
- 1aws lakeformation跨账号共享数据的两种方式和相关配置
- 2代码随想录算法训练营Day54|LeetCode123买卖股票的最佳时机III、LeetCode188买卖股票的最佳时机IV(补卡)
- 32020B证(安全员)考试及B证(安全员)考试试题_.通过对一些典型事故进行原因分析、事故教训及预防事故发生所回提供施工现场
- 4【哈希冲突解决】线性探测再散列和二次探测再散列_线性探测再散列二次探测再散列
- 5安装nginx
- 630道软件测试基础面试题!(含答案)_软件测试面试常见问题及答案
- 7SparkStreaming 实现黑名单过滤功能_套接字流实现黑名单过滤
- 8Python-VBA函数之旅-property函数_vbaproperty
- 9糖尿病预测 - 基于Pima Indians糖尿病数据集的分析_pimaindiansdiabetes2数据集介绍
- 10Python学习笔记 - 探索字符串格式化
为什么大模型需要向量数据库?_大模型向量存储维度
赞
踩
AIGC 时代万物都可以向量化,向量化是 LLM 大模型以及 Agent 应用的基础。
比如:爆火的 Google 大模型 Gemini 1.0 原生支持的多模态,在预训练的时候就是把文本、图片、音频、视频等多模态先进行 token 化,然后构建一维的“语言”序列,再进行向量化,实现了原生多模态的支持。
向量技术是向量数据库的核心,一个企业级的向量数据库,在功能维度需要具备 Embedding 嵌入生成向量数据、向量数据存储、向量数据相似度检索、提供 "CRUD” API 接口等,在性能维度需要提供分布式架构提供无缝的弹性伸缩功能以支持用户访问请求的高吞吐量和低延迟。在可观性维度需要提供自动化部署、立体监控、业务调试、业务测试、业务评估等功能。
向量数据库的优势
向量数据库相对于传统数据库具有几项重要的优势,特别是在处理大规模高维度向量数据时:
-
高效的相似度搜索: 向量数据库设计旨在快速执行相似度搜索,这意味着它们能够有效地处理大规模的向量数据集,并且能够在其中快速找到最相似的向量。这对于许多应用场景,如推荐系统、图像识别、自然语言处理等是至关重要的。
-
针对向量的优化存储和索引结构: 传统数据库通常使用 B 树或者哈希索引来支持数据检索,但这些索引结构不太适合高维度向量数据的相似度搜索。向量数据库采用了更适合向量数据的存储和索引结构,如向量树、局部敏感哈希(LSH)等,这些结构可以更有效地支持向量数据的相似度搜索。
-
内置向量运算支持: 一些向量数据库提供了内置的向量运算功能,如向量加法、减法、乘法、点积等,这些功能可以直接在数据库中进行向量计算,而无需将数据提取到应用程序中进行处理,从而提高了处理效率并降低了网络通信成本。
-
实时更新和查询: 向量数据库通常能够支持实时更新和查询,这意味着它们能够快速响应数据的变化,并且能够在实时环境下进行相似度搜索和数据分析。
-
容易扩展和部署: 高性能的向量数据库通常支持水平扩展,可以轻松地在集群中添加新节点来处理更多的数据和请求,同时还能保持较高的性能。
总体而言,向量数据库在处理高维度向量数据和执行相似度搜索方面具有明显的优势,能够更好地满足现代数据应用的需求。
向量数据库如何选型
如果你需要快速构建原型系统并对性能有一定要求,Faiss 可能是一个好选择。
Faiss 是 Meta 开源的一个库,用于高效相似性搜索和密集向量聚类。它能处理任意大小的向量集合,甚至是无法全部装入内存的集合。Faiss 还包含了用于评估和参数调优的工具。Faiss 是用 C++ 编写的,但提供了完整的 Python/NumPy 接口。
Faiss 足够简单,性能似乎也足够快,也能够应付小规模的生产场景。当然,还可以通过量化、降维、使用 GPU 等方案进一步提升查询性能。
然而,尽管向量搜索库,比如 Faiss 提供了强大和高效的向量搜索功能,但在实际生产环境中,它们存在一些限制。Faiss 并没有提供处理数据的实时增删、缺乏多语言的支持,无法提供远程调用、不支持标量过滤、也不提供数据的持久化,可扩展性和容灾等问题的解决方案。
正是因为这些原因,向量数据库应运而生,为我们提供了一种更完整、更适合实际应用场景的解决方案。
向量数据库战场目前主要分为四个类别:
-
基于 PG、Clickhouse 等进行魔改或者插件化实现的向量数据库。这类解决方案以现有的关系数据库或列存数据库作为基础,通过修改或插件扩展的方式添加向量搜索功能,PG Vector是这类解决方案的代表产品。
-
基于传统倒排搜索添加稠密向量索引支持的向量数据库。这类解决方案以倒排索引搜索引擎作为基础,通过扩展索引机制以支持向量搜索,ElasticSearch是这类解决方案的代表产品。
-
基于向量检索库实现的轻量级向量数据库。这类解决方案以向量搜索库(如 Faiss)为核心,围绕其构建数据库功能。这些产品通常具有较小的体积和较高的运行效率,Chroma 是这类解决方案的代表产品。
-
基于原生向量设计的分布式向量云原生数据数据库。这类解决方案从零开始设计和实现向量数据库,整个系统从底层到顶层都针对向量搜索进行了优化,通常提供了更完整和高级的功能,包括分布式计算、容灾备份、数据持久化等,Zilliz Cloud/Milvus 是这类解决方案的代表产品。
不过,“Not All Vector Database are born equal”(并非所有向量数据库都生来平等)。在各类向量数据库中,每种解决方案都有其独特的优点和限制,并且它们各自适合于不同的应用场景。
在所有的向量数据库方案中,我个人对基于 PG、Clickhouse等进行魔改或者插件化实现的向量数据库(如 PG Vector)以及基于原生向量设计的分布式向量云原生数据数据库(例如 Zilliz Cloud/Milvus)这两种截然不同的解决方案特别看好。
还有更多选型落地场景,今晚20点直播中详细剖析,请同学们点击免费预约。
总之,掌握好向量数据库的选型和落地实现,对于 IT 人来说是一项非常重要的技能。
基于向量数据库完成 RAG 业务实际工作
第一、基于向量数据库实现 RAG(Retrieval Augmented Generation)应用
RAG 是一种使用企业级私有和实时的数据用来增强 LLM 大模型能力的一种技术,由两个步骤构成:建立向量索引(Indexing)和检索生成(Retrieval and Generation)。
建立向量索引(Indexing)由加载外部知识(Load)、切分大文本为小的单元块(Split)、向量存储(Store)三步组成。
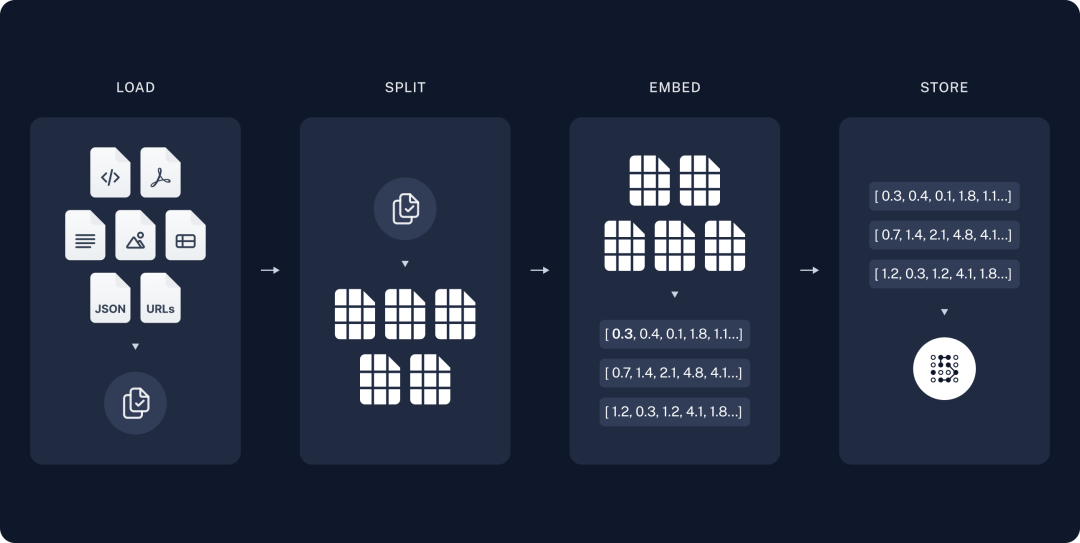
检索生成(Retrieval and Generation)由向量知识库检索最相似的 TopK 记录(Retrieve)和 LLM 大模型生成结果(Generate)两步构成。
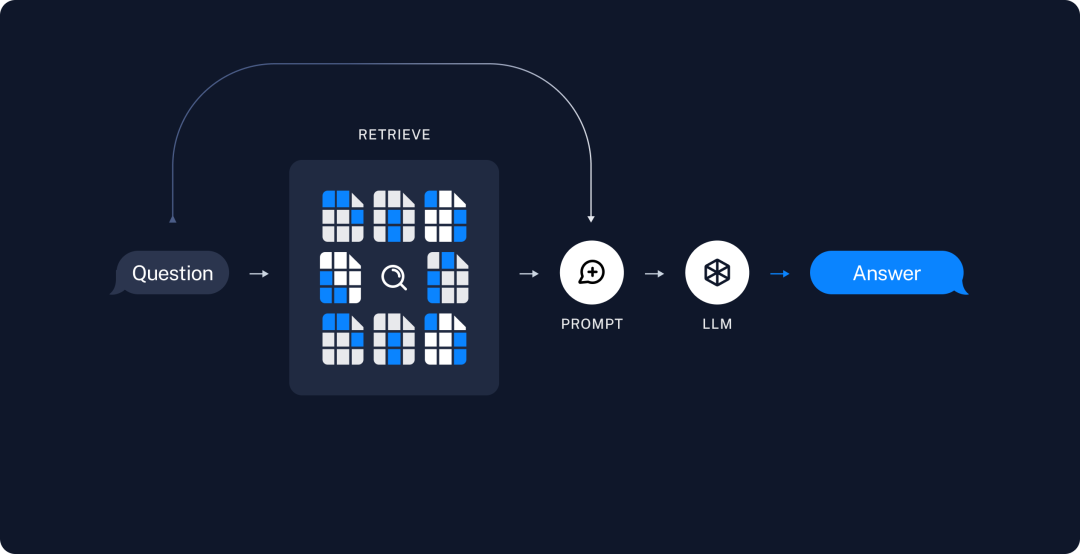
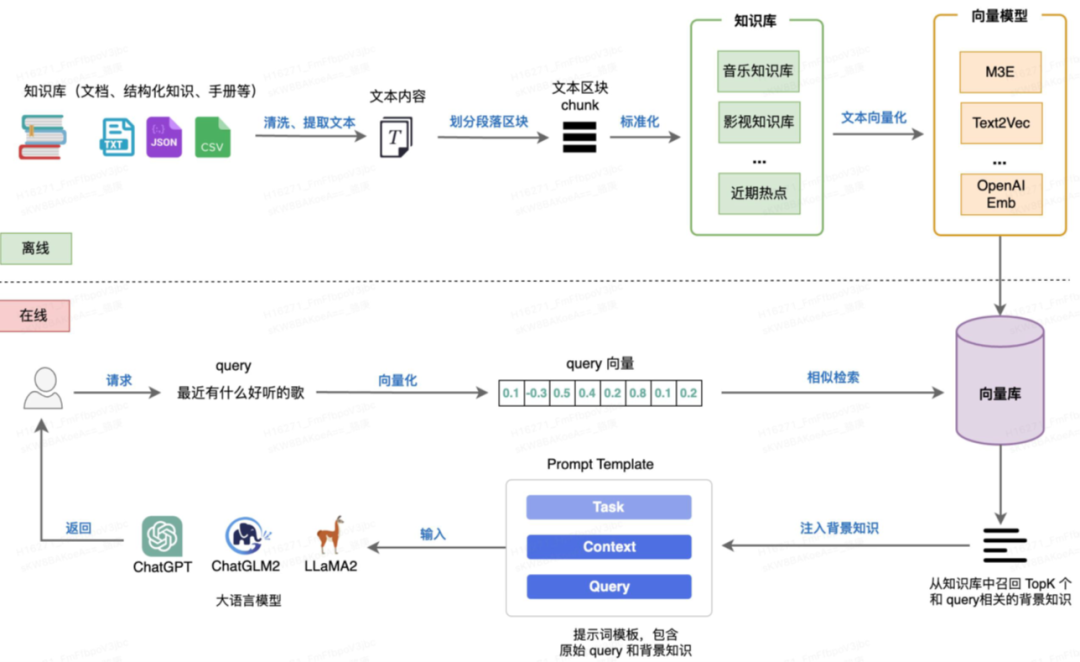
总体来讲,分为离线建立向量数据部分和在线相似度增强和检索部分,如下图所示。
第二、使用 OpenAI Assistants 实现 RAG 应用
乍一看,OpenAI Assistants 自带的检索功能十分强大,但如果对行业足够了解,便会发现其仍存在诸多限制。OpenAI Assistants 检索严格限制了数据规模,且缺乏定制化的能力。因此,搭建高效的应用还需要使用自定义的检索器。
所幸,OpenAI 的函数调用能力允许开发者无缝接入自定义的检索器,从而打破对于知识库数据量的限制,更好地适应多样化的用例。
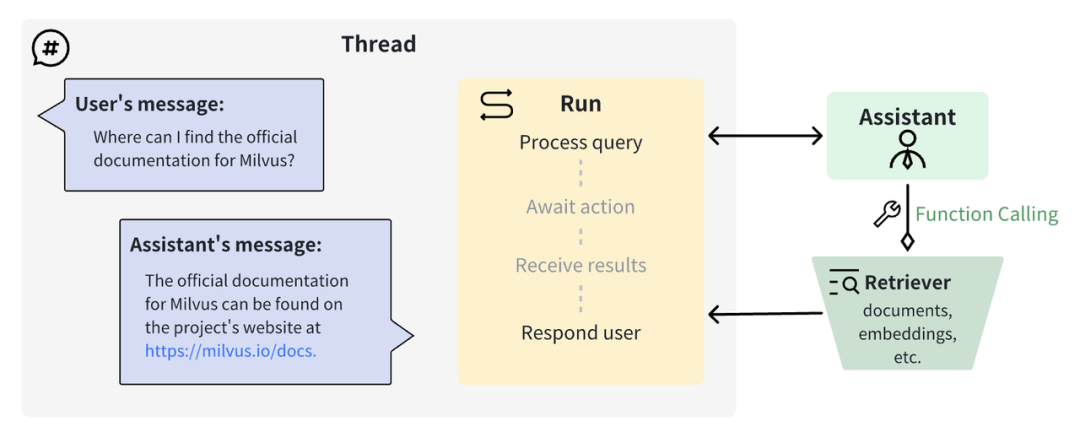
我们可以使用 Milvus 实现 OpenAI Assistants 检索定制化。
Milvus 是一款高度灵活、可扩展的开源向量数据库,毫秒内即可实现十亿级别向量的存储和检索。由于优秀的扩展性和超低的查询延时,Milvus 是定制 OpenAI Assistants 检索的首选,下图为 OpenAI Assistant 函数调用通用的工作原理。
总之,掌握好基于向量数据库的 RAG 业务应用落地实现,对于 IT 人来说是一项非常重要的技能
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了大模型技术交流群,本文完整代码、相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流


