
- 1数学建模常用算法—马尔可夫预测_马尔可夫算法
- 2PHP(9):将上传的Word文件保存到MS SQL Server数据库_上传word文件到数据库
- 3C++ lambda表达式_c++ lambda 表达式
- 4Salesforce系列(0):Salesforce导入数据!_sales force inspector安装
- 5Langchain 的 Structured output parser_langchain structuredoutputparser
- 6软件测试-工作流程(需求分析评审、测试计划、测试用例、用例评审、执行测试、跟踪定位bug、测试报告、缺陷报告)_1.获取需求分析书 2.进行需求评审 3.编写测试用例 4.进行测试用例的执行 5.进行bu
- 7基于SSM的红色文化展示小程序系统设计与实现【包调试】_文化展示小程序论坛界面
- 8重磅!教育部再次审批179所高校新增本科AI专业
- 9基于蜣螂算法改进的DELM分类-附代码_蜣螂优化算法深度极限学习机
- 10Xcode - VALID_ARCHS_xcode valid_archs
FlinkCDC第三部分-同步mysql到mysql,ctrl就完事~(flink版本1.16.2)_flink-connector-jdbc
赞
踩
本文介绍了 来源单表->目标源单表同步,多来源单表->目标源单表同步。
注:1.16版本、1.17版本都可以使用火焰图,生产上最好关闭,详情见文章末尾
Flink版本:1.16.2
环境:Linux CentOS 7.0、jdk1.8
基础文件:
flink-1.16.2-bin-scala_2.12.tgz、
flink-connector-jdbc-3.0.0-1.16.jar、(maven仓库目录:corg.apache.flink/flink-connector-jdbc/3.0.0-1.16)
flink-sql-connector-mysql-cdc-2.3.0.jar、(maven仓库目录:com.ververica/flink-sql-connector-mysql-cdc/2.3.0)
安装Flink步骤详见文章第二篇
Flink版本:1.17.1
环境:Linux CentOS 7.0、jdk1.8
基础文件:
flink-1.17.1-bin-scala_2.12.tgz、
flink-connector-jdbc-3.0.0-1.16.jar、(maven仓库目录:corg.apache.flink/flink-connector-jdbc/3.0.0-1.16)
flink-sql-connector-mysql-cdc-2.3.0.jar、(maven仓库目录:com.ververica/flink-sql-connector-mysql-cdc/2.3.0)
支持的mysql版本:

本次测试使用版本flink1.16.2
一、 来源单表->目标源单表同步:数据源ip为***.50的源表,同步数据到数据源ip为***.134的目标表中,需要以下几个步骤:
1. 启动flink服务:
[root@localhost bin]# ./start-cluster.sh
2. 停止flink服务:
[root@localhost bin]# ./stop-cluster.sh
3. 启动FinkSQL:
[root@localhost bin]# ./sql-client.sh
4. 编写FlinkSql,创建临时表和job:
把写好的Sql粘贴到FlinkSql客户端命令行中,分号' ; '是语句结束标识符,按回车创建:
创建来源表结构:
来源表链接类型为'connector' = 'mysql-cdc'
Flink SQL> CREATE TABLE source_alarminfo51 (
> id STRING NOT NULL,
> AlarmTypeID STRING,
> `Time` timestamp,
> PRIMARY KEY (`id`) NOT ENFORCED
> ) WITH (
> 'connector' = 'mysql-cdc',
> 'hostname' = '***',
> 'port' = '3306',
> 'username' = '***',
> 'password' = '***',
> 'database-name' = 'alarm',
> 'server-time-zone' = 'Asia/Shanghai',
> 'table-name' = 'alarminfo'
> );[INFO] Execute statement succeed.
创建目标表结构(目标表结构可比来源表字段多,可使用视图指定字段默认值):
目标表链接类型为'connector' = 'jdbc',注意url需要跟后面以下属性值
Flink SQL> CREATE TABLE target_alarminfo134 (
> id STRING NOT NULL,
> AlarmTypeID STRING,
> `Time` timestamp,
> sourceLine int,
> PRIMARY KEY (`id`) NOT ENFORCED
> ) WITH (
> 'connector' = 'jdbc',
> 'url' = 'jdbc:mysql://***:3306/alarm?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&serverTimezone=Asia/Shanghai&useSSL=true&dontTrackOpenResources=true&defaultFetchSize=10000&useCursorFetch=true',
> 'username' = '***',
> 'password' = '****',
> 'table-name' = 'alarminfo',
> 'driver' = 'com.mysql.cj.jdbc.Driver',
> 'scan.fetch-size' = '1000'
> );[INFO] Execute statement succeed.
'scan.fetch-size' = '1000' 的含义:
在 Flink SQL 中,scan.fetch-size 属性用于配置批处理查询中的每次批量获取记录的大小。具体地说,它指定了每次从数据源读取的记录数。
如何设置:
以下是一些建议:
考虑数据源的吞吐量:如果你的数据源的吞吐量较高,网络延迟较低,可以适当增大 scan.fetch-size 的值,以减少网络往返次数和请求开销。
考虑网络环境和带宽限制:如果数据源位于远程服务器或网络环境较差,可以选择适当较小的 fetch size 值,以减少网络传输的负载,避免出现大量的网络超时和传输失败情况。
考虑内存开销:fetch size 值过大可能会占用较多的内存资源,特别是对于批处理查询。如果你的查询涉及大量的中间状态(intermediate state)或内存密集型操作,可以选择适当较小的 fetch size 值。
一般来说,可以先尝试将 scan.fetch-size 设置为一个较默认的值,例如 1000 或 5000。然后观察任务的性能和执行效果,根据实际情况进行微调。可以根据实际性能测试和系统资源情况,逐步调整 fetch size 值,以找到性能和资源利用的平衡点。
需要注意的是,scan.fetch-size 属性值是一个相对的配置,不同的数据源和查询场景可能有不同的最佳值。因此,针对具体的数据源和查询条件,最好进行一些实际的性能测试和调优,以获得最优的性能和资源使用。
最后创建同步关系:
INSERT INTO target_alarminfo134 SELECT *,50 AS sourceLine FROM source_alarminfo50
若目标表比源表结构少字段属性则执行完同步关系后如下:

创建完表结构可使用下列语句查看和删除:
查看表:show tables;
删除表:drop table if exists target_alarminfo;
flink-UI页面效果:

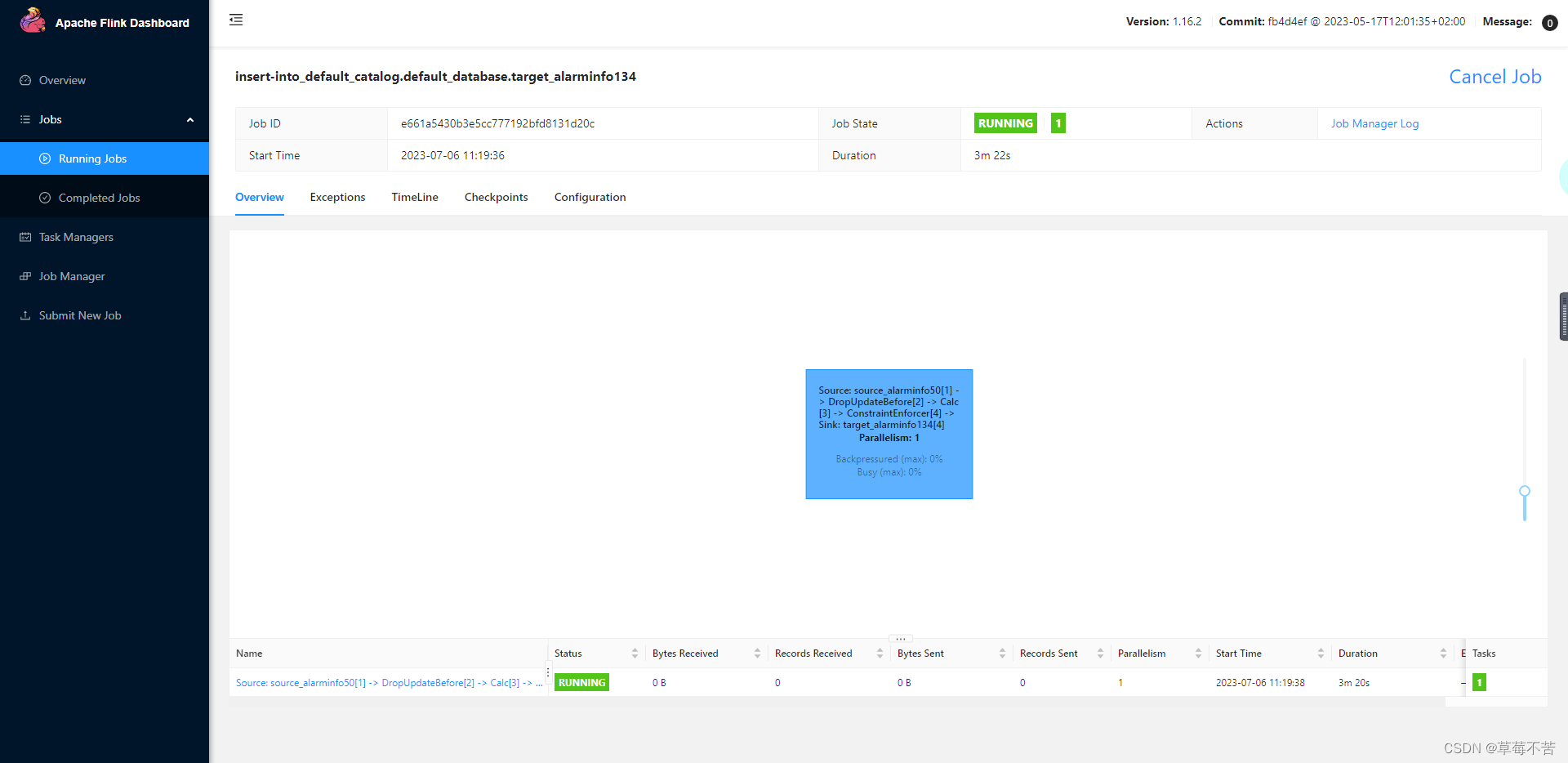
数据同步效果:
源表:
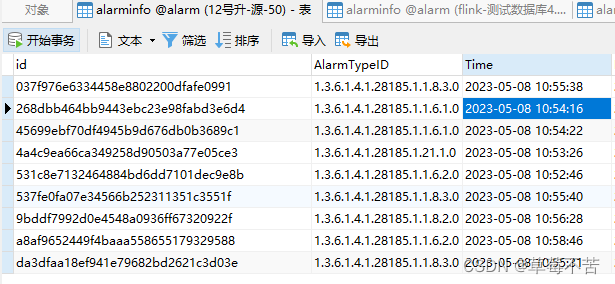
目标表数据:首次数据全量,后面数据变更增量

二、 多来源单表->目标源单表同步:数据源ip为***.50、***.51的两个源表,同步数据到数据源ip为***.134的目标表中,使用sourceLine 用于区分数据来源,需要以下几个步骤:
1. 创建自定义初始化脚本文件 init.sql、flinkSqlInit.sql,flinkSqlInit.sql文件中包含了在FlinkSql中需要执行的语句,用于自动化创建临时表和视图,这两个放在flink的bin目录下:
init.sql内容如下:
- SET execution.runtime-mode=streaming;
- SET pipeline.name=my_flink_job;
- SET parallism.default=4;
SET execution.runtime-mode=streaming 设置了作业的运行模式为流处理模式。这表示作业将以流处理的方式运行,即实时处理每个输入事件,并根据输入数据的到达顺序进行处理。
SET pipeline.name=my_flink_job 设置了作业的流水线名称为 "my_flink_job"。流水线名称主要用于标识作业,以便在运行时进行管理和监控。
SET parallelism.default=4 设置了作业的默认并行度为 4。并行度表示同时执行作业任务的任务数量。通过设置并行度,可以控制作业在集群上使用的资源量和执行的并行度。默认并行度将应用于作业的所有算子,除非为某个算子单独指定了并行度。
这些设置属性可以在 Flink 的初始化脚本中使用,并在作业启动时生效。可以根据作业的需求和资源情况调整这些属性,以获得最佳的性能和资源利用率。
注:mysql-cdc和jdbc的区别:mysql-cdc 标注 数据来源的表,jdbc标注 同步到的目标表
flinkSqlInit.sql内容如下:
SET execution.checkpointing.interval = 60s;
drop table if exists source_alarminfo50;
CREATE TABLE source_alarminfo50 (
id STRING NOT NULL,
AlarmTypeID STRING,
`Time` timestamp,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '**',
'port' = '3306',
'username' = '**',
'password' = '**',
'database-name' = 'alarm',
'server-time-zone' = 'Asia/Shanghai',
'table-name' = 'alarminfo'
);
drop table if exists source_alarminfo51;
CREATE TABLE source_alarminfo51 (
id STRING NOT NULL,
AlarmTypeID STRING,
`Time` timestamp,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '**',
'port' = '3306',
'username' = '**',
'password' = '**',
'database-name' = 'alarm',
'server-time-zone' = 'Asia/Shanghai',
'table-name' = 'alarminfo'
);
drop table if exists target_alarminfo134;
CREATE TABLE target_alarminfo134 (
id STRING NOT NULL,
AlarmTypeID STRING,
`Time` timestamp,
sourceLine int,
PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://***:3306/alarm?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&serverTimezone=Asia/Shanghai&useSSL=true&dontTrackOpenResources=true&defaultFetchSize=10000&useCursorFetch=true',
'username' = '**',
'password' = '**',
'table-name' = 'alarminfo',
'driver' = 'com.mysql.cj.jdbc.Driver',
'scan.fetch-size' = '200'
);BEGIN STATEMENT SET;
INSERT INTO target_alarminfo134
SELECT *,50 AS sourceLine FROM source_alarminfo50
UNION ALL
SELECT *,51 AS sourceLine FROM source_alarminfo51;END;
其中涉及flinksql的语法:
BEGIN STATEMENT SET 是 Flink SQL 中的一个特殊语法,用于将一组 SQL 语句作为一个事务进行处理。它用于将多个 SQL 语句作为一个原子操作执行,要么全部成功提交,要么全部回滚。
在 Flink SQL 中,可以使用 BEGIN STATEMENT SET 将多个 SQL 语句组合成一个事务,以确保这些语句的原子性。
以下是 BEGIN STATEMENT SET 的使用示例:
BEGIN STATEMENT SET;
-- SQL 语句 1
-- SQL 语句 2
-- ...
COMMIT;
在上述示例中,BEGIN STATEMENT SET 表示事务的开始,COMMIT 表示事务的提交。你可以在 BEGIN STATEMENT SET 和 COMMIT 之间编写需要执行的多个 SQL 语句。
如果在 BEGIN STATEMENT SET 和 COMMIT 之间的任何一条语句执行失败,整个事务将回滚,即已经执行的语句会被撤销。
需要注意的是,BEGIN STATEMENT SET 和 COMMIT 语句是 Flink SQL 的扩展语法,它们可能在某些特定的 Flink 版本或环境中才可用。在使用时,请确保你的 Flink 版本和环境支持该语法。
检查点间隔设置:
SET execution.checkpointing.interval = 60s;
通过设置适当的检查点间隔,可以在容忍一定故障的同时,控制检查点的频率和资源使用。较短的检查点间隔可以提供更高的容错性,但也会增加系统开销。
检查点是 Flink 中用于实现容错性的机制,它会定期将作业的状态保存到持久化存储中,以便在发生故障时进行恢复。检查点间隔定义了两个连续检查点之间的时间间隔。
2. 重启Flink服务:
停止flink服务:
[root@localhost bin]# ./stop-cluster.sh
启动flink服务:
[root@localhost bin]# ./start-cluster.sh
启动FinkSQL:
[root@localhost bin]# ./sql-client.sh
3.1 在flink的bin目录下执行初始化文件flinkSqlInit.sql:
有两种方式:
方式一:可设置job名称及资源参数配置
[root@localhost bin]# ./sql-client.sh -i init.sql -f flinkSqlInit.sql
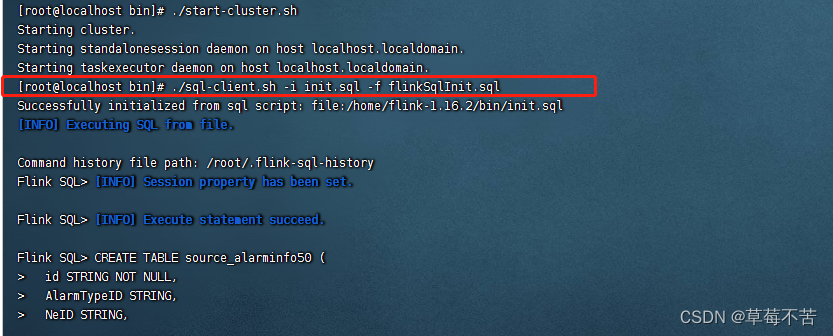
使用这个语句的好处是可以根据作业的需求和资源情况调整这些属性,以获得最佳的性能和资源利用率。
flink-UI页面效果:


方式二:不可设置job名称及资源参数配置
[root@localhost bin]# ./sql-client.sh -f flinkSqlInit.sql



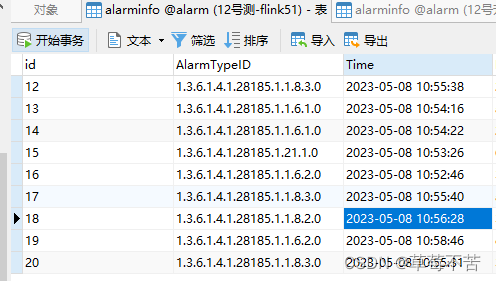
4. 数据同步效果:


三、打开火焰图:
编辑flink-conf.yaml:最后面添加
rest.flamegraph.enabled: true
配置后重启flink服务,重新创建任务。
火焰图效果:

注:
在分析火焰图时,可以关注以下几点:
函数的执行时间:纵向的轴显示了函数的嵌套层级,越往下表示越深层的函数调用。横向轴表示时间,通过不同颜色的方块来表示函数的执行时间。
热点函数:寻找占据执行时间大部分的函数,这些函数可能是需要优化的关键点。
函数之间的关系:观察函数之间的调用关系,查看是否有不必要的函数调用或循环。
I/O 操作:关注是否有大量的数据读取、写入或网络通信,这可能是性能瓶颈的来源。
根据火焰图的分析结果,您可以进一步定位和排查潜在的性能问题,并在代码、配置或资源分配方面进行优化。
请注意,为了准确分析火焰图,建议在负载较高的情况下生成火焰图,并保持足够的监视时间。此外,Flink 的火焰图功能在生产环境中可能会造成一定的开销,因此建议在测试或开发环境中使用。
四、源表、目标表结构with下的属性介绍:
源表with下的属性:
chunk-key.even-distribution.factor.lower-bound:块键(Chunk Key)的均匀分布因子下限。
chunk-key.even-distribution.factor.upper-bound:块键的均匀分布因子上限。
chunk-meta.group.size:块元数据的分组大小。
connect.max-retries:连接重试的最大次数。
connect.timeout:连接的超时时间。
connection.pool.size:连接池的大小。
connector:使用的连接器的名称。
database-name:数据库的名称。
heartbeat.interval:心跳间隔时间。
hostname:主机名或 IP 地址。
password:连接到数据库或其他系统所需的密码。
port:连接的端口号。
property-version:属性版本。
scan.incremental.snapshot.chunk.key-column:增量快照的块键列。
scan.incremental.snapshot.chunk.size:增量快照的块大小。
scan.incremental.snapshot.enabled:是否启用增量快照。
scan.newly-added-table.enabled:是否启用新加入表的扫描。
scan.snapshot.fetch.size:从状态快照中获取的每次批量记录数。
scan.startup.mode:扫描启动模式。
scan.startup.specific-offset.file:指定启动位置的文件名。
scan.startup.specific-offset.gtid-set:指定启动位置的 GTID 集合。
scan.startup.specific-offset.pos:指定启动位置的二进制日志位置。
scan.startup.specific-offset.skip-events:跳过的事件数量。
scan.startup.specific-offset.skip-rows:跳过的行数。
scan.startup.timestamp-millis:指定启动时间戳(毫秒)。
server-id:服务器 ID。
server-time-zone:服务器时区。
split-key.even-distribution.factor.lower-bound:切分键(Split Key)的均匀分布因子下限。
split-key.even-distribution.factor.upper-bound:切分键的均匀分布因子上限。
table-name:表名。
username:连接到数据库或其他系统所需的用户名。
Sink目标表with下的属性:
connection.max-retry-timeout:连接重试的最大超时时间。
connector:使用的连接器的名称。
driver:JDBC 连接器中使用的数据库驱动程序的类名。
lookup.cache:查找表的缓存配置。
lookup.cache.caching-missing-key:是否缓存查找表中的缺失键。
lookup.cache.max-rows:查找表缓存中允许的最大行数。
lookup.cache.ttl:查找表缓存中行的生存时间。
lookup.max-retries:查找操作的最大重试次数。
lookup.partial-cache.cache-missing-key:是否缓存查找表部分缺失的键。
lookup.partial-cache.expire-after-access:查找表部分缓存中行的访问到期时间。
lookup.partial-cache.expire-after-write:查找表部分缓存中行的写入到期时间。
lookup.partial-cache.max-rows:查找表部分缓存中允许的最大行数。
password:连接到数据库或其他系统所需的密码。
property-version:属性版本。
scan.auto-commit:是否自动提交扫描操作。
scan.fetch-size:每次批量获取记录的大小。
scan.partition.column:用于分区的列名。
scan.partition.lower-bound:分区的下限值。
scan.partition.num:要扫描的分区数量。
scan.partition.upper-bound:分区的上限值。
sink.buffer-flush.interval:将缓冲区的数据刷新到目标系统的时间间隔。
sink.buffer-flush.max-rows:缓冲区中的最大行数,达到此值时将刷新数据。
sink.max-retries:写入操作的最大重试次数。
sink.parallelism:写入任务的并行度。
table-name:表名。
url:连接到数据库或其他系统的 URL。
username:连接到数据库或其他系统所需的用户名。
最后FlinkCDC目前不支持整库同步:



