
- 1Kafka学习笔记 : 消费进度监控 [ 消费者 Lag 或 Consumer Lag ]_kafka lag
- 2算法入门之冒泡排序详解(C#、java)实现_请使用 java , c , c #其中的任何一种语言来编写一个冒泡排序方法
- 3全网最全讲解Stable Diffusion原理,小白也能看懂!速来!!!
- 4『FPGA通信接口』DDR(3)DDR3颗粒读写测试
- 5【C语言】库函数—qsort
- 6零基础Linux_6(开发工具_下)函数库链接+Makefile+实现进度条+Git
- 7NLP | python实现word2vec_python word2vec
- 8企业架构研究总结(19)——TOGAF架构开发方法(ADM)之准备阶段
- 9推荐一款强大的Go语言代码审查工具:Goview
- 10加油吧,原力计划升级版来了!_csdn 现有博客加入原力计划
【Deepsort-yolov5实现无人机视觉检测和跟踪】_仿真环境 yolo视觉跟踪
赞
踩
Deepsort-yolov5无人机视觉检测和跟踪
无人机视觉检测和跟踪系列
数据集一
数据集二
数据集三
数据集四
数据集五
数据集六
数据集七
数据集八
无人机视频段
YOLOv5无人机训练权重
YOLOv3无人机训练权重
Darknet-YOLOv3无人机训练权重
Darknet-YOLOv4无人机训练权重
SSD无人机检测训练权重
CenterNet无人机检测训练权重
Deepsort-YOLOv5无人机视觉检测和跟踪代码
1. YOLOv5无人机视觉检测
1.1 训练无人机数据集
- 准备无人机数据集:需要
YOLO格式的标签,若数据标签式VOC,则需要转换; - 划分数据集:将数据集划分为训练集train、验证集
val、测试集test,其中train和val用于训练,test用于对训练好的模型进行评估,在YOLOv5中,test用于val.py(或者test.py,5版中用于验证的脚本是test.py)对训练好的模型进行验证;
# val.py或者test.py
parser.add_argument('--task', default='test', help='train, val, test, speed or study')
- 1
- 2
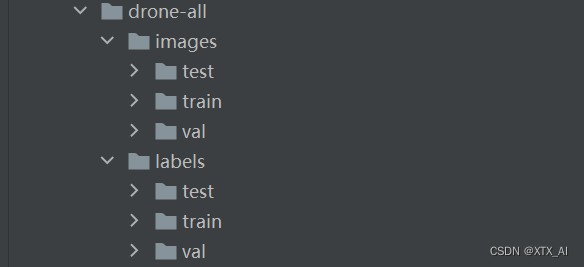
- 划分好的数据集文件目录结构如下所示,其中
images中放图片,lables中放对应的txt格式标签:
- 新建加载数据的配置文件
drone.yaml。在YOLOv5项目文件下的data文件夹中新建drone.yaml文件,其内容如下:
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
#path: ../datasets/coco128 # dataset root dir
train: ../drone-all/images/train # train images (relative to 'path') 128 images
val: ../drone-all/images/val # val images (relative to 'path') 128 images
test: ../drone-all/images/test # test images (relative to 'path') 128 images(optional)
# Classes
nc: 1 # number of classes
names: [ 'drone'] # class names
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 然后修改
train.py中的参数行中的--weights,--data,--epochs,--batch-size,就运行trian.py就开始训练了。修改后的参数如下:
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/drone.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=150)
parser.add_argument('--batch-size', type=int, default=8, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--entity', default=None, help='W&B entity')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
opt = parser.parse_args()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
1.2无人机检测结果
训练完成后,权重文件以及训练过程中的各种指标曲线图保存在runs/train/exp文件夹中;然后在detect.py中修改一些参数加载训练好的无人机pt权重文件,运行detect.py就可以实现无人机的检测,需要修改的部分如下:
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='runs/exp/weights/best.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='./drone_imgs', help='source') # file/folder, 0 for webcam
- 1
- 2
- 3
其中,“--weight” 参数是加载训练好的无人机检测权重文件;'--source'参数是设置要检测的图片或者视频,或者调用摄像头实时检测无人机。'--source'使用方法如下:
Usage - sources:
$ python detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
'path/*.jpg' # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
无人机检测结果示例如下图所示:

2. Deepsort跟踪
2.1 算法原理
Sort算法利用卡尔曼滤波和匈牙利匹配,将 跟踪结果和检测结果之间的 IoU 作为代价矩阵,实现 了一种简单高效并且实用的跟踪范式。
但是 SORT 算 法的缺陷在于所使用的关联度量(Association Metric) 只有在状态估计不确定性较低的情况下有效,因此算 法执行时会出现大量身份切换现象,当目标被遮挡时 跟踪失败。为了改善这个问题,DeepSORT 将目标的 运动信息和外观信息相结合作为关联度量,改善目标 消失后重新出现导致的跟踪失败问题。
DeepSORT 利用检测器的结果初始化跟踪器,每个跟踪器都会设置一个计数器,在卡尔曼滤波之后 计数器累加,当预测结果和检测结果成功匹配时,该 计数器置为 0。在一段时间内跟踪器没有匹配到合适 的检测结果,则删除该跟踪器。DeepSORT 为每一帧 中新出现的检测结果分配跟踪器,当该跟踪器连续 几帧的预测结果都能匹配检测结果,则确认是出现了新 的轨迹,否则删除该跟踪器。
2.2 无人机跟踪实现
将YOLOv5整个项目代码放入到Deepsort项目代码中,并将其重命名为yolov5,在track.py中修改一些参数如下:
parser = argparse.ArgumentParser() #参数设置,下面是一系列参数设置选项,自己根据需要进行设置
parser.add_argument('--yolo_weights', nargs='+', type=str, default='yolov5/weights/yolov5m.pt', help='model.pt path(s)') #加载权重,
parser.add_argument('--deep_sort_weights', type=str, default='deep_sort_pytorch/deep_sort/deep/checkpoint/ckpt.t7', help='ckpt.t7 path')
# file/folder, 0 for webcam
parser.add_argument('--source', type=str, default='car_track-1.mp4', help='source') #这里把car_track-1.mp4改成自己需要跟踪的视屏,注意路径
parser.add_argument('--output', type=str, default='inference/output', help='output folder') # 输出结果保存在inference/output下
parser.add_argument('--img-size', type=int, default=416, help='inference size (pixels)') #416指将图片缩放至416尺寸
parser.add_argument('--show-vid', action='store_true', help='display tracking video results') #--show-vid指运行过程中显示出结果
parser.add_argument('--save-vid', action='store_true', help='save video tracking results') #--save-vid指对跟踪后的视屏
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
修改后运行track.py即可实现无人机的多目标跟踪,跟踪结果如下所示:

2.3 无人机运动轨迹可视化
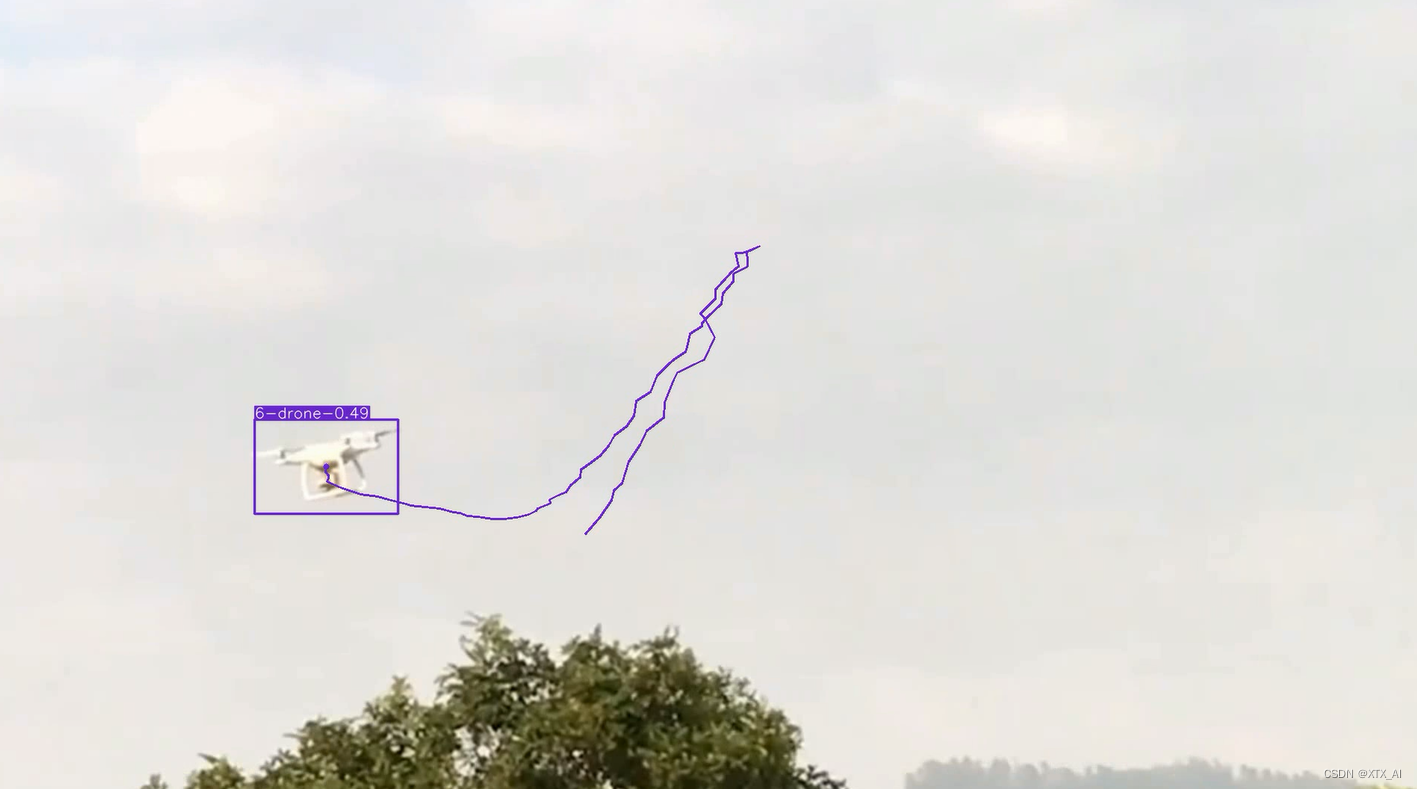
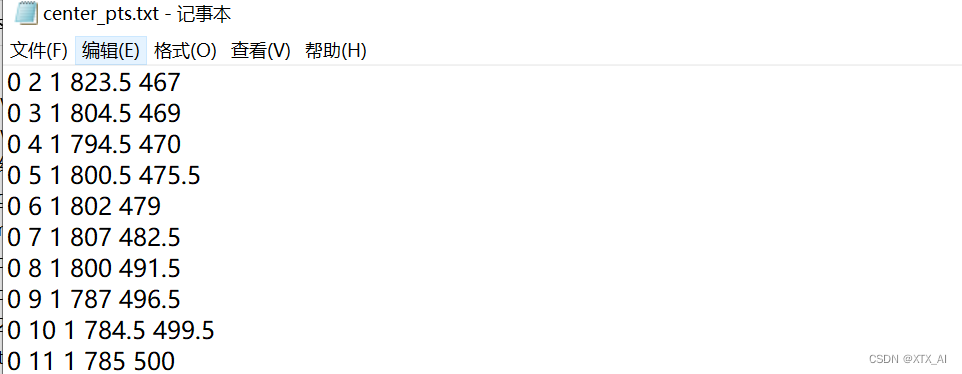
2.4 目标质心点保存
质心坐标保存在center_pts.txt中;其中每行数据分别为cls_id, frame_idx, id,center_x, center_y(类别ID,第几帧,身份ID, 质心坐标x, 质心坐标y)
2.5目标重识别模型要注意的问题
deepsort中的目标重识别模型是在行人数据集中训练得到,针对其他目标的跟踪效果肯定没有行人跟踪效果那么好,但还是能用的。当然也可以针对特定跟踪目标制作目标重识别数据集,然后再选用先进的目标重识别算法训练,这个跟踪的效果可能会更好。
3. 飞机目标检测


