
- 1Window 11本地部署 Meta Llama3-8b_llama3 windows
- 23月9日 笔记:RANSAC随机样本一致性,灭点、对极几何计算、H矩阵、PNP估计相机位置,3D匹配、投影变换、N点定位求解姿态_内参k、外参r、t生成h
- 3计算机网络基础知识 学习笔记_计算机网络技术基础第五版笔记
- 4如何使用Python进行数据分析【新手必看、高手备查】_怎么用python进行数据分析
- 5爬虫实战(三) 用Python爬取拉勾网_python爬拉钩网
- 6521源码-免费网络教程-Linux如何增加安全组端口(命令行方式)
- 7小朋友也能听懂的Rust网络编程框架知识-Tokio基础篇
- 8Hive窗口函数案例_jack,2017-01-01、
- 9vscode编译和调试wsl环境的c语言程序
- 10在自己笔记本上使用 Llama-3 生成 PowerPoint — 幻灯片自动化的第一步_llama3 制作ppt
NLP学习笔记九-机器翻译-seq2seq模型_seq2seq模型已经在翻译领域
赞
踩
NLP学习笔记九-机器翻译-seq2seq模型
seq2seq模型是做机器翻译任务的,根据名字其实我们也能有一些推测seq 2 seq,其实就是sequence to sequence,从一个序列到另一个序列,所以seq2seq模型其实不止可以做机器翻译,还可以做序列转换,序列编码这些任务。
seq2seq模型跟lstm模型有很大关系。
拿英语翻译成德语为例。
seq2seq模型结构如下:

上述的模型其实并不复杂,主要还是需要知晓lstm模型的一些原理,这在之前的博客中,我们做了一些讲解了。
lstm模型最终会输出记忆信息c和最终的输出h,其实我认为,c就是对应RNN里的最终输出h,lstm的最终输出h则是对c进行了一次输出门处理,也就是进行了一次tanh操作和遗忘处理。其实我觉得c中基本上包含了h的信息,但其实lstm只是为了延续RNN模型,按理来说可以只输出记忆信息c的应该就够了。
对于英语翻译德语,我们需要对英语每个字符进行one-hot编码,编码成一个只含有一个1的01向量,比如
a-[1,0,0,0,0,]
为什么不用embeding,因为每个字符没什么相关性,然后,我们将一段文本比如I like apple.输入下属lstm模型。
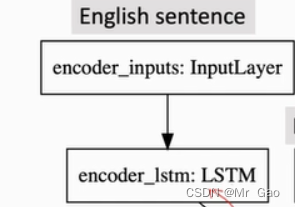
上面其实是指lstm模型,说是输入编码,其实就是一个lstm模型,之后该模型会对我们输入的文本向量矩阵进行特征提出得到
c
1
和
h
1
c_1和h_1
c1和h1。
再次基础上,将德语已经翻译好的句子的第一个字符也进行one-hot编码得到t,将(c,h)和t按照lstm模型流程,t作为x输入,(c,h)作为上一个单元得到的记忆信息和输出然后得到德语下一个预测字符,将下一个预测字符作为x,上一次得到的(c,h)再输入,就变成正常的lstm模型了。
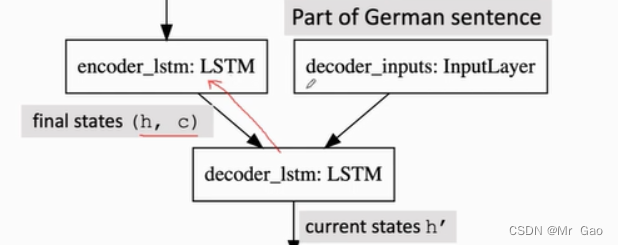
当然,每次都要进行梯度更新参数。我们输入都是按照正确的输入进行输入,再根据预测概率p,求解损失crossEntropy(p,y),去更新网络。

