
- 1第七届集创赛海云捷讯杯教程(二)_海运捷讯杯用什么开发板
- 2小程序测试用例_微信小程序安全测试实例检查系统的安全性,包括身份验证、访问控制、数据加密等
- 3Android 5+ 通知栏的细节问题_现在要求应用程序的通知栏图标只使用alpha图层进行绘制,而不应包括rgb图层
- 4【记录42】centos 7.6安装nginx教程详细教程
- 5UML建模例题100道_uml建模实例100例
- 6浅谈WDM与OTN——光传输大容量技术_光通信 wdm odn spliter
- 73.1 RK3399项目开发实录-Linux开发,编译 Linux 固件(物联技术666)_rk3399模块编译
- 8element 表格套输入框_element表格嵌入输入框
- 9Docker 部署 Harbor 镜像仓库_docker部署harbor仓库
- 10element源码分析_qmixelements 源码
一文读懂「MLLM,Multimodal Large Language Model」多模态大语言模型_mllm,
赞
踩

一. 什么是多模态?
模态是事物的一种表现形式,多模态通常包含两个或者两个以上的模态形式,是从多个视角出发对事物进行描述。生活中常见多 模态表示,例如传感器的数据不仅仅包含文字、图像,还可以包括与之匹配的温度、深度信息等。使用多模态数据能够使得事物呈现更加立体、全面,多模态研究成为当前研究重要方面,在情感分析、机器翻译、自然语言处理 和生物医药前沿方向取得重大突破。
1.1 背景
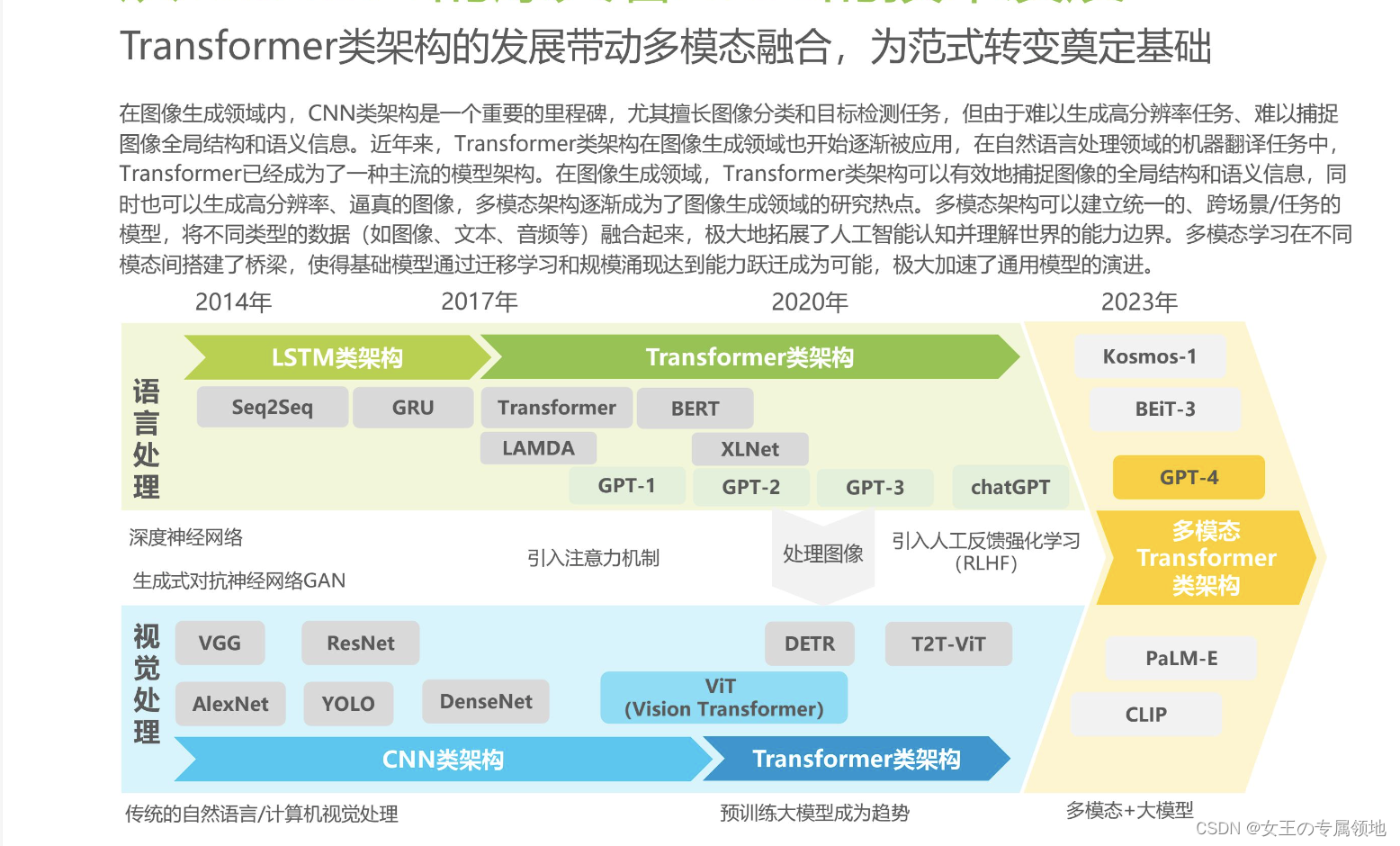
- Transformer颠覆传统模型,但限于单模态领域
- ViT的出现打通了CV和NLP之间壁垒,推动多模态演进,ViT中的Patch embedding在提取视觉特征方面效率优势明显
- 基于Vision Transformer,Video Transformer模型出现,如TimeSformer;
- Transformer权重共享决定其适合多模态,如VLMo;
- BEiT模型的出现将生成式预训练从NLP迁移到CV上
- 多模态模型大一统成趋势:2022年8月,微软推出BEiT-3模型,引领图像、文本、多模态迈向大一统。
2022年8月,微软推出BEiT-3模型,引领图像、文本、多模态迈向大一统。 BEiT-3提出了掩码图像建模,将masked data modeling引入到图像预训练任务,将图像和文本同等看待,以统一的方式对图像、文本、图像-文本对进行建模和学习。实际上,微软在2021年11月就推出了统一模型VLMO,使用混合模态专家(MOME)的方式来进行不同模态中进行预训练,训练出不同的编码器,用于不同的下游任务。BEiT-3在其基础上简化模型并增大预训练数据量,最终在多项下游任务上表现亮眼。2023年3月15日,微软旗下OpenAI推出多模态大模型GPT-4。
- 多模态广泛存在于机器人、数字人、智能家居等
1.2 定义
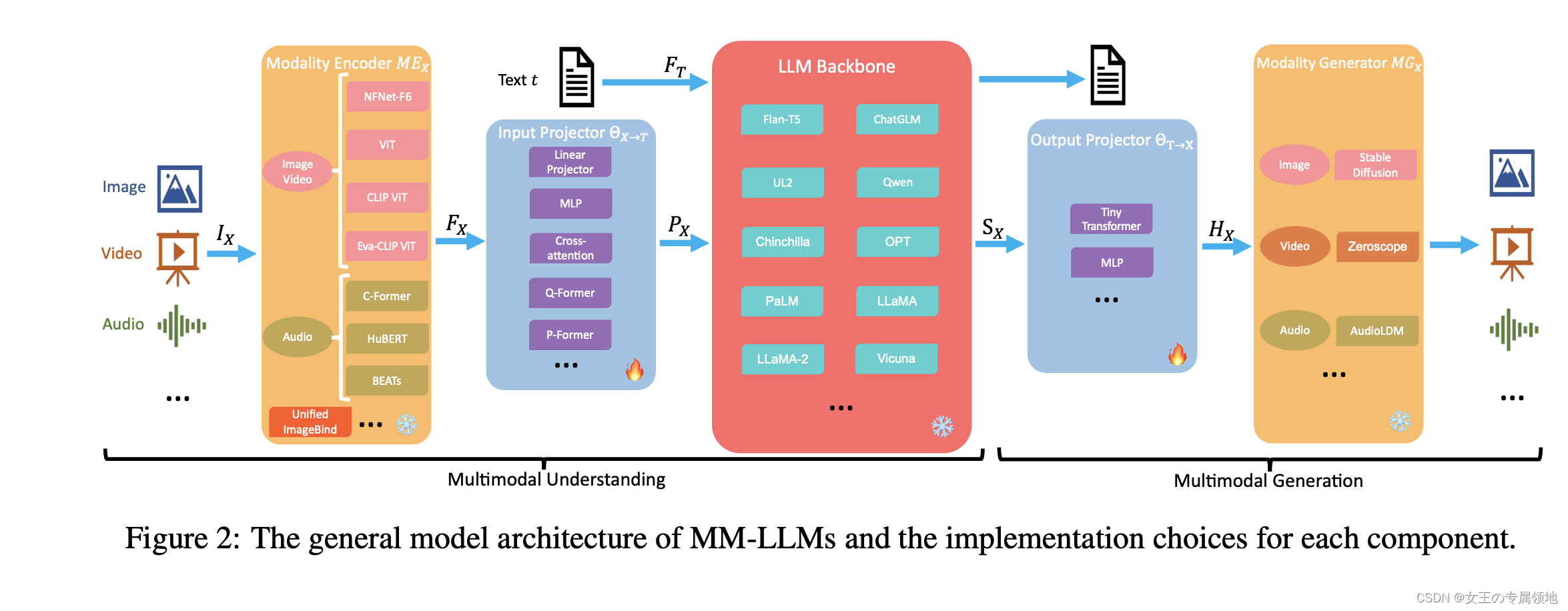
MLLM通常以大语言模型(Large Language Model,LLM)为基础,融入其它非文本的模态信息,完成各种多模态任务。
MLLM定义为“由LLM扩展而来的具有接收与推理多模态信息能力的模型”,该类模型相较于热门的单模态LLM具有以下的优势:
- 更符合人类认知世界的习惯。人类具有多种感官来接受多种模态信息,这些信息通常是互为补充、协同作用的。因此,使用多模态信息一般可以更好地认知与完成任务。
- 更加强大与用户友好的接口。通过支持多模态输入,用户可以通过更加灵活的方式输入与传达信息。
- 更广泛的任务支持。LLM通常只能完成纯文本相关的任务,而MLLM通过多模态可以额外完成更多任务,如图片描述和视觉知识问答等。

二. 关键技术
2.1 指令微调(Multimodal Instruction Tuning,M-IT)
指令(Instruction)指的是对任务的描述,多模态指令微调是一种通过指令格式的数据(Instruction-formatted data)来微调预训练的MLLM的技术。通过该技术,MLLM可以跟随新的指令泛化到未见过的任务上,提升zero-shot性能。
2.2 上下文学习(Multimodal In-Context Learning,M-ICL)
多模态上下文学习指的是给定少量样例作为Prompt输入,激发模型潜在的能力并规范化模型的输出。
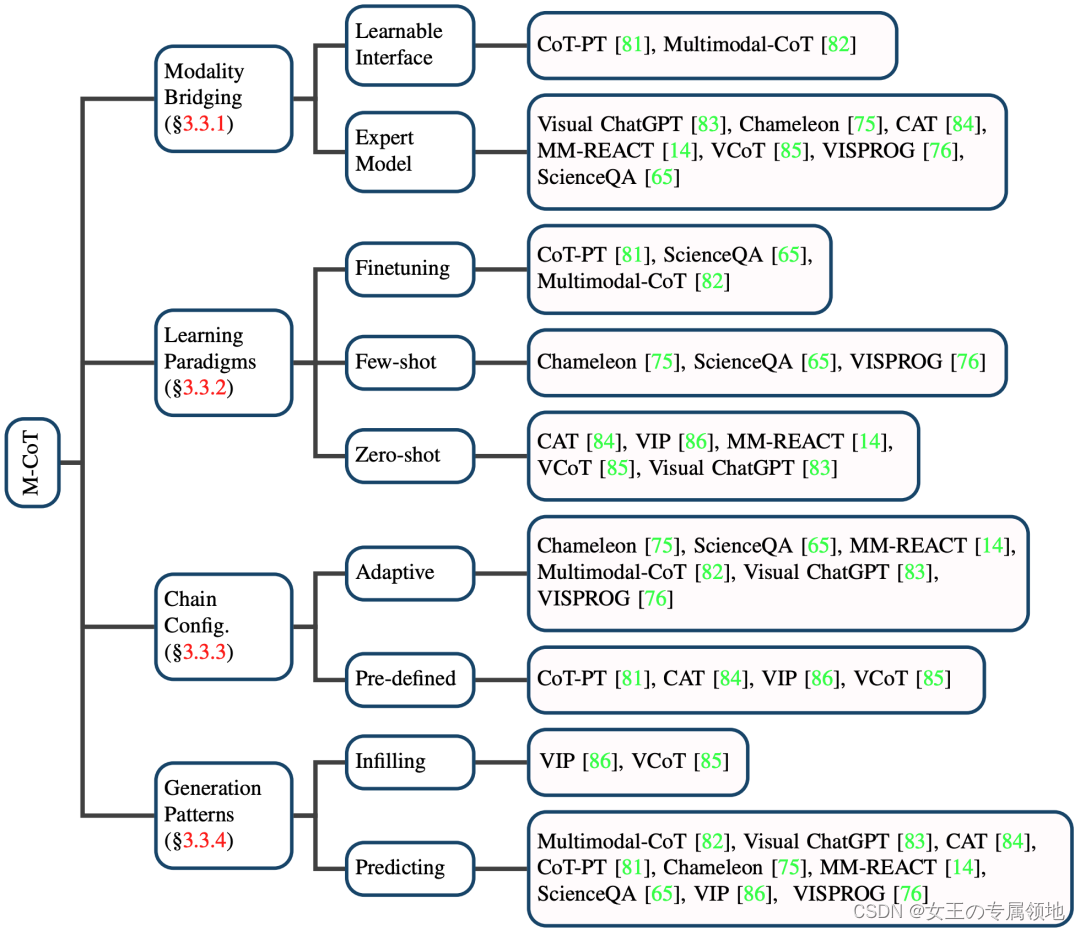
2.3 思维链(Multimodal Chain of Thought,M-CoT)
多模态思维链通过显示地逐步推理(给出中间的推理步骤)来获得多模态任务的答案。相比于直接输出答案,M-CoT在较为复杂的推理任务上能够取得更好的表现。我们从模态桥接(Modality Bridging)、学习范式、思维链配置以及生成模式这四个方面总结了当前的研究:
三、主要模型
3.1 CLIP:使用对比学习实现图文对齐
2021年由OpenAI提出,利用文本信息监督视觉任务自训练,训练数据集为40亿个“文本-图像”对,采用Transformer模型对 图像的patch序列进行建模,将不同模态的原始数据映射到统一或相似的语义空间,实现不同模态信号间的相互理解,拥有寻找不 同模态数据间关系的能力。
CLIP在zero-shot上表现较好。与CV中常用的先预训练然后微调不同,CLIP可以直接使用prompt进行零样本学习图像分类,即不需 要任何训练数据,就能在某个具体下游任务上实现分类。
3.2 DALL·E2:基于CLIP实现更强大的图文跨模态生成
基于CLIP实现文本与图像的联系,基于Diffusion从视觉语义生成图像。 2022年4月由OpenAI提出,在DALL·E1的基础上进行了改进和升级,分辨率从从256x256提升到了1024 x 1024,准确性也得到了较 大提升。
除此之外,其还可以实现以下功能:
1)根据文本生成图片;
2)将图像扩展到画布之外;
3)根据文本对图像进行编辑, 实现添加或删除元素;
4)给定一张图片生成保持原风格的变体。
DALL·E2模型可以分为两部分。
- 首先是利用CLIP文本编码器将图像描述映射到表示空间;
- 其次利用前向扩散从CLIP文本编码映射 到相应的CLIP图像编码,最后通过反向扩散从表示空间映射到图像空间,生成众多可能图像中的一个。
总体来说, DALL·E2实现了功能更齐全的图文跨模态生成,图片的真实性和准确度也较以往的产品有了不错的提升。但是在生成 一些复杂图片的细节方面, DALL·E2仍面临着一些挑战。
3.3 KOSMOS-1:全能型大语言模型
将多模态特征嵌入到Transformer模型中,基于统一的模型架构实现不同模态的对齐。 2023年3月由微软提出,其可以实现文本学习、文本生成等任务,还能够将文本以外的模态(如视觉图像、语音)嵌入到模型中。 研究证明,在多个下游任务中,该模型具有非常优异的性能,例如在语言理解、视觉问答、多模态对话等。KOSMOS-1模型的参数总 量为16亿。 我们认为,随着技术的不断发展和迭代,跨模态模型处理更多模态问题的能力将不断增强,多模态感知的大融合是迈向通用人工智 能的关键一步。
3.4 GPT-4:支持图像输入的ChatGPT升级版
2023年3月14日,OpenAI发布GPT-4。GPT-4沿袭了过去GPT路线,在GPT中引入RLHF机制,并且输入窗口更大,更适合处理长文本, GPT-4的上下文长度为8192个token,远高于GPT-3的2048个token。GPT-4文字输入限制提升到了2.5万字,回答准确率姚显著高于前 模型。GPT-4在各类职业/学术考试上表现优秀,与人类相当,比如模拟律师考试,GPT-4取得了前10%的好成绩,而GPT-3.5是倒数 10%。GPT-4训练过程更加稳定,且响应不被允许请求的概率也大幅度降低。
四、应用
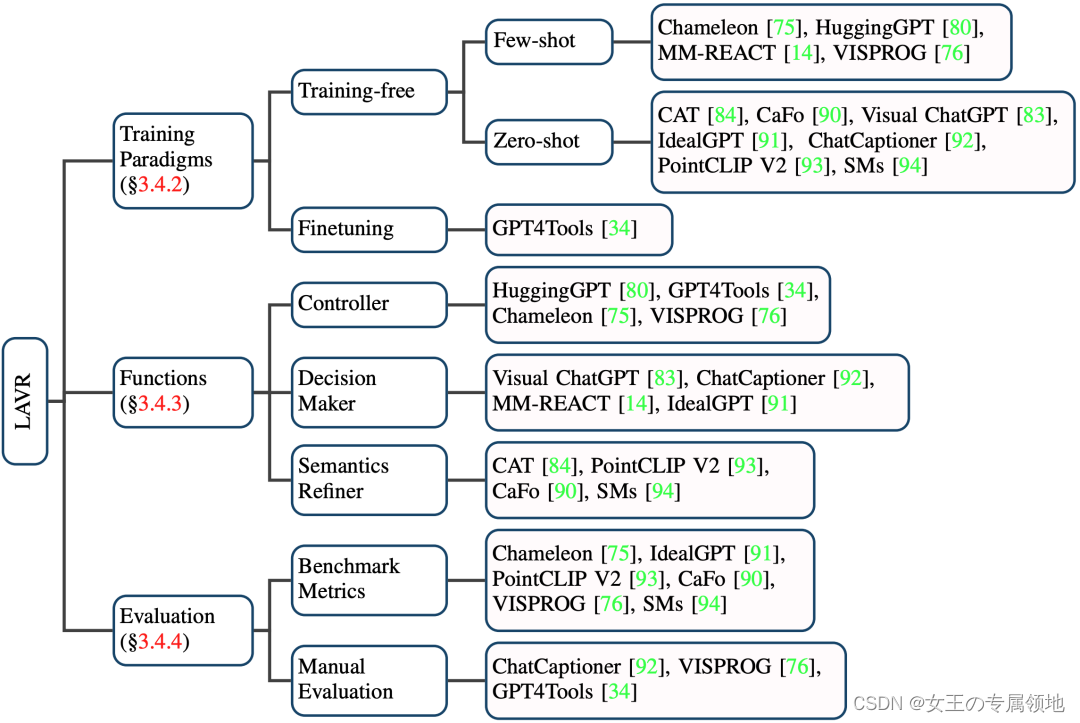
LLM辅助的视觉推理(LLM-Aided Visual Reasoning,LAVR):LLM辅助的视觉推理系统涉及几种典型的设计思路,即将LLM作为控制器、决策器或语义修饰器。
这类工作利用LLM强大的内嵌知识与能力以及其他工具,设计各种视觉推理系统。相比于传统视觉推理模型,这些工作具有以下的好的特性:
- 强大的零/少样本泛化能力。
- 具备新的能力。这些系统能够执行更加复杂的任务,如解读梗图的深层含义。
- 更好的互动性与可控性。
我们从训练范式、LLM扮演的角色以及评测三个部分总结了当前的进展:
五、未来

5.1 发展方向
1. 多模态模型要更大,模态要更多
多模态大模型需要更深层次的网络和更大的数据集进行预训练。多模态大模型多基于Transformer架构进行预训练,而 Transformer因其架构特点,未看到过拟合趋势,模型大小、数据集都未有饱和趋势,CLIP等模型也验证了数据量的大小将使得模型性能提升。以语言模型GPT为例,其从GPT1-3模型大小和预训练数据量均是逐步提升,和语言模型中类似,多模态大模型模 型大小和数据量要逐步提升,例如,谷歌前不久发布的多模态模型PaLM-E,具有5620 亿参数。 现有的多模态预训练大模型通常在视觉和语言两种模态上进行预训练,未来可以获取更多模态进行大规模预训练,包括图像、文 本、音频、时间、热图像等,基于多种模态数据的预训练大模型具有更广阔的应用潜力。
2. 多模态模型训练要加速
虽然多模态大模型在多个领域取得了巨大成功,但是多模态模型对算力的要求还是对模型的训练造成了很大的难题,因此对模型训练加速提出了进一步要求。 DeCLIP在CLIP基础上,通过改进数据处理方式加速模型训练;ViLT通过对使用更加有效率的方式对图像特征进行编码提升后续效 率;此外,训练过程中的并行策略、显存优化、模型稀疏性等均可以提升模型计算效率。
3. 多模态大模型将走向“真正统一”
以微软KOSMOS-1为代表,将图像、音频进一步编码成文本格式,统一成文本进行融合,KOSMOS-1 的模型主干是一个基于 Transformer 的因果语言模型,Transformer 解码器用作多模态输入的通用接口,除了文本之外,其他模态也能被嵌入并输入到 该模型中。谷歌发布PaLM-E,使用Uni-Perceiver,打造“通才”,将不同模态的数据编码到统一的表示空间中,并将不同任务 统一为相同的形式。
4. 多模态预训练将引入更多外部知识
多模态模型的知识是从预训练数据集得到的,但一些任务,例如视觉问答非常依赖常识信息,这些信息是从特定任务数据集中没 法学习到,因此可以将外部知识引入到模型中,补充模型知识,从而在一些问答任务场景下取得更好的成绩。
MAVEx模型使用当前先进的 VQA 模型生成一组候选答案,再将问题和候选答案解析,以检索外部知识,最后预测每个知识来源对 每个候选答案的可信度,预测最匹配的答案。MAVEx 展示了答案引导知识检索的明显优势,在 OK-VQA 数据集上实现了最先进的 性能。随着多模态模型变大,最终训练出来的模型会越来越好,伴随更多模态的加入,最终多模态大模型会应用在越来越多方面, AI正加速奔向通用AI。
5.2 挑战
目前来看,MLLM的发展还处于起步阶段,无论是相关技术还是具体应用都还存在着许多挑战与可研究的问题,我们总结为以下几点:
- 现有MLLM的感知能力受限,导致获取的视觉信息不完整或者有误,并进一步使得后续的推理出错。这可能是因为现有模型在信息容量和计算负担之间的妥协造成的。
- MLLM的推理链较为脆弱。表现为即使是做简单的多模态推理问题,模型有时仍会因为推理链条断裂导致输出错误答案。
- MLLM的指令服从能力需要进一步提升。表现为在进行指令微调后,即使是较为简单的指令,部分MLLM仍然无法输出预期的答案。
- 物体幻视问题普遍存在。表现为MLLM输出的回复与图片的内容不相符,出现了编造物体等现象,影响了MLLM的可靠性。
- 高效参数训练。由于MLLM的模型容量很大,在计算资源受限的条件下,高效参数训练有望能够解锁更多MLLM的能力。
六、拓展资料
课程资源
多模态大模型榜单:
- https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models/tree/Evaluation
论文地址:
-
综述:https://arxiv.org/abs/2306.13549
-
评测:https://arxiv.org/abs/2306.13394
-
综述:https://arxiv.org/abs/2309.10020
-
- 论文标题:MM-LLMs: Recent Advances in MultiModal Large Language Models
- 论文链接:https://arxiv.org/abs/2401.13601
-
《A Survey on Multimodal Large Language Models》
- https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
- https://zhuanlan.zhihu.com/p/625926419

