- 1openmv串口打包发送数据_openmv数据打包串口发送
- 2zookeeper的伪集群的搭建
- 3Intel 英特尔
- 4分治法求点对问题_友谊点对
- 5Android解锁与root_android 获取root权限
- 6大学搜题什么软件有解析?分享六个支持答案和解析的工具 #职场发展#学习方法
- 7ubuntu系统下hbase数据库的安装和使用,hbase配置文件详解_搭建带配置文件的hbase和连接 user.keytab
- 8基于微信小程序的高校新生报到系统(源码+文档+包运行)_基于微信小程序的新生报到系统_基于微信小程序新生报到系统e-r图
- 9【基础】【Python网络爬虫】【10.验证码处理】OCR识别,Tesseract ,ddddocn识别,打码平台,滑块验证码(附大量案例代码)(建议收藏)_验证码识别 ocr python
- 10基于YOLOv8的交通摄像头下车辆检测算法(五):Gold-YOLO,信息聚集-分发(Gather-and-Distribute Mechanism)机制 | 华为诺亚NeurIPS23_数据车辆
基于FPGA的数字图像处理【2.1】_图像行列计数fpga
赞
踩
3.8 应用实例
本节将列举在本书的实例代码中应用比较多的实例(基于Verilog语言)。
3.8.1 信号边沿检测
1.如何得到一个信号的上升沿
一般情况下,可以很容易地得到一个时钟的上升沿。然而在同步
设计中,我们是以时钟的上升沿作为参考,这个时候如何得到另外一个信号的上升沿?新手常常会为此烦恼,因为同时检测两个信号上升沿的代码往往是不可综合的。考虑下面的代码:
- input vsync;
- reg vsync_r;
- reg vsync_r2;
- wire vsync_r2_n;
- wire vsync_rise;
- always @(posedge clk)
- begin
- vsync _r <= vsync
- vsync_r2 <= vsync _r;
- end
- assign vsync_r2_n = ~vsync_r2;
- assign vsync_rise = vsync_r2_n & vsync _r;
以下的时序图(见图3-3)展示了如何得到一个信号的上升沿。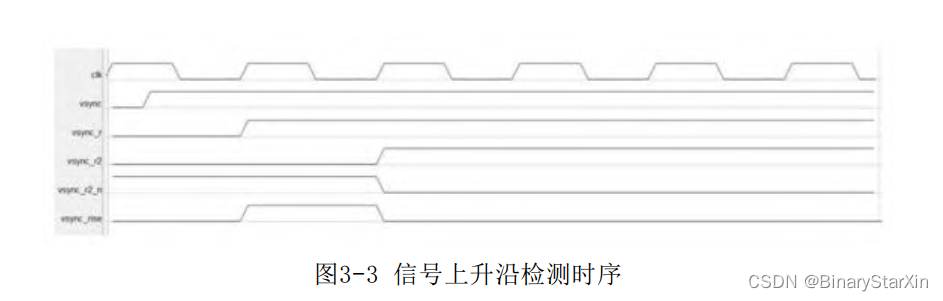
首 先 , 对 待 检 测 信 号 进 行 本 地 同 步 后 , 得 到 本 地 同 步 信 号vsync_r。其次,将同步信号打一拍得到vsync_r2,对第二拍信号取反得到vsync_r2_n。最后与vsync_r进行“与”运算即可得到vsync的上升沿脉冲。
2.如何得到一个信号的下降沿
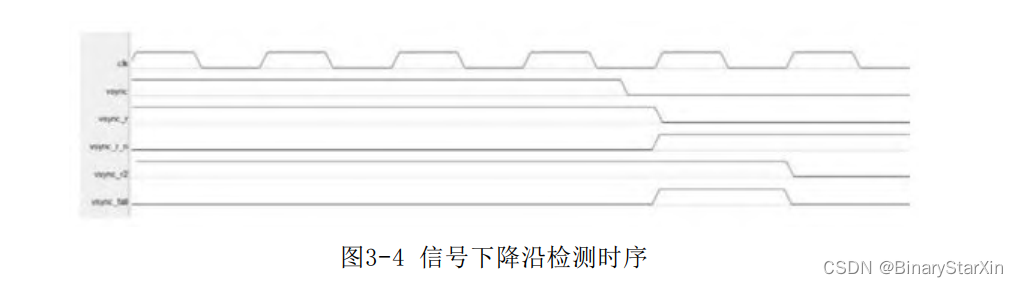
用同样的方法,可得到一个信号的下降沿,如图3-4所示。
3.8.2 多拍处理
1.信号多拍处理
一个信号的多拍信号也就是将信号连续打多拍,这个操作在时序对齐和防止亚稳态的应用中十分常见。将信号打多拍是比较简单的事情,利用移位寄存器即可实现。
考虑下面的代码:
- parameter VSYNC_WIDTH = 9;reg vsync_async;
- reg vsync_async_r1;
- reg [VSYNC_WIDTH:0]vsync_async_r;
- input vsync;
- always @(posedge clk)
- begin
- vsync_async <= ~vsync
- vsync_async_r1 <= vsync_async
- vsync_async_r <=
- {vsync_async_r[8:0],vsync_async_r1};
- end
vsync_async 对 输 入 场 同 步 信 号 取 反 后 进 行 一 个 本 地 同 步 ,vsync_async_r1将本地同步信号打了一拍,vsync_async_r得到此同步信号的连续9拍。仿真时序图如图3-5所示。

得到信号的多拍之后可以在不同的节拍进行不同的算法处理,这适用于某个需要n拍才能完成的算法。应用如下所示:
- always @(posedge clk)
- begin
- if(vsync_async_r[0]== 1'b1)begin
- //第一拍处理
- end
- if(vsync_async_r[1]== 1'b1)
- begin
- //第二拍处理
- end
- …//其他节拍处理
- end
2.数据多拍处理
数据多拍处理在图像处理中也十分常见,这主要用在算法的两个计算模块开销不一致的情况:如果一个模块计算速度较快,但是又需要等待另一个模块的计算结果,就需要首先把当前的计算结果进行缓存几拍。一般情况下这个拍数比较少。否则,就会占用比较多的硬件资源。
数据多拍也可以用类似的移位寄存方法来实现,对于拍数比较多的处理,占用逻辑资源比较多,需使用FPGA片内的移位寄存器来实现。
- parameter DW_INFO = 3;
- parameter LATENCY = 8;
- integer n ;
- input [DW_INFO-1:0]din_info;
- reg [DW_INFO-1:0]din_info_r[LATENCY -1:0];
- always @(posedge clk)
- begin
- din_info_r[0] <= din_info;
- for( n = 1; n < LATENCY; n = n+1 )din_info_r[n]<= din_info_r[n-1];
- end
3.8.3 图像行列计数
图像行列计数在图像处理中非常常见。大部分算法都需要做到精准的像素定位,行列计数法是像素定位的基本方法。另一个方法是像素计数,通常不会这样做,因为它将会给调试工作带来不便(庞大的像素计数当然没有较小的行列计数来得直观些)。
行列计数的最简单的方法是通过输入场行同步信号和像素有效信号进行计数(关于场行同步的概念读者可以参考仿真测试相关章节)。设计原则如下:
(1)每一场信号到来时清空行列计数。
(2)每一个行同步信号到来时行计数加1,同时清空列计数。
(3)像素有效信号有效时列计数加1。
有的时候,视频流并没有伴随行同步信息,这个时候需要通过像素有效信号进行行列计数。
图像行列计数的一个实例如下
- parameter IW = 640;
- parameter IH = 512;
- parameter DW = 8;
- parameter IW_DW = 12; //列计数寄存器宽度
- parameter IH_DW = 12; //行计数寄存器宽度
- input clk;
- input rst_n;
- input vsync;
- input hsync;input dvalid;
- input [DW-1:0]din;
- reg [IH_DW-1:0]line_counter; //行计数
- reg [IW_DW-1:0]column_counter; //列计数
- reg rst_all;
- //frame reset signal
- always @(posedge clk or negedge rst_n)
- if ((~rst_n) == 1'b1)
- rst_all <= #1 1'b1;
- else
- begin
- if (vsync == 1'b1)
- rst_all <= #1 1'b1;
- else
- rst_all <= #1 1'b0;
- end
- wire dvalid_rise; //像素有效数据到来信号
- reg dvalid_r;
- always @(posedge clk or negedge rst_n)
- if ((~rst_n) == 1'b1)
- dvalid_r <= #1 1'b0;
- else
- dvalid_r <= #1 dvalid ;
- assign dvalid_rsie=(~dvalid_r)&dvalid;//像素有效数据到
- 来信号(也表示新的一行数据到来)
- wire hsync_rise; //行同步到来信号
- reg hsync_r;always @(posedge clk or negedge rst_n)
- if ((~ rst_n) == 1'b1)
- hsync_r <= #1 1'b0;
- else
- hsync_r <= #1 hsync;
- assign hsync_rise = (~hsync_r) & hsync; //行同步到来信号
- //用像素有效信号进行行计数
- always @(posedge clk)
- begin
- if (rst_all == 1'b1) //场同步清零行计数
- line_counter <= {IH_DW{1'b0}};
- else
- if(dvalid_rsie == 1'b1)
- line_counter <= line_counter +{ {IH_DW-
- 1{1'b0}},1'b1};
- end
- //用像素有效信号进行列计数
- always @(posedge clk)
- begin
- if (rst_all == 1'b1) //场同步清零行计数
- column_counter <= {IW_DW{1'b0}};
- else
- begin
- if(dvalid_rsie == 1'b1)
- column_counter <= {IW_DW{1'b0}};
- else
- beginif(dvalid == 1'b1)
- column_counter <= column_counter+{
- {IW_DW-1{1'b0}},1'b1};
- end
- end
- end

图像行列计数电路仿真结果如图3-6所示。用dvalid的上升沿得到的行计数从1开始,若采用其下降沿进行行计数,则会得到以0开始的行计数信息。
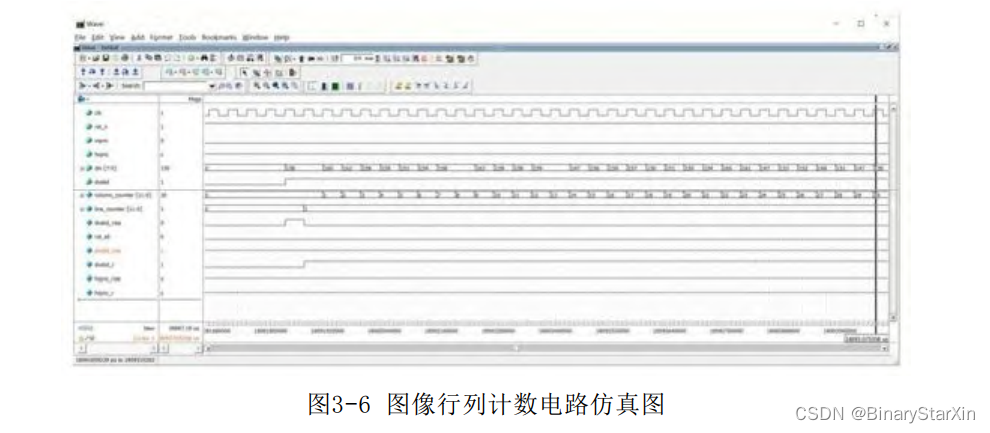
图3-6中列计数延迟输入数据一个节拍,后续的电路中需要对这个节拍进行对齐。行列计数对于一个FPGA的图像处理系统来讲非常重要,由于每一个像素时钟都对后面的时序控制产生影响,行列计数不能有任何偏差(特别是对于列计数来讲)。因此,在时序对齐的时候,需要读者仔细对其进行核对,否则将会带来灾难性的后果。图3-7是一个每行的列计数少1的图像捕获结果。

如果最后的测试结果出现如图3.7所示的情况,那么行列计数电路很有可能出现了问题。实际上,在Verilog代码设计中,有相当一部分的工作都花在时序对齐上。可见,FPGA设计是一个非常细致和严谨的工作,需要开发者有足够的耐心。
第4章 映射技术
将图像处理的算法转换为FPGA系统设计的过程称为算法映射。本章将详细介绍将软件图像处理算法转换为FPGA的映射技术。
4.1 系统结构
映射过程的首要目标便是确定系统设计的结构,在本书中,主要介绍在图像处理中常用的两种系统设计结构:流水线结构和并行阵列结构。
4.1.1 流水线设计
1.基本概念
流水线处理源自现代工业生产装配线上的流水作业,是指将待处理的任务分解为相对独立的、可以顺序执行的而又相互关联的一个个子任务。流水线处理是高速设计中的一个常用设计手段,如果某个设计的处理流程分为若干步骤,并且整个数据处理是“单流向”的,即没有反馈或者迭代运算,前一个步骤的输出是下一个步骤的输入,那么可以考虑采用流水线设计方法来提高系统频率。流水线设计结构如图4-1所示。
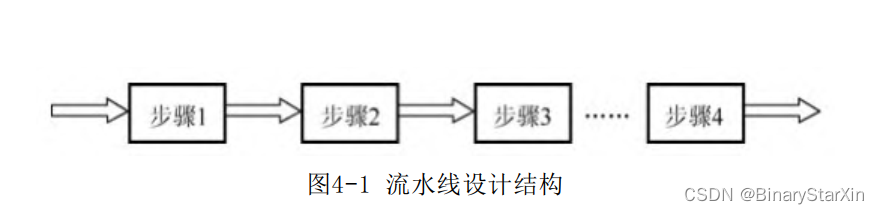
其基本结构是将适当划分的n个操作步骤单流向串联起来。流水线操作的最大特点是数据流在各个步骤的处理从时间上看是连续的,如果将每个操作步骤简化为通过一个D 触发器,那么流水线操作就类似一个移位寄存器组,数据流依次经过D触发器,完成每个步骤的处理。流水线设计时序示意如图4-2所示。
图4-2中总共需要4个设计流水单元电路,从时刻t4 开始,所有的流水线单元开始进入工作状态。将一幅图像的每个像素依次流过流水线即可得到以整幅图像的输出。
2.采用流水线带来的好处
流水线处理采用面积换取速度的思想,可以大大提高电路的工作频率,尤其对于图像处理任务中的二维卷积运算、FIR及FFT滤波器等,采用流水线设计可以保证一个时钟输出一个像素,相对于全并行处理电路占用资源又不会太多。对于大部分的图像处理任务而言,处理过程基本上也是一个“串行”的处理思路。因此,流水线设计无疑是最好的设计方式。图4-3是一个典型的图像处理任务的流程图。

本处理任务也是一个典型的图像处理任务。首先,我们从CCD或CMOS传感器得到需要处理的视频流输入Video Input,并通过视频捕获模块Video Capture将输入视频同步为本地视频流。这些视频流“无等待”地流入下一个处理单元Chroma Resample进行色度重采样和空间变换,经过预处理Pre Filter和指定的处理算法Image Process后(例如预滤波、分割、目标识别、Alpha混合等),转换为视频流输出VideoOutput。
在这个过程中,输入视频流和输出视频流是连续的,流水线结构也保留了这种可能性。每一个处理单元独立为一块单独的电路,也降低了设计的复杂度。
3.流水线时序匹配
流水线设计的关键在于整个设计时序的合理安排、前后级接口之间数据流速的匹配,这就要求每个操作步骤的划分必须合理,要统筹各个步骤间的数据量。如果前级操作的时间恰好等于后级的操作时间,那么设计最为简单,前级的输出直接接入后级的输入即可;如果前级的操作时间小于后级的操作时间,那么需要对前级的输出数据适当缓存,才能汇入后级,还必须注意数据速率的匹配,防止后级数据的溢出;如果前级的操作时间大于后级的操作时间,那么必须通过逻辑复制及串并转换等手段将数据分流,或者在前级对数据采用存储及后处理等方式。否则,就会造成与后级的处理节拍不匹配。考虑以下的流水线处理模型:
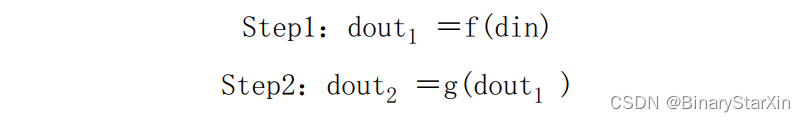
如果处理单元f与g操作时间相同(例如,每个时钟输出一个数据,并且数据带宽等同),那就可以直接将前级流水线的输出接入后级的输入。这个模型在图像处理中十分常见,特别是在流水线运算处理的图像尺寸和带宽都是一致的场合。
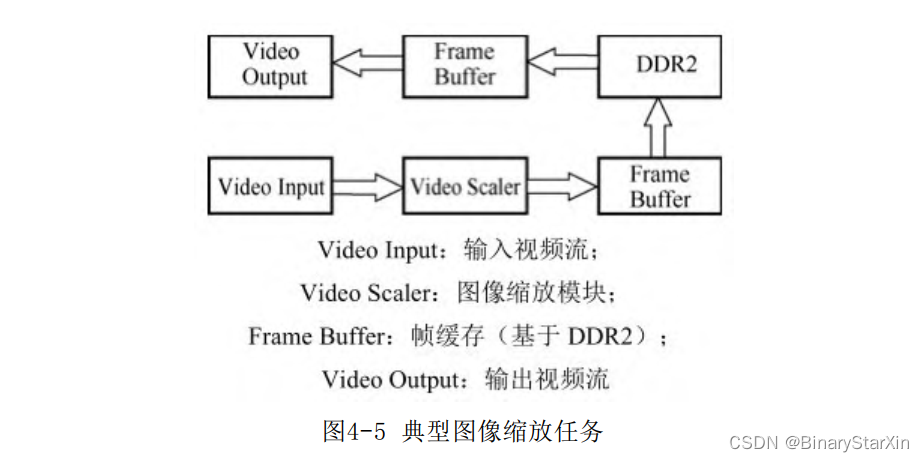
但是,我们往往会遇到复杂一点的流水线。一个典型的处理情况是两级流水线的带宽不同。例如,如图4-4所示的图像缩放任务VideoScaler:
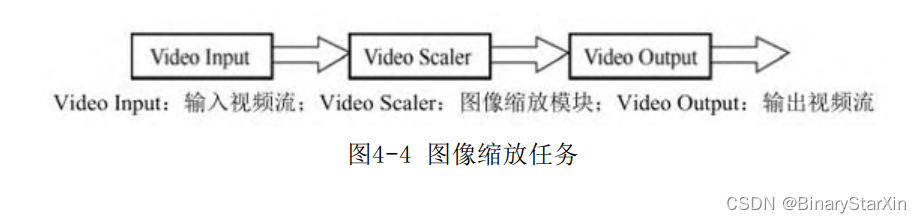
这个任务需要完成视频的缩放功能。图像缩放前后的带宽可能差别非常大(如果宽高缩放2倍,带宽可能会变化4倍之多),这个时候直接将流水线相接,带来的直接问题就是流水线阻塞或停滞,输出屏幕闪烁或是无信号。因此,在这种情况下,必须对流水线的数据流进行缓存。图4-5是一个典型的解决方案。
Frame Buffer是帖缓存模块。通过DDR2作为视频缓存来解决带宽匹配问题,这也是目前的主流解决方案之一。