
- 1垂直同步_显示器自适应垂直同步即将大一统:NVIDIA有条件支持FreeSync
- 2微信小程序的常见的面试题(总结)_小程序面试题
- 3VMware中Kali Linux添加源,更新和安装vmtools_kali 2021.3安装vmtools
- 4使用ElasticsearchRepository和ElasticsearchRestTemplate操作Elasticsearch,Spring Boot整合Elasticsearch_idea连接elasticsearch elasticsearchresttemplate
- 5创维E900V22C、E900V22D_S905L3-L3B免拆卡刷固件_e900v22d刷机
- 6GO开发环境配置_go环境配置
- 7react实现HTML调摄像头拍照功能_react 拍照
- 8php GET 和 POST 方法的区别_php get和post 区别
- 9通俗讲解Pytorch梯度的相关问题:计算图、no_grad、zero_grad、retain_grad、detach和backward;Variable、Parameter和torch.tensor_pytorch retain_grad
- 10cortex a7 a53_西昊人体工学椅A7开箱测评
NLP大模型微调原理_大语言模型微调的原理
赞
踩
1. 背景
LLM (Large Language Model) 大型语言模型,旨在理解和生成人类语言,需要在大量的文本数据上进行训练。一般基于Transformer结构,拥有Billion以上级别的参数量。比如GPT-3(175B),PaLM(560B)。
NLP界发生三件大事:
-
ChatGPT:2022年11月OpenAI发布的AI聊天机器人程序,基于GPT-3.5
-
LLaMA:2023年2月Meta发布的预训练模型,重新定义了大模型的“大”
-
Alpaca:2023年3月斯坦福发布的微调模型,证明Instruction Fine-Tuning的可行性
ChatGPT背后的技术:
-
GPT models:基座模型(base model), GPT-3, GPT-3.5-Turbo and GPT4, 较大的模型容量,需要在大量数据上进行预训练。
-
IFT(Instruction Fine-Tuning):指令微调,指令是指用户传入的目的明确的输入文本,指令微调用以让模型学会遵循用户的指令。OpenAI叫做SFT(Supervised Fine-Tuning),是一样的意思。
-
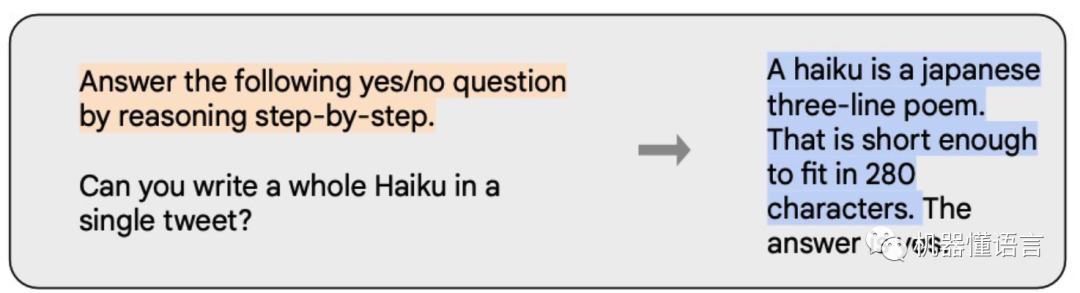
CoT(Chain-of-Thought):在数据层面上,表示指令形式的一种特殊情况,包含step-by-step的推理过程(如下图所示)。在模型层面上,指模型具有逐步推理的reasoning能力。
-
RLHF(Reinforcement Learning from Human Feedback):以强化学习方式依据人类反馈优化语言模型。

2. 大模型训练方法
2.1 FLAN
论文《Finetuned Language Models Are Zero-Shot Learners》FLAN 明确提出了指令微调,本质目的是将NLP任务转换成自然语言指令后再喂给模型训练,使其提升zero-shot任务的性能表现。
paper:https://arxiv.org/abs/2109.01652

2.2 T0
论文《Multitask Prompted Training Enables Zero-shot Task Generalization》T0探究了大模型zero-shot的泛化能力是怎么实现的,并证明了通过显式多任务prompt训练可以实现语言模型的zero-shot泛化能力。
paper:https://arxiv.org/abs/2110.08207

1. 多任务 prompted training 比同参数模型zero-shot能力更强。
2. 论文比较了 T0 与 GPT-3 模型的 zero-shot 性能:
a. 发现 T0 在 11 个数据集中有9个超过 GPT-3;
b. T0 和 GPT-3 都没有接受自然语言推理方面的训练,但 T0 在所有NLI数据集上的表现都优于GPT-3。
2.3 Flan-T5
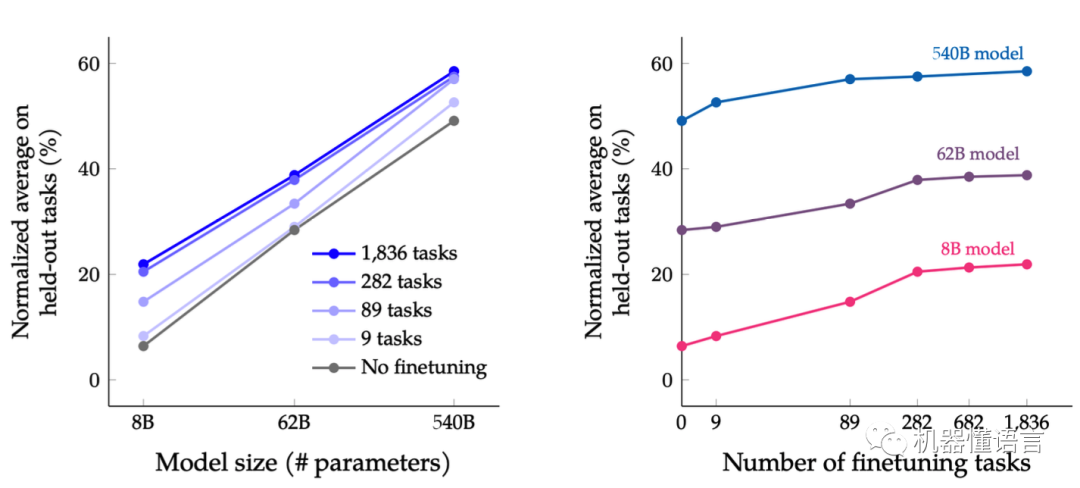
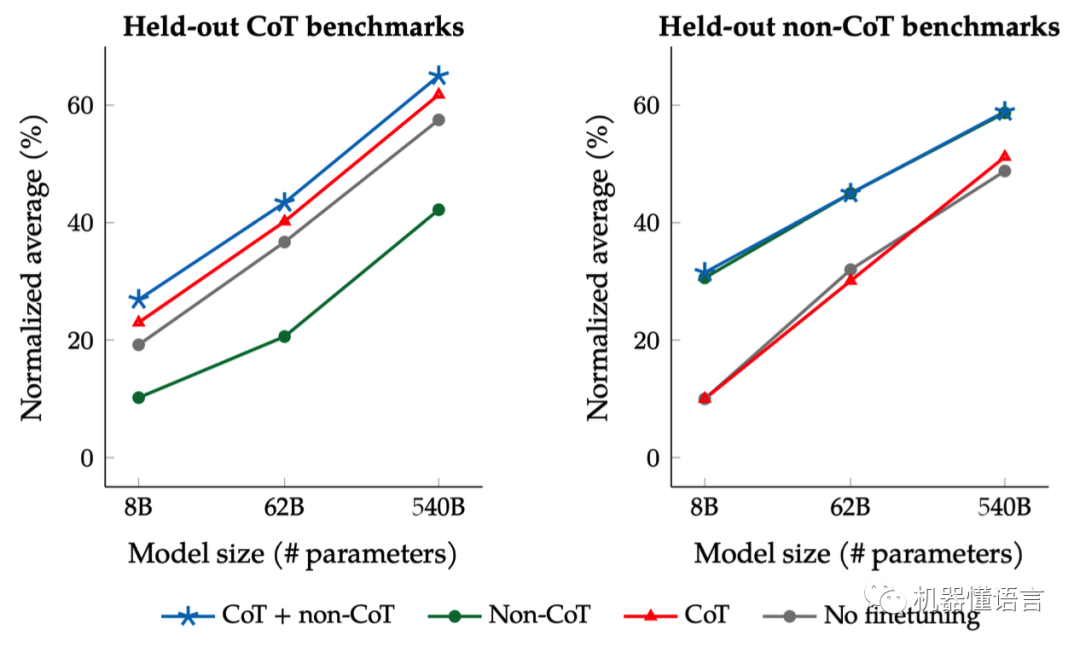
论文《Scaling Instruction-Finetuned Language Models》Flan-T5提出了一套多任务的微调方案(Flan),通过在超大规模的任务上进行微调,让语言模型具备了极强的泛化性能,做到单个模型就可以在1800多个NLP任务上都能有很好的表现。这意味着模型可以直接在几乎全部的NLP任务上直接使用,实现「One model for ALL tasks」,这就非常有诱惑力!
paper:https://arxiv.org/abs/2210.11416
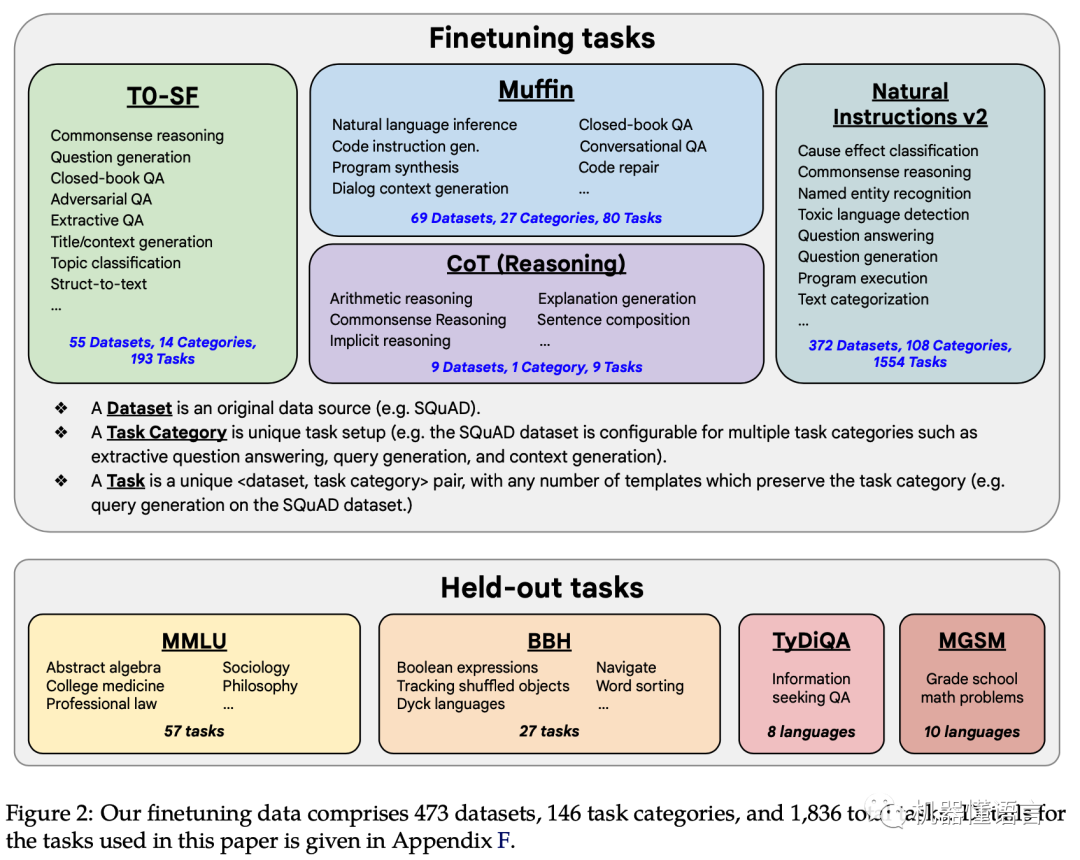
Flan-T5表明了以下实验结论:
-
scaling the number of tasks (Finetune任务越多效果越好)
-
scaling the model size (模型参数越多效果越好)
-
finetuning on chain-of-thought(CoT) data (思维链数据可以提升推理能力)
2.4 Chain-of-Thought(CoT)
● Few-shot CoT
论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》提出了Chain-of-Thought(CoT)思维链的方法来改善大模型在数学计算、常识、符号推理等任务上的推理能力。
paper:https://arxiv.org/abs/2201.11903
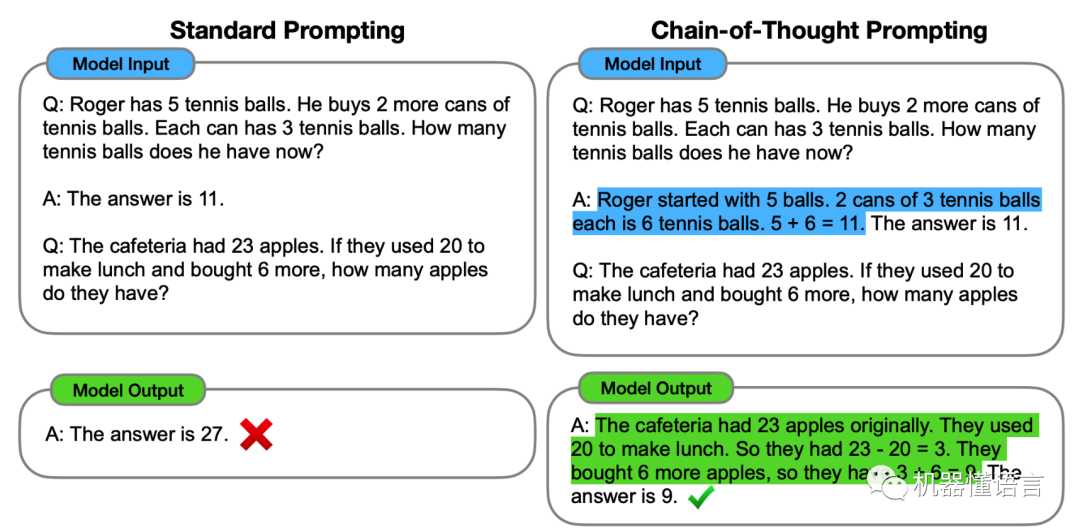
COT 思维链的灵感来源于人做推理的过程,作者借鉴了这个过程,通过设计思维链来激发大模型使之拥有推理能力,并且由于这个有逻辑性的思维链存在,多步的中间推理就可以得到最终的正确答案。
● Zero-shot CoT
论文《Large Language Models are Zero-Shot Reasoners》探究了大模型的推理能力,作者发现,对拥有175B参数的GPT3,通过简单的添加`Let's think step by step`,可以提升模型数学推理(arithmetics reasoning)和符号推理(symbolic reasoning)的zero-shot能力。
paper:https://arxiv.org/abs/2205.11916
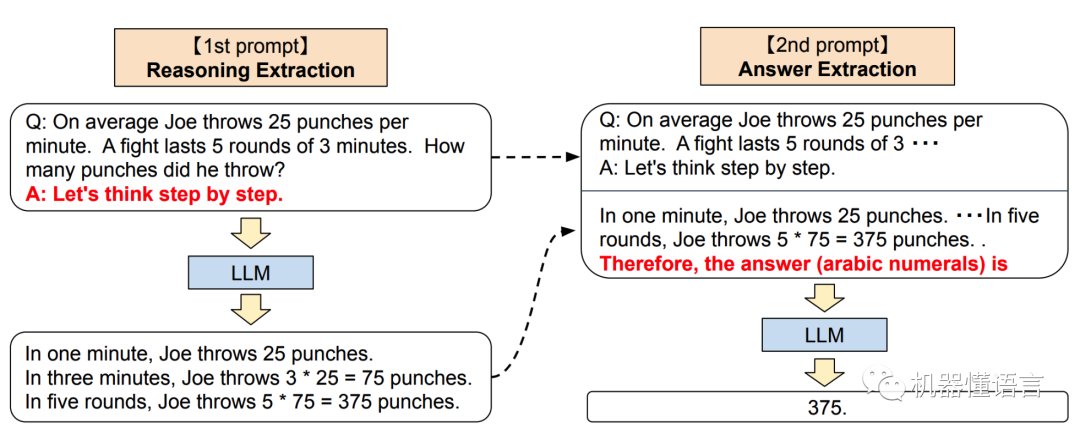
作者提出了Zero-shot-CoT分为两个阶段:
1. 对原问题添加文字提示,使用LLM生成推理过程。(上图左侧)
2. 将LLM生成的推理过程加入到原问题中,并且添加生成答案的提示,使用LLM生成问题的最终答案。(上图右侧)
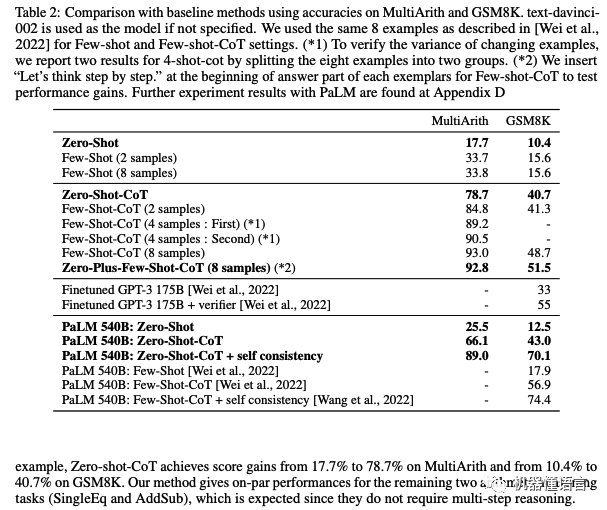
效果:哄一哄能让GPT-3准确率暴涨61%!
2.5 Reinforcement Learning Human Feedback (RLHF)
● InstructGPT
论文《Training language models to follow instructions with human feedback》InstructGPT是ChatGPT的前身,主要探究了用RLHF(Reinforcement Learning from Human Feedback)方法使大模型中对齐人类意图。
paper:https://arxiv.org/abs/2203.02155
GPT等大型语言模型基于Prompt的zero shot的学习范式有一个很大的问题是,预训练的模型完成的任务是后继文本的预测,这和具体任务的要求有一些偏离,生成的结果也不一定符合人的意图。因此需要以某种形式fine-tune来对齐这一点。
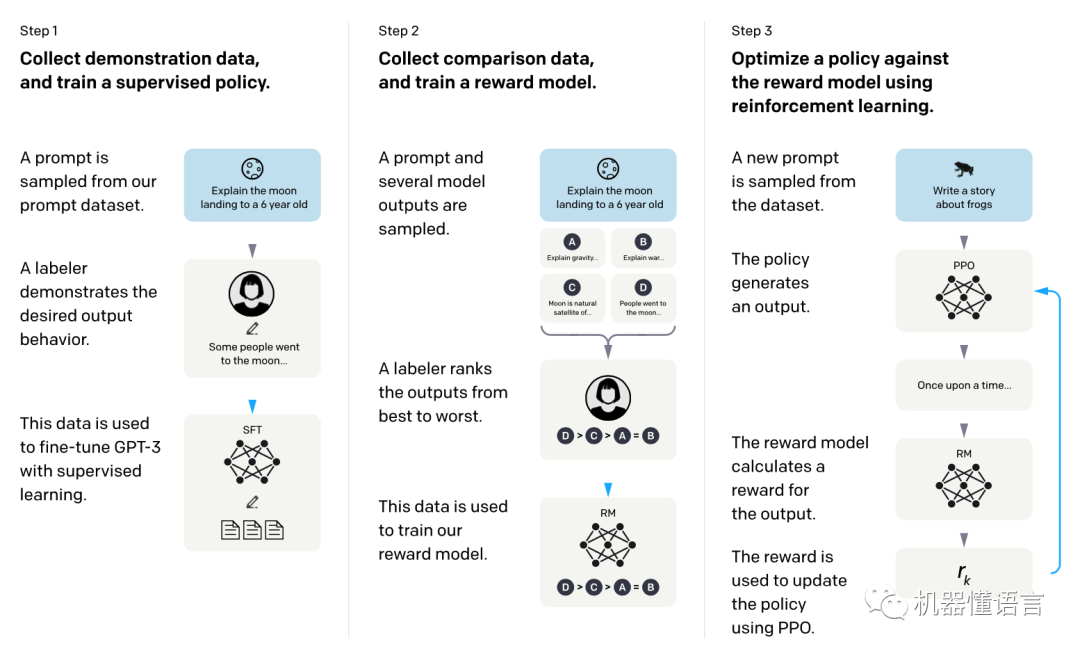
方法是三步走:
1. 使用人工给出的示范性数据监督训练策略模型
2. 使用人工排序的对比性数据训练奖赏模型
3. 通过强化学习(使用了奖赏模型)训练策略模型
第2、3步可以交替迭代,把人参与到优化过程中。
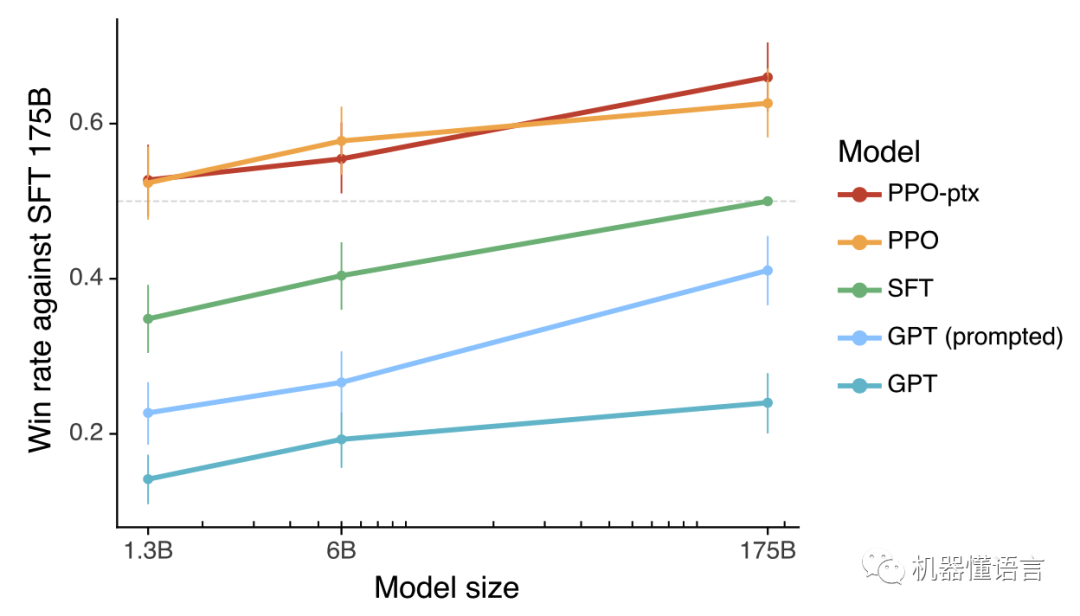
无论左图右图,使用强化学习的模型(PPO和PPO-ptx)要远好于GPT或监督学习的模型。
这里的“好”是指它的输出更被标注员喜欢(真实、有用、无害)。数据和评价标准都和训练时一致,统统向人类偏好对齐。这正是RLHF的优势所在,自然吊打GPT3。
另外PPO-ptx模型在强化学习时加了pretraining的正则,目的是避免在公开NLP任务上掉点(解决所谓“对齐税”问题),但在这里略微有负面影响。
3. LLaMA
论文《LLaMA: Open and Efficient Foundation Language Models》作者在1T级别的token上训练,证明了仅使用公开数据集也可以训练出来SOTA级别的模型。
与Chinchilla,PaLM 或 GPT-3 不同,LLaMA 只使用公开可用的数据,使本文工作与开源兼容,而大多数现有模型依赖于非公开的数据。
paper:https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
3.1 性能

● LLaMA-13B > GPT-3 (175B):LLaMA-13B 比 GPT3(175B) 在大多数测试表现好
● LLaMA-65B ≈ PaLM-540B:LLaMA-65B 与最好的模型 Chinchilla-70B 和 PaLM-540B 相比也有竞争力
LLaMA重新定义了大模型的“大”
3.2 Motivation
1. 开源的OPT (Zhang et al., 2022), GPT-NeoX (Black et al., 2022), BLOOM (Scao et al., 2022) 和 GLM (Zeng et al., 2022)模型,其效果不能和 PaLM-62B or Chinchilla比,LLaMA更强。
2. 论文《Training Compute-Optimal Large Language Models》研究发现最好的性能不是在最大的模型上,而是在用了更多token的模型上,因此作者认为一个较小的模型训练的时间更长,用的token更多,能达到一样的模型效果,并且在预测时较为便宜(cheaper)。
paper:https://arxiv.org/abs/2203.15556
3.3 Optimizer
LLaMA 还对 transformer 架构做了改进:
●Pre-normalization[GPT3]: RMSNorm normalizing function
● SwiGLU activation function [PaLM].
● Rotary Embeddings [GPTNeo].
3.4 Future Work
1. 继续scale更大的模型
2. 做instruction tuning和RLHF
4. 微调方法
4.1 adapter
2019年,论文《Parameter-Efficient Transfer Learning for NLP》提出了Adapter方案,成为Delta Tuning技术方案的开山之作。
该方案的主要思想是,在参数规模较大的模型中,固定预训练模型的参数,不再进行微调,并在原有的网络结构上增加部分可训练参数。这些可训练参数被添加到每层的attention层和feed-forward层后面。具体来说,Adapter方案会在每层的attention层和feed-forward层之间添加一个新的小型神经网络,称为Adapter。
Adapter的参数可以在微调过程中进行训练,以适应特定的下游任务。这种方法可以大大减少需要微调的参数数量,从而提高模型的参数效率和训练速度。
如下图所示,Adapter方案在每层的attention层和feed-forward层后面添加一个Adapter,使得模型的参数规模得到了有效缩减。这种方法在自然语言处理领域得到了广泛应用,并取得了很好的效果。

4.2 LoRA
2021年,微软在论文《LoRA: Low-Rank Adaptation of Large Language Models》提出了一种名为LORA的方案。该方案分析了Transformer的网络结构,发现权重矩阵的计算占用了大量的计算时间,其中包括Attention层的Q/K/V转换矩阵和Feed-Forward层的MLP矩阵。
paper:https://arxiv.org/abs/2106.09685
LORA主要聚焦于Attention的转换矩阵,以提高模型训练速度和效率。LORA方案的核心思想是给转换矩阵并列添加一个矩阵。同时使用低秩矩阵组合来代替添加的矩阵。这种方法可以有效地减少参数数量。
实验结果表明,LORA方案可以在不影响模型性能的情况下,显著提高模型训练速度和效率。该方案已经在自然语言处理领域得到了广泛应用,并在多个任务上取得了优异的效果。

4.3 Prefix-Tuning
2021年Stanford在论文《Prefix-Tuning: Optimizing Continuous Prompts for Generation》中提出Prefix-Tuning方法,其主要思想是不改变原有网络层的结构,而是对输入部分增加一个prompt前缀,prompt可以离散的、具体的,比如对于ner任务可以增加"请找出句子中的全部实体"作为prompt。
这种prompt可以人工设计或者自动化搜索,问题在于最终的性能对人工设计的prompt的变化特别敏感,加一个词或者少一个词,或者变动位置啥的都会造成比较大的变化。自动化搜索prompt成本也比较高。
本文的实现方式是采用第二种方案,给每个任务训练一份单独的连续可微调的virual token,相比较离散的token效果更好。同时为了扩大可微调参数量,不仅是添加在第一层而是添加在transformer的每一层。对于T5网络结构,既有encoder部分又有decoder部分,所以需要在encoder的输入和decoder的输入都添加prompt前缀。
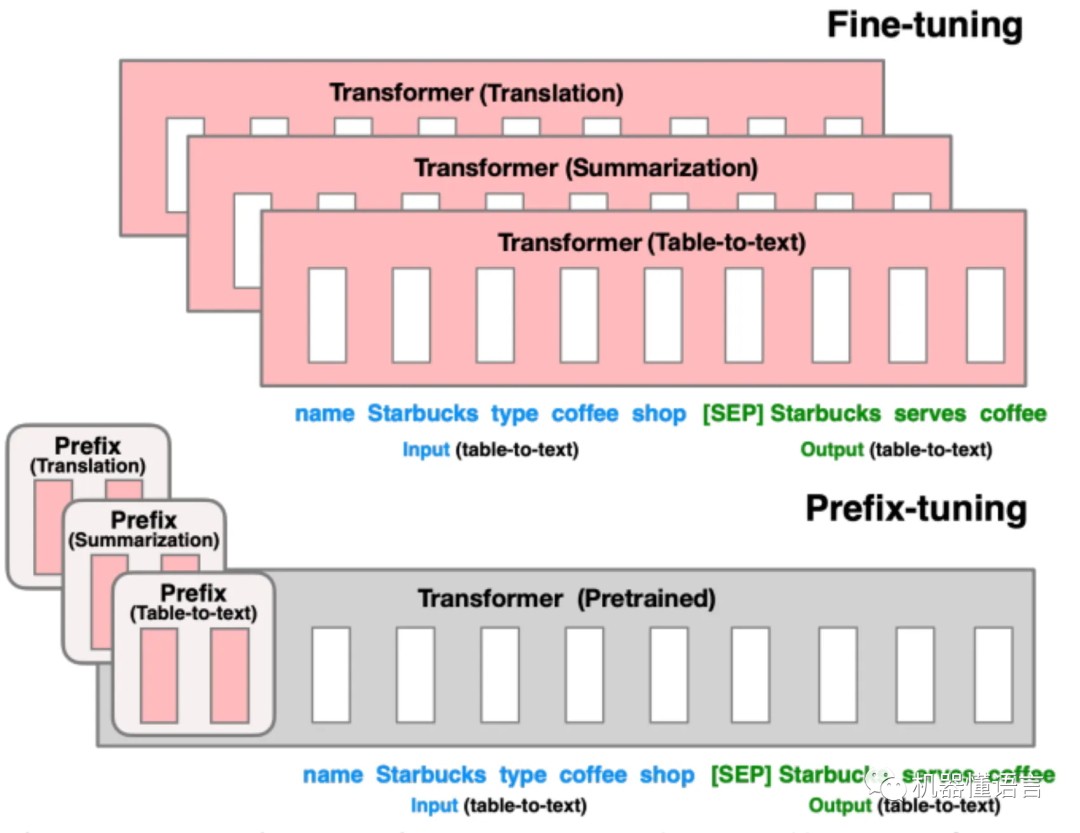
总结来看,delta-tuning的思想就是把原有的预训练模型的参数固定住,然后新增一部分网络参数用于下游任务的微调。至于新增的网络参数往哪里放?哪里放都可以,只要有效果即可。
5. 微调实现
5.1 Alpaca
2023年3月15日,斯坦福发布Alpaca模型《Alpaca: A Strong, Replicable Instruction-Following Model》,是在Meta的LLaMA-7B上进行微调而来,仅用了52k数据,其性能约等于GPT-3.5,且训练成本还不到600美元。
paper:Stanford CRFM
训练大模型的挑战主要有两个:
1. 大的优秀底座模型:使用LLaMA-7B;
2. 高质量的指令数据:基于SELF-INSTRUCT论文中的自动指令数据生成方法,用OpenAI的text-davinci-003生成52K指令数据。
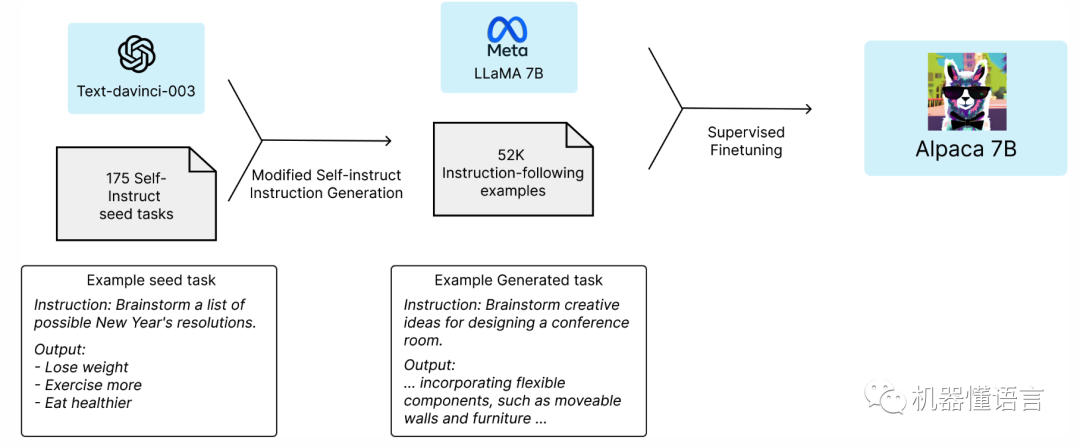
Alpaca羊驼模型之后出现大批基于LLaMA的微调模型,包括ChatLLama、FreedomGPT、Vicuna、Koala等,羊驼家族名字都快不够用了。
从本质来讲,ChatGPT这种大语言模型就是通过烧钱烧算力烧数据达到`大力出奇迹`的效果。而这也带来了一个问题,即这样的大语言模型烧钱的程度会让很多小公司望而却步,只能加入霸权垄断的圈子。而对于像小红书/B站这样不上不下的公司,既承担不起自己训练大模型的成本,也不愿意将自己内容池的数据拱手让人,其实是陷入蛮尴尬的境地。
Alpaca、Vicuna展现了另一种可能性,即通过“知识蒸馏”的方式,以极低的价格复刻大语言模型90%甚至99%的能力。而这就意味着小公司也能训练自己的AI模型。
换句话说,ChatGPT拉开了AI落地的序幕,而Vicuna告诉我们,遍地AI的世界也许就在眼前。
5.2 Self-Instruct
2022年,Washington大学在论文《SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions》提出了一种框架:Self-Instruct,该框架可以使用最少的人工标注,生成大量的用于instruct-tuning的数据;还发布了52K的使用上述方法得到的用于instruct-tuning的数据集。
paper:https://arxiv.org/abs/2212.10560
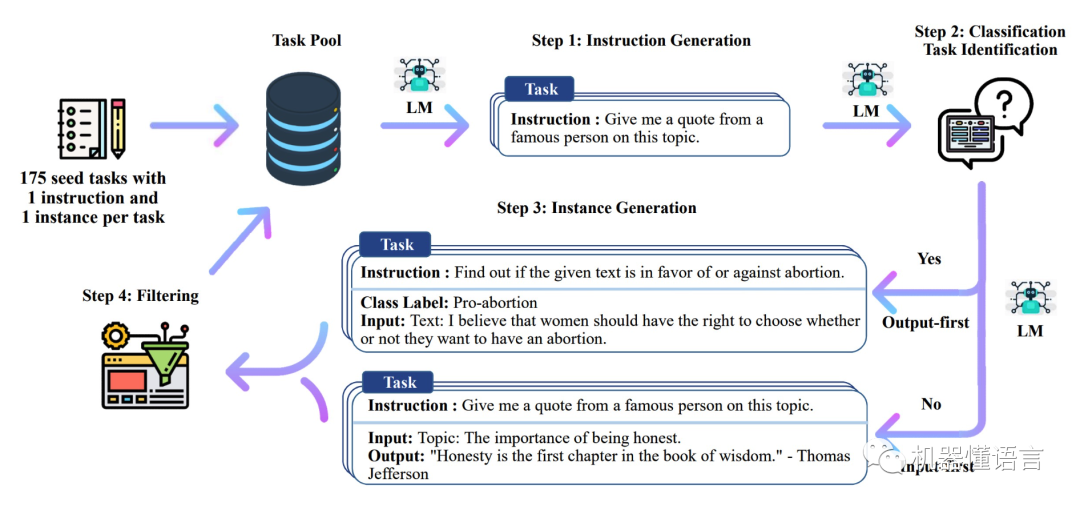
Self-Instruct 数据集构建方法
效果比对:
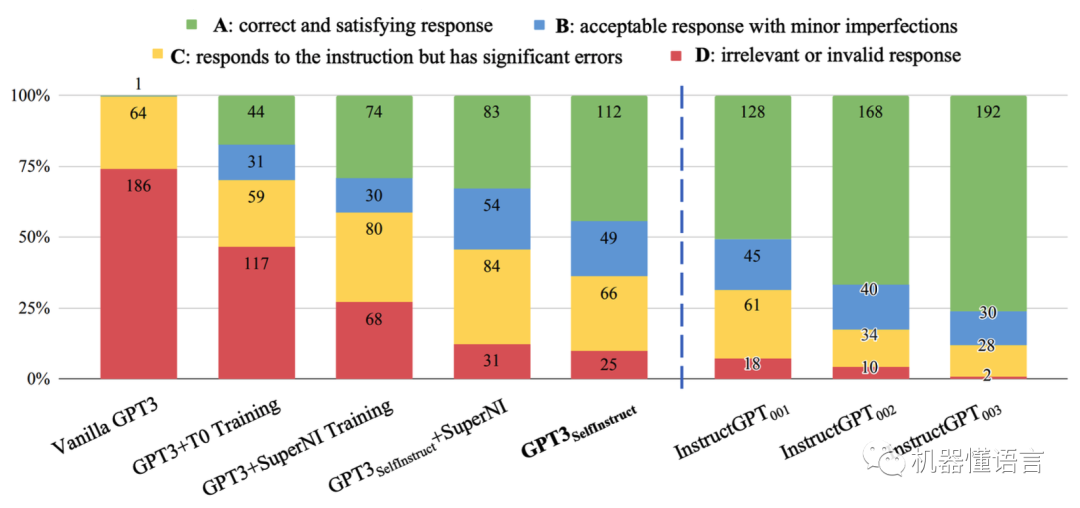
答复结果评分,A最好,D最差;绿色最好,红色最差
可以看出:
-
原始的GPT3几乎无法响应用户的指令,所有instruction-tuned微调过的模型效果都有明显的提升
-
即使Self-Instruct生成的数据有噪音,但是模型GPT3 self-instruct的效果明显优于模型GPT3+T0 Training和GPT3 + SuperNI Training
-
模型GPT3 self-instruct的效果与模型InstructGPT001的效果已经非常接近了
-
InstructGPT003效果最强
指令数据(Instruction data)收集方法:
-
参考Alpaca基于GPT3.5得到的self-instruct数据;
-
参考Alpaca基于GPT4得到的self-instruct数据;
-
用户使用ChatGPT分享的数据ShareGPT。
6. 未来的方向
1. 进一步扩大模型规模,改善模型架构和训练
改善模型的架构或者训练过程可能会带来具有涌现能力的高质量模型,并减少计算量。
一种方向是使用稀疏混合专家架构,其在保持恒定输入成本时具有更好的计算效率,使用更加局部的学习策略,而不是在神经网络的所有权重上进行反向传播,以及使用外部存储来增强模型。
2. 扩大数据规模
在一个足够大的数据集上训练足够长的时间被证明是语言模型获得语法、语义和其他世界知识的关键。近期,Hoffmann et al.认为先前的工作低估了训练一个最优模型的训练数据量,低估了训练数据的重要性。收集模型可以在其上训练更长时间的大量数据,允许在一个固定模型尺寸的约束下有更大范围的涌现能力。
3. 更好的prompt
虽然few-shot prompting简单有效,对prompting通用性的改善将进一步扩展语言模型的能力。
例如,用带有中间步骤的few-shot示例增强后,能够使模型执行多步推理任务,这是标准prompting无法实现的。此外,更好的解释为什么prompting有效,可能对在更小模型上引导涌现能力具有帮助。充分的理解模型为什么能够工作通常会滞后于技术的开发和流行,并且随着更加强大的模型被开发出来,prompting的最佳实践也可能改变。
4. 理解涌现能力
理解涌现除了研究如何进一步解锁涌现能力,一个未来研究方向是,涌现能力是如何以及为什么出现在大语言模型。理解涌现是一个非常重要的方向,这有助于我们确定模型可以拥有哪些涌现能力以及如何训练一个更强的语义模型。

