
- 1jieba自定义词库分词并进行tfidf计算_jieba 计算自定义文本的tfidf
- 2瑞吉外卖项目 基于spring Boot+mybatis-plus开发 超详细笔记,有源码链接_瑞吉外卖是基于什么开发的
- 3例说数据结构&STL(一)——vector_vector属于什么数据结构
- 4Latex关系运算符_latex \@plus
- 5Zabbix6.2升级到6.4实操及遇到的问题_invalid params. invalid parameter "/": unexpected
- 6【备战面试】每日面试题打卡——Java基础篇
- 7用Bert进行文本分类_词向量模型bert实现文本分类
- 8UDP 的报文结构和注意事项
- 9激光SLAM:激光雷达运动畸变补偿--轮速里程计辅助方法_基于激光雷达的运动补偿方法
- 10Uplift 经典模型介绍
A/B Test 使用指南_怎么确定abtest两组是同一个目标人群
赞
踩
一、起源
AB测试的概念来源于医学的双盲实验。
AB Test借鉴了实验的思维,目标是为了归因。通俗来说,就是我们想把条件分开,明确的知道,哪种条件下,用户会买账。这就需要三个条件:有对照组,随机分配用户,且用户量足够。
最早的AB测试本身是起源于医学。当一个药剂被研发后,医学工作人员需要评估药剂的效果。一般就会选择两组用户(随机筛选的用户),构建实验组和对照组。用这两组用户来“试药”。也就是实验组用户给真的药剂,对照组用户给安慰剂,但是用户本身不知道自己是什么组,只有医生知道。之后,在后期的观察中,通过一些统计方法,验证效果的差异性是否显著,从而去校验药剂是否达到我们的预期效果。
这个就是最早期的医学“双盲实验”。互联网行业其实也差不多是这么用。我们需要确认的是,当前改版,是否有效果,也就是说,我们需要验证效果的“药剂”变成了一个“改版”。
互联网的AB Test,将web或者app界面或者流程,拆分为多个版本,在同一时间段里,分别让同质化的用户使用。之后收集相关的业务数据,最后评估出最好的版本,从而达到效果最大化。
从本质上来说,AB-Test是对某唯一变化的有效性进行测试的实验。
二、使用场景
AB测试也不是每种迭代或者改版都能用。一般来说,三种场景可以使用AB测试,三种场景不能使用AB测试。
2.1 适用场景
- 产品迭代:比如界面优化,功能增加,流程增加,这些都可以使用AB测试。因为我们是在原有基础上做一定更新迭代,可以直接使用AB测试。
- 算法优化:算法筛选,算法优化这些我们都可以使用AB测试来测试。因为我们也可以通过流量切分构造实验组和对照组来验证效果。
- 市场营销的部分场景:内容的筛选,时间的筛选,人群的筛选,我们也可以使用AB测试来实验验证效果。
2.2 不适用场景
- 变量不可控:比如我们业务有两个APP,我们想做一个策略,验证是否能够提高用户使用了A产品,再去使用B产品的概率。这种是不支持AB测试的,因为用户关闭一个APP后,非常多的不可控因素。
- 样本量较小:因为从统计学上来说,我们要验证一个数据是否有效,还是需要一定的样本量的。
- 全量投放:比如我们开了一个发布会,换了一个logo,这种全量投放,怎么做AB测试?你可以让用户不来参与发布会还是让用户不看到新logo?
三、步骤
一般来说,产品的优化迭代流程上分为三个阶段:
1、随着业务的发展,我们萌生了优化迭代的思考和想法,并落地成为具体的PRD(产品需求文档)或者其他需求文档;
2、有了需求文档,我们需要将需求开发生产,然后上线验证实际效果是否符合预期;
3、如果效果符合预期,那么我们则落地实施,如果不符合预期,就再次优化迭代。
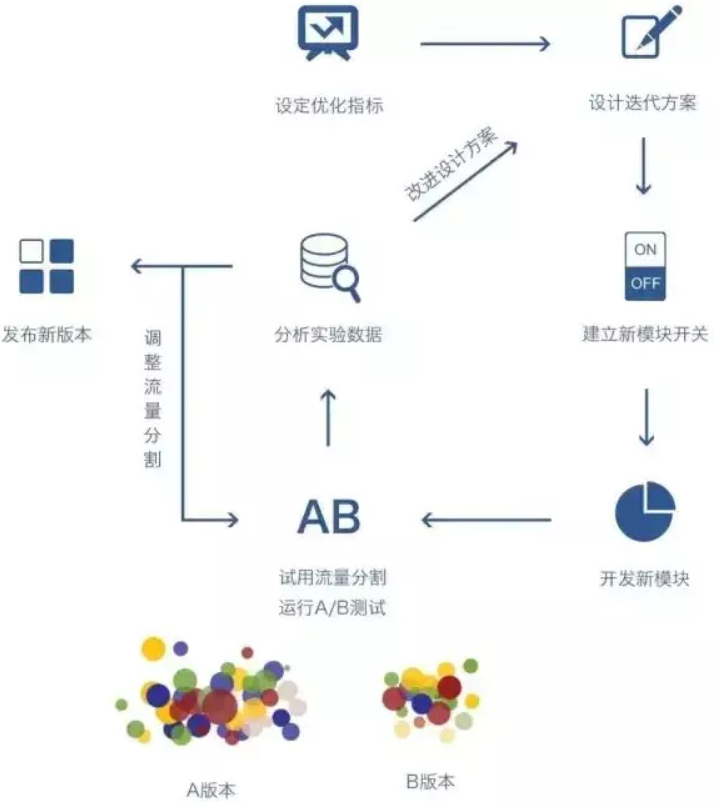
根据上图,我们把AB-Test拆分为实验前 + 实验中 + 实验后来大致讲解下实验的流程及步骤
3.1 实验前
1、设定项目目标:即本次AB测试的主体是什么,一个页面优化,一个app功能,一个文案修改?
2、本次测试的用户群体:是面对整体用户,还是部分用户?是需要分版本生效,还是全部生效?
3、预计会达到的目标:比如点击率,如预期10%上涨至15%,需要有个心理预期
4、计算样本量:根据预计效果,以及显著性水平,计算出所需样本量
5、计算流量分配比例:当计算出样本量后,我们需要根据当前流量,制定分流计划,是分群还是分层,或者同时进行
6、规划整理以上内容,进行AB测试前的文档落盘,方便实验后进行效果观测和实验结果评估
3.2 实验中
1、实验上线:根据事前设定的 测试功能,分流比例,投放人群进行线上AB测试
2、空白组确认:空白组,是否真的空白组,一定需要确认
3、AB生效确认:检验线上AB是否生效,以及AB测试是否按照计划比例分流
4、如果为了验证分流是否有效,及实验效果的显著性检验,我们在AB时,可以进行AA实验
3.3 实验后
1、实验有效性检测:判断实验是否达到最小样本量,从而能够以较大概率避免两个统计错误的发生(弃真错误 & 取伪错误)。一般情况下,通过AA实验的显著性差异检验,就能判断实验结果有效
2、实验效果比较:即通过对比AB实验下,实验组及基准组的区别,是否有显著差异,是否达到预期,从而判断后续迭代策略。
四、案例
举个例子:某社交APP增加了“看一看”功能,即用户之间可以查阅到对方所填写的一些基础信息。现在要分析该功能,是否有效果。
我们得到这个问题,需要脑子里想到AB测试的整体流程图(如下)。

从流程图中,我们需要想到几个问题:
1、实验前:如何选指标,如何做假设,如何选实验单位,根据实验指标和单位,如何计算最小样本量,以及实验的周期
2、实验中:需要验证是否所有用户仅处于同一个桶,还需要验证线上实验桶策略是否符合预期
3、实验后:需要回收数据,通过计算P值或者置信区间Diff的方法,校验该功能是否有效
从该功能来说,我们需要考虑的主要指标是用户之间建立联系的率值是否有提升。因为社交是为了让用户之间建立联系,增加这种查阅资料的功能,是为了让用户通过资料查阅,与感兴趣的用户建立联系。
所以该功能,我们的指标选择为加好友率。这时候,零假设就是该功能无效果,即两个桶的加好友率无明显差异。备选假设则相反。实验单位我们为了避免数据的不置信,我们选择以用户为实验单位。
假设我们的原有添加好友率如下 ,那么我们计算整体样本量如下:
P:45%,p:47%(由于波动范围是[44%,46%],所以至少是2.0%)
总样本量 = 16 * (45%*(1-45%)+ 47%*(1-47%))/ (47%-45%)^2 = 19864
由于实验桶和基线桶的比例是1:1,所以我们分配为实验桶1w样本,基线桶1w样本量。但是由于我们不能一上来就全量试验,所以我们开20%的流量为实验桶(假设DAU的20%是2000/天,即实验桶的DAU为2000/天),那么,我们预计要实验5天(1w/2000)。
但是通过计算,用户的一次活跃周期是7天,所以我们为了让实验效果可信度更高,计划实验7天。
实验上线后,我们对线上数据进行了验证,确认了以下两个问题:
1、实验策略在实验桶已生效,在基线桶未生效。即相关的看一看功能在实验桶已上线,基线桶保持原样;
2、同一个用户仅处在同一分桶中,未出现一个用户处于两个桶的情况。
实验到期后,我们对线上数据进行了回收。由于我们这个是相对值指标,所以我们使用Z检验。
检验方法有以下两种:
1、算P值,P值小于5%,拒绝原假设,即产品功能有效果。这个场景中(假设)P=0.002,即我们判断产品有效果。
2、算执行区间的差值,如果不含0,则拒绝零假设。同样,我们这里假设算出来期间不含0,我们认为该产品有效果。
以上,就是一个整体的AB实验案例。我们从筛选指标,到设计实验(选取实验单位,计算最小样本量,计算实验周期),到实验上线,再到后面的效果验证。
但是不知道大家注意没有,这个实验有些地方设计的并不合理。因为社交用户之间会有网络效应,即一个用户会影响另一个用户,所以我们实验分桶这么设计并不合理。
五、注意事项
除了知道怎么做之外,还需要准备一些冷知识备用。下面是做AB Test时的注意事项。
5.1 网络效应
这种情况通常出现在社交网络,以及共享经济场景(如滴滴)。举个例子:如果微信改动了某一个功能,这个功能让实验组用户更加活跃。但是相应的,实验组的用户的好友没有分配到实验组,而是对照组。但是,实验组用户更活跃(比如更频繁的发朋友圈),作为对照组的我们也就会经常去刷朋友圈,那相应的,对照组用户也受到了实验组用户的影响。本质上,对照组用户也就收到了新的功能的影响,那么AB实验就不再能很好的检测出相应的效果。
5.1.2 解决办法
从地理上区隔用户,这种情况适合滴滴这种能够从地理上区隔的产品,比如北京是实验组,上海是对照组,只要两个城市样本量相近即可。或者从用户上直接区隔,比如我们刚刚举的例子,我们按照用户的亲密关系区分为不同的分层,按照用户分层来做实验即可。但是这种方案比较复杂,建议能够从地理上区隔,就从地理上区隔。
5.2 学习效应
这种情况就类似,产品做了一个醒目的改版,比如将某个按钮颜色从暗色调成亮色。那相应的,很多用户刚刚看到,会有个新奇心里,去点击该按钮,导致按钮点击率在一段时间内上涨,但是长时间来看,点击率可能又会恢复到原有水平。反之,如果我们将亮色调成暗色,也有可能短时间内点击率下降,长时间内又恢复到原有水平。这就是学习效应。
5.2.1 解决办法
一个是拉长周期来看,我们不要一开始就去观察该指标,而是在一段时间后再去观察指标。通过刚刚的描述大家也知道,新奇效应会随着时间推移而消失。另一种办法是只看新用户,因为新用户不会有学习效应这个问题,毕竟新用户并不知道老版本是什么样子的。
5.3 多重检验问题
这个很好理解,就是如果我们在实验中,不断的检验指标是否有差异,会造成我们的结果不可信。也就是说,多次检验同一实验导致第一类错误概率上涨;同时检验多个分组导致第一类错误概率上涨。
举个例子:
出现第一类错误概率:P(A)=5%
检验了20遍:P(至少出现一次第一类错误)
=1-P(20次完全没有第一类错误)
=1- (1−5%) ^20
=64%
也就是说,当我们不断的去检验实验效果时,第一类错误的概率会直线上涨。所以我们在实验结束前,不要多次去观察指标,更不要观察指标有差异后,直接停止实验并下结论说该实验有效。
六、一些坑
6.1 用户属性一定要一致
如果上线一个实验,我们对年轻群体上线,年老群体不上线,实验后拿着效果来对比,即使数据显著性检验通过,那么,实验也是不可信的。因为AB测试的基础条件之一,就是实验用户的同质化。即实验用户群,和非实验用户群的 地域、性别、年龄等自然属性因素分布基本一致。
6.2 一定要在同一时间维度下做实验
举例:如果某一个招聘app,年前3月份对用户群A做了一个实验,年中7月份对用户群B做了同一个实验,结果7月份的效果明显较差,但是可能本身是由于周期性因素导致的。所以我们在实验时,一定要排除掉季节等因素。
6.3 一定要在同一时间维度下做实验
举例:如果某一个招聘app,年前3月份对用户群A做了一个实验,年中7月份对用户群B做了同一个实验,结果7月份的效果明显较差,但是可能本身是由于周期性因素导致的。所以我们在实验时,一定要排除掉季节等因素。
6.4 如果最小样本量不足该怎么办
如果我们计算出来,样本量需要很大,我们分配的比例已经很大,仍旧存在样本量不足的情况,那么我们只能通过拉长时间周期,通过累计样本量来进行比较
6.5 是否需要上线第一天就开始看效果
由于AB-Test,会影响到不同的用户群体,所以,我们在做AB测试时,尽量设定一个测试生效期,这个周期一般是用户的一个活跃间隔期。如招聘用户活跃间隔是7天,那么生效期为7天,如果是一个机酒app,用户活跃间隔是30天,那生效期为30天
6.6 用户是否生效
用户如果被分组后,未触发实验,我们需要排除这类用户。因为这类用户本身就不是AB该统计进入的用户(这种情况较少,如果有,那在做实验时打上生效标签即可)
6.7 用户不能同时处于多个组
如果用户同时属于多个组,那么,一个是会对用户造成误导(如每次使用,效果都不一样),一个是会对数据造成影响,我们不能确认及校验实验的效果及准确性
6.8 如果多个实验同时进行,一定要对用户分层+分组
比如,在推荐算法修改的一个实验中,我们还上线了一个UI优化的实验,那么我们需要将用户划分为4个组:A、老算法+老UI,B、老算法+新UI,C、新算法+老UI,D、新算法+新UI,因为只有这样,我们才能同时进行的两个实验的参与改动的元素,做数据上的评估
6.9 特殊情况(实际情况)
样本量计算这步,可能在部分公司不会使用,更多的是偏向经验值;
假设检验这一步,部分公司可能也不会使用;
大部分公司,都会有自己的AB平台,产运更偏向于平台上直接测试,最后在一段时间后查看指标差异。
对于这两种情况,我们需要计算不同流量分布下的指标波动数据,把相关自然波动下的阈值作为波动参考,这样能够大概率保证AB实验的严谨及可信度。
参考资料:
1.微信公众号(巡山猫说数据)-《A/B Test 方法、流程、案例、避坑完全指南!》

