
热门标签
热门文章
- 110-斐波那契数列-python_编写程序计算此斐波那契数列的前10个值,并按顺序存入一个列表。
- 2Python 机器学习 EM算法_em算法python
- 3Docker实战案例研究:深入行业应用与最佳实践_docker使用案例
- 4这笔钱领了吗?拥有信息系统项目管理师等软考类证书可获技能提升补贴最高2000元!_软考高级 北京补助多少钱
- 5算法数据结构基础——图(Graph)_graph 算法
- 6IDEA(最新版)导入Myeclipse/eclipse的web项目并运行(全) Windows或者Mac系统_idea导入myeclipse web项目
- 7AIGC数字人视频创作平台,赋能企业常态化制作数字内容营销
- 8微信小程序 java失物招领系统uniAPP设计_失物招领微信小程序
- 9解决老旧电脑在win7中浏览器访问https网站出现的Let‘sEncrypt证书过期的问题_dst root ca x3证书下载
- 10网络状态检查工具类_networkinfo info = getactivenetworkinfo();
当前位置: article > 正文
Hadoop入门教程_hadoop 教程
作者:羊村懒王 | 2024-04-28 07:09:26
赞
踩
hadoop 教程
Hadoop入门教程
生命无罪,健康万岁,我是laity
分布式和集群的概念
- 分布式:多台机器,每台机器上部署不同组件。
- 集群:多台机器,每台机器上部署相同组件。
Hadoop核心组件
HDFS:分布式文件存储系统,用于解决海量数据存储YARN:集群资源管理和任务调度框架,用于解决资源任务调度MapReduce:分布式计算框架,用于解决海量数据计算。
HDFS 的shell
基础命令
hadoop fs -ls file:/// # 操作本地文件系统
hadoop fs -ls hdfs://Itlaity101:8020/ # 操作HDFS分布式文件系统
hadoop fs -ls / # 直接根目录,没有指定协议,将加载读取fs.defaultFS值。
- 1
- 2
- 3
# 创建文件夹 mkdir [-p] <hdfs 路径> hadoop fs -mkdir /Itlaity # 查看目录 hadoop fs -ls -h[-r] / # 上传命令 hadoop fs -put [-f] [-p] <localsrc:本地路径-客户端> <dst:HDFS地址> hadoop fs -put file:///root/1.txt hdfs://Itlaity101:8020/Itlaity/ # 标准写法 hadoop fs -put 1.txt /Itlaity/ # 简化写法 -- 参数配置好 # 查看文件内容 hadoop fs -cat <src> hadoop fs -cat /Itlaity/1.txt # 下载HDFS文件 hadoop fs -get <src> <localsrc> # 和上传命令相反 -f 覆盖 -p 保留访问和修改的时间,所有权和权限。 # 拷贝HDFS文件 hadoop fs -cp [-f] <src> <dst> # 追加数据操作 hadoop fs -appendToFile <localsrc> <dst> # 小文件追加合并 # 移动数据操作 hadoop fs -mv <src> <dst> # dst -- HDFS地址 localsrc -- 客户端地址 src -- HDFS相对路径
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
| 选项名称 | 使用格式 | 含义 |
|---|---|---|
| -ls | -ls <路径> | 查看指定路径的当前目录结构 |
| -lsr | -lsr <路径> | 递归查看指定路径的目录结构 |
| -du | -du <路径> | 统计目录下各文件大小 |
| -dus | -dus <路径> | 汇总统计目录下文件(夹)大小 |
| -count | -count [-q] <路径> | 统计文件(夹)数量 |
| -mv | -mv <源路径> <目的路径> | 移动 |
| -cp | -cp <源路径> <目的路径> | 复制 |
| -rm | -rm [-skipTrash] <路径> | 删除文件/空白文件夹 |
| -rmr | -rmr [-skipTrash] <路径> | 递归删除 |
| -put | -put <多个linux上的文件> <hdfs 路径> | 上传文件 |
| -copyFromLocal | -copyFromLocal <多个linux 上的文件> <hdfs 路径> | 从本地复制 |
| -moveFromLocal | -moveFromLocal <多个linux 上的文件> <hdfs 路径> | 从本地移动 |
| -getmerge | -getmerge <源路径> <linux 路径> | 合并到本地 |
| -cat | -cat <hdfs 路径> | 查看文件内容 |
| -text | -text <hdfs 路径> | 查看文件内容 |
| -copyToLocal | -copyToLocal [-ignoreCrc] [-crc] [hdfs 源路径] [linux 目的路径] | 复制到本地 |
| -moveToLocal | -moveToLocal [-crc] <hdfs 源路径> <linux目的路径> | 移动到本地 |
| -setrep | -setrep [-R] [-w] <副本数> <路径> | 修改副本数量 |
| -mkdir | -mkdir <hdfs 路径> | 创建空白文件夹 |
| -touchz | -touchz <文件路径> | 创建空白文件 |
| -stat | -stat [format] <路径> | 显示文件统计信息 |
| -tail | -tail [-f] <文件> | 查看文件尾部信息 |
| -chmod | -chmod [-R] <权限模式> [路径] | 修改权限 |
| -chown | -chown [-R] [属主]: [属组]路径 | 修改属主 |
| -chgrp | -chgrp [-R] 属组名称 路径 | 修改属组 |
| -help | -help -help [命令选项] | 帮助 |
Namenode – 大内存
Datanode – 大磁盘
MapReduce
分布式计算框架 – 现在已经退居二线了
MapReduce 思想
- 分而治之思想 – 大数据框架都集成这个思想
核心思想 :”先分再合,分而治之”。
-
把大的拆分成小的,把复杂的拆分成简单的,然后再合并组成这个问题的最终结果。
-
Map 表示第一阶段,负责”拆分”
-
Reduce表示第二阶段,负责”合并”:即对map阶段的结果进行全局汇总。
-
学会提交
MapReduce程序
MapReduce 执行流程
# 体验一下
myhadoop.sh start # 执行脚本启动集群
cd /opt/laityInstall/hadoop/share/hadoop/mapreduce # 切换路径
hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 2 2 # 执行命令
- 1
- 2
- 3
- 4
YARN
通用的资源管理系统和调度平台。
ResourceManager(RM)- YARN集群中的主角色,决定系统中所有应用程序之间资源分配的最终权限,即最终仲裁权。
- 提交用户的作业情况,并通过NM分配、管理各个机器上的计算资源。
NodeMananger(NM)- YARN中的从角色,一台机器一个,负责管理本机器上的计算资源。
- 根据RM命令,启动Container容器、监视容器的资源使用情况。并且向RM主角色汇报资源使用情况。
ApplicationMaster(App Mstr)(AM)- 用户提交的每个应用程序均包含一个AM。
- 应用程序中的”老大”,负责程序内部各阶段的资源申请,监督程序的执行情况。
Client- 用户端
Container容器(资源的抽象)
YARN调度策略
Scheduler– 没有好的调度器,只有符合你业务的调度器FIFO Scheduler: 先进先出调度器Capacity Scheduler:容量调度器 – Apache版本YARN默认使用Fair Scheduler:公平调度器
数据仓库基础知识
概念:数据仓库,是一个用于存储、分析、报告的数据系统。
- 数据仓库的目的是构建面向分析的集成化数据环境,分析结果为企业提供决策支持。
Hive入门
Hive是基于Hadoop的数据仓库软件,我们负责写Sql,Hive将我们写的Sql帮助我们转为mr。
- 元数据:表与文件的对应关系
元数据的概念:Metadate,又称中介数据、中继数据,为描述数据的数据,主要描述数据的属性信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
元数据的存储:Hive说如果你不想自己存我有一个自己的关系型数据库Derby,当然你也可以使用第三方如MySQL等。
Hive安装部署
搭建远程服务:不使用Hive自己的数据库,使用第三方数据库
<!--在core-size.xml中添加--> <!-- 整合hive 用户代理设置 --> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <!-- 文件系统垃圾桶保存时间 --> <property> <name>fs.trash.interval</name> <value>1440</value> </property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
安装MySQL数据库
已完成
Hive安装
-
只需要在一台服务器上安装即可
-
上传安装包并解压
tar zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/laityInstall/
- 1
- 解决Hive与
Hadoop之间guava版本差异
cd /opt/laityInstall/apache-hive-3.1.2-bin/
rm -rf lib/guava-19.0.jar
cp /opt/laityInstall/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/
- 1
- 2
- 3
-
修改配置文件
-
hive-env.sh
cd /opt/laityInstall/apache-hive-3.1.2-bin/conf mv hive-env.sh.template hive-env.sh vim hive-env.sh export HADOOP_HOME=/opt/laityInstall/hadoop export HIVE_CONF_DIR=/opt/laityInstall/apache-hive-3.1.2-bin/conf export HIVE_AUX_JARS_PATH=/opt/laityInstall/apache-hive-3.1.2-bin/lib- 1
- 2
- 3
- 4
- 5
- 6
- 7
-
-
hive-site.xmlvim hive-site.xml- 1
<configuration> <!-- 存储元数据mysql相关配置 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://Itlaity101:3306/hive3?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>Wang9264.</value> </property> <!-- H2S运行绑定host --> <property> <name>hive.server2.thrift.bind.host</name> <value>Itlaity101</value> </property> <!-- 远程模式部署metastore metastore地址 --> <property> <name>hive.metastore.uris</name> <value>thrift://Itlaity101:9083</value> </property> <!-- 关闭元数据存储授权 --> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
-
-
上传mysql jdbc驱动到hive安装包lib下
mysql-connector-java-5.1.32.jar- 1
-
初始化元数据
cd /opt/laityInstall/apache-hive-3.1.2-bin/ bin/schematool -initSchema -dbType mysql -verbos #初始化成功会在mysql中创建74张表- 1
- 2
- 3
- 4
-
在hdfs创建hive存储目录(如存在则不用操作)
hadoop fs -mkdir /tmp hadoop fs -mkdir -p /user/hive/warehouse hadoop fs -chmod g+w /tmp hadoop fs -chmod g+w /user/hive/warehouse- 1
- 2
- 3
- 4
-
启动hive
-
1、启动metastore服务
#前台启动 关闭ctrl+c /opt/laityInstall/apache-hive-3.1.2-bin/bin/hive --service metastore #前台启动开启debug日志 /opt/laityInstall/apache-hive-3.1.2-bin/bin/hive --service metastore --hiveconf hive.root.logger=DEBUG,console #后台启动 进程挂起 关闭使用jps+ kill -9 nohup /opt/laityInstall/apache-hive-3.1.2-bin/bin/hive --service metastore & # 查看jps 83078 RunJar -- 有这个就说明后台启动成功了- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
-
-
2、启动hiveserver2服务 – 不推荐
nohup /opt/laityInstall/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 & #注意 启动hiveserver2需要一定的时间 不要启动之后立即beeline连接 可能连接不上 # 显示两个 runjar 就是成功的表现 /opt/laityInstall/apache-hive-3.1.2-bin/bin/hive- 1
- 2
- 3
- 4
- 5
-
3、beeline客户端连接 – 推荐
-
拷贝node1安装包到beeline客户端机器上(node3)
scp -r /opt/laityInstall/apache-hive-3.1.2-bin/ Itlaity103:/export/server/- 1
-
错误
Error: Could not open client transport with JDBC Uri: jdbc:hive2://node1:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: root is not allowed to impersonate root (state=08S01,code=0)- 1
-
修改
在hadoop的配置文件core-site.xml中添加如下属性: <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
-
连接访问
/opt/laityInstall/apache-hive-3.1.2-bin/bin/beeline beeline> ! connect jdbc:hive2://Itlaity101:10000 beeline> root beeline> 直接回车- 1
- 2
- 3
- 4
- 5
-
-
错误解决:Hive3执行insert插入操作 statstask异常
-
现象
在执行insert + values操作的时候 虽然最终执行成功,结果正确。但是在执行日志中会出现如下的错误信息。- 1
-
-

- 开启hiveserver2执行日志。查看详细信息
```
2020-11-09 00:37:48,963 WARN [5ce14c58-6b36-476a-bab8-89cba7dd1706 main] metastore.RetryingMetaStoreClient: MetaStoreClient lost connection. Attempting to reconnect (1 of 1) after 1s. setPartitionColumnStatistics
ERROR [5ce14c58-6b36-476a-bab8-89cba7dd1706 main] exec.StatsTask: Failed to run stats task
```
- 1
- 2
- 3
- 4
- 5
- 6
- 7

- 但是 ==此错误并不影响最终的插入语句执行成功==。 - 分析原因和解决 - statstask是一个hive中用于统计插入等操作的状态任务 其返回结果如下  - 此信息类似于计数器 用于告知用户插入数据的相关信息 但是不影响程序的正常执行。 - Hive新版本中 这是一个issues 临时解决方式如下 https://community.cloudera.com/t5/Support-Questions/Hive-Metastore-Connection-Failure-then-Retry/td-p/151661 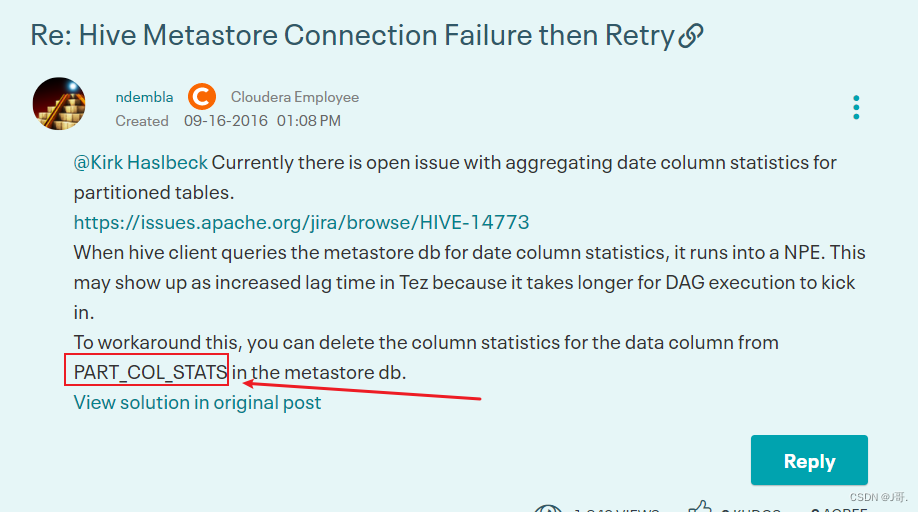 - ==在mysql metastore中删除 PART_COL_STATS这张表即可==。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
SQL语言:
- Hive可视化客户端:
DataGrip、Dbeaver、SQuirrel SQL Client等
DML语法:
关系型数据库sql语句我之前复习完完不久,所以我这里就再不做笔记了。
Load加载数据操作
# Hive服务的启动
nohup /opt/laityInstall/apache-hive-3.1.2-bin/bin/hive --service metastore & # metastore
nohup /opt/laityInstall/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 & # hiveserver2
# 客户端连接
/opt/laityInstall/apache-hive-3.1.2-bin/bin/beeline
beeline> ! connect jdbc:hive2://Itlaity101:10000
beeline> root
beeline> 直接回车
# 在 beeline客户端 中执行 -- 复制
load data local inpath "Hive部署的服务器中文件的地址(Itlaity101)" into table "HDFS存放的目标位置";
# 移动
load data inpath "HDFS的文件位置" into table "HDFS存放的目标位置";
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
insert插入数据操作
# 标准插入 -- 时间很慢
insert into table 表名("指定键") values("数据"...);
insert into table 表名 values("数据"...);
# insert + select
insert into table 表名 select 字段,字段... from student;
- 1
- 2
- 3
- 4
- 5
select查询语句
# having与where区别 -- 两个都是过滤
having 在分组(group by)后对数据进行过滤
where是在分组前对数据进行过滤
having可以使用聚合函数
where不可以使用聚合函数
# 执行顺序
select state,sum(deaths) as cnts from t_usa_covid19
where count_date = "2021-01-28"
group by state
having cnts> 10000
limit 2;
# 也就是 from > where > group by > having > limit > order by > select
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
join 关联查询 外键
# 使用最多的join分别是:
inner join -- 内连接
left join -- 左连接
# 内连接 -- 关联表的交集部分
# 左连接 -- 以左边表的全部数据为准,右边与之关联;左表数据全部返回,右表关联上的显示返回,关怀不上的显示null返回。
- 1
- 2
- 3
- 4
- 5
Hive 常用函数
# 查看hive有哪些函数
show functions;
# 描述一个函数的用法
describe function extended 函数名(count);
- 1
- 2
- 3
- 4
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

