
- 1网络传输:linux下的网络请求和下载(ping wget curl)、端口_linux实时网络请求
- 2专任教师用计算机,辽宁师范大学专任教师 - 计算机与信息技术
- 3IOS- genstrings 国际化_ios genstrings
- 4android 自定义运行异常捕获,android 自定义全局未处理异常捕获器
- 5计算机软件跨考教育学优点,2021教育学考研优势院校分析之:华南师范大学
- 6进程间通信的五种方式(信号量,管道,套接字,消息队列,共享内存)_msgtype是什么意思
- 7等额本金和等额本息两种贷款方式的比较_对比相同本金a,相同年利率 i,n年还款期,等额本金和等额本息两种还款方式下的
- 8Android Studio导致App出现crash的问题_com.android.tools.profiler.support.profilers.event
- 9狗眼看芯片之ARM_arm snoop
- 10安卓平板可以安装python吗,安卓平板可以运行python
在Kaggle上免费使用GPU_kaggle有什么gpu
赞
踩
Intro
Kaggle提供免费访问内核中的NVidia K80 GPU。该基准测试表明,在深度学习模型的训练过程中,为您的内核启用GPU可实现12.5倍的加速。
这个内核是用GPU运行的。我将运行时间与在CPU上训练相同模型内核的运行时间进行比较。
GPU的总运行时间为994秒。仅具有CPU的内核的总运行时间为13,419秒。这是一个12.5倍的加速(只有一个CPU的总运行时间是13.5倍)。
将比较仅限于模型训练,我们看到CPU从13,378秒减少到GPU的950秒。因此,模型训练加速有点超过13倍。
确切的加速度取决于许多因素,包括模型架构,批量大小,输入管道复杂性等。也就是说,GPU在Kaggle内核中开辟了很多可能性。
如果您想将这些GPU用于深度学习项目,您可能会发现我们的深度学习课程是最快速的路径,以便您可以运行自己的项目。我们还在我们的数据集平台上添加了新的图像处理数据集,我们总是有许多竞赛让您使用这些免费的GPU来尝试新的想法。
以下文本显示了如何启用GPU并提供有关基准测试的详细信息。
Adding a GPU
我们通过首先打开内核控件来设置此内核以在GPU上运行。
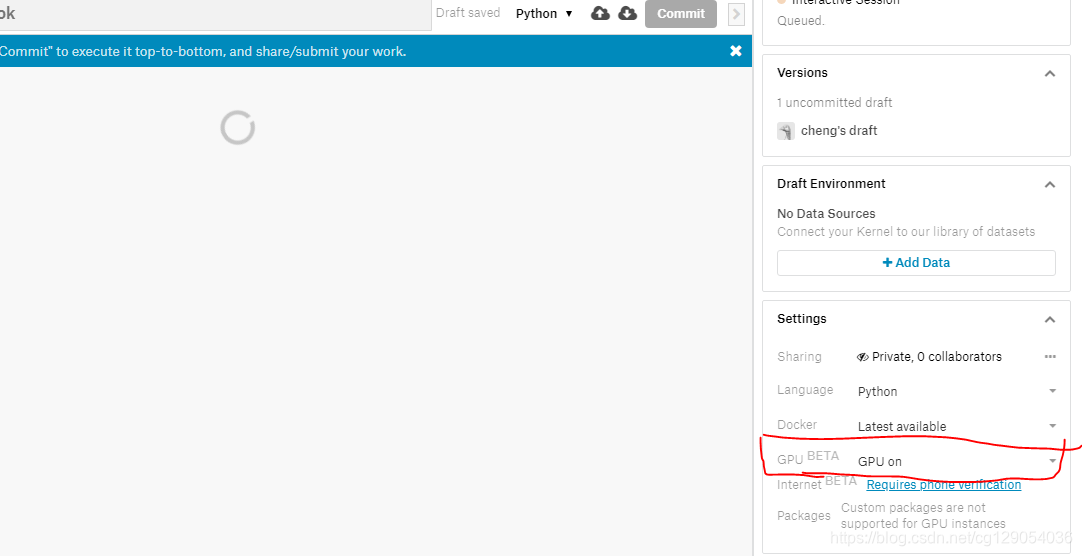
选择“设置”项卡。 然后选中启用GPU的复选框。 验证GPU是否已连接到控制台栏中的内核,它应在资源使用情况指标旁边显示GPU ON。
GPU支持的实例具有较少的CPU功率和RAM。 而且,许多数据科学库无法利用GPU。 因此,GPU对某些任务很有价值(特别是在使用TensorFlow,Keras和PyTorch等深度学习库时)。 但是对于大多数其他任务而言,如果没有GPU,你会更好。
The data
该数据集包含美国手语中29种不同符号的图像。 这些是26个字母(A到Z)加上空格,删除和无标记。 我们的模型将查看这些图像,并学习如何对每张图像中的符号进行分类。
以下示例图片
[1]
- # Imports for Deep Learning
- from keras.layers import Conv2D, Dense, Dropout, Flatten
- from keras.models import Sequential
- from keras.preprocessing.image import ImageDataGenerator
-
- # ensure consistency across runs
- from numpy.random import seed
- seed(1)
- from tensorflow import set_random_seed
- set_random_seed(2)
-
- # Imports to view data
- import cv2
- from glob import glob
- from matplotlib import pyplot as plt
- from numpy import floor
- import random
-
- def plot_three_samples(letter):
- print("Samples images for letter " + letter)
- base_path = '../input/asl_alphabet_train/asl_alphabet_train/'
- img_path = base_path + letter + '/**'
- path_contents = glob(img_path)
-
- plt.figure(figsize=(16,16))
- imgs = random.sample(path_contents, 3)
- plt.subplot(131)
- plt.imshow(cv2.imread(imgs[0]))
- plt.subplot(132)
- plt.imshow(cv2.imread(imgs[1]))
- plt.subplot(133)
- plt.imshow(cv2.imread(imgs[2]))
- return
-
- plot_three_samples('A')

Samples images for letter B
Data Processing Set-Up
[3]
- data_dir = "../input/asl_alphabet_train/asl_alphabet_train"
- target_size = (64, 64)
- target_dims = (64, 64, 3) # add channel for RGB
- n_classes = 29
- val_frac = 0.1
- batch_size = 64
-
- data_augmentor = ImageDataGenerator(samplewise_center=True,
- samplewise_std_normalization=True,
- validation_split=val_frac)
-
- train_generator = data_augmentor.flow_from_directory(data_dir, target_size=target_size, batch_size=batch_size, shuffle=True, subset="training")
- val_generator = data_augmentor.flow_from_directory(data_dir, target_size=target_size, batch_size=batch_size, subset="validation")
Model Specification
[4]
- my_model = Sequential()
- my_model.add(Conv2D(64, kernel_size=4, strides=1, activation='relu', input_shape=target_dims))
- my_model.add(Conv2D(64, kernel_size=4, strides=2, activation='relu'))
- my_model.add(Dropout(0.5))
- my_model.add(Conv2D(128, kernel_size=4, strides=1, activation='relu'))
- my_model.add(Conv2D(128, kernel_size=4, strides=2, activation='relu'))
- my_model.add(Dropout(0.5))
- my_model.add(Conv2D(256, kernel_size=4, strides=1, activation='relu'))
- my_model.add(Conv2D(256, kernel_size=4, strides=2, activation='relu'))
- my_model.add(Flatten())
- my_model.add(Dropout(0.5))
- my_model.add(Dense(512, activation='relu'))
- my_model.add(Dense(n_classes, activation='softmax'))
-
- my_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=["accuracy"])
Model Fitting
[5]
my_model.fit_generator(train_generator, epochs=5, validation_data=val_generator)-
-
- Epoch 1/5
- 1224/1224 [==============================] - 206s 169ms/step - loss: 1.1439 - acc: 0.6431 - val_loss: 0.5824 - val_acc: 0.8126
- Epoch 2/5
- 1224/1224 [==============================] - 179s 146ms/step - loss: 0.2429 - acc: 0.9186 - val_loss: 0.5081 - val_acc: 0.8492
- Epoch 3/5
- 1224/1224 [==============================] - 182s 148ms/step - loss: 0.1576 - acc: 0.9495 - val_loss: 0.5181 - val_acc: 0.8685
- Epoch 4/5
- 1224/1224 [==============================] - 180s 147ms/step - loss: 0.1417 - acc: 0.9554 - val_loss: 0.4139 - val_acc: 0.8786
- Epoch 5/5
- 1224/1224 [==============================] - 181s 148ms/step - loss: 0.1149 - acc: 0.9647 - val_loss: 0.4319 - val_acc: 0.8948
-
- <keras.callbacks.History at 0x7f5cbb6537b8>
-

