
- 1ACM算法入门——二分查找_acm简单二分
- 2模态对话框和非模态对话框的消息循环分析_mfc 使用非模态窗口的消息循环问题
- 3spacy库中文模型的安装_安装spacy的中文模型
- 4算法随想录——数组篇
- 5记一次内网渗透_yxcms1.2.1漏洞
- 6leetcode456.132模式_输入一个整数序列:a1, a2, ..., an,一个132模式的子序列ai, aj, ak被定义为
- 7Java - Apache tomcat环境配置+Java EE项目创建部署_java apache
- 8性能测试(二)—— JMeter元件作用域和执行顺序、JMeter示例、JMeter参数化_jmeter元件执行顺序
- 9VS code开发工具的使用教程_vs icedigeditor 使用
- 10光伏逆变器资料 8-10KW 5-8KW古瑞瓦特光伏逆变器电 路图、光伏逆变器资料 古瑞瓦特的5-10KW资料逆变器带程序_古瑞瓦特逆变器电路图
《数学之美》——第三章 个人笔记_katz’ backoff
赞
踩
数学之美
最近在读《数学之美》这本书,做一下个人笔记。看的是PDF,看完后会买一本的哦!版权意识还是有的。
ps:图片文字都是这本书中的内容,侵权立删。会有点自己的理解。
第三章 统计语言模型
1 用数学的方法描述语言规律
普遍描述:假定S表示某一个有意义的句子,由一连串特定顺序排列的词w1,w2,...,wn组成,(这里应该是特征列表)这里n是句子的长度。现在,我们想知道S在文本中出现的可能性,也就是数学熵上所说的S的概率P(S)。
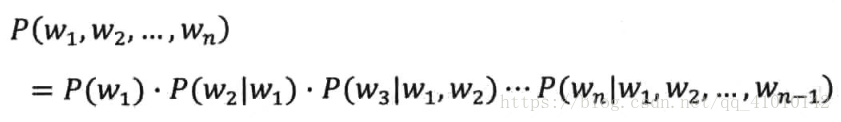
马尔可夫假设后,
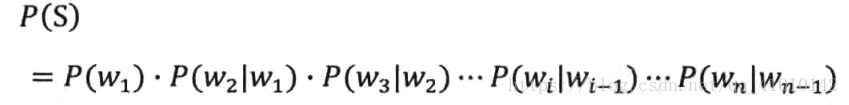
2 延伸阅读:统计语言模型的工程诀窍
2.1 高阶语言模型
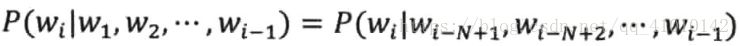
当前词wi的概率值取决于前面N-1个词,上面的假设被称为N-1阶马尔可夫假设,对应的语言模型称为N元模型。N=2就是前面的二元模型。N=1的一元模型实际上是一个上下文无关的模型,N=3在实际中应用最多。
N为什么一般取值都很小?
①首先,N元模型的大小(空间复杂度)几乎是N的指数函数,即0(丨V丨**N),这里丨V丨是一种语言词典的词汇量,一般在几万到几十万个。
②而使用N元模型的速度(时间复杂度)也几乎是一个指数函数,0(丨V丨**N-1)。因此,N不能很大。当N从1到2,再从2到3,效果显著;从3到4,提升就不是很显著了,资源的耗费缺相反。,Google的罗塞塔是4元。
2.2 模型的训练、零概率问题和平滑问题
在数理统计中,我们之所以敢用对采样数据进行观察的结果来预测概率,是因为有大数定理,要求有足够的观测值(增加数据量真的是一个真理)。
针对零概率:
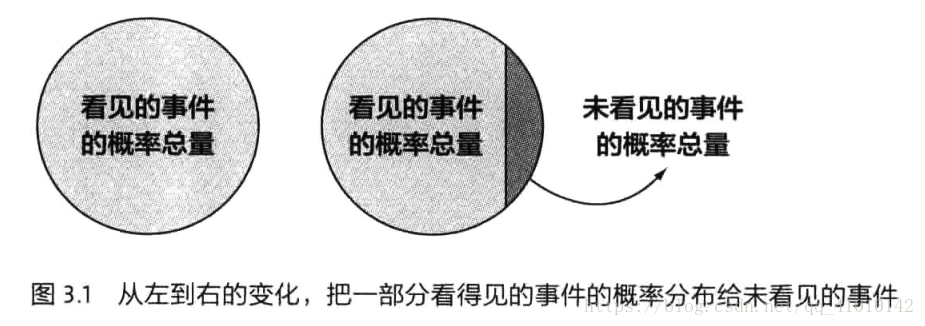
假定r比较小时,统计就不可靠,因此在计算那些出现r次的词的概率时,要实用一个更小一点的次数,是dr,
dr = (r+1)* Nr+1/Nr 显然 ∑dr*Nr = N.
文中有个Zipf定律(Zipf's Law):出现一次的词的数量比出现两次的多,出现两次的比出现三次的多。
出现r次的词的数量Nr和r的关系:
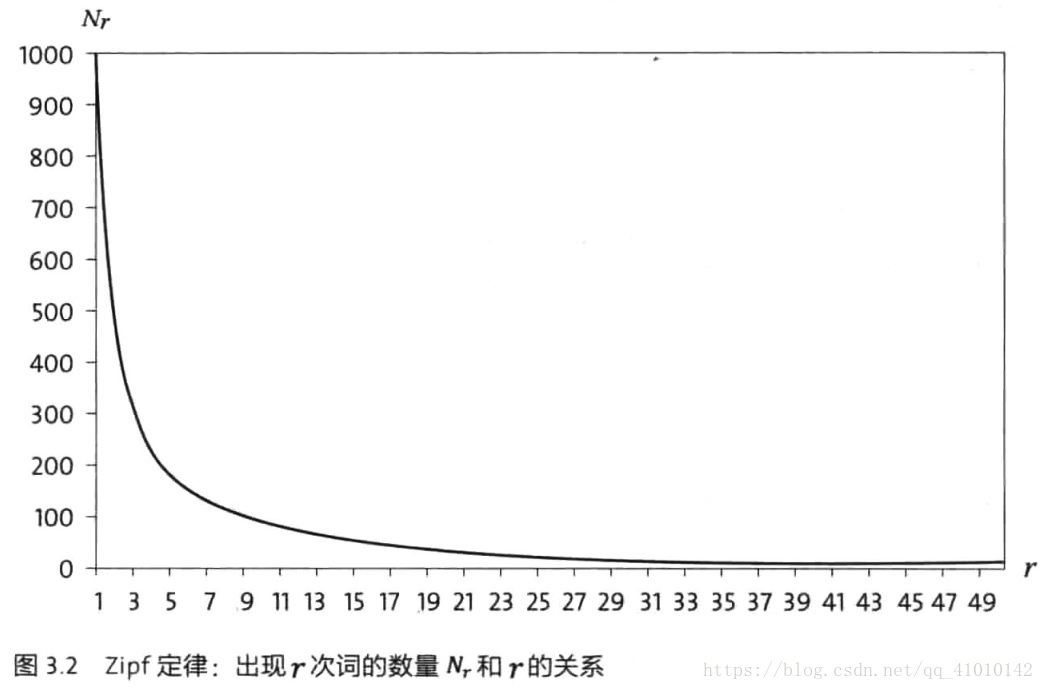
这里就解决了未出现的词,给其赋了一个很小的非零值。
文章中还有二元组和三元组的模型概率公式。卡茨退避法(Katz backoff)
还有一个叫删除差值的方法:用低阶语言模型和高阶模型进行线性插值来达到平滑的目的。
公式如下:三个λ均为正数且加和为1。
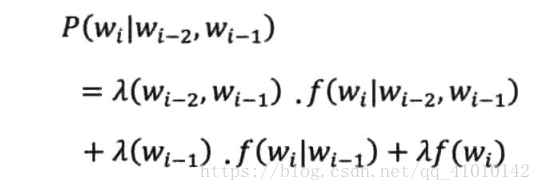
2.3 语料的选取问题
训练数据通常越多越好,数据的预处理很重要。
训练语料和模型应用的领域要切合,这样模型的效果才能体现。

