
热门标签
热门文章
- 12024/1/30 dfs与bfs
- 2万界星空科技电子制造业MES系统解决方案
- 3uniapp—实现长按保存图片的功能_uniapp中h5长按图片保存
- 4【UnityTileMap缝隙问题】完美解决方案_unity tilemap 缝隙
- 5S32K CANFD MailboxFilters Driver(no SDK)_s32k can fifo driver(no sdk)
- 6更改由PLSQL发布的WEBSERVICE_ebs soa 怎样取消部署
- 7博睿数据率先发布HarmonyOS NEXT系统的应用异常观测SDK_harmonyos next app
- 8获取数据Proxy下的Target的数据_proxy target
- 9Kafka原理详解(生产者、消费者、Broker、消息不丢失配置)_kafka-producer-network-thread 什么时候创建
- 10python:pyecharts地图功能,并解决显示不全或只显示南海诸岛问题解决_python使用map绘制地图时只显示部分区域
当前位置: article > 正文
pytorch pso优化cnn-lstm 智慧海洋-渔船轨迹识别_pso-cnn-lstm
作者:花生_TL007 | 2024-02-18 17:32:03
赞
踩
pso-cnn-lstm
1、摘要
本文主要讲解:pytorch pso优化cnn-lstm 智慧海洋-渔船轨迹识别
主要思路:
- 根据经纬度和时间序列创建时序块
- 数据集随机分成训练和测试
- 定义PSO Parameters(粒子数量、 惯性权重)、LSTM Parameters、搜索维度和粒子的位置和速度等定义、所有粒子的位置和速度、个体经历的最佳位置和全局最佳位置、每个个体的历史最佳适应值
- 开始搜索、初始粒子适应度计算、计算适应值、更新个体最优、更新全局最优
- 训练模型 使用PSO找到的最好的神经元个数
2、数据介绍
赛题与数据
train_chusai.csv为我处理好的数据,如有需要请私聊
3、相关技术
1、基于滑动窗口和LSTM自动编码器的渔船作业类型识别
2、TOP1解决方案
3、基于滑动窗口和PSO-CNN-LSTM的渔船轨迹识别
PSO优化LSTM介绍
4、完整代码和步骤
代码输出如下:
主运行程序入口
import random
import time
import matplotlib.pyplot as plt
import numpy as np
import torch
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from torch import nn
from torch.utils.data import TensorDataset
from sklearn.metrics import classification_report, accuracy_score
torch.manual_seed(1) # reproducible
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Hyper Parameters
EPOCH = 122 # train the training data n times, to save time, we just train 1 epoch
LR = 0.001 # learning rate
num_layers = 2
hidden_size = 256
import os
import pandas as pd
os.chdir(r'C:\Projects')
label_dict1 = {'拖网': 0, '围网': 1, '刺网': 2}
label_dict2 = {0: '拖网', 1: '围网', 2: '刺网'}
name_dict = {'渔船ID': 'id', '速度': 'v', '方向': 'dir', 'type': 'label', 'lat': 'x', 'lon': 'y'}
train = pd.read_csv('train_chusai.csv')
# train_chusai = pd.read_csv('train_chusai.csv')
train.rename(columns=name_dict, inplace=True)
# train_chusai.rename(columns=name_dict, inplace=True)
df = train
df['x'] = df['x'] * 100000 - 5630000
df['y'] = df['y'] * 110000 + 2530000
# df = pd.concat([train_chusai, df], axis=0, ignore_index=True)
df = df.drop(['time'], axis=1)
df['label'] = df['label'].map(label_dict1)
X_train = df.iloc[:, :-1]
y_train = df.iloc[:, -1]
INPUT_SIZE = X_train.shape[1] # rnn input size
x_MinMax = preprocessing.MinMaxScaler()
x = x_MinMax.fit_transform(X_train.values)
x = pd.DataFrame(x, columns=['id', 'x', 'y', 'v', 'dir'])
df = pd.concat([x, y_train], axis=1, ignore_index=True)
df.columns = ['id', 'x', 'y', 'v', 'dir', 'label']
# 创建时序块
groups = df.groupby(['id'])
x_train3 = np.zeros(shape=(1, 300, 4))
y_train = []
for name, group in groups:
group_nd = group.iloc[:300, 1:-1].values
if group_nd.shape[0] == 300:
group_nd = group_nd.reshape((1, 300, 4))
x_train3 = np.append(x_train3, group_nd, axis=0)
y_train.append(group.iloc[0, -1])
x_train3_nd = x_train3[1:]
y_train = np.array(y_train)
# 数据集随机分成训练和测试
X_train, X_test, y_train, y_test = train_test_split(x_train3_nd, y_train, test_size=0.2, shuffle=True)
train_data1 = torch.FloatTensor(X_train)
X_test = torch.FloatTensor(X_test)
y = np.eye(3)[y_train]
train_labels = torch.tensor(y).long()
y_test = np.eye(3)[y_test]
train_data, test_x, test_y = TensorDataset(train_data1, train_labels), X_test, y_test
test_x = test_x.to(device)
X_train = train_data1.to(device)
class CNN_LSTM(nn.Module):
def __init__(self, hidden_size, num_layers):
super(CNN_LSTM, self).__init__()
lstm_units = hidden_size
self.conv1d = nn.Conv1d(4, lstm_units, 1)
self.act1 = nn.Sigmoid()
self.maxPool = nn.MaxPool1d(kernel_size=4)
self.drop = nn.Dropout(p=0.01)
self.lstm = nn.LSTM(lstm_units, lstm_units, batch_first=True, num_layers=num_layers, bidirectional=True)
self.act2 = nn.Tanh()
self.cls = nn.Linear(lstm_units * 2, 3)
def forward(self, x):
x = x.transpose(-1, -2) # tf和torch纬度有点不一样
x = self.conv1d(x) # in: bs, dim, window out: bs, lstm_units, window
x = self.act1(x)
x = self.maxPool(x) # bs, lstm_units, 1
x = self.drop(x)
x = x.transpose(-1, -2) # bs, 1, lstm_units
x, (_, _) = self.lstm(x) # bs, 1, 2*lstm_units
x = self.act2(x)
x = x.squeeze(dim=1) # bs, 2*lstm_units
x = self.cls(x)
return x
def training(X):
hidden_size = int(X[0])
num_layers = int(X[1])
LR = round(X[2], 6)
batch_size = int(X[3])
EPOCH = int(X[4])
print([hidden_size, num_layers, LR, batch_size, EPOCH])
lstm_model = CNN_LSTM(hidden_size, num_layers).to(device)
optimizer = torch.optim.AdamW(lstm_model.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss().to(device) # the target label is not one-hotted
# Data Loader for easy mini-batch return in training
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True, pin_memory=True,
sampler=None)
# training and testing
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader): # gives batch data
# b_x = b_x.view(-1, 1, INPUT_SIZE) # reshape x to (batch, time_step, input_size)
b_x = b_x.to(device)
b_y = b_y.to(device)
# b_x = b_x.unsqueeze(1)
output = lstm_model(b_x) # rnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
test_output = lstm_model(test_x) # (samples, time_step, input_size)
pred_y = torch.max(test_output, 1)[1].data.cpu().numpy()
accuracy = float((pred_y == test_y).astype(int).sum()) / float(test_y.size)
print('accuracy:', accuracy)
return accuracy
# (1) PSO Parameters
MAX_EPISODES = 10
MAX_EP_STEPS = 10
c1 = 2
c2 = 2
pN = 10 # 粒子数量
w_start = 0.9 # 惯性权重
w_end = 0.1
t1 = time.time()
# (2) LSTM Parameters
'''
hidden_size = int(X[0])
num_layers = int(X[1])
LR = round(X[2], 6)
batch_size = int(X[3])
EPOCH = int(X[4])
'''
UP = [222, 4, 0.014, 18, 126]
DOWN = [50, 1, 0.0001, 6, 25]
# [234, 4, 0.001411, 39, 65]
# accuracy: 0.894124847001224
# (3) 搜索维度和粒子的位置和速度等定义
dim = len(UP) # 搜索维度
X = np.zeros((pN, dim)) # 所有粒子的位置和速度
V = np.zeros((pN, dim))
pbest = np.zeros((pN, dim)) # 个体经历的最佳位置和全局最佳位置
gbest = np.zeros(dim)
p_fit = np.zeros(pN) # 每个个体的历史最佳适应值
sum_epochs = MAX_EP_STEPS * MAX_EPISODES * pN + pN * MAX_EPISODES
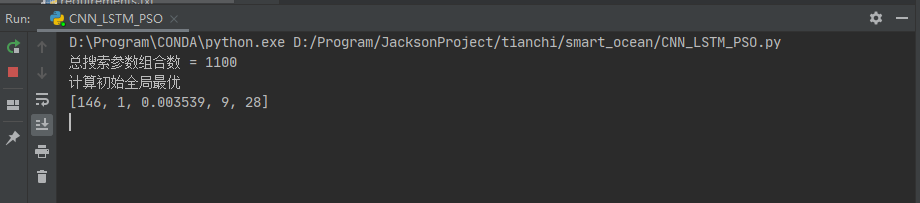
print('总搜索参数组合数 =', sum_epochs)
# (4) 开始搜索
for i_episode in range(MAX_EPISODES):
"""初始化s"""
random.seed(8)
fit = 0.6 # 全局最佳适应值
# 初始粒子适应度计算
print("计算初始全局最优")
for i in range(pN):
for j in range(dim):
V[i][j] = random.uniform(0, 1)
if j in [2]:
X[i][j] = random.uniform(DOWN[j], UP[j])
else:
X[i][j] = round(random.randint(DOWN[j], UP[j]))
pbest[i] = X[i]
# 计算适应值
tmp = training(X[i])
NN = 1
p_fit[i] = tmp
if tmp > fit:
fit = tmp
gbest = X[i]
print("初始全局最优参数:{:}".format(gbest))
fitness = [] # 适应度函数
for j in range(MAX_EP_STEPS):
for i in range(pN):
temp = training(X[i])
if temp > p_fit[i]: # 更新个体最优
p_fit[i] = temp
pbest[i] = X[i]
if p_fit[i] > fit: # 更新全局最优
gbest = X[i]
fit = p_fit[i]
for i in range(pN):
w = w_start - (w_start - w_end) * (2 * (i / pN) - (i / pN) ** 2) # 修改后的惯性权重表达式
V[i] = w * V[i] + c1 * random.uniform(0, 1) * (pbest[i] - X[i]) + c2 * random.uniform(0, 1) * (
gbest - X[i])
ww = 1
for k in range(dim):
if DOWN[k] < X[i][k] + V[i][k] < UP[k]:
continue
else:
ww = 0
X[i] = X[i] + V[i] * ww
fitness.append(fit)
print("全局最优参数:{:}".format(gbest))
print("全局最佳适应值:{:}".format(fit))
print('Running time: ', time.time() - t1)
# 训练模型 使用PSO找到的最好的神经元个数
X = gbest
hidden_size = int(X[0])
num_layers = int(X[1])
LR = round(X[2], 6)
batch_size = int(X[3])
EPOCH = int(X[4])
# Data Loader for easy mini-batch return in training
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True, pin_memory=True,
sampler=None)
lstm_model = CNN_LSTM(hidden_size, num_layers).to(device)
print(lstm_model)
optimizer = torch.optim.AdamW(lstm_model.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
test_accs = []
train_accs = []
losss = []
# training and testing
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader): # gives batch data
b_x = b_x.to(device)
b_y = b_y.to(device)
output = lstm_model(b_x) # rnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
train_output = lstm_model(b_x) # (samples, time_step, input_size)
pred_train_y = torch.max(train_output, 1)[1].data.cpu().numpy()
train_y_pred = np.argmax(pred_train_y, axis=1)
train_y_real = torch.max(b_y, 1)[1].data.cpu().numpy()
# train_y_real = np.argmax(train_y_real, axis=1)
train_accuracy = accuracy_score(train_y_pred, train_y_real)
test_output = lstm_model(test_x) # (samples, time_step, input_size)
pred_y = torch.max(test_output, 1)[1].data.cpu().numpy()
test_accuracy = float((pred_y == test_y).astype(int).sum()) / float(test_y.size)
print('Epoch: ', epoch, '| train loss: %.4f' % loss.data.cpu().numpy (), '| test accuracy: %.3f' % test_accuracy)
losss.append(loss.data.cpu().numpy())
test_accs.append(test_accuracy)
train_accs.append(train_accuracy)
photo_path = 'C:\Projects\photo\\'
plt.plot(losss)
plt.title('LSTM_loss')
plt.ylabel('loss')
plt.xlabel('Epoch')
plt.legend(['train'], loc='best')
plt.savefig(photo_path + "LSTM_PSO_train_loss.png", dpi=500, bbox_inches='tight')
plt.show()
plt.plot(train_accs)
plt.plot(test_accs)
plt.title('accuracy')
plt.ylabel('accuracy')
plt.xlabel('Epoch')
plt.legend(['train', 'test'], loc='best')
plt.savefig(photo_path + "CNN_LSTM_PSO_val_accuracy.png", dpi=500, bbox_inches='tight')
plt.show()
print('accuracy:', max(test_accs))
cls_report = classification_report(y_true=test_y, y_pred=pred_y)
print(cls_report)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/109434?site
推荐阅读
相关标签

