
- 1uboot代码分析_uboot 源码分析
- 2windows下使用ngrok让本地flask服务外网可访问_flask 发布到网上别人可以访问
- 3#if defined 宏定义常用“与”、“或”、“非”判断_ifdef判断两个宏
- 4github搭建博客_怎么搭建github
- 5总结:Prometheus长期存储方案_prometheus 存储
- 6496.下一个更大的元素
- 7分布式系统共识机制:一致性算法设计思想_分布式系统一致性设计
- 8【云计算学习教程】用户如何使用云服务产品?_云服务消费者从云服务提供商或者云服务代理商那里租赁云服务产品在合同期内和
- 9少年侠客【InsCode Stable Diffusion美图活动一期】_stable diffusion调参
- 10[论文笔记]LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
IT学习笔记--Kafka
赞
踩
Kafka概述:
定义:
Kafka是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。
消息队列消息队列的两种模式:
- 点对点模式:
消息生产者生产消息发送到Queue中,然后消息消费者从Queue中取出并且消费消息。
消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
- 发布/订阅模式(一对多,消费者消费数据之后不会清除消息):
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。
Kafka的基本架构:
基础架构:
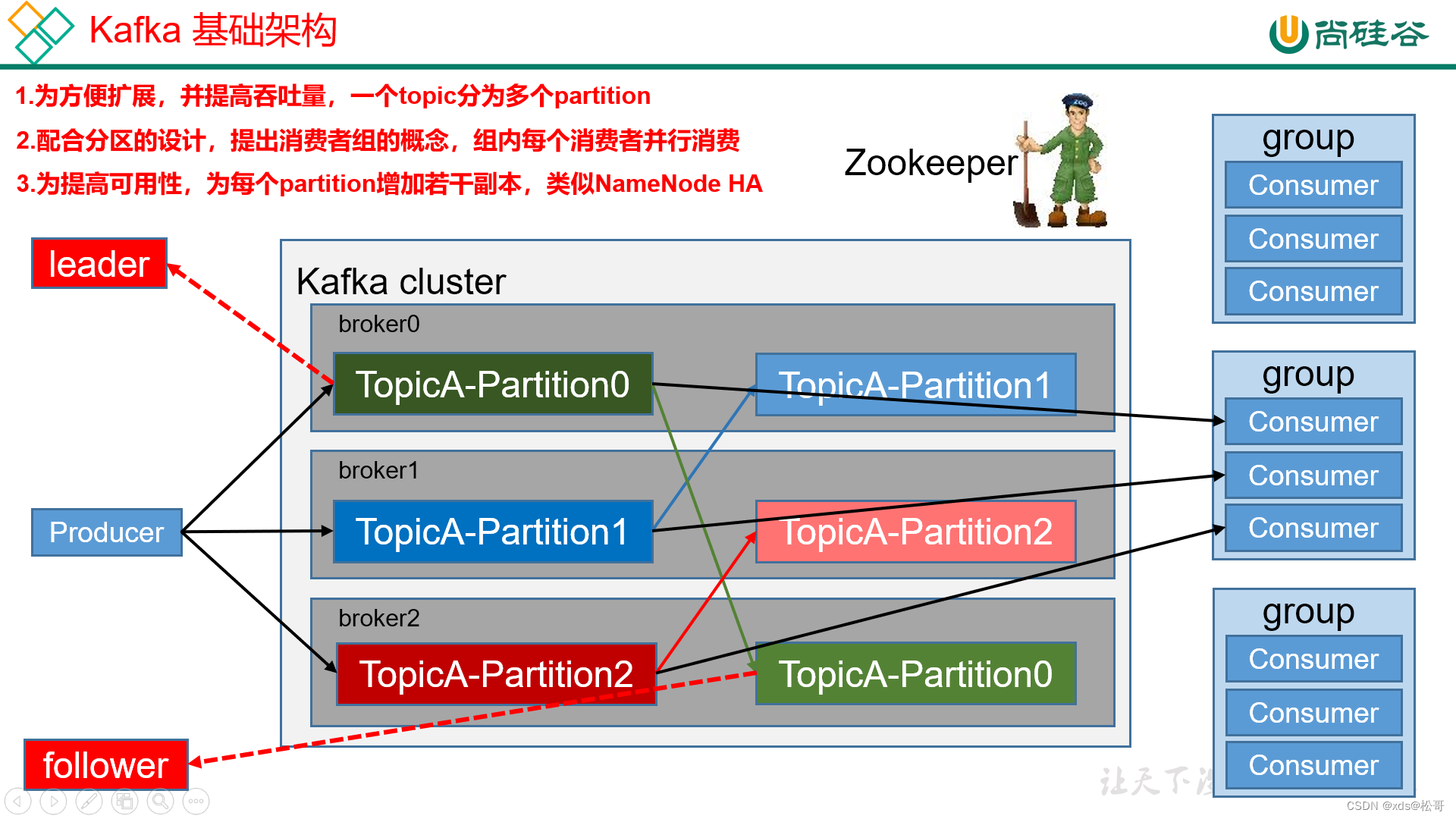
- Producer:消息生产者,就是向kafka broker发消息的客户端;
- Consumer:消息消费者,向kafka broker取消息的客户端;
- Consumer Group (CG):消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个消费者消费;消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
- Broker:一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
- Topic:可以理解为一个队列,生产者和消费者面向的都是一个topic;
- Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列;
- Replica:副本,为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,kafka提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower。
- Leader:每个分区多个副本的“主”,生产者发送数据的对象,以及消费者消费数据的对象都是leader。
- Follower:每个分区多个副本中的“从”,实时从leader中同步数据,保持和leader数据的同步。leader发生故障时,某个follower会成为新的follower。
kafka中partition和消费者对应关系:
1个partition只能被同组的一个consumer消费,同组的consumer则起到均衡效果。
- 消费者多于partition:同一个partition内的消息只能被同一个组中的一个consumer消费。当消费者数量多于partition的数量时,多余的消费者空闲。
- 消费者少于和等于partition:消息在同一个组之间的消费者之间均分。
- 多个消费者组:启动多个组,则会使同一个消息被消费多次。
Kafka文件存储机制:
Kafka中消息是以topic进行分类的,生产者生产消息,消费者消费消息,都是面向topic的。
topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是producer生产的数据。Producer生产的数据会被不断追加到该log文件末端,且每条数据都有自己的offset。消费者组中的每个消费者,都会实时记录自己消费到了哪个offset,以便出错恢复时,从上次的位置继续消费。
由于生产者生产的消息会不断追加到log文件末尾,为防止log文件过大导致数据定位效率低下,Kafka采取了分片和索引机制,将每个partition分为多个segment。每个segment对应两个文件——“.index”文件和“.log”文件。这些文件位于一个文件夹下,该文件夹的命名规则为:topic名称+分区序号。例如,first这个topic有三个分区,则其对应的文件夹为first-0,first-1,first-2。
index和log文件以当前segment的第一条消息的offset命名;“.index”文件存储大量的索引信息,“.log”文件存储大量的数据,索引文件中的元数据指向对应数据文件中message的物理偏移地址。
生产者:
分区原因:
- 方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了。
- 可以提高并发,因为可以以Partition为单位读写了。
如何保证数据可靠性:
为保证producer发送的数据,能可靠的发送到指定的topic,topic的每个partition收到producer发送的数据后,都需要向producer发送ack(acknowledgement确认收到),如果producer收到ack,就会进行下一轮的发送,否则重新发送数据。
副本的同步策略:
| 方案 | 优点 | 缺点 |
|---|---|---|
| 半数以上完成同步,就发送ack | 延迟低 | 选举新的leader时,容忍n台节点的故障,需要2n+1个副本 |
| 全部完成同步,才发送ack | 选举新的leader时,容忍n台节点的故障,需要n+1个副本 | 延迟高 |
Kafka选择了第二种方案,原因如下:
- 同样为了容忍n台节点的故障,第一种方案需要2n+1个副本,而第二种方案只需要n+1个副本,而Kafka的每个分区都有大量的数据,第一种方案会造成大量数据的冗余。
- 虽然第二种方案的网络延迟会比较高,但网络延迟对Kafka的影响较小。
ACK应答机制:
Kafka为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡,选择以下的配置。acks参数配置:
- 0:producer不等待broker的ack,这一操作提供了一个最低的延迟,broker一接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据;
- 1:producer等待broker的ack,partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将会丢失数据;
- -1(all):producer等待broker的ack,partition的leader和follower全部落盘成功后才返回ack。但是如果在follower同步完成后,broker发送ack之前,leader发生故障,那么会造成数据重复。
消费者:
消费方式:
consumer采用pull(拉)模式从broker中读取数据;push(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息。
pull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,Kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时长即为timeout。
分区分配策略:
一个consumer group中有多个consumer,一个 topic有多个partition,所以必然会涉及到partition的分配问题,即确定那个partition由哪个consumer来消费。
Kafka有两种分配策略,一是roundrobin,一是range。
offest维护:
由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。
Kafka 0.9版本之前,consumer默认将offset保存在Zookeeper中,从0.9版本开始,consumer默认将offset保存在Kafka一个内置的topic中,该topic为__consumer_offsets。

