
- 1(4) 特征降维:主成分分析PCA和奇异值分解SVD_pca的奇异值
- 2【经验】Word 2021|Word文档间复制粘贴保留源格式后,行间距却发生变化(文档网格)_为什么按原格式粘贴还是变了
- 3python3.x中如何使用base64、base32、base16编码解码_ssbsb3zlihlvdq==
- 4vue构建版本
- 5青龙脚本(高佣联盟,附脚本)(已废)_av101hd
- 6SpringCloud&SpringSecurity_springsecurity springcloud
- 7fatal: Authentication failed for ‘https://ghproxy.com/https://github.com_用户名ghproxy
- 8Python数据结构与算法(8)---维护有序列表bisect_数据结构 维护有序序列
- 9nginx 配置 upstream backup 报错_nginx: [emerg] balancing method does not support p
- 10【随手记】MySQL中ROW_NUMBER()、RANK()和DENSE_RANK()函数的用法
redis详解、哨兵模式、集群模式_redis 3.2.5哨兵搭建
赞
踩
redis 安装
安装步骤:
1、下载获得redis-3.2.5.tar.gz后将它放入我们的Linux目录/opt
2、解压命令:tar -zxvf redis-3.2.5.tar.gz
3、解压完成后进入目录:cd redis-3.2.5
4、在redis-3.2.5目录下执行make命令
运行make命令时出现故障意出现的错误解析:gcc:命令未找到
能上网:
yum install gcc
yum install gcc-c++
不能上网:
将资料中的rpmgcc目录复制到Linux的opt目录中
进入opt目录中的rpmgcc目录执行命令:rpm -Uvh *.rpm --nodeps --force
然后使用gcc –v和g++ -v查看gcc和g++版本,会看到详细的版本信息,然后
离线环境下安装GCC和GCC-C++就完成了。
5、在redis-3.2.5目录下再次执行make命令
Jemalloc/jemalloc.h:没有那个文件
解决方案:运行make distclean之后再 make
6、在redis-3.2.5目录下再次执行make命令
查看默认安装目录:usr/local/bin
Redis-benchmark:性能测试工具,可以在自己本子运行,看看自己本子性能如何(服务启动起来后执行)
Redis-check-aof:修复有问题的AOF文件,持久化
Redis-check-dump:修复有问题的dump.rdb文件
Redis-sentinel:Redis集群使用,哨兵
redis-server:Redis服务器启动命令
redis-cli:客户端,操作入口

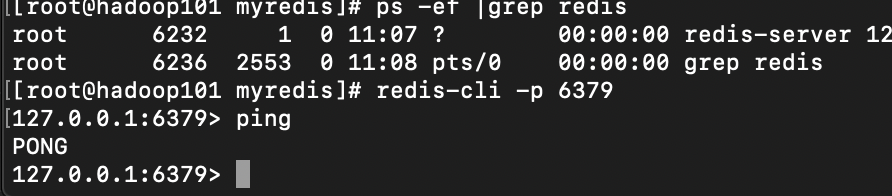
启动
1、备份redis.conf:拷贝一份redis.conf到其他目录

2、修改redis.conf文件将里面的daemonize no 改成 yes,让服务在后台启动

3、启动命令:执行 redis-server /myredis/redis.conf

4、用客户端访问: redis-cli
5、测试验证: ping
Redis的Java客户端Jedis
Jedis所需要的jar包
Commons-pool-1.6.jar
Jedis-2.1.0.jar
- 1
- 2
idea连接虚拟机的Redis的注意事项
禁用Linux的防火墙:
临时禁用:service iptables stop
关闭开机自启:chkconfig iptables off
redis.conf中注释掉bind 127.0.0.1(61行) ,然后 protect-mode(80行)设置为 no。


Jedis测试连通性

Redis事务
Redis事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
Redis事务的主要作用就是串联多个命令防止别的命令插队
Multi、Exec、discard
从输入Multi命令开始,输入的命令都会依次进入命令队列中,但不会执行,至到输入Exec后,Redis会将之前的命令队列中的命令依次执行。
组队的过程中可以通过discard来放弃组队。

事务的错误处理
组队中某个命令出现了报告错误,执行时整个的所有队列会都会被取消。

如果执行阶段某个命令报出了错误,则只有报错的命令不会被执行,而其他的命令都会执行,不会回滚。

悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量。Redis就是利用这种check-and-set机制实现事务的。

Redis的持久化
Redis 提供了2个不同形式的持久化方式。
RDB (Redis DataBase)
AOF (Append Of File)
RDB
在指定的时间间隔内将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里。
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行任何IO操作的,这就确保了极高的性能如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化后的数据可能丢失。
关于fork
在Linux程序中,fork()会产生一个和父进程完全相同的子进程,但子进程在此后多会exec系统调用,出于效率考虑,Linux中引入了“写时复制技术”,一般情况父进程和子进程会共用同一段物理内存,只有进程空间的各段的内容要发生变化时,才会将父进程的内容复制一份给子进程。
rdb的保存的文件
在redis.conf中配置文件名称,默认为dump.rdb

rdb文件的保存路径,也可以修改。默认为Redis启动时命令行所在的目录下

rdb的保存策略

手动保存快照
命令save: 只管保存,其它不管,全部阻塞
save vs bgsave
stop-writes-on-bgsave-error yes
- 1
当Redis无法写入磁盘的话,直接关掉Redis的写操作
rdbcompression yes
- 1
进行rdb保存时,将文件压缩
rdbchecksum yes
- 1
在存储快照后,还可以让Redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能
rdb的备份
先通过config get dir 查询rdb文件的目录
将*.rdb的文件拷贝到别的地方
rdb的恢复
关闭Redis
先把备份的文件拷贝到工作目录下
启动Redis, 备份数据会直接加载
rdb的优点
节省磁盘空间
恢复速度快
rdb的缺点
虽然Redis在fork时使用了写时拷贝技术,但是如果数据庞大时还是比较消耗性能。
在备份周期在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改。
AOF
以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,Redis启动之初会读取该文件重新构建数据,换言之,Redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
AOF默认不开启,需要手动在配置文件中配置

可以在redis.conf中配置文件名称,默认为 appendonly.aof

AOF文件的保存路径,同RDB的路径一致。
AOF和RDB同时开启,redis 听aof的
AOF文件故障备份
AOF的备份机制和性能虽然和RDB不同, 但是备份和恢复的操作同RDB一样,都是拷贝备份文件,需要恢复时再拷贝到Redis工作目录下,启动系统即加载。
AOF文件故障恢复
如遇到AOF文件损坏,可通过
redis-check-aof --fix appendonly.aof 进行恢复
AOF同步频率设置
始终同步,每次Redis的写入都会立刻记入日志
每秒同步,每秒记入日志一次,如果宕机,本秒的数据可能丢失。
把不主动进行同步,把同步时机交给操作系统。

Rewrite
AOF采用文件追加方式,文件会越来越大为避免出现此种情况,新增了重写机制,当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集.可以使用命令bgrewriteaof。
Redis如何实现重写?
AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename),遍历新进程的内存中数据,每条记录有一条的Set语句。重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
何时重写
重写虽然可以节约大量磁盘空间,减少恢复时间。但是每次重写还是有一定的负担的,因此设定Redis要满足一定条件才会进行重写。
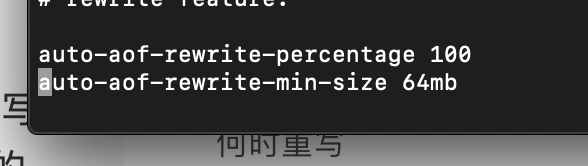
系统载入时或者上次重写完毕时,Redis会记录此时AOF大小,设为base_size,如果Redis的AOF当前大小>= base_size +base_size*100% (默认)且当前大小>=64mb(默认)的情况下,Redis会对AOF进行重写。
AOF的优点
备份机制更稳健,丢失数据概率更低。
可读的日志文本,通过操作AOF稳健,可以处理误操作。
AOF的缺点
比起RDB占用更多的磁盘空间。
恢复备份速度要慢。
每次读写都同步的话,有一定的性能压力。
存在个别Bug,造成恢复不能。
用哪个好
官方推荐两个都启用。
如果对数据不敏感,可以选单独用RDB。
不建议单独用 AOF,因为可能会出现Bug。
如果只是做纯内存缓存,可以都不用。
Redis的主从复制
主从复制,就是主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主
用处
读写分离,性能扩展
容灾快速恢复
配从(服务器)不配主(服务器)
在这里插入图片描述




启动3台redis服务

info replication
打印主从复制的相关信息
slaveof
成为某个实例的从服务器


一主二仆模式演示
复制原理
每次从机联通后,都会给主机发送sync指令
主机立刻进行存盘操作,发送RDB文件,给从机
从机收到RDB文件后,进行全盘加载
之后每次主机的写操作,都会立刻发送给从机,从机执行相同的命令
薪火相传
上一个slave可以是下一个slave的Master,slave同样可以接收其他slaves的连接和同步请求,那么该slave作为了链条中下一个的master, 可以有效减轻master的写压力,去中心化降低风险。
用 slaveof
中途变更转向:会清除之前的数据,重新建立拷贝最新的
风险是一旦某个slave宕机,后面的slave都没法备份
反客为主
当一个master宕机后,后面的slave可以立刻升为master,其后面的slave不用做任何修改。。
用 slaveof no one 将从机变为主机。

哨兵模式(sentinel)
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库.
配置哨兵
调整为一主二仆模式
自定义的/myredis目录下新建sentinel.conf文件
在配置文件中填写内容:
sentinel monitor mymaster 127.0.0.1 6379 1
- 1
其中mymaster为监控对象起的服务器名称, 1 为 至少有多少个哨兵同意迁移的数量。

启动哨兵
执行redis-sentinel /myredis/sentinel.conf

现在我将6379 shutdown 然后在将6379连上,发现 主机为6381 从机为6379、6380

哨兵模式搭建完毕,下面来搞集群
redis的集群
Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
1、安装ruby环境
能上网:
执行yum install ruby
执行yum install rubygems
不能上网:
cd /run/media/root/CentOS 7 x86_64/Packages(路径跟centos6不同) 获取右图rpm包
拷贝到/opt/rpmruby/目录下,并cd到此目录
执行:rpm -Uvh *.rpm --nodeps --force
按照依赖安装各个rpm包
2、拷贝redis-3.2.0.gem到/opt目录下
3、执行在opt目录下执行 gem install --local redis-3.2.0.gem

制作6个实例,6379,6380,6381,6389,6390,6391.conf
cluster-enabled yes 打开集群模式
cluster-config-file nodes-6379.conf 设定节点配置文件名
cluster-node-timeout 15000 设定节点失联时间,超过该时间(毫秒),集群自动进行主从切换。

复制6份

并且改端口(每个都要改)


将六个节点合成一个集群
组合之前,请确保所有redis实例启动后,nodes-xxxx.conf文件都生成正常。


合体:
cd /opt/redis-3.2.5/src
./redis-trib.rb create --replicas 1 192.168.1.101:6379 192.168.1.101:6380 192.168.1.101:6381 192.168.1.101:6389 192.168.1.101:6390 192.168.1.101:6391
- 1


合体成功

通过 cluster nodes 命令查看集群信息
redis cluster 如何分配这六个节点?
一个集群至少要有三个主节点。
选项 --replicas 1 表示我们希望为集群中的每个主节点创建一个从节点。
分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
什么是slots?
一个 Redis 集群包含 16384 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。
集群中的每个节点负责处理一部分插槽。 举个例子, 如果一个集群可以有主节点, 其中:
节点 A 负责处理 0 号至 5500 号插槽。
节点 B 负责处理 5501 号至 11000 号插槽。
节点 C 负责处理 11001 号至 16383 号插槽。
如果主节点下线?从节点能否自动升为主节点?
主节点恢复后,主从关系会如何?
如果所有某一段插槽的主从节点都宕掉,redis服务是否还能继续?
redis.conf中的参数 cluster-require-full-coverage
集群的Jedis开发
public class JedisClusterTest {
public static void main(String[] args) {
Set<HostAndPort> set =new HashSet<HostAndPort>();
set.add(new HostAndPort("192.168.1.101",6379));
JedisCluster jedisCluster=new JedisCluster(set);
jedisCluster.set("k1", "v1");
System.out.println(jedisCluster.get("k1"));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
Redis 集群提供了以下好处:
实现扩容
分摊压力
无中心配置相对简单
Redis 集群的不足:
多键操作是不被支持的
多键的Redis事务是不被支持的。lua脚本不被支持。
由于集群方案出现较晚,很多公司已经采用了其他的集群方案,而代理或者客户端分片的方案想要迁移至redis cluster,需要整体迁移而不是逐步过渡,复杂度较大。

