
热门标签
热门文章
- 1Docker:探索容器化技术,重塑云计算时代应用交付与管理
- 2OpenAI分裂出去的兄弟公司Anthropic,默默推出Claude3模型 | Claude3实测_claude 3个模型名称起源
- 3【数理逻辑四】谓词逻辑及形式系统 【中】_一阶语言的变量替换
- 4C++的并发世界(二)——初识多线程
- 5【懒懒】我不生产笑话,我只是笑话的搬运工 [问题点数:200分]
- 6【人工智能项目】LSTM实现电影评论情感分类实验_基于lstm的影评分类情感分析识别系统设计与实现
- 7CSS clip:rect矩形剪裁功能及一些应用介绍_css rect
- 8开源大语言模型(LLM)汇总(持续更新中)
- 9代码抽取功能优化(二)_代码抽取怎么更优
- 10腾讯云函数计算技术:云原生架构下的Serverless与微服务新篇章
当前位置: article > 正文
NLP-文本表示(Text Representation):TF-IDF和Embedding_tfidf representation
作者:花生_TL007 | 2024-04-03 23:54:41
赞
踩
tfidf representation
TF-IDF(词频逆文档频次算法)
该指标的意义:tf-idf通过词频统计的方法得到某个词对一篇文档的重要性大小(没有考虑语义信息)。
计算公式: TF-IDF = tf * idf 可以看出,是tf与idf值得乘积
tf 值(term frequency):
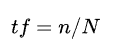
其中n表示某个词在该文档中出现的次数,N表示该文档中所有词出现的次数总和,这是一个归一化的过程,目的是消除文档篇幅长短上的差异。
idf值(inverse document frequency)
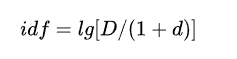
D表示语料中所有的文档总数,d表示语料中出现某个词的文档数量,公式中的1是为了防止分母为0的情况,lg是以10为底的对数(有时也用自然对数),具有类似于增强区分度的作用(拥挤的值尽可能散开,离群的值尽可能合拢)。
分析公式:出现该词的文档越多,说明该词普遍性很强,是常见词,类似the,a,that这种,但其关键程度或主题性可能不是很强。
tf-idf值
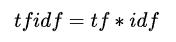
用tfidf值可以弱化常见词,保留重要的词。若某个词在某个文档中是高频词,在整个语料中又是低频出现,那么这个词将具有高tfidf值,它对这篇文档来说,就是关键词,或主题词。
Embedding
Embedding就是一种将自然语言单词映射到实数域vector的编码操作,映射到实数域才能使用数学方法进行特征提取等操作,相比one-hot编码,占空间更小。
Embedding操作之前还有字符串对齐等简单的基本操作,这里我们直接使用一个电影英文评论的正负二分类任务来讲述Embedding。
我们可以把训练数据中的所有单词或一部分常用词作为词库或字典,这里取其中的10000个常用词作为单词。
- 第一部对词库中的单词进行one-hot编码。one-hot本身作为一种编码方式,也可以将字符串映射到实数vectors,但当词库中单词数量太多时(假设10000个),那显然每个单词都要用10000维的向量表示,这太占空间了,还有其他缺点也导致它不适用于word encode,这里略过。

- embedding:我们设定每个单词用长度为d的向量表示,这里的d远小于10000,
,因为这里的d并非onehot那样的二进制向量,所以其可表达的信息量并不少,那么表示10000(v)个单词的向量组就可以表示成d * v大小的P,而每个单词对应的编码则可以用P * ei表示。而P是随机初始化的,可以用训练数据进行学习。
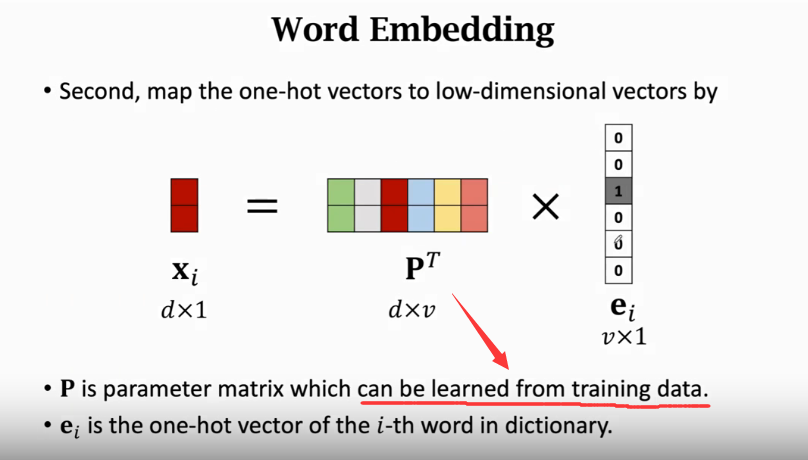
训练出来的P,具有相似性的词,其距离应该更近,反之相反。下图中的例子是对电影正面与负面评价分类任务。

- 我们假设d即embedding_dim=8, 词库使用10000个词,每个电影评论的句子对齐为20个单词。使用keras实现一个简单的文本分类器:

注意其embedding层的param为80000,这就是网络要根据训练数据学的P。输入的一个包含20个词的句子经过embedding层就编码为20*8的vector,这就完成了自然语言到实数域的编码,这个小例子中后续使用单层MLP进行分类,更先进的可以使用RNN,LSTM等。
参考:https://zhuanlan.zhihu.com/p/263476409
https://www.youtube.com/user/wsszju/videos
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/356866
推荐阅读
相关标签

