
- 1魔百盒CM311-1a免拆机卡刷固件加+刷armbian装docker运行青龙面板
- 2基于YOLOv8深度学习的农作物幼苗与杂草检测系统【python源码+Pyqt5界面+数据集+训练代码】深度学习实战、目标检测
- 3海睿思分享 | 浅谈企业数据质量问题_数据中台中数据质量有哪些场景?
- 4技术速览|Meta Llama 2 下一代开源大型语言模型_llam2最大支持输入
- 5聊聊c#与Python以及IronPython
- 6NLP任务中常用的损失函数_nlp 损失函数分类
- 7图神经网络GAT最详细讲解(图解版)_gat网络
- 8计算机图形学 第10章 真实感图形_计算机制图是依据加色原则混合而获得的
- 9Mac系统 Redis下载与启动_mac redis下载
- 10error: src refspec master does not match any. 错误处理办法
项目实操:KBQA常规实现流程与医疗知识图谱问答源码解读_kbqa医疗问答系统 流程图
赞
踩
转载地址:项目实操:KBQA常规实现流程与医疗知识图谱问答源码解读
"看了文章,不会的还是不会,还是直接实操、直白一点好"
这其实是一种对当前碎片化阅读带来的知识获得感不足的直接表现。
而且,这也确实是最直接的知识需求。
因此,作为“理论与实践相结合”一贯理念的延续,更多实践,本文主要围绕《KG项目实操:KBQA标准实现流程与医疗知识图谱问答源码解读》,结合具体项目,讲讲知识图谱问答。
与可视化落地一样,知识图谱问答虽然目前被称作"人工智障"的典型代表,目前也有大量的个人、团队、公司在做。
而接触过知识图谱问答的朋友,可能了解过开源医疗知识图谱问答项目QASystemOnMedicalKG
地址:
https://github.com/liuhuanyong/QASystemOnMedicalKG
这是当前老刘开源项目中的一个重要部分,思想很简单,很朴素,但也收获了不少开发者的关注。
该项目目前收获3.5K个star、1.4K个fork,可以作为说明知识图谱问答的一个典型例子。
借着这个项目,本文先介绍基于KBQA的解析式知识问答流程,然后再对该项目进行进一步的拆解和源码解读,希望给大家带来一定的启发和借鉴。
一、基于KBQA的解析式知识问答流程
KBQA(Knowledge base question answering)是针对结构化数据的一种直截了当的问答方式,可以根据设定的问题类型,通过问句解析的方式,形成若干三元组及相关的操作条件,并转换成特定的查询语句,直接返回相应结果,是当前一种较为流行和新颖的搜索方式,但技术还相对较为初步。
KBQA方式的问答包括意图分析、标签(实体、操作符)识别、条件体与目标体识别、查询语句生成等几个关键步骤。
1、意图分析
意图分析是KBQA范式知识问答的第一步,其任务在于对用户所提出的问题进行问题分类,因此又称为意图分类。不同的意图对应于不同的意图槽(即所需要进行抽取识别的问句查询要素),因此后续所需进行的标签识别、条件体与目标体识别也不同,意图分类的准确性会影响整个后续环节的性能。与典型的自然语言处理分类任务一样,问题分类的方法主要包括基于学习和基于规则词典两种方式。在已有语料的情况下,可以通过语料训练,得到基于学习型方法的问题分类,在缺少训练语料时,基于关键词和规则的问题方式往往成为首选,
(1)基于词典规则的意图分类
基于词典规则方式的问题分类核心思想在于通过收集制定出能够明显标记和区分出该问题类型的触发词或关键词集合,并对所输入的问句进行词语匹配或在此基础上设定相应规则进行问题判定。
症状表现:['症状', '表征', '现象', '症候', '表现']
发病原因:['原因','成因', '为什么', '怎么会', '怎样才', '咋样才', '怎样会', '如何会', '为啥', '为何', '如何才会', '怎么才会', '会导致', '会造成']
并发症状:['并发症', '并发', '一起发生', '一并发生', '一起出现', '一并出现', '一同发生', '一同出现', '伴随发生', '伴随', '共现']
针对一个问句,分别对问句进行意图关键词进行匹配,并分别得到每种意图中对应词语的个数进行计数,根据计数信息进行排序,选择数目最大的意图作为问句的最佳意图。
(2)基于学习模型的意图分类
基于学习模型的意图分类方法,则通过预先对问句进行意图标注,形成一定规模的标注数据集,然后通过构造分类器进行训练,然后得到分类结果。
例如,在典型的FAQ法律问答当中,存在"婚姻家庭"、"劳动纠纷"、"交通事故"、"债权债务"、"刑事辩护"、"合同纠纷","房产纠纷","侵权"等13类问题,通过构造CNN和LSTM模型,可以实现意图分类,如下图采用keras搭建双向LSTM分类模型。
- '''构造LSTM网络'''
- def build_lstm_model(self):
- model = Sequential()
- model.add(LSTM(32, return_sequences=True, input_shape=(self.max_length, self.embedding_size))) # returns a sequence of vectors of dimension 32
- model.add(LSTM(32, return_sequences=True)) # returns a sequence of vectors of dimension 32
- model.add(LSTM(32)) # return a single vector of dimension 32
- model.add(Dense(13, activation='softmax'))
- model.compile(loss='categorical_crossentropy',
- optimizer='rmsprop',
- metrics=['accuracy'])
- return model
- '''训练lstm模型'''
- def train_lstm(self):
- X_train, Y_train, X_test, Y_test = self.split_trainset()
- model = self.build_lstm_model()
- model.fit(X_train, Y_train, batch_size=100, epochs=50, validation_data=(X_test, Y_test))
- model.save(self.lstm_modelpath)

通过模型运行,可以对输入的问句进行问题类型预测,例如:
- 输入:question desc:他们俩夫妻不和睦,老公总是家暴,怎么办?
- 输出:question_type: 婚姻家庭,概率为0.9994359612464905;
- 输入:question desc:我们老板总是拖欠工资怎么办,怎么起诉他?
- 输出:question_type: 劳动纠纷,概率为0.9999903440475464
实际上,单意图分类在实现上已经有较好的方式,但在真实情况下会出现多意图分类的情况,例如“我今天为啥会头痛,该怎么办?”问句中同时包含了“发病原因”和“发病治疗措施”两个意图。针对这种情况,则常需要转换成一个多标签分类任务进行处理。
2、标签(实体、操作符)识别
标签识别,是指识别出与目标数据库中相关联的实体、属性、关系或操作符集合,即常说的槽位识别。实体识别包括常见的机构、日期、金额、地点、人物等实体,职位、指标名称等属性关系。
例如,给定问句“比亚迪的老总和董秘是谁”,经过标签识别后,可以得到公司实体“比亚迪”,属性类型“老总”和“董秘”。
包含操作符的回答是处理难度较大的一类,我们会经常涉及到一些最高、最低、平均、总和、相差多少等问法,这种问题比确定性问题的解决方法要复杂一些,下图列举了一些常见的操作符示例。
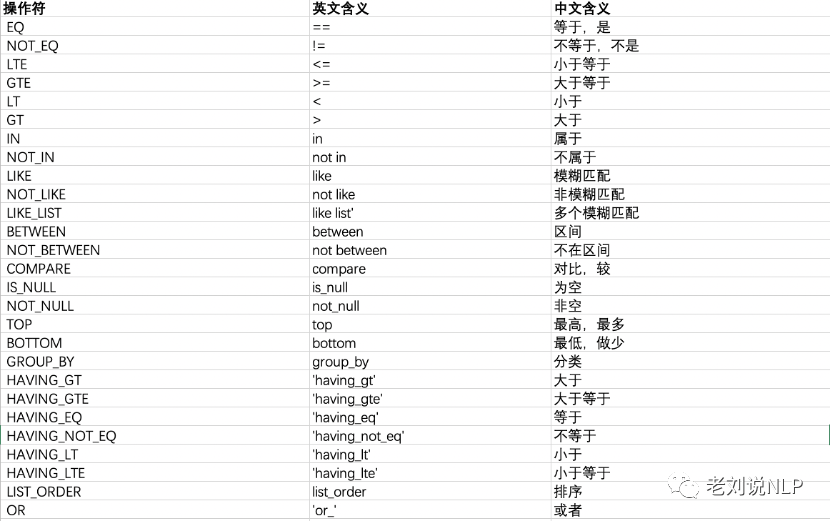
3、条件体与目标体识别
在识别完特定的标签之后,还需要在此基础上形成可供查询转换的条件部分和目标部分。条件体,即在进行答案搜索过程中需要进行匹配的条件,如某个实体或标签应该满足的属性值或关系类型(也常称为意图槽填充)。
目标体指具体需要返回的数据,通常包括某个实体或标签、某个实体或标签的属性或关系、符合条件体的布尔型数据(是否存在这样的数据)。同样的,用于条件体和目标体识别的方法包括基于规则模板和基于学习两种,基于学习方式的识别方法,可以将该任务转换为一个实体关系识别的任务。
其中,基于规则模板的识别方法包括基于问题模板和基于标签依存两种。
问题模板,即对目标实体条件体和目标体进行符号化,后续通过符号化所在索引位置直接进行相应的取值。
例如,在进行电影知识图谱问答时,在识别出电影名称、人物、角色等标签后,可针对某一类问题,自定义识别模板,例如 “参演电影”、“ 扮演角色的演员”、“ 谁在电影中扮演了某个角色”三类问题的模板示例的问题模板。
- ACTOR.*作品,ACTOR-ACTEDIN-MOVIE?
- ACTOR.*电影,ACTOR-ACTEDIN-MOVIE?
- #问扮演角色的演员
- .*参演.*ROLE,ACTOR?-TAKES-ROLE
- .*饰演.*ROLE,ACTOR?-TAKES-ROLE
- #问谁在电影中扮演了某个角色
- MOVIE.*ROLE.*出演,ACTOR?-ACTEDIN-MOVIE AND MOVIE-HASROLE-ROLE AND ACTOR?-TAKES-ROLE
- MOVIE.*ROLE.*扮演,ACTOR?-ACTEDIN-MOVIE AND MOVIE-HASROLE-ROLE AND ACTOR?-TAKES-ROLE
自定义模板映射的方式具有准确率较高,易维护和扩展的优点,但人工成本要求较多,同一个问题通常会有多种不同问法,在短时间内无法穷举所有可能。
依存关系的引入,在一定程度上解决了这一难题,构建起所识别的标签之间的父子关系,可对条件体和查询体进行准确定位,将实现识别好的标签组成一张图,并通过计算标签与标签之间的可能关联,利用动态规划的方法,找出标签之间概率最大化的依存路径。

上图以“比亚迪的老总和董秘是谁”这一问题出发,通过识别出比亚迪(公司实体)、老总(职位关系)、董秘(职位关系)并进行统一标准化后,进一步形成 <Root,比亚迪>、<比亚迪,董事长>、<比亚迪,董事会秘书>两个父子依存关联。
4、查询语句生成
查询语句生成是整个KBQA过程中的最后一步,通过问题意图分析之后,得到了查询体中的条件体和目标体,即可以通过模板转换的方式,进行语句的映射和转换,其中,查询语句的转换要和目标数据库的语言保持一致。
例如对于如下“演员导演作品”、“演员的身高”、“演员的毕业院校”、“演员扮演的角色”分别对应的查询问句转换方式为:
- # 演员导演作品
- if intention == 'ACTOR-DIRECTED-MOVIE?':
- actor = ACTORS[0]
- sql = 'MATCH (n:Actor)-[:DIRECTED]->(m:Movie) WHERE n.cn_name = "%s" return m.movie_name as name'% actor
- # 问演员的身高
- elif intention == 'ACTOR-height':
- actor = ACTORS[0]
- sql = 'MATCH (n:Actor) WHERE n.cn_name = "%s" return n.height as name'% actor
- # 问演员的毕业院校
- elif intention == 'ACTOR-college':
- actor = ACTORS[0]
- sql = 'MATCH (n:Actor) WHERE n.cn_name = "%s" return n.college as name' % actor
- # 问演员扮演的角色
- elif intention == 'ACTOR-TAKES-ROLE?':
- actor = ACTORS[0]
- sql = 'MATCH (n:Actor)-[:TAKES]->(m:Role) WHERE n.cn_name = "%s" return m.role_name as name' % actor
-
二、医疗知识图谱问答项目实践
知识图谱中记录了关于诊断检查项目、医疗科目、疾病、药品、食物、在售药品、疾病症状等多项医疗实体,疾病常用药品、宜吃食物、所需检查、忌吃食物、推荐药品、推荐食谱等实体属性信息项,疾病名称、简介、病因、预防措施、治疗周期、治疗方式、治愈概率等关系信息,可以支撑关于这些信息项的问答服务。
本项目立足医药领域,以垂直型医药网站为数据来源,以疾病为核心,构建起一个包含7类规模为4.4万的知识实体,11类规模约30万实体关系的知识图谱,
该项目利用基于关键词的方式完成问题分类,基于规则完成了问句解析和查询语句转换,以一种较为简易的方式提供了预设的问题回答服务,初步取得了一定的效果。
1、医疗知识图谱的设计
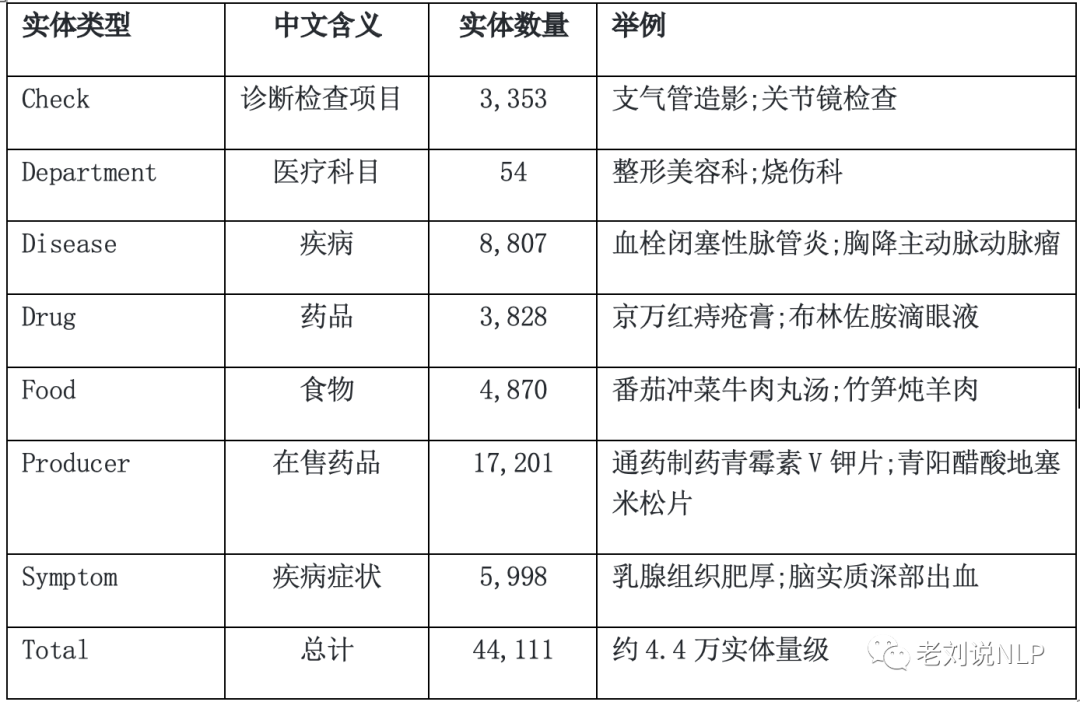
(1)实体类型 实体包含7类规模为4.4万的知识实体约4.4万实体量级。
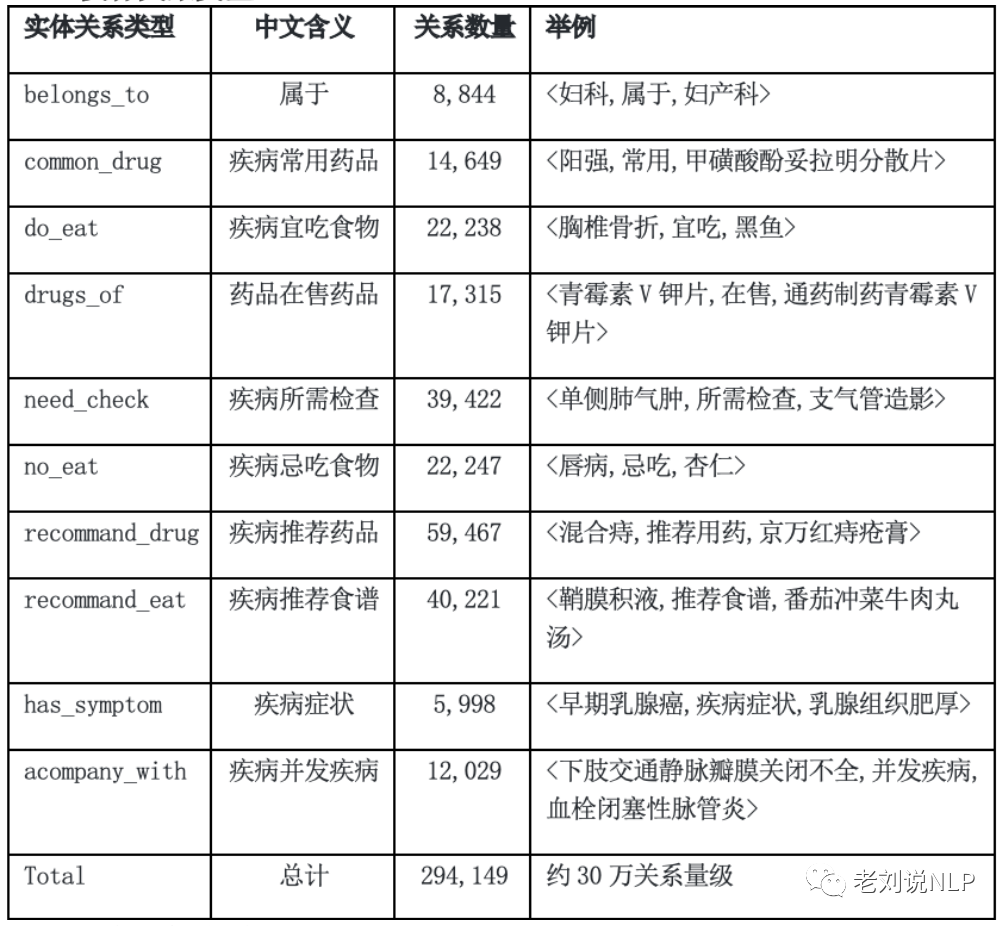
(2)实体关系类型 实体关系类型包括:11类规模约30万实体关系,总计294,149(约30万)关系。
(3)实体属性类型
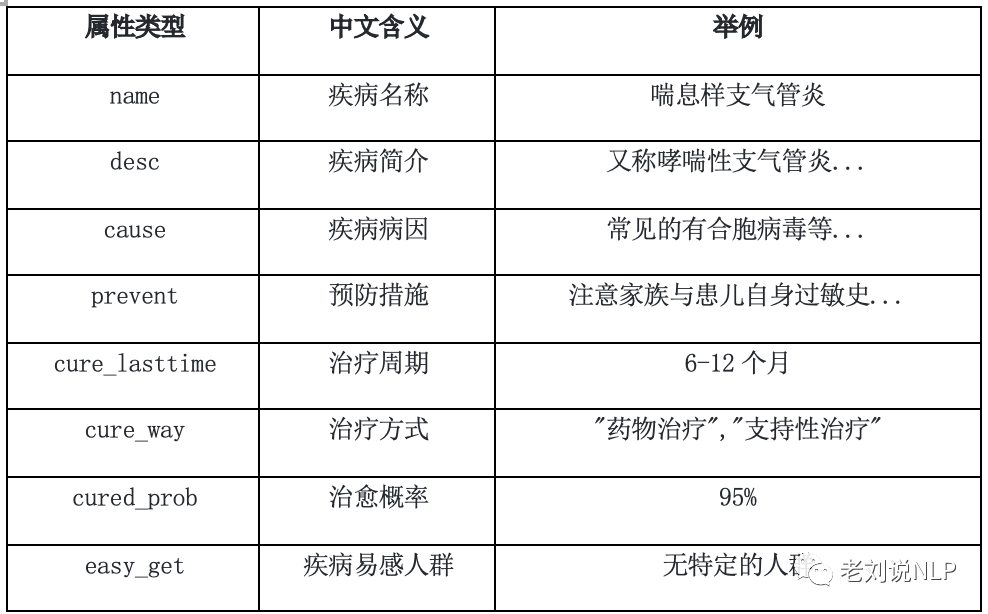
2、 知识图谱数据的导入
Neo4j是目前使用规模较大的一类图数据库,能够适用于多层关系存储、路径搜索推理等多项应用场景,并提供了人性化和语义化的查询语句cypher,本项目以Neo4j为目标数据库进行知识图谱存储。在实现上,使用py2neo编写cypher语句进行操作,先进行节点新建操作,再进行关系边新建操作,如下:
(1)创建图谱节点
- def create_node(self, label, nodes):
- count = 0
- for node_name in nodes:
- node = Node(label, name=node_name)
- self.g.create(node)
- count += 1
- print(count, len(nodes))
- return
(2)创建节点关系
- def create_relationship(self, start_node, end_node, edges, rel_type, rel_name):
- count = 0
- # 去重处理
- set_edges = []
- for edge in edges:
- set_edges.append('###'.join(edge))
- all = len(set(set_edges))
- for edge in set(set_edges):
- edge = edge.split('###')
- p = edge[0]
- q = edge[1]
- query = "match(p:%s),(q:%s) where p.name='%s'and q.name='%s' create (p)-[rel:%s{name:'%s'}]->(q)" % (
- start_node, end_node, p, q, rel_type, rel_name)
- try:
- self.g.run(query)
- count += 1
- print(rel_type, count, all)
- except Exception as e:
- print(e)
二、知识图谱问句分类与解析
1、 问句意图的设计
在对知识图谱数据进行分析之后,共设计出包括disease_symptom(疾病症状)、symptom_disease(已知症状找可能疾病)、disease_cause(疾病病因)、disease_desc(疾病描述)等在内的18种问题类型。问句类型、中文含义以及对应的问句举例如下表所示:

2、问句意图识别
在本项目中,采用基于问题关键词匹配的问题分类方法,具体步骤如下:
(1)医疗领域问句分类
先进行领域识别,因为如果用户所输入的问题与医疗领域无关,则无须进入下一步流程。在实现上,采用关键词匹配的领域分类,将医疗知识图谱中的所有实体、属性、属性值、关系类型都作为领域特征词,若问句中命中了领域特征词,则认为属于该领域;
- def check_medical(self, question):
- region_wds = []
- for i in self.region_tree.iter(question):
- wd = i[1][1]
- region_wds.append(wd)
- stop_wds = []
- for wd1 in region_wds:
- for wd2 in region_wds:
- if wd1 in wd2 and wd1 != wd2:
- stop_wds.append(wd1)
- final_wds = [i for i in region_wds if i not in stop_wds]
- final_dict = {i:self.wdtype_dict.get(i) for i in final_wds}
- return final_dict
(2)医疗实体识别与链接
医疗实体识别与链接当中,所完成的是对输入问句中的实体进行识别,并唯一地链接到医疗知识图谱中。本系统采用基于词典匹配的方式的方式来实现,由于识别出来的实体名称已经严格对应于知识图谱,因此实体链接的步骤直接完成。
因为预先设定了“disease”、“department”、 check、drug、food、symptom等实体,因此可以构造一个存储实体类别的字典wdtype_dict,可以在进行医疗领域分类时,通过获取命中关键词的所属实体类型,来得到命名实体识别的效果。需要注意的是,为了解决问句中可能会存在实体重叠的现象,本系统只保留一个最长的实体名称。
- def build_wdtype_dict(self):
- wd_dict = dict()
- for wd in self.region_words:
- wd_dict[wd] = []
- if wd in self.disease_wds:
- wd_dict[wd].append('disease')
- if wd in self.department_wds:
- wd_dict[wd].append('department')
- if wd in self.check_wds:
- wd_dict[wd].append('check')
- if wd in self.drug_wds:
- wd_dict[wd].append('drug')
- if wd in self.food_wds:
- wd_dict[wd].append('food')
- if wd in self.symptom_wds:
- wd_dict[wd].append('symptom')
- if wd in self.producer_wds:
- wd_dict[wd].append('producer')
- return wd_dict
(3)问句意图识别与槽位填充
针对所设计的问句意图,问句的意图往往与三元组中的属性类型或者关系类型等价,因此,可以以属性或关系类型作为意图种子词,通过同义词扩展的方式(借助外部同义词词典或word2vec求相似),设计能够显式标记出该问句的关键词集合。
如对于“询问症状”、“询问病因”、“询问并发症”三种意图,可以构造出如下意图关键词:
- self.symptom_qwds = ['症状', '表征', '现象', '症候', '表现']
- self.cause_qwds = ['原因','成因', '为什么', '怎么会', '怎样才', '咋样才', '怎样会', '如何会', '为啥', '为何', '如何才会', '怎么才会', '会导致', '会造成']
- self.acompany_qwds = ['并发症', '并发', '一起发生', '一并发生', '一起出现', '一并出现', '一同发生', '一同出现', '伴随发生', '伴随', '共现']。
在执行check_medical函数后,除了得到该问句是否属于医疗领域之外,实际上还顺便完成了实体识别的任务,得到的medical_dict中存储了识别出来的实体类型信息。
因此,可以基于类型识别结果和问句意图关键词匹配结果的基础上,并设定相应规则,确定该问句的意图识别。
例如,如果问句中出现了描述原因的关键词,并且包含疾病类实体(disease),那么该问句就构成了“查询疾病原因”(disease_cause)的意图,即本质上在完成已知头实体-疾病,属性词-原因,查询<疾病,原因,病因>三元组中的属性值-病因。
- def classify(self, question):
- data = {}
- medical_dict = self.check_medical(question)
- if not medical_dict:
- return {}
- data['args'] = medical_dict
- #收集问句当中所涉及到的实体类型
- types = []
- for type_ in medical_dict.values():
- types += type_
- question_type = 'others'
- question_types = []
- # 原因
- if self.check_words(self.cause_qwds, question) and ('disease' in types):
- question_type = 'disease_cause'
- question_types.append(question_type)
- # 并发症
- if self.check_words(self.acompany_qwds, question) and ('disease' in types):
- question_type = 'disease_acompany'
- question_types.append(question_type)
- data['question_types'] = question_types
- return data
一般而言,每个意图都会跟着一个预先设定好的槽位,用于填充后续查询语句转换中的具体条件取值。
而由于本系统中完成的问答是简单的三元组单条件问答,因此对于“查询疾病原因”该意图,对应的槽位较为简单,为疾病类型,槽位的元素为疾病类型具体的实体取值。如“为啥会得肩周炎”这个问句中,经识别后得到的槽位元素为“肩周炎”。
三、查询sql的生成与答案搜索
1、查询语句转换与答案组装
(1)问答查询语句转换 在完成意图识别和槽位填充之后,可以得到针对一个用户问句的问句意图以及该意图下对应的实体类型和实体值,此时则需要将其转换为相匹配的数据查询语句。
本系统依旧采用基于规则的查询语句转换方法,根据不同的查询意图,预先设计出相对应的查询语句。
例如,对于查询疾病原因这一意图,通过遍历槽位中的实体列表,形成一个标准化的查询语句。
- def sql_transfer(self, question_type, entities):
- if not entities:
- return []
- # 查询语句
- sql = []
- # 查询疾病的原因
- if question_type == 'disease_cause':
- sql = ["MATCH (m:Disease) where m.name = '{0}' return m.name, m.cause".format(i) for i in entities]
- # 查询疾病的防御措施
- elif question_type == 'disease_prevent':
- sql = ["MATCH (m:Disease) where m.name = '{0}' return m.name, m.prevent".format(i) for i in entities]
- # 查询疾病的持续时间
- elif question_type == 'disease_lasttime':
- sql = ["MATCH (m:Disease) where m.name = '{0}' return m.name, m.cure_lasttime".format(i) for i in entities]
(2)答案搜素与组装
在完成查询语句的转换之后,则可以进入知识图谱数据库中进行查询,得到相应的结果,而由于返回的结果是十分精简的。
因此为了增强用户的使用体验,一般情况下会采用规范化模板的方式进行答案组装,根据对应的问句意图类别,调用相应的回复模板。
- def answer_prettify(self, question_type, answers):
- final_answer = []
- if not answers:
- return ''
- if question_type == 'disease_symptom':
- desc = [i['n.name'] for i in answers]
- subject = answers[0]['m.name']
- final_answer = '{0}的症状包括:{1}'.format(subject, ';'.join(list(set(desc))[:self.num_limit]))
2、答案拼接与问答返回
例如,下面是该系统搭建后的一些实际运行实例:
- 用户:乳腺癌的症状有哪些?
- 小勇: 乳腺癌的症状包括:乳腺癌的远处转移;胸痛;乳头溢液;乳头破碎;肝肿大;泌乳障碍;乳头内陷;乳房肿块;剧痛
- ************************************************************
- 用户:最近老流鼻涕怎么办?
- 小勇: 症状流鼻涕可能染上的疾病有:枯草热;副流行性感冒;急性上呼吸道感染;硫化氢中毒;小儿衣原体肺炎;风寒感冒;慢性额窦炎;鼻源性头痛;人禽流行性感冒;小儿流行性喘憋性肺炎;病毒性感冒;慢性鼻炎;风热犯肺;感冒;顿呛;小儿急性上呼吸道感染;嗜酸细胞增多性非变态反应性鼻炎;干酪性鼻窦炎;下呼吸道感染;麻疹。
- ************************************************************
- 用户:失眠有哪些并发症?
- 小勇: 失眠的症状包括:心肾不交;神经性耳鸣;咽鼓管异常开放症;偏执狂;十二指肠胃反流及胆汁反流性胃炎;腋臭;黧黑斑;巨细胞动脉炎;Stargardt病;抑郁症;腔隙性脑梗死;甲状腺功能亢进伴发的精神障碍;紧张性头痛;胃下垂;心血虚;迷路震荡;口腔结核性溃疡;痰饮;游走性结节性脂膜炎;小儿脑震荡
- ************************************************************
- 用户:失眠的人不要吃啥?
- 小勇: 失眠忌食的食物包括有:油条;河蚌;猪油(板油);淡菜(鲜)
四、总结
本文主要围绕知识图谱应用中的KBQA进行介绍,包括KBQA的标准流程以及以现有的医疗知识图谱问答项目为例子进行讲解。
关于该项目的更多信息,可以直接访问地址:https://github.com/liuhuanyong/QASystemOnMedicalKG。
网上也有很多关于该项目的解读,关于运行环境等,也可以直接查询。
开源项目的用法,建议先了解原理,明确运行环境,然后实践,真正转化为自己的东西。
参考文献
1、https://liuhuanyong.github.io
2、https://github.com/liuhuanyong/QASystemOnMedicalKG
3、https://github.com/liuhuanyong/QAonMilitaryKG
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
现就职于360人工智能研究院、曾就职于中国科学院软件研究所。
老刘说NLP,将定期发布语言资源、工程实践、技术总结等内容,欢迎关注。


