
- 1jsoncpp 的学习和简单的使用案例_jsoncpp json数组赋值
- 2Solaris基本安全配置规范_solaris检查是否配置安全日志完备性要求
- 3使用Docker部署debezium来监控 MySQL 数据库_debezium镜像的dockerfile
- 42024年的低代码:数字化、人工智能、趋势及未来展望
- 5Python-VBA函数之旅-classmethod函数
- 6Linux操作系统各版本ISO镜像下载(包括oracle linux\redhat\centos\ubuntu\debian等)_download linux iso
- 7工作流是什么
- 8STM32—— DMA介绍_stm32 dma
- 9GitHub项目首页添加内容介绍(添加图片)_github添加图片介绍
- 10迅为嵌入式linux驱动开发笔记(十)—IIC驱动实验_i2cdev 应用层开发
yolov5训练自己的数据集,详细教程!_yolov5数据集要多少张合适
赞
踩
yolov5系列文章目录
yolov5 win10 CPU与GPU环境搭建,亲测有效!
爬取百度图片Python脚本
yolov5训练自己的数据集,详细教程!
yolov5转tensorrt模型
前言
前一篇文章已经交代了yolov5的安装步骤,这篇文章来讲述一下训练自己的数据集的过程。
公司项目:轮船黑烟检测,现在基本做完了特此来记录一下。
一、数据集的制作
制作数据集是一个繁琐且枯燥的过程,这里需要使用LabelImg工具,具体步骤就不展开了,但是大家标注具体类别的时候一定要细心,因为这会决定你的预测结果。
尽量标注最小矩形框!!!
我用到的是自己收集和标注的黑烟数据集,大概7000张。
二、配置文件
1.创建文件
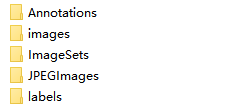
在data下创建如下几个文件夹(注意: images内为数据集原始图片,Annotations内为标注的xml文件)
并将images内文件复制到JPEGIamges中。
根目录下创建 make_txt.py 文件,代码如下:
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
根目录下继续创建 voc_label.py 文件,代码如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test','val']
classes = ['darksmoke']
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id))
out_file = open('data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
在这里要注意: 我这里的 classes = [‘darksmoke’] 仅代表我的数据集需要标注的类别是darksmoke类,单引号的内容需要根据你的数据集确定,有几类就写几类。
修改之后,依次执行上面两个py文件,执行成功是这样的:
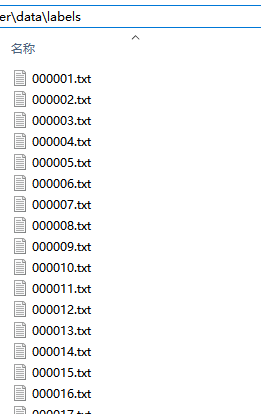
(1) labels下生成txt文件(显示数据集的具体标注数据)
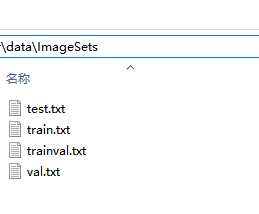
(2) ImageSets下生成四个txt文件
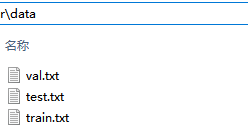
(3) data下生成三个txt文件(带有图片的路径)
2 .修改yaml文件
这里的yaml和以往的cfg文件是差不多的,但需要配置一份属于自己数据集的yaml文件。
复制data目录下的coco.yaml,我这里命名为darksmoke.yaml
主要修改三个地方:
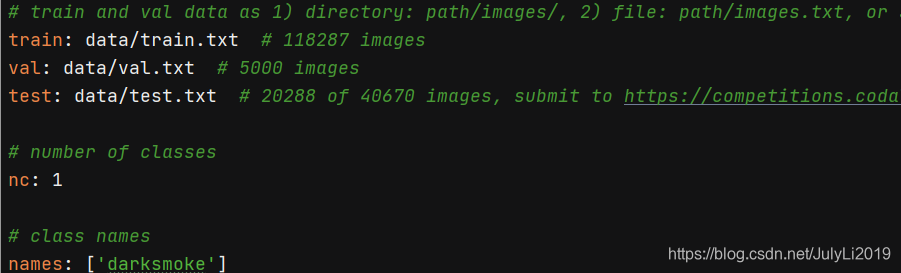
a. 修改train,val,test的路径为自己刚刚生成的路径
b. nc 里的数字代表数据集的类别,我这里只有darksmoke一类,所以修改为1
c. names 里为自己数据集标注的类名称,我这里是darksmoke
3.修改models模型文件
models下有四个模型,smlx需要训练的时间依次增加,按照需求选择一个文件进行修改即可
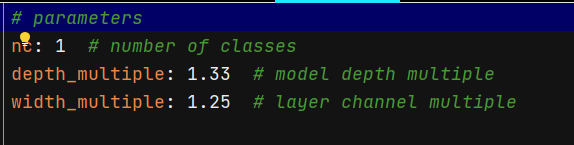
因为是工程项目,这里修改了yolov5x.yaml,确保有效性,只需要将nc的类别修改为自己需要的即可,我这里是一类所以为1。
4.训练train.py
这里需要对train.py文件内的参数进行修改,按照我们的计算机配置修改即可,以下是按照公司显卡2080TI来配置的。
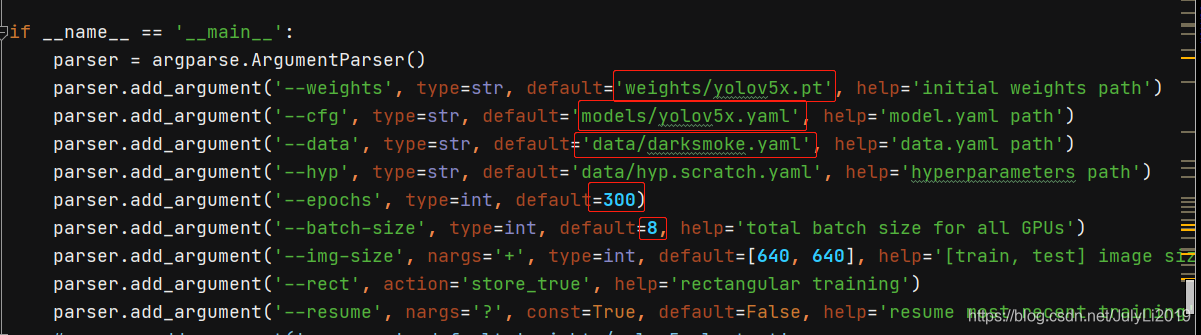
weights,cfd,data按照自己所需文件的路径修改即可
epochs迭代次数自己决定,我这里仅用300次进行测试
batch-size过高可能会影响电脑运行速度,还是要根据自己电脑硬件条件决定增加还是减少
修改完成,运行即可!
5.可能遇到的错误
1.训练时总是提醒out of memory
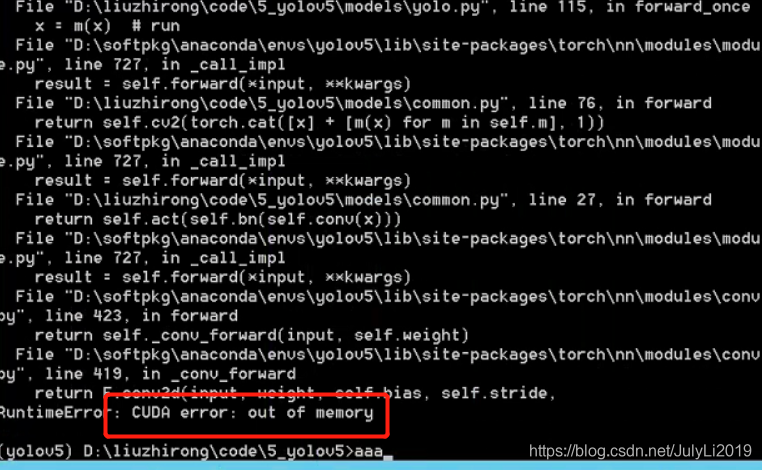
解决尝试:
1.把batchsize调小
2.如果batchsize设置为1了跑不起来,在train.py文件开头加上(我遇到的问题)
import os
os.environ['CUDA_VISIBLE_DEVICES']='0'
- 1
- 2
6.测试detect.py
当train.py跑完时,会在runs\train\exp**\weights下生成最好与最新的pt权重文件。

可以去detect.py下修改参数,也可以直接运行这一行代码
python detect.py --weights runs/train/exp3/weights/best.pt --source data/Samples/ --device 0 --save-txt
- 1
source data/Samples/ 代表的是需要预测的图片路径,根据自己情况修改即可
运行结果:(结果图片会在runs\detect\exp文件夹中生成)

淡淡的黑烟也能检测出:

总结
yolov5效果很强大,也很容易上手!!!学了yolov5就不想再用mask了。。。
数据集有需要记得留言呀!!!
如果阅读本文对你有用,欢迎关注点赞评论收藏呀!!!
2021年1月16日14:50:31

