
- 1linux配置git账号密码_linux git重新设置用户名密码
- 22021“MINIEYE杯”中国大学生算法设计超级联赛(10)Pty loves lines(动态规划 | DP)_pty loves lineshdu
- 3Qt实现多通道串口示波器(附完整源码)_使用qt多通道波形显示
- 4Paper:《Is GPT-4 a Good Data Analyst?GPT-4是一个好的数据分析师吗?》翻译与解读_gpt data analyst
- 5视频流网络透传分析_视频透传方案
- 6给定横坐标插值获得纵坐标(包含时间序列插值)Python_python中如何将一个函数的纵坐标的某一个值与它对应的横坐标用虚线连接起来
- 7async await 面试题_async function async1(){ console.log(1); await asy
- 82023年,程序员如何构建持续增长的被动收入?
- 9Ts学习之路-基础篇(可选参数 or 参数默认值)_ts 定义对象设置默认值
- 10在线教育数据分析实战项目案例_在线教育数据分析项目实战数据分析--
Ubuntu22.04本地部署qwen模型、jupyterlab开发环境、LoRA微调全流程-续
赞
踩
接上一篇博客。现在开始准备数据,进行Qwen模型的LoRA微调。
准备微调环境及微调数据
准备微调环境
Qwen微调环境要求为:

降级pydantic为2.0以下
先查看版本:
pip show pydantic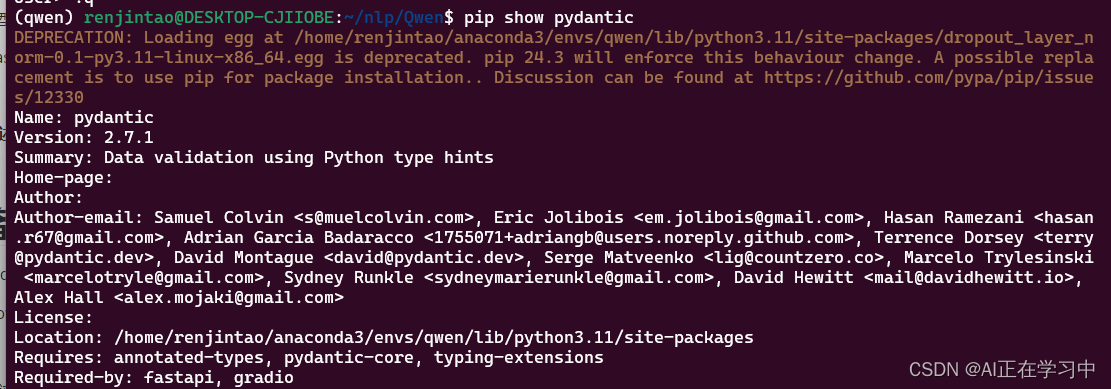
可以通过试错的方式验证当前这个包有哪些版本:
pip install pydantic==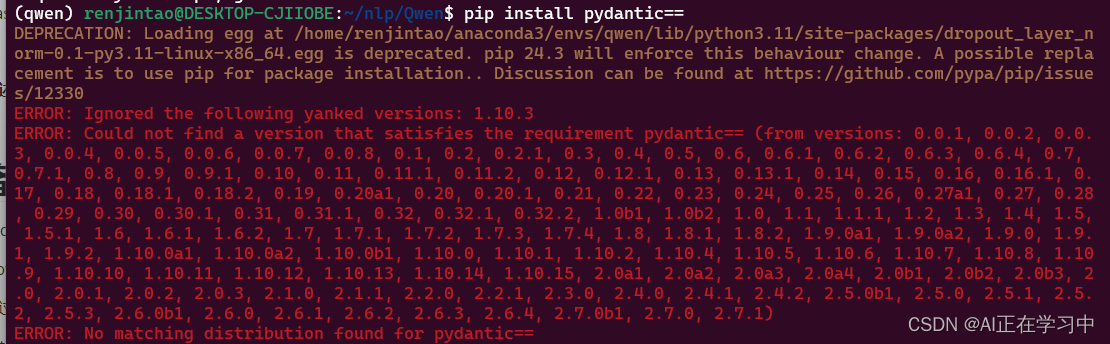
这里选择1.10.10的版本:
pip install pydantic==1.10.10安装合适版本的deepspeed(采用多GPU的需要,实现了多卡的并行加速,负载均衡等)
pip install deepspeed==0.10.0同样的方式安装peft:
查看有哪些版本:
pip install peft==
选择0.6.2
pip install peft==0.6.2
微调数据准备
Qwen模型微调数据格式:

我们选择一个开源中文医疗问答数据集:
网址:wjjingtian/cMQA: 中文医疗问答数据集 (github.com)
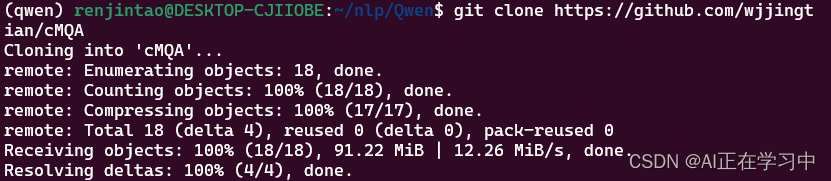
直接git clone:
git clone https://github.com/wjjingtian/cMQA多尝试几次就能下载成功:
解压文件:
unzip questions.zip
我们可以查看一下下载的数据:
问题:
- import pandas as pd
- question_file_path = './cMQA/questions.csv'
- question_df = pd.read_csv(question_file_path)
- print(question_df.head(10))

答案:
- ans_file_path = './cMQA/answers.csv'
- ans_df = pd.read_csv(ans_file_path)
- print(ans_df.head(10))

可以看到该数据集是根据question_id和ans_id一一对应的。
我们需要将其转换为Qwen模型可以进行训练的格式:

采用pd的DataFrame
- # 合并问题和答案 DataFrame
- merged_df = pd.merge(question_df, ans_df, on='question_id', suffixes=('_question', '_answer'))
-
- # 查看合并后的dataFrame
- merged_df.head(10)

我们定义一个完整的函数进行转换:
- import json
-
- def export_conversations_to_json(df, num_records, file_name):
- """
- 将对话数据导出到JSON文件。
-
- :param df: 包含对话数据的 DataFrame
- :param num_records: 要导出的记录数
- :param file_name: 输出 JSON文件的名称
- """
- output = []
-
- # 遍历DataFrame并构建所需的数据结构
- for i, row in df.head(num_records).iterrows():
- identity = f"identity_{i}"
- conversation = [
- {"from": "user",
- "value": row['content_question']},
- {"from": "assistant",
- "value": row['content_answer']}
- ]
- output.append({"id": identity,
- "conversations": conversation})
- # 将列表转换为JSON格式并保存为文件
- with open(file_name, 'w', encoding='utf-8') as f:
- json.dump(output, f, ensure_ascii=False, indent=2)

实施转换:
- # 使用示例
- export_conversations_to_json(merged_df, 20000, 'medical_treatment.json')
再查看一下转换后的数据:
- import pandas as pd
-
- # 假设df是你的DataFrame
- df = pd.read_json('medical_treatment.json')
-
- # 查看前两条数据
- df.head(2)
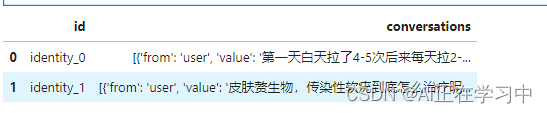
也可以到pycharm或者jupyterlab中查看,转换后的数据格式:
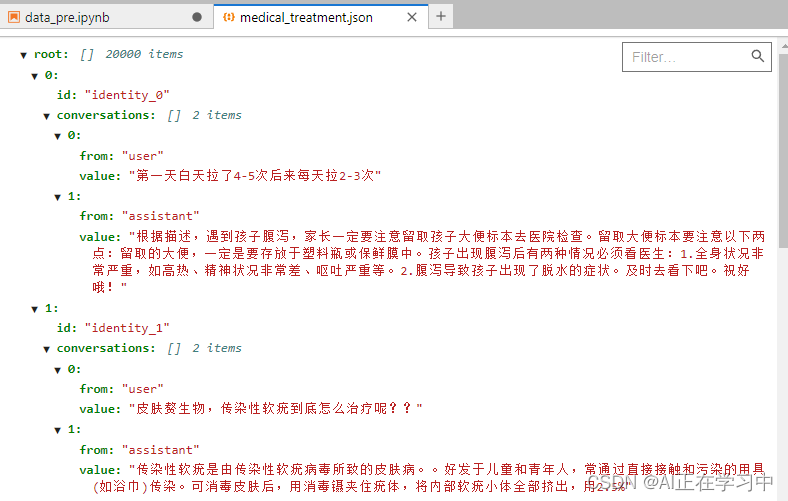
到这里数据准备妥当了,开始修改微调的配置文件,启动微调。
启动LoRA微调
修改微调脚本
我是单GPU,因此选择的是finetune_lora_single_gpu.sh:
修改对应的路径:
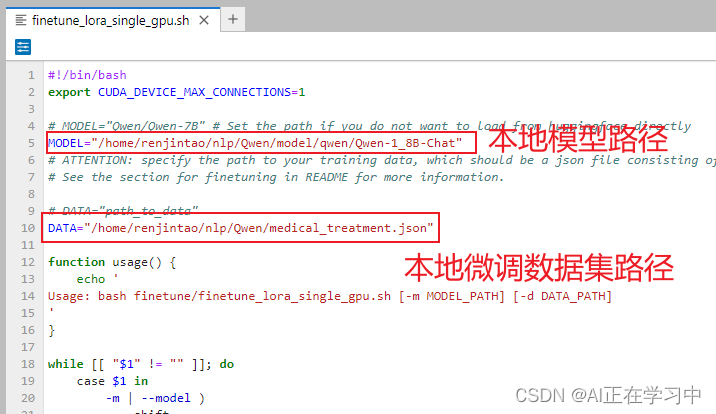
注意,这里都需要使用绝对路径。
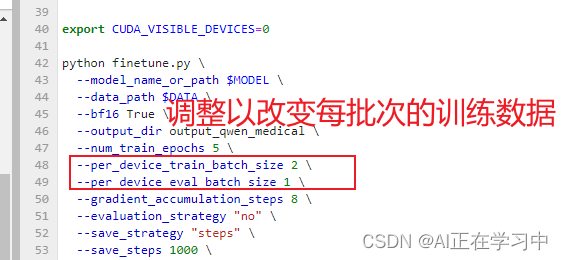
还有两处修改:

也可以调整每批次的训练数据,来最大化利用显存:
启动微调脚本
在终端上输入:
bash finetune_lora_single_gpu.sh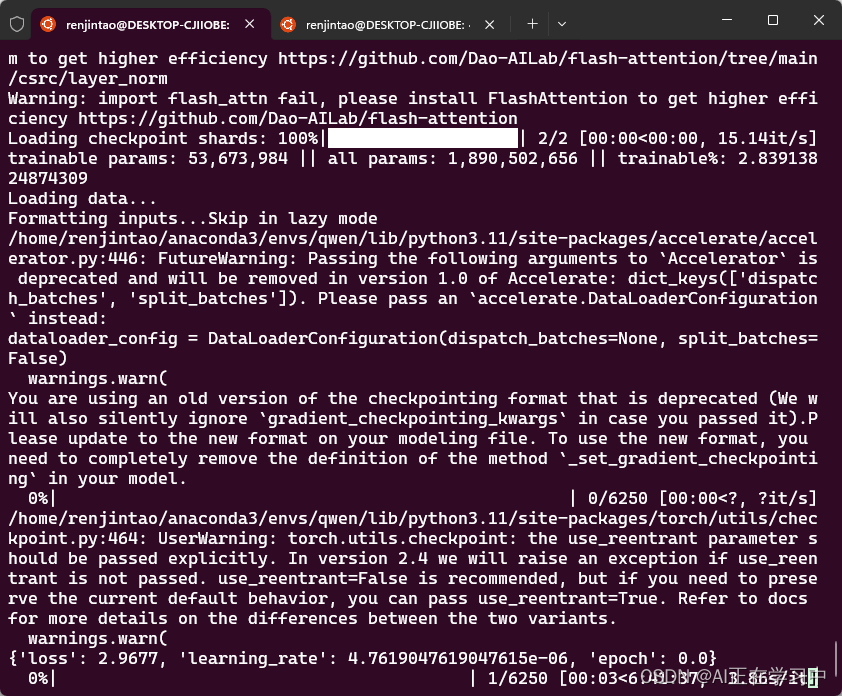
看一下显存占用
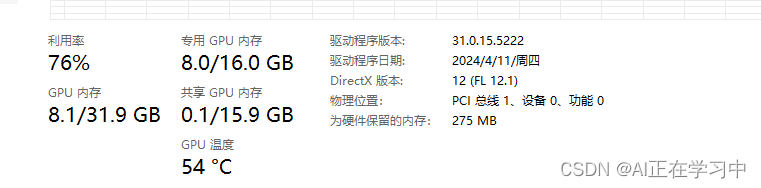
1.8B模型的LoRA微调,占用也就8GB显存
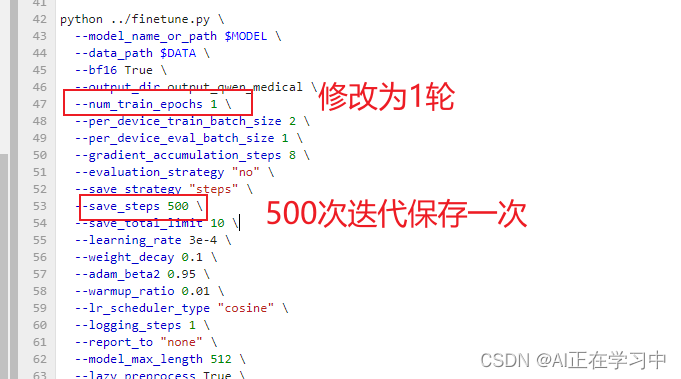
这个太久了,把参数修改一下:

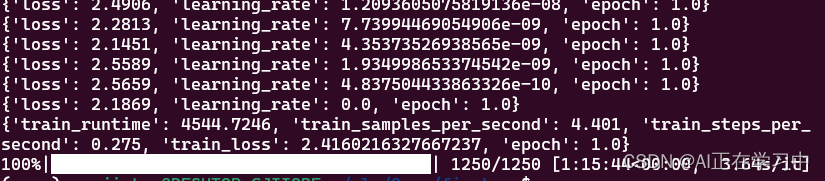
接下来等待一个小时,发现已经微调完毕了:
在finetune文件夹下多出一个文件夹:
里面有相应的参数,以及checkpoint文件夹。我这里发现最后一步1250的checkpoint未保存,因为我设置的是每500次迭代保存一次。
启动LoRA微调后的模型

检查peft版本
pip show peft如果peft版本大于多等于0.8.0,要进行版本降级:
pip install peft==0.6.2通过peft加载微调后的模型:
- from peft import AutoPeftModelForCausalLM
- # 设置LoRA微调后的模型存储路径(checkpoint)
- model = AutoPeftModelForCausalLM.from_pretrained("/home/renjintao/nlp/Qwen/finetune/output_qwen_medical/checkpoint-1000/", device_map='auto',trust_remote_code=True).eval()
- from transformers import AutoTokenizer
- tokenizer = AutoTokenizer.from_pretrained("/home/renjintao/nlp/Qwen/model/qwen/Qwen-1_8B-Chat", trust_remote_code=True)
启动对话:
- # 第一轮对话
- response, history = model.chat(tokenizer, "我月经已经超过20天没来了用试纸检查没有怀孕,我刚刚参加工作会不会是工作压力导致的", history =None)
- print(response)
回答:
![]()
如果不采用微调模型的回答:
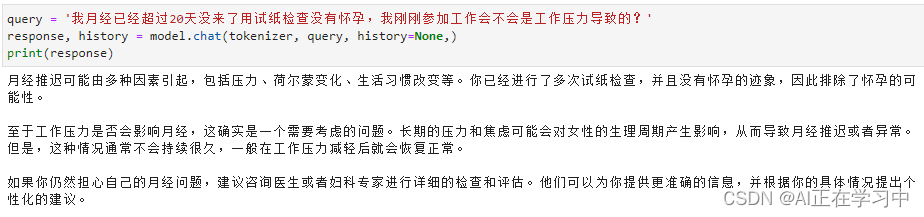
其实从该回答上来看已经与未经过微调的模型有很大的区别了,LoRA微调已经使得模型在回答医疗相关的问题上有很大的改变。
下一篇将描述微调模型的保存,合并,以及对微调前后的模型进行对比。

