
- 1当「软件研发」遇上 AI 大模型_模板生成代码大模型
- 2一键解决 go get golang.org/x 包失败_ubunt安装golang失败
- 3git stash save和stash pop操作
- 4ASP.NET Core Web解决跨域问题_asp跨域
- 5YOLOv8独家改进:KAN系列 | 「一夜干掉MLP」的KAN ,全新神经网络架构一夜爆火
- 6【华为OD机考 统一考试机试C卷】 转盘寿司(C++题解)
- 7访问网站显示不安全怎么办?教您不花一分钱解决!_怎么解除网站连接不安全
- 8linux安装kafka3.5.2、kafka可视化管理工具kafka-ui-lite_linux kafka
- 9无需MAC,也能打开Sketch文件:多平台兼容软件介绍
- 10java 力扣 5. 最长回文子串_java 力扣 最长回文子串
jenkins与svn与shell_jenkins sshpass
赞
踩
1、subversion update has been canceled
公司SVN账号密码和AD账号密码是绑定在一起的,为了保证代码检出总是最新,jenkins中做代码检查前总会从SVN中检出最新代码。最近公司要求AD账户不得使用原始密码,更改密码后,jenkins在检出代码的时候出现了一个坑爹的问题:控制台打印的问题是subversion update has been canceled。
subversion update has been canceled——SVN代码无法正常更新,这很明显是SVN密码更改后的副作用。
最后解决:我在后台管理系统修改了密码之后,出现了之前的密码和后面的密码不一致,导致出现此问题;在查找寻多解决办法后,仍然不能解决;我回忆起了原先的密码,改回去了…全剧终
2、 Authentication realm:'<https://210…
默认用户权限问题,我在svn相关命令操作中,加入了指定用户密码
Revision=$(svn info ${Url} --username XXX --password XXX --no-auth-cache |grep Revision: |awk ‘{print $2}’)
3、sshpass的使用方法
应用范围:可以在命令行直接使用密码来进行远程连接和远程拉取文件
1、使用前提:对于未连接过的主机。而又不输入yes进行确认,需要进行sshd服务的优化:
# vim /etc/ssh/ssh_config
StrictHostKeyChecking no
# vim /etc/ssh/sshd_config
GSSAPIAuthentication no
UseDNS no
# systemctl restart sshd(需要输入此命令重启文件修改才生效)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2、sshpass 命令的安装:
# yum -y install sshpass
- 1
实例1:直接远程连接某台主机:
命令:sshpass -p xxx ssh root@192.168.11.11
sshpass -p xxx ssh root@192.168.11.11 ‘w’ -o StrictHostChecking=no 免输入yes。
实例2:远程连接指定ssh的端口:
命令:sshpass -p 123456 ssh -p 1000 root@192.168.11.11 (当远程主机不是默认的22端口时候)
实例3:从密码文件读取文件内容作为密码去远程连接主机
命令:sshpass -f xxx.txt ssh root@192.168.11.11
实例4:从远程主机上拉取文件到本地
命令: sshpass -p ‘123456’ scp root@host_ip:/home/test/t ./tmp/
实例5:sshpass不可以直接接带特殊字符意义的密码,需要转义或者用小括号,或者指定文件的方式来连接都可以规避这个问题。
4、shell中 -eq,-ne,-gt,-lt,-ge,-le数字比较符
-eq //equals等于
-ne //no equals不等于
-gt //greater than 大于
-lt //less than小于
-ge //greater equals大于等于
-le //less equals小于等于
- 1
- 2
- 3
- 4
- 5
- 6
5、Shell 数组
1、获取数组元素的个数: array=('bill','chen','bai','hu'); num=${#array[@]} //获取数组元素的个数。 遍历数组就变成非常简单的事情: for ((i=0;i<num;i++)) { echo $array[i]; } 获取数组某一个单元的长度就变成了: ${#array[i]} 2、获取数组的所有元素: ${array[*]} 遍历数组就编程了非常简单的事情: for var in ${array[*]} do echo $var; done 获取数组某一个单元的长度就变成了: ${#var} 3、获取字符串的长度: str="hello" len=${#str}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
6、shell 脚本for循环
array=("beijing" "tianjin" "hebei")
#echo ${array[0]}
for((i=0;i<${#array[@]};i++));
do
echo ${array[$i]}
done
- 1
- 2
- 3
- 4
- 5
- 6
7、通过shell脚本执行远程命令
登入到远程服务器并执行两个remotssh之间的命令,remotssh相当于一个标识,可以换成其它( <<eeooff也可以)
sshpass -p serverpassword ssh ubuntu@123.8.132.241 << remotssh
#执行的sehll命令
exit
remotssh
- 1
- 2
- 3
- 4
7、Shell函数详解(函数定义、函数调用)
Shell 函数定义的语法格式如下:
function name() {
statements
[return value]
}
- 1
- 2
- 3
- 4
对各个部分的说明:
function是 Shell 中的关键字,专门用来定义函数;
name是函数名;
statements是函数要执行的代码,也就是一组语句;
return value表示函数的返回值,其中 return 是 Shell 关键字,专门用在函数中返回一个值;这一部分可以写也可以不写。
由{ }包围的部分称为函数体,调用一个函数,实际上就是执行函数体中的代码。
调用 Shell 函数时可以给它传递参数,也可以不传递。如果不传递参数,直接给出函数名字即可:
name
- 1
如果传递参数,那么多个参数之间以空格分隔:
name param1 param2 param3
- 1
不管是哪种形式,函数名字后面都不需要带括号。
和其它编程语言不同的是,Shell 函数在定义时不能指明参数,但是在调用时却可以传递参数,并且给它传递什么参数它就接收什么参数。
Shell 也不限制定义和调用的顺序,你可以将定义放在调用的前面,也可以反过来,将定义放在调用的后面。
实例演示
- 定义一个函数,输出 Shell 教程的地址:
#!/bin/bash
#函数定义
function url(){
echo "http://c.biancheng.net/shell/"
}
#函数调用
url
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 定义一个函数,计算所有参数的和:
#!/bin/bash
function getsum(){
local sum=0
for n in $@
do
((sum+=n))
done
return $sum
}
getsum 10 20 55 15 #调用函数并传递参数
echo $?
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
运行结果:
100
@
表示函数的所有参数,
@表示函数的所有参数,
@表示函数的所有参数,?表示函数的退出状态(返回值)
这里是比较全的以上shell
https://blog.csdn.net/weixin_42280882/article/details/107453222
8、Pseudo-terminal will not be allocated because stdin is not a terminal.
加上-tt运行结果: ssh -tt hadoop@’xxxx’
每个终端都打印出执行的命令
9、shell 将文件内容读取到 数组中
#!/bin/bash prod_file=/home/vmuser/linbo/kettleDemo/job/test/CA-20201224.csv test_file=/home/vmuser/linbo/kettleDemo/job/test/uat_CA-20201224.csv dtm=`date +"%Y%m%d%H%M%S"` echo $dtm rowCnt=`cat $test_file | wc -l ` echo $rowCnt echo "---------------------------------------------------" # 设置IFS,将分隔符设置为换行符 OLDIFS=$IFS IFS=$'\n' # 读取文件中的内容到数组中 array=($(cat $test_file)) # 恢复之前的设置 IFS=$OLDIFS echo ${#array[*]} # 循环显示文件内容 for v in {1..10} do echo " $v ==== ${array[v]} " done
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
10、利用shell脚本批量提取txt文件中任意字段
对于测试中出现的log,我们经常需要提取其中的关键信息进行分析,之前我通常使用python的工具来处理一些字符串,但是效率不是很高。现在通过shell脚本的方法会极大的增加效率,一句话就可以在任意的txt文本中提取到我们想要的字段,下面我们来看一下这个神奇的工具。
假如我们要从下面这段txt格式的log中提取‘sequence’后面的数据以及‘alpha’后面的数据,我们仅通过一句怎么来实现这个功能呢?
02-11 10:30:56.062 1512 1512 D OplusLayer: setAlpha sequence=6092, alpha=1.000000, name=Surface(name=5213b6f InputMethod)/@0x45bb15a - animation-leash of insets_animation#0
02-11 10:30:56.062 1512 1512 D OplusLayer: setAlpha sequence=6145, alpha=4.000000, name=Surface(name=5213b6f InputMethod)/@0x45bb15a - animation-leash of insets_animation#0
02-11 10:30:56.062 4132 4363 D OplusFastRecovery: network netid not match!! null,103
02-11 10:30:56.063 1512 1512 D OplusMovieIdle: updateLayerStacks,mOmiSupport is not supoort
- 1
- 2
- 3
- 4
- 5
我们只需要以下命令就可以得到我们想要的数据:
cat old.log | grep "setAlpha" | awk -F: '{ print $4}' | awk -F, '{ print $1"="$2 }' | awk -F= '{ print $2 "," $4 }'> new.log
- 1
- 2
解析这条指令是怎么实现的
- cat命令
cat old.log
- 1
cat命令是常用的shell命令,此处的作用就是打开文件名为“old.log”的文件,并准备进行编辑。这个文件也可以是‘.txt’格式结尾的。
-
'|'符号与‘>’符号
shell命令中,‘|’符号表示的是管道。假设输入了如下指令:command0 | command1,则command0的输出流入到command1中。在我们的指令中,‘|’负责把上一句执行的输出当作输入流入到下一句。
‘>’符号在本文指令中的作用是重定向到文本, cat指令将文本打开,然后通过’|‘符号流入到后续的语句进行处理,处理完之后通过’>'将处理之后的结果存放在指定文本中。 -
grep命令
grep指令常用于搜索文本文件中是否含有某些特定模式的字符串。该命令以行为单位读取文本并使用正则表达式进行匹配,匹配成功后打印出该行文本。
grep命令记住两点,**第一,它用来匹配文本中的字符串,第二,以行为单位读取,**也就是说,如果文本中国一行含有目标字符串,grep就将整行打印出来。我们指令中的grep用法为:
grep "setAlpha"
- 1
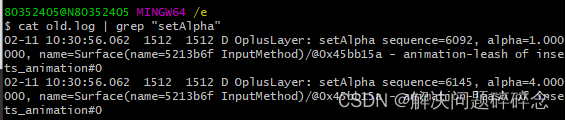
这句命令将含有“setAlpha”字符串的语句成行地打印了出来,对于log中比较多地数据,我们可以将结果保存在新的文件中:
cat old.log | grep “setAlpha” > new.log
- awk命令
AWK 是一种处理文本文件的语言,处理文本非常方便,熟悉python的同学可以把它当作python中的split()函数,它的作用就是根据指定字符来对文本进行分割并生成列表。
cat old.log | grep "setAlpha" | awk -F: '{ print $4}'
- 1
awk语句根据前面生成的文本,以‘-F’后面的符号,即‘:’(冒号)为分界点进行分割,然后将分割后的第四个元素打印出来(即‘print $4’),运行结果为
 这样我们可以初步提取到包含我们想要信息的数据,后面可以根据该输出进一步处理文本:
这样我们可以初步提取到包含我们想要信息的数据,后面可以根据该输出进一步处理文本:
cat old.log | grep "setAlpha" | awk -F: '{ print $4}' | awk -F, '{ print $1"="$2 }'
- 1
上面语句的含义就是将文本以‘,’(逗号)为分界点就行分割,并且打印第1个和第2个元素,两个元素中间用‘=’符号连接。运行结果为:

cat old.log | grep "setAlpha" | awk -F: '{ print $4}' | awk -F, '{ print $1"="$2 }' | awk -F= '{ print $2 "," $4 }'
- 1
根据上一步的结果以‘=’为分界点进行分割,然后打印第2个与第4个元素,两个元素之间用“,”连接,运行结果为:

对于数据量比较大的文本,我们可以将最终的结果存储到一个文件中:
cat old.log | grep “setAlpha” | awk -F: ‘{ print $4}’ | awk -F, ‘{ print $1"="$2 }’ | awk -F= ‘{ print $2 “,” $4 }’ > new.log
awk默认的分隔符为空格和tab。然而,实践中往往需要指定其它符号作为分隔符。
- 1
假设有一个test.txt文本文件,其内容如下所示,共4行,每行由逗号分隔成三个元素。现在,通过后续的几种方式对它进行分列操作。
cat test.txt
sample1,male,12
sample2,female,23
sample3,male,15
sample4,female,28
- 1
- 2
- 3
- 4
- 第一种方式:通过-F参数实现
通过 -F 参数指定分隔符。需要注意的是,分隔符紧跟在-F参数后面(中间没有空格)。
awk -F, '{print $2}' test.txt
male
female
male
female
- 1
- 2
- 3
- 4
- 5
- 6
- 第二种方式:通过指定内置变量 FS 来实现
通过-v参数,设置内置变量FS的值为,,从而达到将分隔符指定为逗号。
awk -v FS="," '{print $2}' test.txt
male
female
male
female
- 1
- 2
- 3
- 4
- 5
- 6
输出分隔符
如果拆分的2列或2列以上需要输出,默认也是以空格进行分隔的。例如:
awk -v FS=',' '{print $1,$3}' test.txt
- 1
sample1 12
sample2 23
sample3 15
sample4 28
- 1
- 2
- 3
- 4
那么,当需要在输出文件中,需要指定其它分隔符时,可以通过-v 参数指定内置变量OFS实现。例如:
awk -v FS="," -v OFS="@@" '{print $1,$3}' test.txt
- 1
sample1@@12
sample2@@23
sample3@@15
sample4@@28
- 1
- 2
- 3
- 4
11、调用shell jenkins不能自动结束
在linux环境中启动一个程序想放入后台正常做法是使用nohup加&符号。
但是这样的命令放到shell脚本里,然后通过jenkins去发布的话会把输出日志打印到jenkins的output里,导致任务不能结束。
这时需要重新在命令后面加上重定向如:nohup java -jar test.jar >start.log 2>&1 &。
使用中遇到的坑
除了上面一种情况,还有下面的情况
明明设置的没什么问题了,但是还是出现jenkins任务不会自动结束。
通过一步步排查,最后发现问题是在启动前,做了个cd的操作:先是cd到文件目录下,然后使用相对路径进行后台启动,然后就…
改为绝对路径,去掉cd的操作一切ok!
调用shell脚本,在脚本里进行判断程序启动是否正常。防止不管是否正常jenkins都提示成功的方法是:
脚本里成功的情况下使用正常退出exit 0,异常情况下使用exit 1退出。jenkins在获取到非0的情况下会提示任务失败
12、Jenkins调用shell脚本提示command not found
sh tfb-app-service.sh restart] ...
SSH: EXEC: connected
tfb-app-service.sh: line 35: route: command not found
tfb-app-service.sh: line 36: ifconfig: command not found
- 1
- 2
- 3
- 4
按照提示说明,找不到route命令和ifconfig命令,通过whereis命令找到这两个命令都在/usr/sbin下面,那么就是在执行shell脚本的时候,没有引用到/usr/sbin这个路径。
[nexus@localhost .jenkins]$ whereis route
route: /usr/sbin/route /usr/share/man/man8/route.8.gz
[nexus@localhost .jenkins]$ whereis ifconfig
ifconfig: /usr/sbin/ifconfig /usr/share/man/man8/ifconfig.8.gz
- 1
- 2
- 3
- 4
在tfb-app-service.sh脚本里,route和ifconfig写全路径:
/usr/sbin/route和/usr/sbin/ifconfig
也就是
#获取当前服务器IP地址,拼接服务名
agent_name(){
iface="$( /usr/sbin/route -n | grep ^0.0.0.0 | awk '{print $8}')"
ip="$(/usr/sbin/ifconfig $iface | grep "inet 172" | awk '{ print $2}')"
if [ -z $ip ]; then
ip="xxx.xxx.xxx.192"
echo ${JAR_NAME/%-6.0.1-SNAPSHOT.jar/}-${ip##*.}
else
echo ${JAR_NAME/%-6.0.1-SNAPSHOT.jar/}-${ip##*.}
fi
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
13、jenkins有些操作被禁止,报“Operation not permitted“错误
vim /etc/sysconfig/jenkins
#JENKINS_USER=“root”
JENKINS_GROUP=“root”
#重启jenkins
systemctl restart jenkins
14、ssh 服务器报错 packet_write_wait: Connection to xxx port 22: Broken pipe
使用 ssh root@xxx.xx.xx.xxx 命令登录服务器,一段时间不用服务器,再进入终端会无响应,报错
1、在客户端打开 ~/.ssh/config 文件(下面的设置对所有的远程服务器都生效
Host *
# 客户端每隔 30 秒给服务器发送一次请求信号
ServerAliveInterval 30
2、其实也可以在特定服务器上配置,代码如下:
sudo vim /etc/ssh/sshd_config
3、最后记得刷新一下
重启sshd服务(切记重启!!!):systemctl restart sshd

