
- 1目前我国网络安全人才市场状况_23年网络空间安全就业现状
- 2Tomcat 第二篇:启动流程_this file is needed to run this program
- 3Windows下如何方便的运行py脚本_windows server运行.py文件
- 4Egret置于后台时,暂停游戏逻辑 (Egret 5 )
- 5aws iam_AWS IAM入门
- 6路由表字段_路由表有哪些关键字段分别代表什么
- 7爬虫——手机抓包,fiddler抓取手机qq请求_iphone抓取手机qq页面
- 8Docker教程-Windows版_windows docker -v
- 9使用yolo进行饮料分类所涉问题及其解决方法简析_yolo没生成.cache
- 10「从零入门推荐系统」21:chatGPT、大模型介绍
pandas数据读取处理详解_pandas 读取txt
赞
踩
文章目录
使用环境:python3.7+win10+pandas:0.23.4,不同版本可能存在些许差异。
安装pandas包:win+r,输入cmd,在终端输入pip3 install pandas
'''导入模块取别名为:pd,下面的df指的是DataFrame'''
import pandas as pd
'''案例中可能会设计到这个模块,如果出现np,代表的是numpy模块。'''
import numpy as np
- 1
- 2
- 3
- 4
- 5
数据读取
read_table:读取txt文本文件
也可以用于读取csv文件,两者都是文本文件,一定程度上等同于read_csv(很多参数共用)
新版本pandas的可能不再支持read_table方法,使用read_csv即可;
df= pd.read_table('tt.txt',sep = ',',comment='#',encoding = 'gbk',skiprows=2,skipfooter=3,thousands='&',parse_dates={'birthday':[0,1,2]})
- 1
常用参数:
- sep:分隔符,默认为tab
- header:是否需要将原数据集中的第一行作为表头,默认将第一行用作字典名。
- names:如果原数据集中没有字段,可以通过该参数在数据读取时给数据框添加具体的表头。
- index_col:指定原数据集中的某些列作为数据框的行索引。
- usecols:指定需要读取原数据集中的哪些变量名,以列表传入。
- dtype:读取数据时,可以为原数据的每个字典设置不同的数据类型。可以以字典表达。{‘a’: np.float64, ‘b’: np.int32}
- converters:通过字典格式,为数据集中的某些字段设置转化函数。{0:str}第一列转化为字符串
- skiprows:跳过开头行数
- skipfooter:跳过原始数据末尾行数。
- nrows:指定读取数据的行数;
- na_values:指定原数据集中哪些特征的值作为缺失值。
- skip_blank_lines:读取数据时是否需要跳过原数据集中的空白行,默认为True;
- parse_dates:如果参数为True,则尝试解析数据框的行索引;如果参数为列表,则尝试解析对应的日期列;如果参数为嵌套列表,则将某些列合并为日期列;如果参数为字典,则解析对应的列(字典中的值),并生成新的字段名(字典中的键);
- thousands:指定原始数据中的千位符;
- comment:指定注释符,在读取数据时,如果碰到首行指定的注释符,则跳过该行。
- encoding:如果文件中有中文,有时需要指定字符编码;
- skipinitialspace : boolean, default False;忽略分隔符后的空白(默认为False,即不忽略)
- na_filter : boolean, default True;是否检查丢失值(空字符串或者是空值)。对于大文件来说数据集中没有空值,设定na_filter=False可以提升读取速度。
- nrows:限制读取多少行。
- error_bad_lines : boolean, default True;如果一行包含太多的列,那么默认不会返回DataFrame ,如果设置成false,那么会将改行剔除(只能在C解析器下使用)。
- chunksize:指定文件块的大小,分块读取。
- iterator:为True时,返回可迭代对象。
reader = pd.read_table('tmp.sv', sep='\t', iterator=True)
#通过get_chunk(size),返回一个size行的块#接着同样可以对df处理
df=reader.get_chunk(10000)
- 1
- 2
- 3
逐块读取
场景应用:读取大块文件进行聚合操作,我们可以逐块读取聚合再合并:分而治之。
f = open(r'\train.csv','r')
reader = pd.read_csv(f, iterator=True, nrows=20000000)
loop = True
chunkSize = 100
chunks = []
while loop:
try:
chunk = reader.get_chunk(chunkSize)
chunks.append(chunk)
#停止迭代,数据读到尾部,结束循环。
except StopIteration:
loop = False
print("文件读取完毕.")
'''使用concat合并数据块,ignore_index=True表示忽略原始索引,重建索引。'''
df = pd.concat(chunks, ignore_index=True)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
read_excel:读取excel文件
add = pd.read_excel(f,usecols='f,g,u:ac',skiprows=1,skipfooter=1,encoding='utf_8',dtype={'日期':str})
- 1
常用参数
- sheetname:指定读取的第几个sheet,可以传递整数,也可以是具体的sheet表名字;
- header:第一行表头,默认需要。不需要header=None
- names:如果原始数据中没有字段,可以通过该参数在数据读取时给数据框添加具体的表头;
- skip_rows:跳过开头行
- skip_footer:跳过结尾行数
- useclos:指定读取那些列,比如usecols=‘f,g,u:ac’,也可以传入数值型列表,比如:[1,2,3,5],[‘student’,‘score’]
- encoding:编码格式
- index_col:指定列为行索引;比如指定第一列为索引,可以设置index_col=0,excel第一列没有列标题,默认是读成索引。
- parse_dates:同read_table;
- na_value:指定原始数据中哪些特殊值代表了缺失值;
- thousands:指定千位符
- convert_float:默认将所有的数值型字段转化为浮点型字段。
- converters:通过字典的形式,指定某些列需要转化的形式。
读取一个工作簿下多个sheet:ExcelFile类
读取一个工作簿下多个sheet,使用ExcelFile类,无须重复载入内存;
wb = pd.ExcelFile('path_to_file.xls')
sheet1 = wb.read_excel(wb,'sheetname1')
sheet2 = wb.read_excel(wb,'另外一个工作表名字')
# 也可以作为上下文管理器使用
with pd.ExcelFile('path_to_file.xls') as wb:
sheet1 = wb.read_excel(wb,'sheetname1',index_col=None,na_values=['NA'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
read_fwf:读取固定宽度文件
read_fwf(filepath_buffer,colspecs=‘infer’,widths=None,**kwargs)
#使用widths参数
widths = [5,5,7,5] #表示每一次取字符串的宽度,包括空格其他字符串长度在内。
df = pd.read_fwf(test_data,widths=widths,header=None,names=['col1','col2','col3','col4'])
#使用colspecs参数
colspecs = [(1, 7), (11, 21), (24, 34), (37, 44)] #字段严格的位置,中间的位置不需要。
df = pd.read_fwf(test_data, colspecs=colspecs, header=None, index_col=None)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
常用参数:
- widths:由整数组成的列表,选填,如果间隔是连续的,可以使用的字段宽度列表而不是‘colspecs’
- colspecs:一个元组列表,给出每行固定宽度字段的范围为半开区间(即[from,to [)),如[(1,3),(10,22),…]每个字段为半开区间即[int,int);字符串值’infer’可用于指示解析器尝试检测数据的前100行中的列规范,默认read_fwf尝试colspecs使用文件前100行来推断文件。只能在列对齐并且delimiter分隔符为空格(默认)情况下执行(default =‘infer’)。
其他很多参数同read_csv,详情可以输入help(pd.read_fwf)查看具体方法属性。
read_sql:读取mysql
需要安装pymysql模块,在终端执行‘pip3 install pymysql’即可。
import pymysql
import pandas as pd
# 创建数据库连接
# host:服务器地址,这里用的是本地mysql;user:用户名;password:mysql密码;database:数据库;port:端口号;charset:编码
connect = pymysql.connect(host='localhost',user = 'root',password='1234',database = 'yy',port = 3306,charset='utf8')
# 读取数据
user=pd.read_sql('select from aa',connect)
# 描述性统计
user.describe
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
read_pickle:读取二进制数据
读取二进制数据,速度快,很多时候我们可以将一些数据保存为二进制数据文件。
frame = pd.read_pickle('frame_pickle')
- 1
读取文件中编码格式问题
有些时候由于编码问题,我们无法正常读取文件,这时候可以使用chardet模块识别文件内容编码,方法:chardet.detect
安装:同样的,cmd终端:pip3 install chardet
import chardet
#先以二进制可读打开文件
with open('test.txt','rb') as f:
chardet.detect(f.read())
#输出示例:这里提示编码GB2312,可信度99%,语言:中文;
#>>> {'encoding': 'GB2312', 'confidence': 0.99, 'language': 'Chinese'}
- 1
- 2
- 3
- 4
- 5
- 6
中文路径无法读取问题
版本问题,可能有些时候会出现带中文路径无法读取问题。
出错提示:OSError: Initializing from file failed
#路径中带中文,直接读取报错了。
df = pd.read_csv('d:/Desktop/身高信息.txt',sep=',')
#先open打开文件,再向read方法里边传参,文件正常读取
with open('d:/Desktop/身高信息.txt','r') as f:
#用read_csv方法读txt文件,两者基本就是后缀名,分隔符差异,读取导出方法基本共用。
df = pd.read_csv(f,sep=',')
- 1
- 2
- 3
- 4
- 5
- 6
文件路径使用问题
- 如果文件和数据源在同文件夹下,read第一个参数可以直接填写文件名字,如果不是填写数据完整路径,比如:r’d:\desktop\tt.txt’。
- 文件路径:python的‘\’具有转义作用,输入路径时,如果不想使用‘\’,请字符串前加上r字母,代表原生字符串。或者也可以直接使用‘/’反斜杠。
- 文件导出路径使用跟读取是一样的,python默认在当前文件工作目录下读写文件
关于读取大文件的方法
- 生成可迭代对象iterator=True,指定chunksize参数,逐块读取,处理后再拼接起来。
- 指定dtype数据类型(不同类型占用空间不同),pandas的read函数数值型默认读取是int64,如果确认数值比较小,可以使用int8;
df = pd.read_csv("xxxx.txt",sep=',',dtypes={'score':'int8[pyarrow]',name:'string[pyarrow]'})
- 1
字段当涉及到中文,使用pyarrow读取,能大量减少内存使用;
- 指定读取数据源的col(某些column可能我们不需要)
数据导出
to_sql:导出到mysql
这里需要使用到sqlalchemy,还是一样cmd终端输入‘pip3 install sqlalchemy’安装该模块就好。
import numpy as np import pandas as pd from sqlalchemy import create_engine df = pd.DataFrame(np.random.randint(3,20,(5,4)),columns=list('ABCD')) #connect = pymysql.connect(host='localhost',user = 'root',password='123456',database = 'yy',port = 3306,charset='utf8') #启动引擎,参数对照上面pymysql。 engine = create_engine('mysql://root:123456@localhost:3306/yy?charset=utf8') # if_exists='replace'时,如果原表存在,会删除原表,新建一张该名称表;append是尾部添加,默认是fail, {'fail', 'replace', 'append'}, # 此外还可以传入dtype参数,字典类型,key为字段名称,value为sql字段类型; df.to_sql(name='表名',con=engine,if_exists='replace',index=False,index_label=False) #read_sql也可以使用sqlalchemy模块。 df1 = pd.read_sql('select from 表名',engine) # read_sql_table方法:使用id为索引读取Col_1,Col_2两列数据 df = pd.read_sql_table('data', engine,index_clo='id',columns=['Col_1', 'Col_2'])

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
to_csv:导出为csv文件
该方法也可以直接导出txt文件,txt同csv文件都是文本文件,很多地方使用方法是共通的。
#需要注意的一点是,导出csv文件,需要指定编码为'uft_8_sig,不然中文可能会乱码。'
df.to_csv(aa.csv,na_rep='NULL',sep = ',',index=False,header = False,encoding = 'utf_8_sig')
- 1
- 2
一些参数:
- chunksize:int或者None,一次写入的行数。
- na_rep :空值填充;
- sep:分隔符
- index=False不保存索引。
- header=False不需要表头。
- columns:list指定要导出的列。
- encoding:编码格式
to_excel:导出为excel文件
#pandas读取或导出excel文件很慢,如果没有必要,尽量避免使用excel文件,如果只是便于excel以表格形式查看的话,也可以导出csv文件,office也可以打开。
df.to_excel('test.xlsx',encoding='utf_8',index=False)
- 1
- 2
to_pickle:导出数据为二进制格式
df.to_pickle("frame_pickle")
- 1
创建DataFrame和Series
#我们可以通过向pd.Series传入列表,元组或者ndarray等创建Series import pandas as pd import numpy as np #创建Series nd = np.array((1,3,4)) s = pd.Series(nd,index=['张三','李四','王五']) #或者我们也可以先不指定Series的索引index,直接对Series的index赋值。 s.index = ['张三','李四','王五'] #创建DataFrame #通过传入字典创建DataFrame df = pd.DataFrame({'姓名':['张三','李四','王五'],'成绩':[85,59,76]}) # 通过传入ndarray,再指定columns列索引创建 df = pd.DataFrame(np.array([['张三','85'],['李四','59'],['王五','76']]),columns=['姓名','成绩']) # 创建空DataFrame对象 df = pd.DataFrame(columns=['name','age'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
切片及记录抽取
抽取前面或最后若干条记录
#抽取前面5行数据,默认是前5条,也可以传入其他整数,比如前20条记录。
df.head()
df.head(20)
#抽取最后5,20条记录
df.tail()
df.tail(20)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
显示索引和隐式索引
import pandas as pd df = pd.DataFrame({'姓名':['张三','李四','王五'],'成绩':[85,59,76]}) #传入冒号‘:’,表示所有行或者列 #显示索引:loc,第一个参数为index切片,第二个为columns df.loc[2] #index为2的记录,这里是王五的成绩。 df.loc[:,'姓名'] #第一个参数为冒号,表示所有行,这里是筛选姓名这列记录。 #隐式索引:iloc(integer_location),只能传入整数。 df.iloc[:2,:] #张三和李四的成绩,跟列表切片一样,冒号左闭右开。 df.iloc[:,'成绩'] #输入中文,这里就报错了,只能使用整数。 # 也可以通过传入列表切片 df.iloc[[0,2],[1]] #也可以使用at定位到某个元素 # 新版本可能不再支持at语法,直接使用loc和iloc即可 df.at[index,columns] df.at[1,'成绩'] #使用索引标签,李四的成绩 df.iat[1,1] #类似于iloc使用隐式索引访问某个元素
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
| 操作 | 语法 | 返回结果 |
|---|---|---|
| 选择列 | df[col] | Series |
| 按标签选择行 | df.loc[label] | Series |
| 按整数位置选择行 | df.iloc[loc] | Series |
| 切片行 | df[5:10] | DataFrame |
| 按布尔向量选择行 | df[bool_vec] | DataFrame |
值修改
可以通过loc亦或iloc赋值修改,比如:df.iloc[2,4]=10在原DataFrame上修改
也可以筛选后修改,比如:df[df.age>20]=20该方式会将符合条件的所有元素修改为20,在原DataFrame上修改
其他修改诸如空白填充fillna,替换replace等;
列的增加与删除
ls = list('ABCD') df = pd.DataFrame(dict(col1=['A','B','C','D'],col2=[1,2,3,7])) df['col3'] = np.random.choice(ls,4) # 新增列col3:可重复随机从列表抽取四个元素 df['col4'] = df.col3[:3] # 新增列col4:只取三个元素,会按照索引对齐 '''插入列:0在第一列插入;col:插入字段名称;插入字段内容''' df.insert(0, "col", df["col4"]) print(df) '''使用DataFrame.assign(**kwargs)创建列''' # assign方法返回的是一个副本,不会对原数据修改 df1 = df.assign(col5=df['col2']/2,col6=df.col2 *10) # 还可以传入一个函数,该函数将在分配给的 DataFrame 上进行评计算 df2 = df.assign(col7=lambda x:x['col1'] + x['col']) '''删除列''' del df['col4'] # 删除col4属性 col1 = df.pop('col1') # 类同列表的pop方法,删除并返回删除内容
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19

数据记录抽取(筛选)
df[condition]
condition参数:过滤条件
返回值:DataFrame
常用condition:
比较运算
==,<,>,>=,<=,!= 如:df[df.column_name<100]
范围运算
between:数值筛选区间
'''筛选column_name属性0-1000的数据记录,这里的columns_name指的是df的一个属性名称,列标题'''
df[df.column_name.between(0,1000)]
df = pd.DataFrame({'name':['zhangsan','lisi','wangwu'],'age':[10,15,8],'体重':[110,120,140]})
# 筛选年龄age大于10的用户
df[df.age>10]
# 筛选体重大于110且年龄小于10的数据:如果字段名称是中文,需使用中括号表示属性df['体重']
df[(df['体重']>110) & (df.age<10)]
'''如果字段名是非中文,可以直接使用df.column_name指代Series,中文名称需使用[]括起来,比如:'''
df.age
df['体重'] # 中文字段需使用中括号括起来
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
筛选字段
df = pd.DataFrame({'name':['zhangsan','lisi','wangwu'],'age':[10,15,8],'体重':[110,120,140]})
df[['name','age']] # 选择name和age列,也可以用该方法调整字段顺序
'''如果字段比较多,想要剔除某个列可以使用列表推导式'''
df[[x for x in df.columns if x!='体重']]
- 1
- 2
- 3
- 4
isin:在区域范围内
类似与sql的where in语句,可以传入Series,list,tuple,set等。如果想表示not in 的话,可以在condition前面加上‘~’符号。
df[df.column_name.isin(df1.column_name)]
'''df中columns_name属性不在df1这列数据里边的数据记录。'''
df[~df.column_name.isin(df1.column_name)]
'''这么写,也可以表示not in'''
df[df.column_name.isin(df1.column_name)==False]
- 1
- 2
- 3
- 4
- 5
isnull:空值运算
'''筛选df的column_name属性为空的数据记录'''
df[df.column_name.isnull()]
- 1
- 2
- contains:字符匹配,筛选包含‘包含文字’的数据记录
Series.str.contains(pat, case=True, flags=0, na=nan, regex=True)
参数: - pat:字符串或者正则表达式;
- case:如果为True,区分大小写;
- flags:正则标记,标记传入到re模块,比如re.IGNORECASE,就是re.compile中的flags参数。
- regex:为True时,表示pat为正则表达式。
df[df.column_name.str.contain('包含文字'),na = False]
- 1
逻辑运算符
|:或;&:并且;not:非;
'''筛选语文大于80分且数学大于70分的数据记录'''
df[(df['语文']>80) & (df['数学']<70)]
- 1
- 2
字段类型筛选
# 筛选字段为object类型的列数据
df.select_dtypes(['object'])
# 筛选为数值型列的数据
df.select_dtypes(['number'])
# 筛选为整数列的数据
df.select_dtypes(include=['int'])
- 1
- 2
- 3
- 4
- 5
- 6
删除
drop_duplicates:删除重复数据
df.drop_duplicates(subset=None, keep=‘first’, inplace=False)
参数:
- subset:删除重复列标签,默认为所有列,也可以以列表传入部分字段名。
- keep:first保留第一次出现的、last保留最后出现的、False所有重复的都会被标记重复。
- inplace:Fasle不再源数据上做更改,需要赋值给其他变量。True直接在源数据上删除重复数据条。
df = pd.DataFrame({'姓名':['张三','李四','张三'],'科目':['语文','数学','语文'],'成绩':[70,85,77]})
df.drop_duplicates(['姓名','科目'],keep='last',inplace=True)
print(df)
- 1
- 2
- 3
输出如下:
姓名 科目 成绩
1 李四 数学 85
2 张三 语文 77
查看重复数据可使用:df[df.duplicated()]
drop:删除
DataFrame.drop(labels = None,axis = 0,index = None,columns = None,level = None,inplace = False,errors =‘raise’ )
参数:
- labels:单个标签或类似列表,要删除的索引或列标签。
- axis:删除行还是删除列,{0或’index’,1或’columns’},默认为0,删除行。
- index,columns : 单个标签或类似列表,直接指定索引或者列标签删除。效果等同于:labels+axis参数
- level : int或level name,可选;对于MultiIndex(复合索引),将从中删除标签的级别。
- inplace:是否在原数据集上做删除,默认为False,可以赋值给其他变量。
- errors:错误忽略或者提示,可选:{‘ignore’, ‘raise’};默认为raise报错提示。如果忽略,则在数据有的标签上做删除。
df = pd.DataFrame({'姓名':['张三','李四','张三'],'科目':['语文','数学','语文'],'成绩':[70,85,77]})
'''删除张三记录'''
df1 = df.drop(index=[0,2])
'''没有索引10,添加errors参数'''
df2 = df.drop(labels=[0,2,10],axis=0,errors='ignore')
- 1
- 2
- 3
- 4
- 5
df1和df2两者效果是等同的,效果如下:
姓名 科目 成绩
1 李四 数学 85
dropna:删除空值
DataFrame.dropna(axis = 0,how = ‘any’,subset=None,inplace=False)
参数:
- axis和inplace参数和drop方法是一样的。
- how:any或者all,any表示指定轴有一个为空值则删除,all表示指定轴所有为空才删除。
- subset:标签,指定axis轴,这些轴标签范围内再根据how参数去删除行或者列。
df = pd.DataFrame({'姓名':['张三','李四','张三'],'科目':['语文',None,'语文'],'成绩':[70,85,None]})
df1 = df.dropna(axis=0,subset=['姓名','科目'],how='any')
df2 = df.dropna(axis=1,subset=[0,1],how='any')
- 1
- 2
- 3
df1效果如下:
姓名 科目 成绩
0 张三 语文 70.0
2 张三 语文 NaN
df2效果如下:
姓名 成绩
0 张三 70.0
1 李四 85.0
2 张三 NaN
索引的堆
stack:列索引转化为行索引
索引level默认时从-1开始的,-1代表里层索引。
DataFrame.stack(level=-1,dropna=True)
df = pd.DataFrame(np.random.randint(50,96,size=(3,6)),
index=['张三','李四','王五'],
columns=[['java','java','html5','html5','python','python'], ['期中','期末','期中','期末','期中','期末']])
# 类似于excel的逆透视,stack方法后可以使用reset_index方法把index变成column
df1 = df.stack()
- 1
- 2
- 3
- 4
- 5
df内容:
java html5 python
期中 期末 期中 期末 期中 期末
张三 79 63 62 68 56 75
李四 83 87 62 87 75 56
王五 87 79 61 74 61 93
df1内容:
将列索引转化为index,dropna为True如果转化存在空的行,则删除。
html5 java python
张三 期中 62 79 56
期末 68 63 75
李四 期中 62 83 75
期末 87 87 56
王五 期中 61 87 61
期末 74 79 93
unstack:行索引转化为列索引
#我们把姓名索引转化为列索引,姓名在从里到外第二层索引,level从-1开始,这里level设置为0
df2 = df1.unstack(level=0)
- 1
- 2
df2内容如下:
html5 java python
张三 李四 王五 张三 李四 王五 张三 李四 王五
期中 62 62 61 79 83 87 56 75 61
期末 68 87 74 63 87 79 75 56 93
一些字符串类型字段处理方法
DataFrame.str.strip:去重两边空格
同字符串的strip方法:默认去除两边的空,去除其他字符串可以以参数传入,比如去除两遍空格和换行,lstrip和rstrip左右去除,该函数页适用于Series。
str_test = ' \n苹果\t'
'''去除两边空格,制表符,换行符'''
out_str = str_test.split(' \n\t')
#out_str:苹果
df[columns_name] = df[column_name].str.split( \n\t)
- 1
- 2
- 3
- 4
- 5
DataFrame.str.replace:替换
使用跟字符串使用方法一样,还可以同时替换做个字段某些文本为替换文本,该函数页适用于Series。该方法第一个参数pat默认是使用正则表达式,如果只想表示字符串,可以设置regexp参数为False;
'''体育字段的‘作弊’和军训字段的‘缺考’替换为0'''
df.replace({'体育':'作弊','军训':'缺考'},0)
'''把df中的‘一箱’替换成‘1箱’,‘二箱’替换成‘2箱’,可在不同字段的值,regexp=True表示字典的key是正则表达式,不然要完全匹配才能替换。'''
df.replace({'一箱':'1箱','二箱':'2箱'},regex=True)
'''第一个参数默认是正则表达式'''
s3.str.replace('^.a|dog', 'XX-XX ', case=False)
'''pat参数还可以接受re.complie编译对象'''
regex_pat = re.compile(r'^.adog', flags=re.IGNORECASE)
s3.str.replace(regex_pat, 'XX-XX ')
'''直接传入flags参数会报错。'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
Series.split(sep,expand=True):分隔符分隔
按照分割符分列 expand=True转化为DataFrame,不然那只是一个数组,逗号间隔。再用concat合并即可。n参数是切割字数,默认最大。
newdf = df.column_name.str.split('|',expand=True,n=2)
'''使用get访问切分后的元素'''
s2.str.split('_').str.get(1)
- 1
- 2
- 3
cat:连接函数
参数:sep连接分隔符;na_rep:指定空值,默认None;第一个参数传入跟序列长度一样常的列表时,表示将两个序列合并。join参数:left,right,inner,outer。类似于sql连接,根据索引合并两个序列;
其他常用字符串处理函数
- rsplit(): 在字符串末尾的分隔符上拆分字符串
- get(): 索引到每个元素(检索第i个元素)
- join(): 使用传递的分隔符连接Series的每个元素中的字符串
- get_dummies(): 在分隔符上拆分字符串,返回虚拟变量的DataFrame
- contains(): 如果每个字符串包含pattern / regex,则返回布尔数组
- replace(): 将pattern / regex / string的出现替换为其他字符串或给定事件的可调用的返回值
- repeat(): 重复值(s.str.repeat(3)相当于)x * 3
- pad(): 在字符串的左侧,右侧或两侧添加空格
- center(): 相当于 str.center
- ljust(): 相当于 str.ljust
- rjust(): 相当于 str.rjust
- zfill(): 相当于 str.zfill
- wrap(): 将长字符串拆分为长度小于给定宽度的行
- slice(): 切割系列中的每个字符串
- slice_replace(): 用传递的值替换每个字符串中的切片
- count(): 计算模式的出现次数
- startswith(): 相当于str.startswith(pat)每个元素
- endswith(): 相当于str.endswith(pat)每个元素
- findall(): 返回每个字符串的所有出现的pattern / regex的列表
- match(): 调用re.match每个元素,将匹配的组作为列表返回
- extract(): 调用re.search每个元素,为每个元素返回一行DataFrame,为每个正则表达式捕获组返回一列
- extractall(): 调用re.findall每个元素,返回DataFrame,每个匹配一行,每个正则表达式捕获组一列
- len(): 计算字符串长度
- rstrip(): 相当于 str.rstrip
- lstrip() 相当于 str.lstrip
- partition() 相当于 str.partition
- rpartition() 相当于 str.rpartition
- lower() 相当于 str.lower
- upper() 相当于 str.upper
- find() 相当于 str.find
- rfind() 相当于 str.rfind
- index() 相当于 str.index
- rindex() 相当于 str.rindex
- capitalize() 相当于 str.capitalize
- swapcase() 相当于 str.swapcase
- normalize() 返回Unicode普通表单。相当于unicodedata.normalize
- translate() 相当于 str.translate
- isalnum() 相当于 str.isalnum
- isalpha() 相当于 str.isalpha
- isdigit() 相当于 str.isdigit
- isspace() 相当于 str.isspace
- islower() 相当于 str.islower
- isupper() 相当于 str.isupper
- istitle() 相当于 str.istitle
- isnumeric() 相当于 str.isnumeric,
df[df.field_name.str.isnumeric()] - isdecimal() 相当于 str.isdecimal
数据聚合
concat:按照索引聚合
pd.concat
一些参数:
- objs:需要合并的对象,可以是序列、数据框或面板数据构成的列表。[df1,df2,df3]
- axis: {0 /‘index’,1 /‘columns’},默认为0。表示按行0(上下合并)或者按照列1(左右合并)拼接。
- join:指定合并的方式,默认为outer,表示合并所有的数据,如果改为inner,表示合并公共部分的数据。
- jion_axes:合并数据后,指定保留的数据轴。
- ignore_index:bool类型的参数,表示是否忽略原数据集的索引,默认为False,如果设为True,就表示忽略原索引并生成新索引。
- keys:为合并后的数据添加新索引,用于区分各个数据部分。
'''按照行合并,重建索引'''
df1 = pd.DataFrame(np.random.randint(3,20,(3,4)),columns=list('ABCD'))
df2 = pd.DataFrame(np.random.randint(3,20,(2,3)),columns=list('ABC'))
df3 = pd.concat([df1,df2],axis=0,ignore_index=True)
- 1
- 2
- 3
- 4
合并同一个目录下的excel表格
import pandas as pd
import glob
file_name_list = glob.glob('c:/*.xlsx')
usecols = ['id','name','sales']
df_list = [pd.read_excel(x,usecols=usecols) for x in file_name_list]
# 读取多个函数,也可以用map函数,如果只需一个文件参数的话
# df_list = map(pd.read_excel,file_name_list)
df = pd.concat(df_list)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
append:数据拼接(尾部追加)
跟列表的append方法时一样的,需要注意的时两个DataFrame字段位置,命名要一致,还是尽量使用concat方法好些。
'''ignore_index参数设置为True,忽略df1原来索引,重建索引。'''
df1021 = pd.DataFrame([['alice',18]],columns=['name','age'])
df1022 = pd.DataFrame([['bob',180]],columns=['name','height'])
df1021.append(df1022,ignore_index=True)
- 1
- 2
- 3
- 4
merge:数据连接,类似sql中的join
这个函数效果类似于sql的连接。
需要注意的是,如果连接字段有重复数据,结果会产生笛卡尔积,不需要重复数据,请先去重。
一些参数:
- left:指定需要连接的主表
- right:指定需要连击的辅表
- how:连接方式,默认为inner(内连接),其他:left(左连接),right(右连接),outer(外连接)
- on:指定连接两张表的共同字段,如果两个表连接字段同名的话,可以指定这个,而不需要再指定left_on和right_on参数。
- left_on:指定主表需要连接的字段
- righ_on:次表连接字段
- left_index:bool类型参数,是否将主表中的行索引引用作表连接的共同字段,默认为False
- right_index:bool,辅表~~使用left_index和right_index时,等同于concat列拼接,axis=1
- sort:bool,是否对连接后的数据按照共同字段排序,默认为False;
- suffixes:如果数据链接的结果中存在重叠的变量名,则使用格子的前缀进行区分。
'''左连接示例'''
df2 = pd.merge(df,df1,left_on='办理渠道编码',right_on='编码',how='left')
'''多个字段匹配示例'''
df1 = pd.DataFrame({'name':['alice','bob'],'class':[2,3],'age':[18,20]})
df2 = pd.DataFrame({'name':['alice','bob'],'class':[2,4],'weight':[180,200]})
df2 = df2.rename(columns={'name':'姓名'}) #我们给name改个名字
pd.merge(df1,df2,left_on=['name','class'],right_on=['姓名','class'],how='inner')
输入如下截图:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

pivot_table:类似Excel的透视表
跟excel的透视表性质是一样的。
关于部分values字段不出现在统计结果中的原因:可能是由于字段类型不一致,比如a,b字段类型是object,c,d字段类型是float,同时传入[a,b,c,d],返回统计字段可能只会出现c,d,遇到这种情况使用astype方法字段类型转化成一致;
一些参数:
- data:指定需要构造透视表的数据集
- values:指定需要拉入“数值”框的字段列表;
- index:指定行索引
- columns:指定需要拉入‘列标签’框的字段列表;
- aggfunc:指定数值的统计函数,默认为统计均值,也可以指定numpy模块中的其他统计函数。
- fill_value:指定一个标量,用于填充缺失值。
- margins:bool类型参数,是否需要显示行或者列的总计值,默认为False
- dropna:bool类型,是否需要删除整列为缺失字段,默认为True
- margins_name:指定行或列的总计名称,默认为ALL
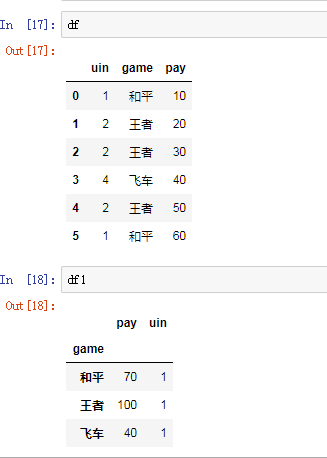
'''对Price求平均,对Sales求和''' pt = pd.pivot_table(df,index='Fruits',values=['Price','Sales'],aggfunc={'Price':np.mean,'Sales':np.sum}) '''行索引:分公司,渠道;列索引:地区;计算字段:新增;计算依据:求和。''' df1 = pd.pivot_table(df,values='新增',index=['分公司','渠道'],columns='地区',aggfunc='sum') '''使用自定义函数,分组后去重计数''' df = pd.DataFrame({'uin':[1,2,2,4,2,1], 'game':['和平','王者','王者','飞车','王者','和平'], 'pay':[10,20,30,40,50,60]} ) def unique_count(data): # 自定义去重计数函数 return len(set(data)) '''按照游戏分组,计算uv(去重计数),求和付费''' df1 = pd.pivot_table(df,index='game',values=['uin','pay'],aggfunc={'uin':unique_count,'pay':np.sum}) print(df,df1) #输出如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
groupby:类似sql中的group by聚合操作
df.groupby(by = [‘分类一’,‘分类二’,‘分类三’…])[‘被统计的列’].agg({列别名1:统计函数1,列别名2:统计函数2,列别名3:统计函数3…})
一些参数:
- by:表示用于分组的字段,可以为多列。
- []:表示分组后用于统计的字段,可以为多列。
- agg:表示统计别名统计值的名称,统计函数用于统计数据。常用的统计函数有:size计数,sum求和,mean平均值。可以自定义函数
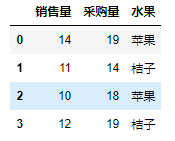
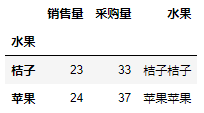
'''按日期分组,对tip字段求平均,对day字段计数''' df.groupby('day').agg({'tip': np.mean, 'day': np.size}) '''指定as_index参数为False,分组字段不会被列为index,等同于再处理reset_index(drop=Flase)''' df.groupby('day', as_index=False) '''按smoker,day分组,对tip分别计数,求平均值''' df.groupby(['smoker','day']).agg({'tip': [np.size, np.mean]}) '''按照班级,性别分组,统计语文分数。总分:对语文求和;人数:对语文分数计数;......''' df.groupby(by=['班级','性别'])['语文分数'].agg({'总分':np.sum,'人数':np.size,'平均值':np.mean,'方差':np.var,'标准差':np.std,'最高分':np.max,'最低分':np.min}) '''如果指向简单求和的话,不需要使用agg方法,后面直接跟.sum()方法就可以了''' df.groupby(by =['班级','性别'])['语文分数'].sum() '''可以使用get_group方法获取到指定分组,假设这里有(一年级,男)这个分区''' df.groupby(by =['班级','性别']).get_group(('一年级','男')) '''有时候为了结果表格好看些(规整),比如导出excel文件,我们会设置索引名字为空,具体效果大家可以手动尝试下。''' df.index.name = None '''还可以对分组使用apply方法,只是对分组后的数据进行apply,用法跟apply一样的。''' df1 = pd.DataFrame(np.random.randint(10,20,size=(4,2)),columns=['销售量','采购量']) df1['水果'] = ['苹果','桔子','苹果','桔子'] print(df1) df2 = df1.groupby('水果').apply(sum,axis=1) print(df2) df3 = df1.groupby('水果').apply(sum,axis=0) print(df3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
df1输出:
df2输出:

df3输出:
'''df.groupby对象返回的是一个键值对,key是groupby跟的参数,value是一个DataFrame'''
# 返回key是水果,value是columns是['销售量','采购量']的DataFrame
for name,group in df1.groupby('水果')['销售量','采购量']:
print(name)
print(group)
- 1
- 2
- 3
- 4
- 5

grouped.indices返回一个字典,其键为组名,值为本组索引的array格式,可以实现对单分组数据的选取;df.groupby(df.age>20).indices
理解了这个,就可以自定义构造各种聚合亦或类似sql中的开窗函数逻辑
'''假设这里有一张user表,内容如下'''
'''分组后,用join将name字段用‘_’拼接起来,向apply传入自定义函数。'''
df = user.groupby('id')['name'].apply(lambda x : '_'.join(x))
print(df)
- 1
- 2
- 3
- 4
user表

df
案例:
表字段:专业公司:company,用户id:party_id,资产:t_value
计算指标:按专业公司分组,
计算用户pv:party_id计数
用户uv:party_id去重计数
平均资产:t_value取平均数
大资产客户uv(t_value>15):当t_value>15,对party_id去重计数
company_list = ['银行','证券','壹钱包','养老险','产险','寿险'] id_list = list('ABCDEFGH') df = pd.DataFrame({ 'company':np.random.choice(company_list,25), 'party_id':np.random.choice(id_list,25)}).drop_duplicates() # 插入t_value字段:随机数12-20 df.insert(2,'t_value',np.random.randint(12,20,size=df.shape[0])) # 判断是否大资产用户,如果是返回party_id df['is_high_user'] = df.apply(lambda x:[np.nan,x[1]][x[2]>15],axis=1) # 指定as_index参数为False,会返回聚合后的分组(是column而非index),等同于后面reset_index操作 # 计算字段名默认为函数名,如果重名不会重复计算,多个lambda匿名函数系统会自动重命名 df1 = df.groupby('company',as_index=False).agg({ 'party_id':[np.size,lambda x:len(set(x))], 't_value':np.mean, 'is_high_user':lambda x:np.size(set(x)) }) # 只取聚合函数计算的列名称 df1.columns = df1.columns.levels[-1] print(df1.head(2)) df1.rename(columns={'<lambda>':'pv','<lambda_0>':'uv','mean':'avg','size':'high_user_uv'}).reset_index(drop=False).head(2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
计算字段名默认为函数名,如果重名不会重复计算,多个lambda匿名函数系统会自动重命名

重命名后的df
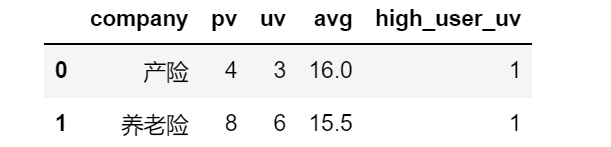
可以使用如下方法指定计算字段名称
# 这里使用as_index=False参数,计算字段输出会少一个,使用reset_index重置索引;
df1 = df.groupby('company').agg(**{
pv:pd.NamedAgg(column='party_id',aggfunc=np.size),
uv:pd.NamedAgg(column='party_id',aggfunc=lambda x:len(set(x))),
avg:pd.NamedAgg(column='t_value',aggfunc=np.mean),
high_user_uv:pd.NamedAgg(column='is_high_user',aggfunc=lambda x:np.size(set(x)))
}).reset_index(drop=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
pandas.NamedAgg只是一个namedtuple. 也允许使用普通元组
df1 = df.groupby('company').agg(
pv=('party_id',np.size),
uv=('party_id',lambda x:len(set(x))),
avg=('t_value',np.mean),
high_user_uv=('is_high_user',lambda x:np.size(set(x)))
).reset_index(drop=False)
print(df1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7

groupby对象的groups属性是一个字典,其键是计算出的唯一组,对应的值是属于每个组的轴标签。
df.groupby(‘company’).groups

groupby对象可以通过get_group获取指定分组的groupby对象
df.groupby('company').get_group('产险')

实现类似sql中的row_number开窗逻辑:
开窗根本上是按partition by的字段分组,把同一个key的value放到一起进行开窗函数应用;pandas里可以这样实现,比如取每个班级分数前2的名单;同sql中的row_number开窗
import pandas as pd
df = pd.DataFrame(columns=['班级','姓名','成绩'],data=[[1,'张三',77],[1,'李四',55],[1,'王五',77],[2,'小明',55],[2,'小丽',66],[2,'小红',77]])
print(df)
- 1
- 2
- 3
- 4
- 5

df['rnk'] = df['成绩'].groupby(df['班级']).rank(ascending=False,method='first')
df1 = df[df.rnk<=2]
print(df1)
- 1
- 2
- 3
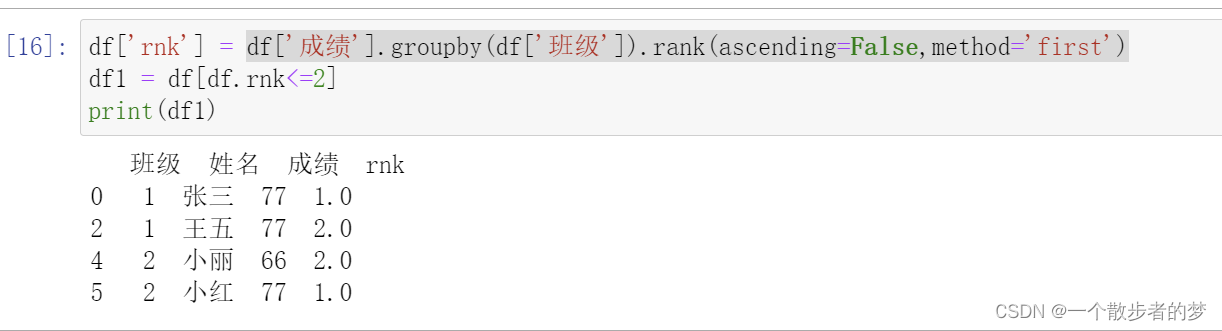
rnk函数method参数几个值的含义(比如有三个值:10,20,20,降序):
average:如果有相同的,取平均:3,1.5,1.5
min:跨越排序,相同都取最小值:3,1,1
max:跨越排序,相同值取最大值,3,2,2
first:连续排序,相同值排位不连续,同row_number:3,1,2
dense:连续排序,相同值排位一样,都取最小,同sql中的dense_rank:2,1,1
df.groupby('name).apply(lambda x:x*10),分组value的每个元素乘以10
# Q1成绩至少有一个大于97的组
df.groupby(['team']).filter(lambda x: (x['Q1'] > 97).any())
# 所有成员平均成绩大于60的组
df.groupby(['team']).filter(lambda x: (x.mean() >= 60).all())
# Q1所有成员成绩之和超过1060的组
df.groupby('team').filter(lambda g: g.Q1.sum() > 1060)
- 1
- 2
- 3
- 4
- 5
- 6
此外,还可以按筛选条件亦或函数进行分组
df.groupby(df.age>20).count()
df.groupby([df.dt.year,df.dt.month]) #日期提取年月分组
df.groupby(df.dt.apply(lambda x:x.year)).count()
# 结合分箱使用
df.groupby(pd.cut(df.Q1, bins=[0, 60, 100])).count()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
其他功能:
df.groupby('team').first() # 组内第一个 df.groupby('team').last() # 组内最后一个 df.groupby('team').ngroups # 5(分组数) df.groupby('team').ngroup() # 分组序号 grouped.backfill() grouped.bfill() df.groupby('team').head() # 每组显示前5个 grouped.tail(1) # 每组最后一个 grouped.rank() # 排序值 grouped.fillna(0) grouped.indices() # 组名:索引序列组成的字典 # 分组中的第几个值 gp.nth(1) # 第一个 gp.nth(-1) # 最后一个 gp.nth([-2, -1]) # 第n个非空项 gp.nth(0, dropna='all') gp.nth(0, dropna='any') df.groupby('team').shift(-1) # 组内移动 grouped.tshift(1) # 按时间周期移动 df.groupby('team').any() df.groupby('team').all() df.groupby('team').rank() # 在组内的排名 # 仅 SeriesGroupBy 可用 df.groupby("team").Q1.nlargest(2) # 每组最大的两个 df.groupby("team").Q1.nsmallest(2) # 每组最小的两个 df.groupby("team").Q1.nunique() # 每组去重数量 df.groupby("team").Q1.unique() # 每组去重值 df.groupby("team").Q1.value_counts() # 每组去重值及数量 df.groupby("team").Q1.is_monotonic_increasing # 每组值是否单调递增 df.groupby("team").Q1.is_monotonic_decreasing # 每组值是否单调递减 # 仅 DataFrameGroupBy 可用 df.groupby("team").corrwith(df2) # 相关性
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
分组常用计算函数
df.groupby('team').describe() # 描述性统计 df.groupby('team').sum() # 求和 df.groupby('team').count() # 每组数量,不包括缺失值 df.groupby('team').max() # 求最大值 df.groupby('team').min() # 求最小值 df.groupby('team').size() # 分组数量 df.groupby('team').mean() # 平均值 df.groupby('team').median() # 中位数 df.groupby('team').std() # 标准差 df.groupby('team').var() # 方差 grouped.corr() # 相关性系数 grouped.sem() # 标准误差 grouped.prod() # 乘积 grouped.cummax() # 每组的累计最大值 grouped.cumsum() # 累加 grouped.mad() # 平均绝对偏差
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
数据映射
apply和map和applymap区别:
- apply:针对行或者列计算
- map和applymap:针对元素进行计算。
- map只能用作于series,applymap可用于DataFrame,也是针对元素进行操作。
如果是针对Series操作,三者效果是等同的。
apply:对行或者列进行计算
DataFrame.apply(func, axis=0,args=())
apply传入的是一个Series对象,返回的也是一个Series对象;针对一列映射,与map另一个不同的是,apply可以传入args参数;
参数:
- func:传入的函数方法,可以传入自定义函数,传入函数时不要带括号
- axis:{0 or ‘index’, 1 or ‘columns’},默认是0,对每一列(所有行)计算。
df = pd.DataFrame({'姓名':['张三','李四','张三'],'科目':['语文',None,'语文'],'成绩':[70,85,None]}) ''' 姓名 科目 成绩 0 张三 语文 70.0 1 李四 None 85.0 2 张三 语文 NaN ''' '''查看每一列空值的个数。''' def sum_null(data): return sum(data.isnull()) '''传入匿名函数''' df.apply(lambda x : sum(x.isnull())) '''传入自定义函数''' df.apply(sum_null) ''' 姓名 0 科目 1 成绩 1 ''' # 查看各列空值个数: df.isull().sum()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
连续n(3)天活跃问题
- 现在有一张数据表,存储的是用户id和用户活跃时间;字段分别为{‘用户id’:‘uin’,‘用户活跃时间’:‘ftime’};目标,找出连续活跃3天的用户;
import datetime import pandas as pd from random import choices # 从数组中随机抽取n个元素,可重复; import numpy as np # 生成随机DataFrame:df uin_tuple = ('123','456','789','007','123','456','123') # 定义用户qq号 date_list = [datetime.date(2020,8,np.random.randint(1,7)) for d in range(30)] # 生成1-6号随机日期 df = pd.DataFrame({'uin':choices(uin_tuple,k=30),'ftime':date_list}) # 生成用户活跃信息 df = df.drop_duplicates() # 单日用户可能会有多条记录,进行去重; df = df.sort_values(by=['uin','ftime'],ascending=True) # 对df进行排序 '''定义全局变量,供apply调用''' uin = '0' ftime = datetime.date(2020,1,1) keep_days = 0 # 定义apply函数 def apply_func(data): global uin # 需要定义为全局变量 global keep_days global ftime if data[0] == uin and (data[1] - ftime).days == 1: keep_days = keep_days + 1 # 如果上一条记录跟当前用户相同,切活跃日期差1天,视为连续活跃;keep_days+1 else: keep_days = 1 ftime = data[1] uin = data[0] return keep_days '''新增一列,值为apply函数返回的keep_days值;axis=1,每一行记录作为一个Series传入;''' df['keep_days'] = df.apply(apply_func,axis=1) result = df[df.keey_days>=3].uin.unique() # 返回存在连续活跃3天记录的用户
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
输出结果df如下:返回用户123和用户456(数据是随机生成的,重运行结果可能会有所不同)

applymap:元素级别转化
'''A-J同学的成绩,60分一下标记不及格,60-80标记良好,80分以上标记优秀'''
df = pd.DataFrame(np.random.randint(40,99,size=(10,3)),columns=['语文','数学','英语'],index=list('ABCDEFGHIJ'))
'''创建分层自定义函数'''
def qut(data):
if data < 60:
return '不及格'
elif data <80:
return '良好'
else:
return '优秀'
df.applymap(qut)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
输出如下:
语文 数学 英语
A 不及格 优秀 不及格
B 优秀 良好 不及格
C 不及格 良好 优秀
D 优秀 不及格 良好
E 优秀 良好 不及格
F 不及格 不及格 良好
G 不及格 不及格 优秀
H 不及格 优秀 不及格
I 良好 良好 不及格
J 优秀 优秀 优秀
map、transfrom:内置函数,类同applymap
df = pd.DataFrame(np.random.randint(40,99,size=(5,3)),columns=['语文','数学','英语'],index=list('ABCDE'))
'''对于某一列(Series)进行操作时,下面映射函数效果是等同的,这里我们还是借用上面的qut函数'''
df['语文成绩分档'] = df['语文'].map(qut)
df2 = df['语文'].applymap(qut)
df3 = df['语文'].apply(qut)
df4 = df['语文'].transform(qut)
- 1
- 2
- 3
- 4
- 5
- 6
transpose:行列转置
一起放在这里吧,需要注意的是,如果index使用的是默认的数值索引,转置后,列索引会变成原来的index,可能不是我们想要的。这时候可以先使用set_index方法设置索引。
df = pd.DataFrame(np.random.randint(40,99,size=(5,3)),columns=['语文','数学','英语'],index=list('ABCDE'))
df1 = df.transpose()
# 或者使用df.T转置
- 1
- 2
- 3
df1输出如下:
A B C D E
语文 47 86 96 84 48
数学 76 45 62 97 65
英语 72 65 65 70 41
index(行索引)一些操作
sort_index:按照索引排序
'''按照索引降序排列:ascending排序参数.True是升序排列。'''
'''level:如果是多级索引的话需要指定按照哪级索引进行排序;'''
'''axis=0,按照index索引排序,axis=1按照columns索引排序'''
'''by是针对某一列或几列进行排序,axis=0,结合by传参,这种用法,作用等同于sort_values;'''
df.sort_index(axis= 1,ascending=False,by = None,level=0)
- 1
- 2
- 3
- 4
- 5
set_index:设置指定column为索引
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
参数:
- keys:设置索引的字段,字符串或者列表。
- drop:设置字段为索引后,原来字段是否删除。
- append:等于True时,保留原索引,并添加新索引。一般原来索引就不需要了。
- inplace:是否在原数据上做修改。
- verify_integrity:是否对索引做重复检查,一般不用这个,影响效率,没有必要性。
df = pd.DataFrame({'姓名':['张三','李四','王五'],'成绩':[88,75,90]})
df.set_index('姓名',drop=True,inplace=True)
print(df)
- 1
- 2
- 3
效果如下:
姓名 成绩
张三 88
李四 75
王五 90
reset_index:重置索引
DataFrame.reset_index(level = None,dorp = False,inplace = False,col_level=0)
一些参数:
- drop参数,=False,保留原有索引到列column字段。
- inplace=True 修改替换。
- level可以传入列表,用于指定index多级索引中重置索引级别
- col_level:如果列具有多个级别,则确定如何命名其他级别。如果为None,则重复索引名称。
reindex:索引重新调整顺序
通过该方法可以设置索引数据顺序,如果出现原来没有的索引,则填充为None。
reindex(index = None,**kwargs)
- 常用**kwargs参数:method = None,fill_value = np.nan:重建索引里边如果有索引原来没有则会在表里边添加,初始值为空,可用fill_value填充缺失值。
- method参数:
pad/ffill:用前一个非缺失值去填充该缺失值
backfill/bfill:用下一个非缺失值填充该缺失值
None:指定一个值取替换缺失值。
df = pd.DataFrame({'a':[1,2,3],'b':[2,2,3],'c':[3,2,1]})
df.reindex([2,0,1]) #第一参数传入列表默认修改index位置
df.reindex(columns = ['b','a','c']) #按照参数columns传入列表顺序修改列位置
- 1
- 2
- 3
效果如下:

分箱—指标值分层
cut:等宽分箱
Serise.cut(Series,bins,right = True,labels=null)
一些参数:
- series:需要分组的数据。
- bins:分组的依据
- right:分组的时候右边是否闭合。
- labes:分组的自定义标签,可以不定义。
import pandas as pd
import numpy as np
df['数学'] = np.random.randint(40,98,size=10)
bins = [df['数学'].min()-1,60,70,80,df['数学'].max()+1]
labels = ['不及格','及格','良好','优秀']
demo = pd.cut(df['数学'],bins = bins,labels = labels,right = False)
- 1
- 2
- 3
- 4
- 5
- 6
等深分箱:频数
lst = [6,8,10,15,16,24]
'''等深分箱:lst列表;q按照数据个数分为几等分,lables分箱对应的自定义标签。'''
pd.qcut(lst,q = 3,labels = None)
'''等宽分箱。bins参数,按照宽度区间分箱,也可以指定labels。 '''
pd.cut(lst,bins = 3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
null(空)的一些函数
dropna函数上面提及了,这里就不再重复了。
pandas里面的NAN是浮点类型,一个包含null的整数列字段类型会被强制转化为float类型;读取时如果是整数不想被转化成float类型,可以指定dtype,比如;
pd.Series([11, None], dtype="Int64")
isnull:判断空
df = pd.DataFrame({'语文':np.random.randint(50,100,size=(5)),'数学':np.random.randint(50,100,size=(5)),
'英语':np.random.randint(50,100,size=(5)),'理综':[140,None,188,190,np.nan]},
index=['张三', '李四','王素','凌凌漆','王五'])
print(df)
- 1
- 2
- 3
- 4
数据如下:
语文 数学 英语 理综
张三 51 96 64 140.0
李四 83 68 88 NaN
王素 89 70 66 188.0
凌凌漆 51 78 84 190.0
王五 80 78 90 NaN
'''any表示只要有一个为空就返回True,axis=1表示所有列,即针对每一行判断,如果一行中有一个为空,则返回True'''
'''相对应的all表示范围内所有都不为空,才返回True,只要有一个不是空返回False'''
df1 = df.isnull().any(axis=1)
df2 = df[df.isnull().any(axis=1)]
print(df1)
print(df2)
'''如果想查看‘理综’字段有空值的数据记录,可以这么抽取'''
df[df['理综'].isnull()]
# df各列是null的个数
df.isnull().sum()
# df总null个数
df.isnull().sum().sum()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
输出如下:
张三 False
李四 True
王素 False
凌凌漆 False
王五 True
df2中只有李四和王五的成绩中存在空值,所以df2返回这两条记录。
语文 数学 英语 理综
李四 83 68 88 NaN
王五 80 78 90 NaN
'''axis=0时,针对每一列进行判断,如果一列中有空,则返回True,相应的all方法,该列所有都是空才返回True'''
df1 = df.isnull().any(axis=0)
'''针对列筛选,我们用loc,列参数再传入df1'''
df2 = df.loc[:,df1]
print(df1)
print(df2)
- 1
- 2
- 3
- 4
- 5
- 6
df1中只有理综有空值
语文 False
数学 False
英语 False
理综 True
df2
理综
张三 140.0
李四 NaN
王素 188.0
凌凌漆 190.0
王五 NaN
'''查看每一列空值的个数'''
df.isnull().sum()
# 查看各字段缺失值占比
df.apply (lambda col:sum(col.isnull ()) /col.size)
- 1
- 2
- 3
- 4
notnull:非空,与isnull相反
用法个isnull一样的
'''查看每一列非空单元格个数'''
df.notnull().sum()
'''针对每一列,查看是否都不为空'''
df.notnull().all(axis=0)
'''针对每一行,看是否有非空'''
df.notnull.any(axis=1)
'''筛选也是一样的,这里不再多赘述了。'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
fillna:空值填充
DataFrame.fillna(value = None,method = None,axis = None,inplace = False,limit = None)
一些参数:
- value:用于填充null的值(例如0),或者用于指定每个索引(对于Series)或列(对于DataFrame)使用哪个值的值的Dict / Series / DataFrame,该值不能是列表。
- method:{‘backfill’,‘bfill’,‘pad’,‘ffill’,None},填充方法,默认无;backfill和bfill用后面一个值填充空值,pad和ffill用前面一个值填充空值。
- axis: {0或’索引’,1或’列’},还是一样的,这个参数指的是轴。
- inplace:是否在原数据上做修改,如果不想再原数据上修改,可以将结果赋值给另一个变量。
- limit:如果指定method方法的话,如果有连续空值,表示填充空值的个数,如果连续空值超过limit参数,则不再填充。
'''用后一个值填充空值'''
df.fillna(method='bfill')
'''用平均数或者其他描述性统计量填充空值'''
df.fillna(df.mean())
'''也可以传入一个字典对不用列填充不同的值。'''
df.fillna({'列名一':值一,'列名二':值二})
'''如果字典‘检测值’为空,用‘检验结果’填充'''
df1.loc[df1[df1.检测值.isnull()].index,'检测值'] = df1.loc[df1[df1.检测值.isnull()].index,'检验结果']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
关于空值释义及判断的一些问题
空的几种解释:
- 空字符串
- 不存在:比如小孩没有身份证
- 不确定:不知道具体是什么
针对上面第三种情况,因为不确定,所以与其他任何对象都是不对等的;在SQL中也常常可以体现这个问题;
pandas的null基本可以理解为第三种解释
numpy模块可以有三个对象,可以表示该中空:from numpy import NAN,nan,NaN
针对DataFrame的单个元素e,我们可以用np.isnan(e)或者pd.isnull(e)来判断内容是否为空,非空可以使用pd.notnull(e)
np.nan和None在DataFrame中都是numpy.float64类型,在用‘==’进行单个元素空值判断的时候,发现即使两边都是空值,输出还是False。Series和DataFrame可以使用isnull方法识别。
df = pd.DataFrame({'姓名':['张三','李四','王五'],'年龄':[np.nan,25,None]})
print(df)
'''定义自定义函数:判断是否为空'''
def isnull(e):
ret = 1 if pd.isnull(e) else 0
return ret
df.applymap(isnull).apply(sum) # 查看各列空值的个数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
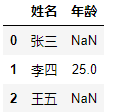
'''推荐使用该方法''' np.isnan(df.at[0,'年龄']) #out:True '''或者:''' if df.at[0,'年龄']: print(1) #out:1 df.at[0,'年龄'] #out:nan type(df1.at[2,'年龄']) #out:numpy.float64 df.at[0,'年龄'] == df.at[0,'年龄'] #out:False df.at[0,'年龄'] == np.nan #out:False df.at[0,'年龄'] == None #out:False #Pandas使用NumPy NaN(np.nan)对象表示缺失值。这是一个不等于自身的特殊 对象(类似于sql的不确定): np.nan == np.nan #out:False # Python的None对象是等于自身的 None == None # out:True # 所有和np.nan的比较都返回False,除了不等于: 5 > np.nan # out:False np.nan > 555 # out:False 10 != np.nan # out:True
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
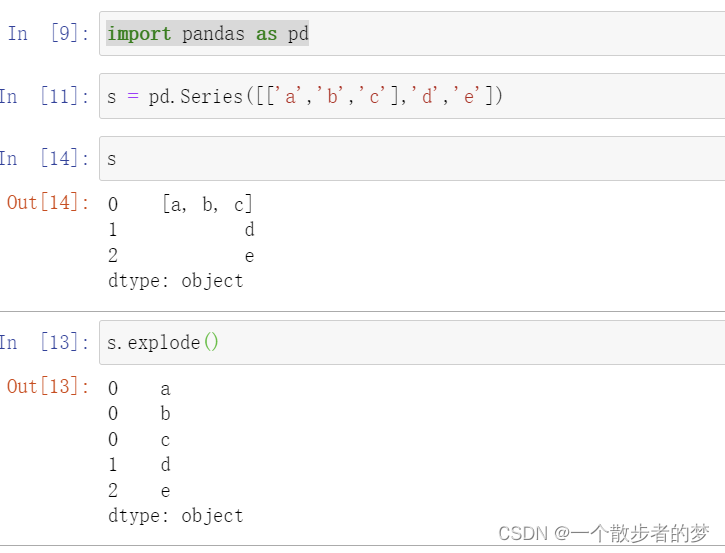
数据炸裂:explode
类似于sql中的explode函数;类似于spark的flatmap算子;将一个Series每个value,如果是数组,每个数组值拆成一行;
比如:
import pandas as pd
s = pd.Series([['a','b','c'],'d','e'])
s.explode()
- 1
- 2
- 3
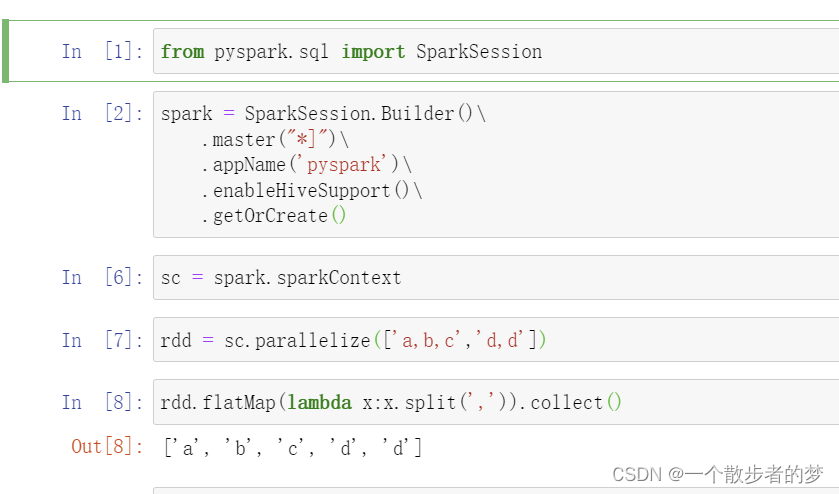
在spark中的flatMap算子示例:
from pyspark.sql import SparkSession
spark = SparkSession.Builder()\
.master("*]")\
.appName('pyspark')\
.enableHiveSupport()\
.getOrCreate()
sc = spark.sparkContext
rdd = sc.parallelize(['a,b,c','d,d'])
rdd.flatMap(lambda x:x.split(',')).collect()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
hive亦或SparkSQL中,可以这样写:select explode(split(field_name,'sep'));其中,field_name是字段名;sep是字段分割符号;
如果是DataFrame应用:df.explode('field_name');field_name为column字段名
SQL在表中的实现:field_name按英文逗号分隔再炸裂
select a.id,b.sub_field_name
from table_name a lateral view explode(split(field_name,',') b as sub_field_name
- 1
- 2
窗口函数
rolling
# 语法
df.rolling(window, min_periods=None
,center=False
,win_type=None,on=None,axis=0,closed=None)
- 1
- 2
- 3
- 4
参数:
- window:必传,如果使用int,可以表示窗口的大小;如果是offset类型,表示时间数据中窗口按此时间偏移量设定大小。
- min_periods:每个窗口的最小数据,小于此值窗口的输出值为NaN,offset情况下,默认为1。默认情况下此值取窗口的大小。
- win_type:窗口的类型,默认为加权平均,支持非常丰富的窗口函数,如boxcar、triang、blackman、hamming、bartlett、parzen、bohman、blackmanharris、nuttall、barthann、kaiser(beta)、gaussian(std)、general_gaussian (power, width)、slepian (width)、exponential (tau)等。
- 具体算法可参考SciPy库的官方文档:https://docs.scipy.org/doc/scipy/reference/signal.windows.html。on:可选参数,对于DataFrame要作为窗口的列。
- axis:计算的轴方向。
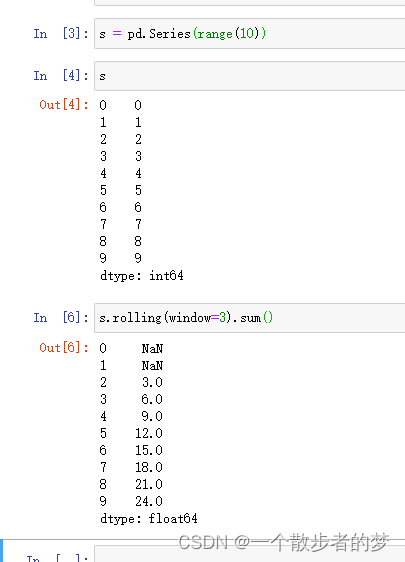
import pandas as pd
s = pd.Series(range(10))
s.rolling(window=3).sum() # 窗口window参数是3,所以前面两个值窗口数值数不够3个返回nan
- 1
- 2
- 3
- 4
每两天一个窗口,求平均数df.rolling('2D').mean()
窗口主要支持以下统计方法。
- count():非空值数
- sum():值的总和
- mean():平均值
- median():数值的算术中位数min():最小值
- max():最大值std():贝塞尔校正的样本标准偏差
- var():无偏方差skew():样本偏斜度(三阶矩)
- kurt():峰度样本(四阶矩)
- quantile():样本分位数(百分位上的值)
- cov():无偏协方差(二进制)
- corr():关联(二进制)
对窗口中的不同列使用不同的计算方法df.rolling('2D').agg({'A':sum, 'B': np.std})
对同一列使用多个函数df.A.rolling('2D').agg({'A_sum':sum, 'B_std': np.std})
自定义函数:df.A.rolling('2D').apply(lambda x: abs(sum(x)+1))
expanding
与rolling类似,不过窗口是从最上面第一行到当前行。而不是window参数指定的行数
其他一些常用函数/方法
查看数据类型及转化
查看类型:type(df),df.dtypes:df每一列的类型。
挑出所有数值型变量:
num_variables = df.columns[df.dtypes != 'object']
- 1
- 类型转化
'''使用astype方法,参数也可以直接传入int,str,float,不用加双引号。'''
df['Name'] = df['Name'].astype(np.datetime64)
'''对于符合日期格式的字符串,转化为日期。比如2019-1-31'''
'''此外还有to_numeric转化为数值;to_pickle转化为二进制'''
df.column_name = pd.to_datetime(df.column_name)
- 1
- 2
- 3
- 4
- 5
- 6
value_counts:计数
s = np.random.randint(1,100,size = 100)
n_s = pd.Series(s,name = '数字')
'''normalize参数为True时,是计算百分比。默认是False计数'''
n_s.value_counts(normalize = True)
- 1
- 2
- 3
- 4
sort_values:排序
'''按照shuxve字段排序,axis=0表示按照行排序,inplace表示是否在原数据集上操作修改。asceding=False:降序'''
df.sort_values('shuxve',axis = 0,ascending=False,inplace =True)
'''先按字段a排序再按照字段b排序;等同于sort_index(by = ['a','b'])'''
df.sort_values(by= ['a','b'])
'''传入两个参数,整体排序按照acending第一参数排序,第一个字段存在重复时,第二个字段按照ascending的第二个参数True排序'''
df = pd.DataFrame({'语文':[1,2,2,5],'数学':[4,6,1,9]})
df.sort_values(['语文','数学'],ascending=[False,True])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

rank:排名
一些参数:
- axis:0或1,如果是0,表示在某一列(所有行)进行排名。如果是1,就是每一行数据中的排名。
- method:默认是‘average’,当存在两个相同数据时,排名取两个的平均值。‘min’两个数值相同,两个都取小的那个排名。‘max’相同排名取大
- asceding:当为True时,最小值为第一名。假设有两个最小值,method取‘min’,即两个都是第一。为False时,最大值为第一名,相对应的假设有两个最大值,method参数为‘max’,那两个都取第2;
s = pd.Series([10,20,10,80,12])
s.rank(ascending=True,method='min')
- 1
- 2
效果如下:
0 1.0
1 4.0
2 1.0
3 5.0
4 3.0
unique:唯一、去重
'''is_unique判断是否唯一'''
df.index.is_unique #index索引是否唯一
df.column_name.is_unique #df的column_name属性的值是否唯一
df.column_name.unique() #提取df的column_name属性的唯一值。
- 1
- 2
- 3
- 4
sample:抽样
'''抽样10个'''
df.sample(n=10)
'''按照百分比抽样。'''
df.sample(frac = 0.01)
- 1
- 2
- 3
- 4
- 5
value(值)、index(行索引)、columns(列索引)
'''转化为数组'''
arr = df.values
brr = df.column_name.values
'''index索引'''
df.index
'''column索引'''
df.columns
'''columns索引转化为列表'''
df.columns.tolist()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
rename:索引重命名
inplace参数:是否在原数据源上做修改,默认为False。
'''index参数和columns参数传入字典,通过字典键值对修改索引名'''
df = pd.DataFrame(np.random.randint(3,20,(3,4)),columns=list('ABCD'))
'''把columns:A索引重命名为‘列A’,修改index索引也是一样的,传入字典即可。'''
df.rename(columns={'A':'列A'})
- 1
- 2
- 3
- 4
DataFrame.to_dic:转化为字典
DataFrame.to_dict(orient =‘dict’)
orient参数:
orient : str {‘dict’,‘list’,‘series’,‘split’,‘records’,‘index’}
该参数确定返回字典的类型
- ‘dict’(默认值):像{column - > {index - > value}}这样的字典
- ‘list’:像{column - > [values]}这样的字典
- ‘series’:dict like {column - > Series(values)}
- ‘split’:dict like {‘index’ - > [index],‘columns’ - > [columns],‘data’ - > [values]}
- ‘records’:列表如[{column - > value},…,{column - > value}]
- ‘index’:像{index - > {column - > value}}这样的字典
'''举几个例子,具体大家可以尝试看下其他效果。'''
df = pd.DataFrame({"姓名":['张三','李四'],'语文':[78,61],'数学':[89,91]})
dic_dict = df.to_dict("dict")
dic_records = df.to_dict('records')
dic_list = df.to_dict('list')
print(dic_dict,dic_records,dic_list)
- 1
- 2
- 3
- 4
- 5
- 6
输出如下:
dic_dict
{‘姓名’: {0: ‘张三’, 1: ‘李四’}, ‘语文’: {0: 78, 1: 61}, ‘数学’: {0: 89, 1: 91}}
dic_records
[{‘姓名’: ‘张三’, ‘语文’: 78, ‘数学’: 89}, {‘姓名’: ‘李四’, ‘语文’: 61, ‘数学’: 91}]
dic_list
{‘姓名’: [‘张三’, ‘李四’], ‘语文’: [78, 61], ‘数学’: [89, 91]}
常用计算函数
可能出现的一些参数:
- axis : {index(0),columns(1)}指定轴,0表示对于每一列进行计算。
- skipna:是否跳过空格,默认为True
- level:int或level name,默认为None;如果轴是MultiIndex(分层),则沿特定级别计数,折叠为系列
- numeric_only:book,默认为None,是否仅针对只包含数值的轴进行计算。
常用函数及作用如下:
- count:非空计数
- sum:求和,比如:
df.sales.sum() - mode:众数
- mad:平均绝对偏差
- max:最大值,
df.age.max() - min:最小值
- std:标准差
- var:方差
- cov:协方差
- skew:偏态系数
- kurt:峰态系数
- mean:平均值
- cumsum:累加函数,该函数只能针对Series计算。
- corr:method参数:pearson (default):标准相关系数;kendall:Kendall Tau相关系数;spearman :斯皮尔曼等级相关系数
- quantile:样本分位数,比如0.25四分位。
- describe:描述性统计;
离散型变量描述性统计:df.describe(include = ['object'])
时间序列
datetime.dt:提取时间元素
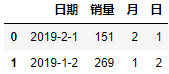
df = pd.DataFrame({'日期':['2019-2-1','2019-1-2'],'销量':[151,269]})
df['月'] = pd.to_datetime(df['日期']).dt.month
df['日'] = pd.to_datetime(df['日期']).dt.day
print(df)
- 1
- 2
- 3
- 4
输出如下:
to_datetime:字符串转化为日期
errors参数:
ignore:在日期无法解析时返回原始输入
coerce:无法解析时转化为NaT(not a time)
import datetime
dti = pd.to_datetime(['1/1/2018', np.datetime64('2018-01-01'),datetime.datetime(2018, 1, 1)] , errors='ignore')
'''使用origin参数时,可以指定创建DatetimeIndex。例如,将1960-01-01作为开始日期:'''
s = pd.to_datetime([1, 2, 3], unit='D', origin=pd.Timestamp('1960-01-01'))
print(s)
- 1
- 2
- 3
- 4
- 5
s输出如下:
DatetimeIndex([‘1960-01-02’, ‘1960-01-03’, ‘1960-01-04’], dtype=‘datetime64[ns]’, freq=None)
13.3 date_range:固定频率生成日期
一些参数:
- start:开始日期,用字符串
- end:结束日期,用字符串
- freq:间隔,其他参数需要进一步查询
- periods:没有指定结束日期,可以指定该参数说明生成日期个数。
dti = pd.date_range('2018-01-01', periods=3, freq='H')
print(dti)
- 1
- 2
dti输出如下:
DatetimeIndex([‘2018-01-01 00:00:00’, ‘2018-01-01 01:00:00’,‘2018-01-01 02:00:00’],type=‘datetime64[ns]’, freq=‘H’)
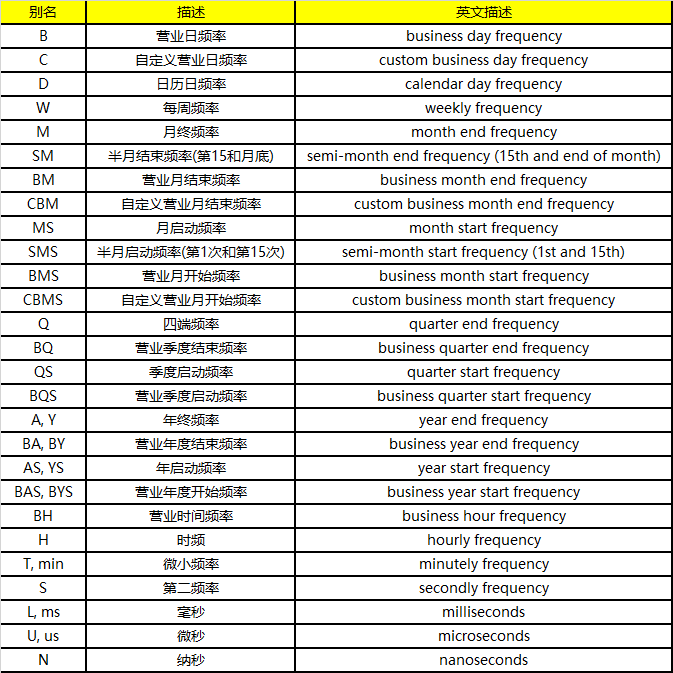
freq详参:
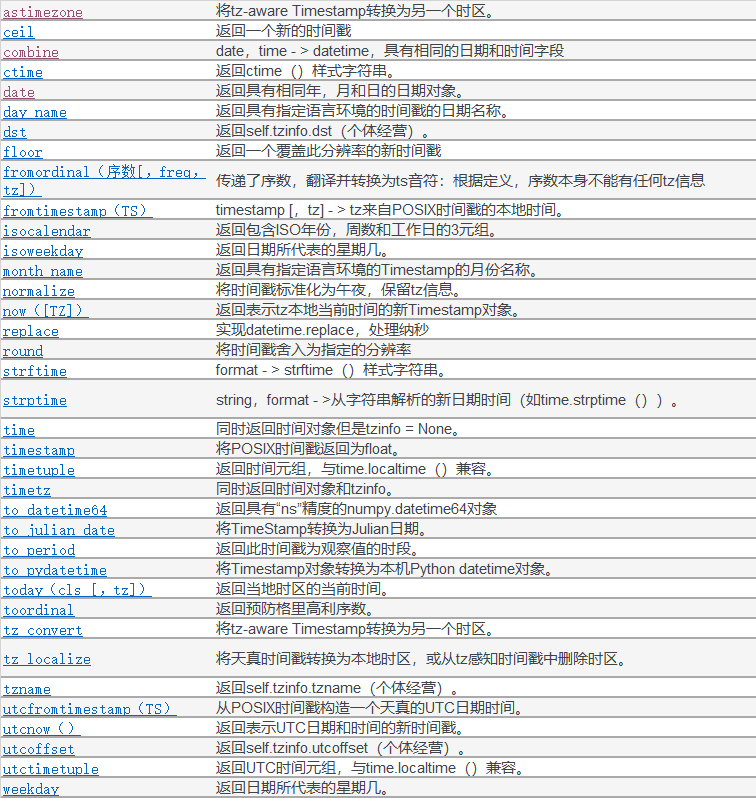
Timestamp:继承于datetime.datetime
pd.Timestamp(2017, 1, 1, 12)
#Timestamp('2017-01-01 12:00:00')
pd.Timestamp(year=2017, month=1, day=1, hour=12)
#Timestamp('2017-01-01 12:00:00')
- 1
- 2
- 3
- 4
Timestamp一些属性:
t = pd.Timestamp('2019-1-1')
t.dayofweek '''星期一到星期日:0-6'''
#4
- 1
- 2
- 3
- day:返回日期的day
- dayofweek :返回星期几
- dayofyear:返回一年当中第多少天
- days_in_month:返回当月一共有多少天
- daysinmonth:返回当月的第多少天
- hour :返回小时
- is_leap_year
- is_month_end :是否当月最后一天
- is_month_start :是否当月的第一天
- is_quarter_end :是否最后季度
- is_quarter_start :是否第一个季度
- is_year_end :是否当年最后一天
- is_year_start :是否当年第一天
- microsecond
- minute :返回分钟
- month :返回月份
- nanosecond
- quarter :返回季度
- second :返回时间的秒
- value :返回时间戳,数值型
- weekofyear :返回一年中第多少周
- year:返回日期的年
一些方法:
'''strptime字符串转化为日期'''
pd.Timestamp.strptime('2019-1-1','%Y-%m-%d')
#Timestamp('2019-01-01 00:00:00')
- 1
- 2
- 3
Timedelta:时间差、持续时间
该类继承于datetime.timedelta,timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0)
表示持续时间,两个日期或者时间之间的差异,具体大家根据nuit参数灵活使用。参数从官网copy下来的,尝试了下,可能有个别参数用不了,比如M,W。大家可以多试试。
Timedelta(value, unit=None, **kwargs)
value参数 : Timedelta, timedelta, np.timedelta64, string, or integer
kwargs参数继承自datatime.timedelta: {days, seconds, microseconds,milliseconds, minutes, hours, weeks}
unit参数:
str,可选,如果输入是整数,则表示输入的单位。默认为’ns’。可能的值:{‘Y’,‘M’,‘W’,‘D’,‘days’,‘day’,‘hours’,hour’,‘hr’,‘h’,‘m’,‘minute’ ,‘min’,‘minutes’,‘T’,‘S’,‘seconds’,‘sec’,‘second’,‘ms’,‘milliseconds’,‘millisecond’,‘milli’,‘millis’,’ L’,‘us’,‘microseconds’,‘microsecond’,‘micro’,‘micros’,‘U’,‘ns’,‘nanoseconds’,‘nano’,‘nanos’,‘nanosecond’,‘N’ }
friday = pd.Timestamp('2018-01-05') print(friday.day_name()) #'Friday' '''加一天,unit参数表示间隔时间单位''' saturday = friday + pd.Timedelta('1 day') print(saturday.day_name()) #'Saturday' '''加5小时''' dt = friday + pd.Timedelta('5 h') print(dt) #Timestamp('2018-01-05 05:00:00') '''也可以这样传入参数,下面这几个参数是生效的,月份试过不生效''' pd.Timedelta(hours=1) #Timedelta('0 days 01:00:00') pd.Timedelta(days=1) #Timedelta('1 days 00:00:00') pd.Timedelta(minutes=1) #Timedelta('0 days 00:01:00') pd.Timedelta(seconds=1) #Timedelta('0 days 00:00:01') pd.Timedelta(weeks=1) #Timedelta('7 days 00:00:00') '''传入datetime模块timedelta类不支持months参数,可以使用下面方法''' from dateutil.relativedelta import relativedelta import datetime a = datetime(2008,3,31) a + relativedelta(months=-1) #out: datetime.date(2008, 2, 29)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
date_range:生成时间序列[时间切片]
rng = pd.date_range(start, end, freq='BM')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
print(ts.index)
- 1
- 2
- 3
输出如下:
DatetimeIndex([‘2011-01-31’, ‘2011-02-28’, ‘2011-03-31’, ‘2011-04-29’,
‘2011-05-31’, ‘2011-06-30’, ‘2011-07-29’, ‘2011-08-31’,
‘2011-09-30’, ‘2011-10-31’, ‘2011-11-30’, ‘2011-12-30’],
dtype=‘datetime64[ns]’, freq=‘BM’)
ts[:5].index
- 1
输出:
DatetimeIndex([‘2011-01-31’, ‘2011-02-28’, ‘2011-03-31’, ‘2011-04-29’,‘2011-05-31’],dtype=‘datetime64[ns]’, freq=‘BM’)
ts[::2].index
- 1
输出:
DatetimeIndex([‘2011-01-31’, ‘2011-03-31’, ‘2011-05-31’, ‘2011-07-29’,
‘2011-09-30’, ‘2011-11-30’],dtype=‘datetime64[ns]’, freq=‘2BM’)
'''2011年1月31日''' ts['1/31/2011'] '''也可以结合datetime模块直接传入datetime''' ts[datetime.datetime(2011, 12, 25):] '''2011年10月31日-2011年12月31日''' ts['10/31/2011':'12/31/2011'] '''按照年筛选''' ts['2011'] '''按照年月筛选''' ts['2011-6'] '''DataFrame也是实用的,我们也可以使用loc切片''' '''年月范围筛选,包含月最后一天''' df['2013-1':'2013-2'] df.loc['2013-1':'2013-2',:] '''年月日筛选''' df['2013-1':'2013-2-28'] '''传入datetime字符串筛选'' df['2013-1':'2013-2-28 00:00:00'] '''精确索引:这些Timestamp和datetime物体有精确的hours, minutes,和seconds,即使没有显式指定它们(它们是0)''' df[datetime.datetime(2013, 1, 1):datetime.datetime(2013, 2, 28)] df[datetime.datetime(2013, 1, 1, 10, 12, 0):datetime.datetime(2013, 2, 28, 10, 12, 0)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
展示样式:style
df.style 类似于excel中,可以对单元格,字体等设置样式;更详细的参数亦或子类属性,可以通过help,亦或dir指令查看;比如:help(df.style)
Pandas提供的样式功能可实现:数值格式化,如千分号、小数位数、货币符号、日期格式、百分比等;凸显某些数据,对行、列或特定的值(如最大值、最小值)使用样式,如字体大小、黄色、背景;显示数据关系,如用颜色深浅代表数据大小;迷你条形图,如在一个百分比的格子里,用颜色比例表达占比;表达趋势,类似Excel中每行代表趋势变化的迷你走势图(sparkline)
空值高亮:
# 使用颜色名
df.head().style.highlight_null(null_color='blue')
# 使用颜色值
df.head().style.highlight_null(null_color='#ccc',subset=['col1','col2']) # subset指定字段适用该格式设置
- 1
- 2
- 3
- 4
最大/最小值高亮
# 将最大值高亮,默认为黄色背景
df.head().style.highlight_max()
# 将最小值高亮
df.head().style.highlight_min()
# 以上同时使用并指定颜色
(df.head()
.style.highlight_max(color='lime') # 将最大值高亮并指定颜色
.highlight_min() # 将最小值高亮
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
颜色渐变
background_gradient()
# 链式方法使用样式
(df.head(10)
.style
.background_gradient(subset=['Q1'], cmap='spring') # 指定色系
.background_gradient(subset=['Q2'], vmin=60, vmax=100) # 指定应用值区间
.background_gradient(subset=['Q3'], low=0.6, high=0) # 高低百分比范围
.background_gradient(subset=['Q4'], text_color_threshold=0.9) # 文本色深
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
条形图
df.head().style.bar(subset=['Q4'], vmin=50, vmax=100) 显示Q4列的条形图
# 基本用法,默认对数字应用 df.style.bar() # 指定应用范围 df.style.bar(subset=['Q1']) # 定义颜色 df.style.bar(color='green') df.style.bar(color='#ff11bb') # 以行方向进行计算和展示 df.style.bar(axis=1) # 样式在格中的占位百分比,0~100,100占满 df.style.bar(width=80) # 对齐方式: # 'left':最小值开始 # 'zero':0值在中间 # 'mid':(max-min)/2 值在中间,负(正)值0在右(左) df.style.bar(align='mid') # 大小基准值 df.style.bar(vmin=60, vmax=100)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
字体格式
# 语法格式
Styler.format(self, formatter,
subset=None,
na_rep: Union[str, NoneType]=None)
- 1
- 2
- 3
- 4
formatter可以是(str,callable, dict, None)中的任意一个,一般是一个字典(由列名和格式组成),也可以是一个函数。关于字符的格式化可参考Python的格式化字符串方法。
df.head().style.format("[{}]") 给所有数据加一个方括号
# 百分号 df.style.format("{:.2%}") # 指定列全变为大写 df.style.format({'name': str.upper}) # B,保留四位;D,两位小数并显示正负号 df.style.format({'B': "{:0<4.0f}", 'D': '{:+.2f}'}) # 应用lambda df.style.format({"B": lambda x: "±{:.2f}".format(abs(x))}) # 缺失值的显示格式 df.style.format("{:.2%}", na_rep="-") # 处理内置样式函数的缺失值 df.style.highlight_max().format(None, na_rep="-") # 常用的格式 {'a': '¥{0:,.0f}', # 货币符号 'b': '{:%Y-%m}', # 年月 'c': '{:.2%}', # 百分号 'd': '{:,f}', # 千分位 'e': str.upper} # 大写
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
添加标题
df.style.set_caption('表格标题名')
设置全局数据精度
df.style..set_precision(2)
CSS样式
以通过直接指定HTML树节点上的CSS样式来实现复杂的功能
df.head().style.set_properties(subset=['Q1'], **{'color': 'red'}) 将Q1列文字设为红色
也可以设置背景颜色:background-color,align对齐(right右),fond-size字体大小等;更多可以网上搜索html相关格式语法;
style.set_table_attributes()用于给
.set_table_styles()用于设置表格样式属性,用来实现极为复杂的显示功能。
# 给所有的行(tr标签)的hover方法设置黄色背景
# 效果是当鼠标移动上去时整行背景变黄
df.style.set_table_styles(
[{'selector': 'tr:hover',
'props': [('background-color', 'yellow')]}]
)
- 1
- 2
- 3
- 4
- 5
- 6
函数应用
也可以应用自定义函数
# 将最大值显示红色,x.name='field_name1'仅对字段field_name1应用
def highlight_max(x):
return ['color: red' if v == x.max() and x.name='field_name1' else '' for v in x]
# 应用函数
df.style.apply(highlight_max)
# 按行应用
df.loc[:,'Q1':'Q4'].style.apply(highlight_max, axis=1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
applymap()对全表起作用。如下将所有值大于90分的格子的背景设置为黄色
# 定义函数,只对数字起作用,将大于90的值的背景设置为黄色
bg = lambda x: 'background-color: yellow' if type(x) == int and x > 90 else ''
# 应用函数
df.style.applymap(bg)
- 1
- 2
- 3
- 4
subset可以限制应用的范围:
# 指定列表(值大于0)加背景色
df.style.applymap(lambda x: 'background-color: grey' if x>0 else '',
subset=pd.IndexSlice[:, ['B', 'C']])
- 1
- 2
- 3
样式清除
df.style.clear()
导出excel
# 导出Excel df.style.to_excel('gairuo.xlsx') # 使用指定引擎 df.style.to_excel('gairuo.xlsx', engine='openpyxl') # 指定标签页名称,sheet name dfs.to_excel('gairuo.xlsx', sheet_name='Sheet1') # 指定缺失值的处理方式 dfs.to_excel('gairuo.xlsx', na_rep='-') # 浮点数字格式,下例将0.1234转为0.12 dfs.to_excel('gairuo.xlsx', float_format="%.2f") # 只要这两列 dfs.to_excel('gairuo.xlsx', columns=['Q1', 'Q2']) # 不带表头 dfs.to_excel('gairuo.xlsx', header=False) # 不带索引 dfs.to_excel('gairuo.xlsx', index=False) # 指定索引,多个值代表多层索引 dfs.to_excel('gairuo.xlsx', index_label=['team', 'name']) # 从哪行取,从哪列取 dfs.to_excel('gairuo.xlsx', startrow=10, startcol=3) # 不合并单元格 dfs.to_excel('gairuo.xlsx', merge_cells=False) # 指定编码格式 dfs.to_excel('gairuo.xlsx', encoding='utf-8') # 无穷大表示法(Excel中没有无穷大的本机表示法) dfs.to_excel('gairuo.xlsx', inf_rep='inf') # 在错误日志中显示更多信息 dfs.to_excel('gairuo.xlsx', verbose=True) # 指定要冻结的最底行和最右列 dfs.to_excel('gairuo.xlsx', freeze_panes=(0,2))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
生成html
可用于发邮件
Styler.render()可以输出样式的HTML代码
如果是邮件正文输出表格,一般不用展示index,如果想隐藏index,可使用:df.style.hide_index()

在Jupyter Notebook中,为了得到更好的浏览体验,可以用IPython来展示生成的HTML效果:
# 在Jupyter Notebook中可以用IPython来展示生成的HTML
from IPython.display import HTML
HTML(df.style.render())
- 1
- 2
- 3
链式表达
多段逻辑用小括号括起来,后面加上注释,代码整体可读性会好很多
(
pd.read_csv(file_path)
.query("sales>100")
.groupby('group')
.agg(
'id':'count',
'sales':'sum'
)
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
参考:
《深入浅出Pandas》 - 李庆辉
《从零开始学数据分析与挖掘》 - 刘顺祥
pandas官方文档:http://pandas.pydata.org/pandas-docs/stable/
转载请注明出处

