
- 1springcloudalibaba整合nacos
- 2【Unity】AssetBundle加载与卸载
- 3uniapp获取当前位置和经纬度信息(app端高德地图)_uni-app app端根据经纬度获取address
- 4微软如何打造数字零售力航母系列科普03 - Mendix是谁?作为致力于企业低代码服务平台的领头羊,它解决了哪些问题?
- 5npm run build 时出现Build failed with errors_build failed with errors.
- 6kafka-exporter部署手册_kafka-exporter官网文档
- 7【Java接入通义千问】_通义千问api接口文档
- 8程序员的浪漫,2024跨年烟花代码(Python)_跨年编程
- 9mid360+point-lio_all processes on machine have died, roslaunch will
- 10Superset V1.2 WIN10安装与汉化_superset中文版
【论文阅读】UniMSE: Towards Unified Multimodal Sentiment Analysis and Emotion Recognition(EMNLP 2022)
赞
踩
【论文链接】https://arxiv.org/pdf/2211.11256.pdf
【代码链接】https://github.com/lemei/unimse
问题动机:
从心理学的角度来看,emotions是短时间内情感或感受的表达,而sentiments的形成和保持则需要较长的时间。大多数现有工作分别研究情感和情绪,并没有充分利用两者背后的互补知识。本文提出了一个统一的框架,将Multimodal Sentiment Analysis(MSA)和Emotion Recognition in Conversations(ERC)两个任务结合起来。MSA 的目标是预测情绪强度或极性,而 ERC 旨在预测预定义的情绪类别。
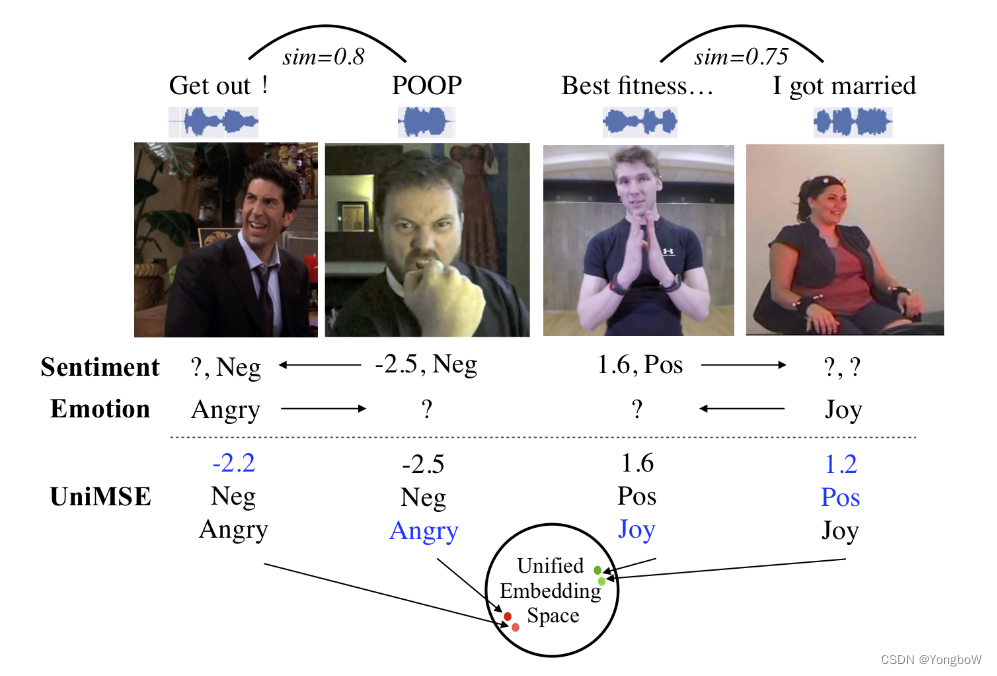
从下图中,我们可以看出情绪和情感在语言或非语言中是如何相关的,并且可以投射到统一的嵌入空间中。
解决方法:
本文提出了一个多模态情感知识共享框架,统一了 MSA 和 ERC (UniMSE) 任务。 UniMSE 将 MSA 和 ERC 重新表述为生成任务,以统一输入、输出和任务。我们提取并统一音频和视频特征,并将 MSA 和 ERC 标签形式化为通用标签 (UL),以统一情绪和情感。
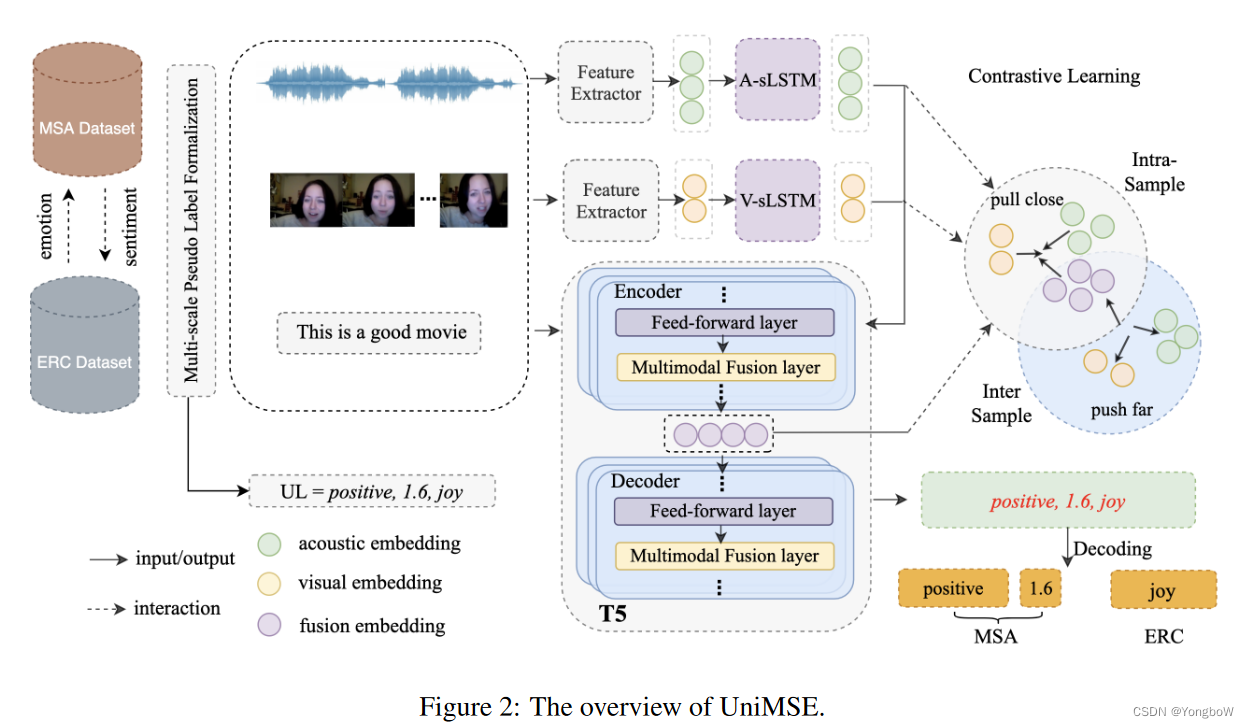
UniMSE 包括任务形式化、预训练模态融合和模态间对比学习。首先,我们将 MSA 和 ERC 任务的标签离线处理为通用标签(UL)格式。然后我们使用数据集中的统一特征提取器分别提取音频和视频特征。获得音频和视频特征后,我们将它们输入到两个单独的 LSTM 中以利用长期上下文信息。对于文本模态,我们使用 T5 作为编码器来学习序列的上下文信息。此外,我们执行模态间对比学习来区分样本之间的多模态融合表示。具体来说,对比学习旨在缩小同一样本的模态之间的差距,并将不同样本的模态表示进一步分开。
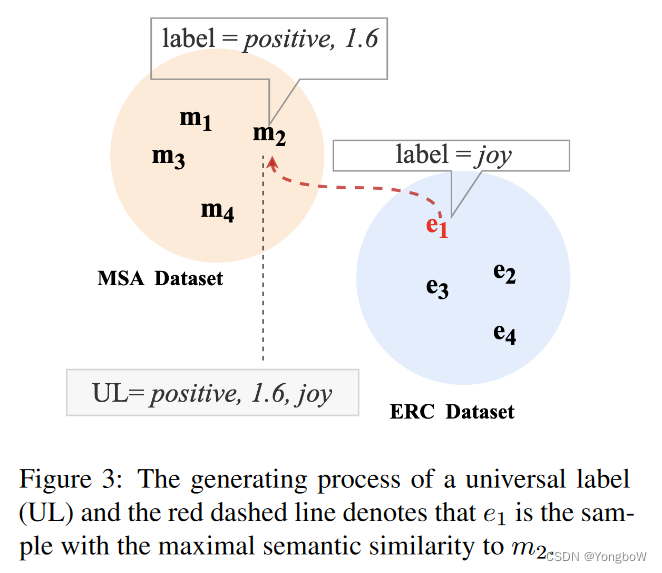
1. MSA 和 ERC 通过任务形式化在输入特征、模型架构和标签空间上统一。任务形式化包含输入形式化和标签形式化,其中输入形式化用于处理对话文本和模态特征,标签形式化用于通过将 MSA 和 ERC 任务的标签转换为通用标签来统一 MSA 和 ERC 任务。如下图,给定一个 MSA 样本 m2,它带有积极的情绪和 1.6 的注释分数。对标通用标签的格式,m2 缺少情感类别标签。在这个例子中,e1 与 m2 的语义相似度最大,然后我们将 e1 的情感类别指定为 m2 的情感类别。
2. 预训练的模态融合,我们将多模态融合层嵌入到预训练模型中。因此,声音和视觉信号可以参与文本编码,并与多层次的文本信息融合。此外,向T5注入音频和视觉可以探测海量预训练文本知识中的相关信息,从而将更丰富的预训练理解融入多模态融合表示中。我们将这种多模态融合过程命名为预训练模态融合 (PMF)。虽然我们可以在 T5 的编码器和解码器的每个 Transformer 中嵌入一个多模态融合层,但它可能会带来两个缺点:1)扰乱文本序列的编码,以及 2)由于为多模态融合层设置了更多参数而导致过拟合。考虑到这些问题,我们使用前 j 个 Transformer 层对文本进行编码,其余的 Transformer 层注入非语言(即听觉和视觉)信号。
3. 模态间对比学习,在本文的工作中,我们执行模态间对比学习以增强模态之间的相互作用并放大样本之间融合表示的差异。我们用 K 个样本构建每个小批量(每个样本由声学、视觉和文本模式组成)。由于文本模态的重要性在之前的工作中已经证明,因此,我们将文本模态作为锚点,将其他两种模态作为其增强版本。
T5模型链接:https://github.com/huggingface/transformers/tree/main/src/transformers/models/t5
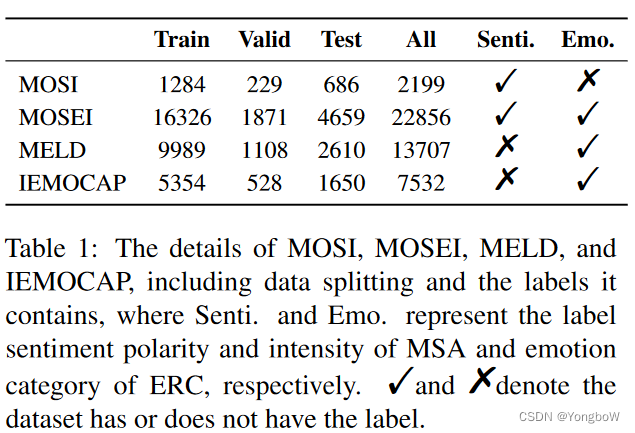
实验结果:
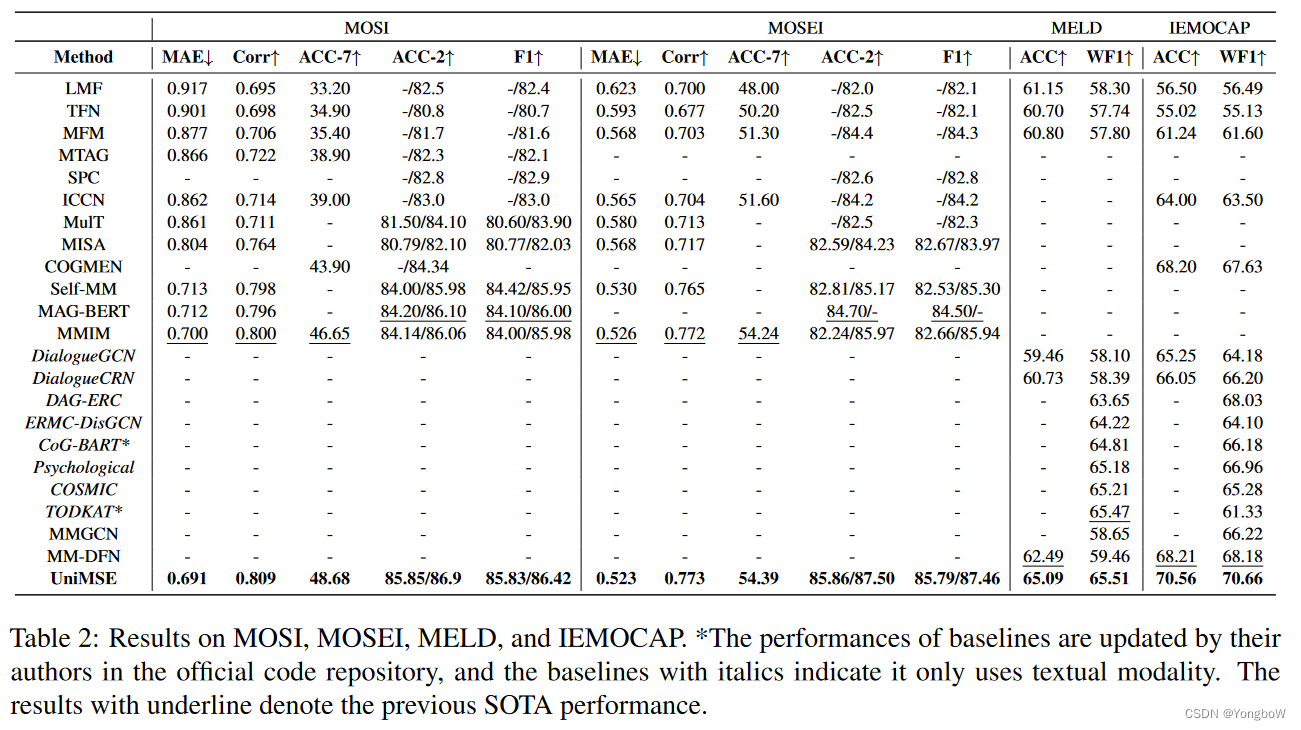
启发:
本文统一了MSA和ERC任务,进行互相补充,达到了较好结果,是否可以统一模态缺失与不缺少的问题。在其中的对比学习部分,只考虑了模态间的对比学习,是否可以考虑模态内的对比学习。

