
热门标签
热门文章
- 1(神经网络)MNIST手写体数字识别MATLAB完整代码_mnist matlab
- 2调研120+模型!腾讯AI Lab联合京都大学发布多模态大语言模型最新综述
- 3安装tokenizers拓展包_tokenizers-0.15.0.tar.gz
- 4解决VMvare仅主机模式下宿主机与虚拟机互相ping不通的问题_三台仅主机模式的虚拟机,两台与主机通,一台与主机不通,什么情况
- 5ASM 和 LVM
- 6mmsegmentation自定义数据集_mmseg 2class
- 7机器学习入门教程_机器学习 教程
- 8只要一个软件让电脑硬盘瞬间扩容10T空间 | 阿里云盘变本地硬盘。
- 9Android实现新闻列表
- 10AI算法工程师 | 01人工智能基础-快速入门_人工智能算法
当前位置: article > 正文
python大作业代码及文档,python大作业有哪些题目
作者:花生_TL007 | 2024-03-26 18:45:32
赞
踩
python大作业
大家好,小编为大家解答python大作业设计一个纸牌类游戏的问题。很多人还不知道python大作业代码及文档,现在让我们一起来看看吧!

作业要求
- [基础要求] 基于Jupyter Notebook 完成以下实验一、实验二、实验三;
- [重点要求] 修改以下示例代码,以测试不同知识点。在博客上写出你:
- 修改的代码、
- 修改的愿意(意图)
- 代码运行的结果
- 你的结论
实验一:Series对象的应用
实验要求:
- 定义一个Series对象,包含5个整数数据;
- 访问、修改Series对象中的数据;
- 打印Series对象;
- 对Series对象进行计算,如求和、求平均值等用python绘制满天星代码。
示例代码:
- import pandas as pd
-
-
- # 定义一个Series对象
- s = pd.Series([10, 20, 30, 40, 50])
-
-
- # 访问Series对象中的数据
- print(s[0]) # 输出第一个元素
- print(s[2:4]) # 输出第3个到第4个元素
-
-
- # 修改Series对象中的数据
- s[1] = 25
-
-
- # 打印Series对象
- print(s)
-
-
- # 对Series对象进行计算
- print(s.sum()) # 求和
- print(s.mean()) # 求平均值

修改后的代码:
- import pandas as pd
-
- # 定义一个Series对象
- s = pd.Series([10, 20, 30, 40, 50])
-
- # 访问Series对象中的数据
- print(s[0]) # 输出第一个元素
- print(s[2:4]) # 输出第3个到第4个元素
-
- #访问Series对象中大于20的数据
- print(s[s>20])
-
- # 对Series对象进行去重操作
- s1=pd.Series([1,1,2,3,3,5,5,9,4])
- news1=s1.unique()
- print(news1)
-
- # 修改Series对象中的数据
- s[1] = 25
-
- # 打印Series对象
- print(s)
-
- # 对Series对象进行计算
- print(s.sum()) # 求和
- print(s.mean()) # 求平均值
修改意图:测试Series对象的筛选数据与去重功能
运行结果:
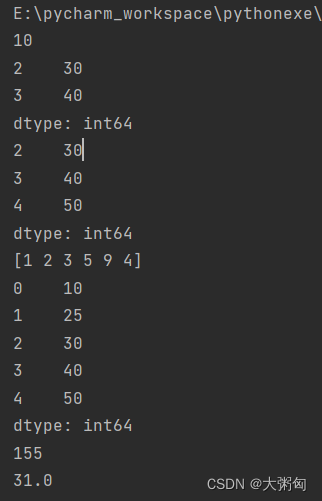
结论:
要在Series中筛选数据,可以使用布尔索引,直接在Series对象后加上筛选条件即可;
Series对象可以使用unique()方法进行去重操作。
实验二:DataFrame对象的应用
实验要求:
- 定义一个DataFrame对象,包含3个列,每列分别为整数、浮点数和字符串类型;
- 访问、修改DataFrame对象中的数据;
- 对DataFrame对象进行计算,如求和、求平均值等。
示例代码:
- import pandas as pd
-
- # 定义一个DataFrame对象
- data = {'int_col': [1, 2, 3, 4, 5], 'float_col': [1.2, 2.3, 3.4, 4.5, 5.6], 'str_col': ['a', 'b', 'c', 'd', 'e']}
- df = pd.DataFrame(data)
-
- # 访问DataFrame对象中的数据
- print(df['int_col'][0]) # 输出第一行第一列的数据
- print(df.loc[1, 'str_col']) # 输出第二行第三列的数据
-
- # 修改DataFrame对象中的数据
- df.loc[2, 'float_col'] = 3.5
-
- # 对DataFrame对象进行计算
- print(df.sum()) # 求和
- print(df.mean()) # 求平均值
修改后的代码:
- import pandas as pd
-
- # 定义一个DataFrame对象
- data = {'int_col': [1, 2, 3, 4, 5,6,7,8], 'float_col': [1.2, 2.3, 3.4, 4.5, 5.6,6.7,7.8,8.9], 'str_col': ['a', 'b', 'c', 'd', 'e','f','g','h']}
- df = pd.DataFrame(data)
-
- # 访问DataFrame对象中的数据
- print(df['int_col'][0]) # 输出第一行第一列的数据
- print(df.loc[1, 'str_col']) # 输出第二行第三列的数据
-
- # 访问DataFrame对象前n行数据与后n行数据
- print(df.head())
- print(df.tail(2))
-
- # 筛选数据
- print(df[df['str_col'] > 'c'])
-
-
- # 修改DataFrame对象中的数据
- df.loc[2, 'float_col'] = 3.5
-
- # 对DataFrame对象进行计算
- print(df.sum()) # 求和
- print(df.mean()) # 求平均值
修改意图:测试DataFrame对象对象访问前n行和后n行数据的功能,以及筛选数据的功能
运行结果:
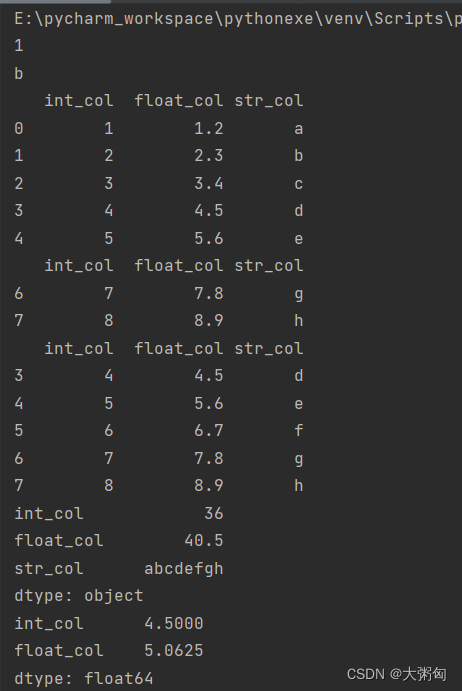
结论:
DataFrame对象可以通过df.head(n)、df.tail(n)命令查看前后n行数据,默认为5行;
DataFrame对象可以使用以下命令实现根据某一列数据进行条件过滤,返回DataFrame类型。
df[df[column] > value]实验三:综合实例
实验要求:
- 定义一个包含省会城市、人口、GDP、城市面积的DataFrame对象;
- 计算各种排名,如人口最多的城市、GDP最高的城市等;
- 使用Pandas绘图,可视化上述实验结果。
示例代码:
- import pandas as pd
- import matplotlib.pyplot as plt
-
- # 定义一个包含省会城市、人口、GDP、城市面积的DataFrame对象
- data = {'city': ['北京', '上海', '广州', '深圳'], 'population': [2171, 2424, 1500, 1303],
- 'gdp': [30320, 32679, 20353, 22458], 'area': [16410, 6340, 7434, 1996]}
- df = pd.DataFrame(data)
-
- # 计算各种排名
- pop_rank = df['population'].rank(ascending=False)
- gdp_rank = df['gdp'].rank(ascending=False)
- area_rank = df['area'].rank(ascending=False)
-
- # 将排名添加到DataFrame对象中
- df['pop_rank'] = pop_rank
- df['gdp_rank'] = gdp_rank
- df['area_rank'] = area_rank
-
- # 使用Pandas绘图,可视化实验结果
- df.plot(kind='bar', x='city', y=['population', 'gdp', 'area'], title='China Capital Cities')
- plt.show()
修改后的代码:
- import pandas as pd
- import matplotlib.pyplot as plt
-
- # 定义一个包含省会城市、人口、GDP、城市面积的DataFrame对象
- data = {'city': ['bj', 'sh', 'gz', 'sz'], 'population': [2171, 2424, 1500, 1303],
- 'gdp': [30320, 32679, 20353, 22458], 'area': [16410, 6340, 7434, 1996]}
- df = pd.DataFrame(data)
-
- # 计算各种排名
- pop_rank = df['population'].rank(ascending=False)
- gdp_rank = df['gdp'].rank(ascending=False)
- area_rank = df['area'].rank(ascending=False)
-
- # 将排名添加到DataFrame对象中
- df['pop_rank'] = pop_rank
- df['gdp_rank'] = gdp_rank
- df['area_rank'] = area_rank
-
- # 使用Pandas绘图,可视化实验结果
- df.plot(kind='bar', x='city', y=['population', 'gdp', 'area'], title='China Capital Cities')
- plt.show()
-
- # 绘制城市面积的饼图
- fig, ax = plt.subplots()
- ax.pie(df['area'], labels=df['city'], autopct='%1.1f%%')
- ax.axis('equal')
- ax.set_title('Area distribution')
- plt.show()
修改意图:
使城市名称能显示出来,示例代码未考虑到中文显示问题,如果系统默认编码不是utf-8会导致出现中文乱码问题,于是我将城市名称换位了拼音首字母;
使用pandas绘制城市面积数据的饼图。
运行结果:
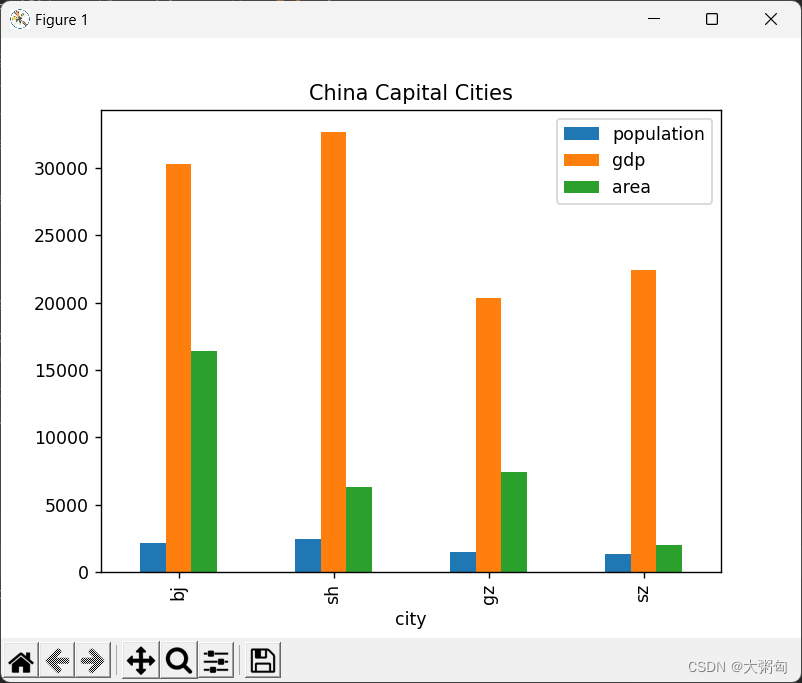
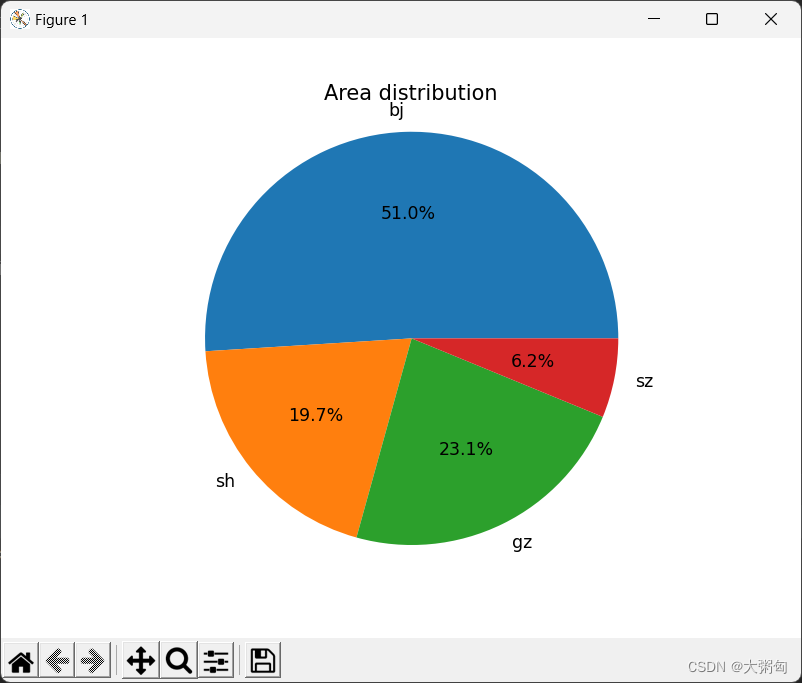
结论:
可使用下图命令绘制饼图,其中,kind="pie" 表示绘制饼图,subplots=True 表示将不同数据分别绘制在一个子图中,figsize 表示设置图形大小。最后通过 plt.show() 展示图像。
- df.plot(kind='pie', subplots=True, figsize=(8, 8))
- plt.show()
文章知识点与官方知识档案匹配,可进一步学习相关知识
Python入门技能树人工智能机器学习工具包Scikit-learn405476 人正在系统学习中
本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读

相关标签

