
- 1Python中函数的参数定义和可变参数_python函数中的可变参数
- 2C++之最短路径算法(Dijkstra)_c++ 最短路径
- 3Android O 前期预研之二:HIDL相关介绍_export_generated_headers androidbp
- 4sqlserver 查询数据字段末尾存在空格 用等于号也会命中_sqlserver where 有空格和没空格
- 5已经会用stm32做各种小东西了,下一步学什么,研究stm32的内部吗?
- 6疲劳驾驶样本集_开车犯困怎么办?用TF机器学习制作疲劳检测系统
- 7Java实现WebSocket_java原生websocket的源码
- 8Android Studio中运行Android模拟器_android studio怎么运行模拟器
- 9android10.0(Q) 后台启动Activity白名单_background activity start [callingpackage:
- 10鸿蒙Harmony-数据持久化(Preferences)详解_鸿蒙preferences
B站:李宏毅2020机器学习笔记 4 —— 深度学习优化 Optimization for Deep Learning_bergman optimzation
赞
踩
总览学习目录篇 链接地址:https://blog.csdn.net/xczjy200888/article/details/124057616
B站:李宏毅2020机器学习笔记 4 —— 深度学习优化 Optimization for Deep Learning
一、深度学习的简单介绍
Deep = Many Hidden Layers
1. 深度学习的浮浮沉沉

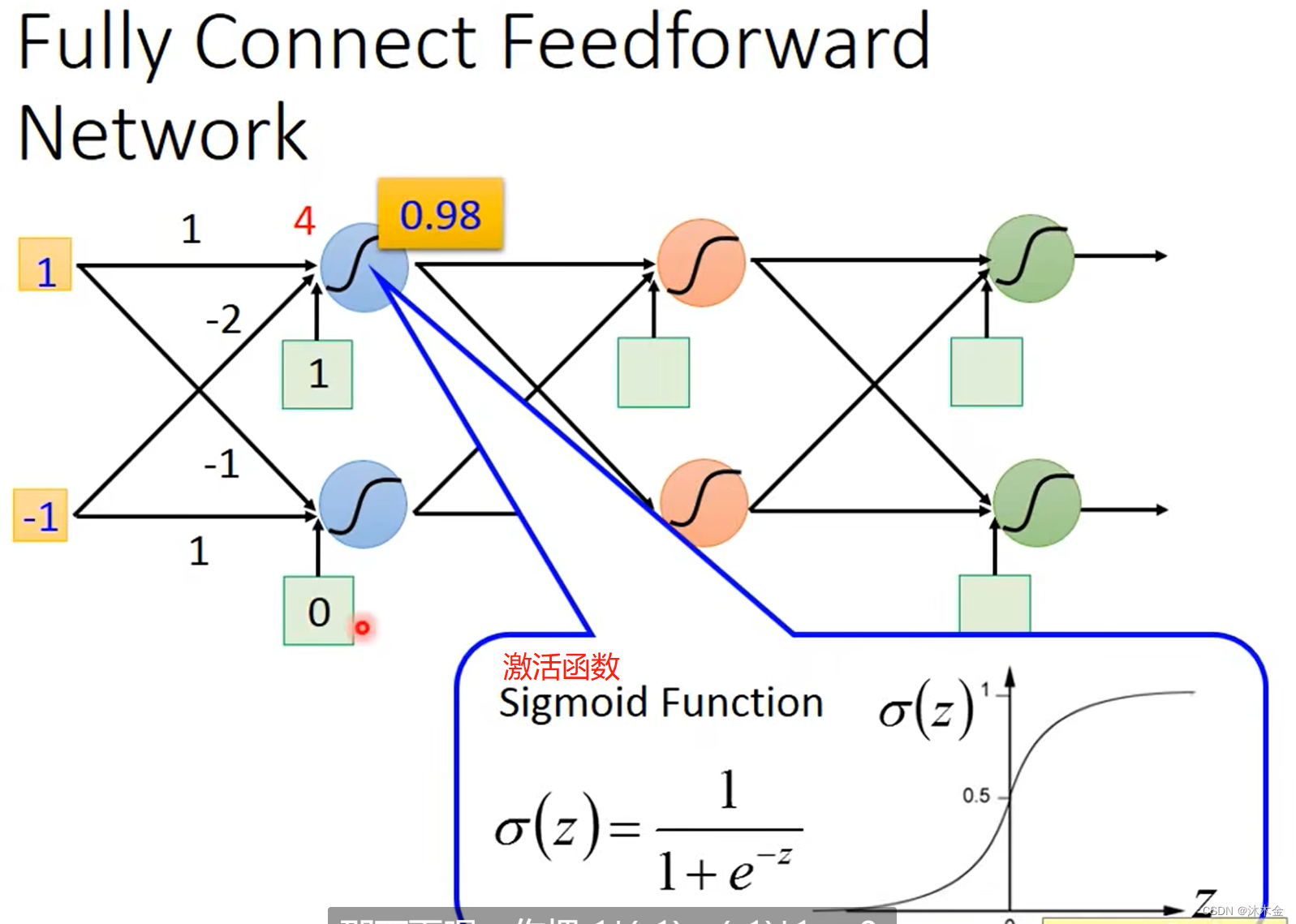
2. 全连接神经网络
z
=
w
x
+
b
i
a
s
=
1
×
1
+
(
−
1
)
×
(
−
2
)
+
1
=
4
z=wx+bias=1\times1+(-1)\times(-2)+1=4
z=wx+bias=1×1+(−1)×(−2)+1=4
σ
(
z
)
=
1
1
+
e
−
z
=
1
1
+
e
−
4
≈
0.98
\sigma(z)=\frac{1}{1+e^{-z}}=\frac{1}{1+e^{-4}} \approx 0.98
σ(z)=1+e−z1=1+e−41≈0.98
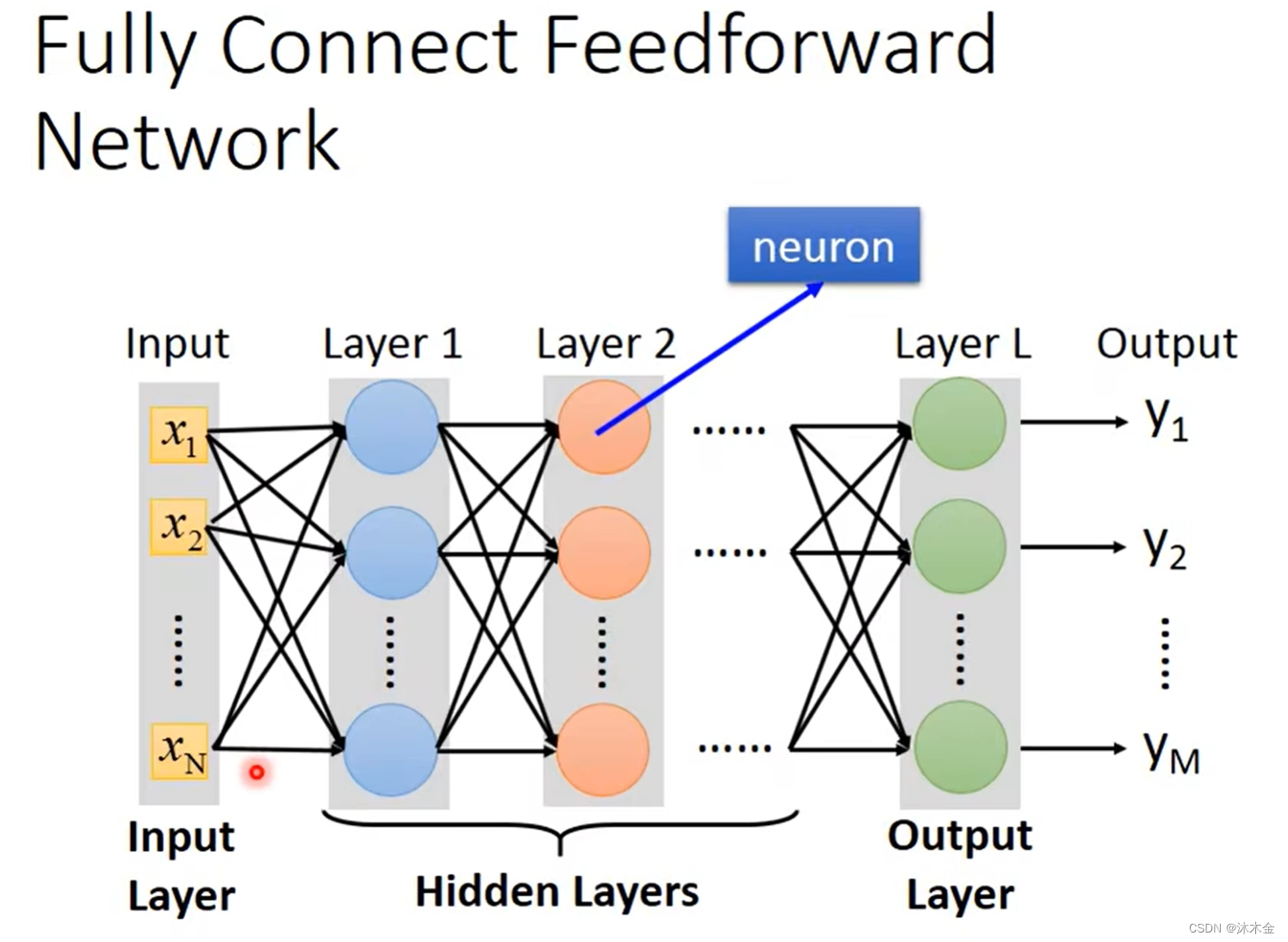
3. 矩阵操作
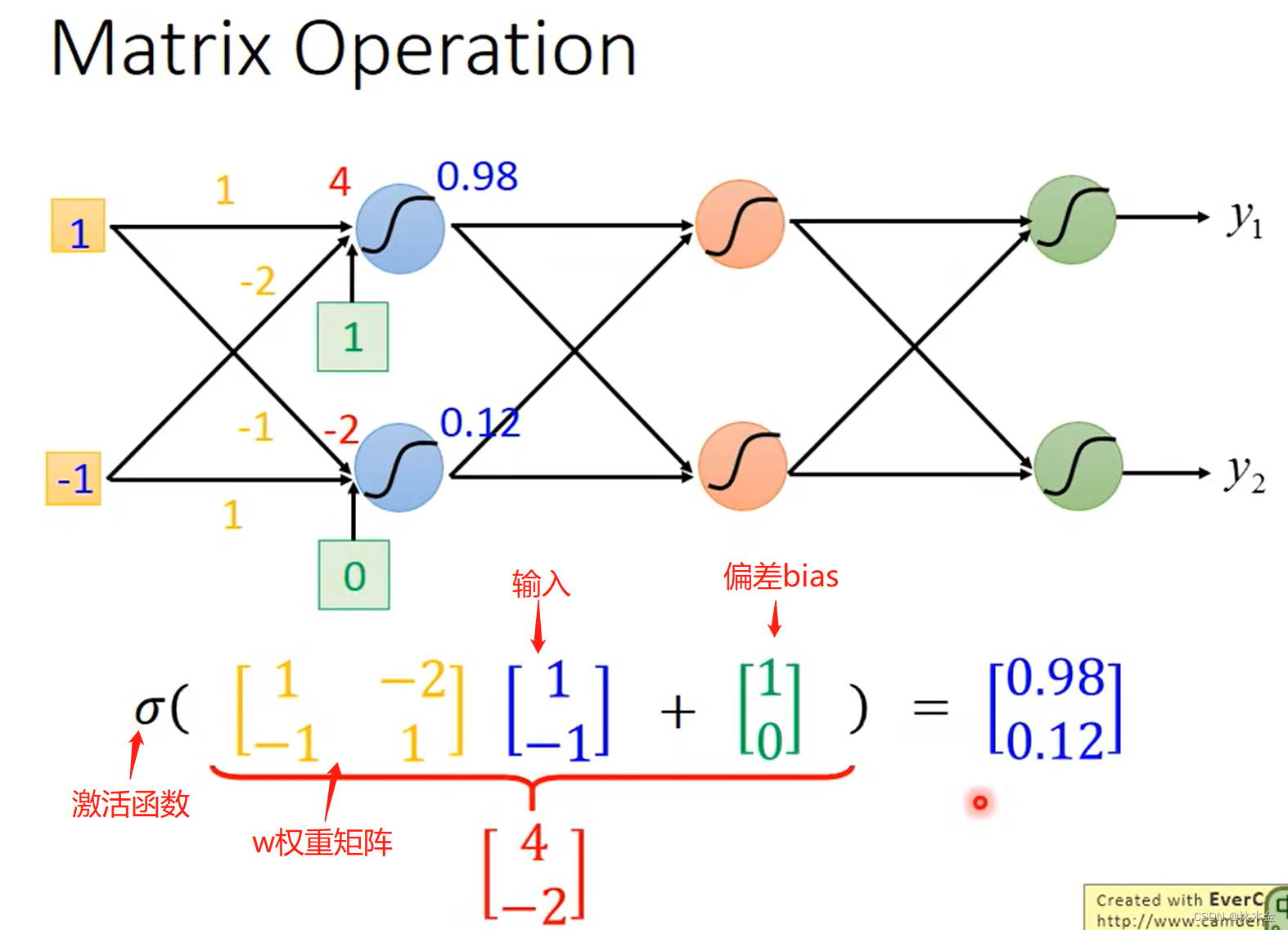
- 使用并行计算技术GPU来加速矩阵运算
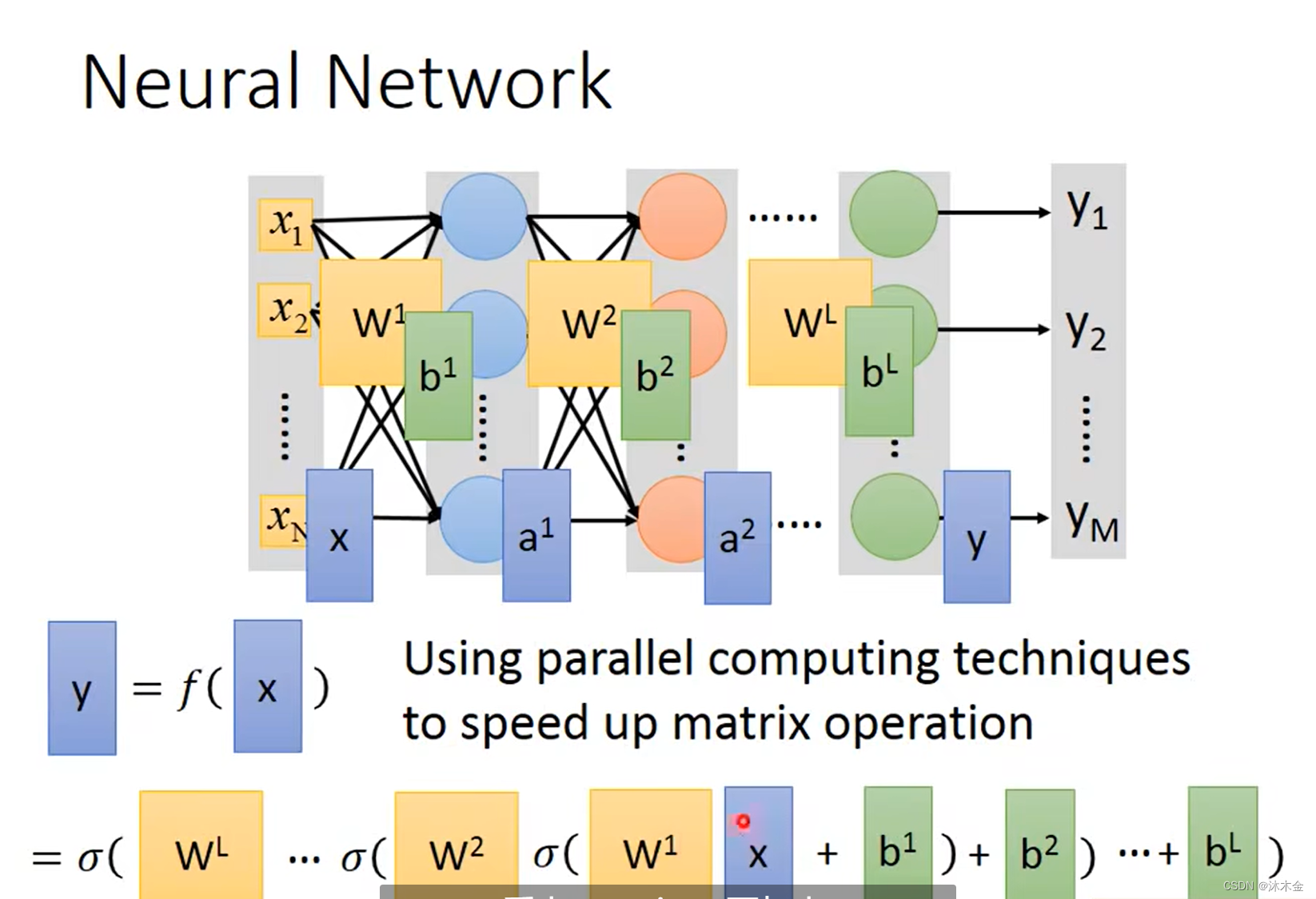
- 特征提取替代特征工程
- 把输出层看做一个多分类问题,那最后一层的激活函数使用softmax,而不是用sigmod
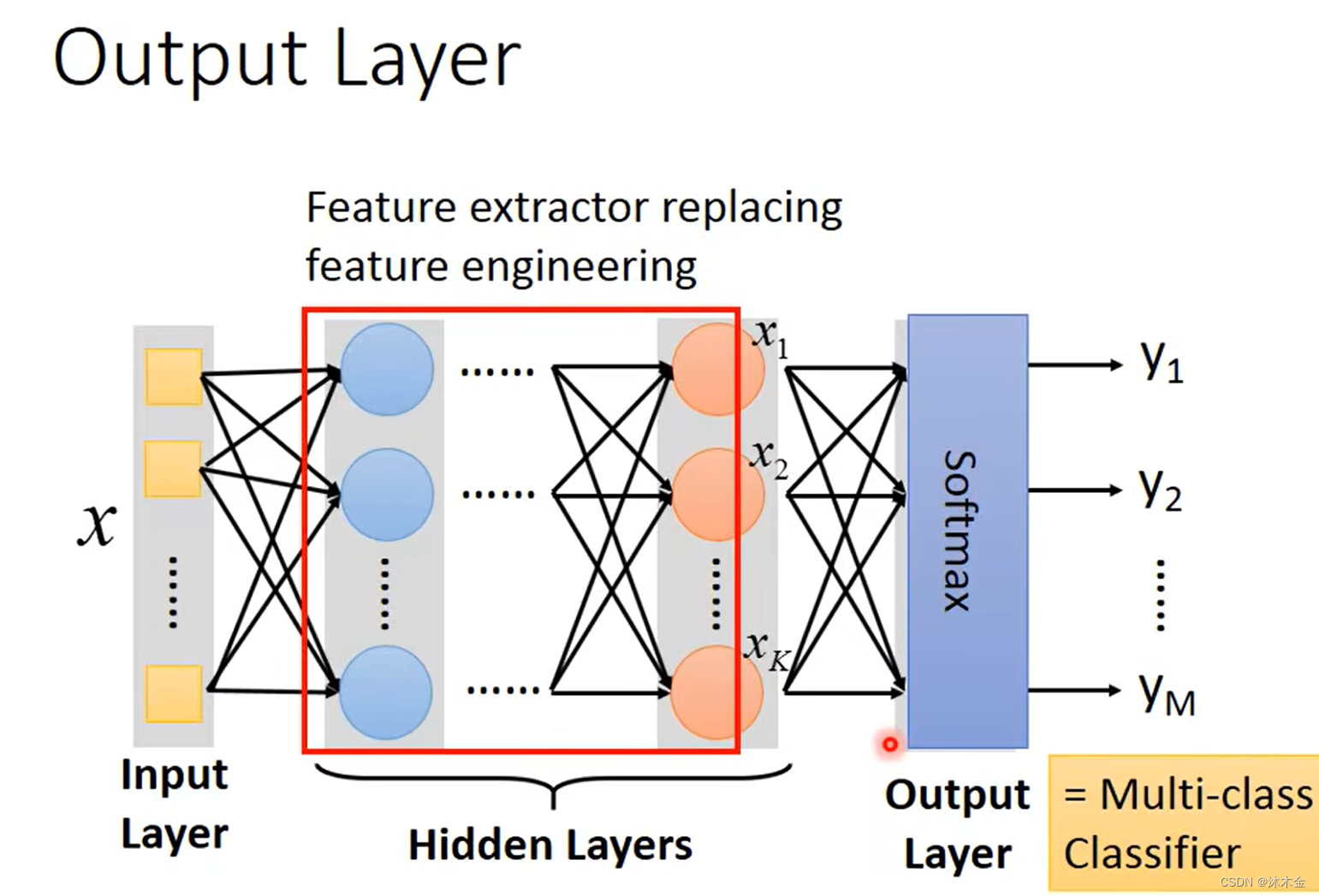
二、深度神经网络的技巧
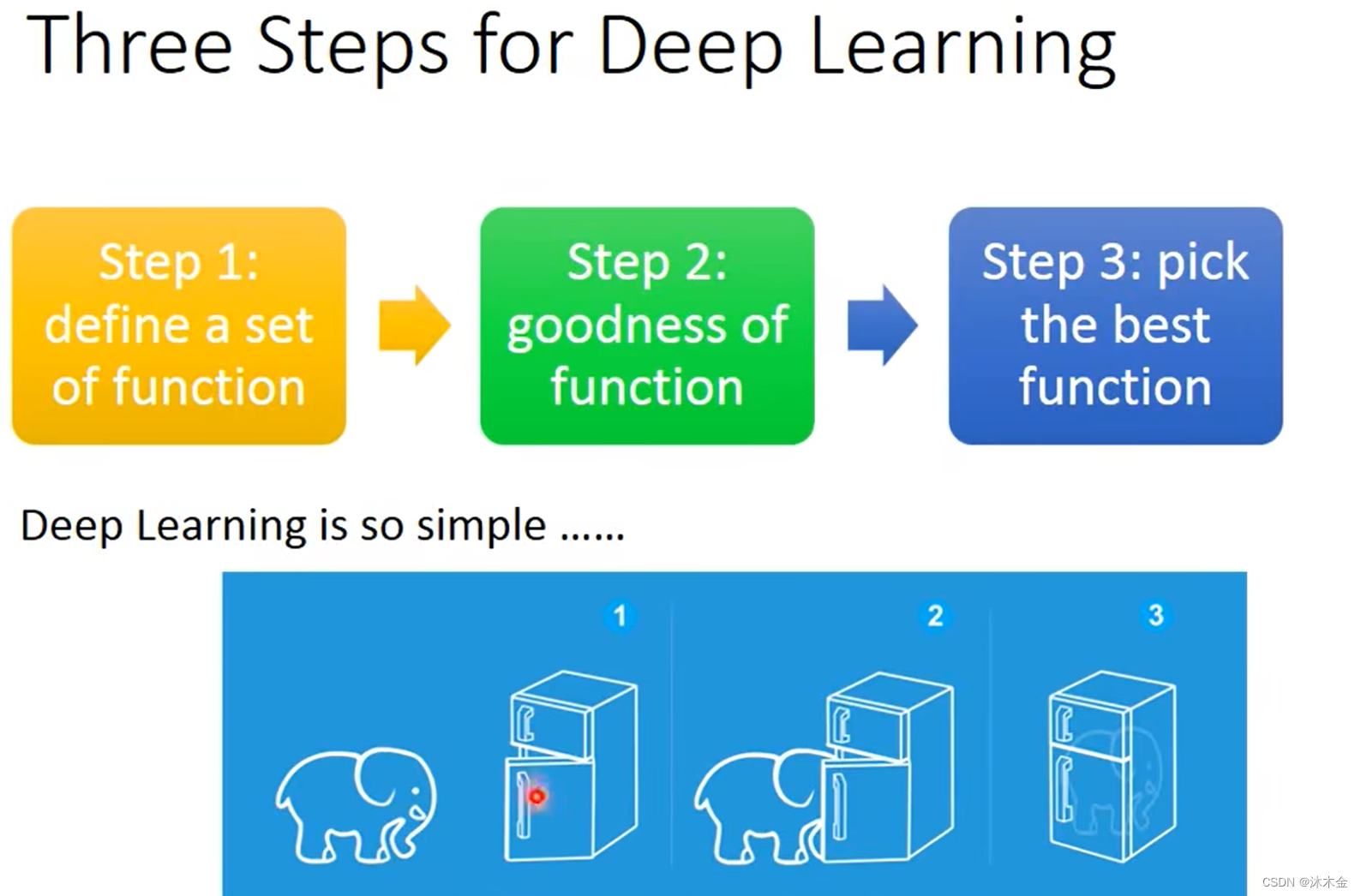
1. 深度学习的三个步骤
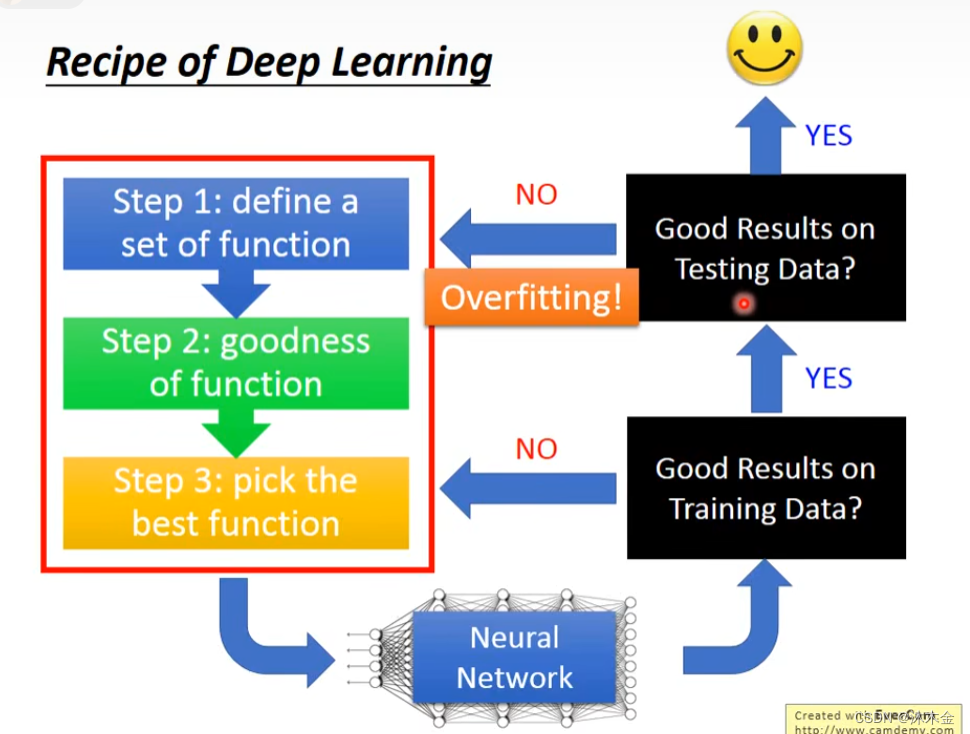
- 定义函数模型集合
- 判断每个函数模型的好坏
- 选择最好的函数模型
2. 过拟合/欠拟合
- 欠拟合:是指模型在训练集、验证集和测试集上均表现不佳的情况。
- 过拟合:是指模型在训练集上表现很好,到了验证和测试阶段就很差,即模型的泛化能力很差。
- 隐藏层越多,并不一定学习能力就越好。
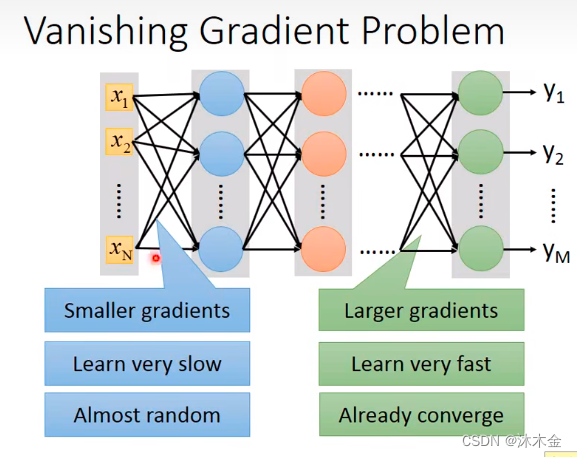
3. 梯度消失问题
- 梯度越小,学习越慢,几乎是随机的
- 梯度越大,学习越快,很快收敛
造成梯度消失的原因:
- 激活函数的影响
- 隐藏层过多
4. Maxout:可学习的激活函数
- 选用ReLU激活

- ReLU的变种:可学习的激活函数Maxout
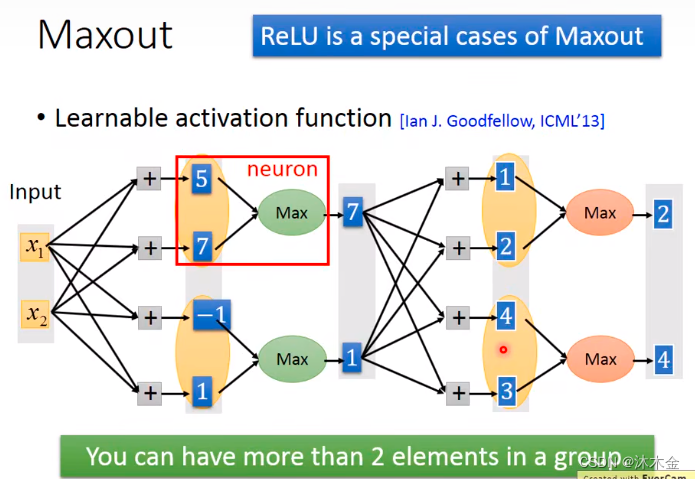
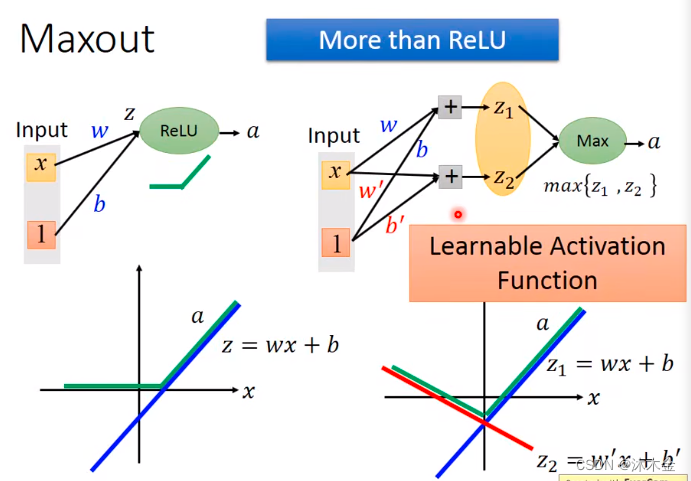
- 每个神经元经过取最大值的激活函数处理后,会根据权重值不同,输出发生变化。

如上图,针对
x
1
x_1
x1的输入,得到
z
1
1
>
z
2
1
z_1^1>z_2^1
z11>z21经过maxout激活之后,得到输出
a
1
1
a_1^1
a11。
z
1
1
z_1^1
z11和
a
1
1
a_1^1
a11之间存在线性关系。
不同的input值,max的值不同,输出值不同。
Maxout相关论文 Ian J. Goodfellow, David Warde-Farley, Mehdi Mirza, Aaron C. Courville, Yoshua Bengio: Maxout Networks. ICML (3) 2013: 1319-1327
5. 回顾
5.1 优化算法一:Adagrad
- Adagrad:通过参数来调整合适的学习率η,对稀疏参数进行大幅更新和对频繁参数进行小幅更新。因此,Adagrad方法非常适合处理稀疏数据。
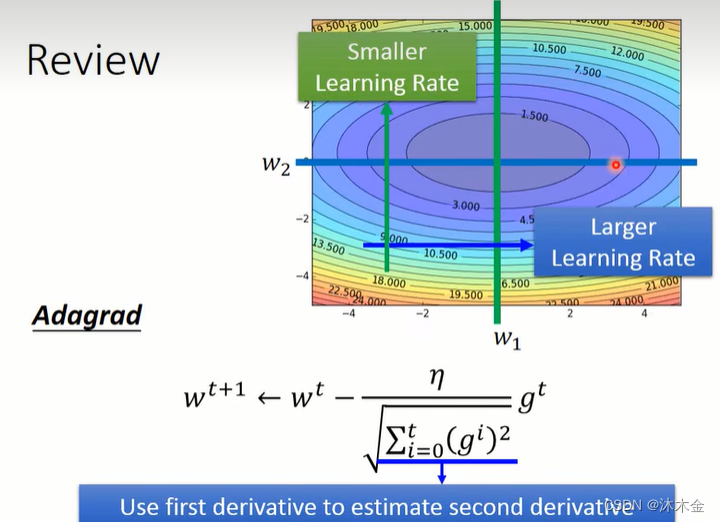
- AdaGrad的局限:可能会在搜索结束时导致每个参数的步长(学习率)非常小,这可能会大大减慢搜索进度,并且可能意味着无法找到最优值。
5.2 优化算法二:RMSProp
- RMSProp:Root Mean Square Propagation 是一种梯度下降优化算法

- RMSProp采用了指数加权移动平均(exponentially weighted moving average)。RMSProp比AdaGrad只多了一个超参数,其作用类似于动量(momentum),其值通常置为0.9
5.3 难以找到最优参数
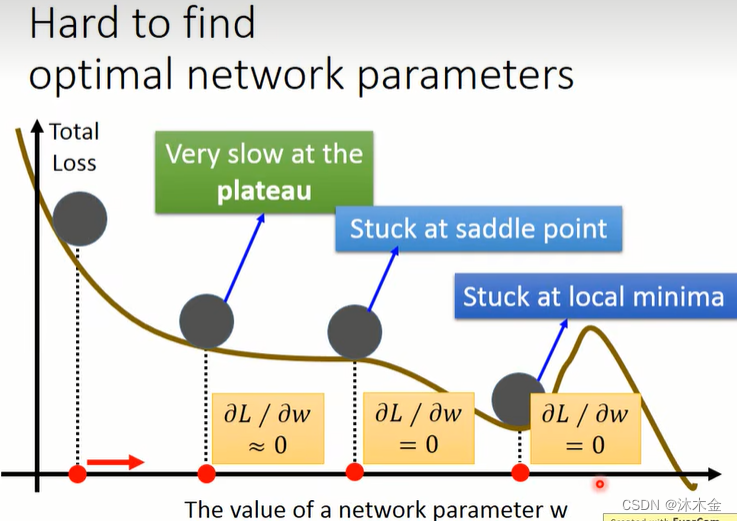
-
难以找到最优参数的原因:
- 在平稳阶段更新很慢
- 卡在鞍点
- 陷入局部极小值
-
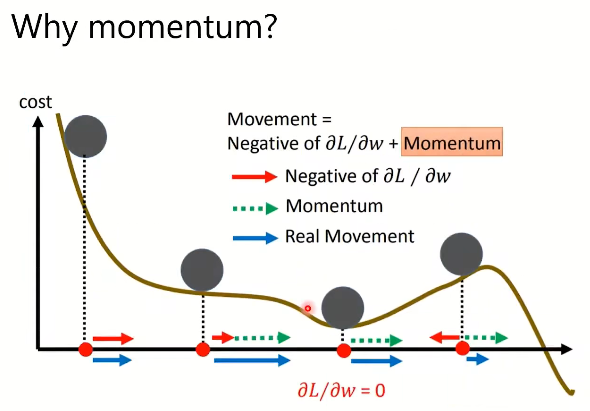
解决方案:引入动量momentum
下图第三个点,可能因为惯性,翻过小坡,达到一个更优的点。
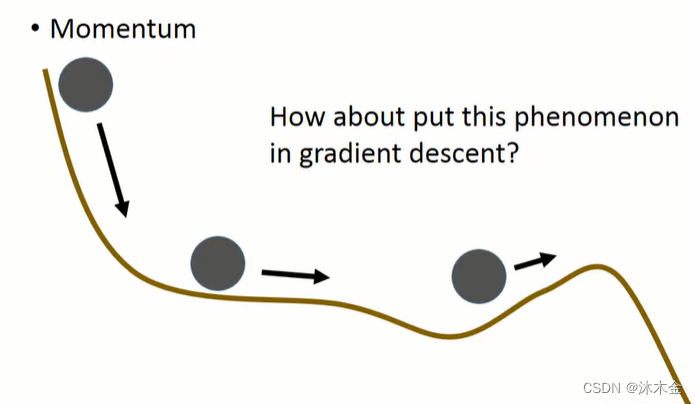
5.4 引入动量的梯度下降算法
-
引入动量前
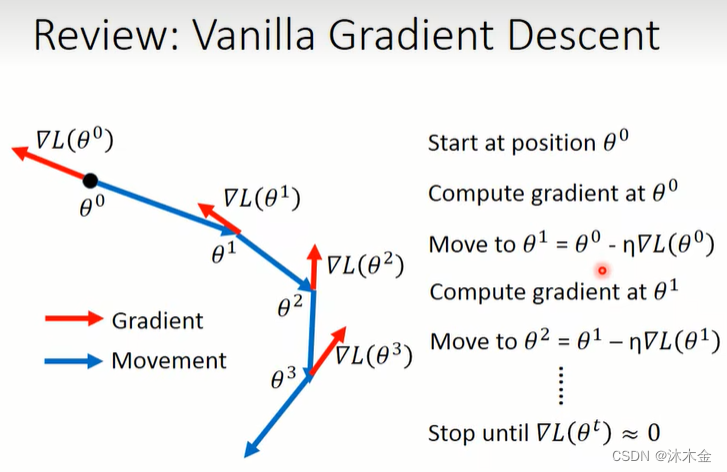
-
引入动量后
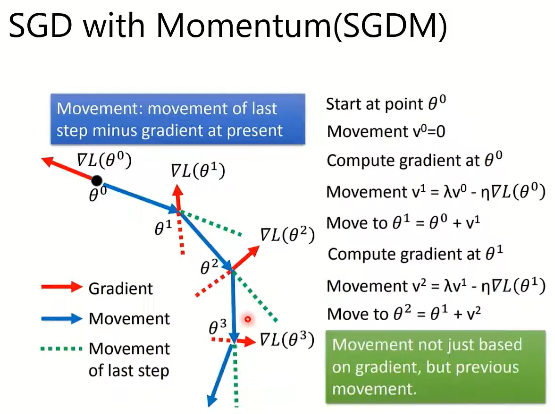
移动:最后一步的移动量减去当前的梯度(类似会受惯性的影响)
λ λ λ类似学习参数

上图,红色线为计算的梯度,蓝色的线会实际移动的方向,绿色虚线为上一步移动的方向,红色虚线为上一步梯度移动的方向。

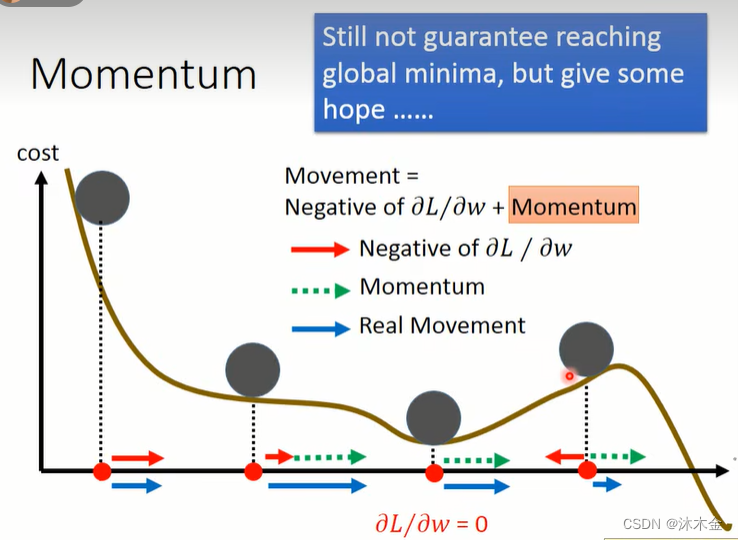
上图最后一个图,当动量不足时,不能完全保证达到全局最优,但是如果动量足够可以翻越小坡,给达到最优一个希望。
5.5 优化算法三:Adam

6. 深度学习的技巧
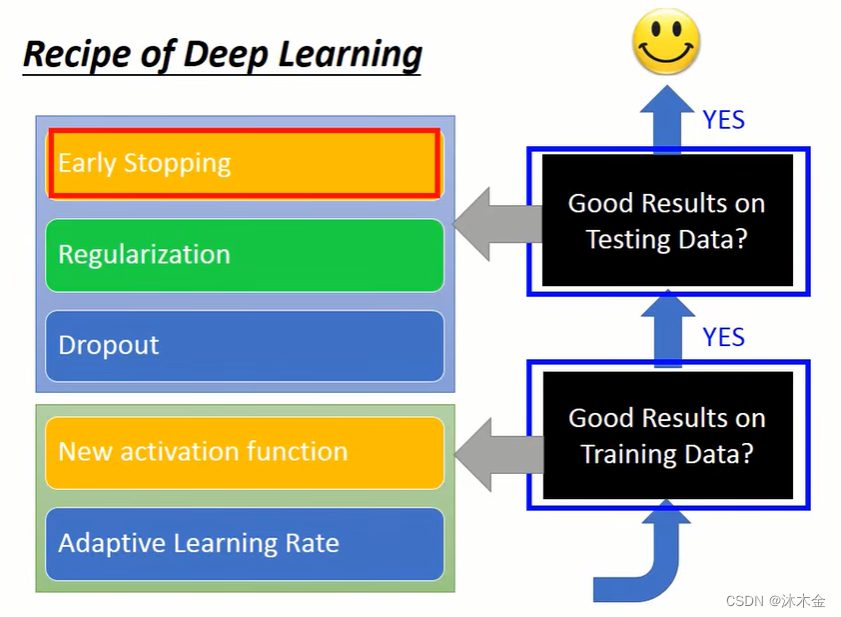
6.1 早停法 early stopping
理想的情况下,如果知道测试集的损失值变化,那么,当测试集的loss达到最低时就应该停止训练。
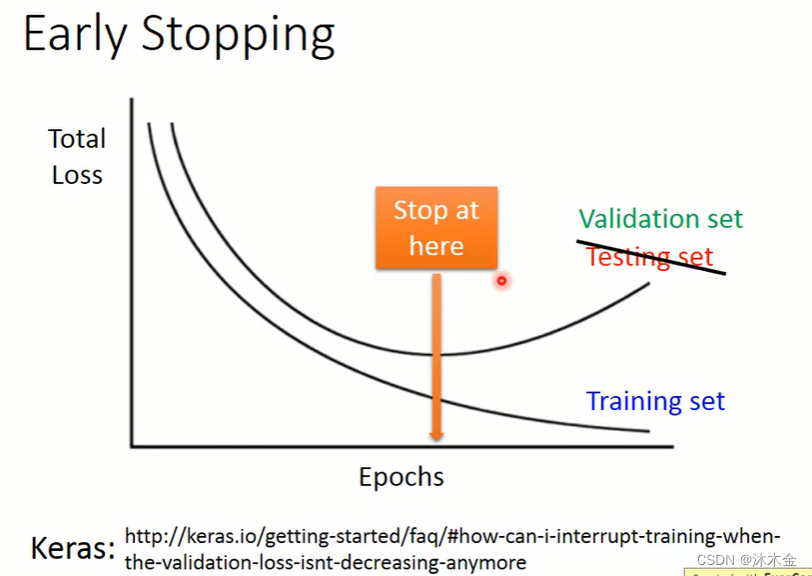
6.2 正则化 regularization
- 做正则化的时候,不考虑偏差bias
- 做正则化的目的,是让函数模型更平滑,bias和函数更平滑没有关系

L2正则化:因为 1 − η λ < 1 1-η λ<1 1−ηλ<1, 所以 ( 1 − η λ ) w t (1-η λ)w^t (1−ηλ)wt 会越来越接近0,造成参数衰退,值平均都比较小

L1正则化:有很多很大的值,有很多很小的值

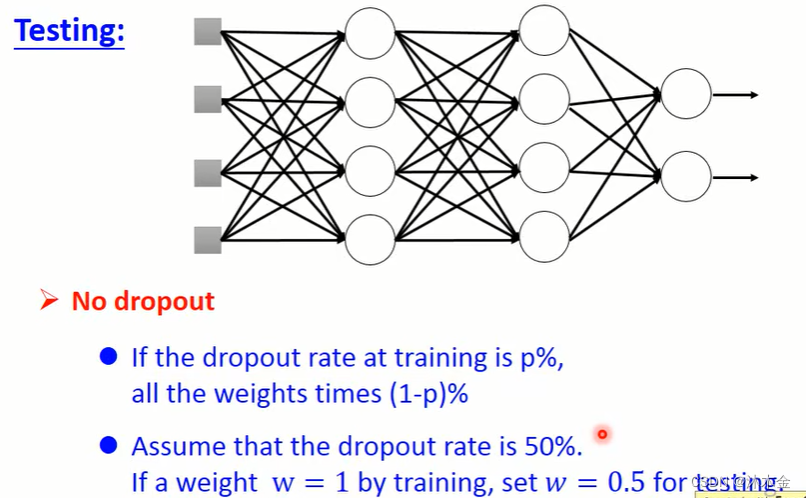
6.3 随机失活 dropout
随机失活dropout:将隐含层的部分权重或输出随机归零,降低节点间的相互依赖性,从而实现神经网络的正则化,降低其结构风险。
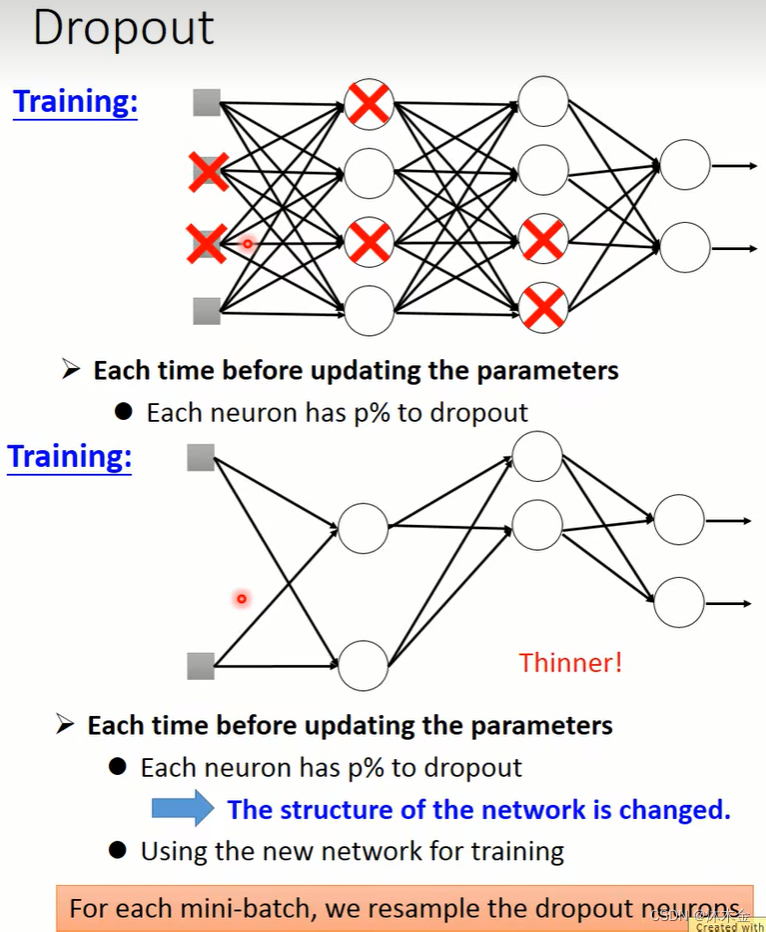
训练集:每个小批量数据mini-batch,都需要随机抽样需要失活的神经元。
6.4 新激活函数 new activation function
6.5 自适应学习率 adaptive learning rate
6.6 模组化 modularization
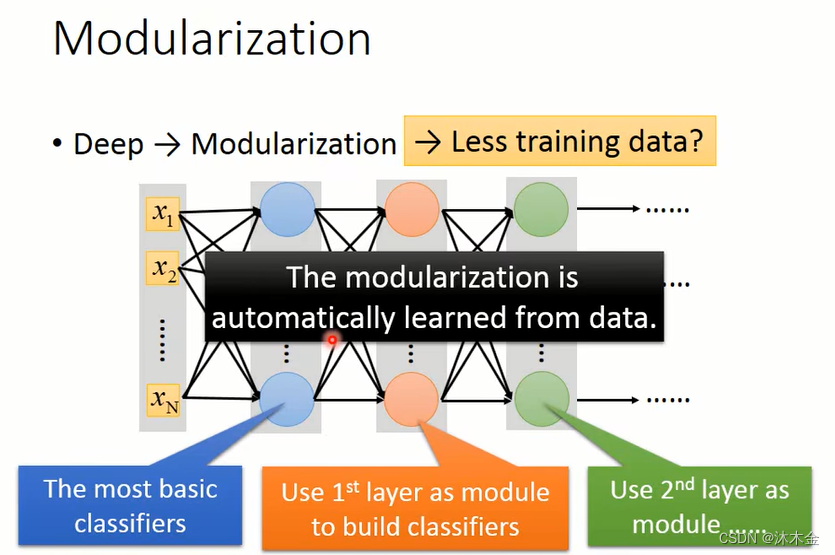
三、深度学习优化
1. 一些符号说明
- θ t θ_t θt:在step t t t时,模型的参数
- ∇ L ( θ t ) ∇L(θ_t) ∇L(θt)或者 g t g_t gt:参数值为 θ t θ_t θt时的梯度,被用来计算 θ t + 1 θ_{t+1} θt+1
- m t + 1 m_{t+1} mt+1:从step 0 0 0到step t t t的积累的势能,被用来计算 θ t + 1 θ_{t+1} θt+1
- 最优是什么?
- 找到一个 θ θ θ,得到最小的 ∑ x L ( θ ; x ) \sum_x{L(θ;x)} ∑xL(θ;x)
- 或找到一个 θ θ θ,得到最小的 L ( θ ) L(θ) L(θ)
2. On-line vs Off-line
- on-line:某个时间点一次放一个样本进模型里
- off-line:每个时间点一次性把所有样本放进模型里(着重介绍off-line)

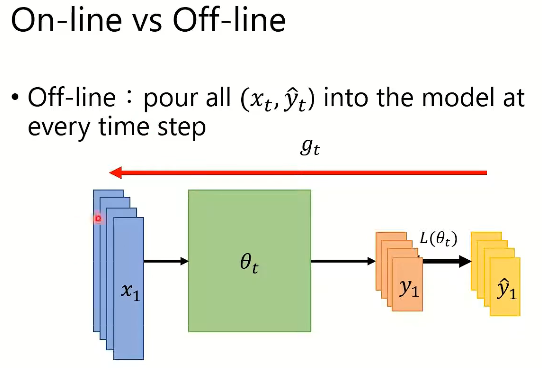
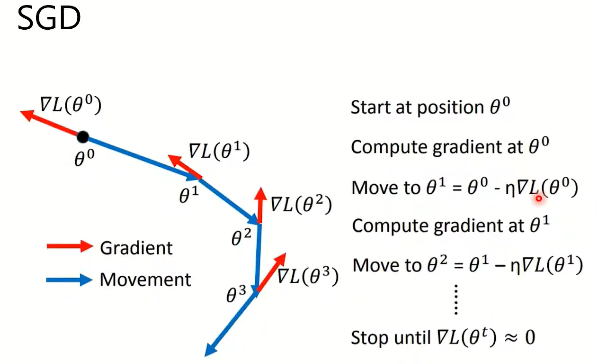
3. 梯度下降算法回顾
3.1. SGD(Stochastic Gradient Descent)随机梯度下降
- 朝梯度下降的方向优化
3.2. SGDM(SGD with Momentum)加入动量机制的随机梯度下降
- 动量不仅仅基于梯度,也基于之前的动量值

-
v
i
v^i
vi是之前所有梯度的加权和
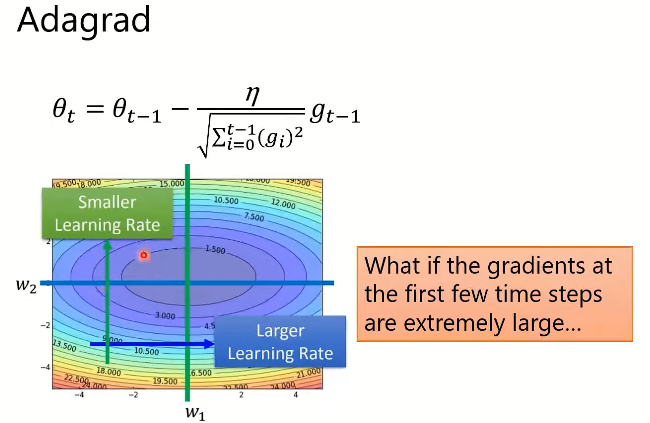
3.3. Adagrad 自适应梯度算法
- 如果过去的梯度很大, ∑ i = 0 t − 1 ( g i ) 2 \sqrt{\sum_{i=0}^{t-1}{(g_i)^2}} ∑i=0t−1(gi)2 就越小,后续优化更新就越缓
- 自适应梯度算法缺点:分母部分
∑
i
=
0
t
−
1
(
g
i
)
2
\sqrt{\sum_{i=0}^{t-1}{(g_i)^2}}
∑i=0t−1(gi)2
,如果梯度特别大,优化速度会越来越慢
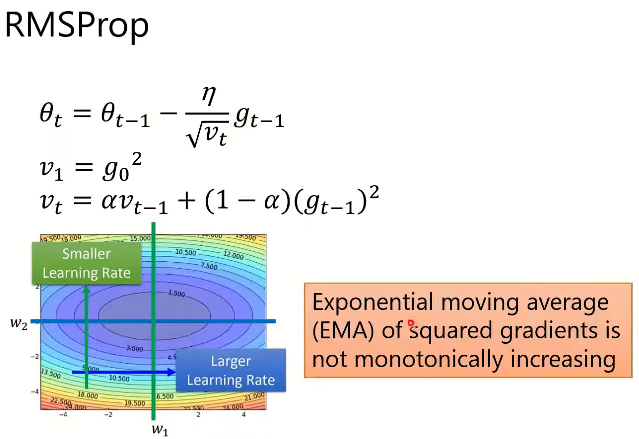
3.4. RMSProp(root mean square prop) 均方根传递
- 解决自适应梯度算法,随着时间,优化调整步伐越来越小的问题,平方梯度的指数移动平均值不是单调递增的
3.5. Adam梯度下降法
- Adam梯度下降法,结合了SGDM梯度下降法和RMSProp梯度下降法的方法
-
β
β
β是一个小于1的值,开始的时候
β
1
m
t
−
1
β_1m_{t-1}
β1mt−1很小,所以用一个
m
t
^
=
m
t
1
−
β
1
t
\hat{m_t}=\frac{m_t}{1-β_1^t}
mt^=1−β1tmt来让值稍大一点,稳定一些。随着时间的推移,
m
t
m_t
mt慢慢的稳定下来。

4. 真实场景应用
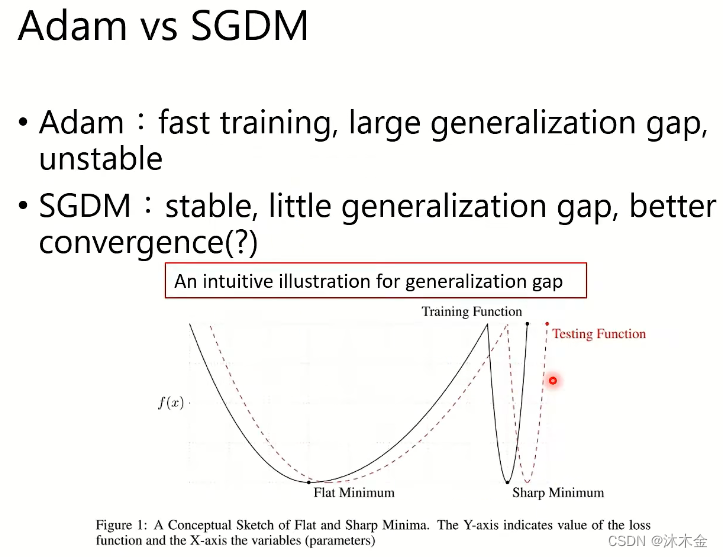
4.1. Adam和SGDM算法比较
- Adam和SGDM是表现较好且常用的两种梯度下降算法。
- 两者在不同场景,表现优劣不同。
- Adam:训练快,泛化差距大,不稳定
- SGDM:训练稳定,泛化差距小,收敛性更好
- 下图:泛化的直观意思是:
(Y 轴表示损失函数的值,X 轴表示变量参数)- flat是相对平稳的获取到的一个损失函数的最小值
- sharp是快速获取到一个损失函数的最小值
4.2. SWATS:Adam和SGDM算法结合
- 开始使用Adam,快速下降,后面用SGDM
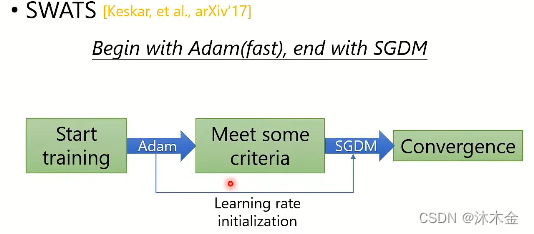
SWATS相关论文:Keskar N S , Socher R . Improving Generalization Performance by Switching from Adam to SGD[J]. 2017.
文中,切换两种梯度算法的中间节点没有细说。
4.3. 改进Adam
4.3.1 Adam存在的问题
- 在训练前期,大多数梯度很小且无信息,在训练的最后阶段,由于累计值影响较大,一些 mini-batch 提供大的信息但梯度更新较小。

- 一次更新的最大移动距离上限为
1
1
−
β
2
η
\sqrt{\frac{1}{1-β_2}η}
1−β21η
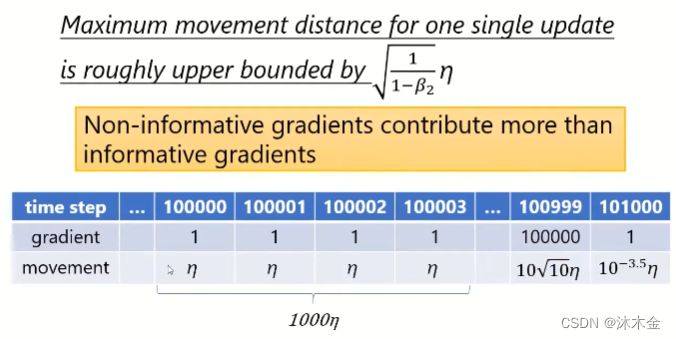
4.3.2 提出了AMSGrad(Dr.李认为直接取当前和累计的最大值不对) - 降低无信息数据对梯度影响
- 移除由于大操作造成的去偏
- 学习率单调递减

4.3.3 提出了AdaBound(Dr.李认为指定不同阶段学习率,不是自适应,太粗暴)

4.4. 改进SGDM
4.4.1 SGDM存在的问题
- 自适应学习率算法:随时间动态调整学习率
- 随机梯度下降SGD类型的算法:固定的学习率进行更新,小的学习率太慢,大的学习率效果不好

4.4.2 提出了Cyclical LR - learning rate学习率在大小大小周期性的进行变化
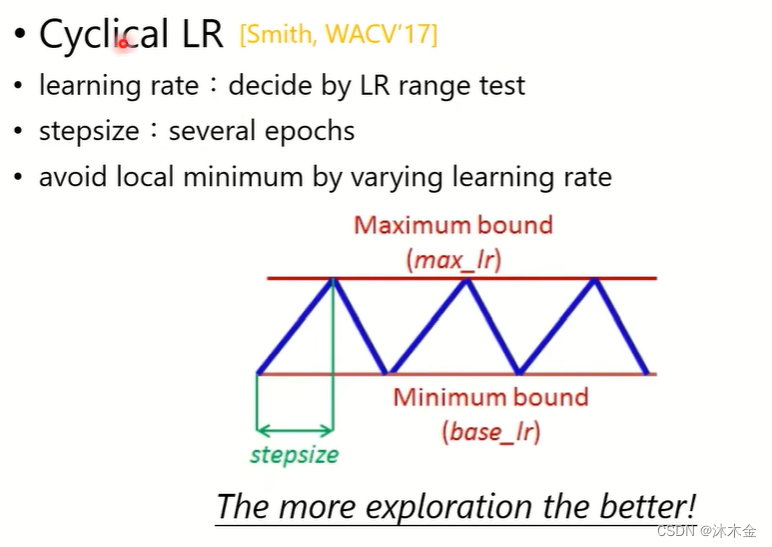
4.4.3 提出了SGDR - 用一个三角函数周期性的调整学习率
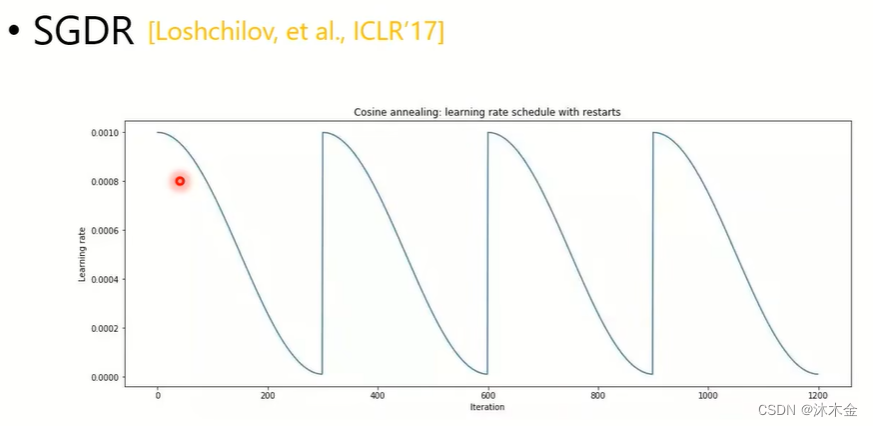
4.4.4 提出了One-cycle LR
- 单周期调整学习率
- 单周期分为三段,warm-up:学习率越来越高;anneling:学习率下降;fine-tuning:微调

4.5. Adam需要warm-up吗?
在优化选学(二)后续完成后继续…

