器目录applications,将应用目录放在此目录下将可以作为应用访问,如果是Web应用,应用目录需要满足Web应用目录要求,jsp文件可以直接放在应用目录中,Javabean需要放在应用目录的WEB-INF目录的classes目录中,设置服务器的缺省应用将可以实现在浏览器上无需输入应用名。
111、请说明一下jsp有哪些动作? 这些动作的作用又分别是什么?
JSP 共有以下6种基本动作 jsp:include:在页面被请求的时候引入一个文件。 jsp:useBean:寻找或者实例化一个JavaBean。
jsp:setProperty:设置JavaBean的属性。 jsp:getProperty:输出某个JavaBean的属性。 jsp:forward:把请求转到一个新的页面。
jsp:plugin:根据浏览器类型为Java插件生成OBJECT或EMBED标记。
- 1
- 2
112、请详细说明一下Request对象的主要方法是什么?
setAttribute(String name,Object):设置名字为name的request的参数值 getAttribute(String name):返回由name指定的属性值 getAttributeNames():返回request对象所有属性的名字集合,结果是一个枚举的实例 getCookies():返回客户端的所有Cookie对象,结果是一个Cookie数组 getCharacterEncoding():返回请求中的字符编码方式 getContentLength():返回请求的Body的长度 getHeader(String name):获得HTTP协议定义的文件头信息 getHeaders(String name):返回指定名字的request Header的所有值,结果是一个枚举的实例 getHeaderNames():返回所以request Header的名字,结果是一个枚举的实例 getInputStream():返回请求的输入流,用于获得请求中的数据 getMethod():获得客户端向服务器端传送数据的方法 getParameter(String name):获得客户端传送给服务器端的有name指定的参数值 getParameterNames():获得客户端传送给服务器端的所有参数的名字,结果是一个枚举的实例 getParameterValues(String name):获得有name指定的参数的所有值 getProtocol():获取客户端向服务器端传送数据所依据的协议名称 getQueryString():获得查询字符串 getRequestURI():获取发出请求字符串的客户端地址 getRemoteAddr():获取客户端的IP地址 getRemoteHost():获取客户端的名字 getSession([Boolean create]):返回和请求相关Session getServerName():获取服务器的名字 getServletPath():获取客户端所请求的脚本文件的路径 getServerPort():获取服务器的端口号 removeAttribute(String name):删除请求中的一个属性
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
113、请简要说明一下四种会话跟踪技术分别是什么?
会话作用域ServletsJSP 页面描述
page否是代表与一个页面相关的对象和属性。一个页面由一个编译好的 Java servlet 类(可以带有任何的 include 指令,但是没有 include 动作)表示。这既包括 servlet 又包括被编译成 servlet 的 JSP 页面request是是代表与 Web 客户机发出的一个请求相关的对象和属性。一个请求可能跨越多个页面,涉及多个 Web 组件(由于forward 指令和 include 动作的关系)session是是代表与用于某个 Web 客户机的一个用户体验相关的对象和属性。一个 Web 会话可以也经常会跨越多个客户机请求application是是代表与整个 Web 应用程序相关的对象和属性。这实质上是跨越整个 Web 应用程序,包括多个页面、请求和会话的一个全局作用域。
114、请简要说明一下JSP和Servlet有哪些相同点和不同点?另外他们之间的联系又是什么呢?
JSP 是Servlet技术的扩展,本质上是Servlet的简易方式,更强调应用的外表表达。JSP编译后是”类servlet”。Servlet和JSP最主要的不同点在于,Servlet的应用逻辑是在Java文件中,并且完全从表示层中的HTML里分离开来。而JSP的情况是Java和HTML可以组合成一个扩展名为.jsp的文件。JSP侧重于视图,Servlet主要用于控制逻辑。
115、请说明一下JSP的内置对象以及该对象的使用方法。
request表示HttpServletRequest对象。它包含了有关浏览器请求的信息,并且提供了几个用于获取cookie, header, 和session数据的有用的方法。
response表示HttpServletResponse对象,并提供了几个用于设置送回浏览器的响应的方法(如cookies,头信息等)
out对象是javax.jsp.JspWriter的一个实例,并提供了几个方法使你能用于向浏览器回送输出结果。
pageContext表示一个javax.servlet.jsp.PageContext对象。它是用于方便存取各种范围的名字空间、servlet相关的对象的API,并且包装了通用的servlet相关功能的方法。
session表示一个请求的javax.servlet.http.HttpSession对象。Session可以存贮用户的状态信息
applicaton 表示一个javax.servle.ServletContext对象。这有助于查找有关servlet引擎和servlet环境的信息
config表示一个javax.servlet.ServletConfig对象。该对象用于存取servlet实例的初始化参数。
page表示从该页面产生的一个servlet实例
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
116、请谈谈你对Javaweb开发中的监听器的理解?
Java Web开发中的监听器(listener)就是application、session、request三个对象创建、销毁或者往其中添加修改删除属性时自动执行代码的功能组件,如下所示:
①ServletContextListener:对Servlet上下文的创建和销毁进行监听。
②ServletContextAttributeListener:监听Servlet上下文属性的添加、删除和替换。
③HttpSessionListener:对Session的创建和销毁进行监听。
- 1
- 2
- 3
session的销毁有两种情况:
1). session超时(可以在web.xml中通过<session-config>/<session-timeout>标签配置超时时间)
2). 通过调用session对象的invalidate()方法使session失效。
④HttpSessionAttributeListener:对Session对象中属性的添加、删除和替换进行监听。
⑤ServletRequestListener:对请求对象的初始化和销毁进行监听。
⑥ServletRequestAttributeListener:对请求对象属性的添加、删除和替换进行监听。
- 1
- 2
- 3
117、请问过滤器有哪些作用?以及过滤器的用法又是什么呢?
Java Web开发中的过滤器(filter)是从Servlet 2.3规范开始增加的功能,并在Servlet 2.4规范中得到增强。对Web应用来说,过滤器是一个驻留在服务器端的Web组件,它可以截取客户端和服务器之间的请求与响应信息,并对这些信息进行过滤。当Web容器接受到一个对资源的请求时,它将判断是否有过滤器与这个资源相关联。如果有,那么容器将把请求交给过滤器进行处理。在过滤器中,你可以改变请求的内容,或者重新设置请求的报头信息,然后再将请求发送给目标资源。当目标资源对请求作出响应时候,容器同样会将响应先转发给过滤器,在过滤器中你可以对响应的内容进行转换,然后再将响应发送到客户端。
常见的过滤器用途主要包括:对用户请求进行统一认证、对用户的访问请求进行记录和审核、对用户发送的数据进行过滤或替换、转换图象格式、对响应内容进行压缩以减少传输量、对请求或响应进行加解密处理、触发资源访问事件、对XML的输出应用XSLT等。
和过滤器相关的接口主要有:Filter、FilterConfig和FilterChain。
118、请问redis的List能在什么场景下使用?
Redis 中list的数据结构实现是双向链表,所以可以非常便捷的应用于消息队列(生产者 / 消费者模型)。消息的生产者只需要通过lpush将消息放入 list,消费者便可以通过rpop取出该消息,并且可以保证消息的有序性。如果需要实现带有优先级的消息队列也可以选择sorted set。而pub/sub功能也可以用作发布者 / 订阅者模型的消息。
119、请分别介绍一下aof和rdb都有哪些优点?以及两者有何区别?
RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot)。
AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。 AOF 文件中的命令全部以 Redis 协议的格式来保存,新命令会被追加到文件的末尾。 Redis 还可以在后台对 AOF 文件进行重写(rewrite),使得 AOF 文件的体积不会超出保存数据集状态所需的实际大小。Redis 还可以同时使用 AOF 持久化和 RDB 持久化。 在这种情况下, 当 Redis 重启时, 它会优先使用 AOF 文件来还原数据集, 因为 AOF 文件保存的数据集通常比 RDB 文件所保存的数据集更完整。你甚至可以关闭持久化功能,让数据只在服务器运行时存在。
RDB 的优点:
RDB 是一个非常紧凑(compact)的文件,它保存了 Redis 在某个时间点上的数据集。 这种文件非常适合用于进行备份: 比如说,你可以在最近的 24 小时内,每小时备份一次 RDB 文件,并且在每个月的每一天,也备份一个 RDB 文件。 这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本。RDB 非常适用于灾难恢复(disaster recovery):它只有一个文件,并且内容都非常紧凑,可以(在加密后)将它传送到别的数据中心,或者亚马逊 S3 中。RDB 可以最大化 Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
RDB 的缺点:
如果你需要尽量避免在服务器故障时丢失数据,那么 RDB 不适合你。 虽然 Redis 允许你设置不同的保存点(save point)来控制保存 RDB 文件的频率, 但是, 因为RDB 文件需要保存整个数据集的状态, 所以它并不是一个轻松的操作。 因此你可能会至少 5 分钟才保存一次 RDB 文件。 在这种情况下, 一旦发生故障停机, 你就可能会丢失好几分钟的数据。每次保存 RDB 的时候,Redis 都要 fork() 出一个子进程,并由子进程来进行实际的持久化工作。 在数据集比较庞大时, fork() 可能会非常耗时,造成服务器在某某毫秒内停止处理客户端; 如果数据集非常巨大,并且 CPU 时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒。 虽然 AOF 重写也需要进行 fork() ,但无论 AOF 重写的执行间隔有多长,数据的耐久性都不会有任何损失。
AOF 的优点:
使用 AOF 持久化会让 Redis 变得非常耐久(much more durable):你可以设置不同的 fsync 策略,比如无 fsync ,每秒钟一次 fsync ,或者每次执行写入命令时 fsync 。 AOF 的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync 会在后台线程执行,所以主线程可以继续努力地处理命令请求)。AOF 文件是一个只进行追加操作的日志文件(append only log), 因此对 AOF 文件的写入不需要进行 seek , 即使日志因为某些原因而包含了未写入完整的命令(比如写入时磁盘已满,写入中途停机,等等), redis-check-aof 工具也可以轻易地修复这种问题。
Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
AOF 的缺点:
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。AOF 在过去曾经发生过这样的 bug : 因为个别命令的原因,导致 AOF 文件在重新载入时,无法将数据集恢复成保存时的原样。 (举个例子,阻塞命令 BRPOPLPUSH 就曾经引起过这样的 bug 。) 测试套件里为这种情况添加了测试: 它们会自动生成随机的、复杂的数据集, 并通过重新载入这些数据来确保一切正常。 虽然这种 bug 在 AOF 文件中并不常见, 但是对比来说, RDB 几乎是不可能出现这种 bug 的。
120、简单说一说,缓存的优点是什么?
1、减少了对数据库的读操作,数据库的压力降低
2、加快了响应速度
121、请问,redis为什么是单线程?
因为CPU不是Redis的瓶颈。Redis的瓶颈最有可能是机器内存或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。缺点:服务器其他核闲置。
122、请问,为什么 redis 读写速率快、性能好?
Redis是纯内存数据库,相对于读写磁盘,读写内存的速度就不是几倍几十倍了,一般hash查找可以达到每秒百万次的数量级。
多路复用IO,“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗)。可以直接理解为:单线程的原子操作,避免上下文切换的时间和性能消耗;加上对内存中数据的处理速度,很自然的提高redis的吞吐量。
123、讲一下redis的主从复制怎么做的?
第一阶段:与master建立连接
第二阶段:向master发起同步请求(SYNC)
第三阶段:接受master发来的RDB数据
第四阶段:载入RDB文件
- 1
- 2
- 3
- 4
- 5
- 6
- 7
124、谈一下,什么是DAO模式?
DAO(Data Access Object)顾名思义是一个为数据库或其他持久化机制提供了抽象接口的对象,在不暴露底层持久化方案实现细节的前提下提供了各种数据访问操作。在实际的开发中,应该将所有对数据源的访问操作进行抽象化后封装在一个公共API中。用程序设计语言来说,就是建立一个接口,接口中定义了此应用程序中将会用到的所有事务方法。在这个应用程序中,当需要和数据源进行交互的时候则使用这个接口,并且编写一个单独的类来实现这个接口,在逻辑上该类对应一个特定的数据存储。DAO模式实际上包含了两个模式,一是Data Accessor(数据访问器),二是Data Object(数据对象),前者要解决如何访问数据的问题,而后者要解决的是如何用对象封装数据。
125、说一说,MVC的各个部分都有那些技术来实现?如何实现?
MVC 是Model-View-Controller的简写。”Model” 代表的是应用的业务逻辑(通过JavaBean,EJB组件实现), “View” 是应用的表示面,用于与用户的交互(由JSP页面产生),”Controller” 是提供应用的处理过程控制(一般是一个Servlet),通过这种设计模型把应用逻辑,处理过程和显示逻辑分成不同的组件实现。这些组件可以进行交互和重用。
model层实现系统中的业务逻辑,view层用于与用户的交互,controller层是model与view之间沟通的桥梁,可以分派用户的请求并选择恰当的视图以用于显示,同时它也可以解释用户的输入并将它们映射为模型层可执行的操作。
126、谈一谈,使用标签库有什么好处?如何自定义JSP标签?
使用标签库的好处包括以下几个方面:
- 分离JSP页面的内容和逻辑,简化了Web开发;
- 开发者可以创建自定义标签来封装业务逻辑和显示逻辑;
- 标签具有很好的可移植性、可维护性和可重用性;
- 避免了对Scriptlet(小脚本)的使用(很多公司的项目开发都不允许在JSP中书写小脚本)
- 1
- 2
- 3
- 4
编写一个Java类实现实现Tag/BodyTag/IterationTag接口(开发中通常不直接实现这些接口而是继承TagSupport/BodyTagSupport/SimpleTagSupport类,这是对缺省适配模式的应用),重写doStartTag()、doEndTag()等方法,定义标签要完成的功能:
- 编写扩展名为tld的标签描述文件对自定义标签进行部署,tld文件通常放在WEB-INF文件夹下或其子目录中
- 在JSP页面中使用taglib指令引用该标签库
127、请说说你做过的项目中,使用过哪些JSTL标签?
项目中主要使用了JSTL的核心标签库,包括<c:if>、<c:choose>、<c: when>、<c: otherwise>、<c:forEach>等,主要用于构造循环和分支结构以控制显示逻辑。
虽然JSTL标签库提供了core、sql、fmt、xml等标签库,但是实际开发中建议只使用核心标签库(core),而且最好只使用分支和循环标签并辅以表达式语言(EL),这样才能真正做到数据显示和业务逻辑的分离,这才是最佳实践。
128、请谈谈,转发和重定向之间的区别?
forward是容器中控制权的转向,是服务器请求资源,服务器直接访问目标地址的URL,把那个URL 的响应内容读取过来,然后把这些内容再发给浏览器,浏览器根本不知道服务器发送的内容是从哪儿来的,所以它的地址栏中还是原来的地址。redirect就是服务器端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址,因此从浏览器的地址栏中可以看到跳转后的链接地址,很明显redirect无法访问到服务器保护起来资源,但是可以从一个网站redirect到其他网站。forward更加高效,所以在满足需要时尽量使用forward(通过调用RequestDispatcher对象的forward()方法,该对象可以通过ServletRequest对象的getRequestDispatcher()方法获得),并且这样也有助于隐藏实际的链接;在有些情况下,比如需要访问一个其它服务器上的资源,则必须使用重定向(通过HttpServletResponse对象调用其sendRedirect()方法实现)。
129、请谈一谈,get和post的区别?
1)在客户端, Get 方式在通过 URL 提交数据,数据 在URL中可以看到;POST方式,数据放置在HTML HEADER内提交。
2)GET方式提交的数据最多只能有1024字节,而POST则没有此限制。
3)安全性问题。正如在( 1 )中提到,使用 Get 的时候,参数会显示在地址栏上,而 Post 不会。所以,如果这些数据是中文数据而且是非敏感数据,那么使用 get ;如果用户输入的数据不是中文字符而且包含敏感数据,那么还是使用 post 为好。
安全的和幂等的。所谓安全的意味着该操作用于获取信息而非修改信息。幂等的意味着对同一 URL 的多个请求应该返回同样的结果。完整的定义并不像看起来那样严格。换句话说, GET 请求一般不应产生副作用。从根本上讲,其目标是当用户打开一个链接时,她可以确信从自身的角度来看没有改变资源。比如,新闻站点的头版不断更新。虽然第二次请求会返回不同的一批新闻,该操作仍然被认为是安全的和幂等的,因为它总是返回当前的新闻。反之亦然。 POST 请求就不那么轻松了。 POST 表示可能改变服务器上的资源的请求。仍然以新闻站点为例,读者对文章的注解应该通过 POST 请求实现,因为在注解提交之后站点已经不同了(比方说文章下面出现一条注解)。
130、请你解释一下,什么是Web Service?
从表面上看,Web Service就是一个应用程序,它向外界暴露出一个能够通过Web进行调用的API。这就是说,你能够用编程的方法透明的调用这个应用程序,不需要了解它的任何细节,跟你使用的编程语言也没有关系。例如可以创建一个提供天气预报的Web Service,那么无论你用哪种编程语言开发的应用都可以通过调用它的API并传入城市信息来获得该城市的天气预报。之所以称之为Web Service,是因为它基于HTTP协议传输数据,这使得运行在不同机器上的不同应用无须借助附加的、专门的第三方软件或硬件,就可相互交换数据或集成。
SOA(Service-Oriented Architecture,面向服务的架构),SOA是一种思想,它将应用程序的不同功能单元通过中立的契约联系起来,独立于硬件平台、操作系统和编程语言,使得各种形式的功能单元能够更好的集成。显然,Web Service是SOA的一种较好的解决方案,它更多的是一种标准,而不是一种具体的技术。
131、请你说说,cookie 和 session 的区别?
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗
考虑到安全应当使用session。
3、session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用COOKIE。
4、单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
132、现在有一个学生表,一个课程成绩表,请问,怎么找出学生课程的最高分数,谈一谈思路(即找出每个学生的最高成绩)
select s.name, b.score from student s,
(select sid, max(score) as score from score group by sid) as b
where s.sid=b.sid
- 1
- 2
- 3
- 4
- 5
思路:首先找到每个学生的最高成绩,作为一张临时表表(学生,最高成绩),然后跟学生表关联查询,查到学生姓名和学生最高成绩。
133、请你讲解一下数据连接池的工作机制?
J2EE 服务器启动时会建立一定数量的池连接,并一直维持不少于此数目的池连接。客户端程序需要连接时,池驱动程序会返回一个未使用的池连接并将其表记为忙。如果当前没有空闲连接,池驱动程序就新建一定数量的连接,新建连接的数量由配置参数决定。当使用的池连接调用完成后,池驱动程序将此连接表记为空闲,其他调用就可以使用这个连接。
134、你了解继承映射吗,请简单讲讲你的理解
继承关系的映射策略有三种:
① 每个继承结构一张表(table per class hierarchy),不管多少个子类都用一张表。
② 每个子类一张表(table per subclass),公共信息放一张表,特有信息放单独的表。
③ 每个具体类一张表(table per concrete class),有多少个子类就有多少张表。
- 1
- 2
- 3
第一种方式属于单表策略,其优点在于查询子类对象的时候无需表连接,查询速度快,适合多态查询;缺点是可能导致表很大。后两种方式属于多表策略,其优点在于数据存储紧凑,其缺点是需要进行连接查询,不适合多态查询。
135、请你介绍一下 mysql的主从复制?
MySQL主从复制是其最重要的功能之一。主从复制是指一台服务器充当主数据库服务器,另一台或多台服务器充当从数据库服务器,主服务器中的数据自动复制到从服务器之中。对于多级复制,数据库服务器即可充当主机,也可充当从机。MySQL主从复制的基础是主服务器对数据库修改记录二进制日志,从服务器通过主服务器的二进制日志自动执行更新。
MySQL主从复制的两种情况:同步复制和异步复制,实际复制架构中大部分为异步复制。
复制的基本过程如下:
1、Slave上面的IO进程连接上Master,并请求从指定日志文件的指定位置(或者从最开始的日志)之后的日志内容。
2、Master接收到来自Slave的IO进程的请求后,负责复制的IO进程会根据请求信息读取日志指定位置之后的日志信息,返回给Slave的IO进程。返回信息中除了日志所包含的信息之外,还包括本次返回的信息已经到Master端的bin-log文件的名称以及bin-log的位置。
3、Slave的IO进程接收到信息后,将接收到的日志内容依次添加到Slave端的relay-log文件的最末端,并将读取到的Master端的 bin-log的文件名和位置记录到master-info文件中,以便在下一次读取的时候能够清楚的告诉Master“我需要从某个bin-log的哪个位置开始往后的日志内容,请发给我”。
4、Slave的Sql进程检测到relay-log中新增加了内容后,会马上解析relay-log的内容成为在Master端真实执行时候的那些可执行的内容,并在自身执行。
136、请你介绍一下数据库的隔离级别
| 隔离级别 | 脏读(Dirty Read) | 不可重复读(NonRepeatable Read) | 幻读(Phantom Read) |
|---|---|---|---|
| 未提交读(Read uncommitted) | 可能 | 可能 | 可能 |
| 已提交读(Read committed) | 不可能 | 可能 | 可能 |
| 可重复读(Repeatable read) | 不可能 | 不可能 | 可能 |
| 可串行化(Serializable ) | 不可能 | 不可能 | 不可能 |
1、未提交读(Read Uncommitted):允许脏读,也就是可能读取到其他会话中未提交事务修改的数据。
2、提交读(Read Committed):只能读取到已经提交的数据。Oracle等多数数据库默认都是该级别 (不重复读)。
3、可重复读(Repeated Read):可重复读。在同一个事务内的查询都是事务开始时刻一致的,InnoDB默认级别。在SQL标准中,该隔离级别消除了不可重复读,但是还存在幻象读。
4、串行读(Serializable):完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞。
- 1
- 2
- 3
- 4
137、简单说明一下,数据库索引底层是怎样实现的,哪些情况下索引会失效
B+树实现的。
没有遵循最左匹配原则。
一些关键字会导致索引失效,例如 or, != , not in,is null ,is not unll
like查询是以%开头
隐式转换会导致索引失效。
对索引应用内部函数,索引字段进行了运算。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
138、请你说一说,mysql数据库的两种引擎 区别
InnoDB是聚集索引,支持事务,支持行级锁;MyISAM是非聚集索引,不支持事务,只支持表级锁。
139、请介绍一下,数据库索引,以及,什么时候用Innodb什么时候用MyISAM。
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。如果想按特定职员的姓来查找他或她,则与在表中搜索所有的行相比,索引有助于更快地获取信息。索引的一个主要目的就是加快检索表中数据的方法,亦即能协助信息搜索者尽快的找到符合限制条件的记录ID的辅助数据结构。InnoDB主要面向在线事务处理(OLTP)的应用。MyISAM主要面向一些OLAP的应用。
①InnoDB支持事务与外键和行级锁,MyISAM不支持(最主要的差别)
②MyISAM读性能要优于InnoDB,除了针对索引的update操作,MyISAM的写性能可能低于InnoDB,其他操作MyISAM的写性能也是优于InnoDB的,而且可以通过分库分表来提高MyISAM写操作的速度
③MyISAM的索引和数据是分开的,而且索引是压缩的,而InnoDB的索引和数据是紧密捆绑的,没有使用压缩,所以InnoDB的体积比MyISAM庞大
- 1
- 2
- 3
MyISAM引擎索引结构的叶子节点的数据域,存放的并不是实际的数据记录,而是数据记录的地址。索引文件与数据文件分离,这样的索引称为“非聚簇索引”。其检索算法:先按照B+Tree的检索算法检索,找到指定关键字,则取出对应数据域的值,作为地址取出数据记录。
InnoDB引擎索引结构的叶子节点的数据域,存放的就是实际的数据记录。这样的索引被称为“聚簇索引”,一个表只能有一个聚簇索引。
④InnoDB 中不保存表的具体行数,也就是说,执行select count(*) from table时,InnoDB要扫描一遍整个表来计算有多少行,但是MyISAM只要简单的读出保存好的行数即可。注意的是,当count(*)语句包含 where条件时,两种表的操作是一样的。
⑤DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除。
⑥InnoDB表的行锁也不是绝对的,假如在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表,例如update table set num=1 where name like “%aaa%”
在where条件没有主键时,InnoDB照样会锁全表
- 1
- 2
- 3
- 4
- 5
选择哪种搜索引擎,应视具体应用而定
- ①如果是读多写少的项目,可以考虑使用MyISAM,MYISAM索引和数据是分开的,而且其索引是压缩的,可以更好地利用内存。所以它的查询性能明显优于INNODB。压缩后的索引也能节约一些磁盘空间。MYISAM拥有全文索引的功能,这可以极大地优化LIKE查询的效率。
- ②如果你的应用程序一定要使用事务,毫无疑问你要选择INNODB引擎
- ③如果是用MyISAM的话,merge引擎可以大大加快应用部门的开发速度,他们只要对这个merge表做一些select count(*)操作,非常适合大项目总量约几亿的rows某一类型(如日志,调查统计)的业务表。
140、请你简单介绍一下,数据库水平切分与垂直切分
垂直拆分就是要把表按模块划分到不同数据库表中(当然原则还是不破坏第三范式),这种拆分在大型网站的演变过程中是很常见的。当一个网站还在很小的时候,只有小量的人来开发和维护,各模块和表都在一起,当网站不断丰富和壮大的时候,也会变成多个子系统来支撑,这时就有按模块和功能把表划分出来的需求。其实,相对于垂直切分更进一步的是服务化改造,说得简单就是要把原来强耦合的系统拆分成多个弱耦合的服务,通过服务间的调用来满足业务需求看,因此表拆出来后要通过服务的形式暴露出去,而不是直接调用不同模块的表,淘宝在架构不断演变过程,最重要的一环就是服务化改造,把用户、交易、店铺、宝贝这些核心的概念抽取成独立的服务,也非常有利于进行局部的优化和治理,保障核心模块的稳定性。
垂直拆分:单表大数据量依然存在性能瓶颈
水平拆分,上面谈到垂直切分只是把表按模块划分到不同数据库,但没有解决单表大数据量的问题,而水平切分就是要把一个表按照某种规则把数据划分到不同表或数据库里。例如像计费系统,通过按时间来划分表就比较合适,因为系统都是处理某一时间段的数据。而像SaaS应用,通过按用户维度来划分数据比较合适,因为用户与用户之间的隔离的,一般不存在处理多个用户数据的情况,简单的按user_id范围来水平切分。
通俗理解:水平拆分行,行数据拆分到不同表中, 垂直拆分列,表数据拆分到不同表中。
141、谈一谈,JDBC中如何进行事务处理?
Connection提供了事务处理的方法,通过调用setAutoCommit(false)可以设置手动提交事务;当事务完成后用commit()显式提交事务;如果在事务处理过程中发生异常则通过rollback()进行事务回滚。除此之外,从JDBC 3.0中还引入了Savepoint(保存点)的概念,允许通过代码设置保存点并让事务回滚到指定的保存点。
142、我们使用JDBC操作数据库时,经常遇到性能问题,请你说明一下如何提升读取数据的性能,以及更新数据的性能?
要提升读取数据的性能,可以指定通过结果集(ResultSet)对象的setFetchSize()方法指定每次抓取的记录数(典型的空间换时间策略);要提升更新数据的性能可以使用PreparedStatement语句构建批处理,将若干SQL语句置于一个批处理中执行。
143、请你讲讲 Statement 和 PreparedStatement 的区别?哪个性能更好?
与Statement相比:
- ①PreparedStatement接口代表预编译的语句,它主要的优势在于可以减少SQL的编译错误并增加SQL的安全性(减少SQL注射攻击的可能性);
- ②PreparedStatement中的SQL语句是可以带参数的,避免了用字符串连接拼接SQL语句的麻烦和不安全;
- ③当批量处理SQL或频繁执行相同的查询时,PreparedStatement有明显的性能上的优势,由于数据库可以将编译优化后的SQL语句缓存起来,下次执行相同结构的语句时就会很快(不用再次编译和生成执行计划)。
为了提供对存储过程的调用,JDBC API中还提供了CallableStatement接口。存储过程(Stored Procedure)是数据库中一组为了完成特定功能的SQL语句的集合,经编译后存储在数据库中,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。虽然调用存储过程会在网络开销、安全性、性能上获得很多好处,但是存在如果底层数据库发生迁移时就会有很多麻烦,因为每种数据库的存储过程在书写上存在不少的差别。
144、请你解释一下Jdo以及它的作用
JDO 是Java对象持久化的新的规范,为java data object的简称,也是一个用于存取某种数据仓库中的对象的标准化API。JDO提供了透明的对象存储,因此对开发人员来说,存储数据对象完全不需要额外的代码(如JDBC API的使用)。这些繁琐的例行工作已经转移到JDO产品提供商身上,使开发人员解脱出来,从而集中时间和精力在业务逻辑上。另外,JDO很灵活,因为它可以在任何数据底层上运行。JDBC只是面向关系数据库(RDBMS)JDO更通用,提供到任何数据底层的存储功能,比如关系数据库、文件、XML以及对象数据库(ODBMS)等等,使得应用可移植性更强。
145、请你谈谈JDBC的反射,以及它的作用?
通过反射com.mysql.jdbc.Driver类,实例化该类的时候会执行该类内部的静态代码块,该代码块会在Java实现的DriverManager类中注册自己,DriverManager管理所有已经注册的驱动类,当调用DriverManager.geConnection方法时会遍历这些驱动类,并尝试去连接数据库,只要有一个能连接成功,就返回Connection对象,否则则报异常。
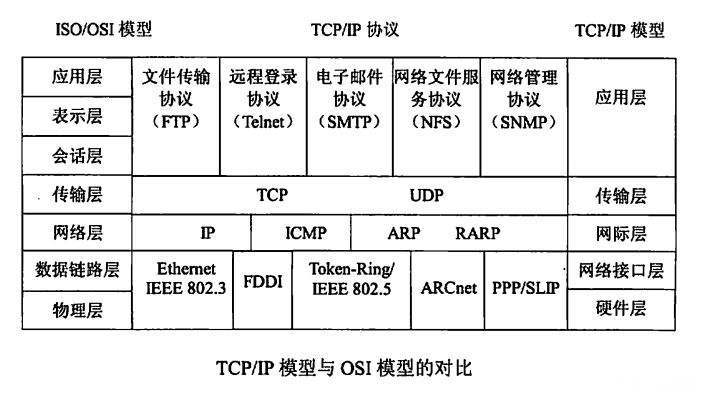
146、你知道TCP协议、IP协议、HTTP协议分别在哪一层吗?
运输层,网络层,应用层。
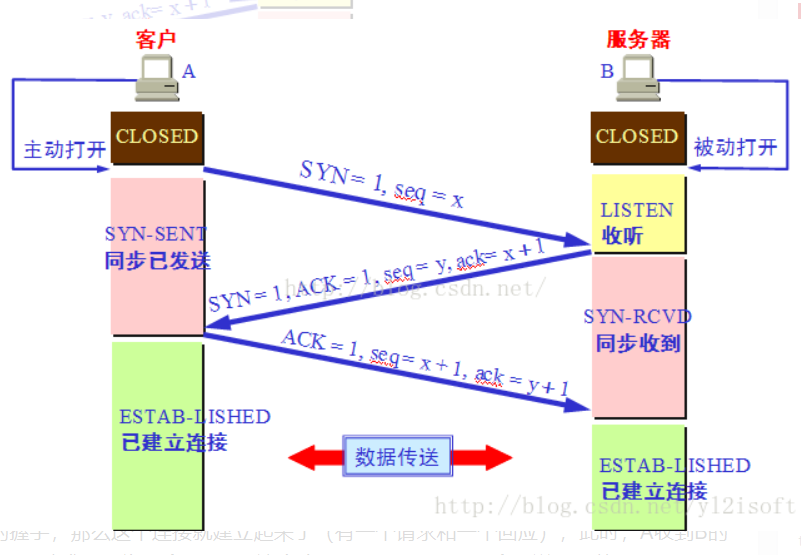
147、简单描述一下,TCP的连接和释放过程。
三次握手的过程
1)主机A向主机B发送TCP连接请求数据包,其中包含主机A的初始序列号seq(A)=x。(其中报文中同步标志位SYN=1,ACK=0,表示这是一个TCP连接请求数据报文;序号seq=x,表明传输数据时的第一个数据字节的序号是x);
2)主机B收到请求后,会发回连接确认数据包。(其中确认报文段中,标识位SYN=1,ACK=1,表示这是一个TCP连接响应数据报文,并含主机B的初始序列号seq(B)=y,以及主机B对主机A初始序列号的确认号ack(B)=seq(A)+1=x+1)
3)第三次,主机A收到主机B的确认报文后,还需作出确认,即发送一个序列号seq(A)=x+1;确认号为ack(A)=y+1的报文;
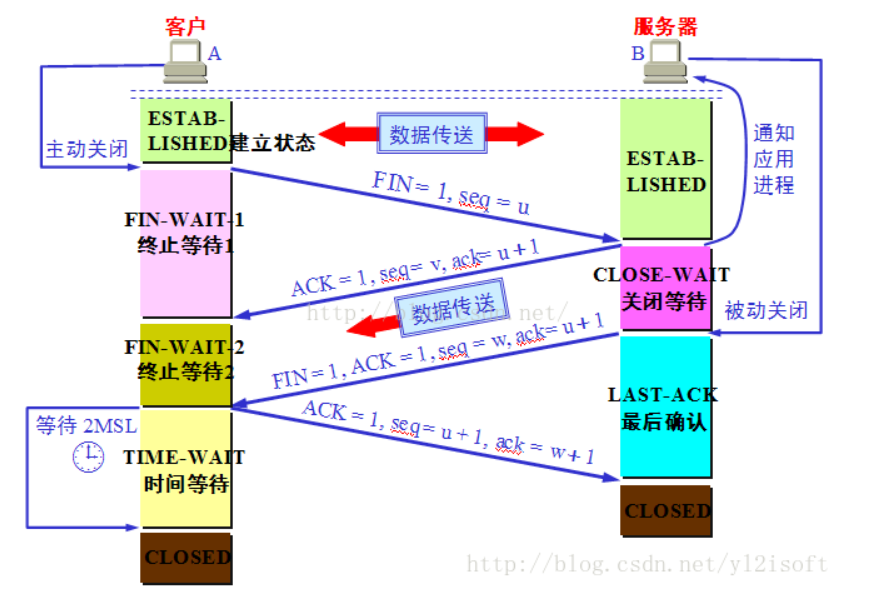
四次挥手过程
假设主机A为客户端,主机B为服务器,其释放TCP连接的过程如下:
1) 关闭客户端到服务器的连接:首先客户端A发送一个FIN,用来关闭客户到服务器的数据传送,然后等待服务器的确认。其中终止标志位FIN=1,序列号seq=u。
2) 服务器收到这个FIN,它发回一个ACK,确认号ack为收到的序号加1。
3) 关闭服务器到客户端的连接:也是发送一个FIN给客户端。
4) 客户段收到FIN后,并发回一个ACK报文确认,并将确认序号seq设置为收到序号加1。 首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
148、请解释一下,http请求中的304状态码的含义
304(未修改)自从上次请求后,请求的网页未修改过。服务器返回此响应时,不会返回网页内容。如果网页自请求者上次请求后再也没有更改过,您应将服务器配置为返回此响应(称为 If-Modified-Since HTTP 标头)。服务器可以告诉 Googlebot 自从上次抓取后网页没有变更,进而节省带宽和开销。
149、请你说明一下,SSL四次握手的过程
1、 客户端发出请求
- 1
首先,客户端(通常是浏览器)先向服务器发出加密通信的请求,这被叫做ClientHello请求。
2、服务器回应
- 1
服务器收到客户端请求后,向客户端发出回应,这叫做SeverHello。
3、客户端回应
客户端收到服务器回应以后,首先验证服务器证书。如果证书不是可信机构颁布、或者证书中的域名与实际域名不一致、或者证书已经过期,就会向访问者显示一个警告,由其选择是否还要继续通信。
4、服务器的最后回应
服务器收到客户端的第三个随机数pre-master key之后,计算生成本次会话所用的"会话密钥"。然后,向客户端最后发送下面信息。
(1)编码改变通知,表示随后的信息都将用双方商定的加密方法和密钥发送。
(2)服务器握手结束通知,表示服务器的握手阶段已经结束。这一项同时也是前面发送的所有内容的hash值,用来供客户端校验。
至此,整个握手阶段全部结束。接下来,客户端与服务器进入加密通信,就完全是使用普通的HTTP协议,只不过用"会话密钥"加密内容。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
150、请你讲讲http1.1和1.0的区别
主要区别主要体现在:
缓存处理,在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
带宽优化及网络连接的使用,HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
错误通知的管理,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
Host头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
长连接,HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。
151、请谈一下,你知道的http请求,并说明应答码502和504的区别
考察点:http协议 参考回答: OPTIONS:返回服务器针对特定资源所支持的HTTP请求方法。也可以利用向Web服务器发送'*'的请求来测试服务器的功能性。 HEAD:向服务器索要与GET请求相一致的响应,只不过响应体将不会被返回。这一方法可以在不必传输整个响应内容的情况下,就可以获取包含在响应消息头中的元信息。 GET:向特定的资源发出请求。 POST:向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的创建和/或已有资源的修改。 PUT:向指定资源位置上传其最新内容。 DELETE:请求服务器删除Request-URI所标识的资源。 TRACE:回显服务器收到的请求,主要用于测试或诊断。 CONNECT:HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 虽然HTTP的请求方式有8种,但是我们在实际应用中常用的也就是get和post,其他请求方式也都可以通过这两种方式间接的来实现。 502:作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。 504:作为网关或者代理工作的服务器尝试执行请求时,未能及时从上游服务器(URI标识出的服务器,例如HTTP、FTP、LDAP)或者辅助服务器(例如DNS)收到响应。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
152、 请说明一下http和https的区别
考察点:http协议
参考回答;
https协议要申请证书到ca,需要一定经济成本;2) http是明文传输,https是加密的安全传输;3) 连接的端口不一样,http是80,https是443;4)http连接很简单,没有状态;https是ssl加密的传输,身份认证的网络协议,相对http传输比较安全。
- 1
- 2
- 3
- 4
- 5
153、请讲一下浏览器从接收到一个URL,到最后展示出页面,经历了哪些过程。
考察点:http协议
参考回答:
1.DNS解析 2.TCP连接 3.发送HTTP请求 4.服务器处理请求并返回HTTP报文 5.浏览器解析渲染页面
- 1
- 2
- 3
- 4
154、请简单解释一下,arp协议和arp攻击。
考察点:ARP协议
参考回答:
地址解析协议。ARP攻击的第一步就是ARP欺骗。由上述“ARP协议的工作过程”我们知道,ARP协议基本没有对网络的安全性做任何思考,当时人们考虑的重点是如何保证网络通信能够正确和快速的完成——ARP协议工作的前提是默认了其所在的网络是一个善良的网络,每台主机在向网络中发送应答信号时都是使用的真实身份。不过后来,人们发现ARP应答中的IP地址和MAC地址中的信息是可以伪造的,并不一定是自己的真实IP地址和MAC地址,由此,ARP欺骗就产生了。
- 1
- 2
- 3
- 4
155、什么是icmp协议,它的作用是什么?
考察点:ICMP协议
参考回答:
它是TCP/IP协议族的一个子协议,用于在IP主机、路由器之间传递控制消息。控制消息是指网络通不通、主机是否可达、路由是否可用等网络本身的消息。这些控制消息虽然并不传输用户数据,但是对于用户数据的传递起着重要的作用。
- 1
- 2
- 3
- 4
156、请你讲一下路由器和交换机的区别?
考察点:路由器
参考回答:
1、工作层次不同:交换机比路由器更简单,路由器比交换器能获取更多信息
交换机工作在数据链路层,而路由器工作在网络层
2、数据转发所依据的对象不同
交换机的数据转发依据是利用物理地址或者说MAC地址来确定转发数据的目的地址
而路由器是依据ip地址进行工作的
3、传统的交换机只能分割冲突域,不能分割广播域;而路由器可以分割广播域
4、路由器有交换机的功能,但是路由器比交换机复杂的多
【补充:】
1、工作层次不同,一个是网络层、一个是数据链路层
2、寻址依据不同,一个是基于IP寻址,一个基于MAC寻址
3、交换机分割冲突域,不划分广播域,即隶属一个交换机的主机属于一个局域网。通过路由器连接的主机可能数据不同的广播域,所以路由器可以划分广播域
4、转发的数据对象不同 ,交换机转发的是数据帧、路由器转发的是分组报文
157、请你谈谈DNS的寻址过程。
考察点:DNS
参考回答:
(1)检查浏览器缓存、检查本地hosts文件是否有这个网址的映射,如果有,就调用这个IP地址映射,解析完成。
(2)如果没有,则查找本地DNS解析器缓存是否有这个网址的映射,如果有,返回映射,解析完成。
(3)如果没有,则查找填写或分配的首选DNS服务器,称为本地DNS服务器。服务器接收到查询时:
如果要查询的域名包含在本地配置区域资源中,返回解析结果,查询结束,此解析具有权威性。
如果要查询的域名不由本地DNS服务器区域解析,但服务器缓存了此网址的映射关系,返回解析结果,查询结束,此解析不具有权威性。
(4)如果本地DNS服务器也失效:
如果未采用转发模式(迭代),本地DNS就把请求发至13台根DNS,根DNS服务器收到请求后,会判断这个域名(如.com)是谁来授权管理,并返回一个负责该顶级域名服务器的IP,本地DNS服务器收到顶级域名服务器IP信息后,继续向该顶级域名服务器IP发送请求,该服务器如果无法解析,则会找到负责这个域名的下一级DNS服务器(如http://baidu.com)的IP给本地DNS服务器,循环往复直至查询到映射,将解析结果返回本地DNS服务器,再由本地DNS服务器返回解析结果,查询完成。
如果采用转发模式(递归),则此DNS服务器就会把请求转发至上一级DNS服务器,如果上一级DNS服务器不能解析,则继续向上请求。最终将解析结果依次返回本地DNS服务器,本地DNS服务器再返回给客户机,查询完成。
- 1
158、请你简单讲解一下,负载均衡 反向代理模式的优点、缺点
考察点:反向代理
参考回答:
-
(1)反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器。
-
(2)反向代理负载均衡技术是把将来自internet上的连接请求以反向代理的方式动态地转发给内部网络上的多台服务器进行处理,从而达到负载均衡的目的。
-
(3)反向代理负载均衡能以软件方式来实现,如apache mod_proxy、netscape proxy等,也可以在高速缓存器、负载均衡器等硬件设备上实现。反向代理负载均衡可以将优化的负载均衡策略和代理服务器的高速缓存技术结合在一起,提升静态网页的访问速度,提供有益的性能;由于网络外部用户不能直接访问真实的服务器,具备额外的安全性(同理,NAT负载均衡技术也有此优点)。
-
(4)其缺点主要表现在以下两个方面
反向代理是处于OSI参考模型第七层应用的,所以就必须为每一种应用服务专门开发一个反向代理服务器,这样就限制了反向代理负载均衡技术的应用范围,现在一般都用于对web服务器的负载均衡。
针对每一次代理,代理服务器就必须打开两个连接,一个对外,一个对内,因此在并发连接请求数量非常大的时候,代理服务器的负载也就非常大了,在最后代理服务器本身会成为服务的瓶颈。
一般来讲,可以用它来对连接数量不是特别大,但每次连接都需要消耗大量处理资源的站点进行负载均衡,如全局search等。
159、谈谈64位和32位的区别?
考察点:
操作系统
参考回答:
操作系统只是硬件和应用软件中间的一个平台。32位操作系统针对的32位的CPU设计。64位操作系统针对的64位的CPU设计。
1、运行能力不同。64位可以一次性可以处理8个字节的数据量,而32位一次性只可以处理4个字节的数据量,因此64位比32位的运行能力提高了一倍。
2、内存寻址不同。64位最大寻址空间为2的64次方,理论值直接达到了16TB,而32位的最大寻址空间为2的32次方,为4GB,换而言之,就是说32位系统的处理器最大只支持到4G内存,而64位系统最大支持的内存高达亿位数。
3、运行软件不同。由于32位和64位CPU的指令集是不同的。所以需要区分32位和64位版本的软件。
为了保证兼容性,64位CPU上也能运行老的32位指令。于是实际上我们可以在64位CPU上运行32位程序,但是反过来不行。简而言之就是64位的操作系统可以兼容运行32位的软件,反过来32位系统不可以运行64位的软件。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
160、谈谈CentOS 和 Linux的关系?
考察点:操作系统
参考回答:
CentOS是Linux众多得发行版本之一,linux有三大发行版本(:Slackware、debian、redhat),而Redhat有收费的商业版和免费的开源版,商业版的业内称之为RHEL系列,CentOS是来自于依照开放源代码规定而公布的源代码重新编译而成。可以用CentOS替代商业版的RHEL使用。两者的不同,CentOS不包含封闭源代码软件,是免费的。
161、你怎么理解操作系统里的内存碎片,有什么解决办法?
考察点:内存碎片
参考回答:
内存碎片分为:内部碎片和外部碎片。
内部碎片就是已经被分配出去(能明确指出属于哪个进程)却不能被利用的内存空间;
内部碎片是处于区域内部或页面内部的存储块。占有这些区域或页面的进程并不使用这个存储块。而在进程占有这块存储块时,系统无法利用它。直到进程释放它,或进程结束时,系统才有可能利用这个存储块。
单道连续分配只有内部碎片。多道固定连续分配既有内部碎片,又有外部碎片。
外部碎片指的是还没有被分配出去(不属于任何进程),但由于太小了无法分配给申请内存空间的新进程的内存空闲区域。
外部碎片是出于任何已分配区域或页面外部的空闲存储块。这些存储块的总和可以满足当前申请的长度要求,但是由于它们的地址不连续或其他原因,使得系统无法满足当前申请。
使用伙伴系统算法。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
162、介绍一下,什么是页式存储?
考察点:页式存储
参考回答:`【自己再行百度】`
主存被等分成大小相等的片,称为主存块,又称为实页。
当一个用户程序装入内存时,以页面为单位进行分配。页面的大小是为2n ,通常为1KB、2KB、2n KB等(是2n不是2n)
- 1
- 2
- 3
- 4
- 5
- 6
163、请谈一谈,系统如何提高并发性?
考察:操作系统综合性
参考回答:
- 1
- 2
- 3
1、提高CPU并发计算能力
(1)多进程&多线程
(2)减少进程切换,使用线程,考虑进程绑定CPU
(3)减少使用不必要的锁,考虑无锁编程
(4)考虑进程优先级
(5)关注系统负载
- 1
- 2
- 3
- 4
- 5
2、改进I/O模型
(1)DMA技术
(2)异步I/O
(3)改进多路I/O就绪通知策略,epoll
(4)Sendfile
(5)内存映射
(6)直接I/O
- 1
- 2
- 3
- 4
- 5
- 6
164、请你解释一下,通常系统CPU比较高是什么原因?
考察点:处理机
参考回答:
1、首先查看是哪些进程的CPU占用率最高(如下可以看到详细的路径)
- 1
- 2
- 3
- 4
ps -aux --sort -pcpu | more
定位有问题的线程可以用如下命令
ps -mp pid -o THREAD,tid,time | more
2、查看JAVA进程的每个线程的CPU占用率
ps -Lp 5798 cu | more # 5798是查出来进程PID
3、追踪线程,查看负载过高的原因,使用JDK下的一个工具
jstack 5798 # 5798是PID
jstack -J-d64 -m 5798 # -j-d64指定64为系统
jstack 查出来的线程ID是16进制,可以把输出追加到文件,导出用记事本打开,再根据系统中的线程ID去搜索查看该ID的线程运行内容,可以和开发一起排查。
165、请说一说,Java中的HashMap的工作原理是什么?
考察点:JAVA哈希表
参考回答:
1.8之后是node 1.7是entry
HashMap类有一个叫做Entry的内部类。这个Entry类包含了key-value作为实例变量。 每当往hashmap里面存放key-value对的时候,都会为它们实例化一个Entry对象,这个Entry对象就会存储在前面提到的Entry数组table中。Entry具体存在table的那个位置是 根据key的hashcode()方法计算出来的hash值(来决定)。
166、介绍一下,什么是hashmap?
考察点:哈希表
参考回答:
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
HashMap 的实例有两个参数影响其性能:“初始容量” 和 “加载因子”。容量 是哈希表中桶的数量,初始容量 只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
hashmap共有4个构造函数:
- 1
// 默认构造函数。HashMap()
// 指定“容量大小”的构造函数
HashMap(int capacity)
- 1
// 指定“容量大小”和“加载因子”的构造函数
HashMap(int capacity, float loadFactor)
- 1
// 包含“子Map”的构造函数
HashMap(Map<? extends K, ? extends V> map)
- 1
167、讲一讲,如何构造一致性 哈希算法。
考察点:哈希算法
参考回答:
先构造一个长度为232的整数环(这个环被称为一致性Hash环),根据节点名称的Hash值(其分布为[0, 232-1])将服务器节点放置在这个Hash环上,然后根据数据的Key值计算得到其Hash值(其分布也为[0, 232-1]),接着在Hash环上顺时针查找距离这个Key值的Hash值最近的服务器节点,完成Key到服务器的映射查找。
这种算法解决了普通余数Hash算法伸缩性差的问题,可以保证在上线、下线服务器的情况下尽量有多的请求命中原来路由到的服务器。
168、请问,Object作为HashMap的key的话,对Object有什么要求吗?
考察点:哈希表
参考回答:
要求Object中hashcode不能变。
169、请问 hashset 存的数是有序的吗?
考察点:哈希
参考回答:
Hashset是无序的。
170、现在有一个单向链表,谈一谈,如何判断链表中是否出现了环
考察点:链表
参考回答:
单链表有环,是指单链表中某个节点的next指针域指向的是链表中在它之前的某一个节点,这样在链表的尾部形成一个环形结构。
链表的节点结构如下 typedef struct node { int data; struct node *next; } NODE;
最常用方法:定义两个指针,同时从链表的头节点出发,一个指针一次走一步,另一个指针一次走两步。如果走得快的指针追上了走得慢的指针,那么链表就是环 形链表;如果走得快的指针走到了链表的末尾(next指向 NULL)都没有追上第一个指针,那么链表就不是环形链表。
通过使用STL库中的map表进行映射。首先定义 map<NODE *, int> m; 将一个 NODE * 指针映射成数组的下标,并赋值为一个 int 类型的数值。然后从链表的头指针开始往后遍历,每次遇到一个指针p,就判断 m[p] 是否为0。如果为0,则将m[p]赋值为1,表示该节点第一次访问;而如果m[p]的值为1,则说明这个节点已经被访问过一次了,于是就形成了环。
- 1
- 2
- 3
- 4
- 5
171、谈一谈,bucket如果用链表存储,它的缺点是什么?
考察点:链表
参考回答:
①查找速度慢,因为查找时,需要循环链表访问
②如果进行频繁插入和删除操作,会导致速度很慢。
- 1
- 2
- 3
172、什么是Java优先级队列(Priority Queue)?
考察点:队列
参考回答:
PriorityQueue是一个基于优先级堆的无界队列,它的元素是按照自然顺序(natural order)排序的。在创建的时候,我们可以给它提供一个负责给元素排序的比较器。PriorityQueue不允许null值,因为他们没有自然顺序,或者说他们没有任何的相关联的比较器。最后,PriorityQueue不是线程安全的,入队和出队的时间复杂度是O(log(n))。
【优先级队列是不同于先进先出队列的另一种队列。每次从队列中取出的是具有最高优先权的元素。PriorityQueue是从JDK1.5开始提供的新的数据结构接口。如果想实现按照自己的意愿进行优先级排列的队列的话,需要实现Comparator接口。如果不提供Comparator的话,优先队列中元素默认按自然顺序排列,也就是数字默认是小的在队列头,字符串则按字典序排列。】
173、请你讲讲LRU算法的实现原理?
考察点:LRU算法
参考回答:
①LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也很高”,反过来说“如果数据最近这段时间一直都没有访问,那么将来被访问的概率也会很低”,两种理解是一样的;常用于页面置换算法,为虚拟页式存储管理服务。
②达到这样一种情形的算法是最理想的:每次调换出的页面是所有内存页面中最迟将被使用的;这可以最大限度的推迟页面调换,这种算法,被称为理想页面置换算法。可惜的是,这种算法是无法实现的。
为了尽量减少与理想算法的差距,产生了各种精妙的算法,最近最少使用页面置换算法便是其中一个。LRU 算法的提出,是基于这样一个事实:在前面几条指令中使用频繁的页面很可能在后面的几条指令中频繁使用。反过来说,已经很久没有使用的页面很可能在未来较长的一段时间内不会被用到 。这个,就是著名的局部性原理——比内存速度还要快的cache,也是基于同样的原理运行的。因此,我们只需要在每次调换时,找到最近最少使用的那个页面调出内存。
算法实现的关键
命中率:
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致 LRU 命中率急剧下降,缓存污染情况比较严重。
复杂度:
实现起来较为简单。
存储成本:
几乎没有空间上浪费。
代价:
命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
174、为什么要设计 后缀表达式,有什么好处?
考察点:逆波兰表达式
参考回答:
后缀表达式又叫逆波兰表达式,逆波兰记法不需要括号来标识操作符的优先级。
175、请你设计一个算法,用来压缩一段URL?
考察点:MD5加密算法
参考回答:
该算法主要使用MD5 算法对原始链接进行加密(这里使用的MD5 加密后的字符串长度为32 位),然后对加密后的字符串进行处理以得到短链接的地址。
176、介绍一下 如何实现动态代理?
考察点:动态代理流程
参考回答:
Java实现动态代理的大致步骤如下:
1.定义一个委托类和公共接口。
2.自己定义一个类(调用处理器类,即实现 InvocationHandler 接口),这个类的目的是指定运行时将生成的代理类需要完成的具体任务(包括Preprocess和Postprocess),即代理类调用任何方法都会经过这个调用处理器类(在本文最后一节对此进行解释)。
3.生成代理对象(当然也会生成代理类),需要为他指定(1)委托对象(2)实现的一系列接口(3)调用处理器类的实例。因此可以看出一个代理对象对应一个委托对象,对应一个调用处理器实例。
4.Java 实现动态代理主要涉及以下几个类:
①java.lang.reflect.Proxy: 这是生成代理类的主类,通过 Proxy 类生成的代理类都继承了 Proxy 类,即 DynamicProxyClass extends Proxy。
②java.lang.reflect.InvocationHandler: 这里称他为"调用处理器",他是一个接口,我们动态生成的代理类需要完成的具体内容需要自己定义一个类,而这个类必须实现 InvocationHandler 接口。
示例代码:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
public final class $Proxy1 extends Proxy implements Subject{
private InvocationHandler h;
private $Proxy1(){}
public $Proxy1(InvocationHandler h){
this.h = h; }
public int request(int i){
Method method = Subject.class.getMethod("request", new Class[]{int.class}); //创建method对象
return (Integer)h.invoke(this, method, new Object[]{new Integer(i)}); //调用了invoke方法 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
177、谈一谈,java中有哪些代理模式?
考察点:代理模式
参考回答:
静态代理,动态代理,Cglib代理。
178、Java IO都有哪些设计模式,简单介绍一下。
考察点:装饰模式,适配器模式
- 1
179、请你介绍一下单例模式?再说一说 懒汉式的单例模式如何实现单例?
考察点:单例模式
参考回答:
定义:保证一个类仅有一个实例,并提供一个访问它的全局访问点。优点:单例类只有一个实例、共享资源,全局使用节省创建时间,提高性能。可以用静态内部实现,保证是懒加载就行了,就是使用才会创建实例对象。
- 1
- 2
- 3
- 4
180、请你讲讲UML中有哪些常用的图?
考察点:用例图
参考回答:
UML定义了多种图形化的符号来描述软件系统部分或全部的静态结构和动态结构,包括:用例图(use case diagram)、类图(class diagram)、时序图(sequence diagram)、协作图(collaboration diagram)、状态图(statechart diagram)、活动图(activity diagram)、构件图(component diagram)、部署图(deployment diagram)等。在这些图形化符号中,有三种图最为重要,分别是:用例图(用来捕获需求,描述系统的功能,通过该图可以迅速的了解系统的功能模块及其关系)、类图(描述类以及类与类之间的关系,通过该图可以快速了解系统)、时序图(描述执行特定任务时对象之间的交互关系以及执行顺序,通过该图可以了解对象能接收的消息也就是说对象能够向外界提供的服务)。
补充下UML的基本知识------------
统一建模语言**(Unified Modeling Language,UML)是一种为面向对象系统的产品进行说明、可视化和编制文档的一种标准语言。UML使用面向对象设计的建模工具,但独立于任何具体程序设计语言。
作用:
(1)为软件系统建立可视化模型。
(2)为软件系统建立构件。
(3)为软件系统建立文档。
- 1
- 2
- 3
- 4
- 5
UML系统开发中有三个主要的模型:
-
功能模型:从用户的角度展示系统的功能,包括用例图。
-
对象模型:采用对象,属性,操作,关联等概念展示系统的结构和基础,包括类别图、对象图。
-
动态模型:展现系统的内部行为。包括序列图,活动图,状态图。

