
- 1Unity性能优化 - 动态图集_unity 动态图集
- 2【games101】作业笔记——作业3_games101笔记
- 3element-ui table 默认勾选 、编辑自动勾选_el table中点击行默认打勾
- 4pytorch冻结BN和一些moudel_冻结bn层是什么意思
- 5【Qt IFW】 覆盖安装向导制作_binarycreator 制作卸载
- 6imu姿态融合基础_imu 姿态融合算法
- 7Python正则表达式
- 8详解MySQL事务日志——undo log_undo log存的是什么
- 9【OpenCV】为树莓派(ARM)交叉编译OpenCV_树莓派交叉编译移植opencv
- 10Caused by: java.lang.ClassNotFoundException: Could not load requested class : com.mysql.jdbc.Driver
Sklearn、TensorFlow 与 Keras 机器学习实用指南第三版(六)
赞
踩
原文:Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow
译者:飞龙
第十四章:使用卷积神经网络进行深度计算机视觉
尽管 IBM 的 Deep Blue 超级计算机在 1996 年击败了国际象棋世界冠军加里·卡斯帕罗夫,但直到最近计算机才能可靠地执行看似微不足道的任务,比如在图片中检测小狗或识别口语。为什么这些任务对我们人类来说如此轻松?答案在于感知主要发生在我们的意识领域之外,在我们大脑中专门的视觉、听觉和其他感觉模块中。当感觉信息达到我们的意识时,它已经被赋予高级特征;例如,当你看到一张可爱小狗的图片时,你无法选择不看到小狗,不注意到它的可爱。你也无法解释如何识别一个可爱的小狗;对你来说这是显而易见的。因此,我们不能信任我们的主观经验:感知并不是微不足道的,要理解它,我们必须看看我们的感觉模块是如何工作的。
卷积神经网络(CNNs)起源于对大脑视觉皮层的研究,自上世纪 80 年代以来就被用于计算机图像识别。在过去的 10 年里,由于计算能力的增加、可用训练数据的增加,以及第十一章中介绍的用于训练深度网络的技巧,CNNs 已经成功在一些复杂的视觉任务上实现了超人类表现。它们驱动着图像搜索服务、自动驾驶汽车、自动视频分类系统等。此外,CNNs 并不局限于视觉感知:它们在许多其他任务上也取得了成功,比如语音识别和自然语言处理。然而,我们现在将专注于视觉应用。
在本章中,我们将探讨 CNNs 的起源,它们的构建模块是什么样的,以及如何使用 Keras 实现它们。然后我们将讨论一些最佳的 CNN 架构,以及其他视觉任务,包括目标检测(对图像中的多个对象进行分类并在其周围放置边界框)和语义分割(根据对象所属的类别对每个像素进行分类)。
视觉皮层的结构
David H. Hubel 和 Torsten Wiesel 在1958 年对猫进行了一系列实验¹,1959 年(以及几年后对猴子进行的实验^(3)),为视觉皮层的结构提供了关键见解(这两位作者因其工作于 1981 年获得了诺贝尔生理学或医学奖)。特别是,他们表明视觉皮层中许多神经元具有小的局部感受野,这意味着它们只对位于视觉场有限区域内的视觉刺激做出反应(见图 14-1,其中五个神经元的局部感受野由虚线圈表示)。不同神经元的感受野可能重叠,它们共同覆盖整个视觉场。
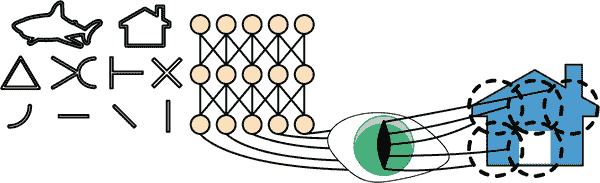
图 14-1. 视觉皮层中的生物神经元对视觉场中称为感受野的小区域中的特定模式做出反应;随着视觉信号通过连续的大脑模块,神经元对更大感受野中的更复杂模式做出反应
此外,作者们表明,一些神经元只对水平线的图像做出反应,而另一些只对具有不同方向的线做出反应(两个神经元可能具有相同的感受野,但对不同的线方向做出反应)。他们还注意到一些神经元具有更大的感受野,它们对更复杂的模式做出反应,这些模式是低级模式的组合。这些观察结果导致了这样一个想法,即高级神经元基于相邻低级神经元的输出(在图 14-1 中,注意到每个神经元只连接到前一层附近的神经元)。这种强大的架构能够在视觉领域的任何区域检测各种复杂的模式。
这些对视觉皮层的研究启发了 1980 年引入的neocognitron,逐渐演变成我们现在称之为卷积神经网络的东西。一个重要的里程碑是 Yann LeCun 等人在 1998 年发表的一篇论文,介绍了著名的LeNet-5架构,这种架构被银行广泛用于识别支票上的手写数字。这种架构具有一些你已经了解的构建块,如全连接层和 Sigmoid 激活函数,但它还引入了两个新的构建块:卷积层和池化层。现在让我们来看看它们。
注意
为什么不简单地使用具有全连接层的深度神经网络来进行图像识别任务呢?不幸的是,尽管这对于小图像(例如 MNIST)效果很好,但对于较大的图像来说,由于需要的参数数量巨大,它会崩溃。例如,一个 100×100 像素的图像有 10,000 个像素,如果第一层只有 1,000 个神经元(这已经严重限制了传递到下一层的信息量),这意味着总共有 1 千万个连接。而这只是第一层。CNN 通过部分连接的层和权重共享来解决这个问题。
卷积层
CNN 最重要的构建块是卷积层:第一个卷积层中的神经元不与输入图像中的每个像素相连接(就像在前几章讨论的层中那样),而只与其感受野中的像素相连接(参见图 14-2)。反过来,第二个卷积层中的每个神经元只与第一层中一个小矩形内的神经元相连接。这种架构允许网络在第一个隐藏层集中于小的低级特征,然后在下一个隐藏层中将它们组合成更大的高级特征,依此类推。这种分层结构在现实世界的图像中很常见,这也是 CNN 在图像识别方面表现出色的原因之一。
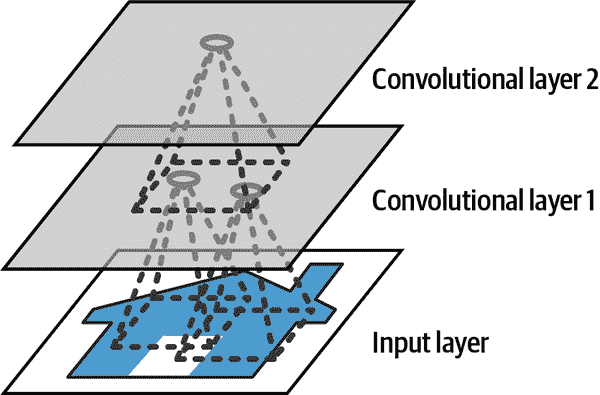
图 14-2。具有矩形局部感受野的 CNN 层
注意
到目前为止,我们看到的所有多层神经网络都由一长串神经元组成,我们必须在将输入图像馈送到神经网络之前将其展平为 1D。在 CNN 中,每一层都以 2D 表示,这使得更容易将神经元与其对应的输入匹配。
给定层中位于第i行,第j列的神经元连接到前一层中位于第i到第i + f[h] – 1 行,第j到第j + f[w] – 1 列的神经元的输出,其中f[h]和f[w]是感受野的高度和宽度(参见图 14-3)。为了使一层具有与前一层相同的高度和宽度,通常在输入周围添加零,如图中所示。这称为零填充。
还可以通过间隔感受野来将大输入层连接到一个较小的层,如图 14-4 所示。这显着降低了模型的计算复杂性。从一个感受野到下一个感受野的水平或垂直步长称为步幅。在图中,一个 5×7 的输入层(加上零填充)连接到一个 3×4 的层,使用 3×3 的感受野和步幅为 2(在这个例子中,步幅在两个方向上是相同的,但不一定要这样)。上层中位于第i行,第j列的神经元连接到前一层中位于第i×s[h]到第i×s[h]+f[h]–1 行,第j×s[w]到第j×s[w]+f[w]–1 列的神经元的输出,其中s[h]和s[w]是垂直和水平步幅。
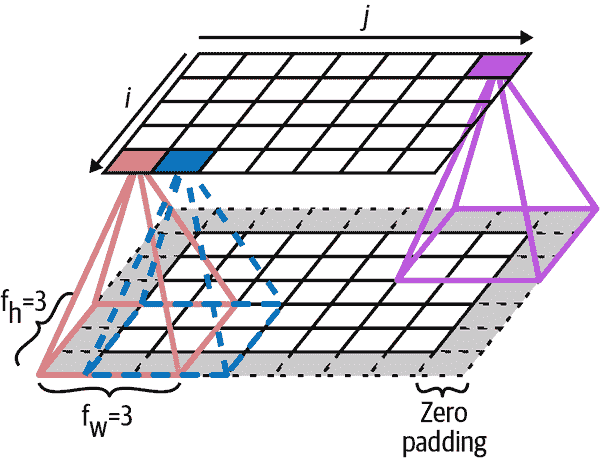
图 14-3。层与零填充之间的连接
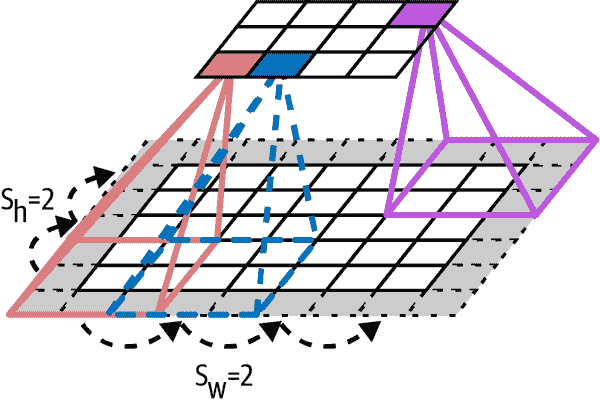
图 14-4。使用步幅为 2 降低维度
滤波器
一个神经元的权重可以表示为一个与感受野大小相同的小图像。例如,图 14-5 显示了两组可能的权重,称为滤波器(或卷积核,或只是内核)。第一个滤波器表示为一个黑色正方形,中间有一条垂直白线(它是一个 7×7 的矩阵,除了中间列全是 1,其他都是 0);使用这些权重的神经元将忽略其感受野中的所有内容,除了中间的垂直线(因为所有输入将被乘以 0,除了中间的垂直线)。第二个滤波器是一个黑色正方形,中间有一条水平白线。使用这些权重的神经元将忽略其感受野中的所有内容,除了中间的水平线。
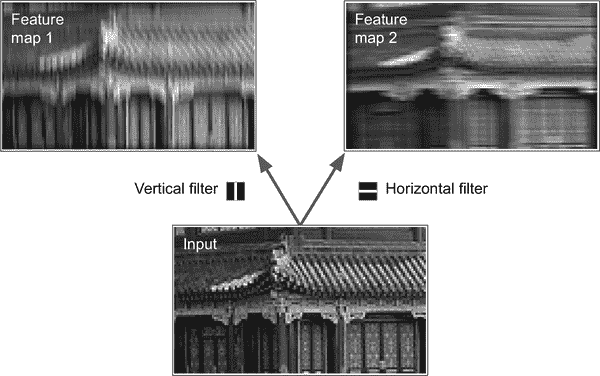
图 14-5。应用两个不同的滤波器以获得两个特征图
现在,如果一个层中的所有神经元使用相同的垂直线滤波器(和相同的偏置项),并且您将输入图像输入到网络中,如图 14-5 所示(底部图像),该层将输出左上角的图像。请注意,垂直白线得到增强,而其余部分变得模糊。类似地,如果所有神经元使用相同的水平线滤波器,则会得到右上角的图像;请注意,水平白线得到增强,而其余部分被模糊化。因此,一个充满使用相同滤波器的神经元的层会输出一个特征图,突出显示激活滤波器最多的图像区域。但不用担心,您不必手动定义滤波器:相反,在训练期间,卷积层将自动学习其任务中最有用的滤波器,上面的层将学会将它们组合成更复杂的模式。
堆叠多个特征图
到目前为止,为了简单起见,我已经将每个卷积层的输出表示为一个 2D 层,但实际上,卷积层有多个滤波器(您决定有多少个),并且每个滤波器输出一个特征图,因此在 3D 中更准确地表示(请参见图 14-6)。每个特征图中的每个像素都有一个神经元,并且给定特征图中的所有神经元共享相同的参数(即相同的内核和偏置项)。不同特征图中的神经元使用不同的参数。神经元的感受野与之前描述的相同,但它跨越了前一层的所有特征图。简而言之,卷积层同时将多个可训练滤波器应用于其输入,使其能够在其输入的任何位置检测多个特征。
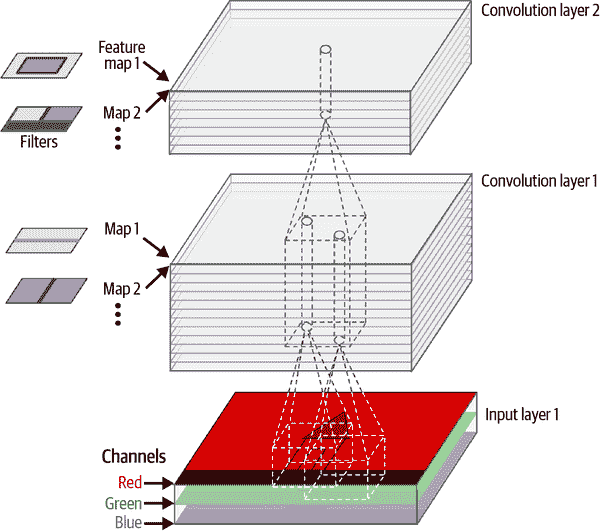
图 14-6。两个具有多个滤波器(内核)的卷积层,处理具有三个颜色通道的彩色图像;每个卷积层输出一个特征图每个滤波器
注意
所有特征图中的所有神经元共享相同的参数,这显著减少了模型中的参数数量。一旦 CNN 学会在一个位置识别模式,它就可以在任何其他位置识别它。相比之下,一旦全连接的神经网络学会在一个位置识别模式,它只能在那个特定位置识别它。
输入图像也由多个子层组成:每个颜色通道一个。如第九章中所述,通常有三个:红色、绿色和蓝色(RGB)。灰度图像只有一个通道,但有些图像可能有更多通道,例如捕捉额外光频率(如红外线)的卫星图像。
具体来说,在给定卷积层l中特征图k中第i行、第j列的神经元与前一层l – 1 中位于第i × s[h]至i × s[h] + f[h] – 1 行和第j × s[w]至j × s[w] + f[w] – 1 列的神经元的输出相连,跨所有特征图(在第l – 1 层)。请注意,在同一层中,位于相同行i和列j但在不同特征图中的所有神经元与前一层中相同位置的神经元的输出相连。
方程 14-1 总结了前面的解释,用一个大数学方程表示:它展示了如何计算卷积层中给定神经元的输出。由于所有不同的索引,它看起来有点丑陋,但它的作用只是计算所有输入的加权和,再加上偏置项。
方程 14-1。计算卷积层中神经元的输出
z i,j,k = b k + ∑ u=0 f h -1 ∑ v=0 f w -1 ∑ k‘=0 f n ’ -1 x i ‘ ,j ’ ,k ‘ × w u,v,k ’ ,k with i ‘ = i × s h + u j ’ = j × s w + v
在这个方程中:
-
z[i,] [j,] [k] 是位于卷积层(第l层)特征图k中第i行、第j列的神经元的输出。
-
如前所述,s[h] 和 s[w] 是垂直和水平步幅,f[h] 和 f[w] 是感受野的高度和宽度,f[n′] 是前一层(第l – 1 层)中特征图的数量。
-
x[i′,] [j′,] [k′] 是位于第l – 1 层,第i′行、第j′列、特征图k′(或通道k′,如果前一层是输入层)的神经元的输出。
-
b[k] 是特征图k(在第l层)的偏置项。您可以将其视为微调特征图k的整体亮度的旋钮。
-
w[u,] [v,] [k′,] [k]是层l中特征图k中的任何神经元与其输入之间的连接权重,该输入位于行u、列v(相对于神经元的感受野),以及特征图k′。
让我们看看如何使用 Keras 创建和使用卷积层。
使用 Keras 实现卷积层
首先,让我们加载和预处理一些样本图像,使用 Scikit-Learn 的load_sample_image()函数和 Keras 的CenterCrop和Rescaling层(这些都是在第十三章中介绍的):
from sklearn.datasets import load_sample_images
import tensorflow as tf
images = load_sample_images()["images"]
images = tf.keras.layers.CenterCrop(height=70, width=120)(images)
images = tf.keras.layers.Rescaling(scale=1 / 255)(images)
- 1
- 2
- 3
- 4
- 5
- 6
让我们看一下images张量的形状:
>>> images.shape
TensorShape([2, 70, 120, 3])
- 1
- 2
哎呀,这是一个 4D 张量;我们以前从未见过这个!所有这些维度是什么意思?嗯,有两个样本图像,这解释了第一个维度。然后每个图像是 70×120,因为这是我们在创建CenterCrop层时指定的大小(原始图像是 427×640)。这解释了第二和第三维度。最后,每个像素在每个颜色通道上保存一个值,有三个颜色通道——红色、绿色和蓝色,这解释了最后一个维度。
现在让我们创建一个 2D 卷积层,并将这些图像输入其中,看看输出是什么。为此,Keras 提供了一个Convolution2D层,别名为Conv2D。在幕后,这个层依赖于 TensorFlow 的tf.nn.conv2d()操作。让我们创建一个具有 32 个滤波器的卷积层,每个滤波器大小为 7×7(使用kernel_size=7,相当于使用kernel_size=(7 , 7)),并将这个层应用于我们的两个图像的小批量:
conv_layer = tf.keras.layers.Conv2D(filters=32, kernel_size=7)
fmaps = conv_layer(images)
- 1
- 2
注意
当我们谈论 2D 卷积层时,“2D”指的是空间维度(高度和宽度),但正如你所看到的,该层接受 4D 输入:正如我们所看到的,另外两个维度是批量大小(第一个维度)和通道数(最后一个维度)。
现在让我们看一下输出的形状:
>>> fmaps.shape
TensorShape([2, 64, 114, 32])
- 1
- 2
输出形状与输入形状类似,有两个主要区别。首先,有 32 个通道而不是 3 个。这是因为我们设置了filters=32,所以我们得到 32 个输出特征图:在每个位置的红色、绿色和蓝色的强度代替,我们现在有每个位置的每个特征的强度。其次,高度和宽度都减小了 6 个像素。这是因为Conv2D层默认不使用任何零填充,这意味着我们在输出特征图的两侧丢失了一些像素,取决于滤波器的大小。在这种情况下,由于卷积核大小为 7,我们水平和垂直各丢失 6 个像素(即每侧 3 个像素)。
警告
默认选项令人惊讶地被命名为padding="valid",实际上意味着根本没有零填充!这个名称来自于这样一个事实,即在这种情况下,每个神经元的感受野严格位于输入内部的有效位置(不会超出边界)。这不是 Keras 的命名怪癖:每个人都使用这种奇怪的命名法。
如果我们设置padding="same",那么输入将在所有侧面填充足够的零,以确保输出特征图最终与输入具有相同大小(因此这个选项的名称):
>>> conv_layer = tf.keras.layers.Conv2D(filters=32, kernel_size=7,
... padding="same")
...
>>> fmaps = conv_layer(images)
>>> fmaps.shape
TensorShape([2, 70, 120, 32])
- 1
- 2
- 3
- 4
- 5
- 6
这两种填充选项在图 14-7 中有所说明。为简单起见,这里只显示了水平维度,但当然相同的逻辑也适用于垂直维度。
如果步幅大于 1(在任何方向上),那么输出大小将不等于输入大小,即使padding="same"。例如,如果设置strides=2(或等效地strides=(2, 2)),那么输出特征图将是 35×60:垂直和水平方向都减半。图 14-8 展示了当strides=2时会发生什么,两种填充选项都有。
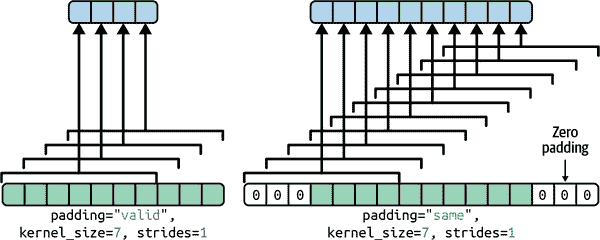
图 14-7。当strides=1时的两种填充选项
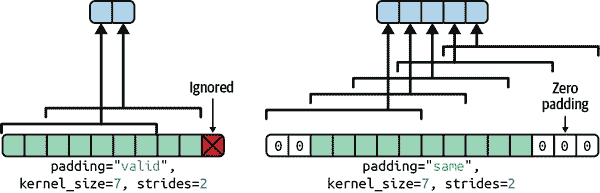
图 14-8。当步长大于 1 时,即使使用"same"填充(和"valid"填充可能会忽略一些输入),输出也会小得多
如果您感兴趣,这是输出大小是如何计算的:
-
当
padding="valid"时,如果输入的宽度为i[h],那么输出宽度等于(i[h] - f[h] + s[h]) / s[h],向下取整。请记住f[h]是卷积核的宽度,s[h]是水平步长。除法中的余数对应于输入图像右侧被忽略的列。同样的逻辑也可以用来计算输出高度,以及图像底部被忽略的行。 -
当
padding="same"时,输出宽度等于i[h] / s[h],向上取整。为了实现这一点,在输入图像的左右两侧填充适当数量的零列(如果可能的话,数量相等,或者在右侧多一个)。假设输出宽度为o[w],那么填充的零列数为(o[w] - 1) × s[h] + f[h] - i[h]。同样的逻辑也可以用来计算输出高度和填充行数。
现在让我们来看一下层的权重(在方程 14-1 中被标记为w[u,] [v,] [k’,] [k]和b[k])。就像Dense层一样,Conv2D层保存所有层的权重,包括卷积核和偏置。卷积核是随机初始化的,而偏置初始化为零。这些权重可以通过weights属性作为 TF 变量访问,也可以通过get_weights()方法作为 NumPy 数组访问:
>>> kernels, biases = conv_layer.get_weights()
>>> kernels.shape
(7, 7, 3, 32)
>>> biases.shape
(32,)
- 1
- 2
- 3
- 4
- 5
kernels数组是 4D 的,其形状为[kernel_height, kernel_width, input_channels, output_channels]。biases数组是 1D 的,形状为[output_channels]。输出通道的数量等于输出特征图的数量,也等于滤波器的数量。
最重要的是,需要注意输入图像的高度和宽度不会出现在卷积核的形状中:这是因为输出特征图中的所有神经元共享相同的权重,正如之前解释的那样。这意味着您可以将任何大小的图像馈送到这一层,只要它们至少与卷积核一样大,并且具有正确数量的通道(在这种情况下为三个)。
最后,通常情况下,您会希望在创建Conv2D层时指定一个激活函数(如 ReLU),并指定相应的内核初始化器(如 He 初始化)。这与Dense层的原因相同:卷积层执行线性操作,因此如果您堆叠多个卷积层而没有任何激活函数,它们都等同于单个卷积层,它们将无法学习到真正复杂的内容。
正如您所看到的,卷积层有很多超参数:filters、kernel_size、padding、strides、activation、kernel_initializer等。通常情况下,您可以使用交叉验证来找到正确的超参数值,但这是非常耗时的。我们将在本章后面讨论常见的 CNN 架构,以便让您了解在实践中哪些超参数值效果最好。
内存需求
CNN 的另一个挑战是卷积层需要大量的 RAM。这在训练过程中尤为明显,因为反向传播的反向传递需要在前向传递期间计算的所有中间值。
例如,考虑一个具有 200 个 5×5 滤波器的卷积层,步幅为 1,使用"same"填充。如果输入是一个 150×100 的 RGB 图像(三个通道),那么参数数量为(5×5×3+1)×200=15,200(+1 对应于偏置项),与全连接层相比相当小。然而,这 200 个特征图中的每一个包含 150×100 个神经元,每个神经元都需要计算其 5×5×3=75 个输入的加权和:总共有 2.25 亿次浮点乘法。虽然不像全连接层那么糟糕,但仍然相当计算密集。此外,如果使用 32 位浮点数表示特征图,那么卷积层的输出将占用 200×150×100×32=9600 万位(12 MB)的 RAM。而这只是一个实例的情况——如果一个训练批次包含 100 个实例,那么这一层将使用 1.2 GB 的 RAM!
在推断(即对新实例进行预测时),一个层占用的 RAM 可以在计算下一层后立即释放,因此你只需要两个连续层所需的 RAM。但在训练期间,前向传播期间计算的所有内容都需要保留以进行反向传播,因此所需的 RAM 量至少是所有层所需 RAM 的总量。
提示
如果由于内存不足错误而导致训练崩溃,你可以尝试减小小批量大小。或者,你可以尝试使用步幅减少维度,去掉一些层,使用 16 位浮点数代替 32 位浮点数,或者将 CNN 分布在多个设备上(你将在第十九章中看到如何做)。
现在让我们来看看 CNN 的第二个常见构建块:池化层。
池化层
一旦你理解了卷积层的工作原理,池化层就很容易理解了。它们的目标是对输入图像进行子采样(即缩小),以减少计算负载、内存使用和参数数量(从而限制过拟合的风险)。
就像在卷积层中一样,池化层中的每个神经元连接到前一层中有限数量的神经元的输出,这些神经元位于一个小的矩形感受野内。你必须像以前一样定义它的大小、步幅和填充类型。然而,池化神经元没有权重;它所做的只是使用聚合函数(如最大值或平均值)聚合输入。图 14-9 展示了最大池化层,这是最常见的池化层类型。在这个例子中,我们使用了一个 2×2 的池化核,步幅为 2,没有填充。在图 14-9 中的左下角感受野中,输入值为 1、5、3、2,因此只有最大值 5 传播到下一层。由于步幅为 2,输出图像的高度和宽度都是输入图像的一半(向下取整,因为我们没有使用填充)。
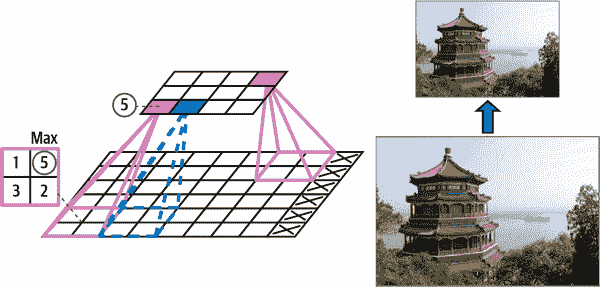
图 14-9。最大池化层(2×2 池化核,步幅 2,无填充)
注意
池化层通常独立地处理每个输入通道,因此输出深度(即通道数)与输入深度相同。
除了减少计算、内存使用和参数数量之外,最大池化层还引入了一定程度的不变性,如图 14-10 所示。在这里,我们假设亮像素的值低于暗像素的值,并考虑三个图像(A、B、C)通过一个 2×2 内核和步幅 2 的最大池化层。图像 B 和 C 与图像 A 相同,但向右移动了一个和两个像素。正如您所看到的,图像 A 和 B 的最大池化层的输出是相同的。这就是平移不变性的含义。对于图像 C,输出是不同的:向右移动一个像素(但仍然有 50%的不变性)。通过在 CNN 中的几层之间插入一个最大池化层,可以在更大的尺度上获得一定程度的平移不变性。此外,最大池化还提供了一定程度的旋转不变性和轻微的尺度不变性。这种不变性(即使有限)在预测不应该依赖这些细节的情况下可能是有用的,比如在分类任务中。
然而,最大池化也有一些缺点。显然,它非常破坏性:即使使用一个微小的 2×2 内核和步幅为 2,输出在两个方向上都会变小两倍(因此其面积会变小四倍),简单地丢弃了输入值的 75%。在某些应用中,不变性并不理想。以语义分割为例(根据像素所属的对象对图像中的每个像素进行分类的任务,我们将在本章后面探讨):显然,如果输入图像向右平移一个像素,输出也应该向右平移一个像素。在这种情况下的目标是等变性,而不是不变性:对输入的微小变化应导致输出的相应微小变化。
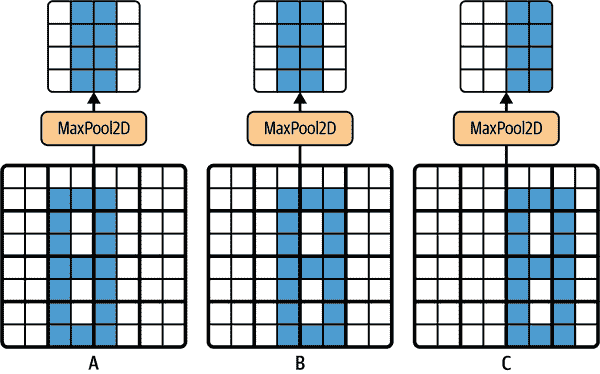
图 14-10。对小平移的不变性
使用 Keras 实现池化层
以下代码创建了一个MaxPooling2D层,别名为MaxPool2D,使用一个 2×2 内核。步幅默认为内核大小,因此此层使用步幅为 2(水平和垂直)。默认情况下,它使用"valid"填充(即根本不填充):
max_pool = tf.keras.layers.MaxPool2D(pool_size=2)
- 1
要创建一个平均池化层,只需使用AveragePooling2D,别名为AvgPool2D,而不是MaxPool2D。正如您所期望的那样,它的工作方式与最大池化层完全相同,只是计算均值而不是最大值。平均池化层曾经非常流行,但现在人们大多使用最大池化层,因为它们通常表现更好。这可能看起来令人惊讶,因为计算均值通常比计算最大值丢失的信息更少。但另一方面,最大池化仅保留最强的特征,摆脱了所有无意义的特征,因此下一层得到了一个更干净的信号来处理。此外,最大池化比平均池化提供更强的平移不变性,并且需要稍少的计算。
请注意,最大池化和平均池化可以沿深度维度而不是空间维度执行,尽管这不太常见。这可以让 CNN 学习对各种特征具有不变性。例如,它可以学习多个滤波器,每个滤波器检测相同模式的不同旋转(例如手写数字;参见图 14-11),深度最大池化层将确保输出不管旋转如何都是相同的。CNN 也可以学习对任何东西具有不变性:厚度、亮度、倾斜、颜色等等。
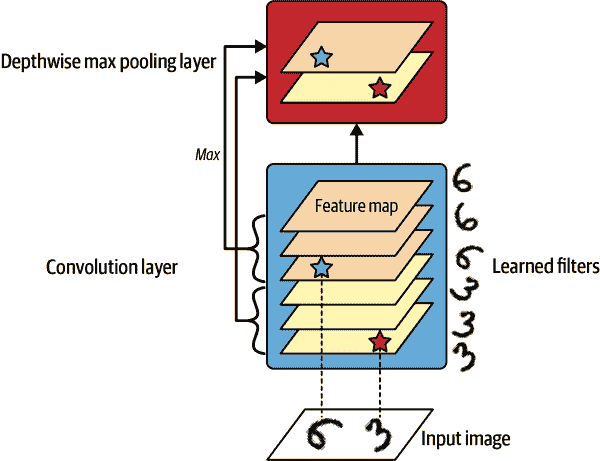
图 14-11。深度最大池化可以帮助 CNN 学习旋转不变性(在这种情况下)
Keras 不包括深度最大池化层,但实现一个自定义层并不太困难:
class DepthPool(tf.keras.layers.Layer):
def __init__(self, pool_size=2, **kwargs):
super().__init__(**kwargs)
self.pool_size = pool_size
def call(self, inputs):
shape = tf.shape(inputs) # shape[-1] is the number of channels
groups = shape[-1] // self.pool_size # number of channel groups
new_shape = tf.concat([shape[:-1], [groups, self.pool_size]], axis=0)
return tf.reduce_max(tf.reshape(inputs, new_shape), axis=-1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这一层将其输入重塑为所需大小的通道组(pool_size),然后使用tf.reduce_max()来计算每个组的最大值。这种实现假定步幅等于池大小,这通常是你想要的。或者,您可以使用 TensorFlow 的tf.nn.max_pool()操作,并在Lambda层中包装以在 Keras 模型中使用它,但遗憾的是,此操作不实现 GPU 的深度池化,只实现 CPU 的深度池化。
在现代架构中经常看到的最后一种类型的池化层是全局平均池化层。它的工作方式非常不同:它只是计算每个整个特征图的平均值(就像使用与输入具有相同空间维度的池化核的平均池化层)。这意味着它只输出每个特征图和每个实例的一个数字。尽管这当然是极其破坏性的(大部分特征图中的信息都丢失了),但它可以在输出层之前非常有用,稍后您将在本章中看到。要创建这样的层,只需使用GlobalAveragePooling2D类,别名GlobalAvgPool2D:
global_avg_pool = tf.keras.layers.GlobalAvgPool2D()
- 1
这等同于以下Lambda层,它计算空间维度(高度和宽度)上的平均值:
global_avg_pool = tf.keras.layers.Lambda(
lambda X: tf.reduce_mean(X, axis=[1, 2]))
- 1
- 2
例如,如果我们将这一层应用于输入图像,我们将得到每个图像的红色、绿色和蓝色的平均强度:
>>> global_avg_pool(images)
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[0.64338624, 0.5971759 , 0.5824972 ],
[0.76306933, 0.26011038, 0.10849128]], dtype=float32)>
- 1
- 2
- 3
- 4
现在您知道如何创建卷积神经网络的所有构建模块了。让我们看看如何组装它们。
CNN 架构
典型的 CNN 架构堆叠了几个卷积层(每个通常后面跟着一个 ReLU 层),然后是一个池化层,然后又是几个卷积层(+ReLU),然后是另一个池化层,依此类推。随着图像通过网络的传递,图像变得越来越小,但也通常变得越来越深(即具有更多的特征图),这要归功于卷积层(参见图 14-12)。在堆栈的顶部,添加了一个常规的前馈神经网络,由几个全连接层(+ReLUs)组成,最后一层输出预测(例如,一个 softmax 层,输出估计的类别概率)。
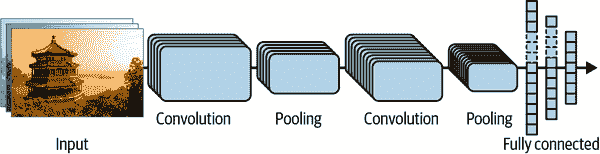
图 14-12. 典型的 CNN 架构
提示
一个常见的错误是使用太大的卷积核。例如,不要使用一个 5×5 的卷积层,而是堆叠两个 3×3 的卷积层:这将使用更少的参数,需要更少的计算,并且通常表现更好。一个例外是第一个卷积层:它通常可以有一个大的卷积核(例如 5×5),通常具有 2 或更大的步幅。这将减少图像的空间维度,而不会丢失太多信息,而且由于输入图像通常只有三个通道,因此成本不会太高。
这是如何实现一个基本的 CNN 来处理时尚 MNIST 数据集的(在第十章介绍):
from functools import partial DefaultConv2D = partial(tf.keras.layers.Conv2D, kernel_size=3, padding="same", activation="relu", kernel_initializer="he_normal") model = tf.keras.Sequential([ DefaultConv2D(filters=64, kernel_size=7, input_shape=[28, 28, 1]), tf.keras.layers.MaxPool2D(), DefaultConv2D(filters=128), DefaultConv2D(filters=128), tf.keras.layers.MaxPool2D(), DefaultConv2D(filters=256), DefaultConv2D(filters=256), tf.keras.layers.MaxPool2D(), tf.keras.layers.Flatten(), tf.keras.layers.Dense(units=128, activation="relu", kernel_initializer="he_normal"), tf.keras.layers.Dropout(0.5), tf.keras.layers.Dense(units=64, activation="relu", kernel_initializer="he_normal"), tf.keras.layers.Dropout(0.5), tf.keras.layers.Dense(units=10, activation="softmax") ])

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
让我们来看一下这段代码:
-
我们使用
functools.partial()函数(在第十一章介绍)来定义DefaultConv2D,它的作用就像Conv2D,但具有不同的默认参数:一个小的 3 的内核大小,"same"填充,ReLU 激活函数,以及相应的 He 初始化器。 -
接下来,我们创建
Sequential模型。它的第一层是一个具有 64 个相当大的滤波器(7×7)的DefaultConv2D。它使用默认的步幅 1,因为输入图像不是很大。它还设置input_shape=[28, 28, 1],因为图像是 28×28 像素,具有单个颜色通道(即灰度)。当您加载时尚 MNIST 数据集时,请确保每个图像具有这种形状:您可能需要使用np.reshape()或np.expanddims()来添加通道维度。或者,您可以在模型中使用Reshape层作为第一层。 -
然后我们添加一个使用默认池大小为 2 的最大池化层,因此它将每个空间维度除以 2。
-
然后我们重复相同的结构两次:两个卷积层后面跟着一个最大池化层。对于更大的图像,我们可以多次重复这个结构。重复次数是一个可以调整的超参数。
-
请注意,随着我们向 CNN 向输出层上升,滤波器的数量会翻倍(最初为 64,然后为 128,然后为 256):这是有道理的,因为低级特征的数量通常相当低(例如,小圆圈,水平线),但有许多不同的方法可以将它们组合成更高级别的特征。在每个池化层后将滤波器数量翻倍是一种常见做法:由于池化层将每个空间维度除以 2,我们可以在下一层中加倍特征图的数量,而不用担心参数数量、内存使用或计算负载的激增。
-
接下来是全连接网络,由两个隐藏的密集层和一个密集输出层组成。由于这是一个有 10 个类别的分类任务,输出层有 10 个单元,并且使用 softmax 激活函数。请注意,我们必须在第一个密集层之前扁平化输入,因为它期望每个实例的特征是一个 1D 数组。我们还添加了两个 dropout 层,每个的 dropout 率为 50%,以减少过拟合。
如果您使用"sparse_categorical_crossentropy"损失编译此模型,并将模型拟合到 Fashion MNIST 训练集,它应该在测试集上达到超过 92%的准确率。这并不是最先进的,但是相当不错,显然比我们在第十章中使用密集网络取得的成绩要好得多。
多年来,这种基本架构的变体已经被开发出来,导致了该领域的惊人进步。这种进步的一个很好的衡量标准是在 ILSVRC(ImageNet 挑战)等比赛中的错误率。在这个比赛中,图像分类的前五错误率,即系统的前五个预测中没有包括正确答案的测试图像数量,从超过 26%下降到不到 2.3%仅仅用了六年。这些图像相当大(例如,高度为 256 像素),有 1000 个类别,其中一些非常微妙(尝试区分 120 种狗品种)。查看获胜作品的演变是了解 CNN 如何工作以及深度学习研究如何进展的好方法。
我们将首先看一下经典的 LeNet-5 架构(1998 年),然后看一下几位 ILSVRC 挑战的获胜者:AlexNet(2012),GoogLeNet(2014),ResNet(2015)和 SENet(2017)。在此过程中,我们还将看一些其他架构,包括 Xception,ResNeXt,DenseNet,MobileNet,CSPNet 和 EfficientNet。
LeNet-5
LeNet-5 架构可能是最广为人知的 CNN 架构。正如前面提到的,它是由 Yann LeCun 在 1998 年创建的,并且被广泛用于手写数字识别(MNIST)。它由表 14-1 中显示的层组成。
表 14-1. LeNet-5 架构
| 层 | 类型 | 特征图 | 尺寸 | 核大小 | 步幅 | 激活函数 |
|---|---|---|---|---|---|---|
| Out | 全连接 | – | 10 | – | – | RBF |
| F6 | 全连接 | – | 84 | – | – | tanh |
| C5 | 卷积 | 120 | 1 × 1 | 5 × 5 | 1 | tanh |
| S4 | 平均池化 | 16 | 5 × 5 | 2 × 2 | 2 | tanh |
| C3 | 卷积 | 16 | 10 × 10 | 5 × 5 | 1 | tanh |
| S2 | 平均池化 | 6 | 14 × 14 | 2 × 2 | 2 | tanh |
| C1 | 卷积 | 6 | 28 × 28 | 5 × 5 | 1 | tanh |
| In | 输入 | 1 | 32 × 32 | – | – | – |
正如您所看到的,这看起来与我们的时尚 MNIST 模型非常相似:一堆卷积层和池化层,然后是一个密集网络。也许与更现代的分类 CNN 相比,主要的区别在于激活函数:今天,我们会使用 ReLU 而不是 tanh,使用 softmax 而不是 RBF。还有一些其他不太重要的差异,但如果您感兴趣,可以在本章的笔记本中找到https://homl.info/colab3。Yann LeCun 的网站还展示了 LeNet-5 对数字进行分类的精彩演示。
AlexNet
AlexNet CNN 架构¹¹在 2012 年 ILSVRC 挑战赛中大幅领先:它实现了 17%的前五错误率,而第二名竞争对手仅实现了 26%!AlexaNet 由 Alex Krizhevsky(因此得名)、Ilya Sutskever 和 Geoffrey Hinton 开发。它类似于 LeNet-5,只是更大更深,它是第一个直接将卷积层堆叠在一起的模型,而不是将池化层堆叠在每个卷积层之上。表 14-2 展示了这种架构。
表 14-2. AlexNet 架构
| 层 | 类型 | 特征图 | 大小 | 核大小 | 步幅 | 填充 | 激活函数 |
|---|---|---|---|---|---|---|---|
| Out | 全连接 | – | 1,000 | – | – | – | Softmax |
| F10 | 全连接 | – | 4,096 | – | – | – | ReLU |
| F9 | 全连接 | – | 4,096 | – | – | – | ReLU |
| S8 | 最大池化 | 256 | 6 × 6 | 3 × 3 | 2 | valid | – |
| C7 | 卷积 | 256 | 13 × 13 | 3 × 3 | 1 | same | ReLU |
| C6 | 卷积 | 384 | 13 × 13 | 3 × 3 | 1 | same | ReLU |
| C5 | 卷积 | 384 | 13 × 13 | 3 × 3 | 1 | same | ReLU |
| S4 | 最大池化 | 256 | 13 × 13 | 3 × 3 | 2 | valid | – |
| C3 | 卷积 | 256 | 27 × 27 | 5 × 5 | 1 | same | ReLU |
| S2 | 最大池化 | 96 | 27 × 27 | 3 × 3 | 2 | valid | – |
| C1 | 卷积 | 96 | 55 × 55 | 11 × 11 | 4 | valid | ReLU |
| In | 输入 | 3(RGB) | 227 × 227 | – | – | – | – |
为了减少过拟合,作者使用了两种正则化技术。首先,他们在训练期间对 F9 和 F10 层的输出应用了 50%的 dropout 率的 dropout(在第十一章中介绍)。其次,他们通过随机移动训练图像的各种偏移量、水平翻转它们和改变光照条件来执行数据增强。
AlexNet 还在 C1 和 C3 层的 ReLU 步骤之后立即使用了一个竞争性归一化步骤,称为局部响应归一化(LRN):最强烈激活的神经元抑制了位于相邻特征图中相同位置的其他神经元。这种竞争性激活已经在生物神经元中观察到。这鼓励不同的特征图专门化,将它们分开并迫使它们探索更广泛的特征,最终提高泛化能力。方程 14-2 展示了如何应用 LRN。
方程 14-2. 局部响应归一化(LRN)
b i = a i k+α∑ j=j low j high a j 2 -β with j high = min i + r 2 , f n - 1 j low = max 0 , i - r 2
在这个方程中:
-
b[i] 是位于特征图i中的神经元的归一化输出,在某一行u和列v(请注意,在这个方程中,我们只考虑位于这一行和列的神经元,因此u和v没有显示)。
-
a[i] 是 ReLU 步骤后,但规范化之前的神经元的激活。
-
k、α、β和r是超参数。k称为偏置,r称为深度半径。
-
f[n] 是特征图的数量。
例如,如果r = 2,并且一个神经元具有强烈的激活,则它将抑制位于其上下特征图中的神经元的激活。
在 AlexNet 中,超参数设置为:r = 5,α = 0.0001,β = 0.75,k = 2。您可以使用tf.nn.local_response_normalization()函数来实现这一步骤(如果要在 Keras 模型中使用它,可以将其包装在Lambda层中)。
由 Matthew Zeiler 和 Rob Fergus 开发的 AlexNet 的一个变体称为ZF Net¹²,并赢得了 2013 年 ILSVRC 挑战赛。它本质上是 AlexNet,只是调整了一些超参数(特征图数量、卷积核大小、步幅等)。
GoogLeNet
GoogLeNet 架构由 Google Research 的 Christian Szegedy 等人开发,¹³,并通过将前五错误率降低到 7%以下赢得了 ILSVRC 2014 挑战。这一出色的性能在很大程度上来自于该网络比以前的 CNN 更深(如您将在图 14-15 中看到的)。这得益于称为inception 模块的子网络,¹⁴,它允许 GoogLeNet 比以前的架构更有效地使用参数:实际上,GoogLeNet 的参数比 AlexNet 少 10 倍(大约 600 万个而不是 6000 万个)。
图 14-14 显示了 Inception 模块的架构。符号“3×3 + 1(S)”表示该层使用 3×3 内核,步幅 1 和"same"填充。输入信号首先并行输入到四个不同的层中。所有卷积层使用 ReLU 激活函数。请注意,顶部卷积层使用不同的内核大小(1×1、3×3 和 5×5),使它们能够捕获不同尺度的模式。还要注意,每个单独的层都使用步幅 1 和"same"填充(即使是最大池化层),因此它们的输出与它们的输入具有相同的高度和宽度。这使得可以在最终的深度连接层(即将来自所有四个顶部卷积层的特征图堆叠在一起)中沿深度维度连接所有输出。可以使用 Keras 的Concatenate层来实现,使用默认的axis=-1。
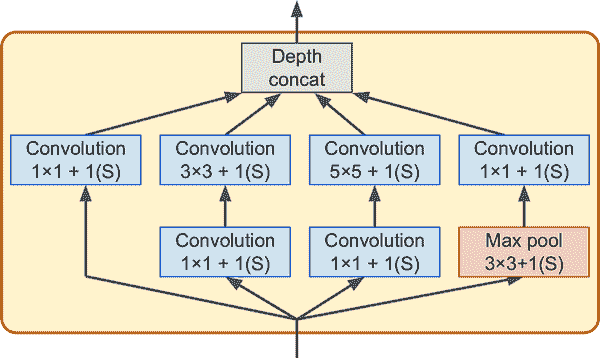
图 14-14。Inception 模块
您可能会想知道为什么 Inception 模块具有具有 1×1 内核的卷积层。毕竟,这些层不能捕获任何特征,因为它们一次只查看一个像素,对吧?实际上,这些层有三个目的:
-
尽管它们不能捕获空间模式,但它们可以捕获沿深度维度(即跨通道)的模式。
-
它们被配置为输出比它们的输入更少的特征图,因此它们充当瓶颈层,意味着它们降低了维度。这降低了计算成本和参数数量,加快了训练速度并提高了泛化能力。
-
每对卷积层([1×1、3×3]和[1×1、5×5])就像一个强大的卷积层,能够捕获更复杂的模式。卷积层等效于在图像上扫过一个密集层(在每个位置,它只查看一个小的感受野),而这些卷积层对等于在图像上扫过两层神经网络。
简而言之,您可以将整个 Inception 模块视为一个超级卷积层,能够输出捕获各种尺度复杂模式的特征图。
现在让我们来看看 GoogLeNet CNN 的架构(参见图 14-15)。每个卷积层和每个池化层输出的特征图数量在内核大小之前显示。该架构非常深,以至于必须用三列来表示,但实际上 GoogLeNet 是一个高高的堆叠,包括九个 Inception 模块(带有旋转顶部的方框)。Inception 模块中的六个数字表示模块中每个卷积层输出的特征图数量(与图 14-14 中的顺序相同)。请注意,所有卷积层都使用 ReLU 激活函数。
让我们来看看这个网络:
-
前两层将图像的高度和宽度分别除以 4(因此其面积除以 16),以减少计算负载。第一层使用大的内核大小,7×7,以便保留大部分信息。
-
然后,本地响应归一化层确保前面的层学习到各种各样的特征(如前面讨论的)。
-
接下来是两个卷积层,其中第一个充当瓶颈层。正如前面提到的,您可以将这一对看作一个更聪明的单个卷积层。
-
再次,本地响应归一化层确保前面的层捕获各种各样的模式。
-
接下来,一个最大池化层将图像的高度和宽度减少了一半,以加快计算速度。
-
然后是 CNN 的骨干:一个高高的堆叠,包括九个 Inception 模块,交替使用一对最大池化层来降低维度并加快网络速度。
-
接下来,全局平均池化层输出每个特征图的平均值:这会丢弃任何剩余的空间信息,这没关系,因为在那一点上剩下的空间信息并不多。事实上,GoogLeNet 的输入图像通常期望为 224×224 像素,因此经过 5 个最大池化层后,每个将高度和宽度除以 2,特征图缩小到 7×7。此外,这是一个分类任务,而不是定位任务,因此物体在哪里并不重要。由于这一层带来的降维,不需要在 CNN 的顶部有几个全连接层(就像在 AlexNet 中那样),这大大减少了网络中的参数数量,并限制了过拟合的风险。
-
最后几层很容易理解:用于正则化的 dropout,然后是一个具有 1,000 个单元的全连接层(因为有 1,000 个类别),以及一个 softmax 激活函数来输出估计的类别概率。
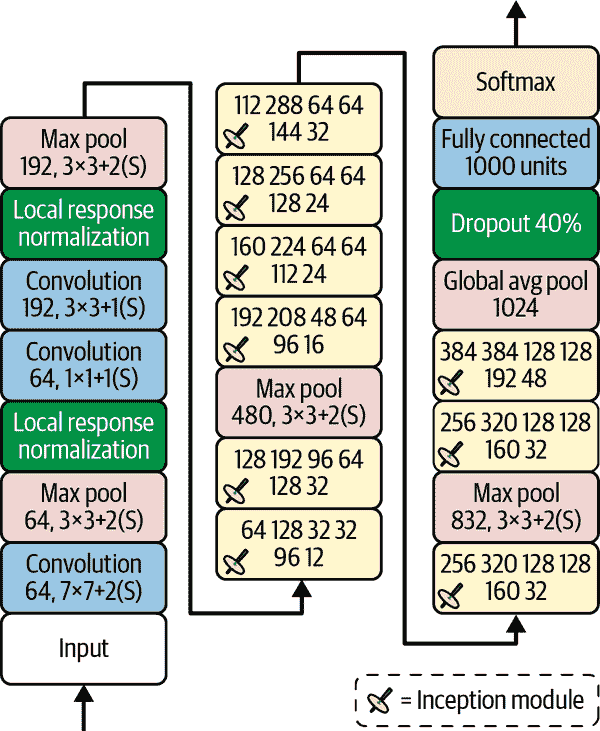
图 14-15。GoogLeNet 架构
原始的 GoogLeNet 架构包括两个辅助分类器,插在第三和第六个 inception 模块的顶部。它们都由一个平均池化层、一个卷积层、两个全连接层和一个 softmax 激活层组成。在训练过程中,它们的损失(缩小了 70%)被添加到整体损失中。目标是解决梯度消失问题并对网络进行正则化,但后来证明它们的效果相对较小。
后来,Google 的研究人员提出了 GoogLeNet 架构的几个变体,包括 Inception-v3 和 Inception-v4,使用略有不同的 inception 模块以实现更好的性能。
VGGNet
在 ILSVRC 2014 挑战赛中的亚军是VGGNet,Karen Simonyan 和 Andrew Zisserman,来自牛津大学视觉几何组(VGG)研究实验室,开发了一个非常简单和经典的架构;它有 2 或 3 个卷积层和一个池化层,然后再有 2 或 3 个卷积层和一个池化层,依此类推(达到 16 或 19 个卷积层,取决于 VGG 的变体),再加上一个最终的具有 2 个隐藏层和输出层的密集网络。它使用小的 3×3 滤波器,但数量很多。
ResNet
Kaiming He 等人在 ILSVRC 2015 挑战赛中使用Residual Network (ResNet)赢得了冠军,其前五错误率令人惊叹地低于 3.6%。获胜的变体使用了一个由 152 层组成的极深 CNN(其他变体有 34、50 和 101 层)。它证实了一个普遍趋势:计算机视觉模型变得越来越深,参数越来越少。能够训练如此深的网络的关键是使用跳跃连接(也称为快捷连接):输入到一个层的信号也被添加到堆栈中更高的层的输出中。让我们看看为什么这很有用。
在训练神经网络时,目标是使其模拟目标函数h(x)。如果将输入x添加到网络的输出中(即添加一个跳跃连接),那么网络将被迫模拟f(x) = h(x) - x而不是h(x)。这被称为残差学习。
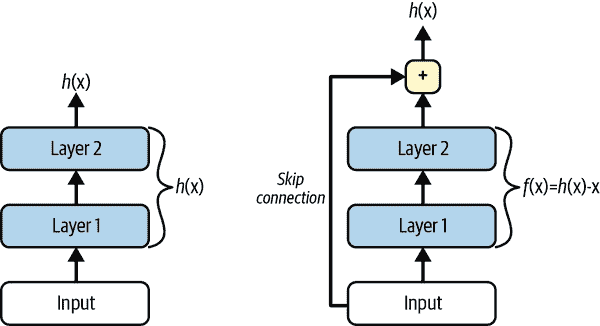
图 14-16。残差学习
当初始化一个常规的神经网络时,它的权重接近于零,因此网络只会输出接近于零的值。如果添加一个跳跃连接,结果网络将只输出其输入的副本;换句话说,它最初模拟的是恒等函数。如果目标函数与恒等函数相当接近(这通常是情况),这将大大加快训练速度。
此外,如果添加许多跳跃连接,即使有几个层尚未开始学习,网络也可以开始取得进展(参见图 14-17)。由于跳跃连接,信号可以轻松地在整个网络中传播。深度残差网络可以看作是一堆残差单元(RUs),其中每个残差单元是一个带有跳跃连接的小型神经网络。
现在让我们看一下 ResNet 的架构(参见图 14-18)。它非常简单。它的开头和结尾与 GoogLeNet 完全相同(除了没有丢弃层),中间只是一个非常深的残差单元堆栈。每个残差单元由两个卷积层组成(没有池化层!),使用 3×3 的卷积核和保持空间维度(步幅 1,"same"填充)的批量归一化(BN)和 ReLU 激活。
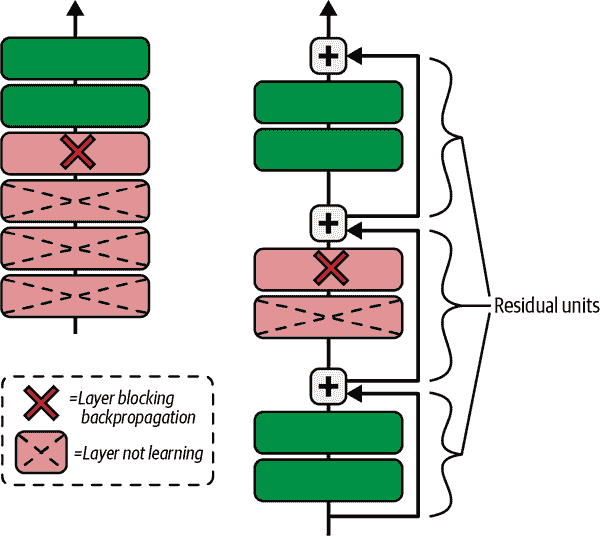
图 14-17。常规深度神经网络(左)和深度残差网络(右)
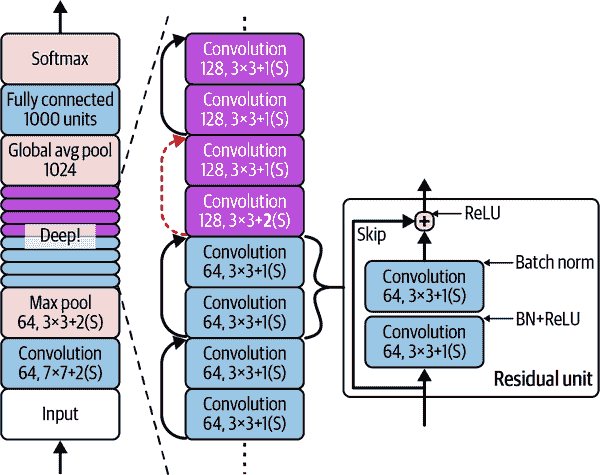
图 14-18。ResNet 架构
请注意,每隔几个残差单元,特征图的数量会加倍,同时它们的高度和宽度会减半(使用步幅为 2 的卷积层)。当这种情况发生时,输入不能直接添加到残差单元的输出中,因为它们的形状不同(例如,这个问题影响了由虚线箭头表示的跳跃连接在图 14-18 中的情况)。为了解决这个问题,输入通过一个步幅为 2 的 1×1 卷积层,并具有正确数量的输出特征图(参见图 14-19)。
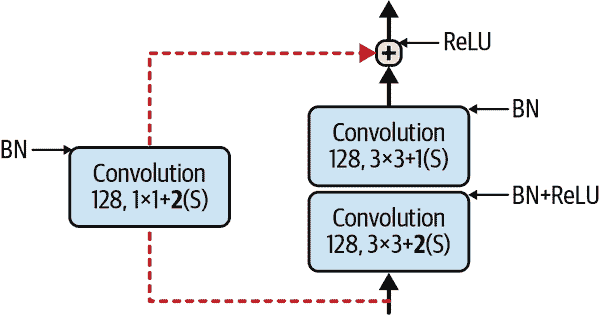
图 14-19。更改特征图大小和深度时的跳跃连接
存在不同变体的架构,具有不同数量的层。ResNet-34 是一个具有 34 层的 ResNet(仅计算卷积层和全连接层),包含 3 个输出 64 个特征图的 RU,4 个输出 128 个特征图的 RU,6 个输出 256 个特征图的 RU,以及 3 个输出 512 个特征图的 RU。我们将在本章后面实现这个架构。
注意
Google 的Inception-v4¹⁸架构融合了 GoogLeNet 和 ResNet 的思想,并在 ImageNet 分类中实现了接近 3%的前五错误率。
比 ResNet-152 更深的 ResNet,例如 ResNet-152,使用略有不同的残差单元。它们不是使用两个具有 256 个特征图的 3×3 卷积层,而是使用三个卷积层:首先是一个只有 64 个特征图的 1×1 卷积层(少了 4 倍),它充当瓶颈层(如前所述),然后是一个具有 64 个特征图的 3×3 层,最后是另一个具有 256 个特征图的 1×1 卷积层(4 倍 64),恢复原始深度。ResNet-152 包含 3 个输出 256 个映射的这样的 RU,然后是 8 个输出 512 个映射的 RU,一个令人惊叹的 36 个输出 1024 个映射的 RU,最后是 3 个输出 2048 个映射的 RU。
Xception
值得注意的是 GoogLeNet 架构的另一个变种:Xception(代表Extreme Inception)由 Keras 的作者 François Chollet 于 2016 年提出,并在一个庞大的视觉任务(3.5 亿张图片和 1.7 万个类别)上明显优于 Inception-v3。就像 Inception-v4 一样,它融合了 GoogLeNet 和 ResNet 的思想,但是用一个特殊类型的层称为深度可分离卷积层(或简称可分离卷积层)替换了 inception 模块。这些层在一些 CNN 架构中之前已经被使用过,但在 Xception 架构中并不像现在这样核心。常规卷积层使用滤波器,试图同时捕捉空间模式(例如,椭圆)和跨通道模式(例如,嘴+鼻子+眼睛=脸),而可分离卷积层则做出了空间模式和跨通道模式可以分别建模的强烈假设(见图 14-20)。因此,它由两部分组成:第一部分对每个输入特征图应用一个单一的空间滤波器,然后第二部分专门寻找跨通道模式——这只是一个具有 1×1 滤波器的常规卷积层。
由于可分离卷积层每个输入通道只有一个空间滤波器,所以应避免在通道较少的层之后使用它们,比如输入层(尽管图 14-20 中是这样的,但那只是为了说明目的)。因此,Xception 架构以 2 个常规卷积层开始,然后剩下的架构只使用可分离卷积(总共 34 个),再加上一些最大池化层和通常的最终层(一个全局平均池化层和一个密集输出层)。
你可能会想为什么 Xception 被认为是 GoogLeNet 的一个变种,因为它根本不包含任何 inception 模块。嗯,正如之前讨论的那样,一个 inception 模块包含有 1×1 滤波器的卷积层:这些滤波器专门寻找跨通道模式。然而,位于它们之上的卷积层是常规卷积层,既寻找空间模式又寻找跨通道模式。因此,你可以将一个 inception 模块看作是一个常规卷积层(同时考虑空间模式和跨通道模式)和一个可分离卷积层(分别考虑它们)之间的中间层。实际上,可分离卷积层通常表现更好。
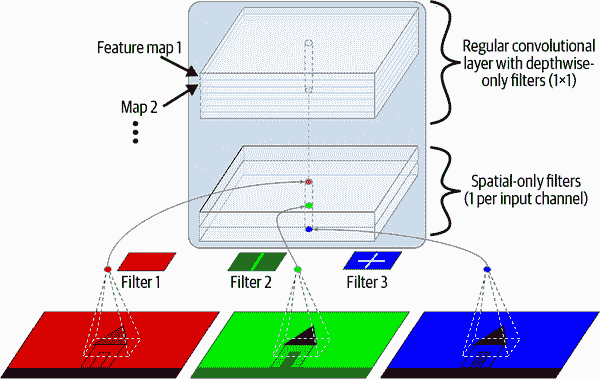
图 14-20。深度可分离卷积层
提示
可分离卷积层使用更少的参数、更少的内存和更少的计算量比常规卷积层,通常表现更好。考虑默认使用它们,除了在通道较少的层之后(比如输入通道)。在 Keras 中,只需使用SeparableConv2D代替Conv2D:这是一个即插即用的替代。Keras 还提供了一个DepthwiseConv2D层,实现深度可分离卷积层的第一部分(即,对每个输入特征图应用一个空间滤波器)。
SENet
在 ILSVRC 2017 挑战中获胜的架构是Squeeze-and-Excitation Network (SENet)。这个架构扩展了现有的架构,如 inception 网络和 ResNets,并提升了它们的性能。这使得 SENet 以惊人的 2.25%的前五错误率赢得了比赛!扩展版本的 inception 网络和 ResNets 分别称为SE-Inception和SE-ResNet。提升来自于 SENet 在原始架构的每个 inception 模块或残差单元中添加了一个小型神经网络,称为SE 块,如图 14-21 所示。
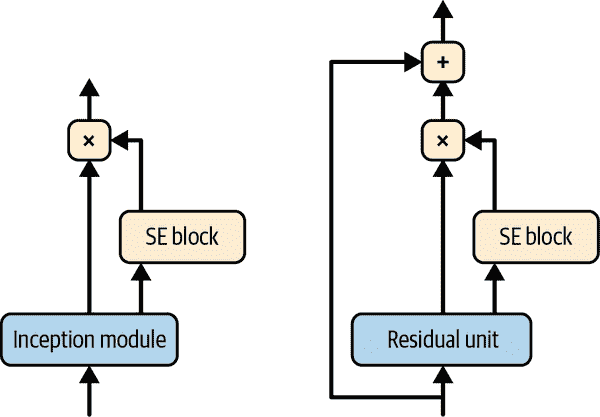
图 14-21. SE-Inception 模块(左)和 SE-ResNet 单元(右)
一个 SE 块分析其所附加的单元的输出,专注于深度维度(不寻找任何空间模式),并学习哪些特征通常是最活跃的。然后,它使用这些信息来重新校准特征映射,如图 14-22 所示。例如,一个 SE 块可能学习到嘴巴、鼻子和眼睛通常一起出现在图片中:如果你看到嘴巴和鼻子,你应该期望也看到眼睛。因此,如果该块在嘴巴和鼻子特征映射中看到强烈的激活,但在眼睛特征映射中只有轻微的激活,它将增强眼睛特征映射(更准确地说,它将减少不相关的特征映射)。如果眼睛有些混淆,这种特征映射的重新校准将有助于解决模糊性。
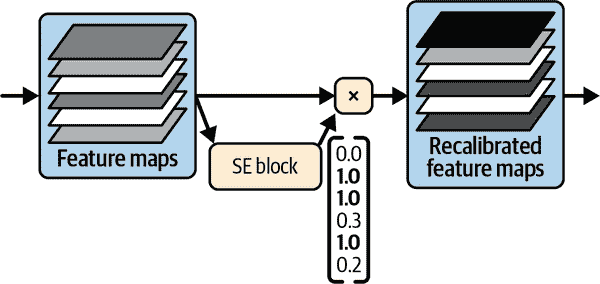
图 14-22. 一个 SE 块执行特征映射重新校准
一个 SE 块由三层组成:一个全局平均池化层,一个使用 ReLU 激活函数的隐藏密集层,以及一个使用 sigmoid 激活函数的密集输出层(见图 14-23)。
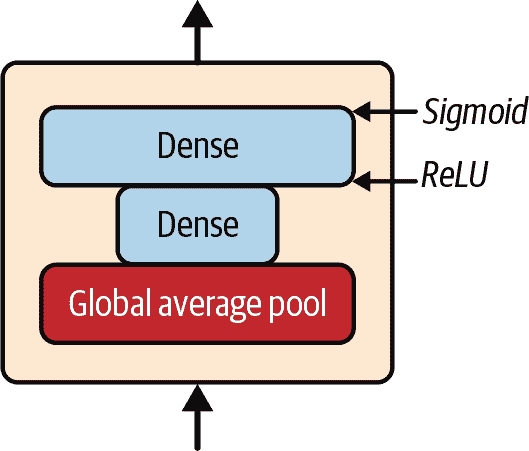
图 14-23. SE 块架构
与之前一样,全局平均池化层计算每个特征映射的平均激活:例如,如果其输入包含 256 个特征映射,它将输出 256 个数字,表示每个滤波器的整体响应水平。接下来的层是“挤压”发生的地方:这一层的神经元数量明显少于 256 个——通常比特征映射的数量少 16 倍(例如,16 个神经元)——因此 256 个数字被压缩成一个小向量(例如,16 维)。这是特征响应分布的低维向量表示(即嵌入)。这个瓶颈步骤迫使 SE 块学习特征组合的一般表示(当我们讨论自编码器时,我们将再次看到这个原则在第十七章中)。最后,输出层接受嵌入并输出一个包含每个特征映射的重新校准向量(例如,256 个),每个数字在 0 到 1 之间。然后特征映射乘以这个重新校准向量,因此不相关的特征(具有低重新校准分数)被缩小,而相关的特征(具有接近 1 的重新校准分数)被保留。
其他值得注意的架构
还有许多其他 CNN 架构可以探索。以下是一些最值得注意的简要概述:
ResNeXt²²
ResNeXt 改进了 ResNet 中的残差单元。而最佳 ResNet 模型中的残差单元只包含 3 个卷积层,ResNeXt 的残差单元由许多并行堆栈组成(例如,32 个堆栈),每个堆栈有 3 个卷积层。然而,每个堆栈中的前两层只使用少量滤波器(例如,只有四个),因此总参数数量与 ResNet 中的相同。然后,所有堆栈的输出相加,并将结果传递给下一个残差单元(以及跳跃连接)。
DenseNet²³
DenseNet 由几个密集块组成,每个块由几个密集连接的卷积层组成。这种架构在使用相对较少的参数的同时实现了出色的准确性。什么是“密集连接”?每一层的输出被馈送为同一块内每一层之后的每一层的输入。例如,块中的第 4 层以该块中第 1、2 和 3 层的输出的深度级联作为输入。密集块之间由几个过渡层分隔。
MobileNet²⁴
MobileNets 是精简的模型,旨在轻量且快速,因此在移动和 Web 应用程序中很受欢迎。它们基于深度可分离卷积层,类似于 Xception。作者提出了几个变体,以牺牲一点准确性换取更快速和更小的模型。
CSPNet²⁵
交叉阶段部分网络(CSPNet)类似于 DenseNet,但是每个密集块的部分输入直接连接到该块的输出,而不经过该块。
EfficientNet²⁶
EfficientNet 可以说是这个列表中最重要的模型。作者提出了一种有效地扩展任何 CNN 的方法,通过以原则性的方式同时增加深度(层数)、宽度(每层的滤波器数量)和分辨率(输入图像的大小)。这被称为复合缩放。他们使用神经架构搜索来找到一个适合 ImageNet 的缩小版本(具有更小和更少的图像)的良好架构,然后使用复合缩放来创建这种架构的越来越大的版本。当 EfficientNet 模型推出时,它们在所有计算预算中都远远超过了所有现有的模型,并且它们仍然是当今最好的模型之一。
理解 EfficientNet 的复合缩放方法有助于更深入地理解 CNN,特别是如果您需要扩展 CNN 架构。它基于计算预算的对数度量,标记为ϕ:如果您的计算预算翻倍,则ϕ增加 1。换句话说,用于训练的浮点运算数量与 2^(ϕ)成比例。您的 CNN 架构的深度、宽度和分辨率应分别按α(*ϕ*)、*β*(ϕ)和γ^(ϕ)缩放。因子α、β和γ必须大于 1,且α + β² + γ²应接近 2。这些因子的最佳值取决于 CNN 的架构。为了找到 EfficientNet 架构的最佳值,作者从一个小的基线模型(EfficientNetB0)开始,固定ϕ = 1,然后简单地运行了一个网格搜索:他们发现α = 1.2,β = 1.1,γ = 1.1。然后,他们使用这些因子创建了几个更大的架构,命名为 EfficientNetB1 到 EfficientNetB7,对应不断增加的ϕ值。
选择正确的 CNN 架构
有这么多 CNN 架构,您如何选择最适合您项目的架构?这取决于您最关心的是什么:准确性?模型大小(例如,用于部署到移动设备)?在 CPU 上的推理速度?在 GPU 上的推理速度?表 14-3 列出了目前在 Keras 中可用的最佳预训练模型(您将在本章后面看到如何使用它们),按模型大小排序。您可以在https://keras.io/api/applications找到完整列表。对于每个模型,表格显示要使用的 Keras 类名(在tf.keras.applications包中)、模型的大小(MB)、在 ImageNet 数据集上的 Top-1 和 Top-5 验证准确率、参数数量(百万)以及在 CPU 和 GPU 上使用 32 张图像的推理时间(毫秒),使用性能较强的硬件。²⁷ 对于每列,最佳值已突出显示。正如您所看到的,通常较大的模型更准确,但并非总是如此;例如,EfficientNetB2 在大小和准确性上均优于 InceptionV3。我之所以将 InceptionV3 保留在列表中,是因为在 CPU 上它几乎比 EfficientNetB2 快一倍。同样,InceptionResNetV2 在 CPU 上速度很快,而 ResNet50V2 和 ResNet101V2 在 GPU 上速度极快。
表 14-3。Keras 中可用的预训练模型
| 类名 | 大小(MB) | Top-1 准确率 | Top-5 准确率 | 参数 | CPU(ms) | GPU(ms) |
|---|---|---|---|---|---|---|
| MobileNetV2 | 14 | 71.3% | 90.1% | 3.5M | 25.9 | 3.8 |
| MobileNet | 16 | 70.4% | 89.5% | 4.3M | 22.6 | 3.4 |
| NASNetMobile | 23 | 74.4% | 91.9% | 5.3M | 27.0 | 6.7 |
| EfficientNetB0 | 29 | 77.1% | 93.3% | 5.3M | 46.0 | 4.9 |
| EfficientNetB1 | 31 | 79.1% | 94.4% | 7.9M | 60.2 | 5.6 |
| EfficientNetB2 | 36 | 80.1% | 94.9% | 9.2M | 80.8 | 6.5 |
| EfficientNetB3 | 48 | 81.6% | 95.7% | 12.3M | 140.0 | 8.8 |
| EfficientNetB4 | 75 | 82.9% | 96.4% | 19.5M | 308.3 | 15.1 |
| InceptionV3 | 92 | 77.9% | 93.7% | 23.9M | 42.2 | 6.9 |
| ResNet50V2 | 98 | 76.0% | 93.0% | 25.6M | 45.6 | 4.4 |
| EfficientNetB5 | 118 | 83.6% | 96.7% | 30.6M | 579.2 | 25.3 |
| EfficientNetB6 | 166 | 84.0% | 96.8% | 43.3M | 958.1 | 40.4 |
| ResNet101V2 | 171 | 77.2% | 93.8% | 44.7M | 72.7 | 5.4 |
| InceptionResNetV2 | 215 | 80.3% | 95.3% | 55.9M | 130.2 | 10.0 |
| EfficientNetB7 | 256 | 84.3% | 97.0% | 66.7M | 1578.9 | 61.6 |
希望您喜欢这次对主要 CNN 架构的深入探讨!现在让我们看看如何使用 Keras 实现其中一个。
使用 Keras 实现 ResNet-34 CNN
到目前为止,大多数描述的 CNN 架构可以很自然地使用 Keras 实现(尽管通常您会加载一个预训练网络,正如您将看到的)。为了说明这个过程,让我们使用 Keras 从头开始实现一个 ResNet-34。首先,我们将创建一个ResidualUnit层:
DefaultConv2D = partial(tf.keras.layers.Conv2D, kernel_size=3, strides=1, padding="same", kernel_initializer="he_normal", use_bias=False) class ResidualUnit(tf.keras.layers.Layer): def __init__(self, filters, strides=1, activation="relu", **kwargs): super().__init__(**kwargs) self.activation = tf.keras.activations.get(activation) self.main_layers = [ DefaultConv2D(filters, strides=strides), tf.keras.layers.BatchNormalization(), self.activation, DefaultConv2D(filters), tf.keras.layers.BatchNormalization() ] self.skip_layers = [] if strides > 1: self.skip_layers = [ DefaultConv2D(filters, kernel_size=1, strides=strides), tf.keras.layers.BatchNormalization() ] def call(self, inputs): Z = inputs for layer in self.main_layers: Z = layer(Z) skip_Z = inputs for layer in self.skip_layers: skip_Z = layer(skip_Z) return self.activation(Z + skip_Z)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
正如您所看到的,这段代码与图 14-19 非常接近。在构造函数中,我们创建所有需要的层:图中右侧的主要层和左侧的跳过层(仅在步幅大于 1 时需要)。然后在call()方法中,我们让输入经过主要层和跳过层(如果有的话),然后我们添加两个输出并应用激活函数。
现在我们可以使用Sequential模型构建一个 ResNet-34,因为它实际上只是一长串的层——现在我们有了ResidualUnit类,可以将每个残差单元视为一个单独的层。代码与图 14-18 非常相似:
model = tf.keras.Sequential([
DefaultConv2D(64, kernel_size=7, strides=2, input_shape=[224, 224, 3]),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation("relu"),
tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding="same"),
])
prev_filters = 64
for filters in [64] * 3 + [128] * 4 + [256] * 6 + [512] * 3:
strides = 1 if filters == prev_filters else 2
model.add(ResidualUnit(filters, strides=strides))
prev_filters = filters
model.add(tf.keras.layers.GlobalAvgPool2D())
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(10, activation="softmax"))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这段代码中唯一棘手的部分是将ResidualUnit层添加到模型的循环:正如前面解释的,前 3 个 RU 有 64 个滤波器,然后接下来的 4 个 RU 有 128 个滤波器,依此类推。在每次迭代中,当滤波器的数量与前一个 RU 中的数量相同时,我们必须将步幅设置为 1;否则,我们将其设置为 2;然后我们添加ResidualUnit,最后我们更新prev_filters。
令人惊讶的是,我们只需大约 40 行代码,就可以构建赢得 ILSVRC 2015 挑战的模型!这既展示了 ResNet 模型的优雅之处,也展示了 Keras API 的表现力。实现其他 CNN 架构会有点长,但并不难。不过,Keras 内置了几种这些架构,为什么不直接使用呢?
使用 Keras 中的预训练模型
通常,您不必手动实现标准模型,如 GoogLeNet 或 ResNet,因为在tf.keras.applications包中只需一行代码即可获得预训练网络。
例如,您可以使用以下代码加载在 ImageNet 上预训练的 ResNet-50 模型:
model = tf.keras.applications.ResNet50(weights="imagenet")
- 1
就这些!这将创建一个 ResNet-50 模型,并下载在 ImageNet 数据集上预训练的权重。要使用它,您首先需要确保图像的尺寸正确。ResNet-50 模型期望 224×224 像素的图像(其他模型可能期望其他尺寸,如 299×299),因此让我们使用 Keras 的Resizing层(在第十三章中介绍)来调整两个示例图像的大小(在将它们裁剪到目标纵横比之后):
images = load_sample_images()["images"]
images_resized = tf.keras.layers.Resizing(height=224, width=224,
crop_to_aspect_ratio=True)(images)
- 1
- 2
- 3
预训练模型假定图像以特定方式预处理。在某些情况下,它们可能期望输入被缩放为 0 到 1,或者从-1 到 1 等等。每个模型都提供了一个preprocess_input()函数,您可以用它来预处理您的图像。这些函数假设原始像素值的范围是 0 到 255,这在这里是正确的:
inputs = tf.keras.applications.resnet50.preprocess_input(images_resized)
- 1
现在我们可以使用预训练模型进行预测:
>>> Y_proba = model.predict(inputs)
>>> Y_proba.shape
(2, 1000)
- 1
- 2
- 3
像往常一样,输出Y_proba是一个矩阵,每行代表一个图像,每列代表一个类别(在本例中有 1,000 个类别)。如果您想显示前K个预测结果,包括类别名称和每个预测类别的估计概率,请使用decode_predictions()函数。对于每个图像,它返回一个包含前K个预测结果的数组,其中每个预测结果表示为一个包含类别标识符、其名称和相应置信度分数的数组:
top_K = tf.keras.applications.resnet50.decode_predictions(Y_proba, top=3)
for image_index in range(len(images)):
print(f"Image #{image_index}")
for class_id, name, y_proba in top_K[image_index]:
print(f" {class_id} - {name:12s}{y_proba:.2%}")
- 1
- 2
- 3
- 4
- 5
输出如下所示:
Image #0
n03877845 - palace 54.69%
n03781244 - monastery 24.72%
n02825657 - bell_cote 18.55%
Image #1
n04522168 - vase 32.66%
n11939491 - daisy 17.81%
n03530642 - honeycomb 12.06%
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
正确的类别是 palace 和 dahlia,因此模型对第一张图像是正确的,但对第二张图像是错误的。然而,这是因为 dahlia 不是 1,000 个 ImageNet 类之一。考虑到这一点,vase 是一个合理的猜测(也许这朵花在花瓶里?),daisy 也不是一个坏选择,因为 dahlias 和 daisies 都属于同一菊科家族。
正如您所看到的,使用预训练模型创建一个相当不错的图像分类器非常容易。正如您在表 14-3 中看到的,tf.keras.applications中提供了许多其他视觉模型,从轻量级快速模型到大型准确模型。
但是,如果您想要为不属于 ImageNet 的图像类别使用图像分类器,那么您仍然可以通过使用预训练模型来进行迁移学习获益。
用于迁移学习的预训练模型
如果您想构建一个图像分类器,但没有足够的数据来从头开始训练它,那么通常可以重用预训练模型的较低层,正如我们在第十一章中讨论的那样。例如,让我们训练一个模型来对花的图片进行分类,重用一个预训练的 Xception 模型。首先,我们将使用 TensorFlow Datasets(在第十三章中介绍)加载花卉数据集:
import tensorflow_datasets as tfds
dataset, info = tfds.load("tf_flowers", as_supervised=True, with_info=True)
dataset_size = info.splits["train"].num_examples # 3670
class_names = info.features["label"].names # ["dandelion", "daisy", ...]
n_classes = info.features["label"].num_classes # 5
- 1
- 2
- 3
- 4
- 5
- 6
请注意,您可以通过设置with_info=True来获取有关数据集的信息。在这里,我们获取数据集的大小和类的名称。不幸的是,只有一个"train"数据集,没有测试集或验证集,所以我们需要拆分训练集。让我们再次调用tfds.load(),但这次将前 10%的数据集用于测试,接下来的 15%用于验证,剩下的 75%用于训练:
test_set_raw, valid_set_raw, train_set_raw = tfds.load(
"tf_flowers",
split=["train[:10%]", "train[10%:25%]", "train[25%:]"],
as_supervised=True)
- 1
- 2
- 3
- 4
所有三个数据集都包含单独的图像。我们需要对它们进行批处理,但首先我们需要确保它们都具有相同的大小,否则批处理将失败。我们可以使用Resizing层来实现这一点。我们还必须调用tf.keras.applications.xception.preprocess_input()函数,以适当地预处理图像以供 Xception 模型使用。最后,我们还将对训练集进行洗牌并使用预取:
batch_size = 32
preprocess = tf.keras.Sequential([
tf.keras.layers.Resizing(height=224, width=224, crop_to_aspect_ratio=True),
tf.keras.layers.Lambda(tf.keras.applications.xception.preprocess_input)
])
train_set = train_set_raw.map(lambda X, y: (preprocess(X), y))
train_set = train_set.shuffle(1000, seed=42).batch(batch_size).prefetch(1)
valid_set = valid_set_raw.map(lambda X, y: (preprocess(X), y)).batch(batch_size)
test_set = test_set_raw.map(lambda X, y: (preprocess(X), y)).batch(batch_size)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
现在每个批次包含 32 个图像,所有图像都是 224×224 像素,像素值范围从-1 到 1。完美!
由于数据集不是很大,一点数据增强肯定会有所帮助。让我们创建一个数据增强模型,将其嵌入到我们的最终模型中。在训练期间,它将随机水平翻转图像,稍微旋转它们,并调整对比度:
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip(mode="horizontal", seed=42),
tf.keras.layers.RandomRotation(factor=0.05, seed=42),
tf.keras.layers.RandomContrast(factor=0.2, seed=42)
])
- 1
- 2
- 3
- 4
- 5
提示
tf.keras.preprocessing.image.ImageDataGenerator类使从磁盘加载图像并以各种方式增强它们变得容易:您可以移动每个图像,旋转它,重新缩放它,水平或垂直翻转它,剪切它,或者应用任何您想要的转换函数。这对于简单的项目非常方便。然而,tf.data 管道并不复杂,通常更快。此外,如果您有 GPU 并且将预处理或数据增强层包含在模型内部,它们将在训练过程中受益于 GPU 加速。
接下来让我们加载一个在 ImageNet 上预训练的 Xception 模型。通过设置include_top=False来排除网络的顶部。这将排除全局平均池化层和密集输出层。然后我们添加自己的全局平均池化层(将其输入设置为基础模型的输出),然后是一个具有每个类别一个单元的密集输出层,使用 softmax 激活函数。最后,我们将所有这些包装在一个 Keras Model中:
base_model = tf.keras.applications.xception.Xception(weights="imagenet",
include_top=False)
avg = tf.keras.layers.GlobalAveragePooling2D()(base_model.output)
output = tf.keras.layers.Dense(n_classes, activation="softmax")(avg)
model = tf.keras.Model(inputs=base_model.input, outputs=output)
- 1
- 2
- 3
- 4
- 5
如第十一章中解释的,通常冻结预训练层的权重是一个好主意,至少在训练开始时是这样的:
for layer in base_model.layers:
layer.trainable = False
- 1
- 2
警告
由于我们的模型直接使用基础模型的层,而不是base_model对象本身,设置base_model.trainable=False不会产生任何效果。
最后,我们可以编译模型并开始训练:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.1, momentum=0.9)
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model.fit(train_set, validation_data=valid_set, epochs=3)
- 1
- 2
- 3
- 4
警告
如果你在 Colab 上运行,请确保运行时正在使用 GPU:选择运行时→“更改运行时类型”,在“硬件加速器”下拉菜单中选择“GPU”,然后点击保存。可以在没有 GPU 的情况下训练模型,但速度会非常慢(每个时期几分钟,而不是几秒)。
在训练模型几个时期后,其验证准确率应该达到 80%以上,然后停止提高。这意味着顶层现在已经训练得相当好,我们准备解冻一些基础模型的顶层,然后继续训练。例如,让我们解冻第 56 层及以上的层(这是 14 个残差单元中第 7 个的开始,如果列出层名称,你会看到):
for layer in base_model.layers[56:]:
layer.trainable = True
- 1
- 2
不要忘记在冻结或解冻层时编译模型。还要确保使用更低的学习率以避免破坏预训练权重:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01, momentum=0.9)
model.compile(loss="sparse_categorical_crossentropy", optimizer=optimizer,
metrics=["accuracy"])
history = model.fit(train_set, validation_data=valid_set, epochs=10)
- 1
- 2
- 3
- 4
这个模型应该在测试集上达到大约 92%的准确率,在几分钟的训练时间内(使用 GPU)。如果调整超参数,降低学习率,并进行更长时间的训练,应该能够达到 95%至 97%的准确率。有了这个,你可以开始在自己的图像和类别上训练出色的图像分类器!但计算机视觉不仅仅是分类。例如,如果你还想知道图片中花朵的位置在哪里?让我们现在来看看。
分类和定位
在图片中定位一个对象可以被表达为一个回归任务,如第十章中讨论的:预测一个对象周围的边界框,一个常见的方法是预测对象中心的水平和垂直坐标,以及它的高度和宽度。这意味着我们有四个数字要预测。对模型不需要太多改变;我们只需要添加一个具有四个单元的第二个密集输出层(通常在全局平均池化层之上),并且可以使用 MSE 损失进行训练:
base_model = tf.keras.applications.xception.Xception(weights="imagenet",
include_top=False)
avg = tf.keras.layers.GlobalAveragePooling2D()(base_model.output)
class_output = tf.keras.layers.Dense(n_classes, activation="softmax")(avg)
loc_output = tf.keras.layers.Dense(4)(avg)
model = tf.keras.Model(inputs=base_model.input,
outputs=[class_output, loc_output])
model.compile(loss=["sparse_categorical_crossentropy", "mse"],
loss_weights=[0.8, 0.2], # depends on what you care most about
optimizer=optimizer, metrics=["accuracy"])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
但是现在我们有一个问题:花卉数据集中没有围绕花朵的边界框。因此,我们需要自己添加。这通常是机器学习项目中最困难和最昂贵的部分之一:获取标签。花时间寻找合适的工具是个好主意。要用边界框注释图像,您可能想使用开源图像标注工具,如 VGG Image Annotator、LabelImg、OpenLabeler 或 ImgLab,或者商业工具如 LabelBox 或 Supervisely。您还可以考虑众包平台,如亚马逊机械土耳其,如果您有大量图像需要注释。然而,设置众包平台、准备发送给工人的表格、监督他们并确保他们产生的边界框的质量是好的,这是相当多的工作,所以确保这是值得的。Adriana Kovashka 等人撰写了一篇非常实用的论文关于计算机视觉中的众包。我建议您查看一下,即使您不打算使用众包。如果只有几百张甚至几千张图像需要标记,并且您不打算经常这样做,最好自己做:使用合适的工具,只需要几天时间,您还将更好地了解您的数据集和任务。
现在假设您已经为花卉数据集中的每个图像获得了边界框(暂时假设每个图像只有一个边界框)。然后,您需要创建一个数据集,其项目将是经过预处理的图像的批次以及它们的类标签和边界框。每个项目应该是一个形式为(images, (class_labels, bounding_boxes))的元组。然后您就可以开始训练您的模型!
提示
边界框应该被归一化,使得水平和垂直坐标以及高度和宽度的范围都在 0 到 1 之间。此外,通常预测高度和宽度的平方根,而不是直接预测高度和宽度:这样,对于大边界框的 10 像素误差不会受到与小边界框的 10 像素误差一样多的惩罚。
均方误差通常作为训练模型的成本函数效果相当不错,但不是评估模型如何预测边界框的好指标。这方面最常见的度量是交并比(IoU):预测边界框与目标边界框之间的重叠区域除以它们的并集的面积(参见图 14-24)。在 Keras 中,它由tf.keras.metrics.MeanIoU类实现。
对单个对象进行分类和定位是很好的,但是如果图像中包含多个对象(通常在花卉数据集中是这种情况),怎么办呢?
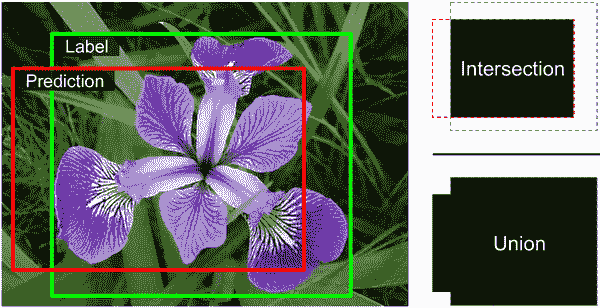
图 14-24。边界框的 IoU 度量
目标检测
在图像中对多个对象进行分类和定位的任务称为目标检测。直到几年前,一种常见的方法是采用一个 CNN,该 CNN 经过训练,可以对图像中大致位于中心的单个对象进行分类和定位,然后在图像上滑动这个 CNN,并在每一步进行预测。通常,CNN 被训练来预测不仅类别概率和边界框,还有一个对象性分数:这是估计的概率,即图像确实包含一个位于中心附近的对象。这是一个二元分类输出;它可以通过具有单个单元的密集输出层产生,使用 sigmoid 激活函数并使用二元交叉熵损失进行训练。
注意
有时会添加一个“无对象”类,而不是对象性分数,但总的来说,这并不起作用得很好:最好分开回答“是否存在对象?”和“对象的类型是什么?”这两个问题。
这种滑动 CNN 方法在图 14-25 中有所说明。在这个例子中,图像被切成了一个 5×7 的网格,我们看到一个 CNN——厚厚的黑色矩形——在所有 3×3 区域上滑动,并在每一步进行预测。
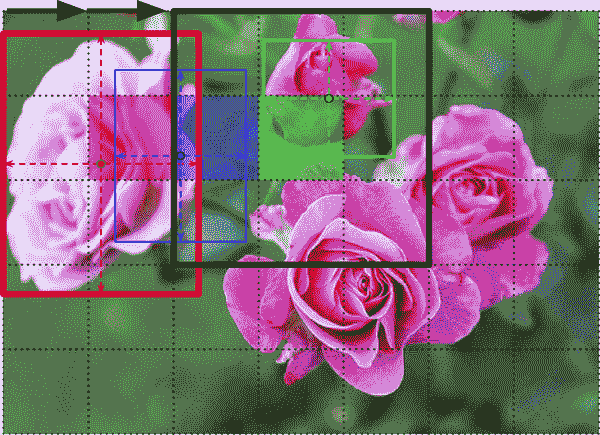
图 14-25。通过在图像上滑动 CNN 来检测多个对象
在这个图中,CNN 已经对这三个 3×3 区域进行了预测:
-
当查看左上角的 3×3 区域(位于第二行第二列的红色阴影网格单元中心)时,它检测到了最左边的玫瑰。请注意,预测的边界框超出了这个 3×3 区域的边界。这完全没问题:即使 CNN 看不到玫瑰的底部部分,它仍能合理猜测它可能在哪里。它还预测了类别概率,给“玫瑰”类别一个很高的概率。最后,它预测了一个相当高的物体得分,因为边界框的中心位于中心网格单元内(在这个图中,物体得分由边界框的厚度表示)。
-
当查看下一个 3×3 区域,向右移动一个网格单元(位于阴影蓝色正方形中心)时,它没有检测到任何位于该区域中心的花朵,因此预测的物体得分非常低;因此,可以安全地忽略预测的边界框和类别概率。您可以看到,预测的边界框也不好。
-
最后,当查看下一个 3×3 区域,再向右移动一个网格单元(位于阴影绿色单元中心)时,它检测到了顶部的玫瑰,尽管不完美:这朵玫瑰没有很好地位于该区域中心,因此预测的物体得分并不是很高。
您可以想象,将 CNN 滑动到整个图像上会给您总共 15 个预测的边界框,以 3×5 的网格组织,每个边界框都伴随着其估计的类别概率和物体得分。由于对象的大小可能不同,您可能希望再次在更大的 4×4 区域上滑动 CNN,以获得更多的边界框。
这种技术相当简单,但正如您所看到的,它经常会在稍微不同的位置多次检测到相同的对象。需要一些后处理来摆脱所有不必要的边界框。一个常见的方法是称为非极大值抑制。下面是它的工作原理:
-
首先,摆脱所有物体得分低于某个阈值的边界框:因为 CNN 认为该位置没有对象,所以边界框是无用的。
-
找到具有最高物体得分的剩余边界框,并摆脱所有与其重叠很多的其他剩余边界框(例如,IoU 大于 60%)。例如,在图 14-25 中,具有最大物体得分的边界框是覆盖最左边的玫瑰的厚边界框。与这朵相同玫瑰接触的另一个边界框与最大边界框重叠很多,因此我们将摆脱它(尽管在这个例子中,它在上一步中已经被移除)。
-
重复步骤 2,直到没有更多需要摆脱的边界框。
这种简单的目标检测方法效果相当不错,但需要多次运行 CNN(在这个例子中为 15 次),因此速度相当慢。幸运的是,有一种更快的方法可以在图像上滑动 CNN:使用全卷积网络(FCN)。
全卷积网络
FCN 的概念最初是由 Jonathan Long 等人在2015 年的一篇论文中提出的,用于语义分割(根据对象所属的类别对图像中的每个像素进行分类的任务)。作者指出,可以用卷积层替换 CNN 顶部的密集层。为了理解这一点,让我们看一个例子:假设一个具有 200 个神经元的密集层位于一个输出 100 个大小为 7×7 的特征图的卷积层的顶部(这是特征图的大小,而不是卷积核的大小)。每个神经元将计算来自卷积层的所有 100×7×7 激活的加权和(加上一个偏置项)。现在让我们看看如果我们用 200 个大小为 7×7 的滤波器和"valid"填充的卷积层来替换密集层会发生什么。这一层将输出 200 个大小为 1×1 的特征图(因为卷积核恰好是输入特征图的大小,而且我们使用"valid"填充)。换句话说,它将输出 200 个数字,就像密集层一样;如果你仔细观察卷积层执行的计算,你会注意到这些数字将与密集层产生的数字完全相同。唯一的区别是密集层的输出是一个形状为[批量大小, 200]的张量,而卷积层将输出一个形状为[批量大小, 1, 1, 200]的张量。
提示
要将密集层转换为卷积层,卷积层中的滤波器数量必须等于密集层中的单元数量,滤波器大小必须等于输入特征图的大小,并且必须使用"valid"填充。步幅可以设置为 1 或更多,稍后您将看到。
为什么这很重要?嗯,密集层期望特定的输入大小(因为它对每个输入特征有一个权重),而卷积层将愉快地处理任何大小的图像(但是,它期望其输入具有特定数量的通道,因为每个卷积核包含每个输入通道的不同权重集)。由于 FCN 只包含卷积层(和具有相同属性的池化层),它可以在任何大小的图像上进行训练和执行!
例如,假设我们已经训练了一个用于花卉分类和定位的 CNN。它是在 224×224 的图像上训练的,并输出 10 个数字:
-
输出 0 到 4 通过 softmax 激活函数发送,这给出了类别概率(每个类别一个)。
-
输出 5 通过 sigmoid 激活函数发送,这给出了物体得分。
-
输出 6 和 7 代表边界框的中心坐标;它们也经过 sigmoid 激活函数,以确保它们的范围在 0 到 1 之间。
-
最后,输出 8 和 9 代表边界框的高度和宽度;它们不经过任何激活函数,以允许边界框延伸到图像的边界之外。
现在我们可以将 CNN 的密集层转换为卷积层。实际上,我们甚至不需要重新训练它;我们可以直接将密集层的权重复制到卷积层!或者,在训练之前,我们可以将 CNN 转换为 FCN。
现在假设在输出层之前的最后一个卷积层(也称为瓶颈层)在网络输入 224×224 图像时输出 7×7 特征图(参见图 14-26 的左侧)。如果我们将 FCN 输入 448×448 图像(参见图 14-26 的右侧),瓶颈层现在将输出 14×14 特征图。³² 由于密集输出层被使用大小为 7×7 的 10 个滤波器的卷积层替换,使用"valid"填充和步幅 1,输出将由 10 个特征图组成,每个大小为 8×8(因为 14-7+1=8)。换句话说,FCN 将仅处理整个图像一次,并输出一个 8×8 的网格,其中每个单元包含 10 个数字(5 个类别概率,1 个物体性分数和 4 个边界框坐标)。这就像拿着原始 CNN 并在图像上每行移动 8 步,每列移动 8 步。为了可视化这一点,想象将原始图像切成一个 14×14 的网格,然后在这个网格上滑动一个 7×7 的窗口;窗口将有 8×8=64 个可能的位置,因此有 8×8 个预测。然而,FCN 方法要更有效,因为网络只看一次图像。事实上,You Only Look Once(YOLO)是一个非常流行的目标检测架构的名称,我们将在接下来看一下。
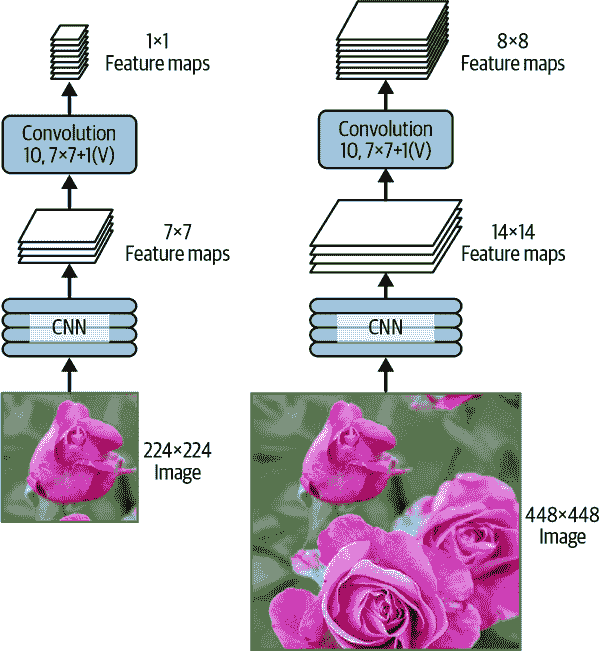
图 14-26。相同的全卷积网络处理小图像(左)和大图像(右)
只看一次
YOLO 是由 Joseph Redmon 等人在2015 年的一篇论文中提出的一种快速准确的目标检测架构。³³ 它非常快速,可以在视频上实时运行,就像在 Redmon 的演示中看到的那样。YOLO 的架构与我们刚讨论的架构非常相似,但有一些重要的区别:
-
对于每个网格单元,YOLO 只考虑边界框中心位于该单元内的对象。边界框坐标是相对于该单元的,其中(0, 0)表示单元的左上角,(1, 1)表示右下角。然而,边界框的高度和宽度可能远远超出单元。
-
它为每个网格单元输出两个边界框(而不仅仅是一个),这使得模型能够处理两个对象非常接近,以至于它们的边界框中心位于同一个单元格内的情况。每个边界框还附带自己的物体性分数。
-
YOLO 还为每个网格单元输出一个类别概率分布,每个网格单元预测 20 个类别概率,因为 YOLO 是在包含 20 个类别的 PASCAL VOC 数据集上训练的。这产生了一个粗糙的类别概率图。请注意,模型为每个网格单元预测一个类别概率分布,而不是每个边界框。然而,可以在后处理期间估计每个边界框的类别概率,方法是测量每个边界框与类别概率图中的每个类别匹配的程度。例如,想象一张图片中有一个人站在一辆车前面。将会有两个边界框:一个大的水平边界框用于车,一个较小的垂直边界框用于人。这些边界框的中心可能位于同一个网格单元内。那么我们如何确定应该为每个边界框分配哪个类别呢?嗯,类别概率图将包含一个“车”类占主导地位的大区域,里面将有一个“人”类占主导地位的较小区域。希望车的边界框大致匹配“车”区域,而人的边界框大致匹配“人”区域:这将允许为每个边界框分配正确的类别。
YOLO 最初是使用 Darknet 开发的,Darknet 是由 Joseph Redmon 最初用 C 开发的开源深度学习框架,但很快就被移植到了 TensorFlow、Keras、PyTorch 等。多年来不断改进,包括 YOLOv2、YOLOv3 和 YOLO9000(再次由 Joseph Redmon 等人开发)、YOLOv4(由 Alexey Bochkovskiy 等人开发)、YOLOv5(由 Glenn Jocher 开发)和 PP-YOLO(由 Xiang Long 等人开发)。
每个版本都带来了一些令人印象深刻的速度和准确性改进,使用了各种技术;例如,YOLOv3 在一定程度上提高了准确性,部分原因在于锚先验,利用了某些边界框形状比其他形状更有可能的事实,这取决于类别(例如,人们倾向于具有垂直边界框,而汽车通常不会)。他们还增加了每个网格单元的边界框数量,他们在不同数据集上进行了训练,包含更多类别(YOLO9000 的情况下最多达到 9,000 个类别,按层次结构组织),他们添加了跳跃连接以恢复在 CNN 中丢失的一些空间分辨率(我们将很快讨论这一点,当我们看语义分割时),等等。这些模型也有许多变体,例如 YOLOv4-tiny,它经过优化,可以在性能较弱的机器上进行训练,并且可以运行得非常快(每秒超过 1,000 帧!),但平均精度均值(mAP)略低。
许多目标检测模型都可以在 TensorFlow Hub 上找到,通常具有预训练权重,例如 YOLOv5、SSD、Faster R-CNN和EfficientDet。
SSD 和 EfficientDet 是“一次查看”检测模型,类似于 YOLO。EfficientDet 基于 EfficientNet 卷积架构。Faster R-CNN 更复杂:图像首先经过 CNN,然后输出传递给区域建议网络(RPN),该网络提出最有可能包含对象的边界框;然后为每个边界框运行分类器,基于 CNN 的裁剪输出。使用这些模型的最佳起点是 TensorFlow Hub 的出色目标检测教程。
到目前为止,我们只考虑在单个图像中检测对象。但是视频呢?对象不仅必须在每一帧中被检测到,还必须随着时间进行跟踪。现在让我们快速看一下目标跟踪。
目标跟踪
目标跟踪是一项具有挑战性的任务:对象移动,它们可能随着接近或远离摄像机而变大或变小,它们的外观可能会随着转身或移动到不同的光照条件或背景而改变,它们可能会被其他对象暂时遮挡,等等。
最受欢迎的目标跟踪系统之一是DeepSORT。它基于经典算法和深度学习的组合:
-
它使用Kalman 滤波器来估计给定先前检测的对象最可能的当前位置,并假设对象倾向于以恒定速度移动。
-
它使用深度学习模型来衡量新检测和现有跟踪对象之间的相似度。
-
最后,它使用匈牙利算法将新检测映射到现有跟踪对象(或新跟踪对象):该算法有效地找到最小化检测和跟踪对象预测位置之间距离的映射组合,同时最小化外观差异。
例如,想象一个红色球刚从相反方向移动的蓝色球上弹起。根据球的先前位置,卡尔曼滤波器将预测球会相互穿过:实际上,它假设对象以恒定速度移动,因此不会预期弹跳。如果匈牙利算法只考虑位置,那么它会愉快地将新的检测结果映射到错误的球上,就好像它们刚刚相互穿过并交换了颜色。但由于相似度度量,匈牙利算法会注意到问题。假设球不太相似,算法将新的检测结果映射到正确的球上。
提示
在 GitHub 上有一些 DeepSORT 的实现,包括 YOLOv4 + DeepSORT 的 TensorFlow 实现:https://github.com/theAIGuysCode/yolov4-deepsort。
到目前为止,我们已经使用边界框定位了对象。这通常足够了,但有时您需要更精确地定位对象,例如在视频会议中去除人物背后的背景。让我们看看如何降到像素级别。
语义分割
在语义分割中,每个像素根据其所属对象的类别进行分类(例如,道路、汽车、行人、建筑等),如图 14-27 所示。请注意,同一类别的不同对象不被区分。例如,分割图像右侧的所有自行车最终会成为一个大块像素。这项任务的主要困难在于,当图像经过常规 CNN 时,由于步幅大于 1 的层,它们逐渐失去空间分辨率;因此,常规 CNN 可能只会知道图像左下角某处有一个人,但不会比这更精确。

图 14-27. 语义分割
与目标检测一样,有许多不同的方法来解决这个问题,有些方法相当复杂。然而,在 Jonathan Long 等人于 2015 年提出的一篇关于完全卷积网络的论文中提出了一个相当简单的解决方案。作者首先采用了一个预训练的 CNN,并将其转换为 FCN。CNN 对输入图像应用了总步幅为 32(即,如果将所有大于 1 的步幅相加),这意味着最后一层输出的特征图比输入图像小 32 倍。这显然太粗糙了,因此他们添加了一个单一的上采样层,将分辨率乘以 32。
有几种可用的上采样解决方案(增加图像的大小),例如双线性插值,但这只能在×4 或×8 的范围内工作得相当好。相反,他们使用转置卷积层:³⁹这相当于首先通过插入空行和列(全是零)来拉伸图像,然后执行常规卷积(参见图 14-28)。或者,有些人更喜欢将其视为使用分数步幅的常规卷积层(例如,图 14-28 中的步幅为 1/2)。转置卷积层可以初始化为执行接近线性插值的操作,但由于它是一个可训练的层,在训练期间会学习做得更好。在 Keras 中,您可以使用Conv2DTranspose层。
注意
在转置卷积层中,步幅定义了输入将被拉伸多少,而不是滤波器步长的大小,因此步幅越大,输出就越大(与卷积层或池化层不同)。
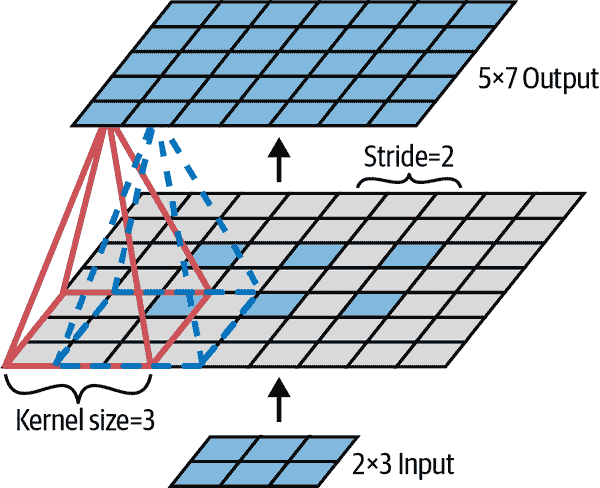
图 14-28. 使用转置卷积层进行上采样
使用转置卷积层进行上采样是可以的,但仍然太不精确。为了做得更好,Long 等人从较低层添加了跳跃连接:例如,他们将输出图像上采样了 2 倍(而不是 32 倍),并添加了具有这种双倍分辨率的较低层的输出。然后,他们将结果上采样了 16 倍,导致总的上采样因子为 32(参见图 14-29)。这恢复了在较早的池化层中丢失的一些空间分辨率。在他们最好的架构中,他们使用了第二个类似的跳跃连接,以从更低的层中恢复更精细的细节。简而言之,原始 CNN 的输出经过以下额外步骤:上采样×2,添加较低层的输出(适当比例),上采样×2,添加更低层的输出,最后上采样×8。甚至可以将缩放超出原始图像的大小:这可以用于增加图像的分辨率,这是一种称为超分辨率的技术。
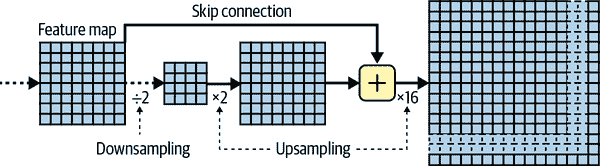
图 14-29。跳跃层从较低层恢复一些空间分辨率
实例分割类似于语义分割,但不是将同一类别的所有对象合并成一个大块,而是将每个对象与其他对象区分开来(例如,它识别每辆自行车)。例如,由 Kaiming He 等人在2017 年的一篇论文中提出的Mask R-CNN架构,通过为每个边界框额外生成一个像素掩码来扩展 Faster R-CNN 模型。因此,您不仅可以获得围绕每个对象的边界框,以及一组估计的类别概率,还可以获得一个像素掩码,该掩码定位属于对象的边界框中的像素。该模型可在 TensorFlow Hub 上获得,预训练于 COCO 2017 数据集。尽管该领域发展迅速,但如果您想尝试最新和最优秀的模型,请查看https://paperswithcode.com的最新技术部分。
正如您所看到的,深度计算机视觉领域广阔且快速发展,每年都会涌现出各种架构。几乎所有这些架构都基于卷积神经网络,但自 2020 年以来,另一种神经网络架构已进入计算机视觉领域:Transformer(我们将在第十六章中讨论)。过去十年取得的进步令人瞩目,研究人员现在正专注于越来越困难的问题,例如对抗学习(试图使网络更具抗干扰性,以防止被设计用来欺骗它的图像)、可解释性(了解网络为何做出特定分类)、现实图像生成(我们将在第十七章中回顾)、单次学习(一个系统只需看到一次对象就能识别该对象)、预测视频中的下一帧、结合文本和图像任务等等。
现在进入下一章,我们将看看如何使用递归神经网络和卷积神经网络处理序列数据,例如时间序列。
练习
-
相比于完全连接的 DNN,CNN 在图像分类方面有哪些优势?
-
考虑一个由三个卷积层组成的 CNN,每个卷积层都有 3×3 的内核,步幅为 2,且具有
"same"填充。最底层输出 100 个特征映射,中间层输出 200 个,顶层输出 400 个。输入图像是 200×300 像素的 RGB 图像:-
CNN 中的参数总数是多少?
-
如果我们使用 32 位浮点数,那么在对单个实例进行预测时,这个网络至少需要多少 RAM?
-
当在一个包含 50 张图像的小批量上进行训练时呢?
-
-
如果您的 GPU 在训练 CNN 时内存不足,您可以尝试哪五种方法来解决这个问题?
-
为什么要添加最大池化层而不是具有相同步幅的卷积层?
-
何时要添加局部响应归一化层?
-
您能否列出 AlexNet 相对于 LeNet-5 的主要创新?GoogLeNet、ResNet、SENet、Xception 和 EfficientNet 的主要创新又是什么?
-
什么是全卷积网络?如何将密集层转换为卷积层?
-
语义分割的主要技术难点是什么?
-
从头开始构建自己的 CNN,并尝试在 MNIST 上实现最高可能的准确性。
-
使用大型图像分类的迁移学习,经过以下步骤:
-
创建一个包含每类至少 100 张图像的训练集。例如,您可以根据位置(海滩、山脉、城市等)对自己的图片进行分类,或者您可以使用现有数据集(例如来自 TensorFlow 数据集)。
-
将其分为训练集、验证集和测试集。
-
构建输入管道,应用适当的预处理操作,并可选择添加数据增强。
-
在这个数据集上微调一个预训练模型。
-
-
按照 TensorFlow 的风格转移教程进行操作。这是使用深度学习生成艺术的有趣方式。
这些练习的解决方案可在本章笔记本的末尾找到,网址为https://homl.info/colab3。
(1)David H. Hubel,“不受限制的猫条纹皮层单元活动”,《生理学杂志》147 卷(1959 年):226-238。
(2)David H. Hubel 和 Torsten N. Wiesel,“猫条纹皮层单个神经元的感受野”,《生理学杂志》148 卷(1959 年):574-591。
(3)David H. Hubel 和 Torsten N. Wiesel,“猴子条纹皮层的感受野和功能结构”,《生理学杂志》195 卷(1968 年):215-243。
(4)福岛邦彦,“Neocognitron:一种不受位置偏移影响的模式识别机制的自组织神经网络模型”,《生物控制论》36 卷(1980 年):193-202。
(5)Yann LeCun 等人,“基于梯度的学习应用于文档识别”,《IEEE 会议录》86 卷,第 11 期(1998 年):2278-2324。
(6)卷积是一种数学操作,它将一个函数滑动到另一个函数上,并测量它们逐点乘积的积分。它与傅里叶变换和拉普拉斯变换有深刻的联系,并且在信号处理中被广泛使用。卷积层实际上使用交叉相关,这与卷积非常相似(有关更多详细信息,请参见https://homl.info/76)。
(7)为了产生相同大小的输出,一个全连接层需要 200×150×100 个神经元,每个神经元连接到所有 150×100×3 个输入。它将有 200×150×100×(150×100×3+1)≈1350 亿个参数!
(8)在国际单位制(SI)中,1 MB = 1,000 KB = 1,000×1,000 字节 = 1,000×1,000×8 位。而 1 MiB = 1,024 kiB = 1,024×1,024 字节。所以 12 MB ≈ 11.44 MiB。
(9)我们迄今讨论过的其他内核具有权重,但池化内核没有:它们只是无状态的滑动窗口。
(10)Yann LeCun 等人,“基于梯度的学习应用于文档识别”,《IEEE 会议录》86 卷,第 11 期(1998 年):2278-2324。
(11)Alex Krizhevsky 等人,“使用深度卷积神经网络对 ImageNet 进行分类”,《第 25 届国际神经信息处理系统会议论文集》1 卷(2012 年):1097-1105。
¹² Matthew D. Zeiler 和 Rob Fergus,“可视化和理解卷积网络”,欧洲计算机视觉会议论文集(2014):818-833。
¹³ Christian Szegedy 等人,“使用卷积深入”,IEEE 计算机视觉和模式识别会议论文集(2015):1-9。
¹⁴ 在 2010 年的电影Inception中,角色们不断深入多层梦境;因此这些模块的名称。
¹⁵ Karen Simonyan 和 Andrew Zisserman,“用于大规模图像识别的非常深的卷积网络”,arXiv 预印本 arXiv:1409.1556(2014)。
¹⁶ Kaiming He 等人,“用于图像识别的深度残差学习”,arXiv 预印本 arXiv:1512:03385(2015)。
¹⁷ 描述神经网络时,通常只计算具有参数的层。
¹⁸ Christian Szegedy 等人,“Inception-v4,Inception-ResNet 和残差连接对学习的影响”,arXiv 预印本 arXiv:1602.07261(2016)。
¹⁹ François Chollet,“Xception:深度学习与深度可分离卷积”,arXiv 预印本 arXiv:1610.02357(2016)。
²⁰ 这个名称有时可能会有歧义,因为空间可分离卷积通常也被称为“可分离卷积”。
²¹ Jie Hu 等人,“挤压激励网络”,IEEE 计算机视觉和模式识别会议论文集(2018):7132-7141。
²² Saining Xie 等人,“聚合残差变换用于深度神经网络”,arXiv 预印本 arXiv:1611.05431(2016)。
²³ Gao Huang 等人,“密集连接卷积网络”,arXiv 预印本 arXiv:1608.06993(2016)。
²⁴ Andrew G. Howard 等人,“MobileNets:用于移动视觉应用的高效卷积神经网络”,arXiv 预印本 arxiv:1704.04861(2017)。
²⁵ Chien-Yao Wang 等人,“CSPNet:一种可以增强 CNN 学习能力的新骨干”,arXiv 预印本 arXiv:1911.11929(2019)。
²⁶ Mingxing Tan 和 Quoc V. Le,“EfficientNet:重新思考卷积神经网络的模型缩放”,arXiv 预印本 arXiv:1905.11946(2019)。
²⁷ 一款 92 核心的 AMD EPYC CPU,带有 IBPB,1.7 TB 的 RAM 和一款 Nvidia Tesla A100 GPU。
²⁸ 在 ImageNet 数据集中,每个图像都映射到WordNet 数据集中的一个单词:类别 ID 只是一个 WordNet ID。
²⁹ Adriana Kovashka 等人,“计算机视觉中的众包”,计算机图形学和视觉基础与趋势 10,第 3 期(2014):177-243。
³⁰ Jonathan Long 等人,“用于语义分割的全卷积网络”,IEEE 计算机视觉和模式识别会议论文集(2015):3431-3440。
³¹ 有一个小例外:使用"valid"填充的卷积层会在输入大小小于核大小时报错。
³² 这假设我们在网络中只使用了"same"填充:"valid"填充会减小特征图的大小。此外,448 可以被 2 整除多次,直到达到 7,没有任何舍入误差。如果任何一层使用不同于 1 或 2 的步幅,那么可能会有一些舍入误差,因此特征图最终可能会变小。
³³ Joseph Redmon 等人,“You Only Look Once: Unified, Real-Time Object Detection”,《IEEE 计算机视觉与模式识别会议论文集》(2016):779–788。
³⁴ 您可以在 TensorFlow Models 项目中找到 YOLOv3、YOLOv4 及其微小变体,网址为https://homl.info/yolotf。
³⁵ Wei Liu 等人,“SSD: Single Shot Multibox Detector”,《第 14 届欧洲计算机视觉会议论文集》1(2016):21–37。
³⁶ Shaoqing Ren 等人,“Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks”,《第 28 届国际神经信息处理系统会议论文集》1(2015):91–99。
³⁷ Mingxing Tan 等人,“EfficientDet: Scalable and Efficient Object Detection”,arXiv 预印本 arXiv:1911.09070(2019)。
³⁸ Nicolai Wojke 等人,“Simple Online and Realtime Tracking with a Deep Association Metric”,arXiv 预印本 arXiv:1703.07402(2017)。
³⁹ 这种类型的层有时被称为反卷积层,但它不执行数学家所说的反卷积,因此应避免使用这个名称。
⁴⁰ Kaiming He 等人,“Mask R-CNN”,arXiv 预印本 arXiv:1703.06870(2017)。
第十五章:使用 RNNs 和 CNNs 处理序列
预测未来是你经常做的事情,无论是在结束朋友的句子还是预期早餐时咖啡的味道。在本章中,我们将讨论循环神经网络(RNNs)-一类可以预测未来的网络(嗯,至少在一定程度上)。RNNs 可以分析时间序列数据,例如您网站上每日活跃用户的数量,您所在城市的每小时温度,您家每日的用电量,附近汽车的轨迹等等。一旦 RNN 学习了数据中的过去模式,它就能利用自己的知识来预测未来,当然前提是过去的模式在未来仍然成立。
更一般地说,RNNs 可以处理任意长度的序列,而不是固定大小的输入。例如,它们可以将句子、文档或音频样本作为输入,使它们非常适用于自然语言处理应用,如自动翻译或语音转文本。
在本章中,我们将首先介绍 RNNs 的基本概念以及如何使用时间反向传播来训练它们。然后,我们将使用它们来预测时间序列。在此过程中,我们将研究常用的 ARMA 模型系列,通常用于预测时间序列,并将它们用作与我们的 RNNs 进行比较的基准。之后,我们将探讨 RNNs 面临的两个主要困难:
-
不稳定的梯度(在第十一章中讨论),可以通过各种技术来缓解,包括循环丢失和循环层归一化。
-
(非常)有限的短期记忆,可以使用 LSTM 和 GRU 单元进行扩展。
RNNs 并不是处理序列数据的唯一类型的神经网络。对于小序列,常规的密集网络可以胜任,而对于非常长的序列,例如音频样本或文本,卷积神经网络也可以表现得相当不错。我们将讨论这两种可能性,并通过实现 WaveNet 来结束本章-一种能够处理数万个时间步的 CNN 架构。让我们开始吧!
循环神经元和层
到目前为止,我们已经专注于前馈神经网络,其中激活仅在一个方向中流动,从输入层到输出层。循环神经网络看起来非常像前馈神经网络,只是它还有指向后方的连接。
让我们看看最简单的 RNN,由一个神经元组成,接收输入,产生输出,并将该输出发送回自身,如图 15-1(左)所示。在每个时间步 t(也称为帧),这个循环神经元接收输入x[(t)]以及来自上一个时间步的自己的输出ŷ[(t–1)]。由于在第一个时间步没有先前的输出,通常将其设置为 0。我们可以沿着时间轴表示这个小网络,如图 15-1(右)所示。这被称为将网络展开到时间轴(每个时间步表示一个循环神经元)。
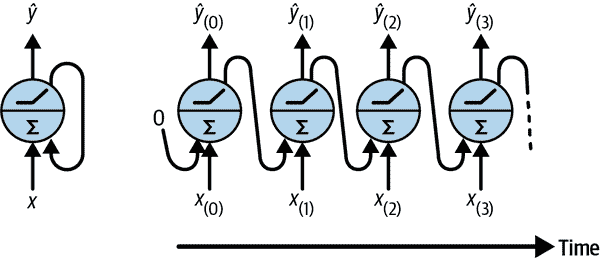
图 15-1. 一个循环神经元(左)在时间轴上展开(右)
您可以轻松创建一个循环神经元层。在每个时间步t,每个神经元都接收来自输入向量x[(t)]和上一个时间步的输出向量ŷ[(t–1)],如图 15-2 所示。请注意,现在输入和输出都是向量(当只有一个神经元时,输出是标量)。
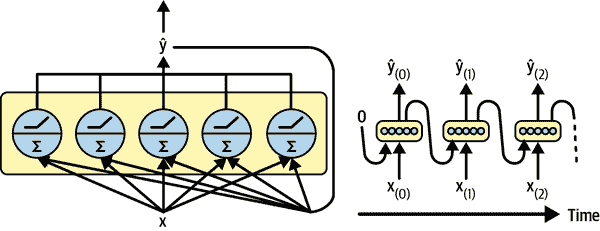
图 15-2. 一个循环神经元层(左)在时间轴上展开(右)
每个递归神经元有两组权重:一组用于输入x[(t)],另一组用于上一个时间步的输出ŷ[(t–1)]。让我们称这些权重向量为w[x]和w[ŷ]。如果我们考虑整个递归层而不仅仅是一个递归神经元,我们可以将所有权重向量放入两个权重矩阵:W[x]和W[ŷ]。
整个递归层的输出向量可以按照你所期望的方式计算,如方程 15-1 所示,其中b是偏置向量,ϕ(·)是激活函数(例如,ReLU¹)。
方程 15-1. 单个实例的递归层输出
ŷ(t)=ϕWx⊺x(t)+Wŷ⊺ŷ(t-1)+b
就像前馈神经网络一样,我们可以通过将时间步t的所有输入放入输入矩阵X[(t)](参见方程 15-2)来一次性计算整个小批量的递归层输出。
方程 15-2. 一次传递中递归神经元层的所有实例的输出:[小批量
Ŷ (t) = ϕ X (t) W x + Ŷ (t-1) W ŷ + b = ϕ X (t) Ŷ (t-1) W + b with W = W x W ŷ
在这个方程中:
-
Ŷ[(t)]是一个m×n[neurons]矩阵,包含小批量中每个实例在时间步t的层输出(m是小批量中实例的数量,n[neurons]是神经元的数量)。
-
X[(t)]是一个m×n[inputs]矩阵,包含所有实例的输入(n[inputs]是输入特征的数量)。
-
W[x]是一个n[inputs]×n[neurons]矩阵,包含当前时间步输入的连接权重。
-
W[ŷ]是一个n[neurons]×n[neurons]矩阵,包含上一个时间步输出的连接权重。
-
b是一个大小为n[neurons]的向量,包含每个神经元的偏置项。
-
权重矩阵W[x]和W[ŷ]通常垂直连接成一个形状为(n[inputs] + n[neurons]) × n[neurons]的单个权重矩阵W(参见方程 15-2 的第二行)。
-
符号[X[(t)] Ŷ[(t–1)]]表示矩阵X[(t)]和Ŷ[(t–1)]的水平连接。
注意,Ŷ[(t)]是X[(t)]和Ŷ[(t–1)]的函数,X[(t–1)]和Ŷ[(t–2)]的函数,X[(t–2)]和Ŷ[(t–3)]的函数,依此类推。这使得Ŷ[(t)]是自时间t=0(即X[(0)], X[(1)], …, X[(t)])以来所有输入的函数。在第一个时间步骤,t=0 时,没有先前的输出,因此通常假定它们都是零。
记忆单元
由于递归神经元在时间步骤t的输出是前几个时间步骤的所有输入的函数,因此可以说它具有一种记忆形式。在时间步骤之间保留一些状态的神经网络的一部分称为记忆单元(或简称单元)。单个递归神经元或一层递归神经元是一个非常基本的单元,只能学习短模式(通常约为 10 个步骤长,但这取决于任务)。在本章后面,我们将看一些更复杂和强大的单元类型,能够学习更长的模式(大约长 10 倍,但这也取决于任务)。
时间步骤t时的单元状态,表示为h[(t)](“h”代表“隐藏”),是该时间步骤的一些输入和上一个时间步骤的状态的函数:h[(t)] = f(x[(t)], h[(t–1)])。在时间步骤t的输出,表示为ŷ[(t)],也是前一个状态和当前输入的函数。在我们迄今讨论的基本单元的情况下,输出只等于状态,但在更复杂的单元中,情况并非总是如此,如图 15-3 所示。
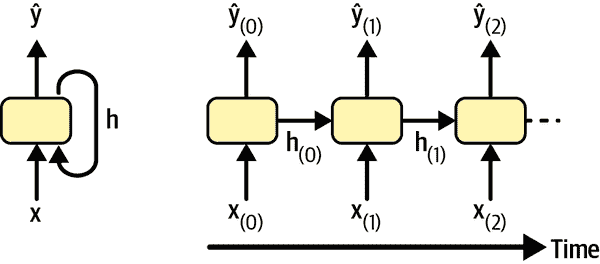
图 15-3。单元的隐藏状态和输出可能不同
输入和输出序列
RNN 可以同时接受一系列输入并产生一系列输出(参见图 15-4 左上方的网络)。这种序列到序列网络对于预测时间序列非常有用,例如您家每天的用电量:您向其提供过去N天的数据,并训练它输出将来一天的用电量(即从N – 1 天前到明天)。
或者,您可以向网络提供一系列输入并忽略除最后一个之外的所有输出(参见图 15-4 右上方的网络)。这是一个序列到向量网络。例如,您可以向网络提供与电影评论相对应的一系列单词,网络将输出情感分数(例如,从 0 [讨厌]到 1 [喜爱])。
相反,您可以在每个时间步骤反复向网络提供相同的输入向量,并让它输出一个序列(参见图 15-4 左下方的网络)。这是一个向量到序列网络。例如,输入可以是一幅图像(或 CNN 的输出),输出可以是该图像的标题。
最后,您可以有一个序列到向量网络,称为编码器,后面是一个向量到序列网络,称为解码器(参见图 15-4 的右下方网络)。例如,这可以用于将一种语言的句子翻译成另一种语言。您将向网络提供一种语言的句子,编码器将把这个句子转换成一个单一的向量表示,然后解码器将把这个向量解码成另一种语言的句子。这种两步模型,称为编码器-解码器²比尝试使用单个序列到序列的 RNN 实时翻译要好得多(就像左上角表示的那种):一个句子的最后几个词可能会影响翻译的前几个词,因此您需要等到看完整个句子后再进行翻译。我们将在第十六章中介绍编码器-解码器的实现(正如您将看到的,它比图 15-4 所暗示的要复杂一些)。
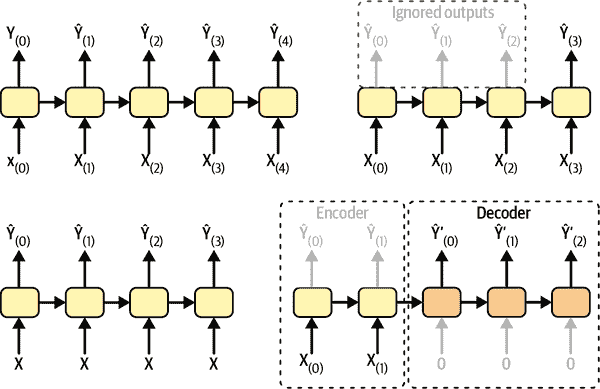
图 15-4. 序列到序列(左上)、序列到向量(右上)、向量到序列(左下)和编码器-解码器(右下)网络
这种多功能性听起来很有前途,但如何训练循环神经网络呢?
训练 RNNs
要训练 RNN,关键是将其通过时间展开(就像我们刚刚做的那样),然后使用常规的反向传播(参见图 15-5)。这种策略称为通过时间的反向传播(BPTT)。
就像常规反向传播一样,首先通过展开的网络进行第一次前向传递(由虚线箭头表示)。然后使用损失函数ℒ(Y[(0)], Y[(1)], …, Y[(T)]; Ŷ[(0)], Ŷ[(1)], …, Ŷ[(T)])评估输出序列(其中Y[(i)]是第i个目标,Ŷ[(i)]是第i个预测,T是最大时间步长)。请注意,此损失函数可能会忽略一些输出。例如,在序列到向量的 RNN 中,除了最后一个输出之外,所有输出都会被忽略。在图 15-5 中,损失函数仅基于最后三个输出计算。然后,该损失函数的梯度通过展开的网络向后传播(由实线箭头表示)。在这个例子中,由于输出Ŷ[(0)]和Ŷ[(1)]没有用于计算损失,梯度不会通过它们向后传播;它们只会通过Ŷ[(2)]、Ŷ[(3)]和Ŷ[(4)]向后传播。此外,由于在每个时间步骤中使用相同的参数W和b,它们的梯度将在反向传播过程中被多次调整。一旦反向阶段完成并计算出所有梯度,BPTT 可以执行梯度下降步骤来更新参数(这与常规反向传播没有区别)。
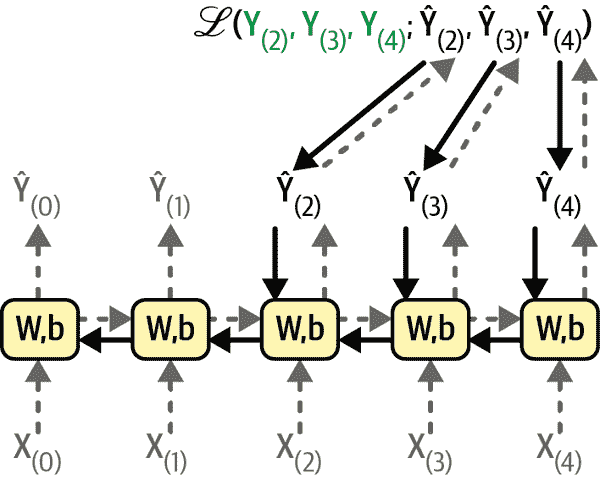
图 15-5. 通过时间反向传播
幸运的是,Keras 会为您处理所有这些复杂性,您将看到。但在我们到达那里之前,让我们加载一个时间序列,并开始使用传统工具进行分析,以更好地了解我们正在处理的内容,并获得一些基准指标。
预测时间序列
好了!假设您刚被芝加哥交通管理局聘为数据科学家。您的第一个任务是构建一个能够预测明天公交和轨道乘客数量的模型。您可以访问自 2001 年以来的日常乘客数据。让我们一起看看您将如何处理这个问题。我们将从加载和清理数据开始:
import pandas as pd
from pathlib import Path
path = Path("datasets/ridership/CTA_-_Ridership_-_Daily_Boarding_Totals.csv")
df = pd.read_csv(path, parse_dates=["service_date"])
df.columns = ["date", "day_type", "bus", "rail", "total"] # shorter names
df = df.sort_values("date").set_index("date")
df = df.drop("total", axis=1) # no need for total, it's just bus + rail
df = df.drop_duplicates() # remove duplicated months (2011-10 and 2014-07)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
我们加载 CSV 文件,设置短列名,按日期对行进行排序,删除多余的total列,并删除重复行。现在让我们看看前几行是什么样子的:
>>> df.head()
day_type bus rail
date
2001-01-01 U 297192 126455
2001-01-02 W 780827 501952
2001-01-03 W 824923 536432
2001-01-04 W 870021 550011
2001-01-05 W 890426 557917
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在 2001 年 1 月 1 日,芝加哥有 297,192 人乘坐公交车,126,455 人乘坐火车。day_type列包含W表示工作日,A表示周六,U表示周日或假期。
现在让我们绘制 2019 年几个月的公交和火车乘客量数据,看看它是什么样子的(参见图 15-6):
import matplotlib.pyplot as plt
df["2019-03":"2019-05"].plot(grid=True, marker=".", figsize=(8, 3.5))
plt.show()
- 1
- 2
- 3
- 4
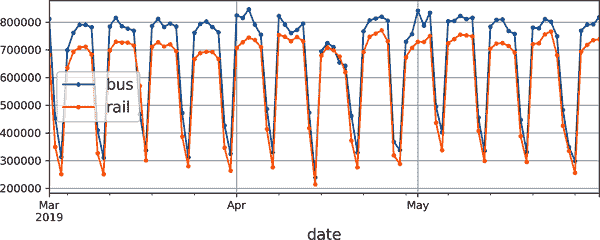
图 15-6。芝加哥的日常乘客量
请注意,Pandas 在范围中包括起始月份和结束月份,因此这将绘制从 3 月 1 日到 5 月 31 日的数据。这是一个时间序列:在不同时间步长上具有值的数据,通常在规则间隔上。更具体地说,由于每个时间步长有多个值,因此称为多变量时间序列。如果我们只看bus列,那将是一个单变量时间序列,每个时间步长有一个值。在处理时间序列时,预测未来值(即预测)是最典型的任务,这也是我们将在本章中重点关注的内容。其他任务包括插补(填补缺失的过去值)、分类、异常检测等。
查看图 15-6,我们可以看到每周明显重复的类似模式。这被称为每周季节性。实际上,在这种情况下,季节性非常强,通过简单地复制一周前的值来预测明天的乘客量将产生相当不错的结果。这被称为天真预测:简单地复制过去的值来进行预测。天真预测通常是一个很好的基准,有时甚至在某些情况下很难超越。
注意
一般来说,天真预测意味着复制最新已知值(例如,预测明天与今天相同)。然而,在我们的情况下,复制上周的值效果更好,因为存在强烈的每周季节性。
为了可视化这些天真预测,让我们将两个时间序列(公交和火车)以及相同时间序列向右移动一周(即向右移动)的时间序列叠加使用虚线。我们还将绘制两者之间的差异(即时间t处的值减去时间t - 7 处的值);这称为差分(参见图 15-7):
diff_7 = df[["bus", "rail"]].diff(7)["2019-03":"2019-05"]
fig, axs = plt.subplots(2, 1, sharex=True, figsize=(8, 5))
df.plot(ax=axs[0], legend=False, marker=".") # original time series
df.shift(7).plot(ax=axs[0], grid=True, legend=False, linestyle=":") # lagged
diff_7.plot(ax=axs[1], grid=True, marker=".") # 7-day difference time series
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
不错!注意滞后时间序列如何紧密跟踪实际时间序列。当一个时间序列与其滞后版本相关联时,我们说该时间序列是自相关的。正如您所看到的,大多数差异都相当小,除了五月底。也许那时有一个假期?让我们检查day_type列:
>>> list(df.loc["2019-05-25":"2019-05-27"]["day_type"])
['A', 'U', 'U']
- 1
- 2
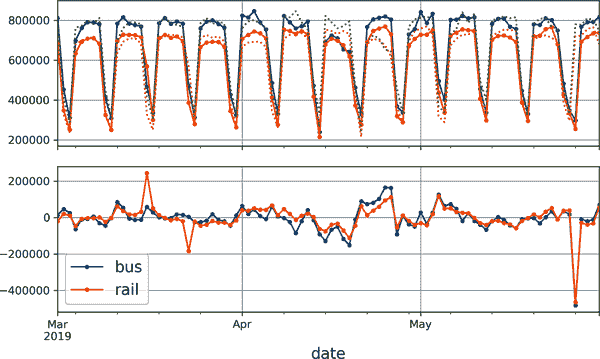
图 15-7。与 7 天滞后时间序列叠加的时间序列(顶部),以及t和t - 7 之间的差异(底部)
事实上,那时有一个长周末:周一是阵亡将士纪念日假期。我们可以使用这一列来改进我们的预测,但现在让我们只测量我们任意关注的三个月期间(2019 年 3 月、4 月和 5 月)的平均绝对误差,以获得一个大致的概念:
>>> diff_7.abs().mean()
bus 43915.608696
rail 42143.271739
dtype: float64
- 1
- 2
- 3
- 4
我们的天真预测得到大约 43,916 名公交乘客和约 42,143 名火车乘客的 MAE。一眼看去很难判断这是好是坏,所以让我们将预测误差放入透视中,通过将它们除以目标值来进行评估:
>>> targets = df[["bus", "rail"]]["2019-03":"2019-05"]
>>> (diff_7 / targets).abs().mean()
bus 0.082938
rail 0.089948
dtype: float64
- 1
- 2
- 3
- 4
- 5
我们刚刚计算的是平均绝对百分比误差(MAPE):看起来我们的天真预测为公交大约为 8.3%,火车为 9.0%。有趣的是,火车预测的 MAE 看起来比公交预测的稍好一些,而 MAPE 则相反。这是因为公交乘客量比火车乘客量大,因此自然预测误差也更大,但当我们将误差放入透视时,结果表明公交预测实际上略优于火车预测。
提示
MAE、MAPE 和 MSE 是评估预测的最常见指标之一。与往常一样,选择正确的指标取决于任务。例如,如果您的项目对大误差的影响是小误差的平方倍,那么 MSE 可能更可取,因为它会严厉惩罚大误差。
观察时间序列,似乎没有明显的月度季节性,但让我们检查一下是否存在年度季节性。我们将查看 2001 年至 2019 年的数据。为了减少数据窥探的风险,我们暂时忽略更近期的数据。让我们为每个系列绘制一个 12 个月的滚动平均线,以可视化长期趋势(参见图 15-8):
period = slice("2001", "2019")
df_monthly = df.resample('M').mean() # compute the mean for each month
rolling_average_12_months = df_monthly[period].rolling(window=12).mean()
fig, ax = plt.subplots(figsize=(8, 4))
df_monthly[period].plot(ax=ax, marker=".")
rolling_average_12_months.plot(ax=ax, grid=True, legend=False)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
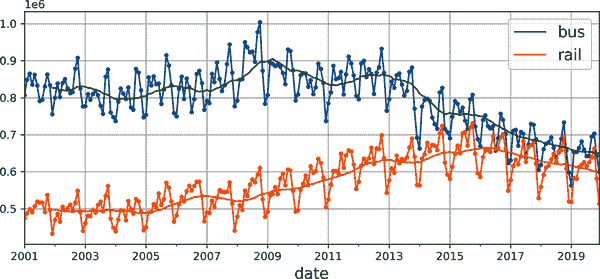
图 15-8。年度季节性和长期趋势
是的!确实存在一些年度季节性,尽管比每周季节性更嘈杂,对于铁路系列而言更为明显,而不是公交系列:我们看到每年大致相同日期出现高峰和低谷。让我们看看如果绘制 12 个月的差分会得到什么(参见图 15-9):
df_monthly.diff(12)[period].plot(grid=True, marker=".", figsize=(8, 3))
plt.show()
- 1
- 2
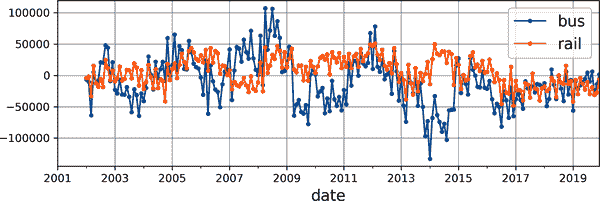
图 15-9。12 个月的差分
注意,差分不仅消除了年度季节性,还消除了长期趋势。例如,2016 年至 2019 年时间序列中存在的线性下降趋势在差分时间序列中变为大致恒定的负值。事实上,差分是一种常用的技术,用于消除时间序列中的趋势和季节性:研究平稳时间序列更容易,这意味着其统计特性随时间保持不变,没有任何季节性或趋势。一旦您能够对差分时间序列进行准确的预测,只需将先前减去的过去值添加回来,就可以将其转换为实际时间序列的预测。
您可能会认为我们只是试图预测明天的乘客量,因此长期模式比短期模式更不重要。您是对的,但是,通过考虑长期模式,我们可能能够稍微提高性能。例如,2017 年 10 月,每日公交乘客量减少了约 2500 人,这代表每周减少约 570 名乘客,因此如果我们处于 2017 年 10 月底,通过从上周复制数值,减去 570,来预测明天的乘客量是有道理的。考虑趋势将使您的平均预测略微更准确。
现在您熟悉了乘客量时间序列,以及时间序列分析中一些最重要的概念,包括季节性、趋势、差分和移动平均,让我们快速看一下一个非常流行的统计模型家族,通常用于分析时间序列。
ARMA 模型家族
我们将从上世纪 30 年代由赫尔曼·沃尔德(Herman Wold)开发的自回归移动平均(ARMA)模型开始:它通过对滞后值的简单加权和添加移动平均来计算其预测,非常类似我们刚刚讨论的。具体来说,移动平均分量是通过最近几个预测误差的加权和来计算的。方程 15-3 展示了该模型如何进行预测。
第 15-3 方程。使用 ARMA 模型进行预测
y^(t)=∑i=1pαiy(t-i)+∑i=1qθiϵ(t-i)with ϵ(t)=y(t)-y^(t)
在这个方程中:
-
ŷ[(t)]是模型对时间步t的预测。
-
y[(t)]是时间步t的时间序列值。
-
第一个总和是时间序列过去p个值的加权和,使用学习到的权重α[i]。数字p是一个超参数,它决定模型应该查看过去多远。这个总和是模型的自回归组件:它基于过去的值执行回归。
-
第二个总和是过去q个预测误差ε[(t)]的加权和,使用学习到的权重θ[i]。数字q是一个超参数。这个总和是模型的移动平均组件。
重要的是,这个模型假设时间序列是平稳的。如果不是,那么差分可能有所帮助。在一个时间步上使用差分将产生时间序列的导数的近似值:实际上,它将给出每个时间步的系列斜率。这意味着它将消除任何线性趋势,将其转换为一个常数值。例如,如果你对系列[3, 5, 7, 9, 11]应用一步差分,你会得到差分系列[2, 2, 2, 2]。
如果原始时间序列具有二次趋势而不是线性趋势,那么一轮差分将不足够。例如,系列[1, 4, 9, 16, 25, 36]经过一轮差分后变为[3, 5, 7, 9, 11],但如果你再进行第二轮差分,你会得到[2, 2, 2, 2]。因此,进行两轮差分将消除二次趋势。更一般地,连续运行d轮差分计算时间序列的d阶导数的近似值,因此它将消除多项式趋势直到d阶。这个超参数d被称为积分阶数。
差分是 1970 年由乔治·博克斯和格威林·詹金斯在他们的书《时间序列分析》(Wiley)中介绍的自回归积分移动平均(ARIMA)模型的核心贡献:这个模型运行d轮差分使时间序列更平稳,然后应用常规 ARMA 模型。在进行预测时,它使用这个 ARMA 模型,然后将差分减去的项加回来。
ARMA 家族的最后一个成员是季节性 ARIMA(SARIMA)模型:它以与 ARIMA 相同的方式对时间序列建模,但另外还为给定频率(例如每周)建模一个季节性组件,使用完全相同的 ARIMA 方法。它总共有七个超参数:与 ARIMA 相同的p、d和q超参数,再加上额外的P、D和Q超参数来建模季节性模式,最后是季节性模式的周期,标记为s。超参数P、D和Q就像p、d和q一样,但它们用于模拟时间序列在t – s、t – 2s、t – 3s等时刻。
让我们看看如何将 SARIMA 模型拟合到铁路时间序列,并用它来预测明天的乘客量。我们假设今天是 2019 年 5 月的最后一天,我们想要预测“明天”,也就是 2019 年 6 月 1 日的铁路乘客量。为此,我们可以使用statsmodels库,其中包含许多不同的统计模型,包括由ARIMA类实现的 ARMA 模型及其变体:
from statsmodels.tsa.arima.model import ARIMA
origin, today = "2019-01-01", "2019-05-31"
rail_series = df.loc[origin:today]["rail"].asfreq("D")
model = ARIMA(rail_series,
order=(1, 0, 0),
seasonal_order=(0, 1, 1, 7))
model = model.fit()
y_pred = model.forecast() # returns 427,758.6
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在这个代码示例中:
-
我们首先导入
ARIMA类,然后我们从 2019 年初开始到“今天”获取铁路乘客数据,并使用asfreq("D")将时间序列的频率设置为每天:在这种情况下,这不会改变数据,因为它已经是每天的,但如果没有这个,ARIMA类将不得不猜测频率,并显示警告。 -
接下来,我们创建一个
ARIMA实例,将所有数据传递到“今天”,并设置模型超参数:order=(1, 0, 0)表示p=1,d=0,q=0,seasonal_order=(0, 1, 1, 7)表示P=0,D=1,Q=1,s=7。请注意,statsmodelsAPI 与 Scikit-Learn 的 API 有些不同,因为我们在构建时将数据传递给模型,而不是将数据传递给fit()方法。 -
接下来,我们拟合模型,并用它为“明天”,也就是 2019 年 6 月 1 日,做出预测。
预测为 427,759 名乘客,而实际上有 379,044 名。哎呀,我们偏差 12.9%——这相当糟糕。实际上,这比天真预测稍微糟糕,天真预测为 426,932,偏差为 12.6%。但也许那天我们只是运气不好?为了检查这一点,我们可以在循环中运行相同的代码,为三月、四月和五月的每一天进行预测,并计算该期间的平均绝对误差:
origin, start_date, end_date = "2019-01-01", "2019-03-01", "2019-05-31"
time_period = pd.date_range(start_date, end_date)
rail_series = df.loc[origin:end_date]["rail"].asfreq("D")
y_preds = []
for today in time_period.shift(-1):
model = ARIMA(rail_series[origin:today], # train on data up to "today"
order=(1, 0, 0),
seasonal_order=(0, 1, 1, 7))
model = model.fit() # note that we retrain the model every day!
y_pred = model.forecast()[0]
y_preds.append(y_pred)
y_preds = pd.Series(y_preds, index=time_period)
mae = (y_preds - rail_series[time_period]).abs().mean() # returns 32,040.7
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
啊,好多了!平均绝对误差约为 32,041,比我们用天真预测得到的平均绝对误差(42,143)显著低。因此,虽然模型并不完美,但平均而言仍然远远超过天真预测。
此时,您可能想知道如何为 SARIMA 模型选择良好的超参数。有几种方法,但最简单的方法是粗暴的方法:进行网格搜索。对于要评估的每个模型(即每个超参数组合),您可以运行前面的代码示例,仅更改超参数值。通常p、q、P和Q值较小(通常为 0 到 2,有时可达 5 或 6),d和D通常为 0 或 1,有时为 2。至于s,它只是主要季节模式的周期:在我们的情况下是 7,因为有强烈的每周季节性。具有最低平均绝对误差的模型获胜。当然,如果它更符合您的业务目标,您可以用另一个指标替换平均绝对误差。就是这样!
为机器学习模型准备数据
现在我们有了两个基线,天真预测和 SARIMA,让我们尝试使用迄今为止涵盖的机器学习模型来预测这个时间序列,首先从基本的线性模型开始。我们的目标是根据过去 8 周(56 天)的数据来预测明天的乘客量。因此,我们模型的输入将是序列(通常是生产中的每天一个序列),每个序列包含从时间步t - 55 到t的 56 个值。对于每个输入序列,模型将输出一个值:时间步t + 1 的预测。
但我们将使用什么作为训练数据呢?嗯,这就是诀窍:我们将使用过去的每个 56 天窗口作为训练数据,每个窗口的目标将是紧随其后的值。
Keras 实际上有一个很好的实用函数称为tf.keras.utils.timeseries_dataset_from_array(),帮助我们准备训练集。它以时间序列作为输入,并构建一个 tf.data.Dataset(在第十三章中介绍)包含所需长度的所有窗口,以及它们对应的目标。以下是一个示例,它以包含数字 0 到 5 的时间序列为输入,并创建一个包含所有长度为 3 的窗口及其对应目标的数据集,分组成大小为 2 的批次:
import tensorflow as tf
my_series = [0, 1, 2, 3, 4, 5]
my_dataset = tf.keras.utils.timeseries_dataset_from_array(
my_series,
targets=my_series[3:], # the targets are 3 steps into the future
sequence_length=3,
batch_size=2
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
让我们检查一下这个数据集的内容:
>>> list(my_dataset)
[(<tf.Tensor: shape=(2, 3), dtype=int32, numpy=
array([[0, 1, 2],
[1, 2, 3]], dtype=int32)>,
<tf.Tensor: shape=(2,), dtype=int32, numpy=array([3, 4], dtype=int32)>),
(<tf.Tensor: shape=(1, 3), dtype=int32, numpy=array([[2, 3, 4]], dtype=int32)>,
<tf.Tensor: shape=(1,), dtype=int32, numpy=array([5], dtype=int32)>)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
数据集中的每个样本是长度为 3 的窗口,以及其对应的目标(即窗口后面的值)。窗口是[0, 1, 2],[1, 2, 3]和[2, 3, 4],它们各自的目标是 3,4 和 5。由于总共有三个窗口,不是批次大小的倍数,最后一个批次只包含一个窗口而不是两个。
另一种获得相同结果的方法是使用 tf.data 的Dataset类的window()方法。这更复杂,但它给了您完全的控制,这将在本章后面派上用场,让我们看看它是如何工作的。window()方法返回一个窗口数据集的数据集:
>>> for window_dataset in tf.data.Dataset.range(6).window(4, shift=1):
... for element in window_dataset:
... print(f"{element}", end=" ")
... print()
...
0 1 2 3
1 2 3 4
2 3 4 5
3 4 5
4 5
5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在这个例子中,数据集包含六个窗口,每个窗口相对于前一个窗口向前移动一个步骤,最后三个窗口较小,因为它们已经到达系列的末尾。通常情况下,您会希望通过向window()方法传递drop_remainder=True来摆脱这些较小的窗口。
window()方法返回一个嵌套数据集,类似于一个列表的列表。当您想要通过调用其数据集方法(例如,对它们进行洗牌或分批处理)来转换每个窗口时,这将非常有用。然而,我们不能直接使用嵌套数据集进行训练,因为我们的模型将期望张量作为输入,而不是数据集。
因此,我们必须调用flat_map()方法:它将嵌套数据集转换为平坦数据集(包含张量而不是数据集)。例如,假设{1, 2, 3}表示包含张量 1、2 和 3 序列的数据集。如果展平嵌套数据集{{1, 2}, {3, 4, 5, 6}},您将得到平坦数据集{1, 2, 3, 4, 5, 6}。
此外,flat_map()方法接受一个函数作为参数,允许您在展平之前转换嵌套数据集中的每个数据集。例如,如果您将函数lambda ds: ds.batch(2)传递给flat_map(),那么它将把嵌套数据集{{1, 2}, {3, 4, 5, 6}}转换为平坦数据集{[1, 2], [3, 4], [5, 6]}:这是一个包含 3 个大小为 2 的张量的数据集。
考虑到这一点,我们准备对数据集进行展平处理:
>>> dataset = tf.data.Dataset.range(6).window(4, shift=1, drop_remainder=True)
>>> dataset = dataset.flat_map(lambda window_dataset: window_dataset.batch(4))
>>> for window_tensor in dataset:
... print(f"{window_tensor}")
...
[0 1 2 3]
[1 2 3 4]
[2 3 4 5]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
由于每个窗口数据集恰好包含四个项目,对窗口调用batch(4)会产生一个大小为 4 的单个张量。太棒了!现在我们有一个包含连续窗口的数据集,表示为张量。让我们创建一个小助手函数,以便更容易地从数据集中提取窗口:
def to_windows(dataset, length):
dataset = dataset.window(length, shift=1, drop_remainder=True)
return dataset.flat_map(lambda window_ds: window_ds.batch(length))
- 1
- 2
- 3
最后一步是使用map()方法将每个窗口拆分为输入和目标。我们还可以将生成的窗口分组成大小为 2 的批次:
>>> dataset = to_windows(tf.data.Dataset.range(6), 4) # 3 inputs + 1 target = 4
>>> dataset = dataset.map(lambda window: (window[:-1], window[-1]))
>>> list(dataset.batch(2))
[(<tf.Tensor: shape=(2, 3), dtype=int64, numpy=
array([[0, 1, 2],
[1, 2, 3]])>,
<tf.Tensor: shape=(2,), dtype=int64, numpy=array([3, 4])>),
(<tf.Tensor: shape=(1, 3), dtype=int64, numpy=array([[2, 3, 4]])>,
<tf.Tensor: shape=(1,), dtype=int64, numpy=array([5])>)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
正如您所看到的,我们现在得到了与之前使用timeseries_dataset_from_array()函数相同的输出(稍微费劲一些,但很快就会值得)。
现在,在开始训练之前,我们需要将数据分为训练期、验证期和测试期。我们现在将专注于铁路乘客量。我们还将通过一百万分之一的比例缩小它,以确保值接近 0-1 范围;这与默认的权重初始化和学习率很好地配合:
rail_train = df["rail"]["2016-01":"2018-12"] / 1e6
rail_valid = df["rail"]["2019-01":"2019-05"] / 1e6
rail_test = df["rail"]["2019-06":] / 1e6
- 1
- 2
- 3
注意
处理时间序列时,通常希望按时间划分。但在某些情况下,您可能能够沿其他维度划分,这将使您有更长的时间段进行训练。例如,如果您有关于 2001 年至 2019 年间 10,000 家公司财务状况的数据,您可能能够将这些数据分割到不同的公司。然而,很可能这些公司中的许多将强相关(例如,整个经济部门可能一起上涨或下跌),如果在训练集和测试集中有相关的公司,那么您的测试集将不会那么有用,因为其泛化误差的度量将是乐观偏倚的。
接下来,让我们使用timeseries_dataset_from_array()为训练和验证创建数据集。由于梯度下降期望训练集中的实例是独立同分布的(IID),正如我们在第四章中看到的那样,我们必须设置参数shuffle=True来对训练窗口进行洗牌(但不洗牌其中的内容):
seq_length = 56
train_ds = tf.keras.utils.timeseries_dataset_from_array(
rail_train.to_numpy(),
targets=rail_train[seq_length:],
sequence_length=seq_length,
batch_size=32,
shuffle=True,
seed=42
)
valid_ds = tf.keras.utils.timeseries_dataset_from_array(
rail_valid.to_numpy(),
targets=rail_valid[seq_length:],
sequence_length=seq_length,
batch_size=32
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
现在我们已经准备好构建和训练任何回归模型了!
使用线性模型进行预测
让我们首先尝试一个基本的线性模型。我们将使用 Huber 损失,通常比直接最小化 MAE 效果更好,如第十章中讨论的那样。我们还将使用提前停止:
tf.random.set_seed(42)
model = tf.keras.Sequential([
tf.keras.layers.Dense(1, input_shape=[seq_length])
])
early_stopping_cb = tf.keras.callbacks.EarlyStopping(
monitor="val_mae", patience=50, restore_best_weights=True)
opt = tf.keras.optimizers.SGD(learning_rate=0.02, momentum=0.9)
model.compile(loss=tf.keras.losses.Huber(), optimizer=opt, metrics=["mae"])
history = model.fit(train_ds, validation_data=valid_ds, epochs=500,
callbacks=[early_stopping_cb])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
该模型达到了约 37,866 的验证 MAE(结果可能有所不同)。这比天真的预测要好,但比 SARIMA 模型要差。⁵
我们能用 RNN 做得更好吗?让我们看看!
使用简单 RNN 进行预测
让我们尝试最基本的 RNN,其中包含一个具有一个循环神经元的单个循环层,就像我们在图 15-1 中看到的那样:
model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(1, input_shape=[None, 1])
])
- 1
- 2
- 3
Keras 中的所有循环层都期望形状为[批量大小,时间步长,维度]的 3D 输入,其中维度对于单变量时间序列为 1,对于多变量时间序列为更多。请记住,input_shape参数忽略第一个维度(即批量大小),由于循环层可以接受任意长度的输入序列,因此我们可以将第二个维度设置为None,表示“任意大小”。最后,由于我们处理的是单变量时间序列,我们需要最后一个维度的大小为 1。这就是为什么我们指定输入形状为[None, 1]:它表示“任意长度的单变量序列”。请注意,数据集实际上包含形状为[批量大小,时间步长]的输入,因此我们缺少最后一个维度,大小为 1,但在这种情况下,Keras 很友好地为我们添加了它。
这个模型的工作方式与我们之前看到的完全相同:初始状态h[(init)]设置为 0,并传递给一个单个的循环神经元,以及第一个时间步的值x[(0)]。神经元计算这些值加上偏置项的加权和,并使用默认的双曲正切函数对结果应用激活函数。结果是第一个输出y[0]。在简单 RNN 中,这个输出也是新状态h[0]。这个新状态传递给相同的循环神经元,以及下一个输入值x[(1)],并且这个过程重复直到最后一个时间步。最后,该层只输出最后一个值:在我们的情况下,序列长度为 56 步,因此最后一个值是y[55]。所有这些都同时为批次中的每个序列执行,本例中有 32 个序列。
注意
默认情况下,Keras 中的循环层只返回最终输出。要使它们返回每个时间步的一个输出,您必须设置return_sequences=True,如您将看到的。
这就是我们的第一个循环模型!这是一个序列到向量的模型。由于只有一个输出神经元,输出向量的大小为 1。
现在,如果您编译、训练和评估这个模型,就像之前的模型一样,您会发现它一点用也没有:其验证 MAE 大于 100,000!哎呀。这是可以预料到的,有两个原因:
-
该模型只有一个循环神经元,因此在每个时间步进行预测时,它只能使用当前时间步的输入值和上一个时间步的输出值。这不足以进行预测!换句话说,RNN 的记忆极为有限:只是一个数字,它的先前输出。让我们来数一下这个模型有多少参数:由于只有一个循环神经元,只有两个输入值,整个模型只有三个参数(两个权重加上一个偏置项)。这对于这个时间序列来说远远不够。相比之下,我们之前的模型可以一次查看所有 56 个先前的值,并且总共有 57 个参数。
-
时间序列包含的值从 0 到约 1.4,但由于默认激活函数是 tanh,循环层只能输出-1 到+1 之间的值。它无法预测 1.0 到 1.4 之间的值。
让我们解决这两个问题:我们将创建一个具有更大的循环层的模型,其中包含 32 个循环神经元,并在其顶部添加一个密集的输出层,其中只有一个输出神经元,没有激活函数。循环层将能够在一个时间步到下一个时间步传递更多信息,而密集输出层将把最终输出从 32 维投影到 1 维,没有任何值范围约束:
univar_model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(32, input_shape=[None, 1]),
tf.keras.layers.Dense(1) # no activation function by default
])
- 1
- 2
- 3
- 4
现在,如果您像之前那样编译、拟合和评估这个模型,您会发现其验证 MAE 达到了 27,703。这是迄今为止我们训练过的最佳模型,甚至击败了 SARIMA 模型:我们做得相当不错!
提示
我们只对时间序列进行了归一化,没有去除趋势和季节性,但模型仍然表现良好。这很方便,因为这样可以快速搜索有前途的模型,而不用太担心预处理。然而,为了获得最佳性能,您可能希望尝试使时间序列更加平稳;例如,使用差分。
使用深度 RNN 进行预测
通常会堆叠多层单元,如图 15-10 所示。这给你一个深度 RNN。
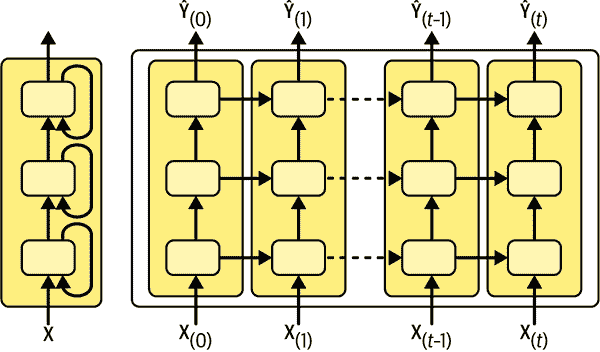
图 15-10. 深度 RNN(左)在时间轴上展开(右)
使用 Keras 实现深度 RNN 很简单:只需堆叠循环层。在下面的示例中,我们使用三个SimpleRNN层(但我们也可以使用任何其他类型的循环层,如LSTM层或GRU层,我们将很快讨论)。前两个是序列到序列层,最后一个是序列到向量层。最后,Dense层生成模型的预测(您可以将其视为向量到向量层)。因此,这个模型就像图 15-10 中表示的模型一样,只是忽略了Ŷ[(0)]到Ŷ[(t–1_)]的输出,并且在Ŷ[(t)]之上有一个密集层,输出实际预测:
deep_model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(32, return_sequences=True, input_shape=[None, 1]),
tf.keras.layers.SimpleRNN(32, return_sequences=True),
tf.keras.layers.SimpleRNN(32),
tf.keras.layers.Dense(1)
])
- 1
- 2
- 3
- 4
- 5
- 6
警告
确保对所有循环层设置return_sequences=True(除非您只关心最后的输出,最后一个循环层除外)。如果您忘记为一个循环层设置此参数,它将输出一个 2D 数组,其中仅包含最后一个时间步的输出,而不是包含所有时间步输出的 3D 数组。下一个循环层将抱怨您没有以预期的 3D 格式提供序列。
如果您训练和评估这个模型,您会发现它的 MAE 约为 31,211。这比两个基线都要好,但它并没有击败我们的“更浅”的 RNN。看起来这个 RNN 对我们的任务来说有点太大了。
多变量时间序列预测
神经网络的一个很大的优点是它们的灵活性:特别是,它们几乎不需要改变架构就可以处理多变量时间序列。例如,让我们尝试使用公交和铁路数据作为输入来预测铁路时间序列。事实上,让我们也加入日期类型!由于我们总是可以提前知道明天是工作日、周末还是假日,我们可以将日期类型系列向未来推移一天,这样模型就会将明天的日期类型作为输入。为简单起见,我们将使用 Pandas 进行此处理:
df_mulvar = df[["bus", "rail"]] / 1e6 # use both bus & rail series as input
df_mulvar["next_day_type"] = df["day_type"].shift(-1) # we know tomorrow's type
df_mulvar = pd.get_dummies(df_mulvar) # one-hot encode the day type
- 1
- 2
- 3
现在 df_mulvar 是一个包含五列的 DataFrame:公交和铁路数据,以及包含下一天类型的独热编码的三列(请记住,有三种可能的日期类型,W、A 和 U)。接下来我们可以像之前一样继续。首先,我们将数据分为三个时期,用于训练、验证和测试:
mulvar_train = df_mulvar["2016-01":"2018-12"]
mulvar_valid = df_mulvar["2019-01":"2019-05"]
mulvar_test = df_mulvar["2019-06":]
- 1
- 2
- 3
然后我们创建数据集:
train_mulvar_ds = tf.keras.utils.timeseries_dataset_from_array(
mulvar_train.to_numpy(), # use all 5 columns as input
targets=mulvar_train["rail"][seq_length:], # forecast only the rail series
[...] # the other 4 arguments are the same as earlier
)
valid_mulvar_ds = tf.keras.utils.timeseries_dataset_from_array(
mulvar_valid.to_numpy(),
targets=mulvar_valid["rail"][seq_length:],
[...] # the other 2 arguments are the same as earlier
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
最后我们创建 RNN:
mulvar_model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(32, input_shape=[None, 5]),
tf.keras.layers.Dense(1)
])
- 1
- 2
- 3
- 4
请注意,与我们之前构建的 univar_model RNN 唯一的区别是输入形状:在每个时间步骤,模型现在接收五个输入,而不是一个。这个模型实际上达到了 22,062 的验证 MAE。现在我们取得了很大的进展!
事实上,让 RNN 预测公交和铁路乘客量并不太难。您只需要在创建数据集时更改目标,将其设置为训练集的 mulvar_train[["bus", "rail"]][seq_length:],验证集的 mulvar_valid[["bus", "rail"]][seq_length:]。您还必须在输出 Dense 层中添加一个额外的神经元,因为现在它必须进行两次预测:一次是明天的公交乘客量,另一次是铁路乘客量。就是这样!
正如我们在第十章中讨论的那样,对于多个相关任务使用单个模型通常比为每个任务使用单独的模型效果更好,因为为一个任务学习的特征可能对其他任务也有用,而且因为在多个任务中表现良好可以防止模型过拟合(这是一种正则化形式)。然而,这取决于任务,在这种特殊情况下,同时预测公交和铁路乘客量的多任务 RNN 并不像专门预测其中一个的模型表现得那么好(使用所有五列作为输入)。尽管如此,它对铁路的验证 MAE 达到了 25,330,对公交达到了 26,369,这还是相当不错的。
提前预测多个时间步
到目前为止,我们只预测了下一个时间步的值,但我们也可以通过适当更改目标来预测几个步骤之后的值(例如,要预测两周后的乘客量,我们只需将目标更改为比 1 天后提前 14 天的值)。但是如果我们想预测接下来的 14 个值呢?
第一种选择是取我们之前为铁路时间序列训练的 univar_model RNN,让它预测下一个值,并将该值添加到输入中,就好像预测的值实际上已经发生了;然后我们再次使用模型来预测下一个值,依此类推,如下面的代码所示:
import numpy as np
X = rail_valid.to_numpy()[np.newaxis, :seq_length, np.newaxis]
for step_ahead in range(14):
y_pred_one = univar_model.predict(X)
X = np.concatenate([X, y_pred_one.reshape(1, 1, 1)], axis=1)
- 1
- 2
- 3
- 4
- 5
- 6
在这段代码中,我们取验证期间前 56 天的铁路乘客量,并将数据转换为形状为 [1, 56, 1] 的 NumPy 数组(请记住,循环层期望 3D 输入)。然后我们重复使用模型来预测下一个值,并将每个预测附加到输入系列中,沿着时间轴(axis=1)。生成的预测在图 15-11 中绘制。
警告
如果模型在一个时间步骤上出现错误,那么接下来的时间步骤的预测也会受到影响:错误往往会累积。因此,最好只在少数步骤中使用这种技术。
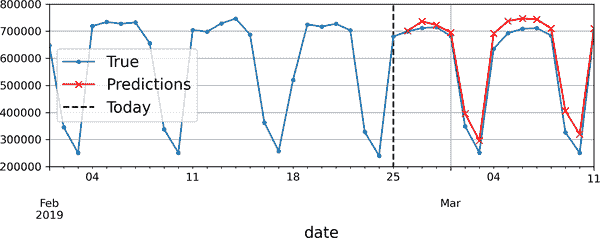
图 15-11。提前 14 步预测,一次预测一步
第二个选项是训练一个 RNN 一次性预测接下来的 14 个值。我们仍然可以使用一个序列到向量模型,但它将输出 14 个值而不是 1。然而,我们首先需要改变目标,使其成为包含接下来 14 个值的向量。为此,我们可以再次使用timeseries_dataset_from_array(),但这次要求它创建没有目标(targets=None)的数据集,并且具有更长的序列,长度为seq_length + 14。然后我们可以使用数据集的map()方法对每个序列批次应用自定义函数,将其分成输入和目标。在这个例子中,我们使用多变量时间序列作为输入(使用所有五列),并预测未来 14 天的铁路乘客量。
def split_inputs_and_targets(mulvar_series, ahead=14, target_col=1):
return mulvar_series[:, :-ahead], mulvar_series[:, -ahead:, target_col]
ahead_train_ds = tf.keras.utils.timeseries_dataset_from_array(
mulvar_train.to_numpy(),
targets=None,
sequence_length=seq_length + 14,
[...] # the other 3 arguments are the same as earlier
).map(split_inputs_and_targets)
ahead_valid_ds = tf.keras.utils.timeseries_dataset_from_array(
mulvar_valid.to_numpy(),
targets=None,
sequence_length=seq_length + 14,
batch_size=32
).map(split_inputs_and_targets)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
现在我们只需要将输出层的单元数从 1 增加到 14:
ahead_model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(32, input_shape=[None, 5]),
tf.keras.layers.Dense(14)
])
- 1
- 2
- 3
- 4
训练完这个模型后,你可以像这样一次性预测接下来的 14 个值:
X = mulvar_valid.to_numpy()[np.newaxis, :seq_length] # shape [1, 56, 5]
Y_pred = ahead_model.predict(X) # shape [1, 14]
- 1
- 2
这种方法效果相当不错。它对于第二天的预测显然比对未来 14 天的预测要好,但它不会像之前的方法那样累积误差。然而,我们仍然可以做得更好,使用一个序列到序列(或seq2seq)模型。
使用序列到序列模型进行预测
不是只在最后一个时间步训练模型来预测接下来的 14 个值,而是在每一个时间步都训练它来预测接下来的 14 个值。换句话说,我们可以将这个序列到向量的 RNN 转变为一个序列到序列的 RNN。这种技术的优势在于损失函数将包含 RNN 在每一个时间步的输出,而不仅仅是最后一个时间步的输出。
这意味着会有更多的误差梯度通过模型流动,它们不需要像以前那样通过时间流动,因为它们将来自每一个时间步的输出,而不仅仅是最后一个时间步。这将使训练更加稳定和快速。
明确一点,在时间步 0,模型将输出一个包含时间步 1 到 14 的预测的向量,然后在时间步 1,模型将预测时间步 2 到 15,依此类推。换句话说,目标是连续窗口的序列,每个时间步向后移动一个时间步。目标不再是一个向量,而是一个与输入相同长度的序列,每一步包含一个 14 维向量。
准备数据集并不是简单的,因为每个实例的输入是一个窗口,输出是窗口序列。一种方法是连续两次使用我们之前创建的to_windows()实用函数,以获得连续窗口的窗口。例如,让我们将数字 0 到 6 的系列转换为包含 4 个连续窗口的数据集,每个窗口长度为 3:
>>> my_series = tf.data.Dataset.range(7)
>>> dataset = to_windows(to_windows(my_series, 3), 4)
>>> list(dataset)
[<tf.Tensor: shape=(4, 3), dtype=int64, numpy=
array([[0, 1, 2],
[1, 2, 3],
[2, 3, 4],
[3, 4, 5]])>,
<tf.Tensor: shape=(4, 3), dtype=int64, numpy=
array([[1, 2, 3],
[2, 3, 4],
[3, 4, 5],
[4, 5, 6]])>]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
现在我们可以使用map()方法将这些窗口的窗口分割为输入和目标:
>>> dataset = dataset.map(lambda S: (S[:, 0], S[:, 1:]))
>>> list(dataset)
[(<tf.Tensor: shape=(4,), dtype=int64, numpy=array([0, 1, 2, 3])>,
<tf.Tensor: shape=(4, 2), dtype=int64, numpy=
array([[1, 2],
[2, 3],
[3, 4],
[4, 5]])>),
(<tf.Tensor: shape=(4,), dtype=int64, numpy=array([1, 2, 3, 4])>,
<tf.Tensor: shape=(4, 2), dtype=int64, numpy=
array([[2, 3],
[3, 4],
[4, 5],
[5, 6]])>)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
现在数据集包含长度为 4 的输入序列,目标是包含下两个步骤的序列,每个时间步。例如,第一个输入序列是[0, 1, 2, 3],对应的目标是[[1, 2], [2, 3], [3, 4], [4, 5]],这是每个时间步的下两个值。如果你和我一样,可能需要几分钟来理解这个概念。慢慢来!
注意
也许令人惊讶的是,目标值包含在输入中出现的值。这是不是作弊?幸运的是,完全不是:在每一个时间步,RNN 只知道过去的时间步;它无法向前看。它被称为因果模型。
让我们创建另一个小型实用函数来为我们的序列到序列模型准备数据集。它还会负责洗牌(可选)和分批处理:
def to_seq2seq_dataset(series, seq_length=56, ahead=14, target_col=1,
batch_size=32, shuffle=False, seed=None):
ds = to_windows(tf.data.Dataset.from_tensor_slices(series), ahead + 1)
ds = to_windows(ds, seq_length).map(lambda S: (S[:, 0], S[:, 1:, 1]))
if shuffle:
ds = ds.shuffle(8 * batch_size, seed=seed)
return ds.batch(batch_size)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
现在我们可以使用这个函数来创建数据集:
seq2seq_train = to_seq2seq_dataset(mulvar_train, shuffle=True, seed=42)
seq2seq_valid = to_seq2seq_dataset(mulvar_valid)
- 1
- 2
最后,我们可以构建序列到序列模型:
seq2seq_model = tf.keras.Sequential([
tf.keras.layers.SimpleRNN(32, return_sequences=True, input_shape=[None, 5]),
tf.keras.layers.Dense(14)
])
- 1
- 2
- 3
- 4
这几乎与我们之前的模型完全相同:唯一的区别是在SimpleRNN层中设置了return_sequences=True。这样,它将输出一个向量序列(每个大小为 32),而不是在最后一个时间步输出单个向量。Dense层足够聪明,可以处理序列作为输入:它将在每个时间步应用,以 32 维向量作为输入,并输出 14 维向量。实际上,获得完全相同结果的另一种方法是使用具有核大小为 1 的Conv1D层:Conv1D(14, kernel_size=1)。
提示
Keras 提供了一个TimeDistributed层,允许您将任何向量到向量层应用于输入序列中的每个向量,在每个时间步。它通过有效地重新塑造输入来实现这一点,以便将每个时间步视为单独的实例,然后重新塑造层的输出以恢复时间维度。在我们的情况下,我们不需要它,因为Dense层已经支持序列作为输入。
训练代码与往常一样。在训练期间,使用所有模型的输出,但在训练后,只有最后一个时间步的输出才重要,其余可以忽略。例如,我们可以这样预测未来 14 天的铁路乘客量:
X = mulvar_valid.to_numpy()[np.newaxis, :seq_length]
y_pred_14 = seq2seq_model.predict(X)[0, -1] # only the last time step's output
- 1
- 2
如果评估此模型对t + 1 的预测,您将发现验证 MAE 为 25,519。对于t + 2,它为 26,274,随着模型试图进一步预测未来,性能会逐渐下降。在t + 14 时,MAE 为 34,322。
提示
您可以结合两种方法来预测多步:例如,您可以训练一个模型,预测未来 14 天,然后将其输出附加到输入,然后再次运行模型,以获取接下来 14 天的预测,并可能重复该过程。
简单的 RNN 在预测时间序列或处理其他类型的序列时可能表现得很好,但在长时间序列或序列上表现不佳。让我们讨论一下原因,并看看我们能做些什么。
处理长序列
要在长序列上训练 RNN,我们必须在许多时间步上运行它,使展开的 RNN 成为一个非常深的网络。就像任何深度神经网络一样,它可能会遇到不稳定的梯度问题,如第十一章中讨论的:可能需要很长时间来训练,或者训练可能不稳定。此外,当 RNN 处理长序列时,它将逐渐忘记序列中的第一个输入。让我们从不稳定的梯度问题开始,看看这两个问题。
解决不稳定梯度问题
许多我们在深度网络中用来缓解不稳定梯度问题的技巧也可以用于 RNN:良好的参数初始化,更快的优化器,辍学等。然而,非饱和激活函数(例如 ReLU)在这里可能不会有太大帮助。实际上,它们可能会导致 RNN 在训练过程中更加不稳定。为什么?嗯,假设梯度下降以一种增加第一个时间步输出的方式更新权重。由于相同的权重在每个时间步使用,第二个时间步的输出也可能略有增加,第三个时间步也是如此,直到输出爆炸——而非饱和激活函数无法阻止这种情况。
您可以通过使用较小的学习率来减少这种风险,或者可以使用饱和激活函数,如双曲正切(这解释了为什么它是默认值)。
同样,梯度本身也可能爆炸。如果注意到训练不稳定,可以监控梯度的大小(例如,使用 TensorBoard),并可能使用梯度裁剪。
此外,批量归一化不能像深度前馈网络那样有效地与 RNN 一起使用。实际上,您不能在时间步之间使用它,只能在循环层之间使用。
更准确地说,从技术上讲,可以在内存单元中添加一个 BN 层(您很快就会看到),以便在每个时间步上应用它(既在该时间步的输入上,也在上一个步骤的隐藏状态上)。然而,相同的 BN 层将在每个时间步上使用相同的参数,而不考虑输入和隐藏状态的实际比例和偏移。实际上,这并不会产生良好的结果,如 César Laurent 等人在2015 年的一篇论文中所证明的:作者发现,只有当 BN 应用于层的输入时才略有益处,而不是应用于隐藏状态。换句话说,当应用于循环层之间(即在图 15-10 中垂直地)时,它略好于什么都不做,但不适用于循环层内部(即水平地)。在 Keras 中,您可以通过在每个循环层之前添加一个 BatchNormalization 层来简单地在层之间应用 BN,但这会减慢训练速度,并且可能帮助不大。
另一种规范化方法在 RNN 中通常效果更好:层归一化。这个想法是由 Jimmy Lei Ba 等人在2016 年的一篇论文中提出的:它与批归一化非常相似,但不同的是,层归一化是在特征维度上进行归一化,而不是在批次维度上。一个优点是它可以在每个时间步上独立地为每个实例计算所需的统计数据。这也意味着它在训练和测试期间的行为是相同的(与 BN 相反),它不需要使用指数移动平均来估计训练集中所有实例的特征统计数据,就像 BN 那样。与 BN 类似,层归一化为每个输入学习一个比例和偏移参数。在 RNN 中,它通常在输入和隐藏状态的线性组合之后立即使用。
让我们使用 Keras 在简单内存单元中实现层归一化。为此,我们需要定义一个自定义内存单元,它就像一个常规层一样,只是它的 call() 方法接受两个参数:当前时间步的 inputs 和上一个时间步的隐藏 states。
请注意,states 参数是一个包含一个或多个张量的列表。在简单的 RNN 单元中,它包含一个张量,等于上一个时间步的输出,但其他单元可能有多个状态张量(例如,LSTMCell 有一个长期状态和一个短期状态,您很快就会看到)。一个单元还必须有一个 state_size 属性和一个 output_size 属性。在简单的 RNN 中,两者都简单地等于单元的数量。以下代码实现了一个自定义内存单元,它将表现得像一个 SimpleRNNCell,但它还会在每个时间步应用层归一化:
class LNSimpleRNNCell(tf.keras.layers.Layer):
def __init__(self, units, activation="tanh", **kwargs):
super().__init__(**kwargs)
self.state_size = units
self.output_size = units
self.simple_rnn_cell = tf.keras.layers.SimpleRNNCell(units,
activation=None)
self.layer_norm = tf.keras.layers.LayerNormalization()
self.activation = tf.keras.activations.get(activation)
def call(self, inputs, states):
outputs, new_states = self.simple_rnn_cell(inputs, states)
norm_outputs = self.activation(self.layer_norm(outputs))
return norm_outputs, [norm_outputs]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
让我们来看一下这段代码:
-
我们的
LNSimpleRNNCell类继承自tf.keras.layers.Layer类,就像任何自定义层一样。 -
构造函数接受单位数和所需的激活函数,并设置
state_size和output_size属性,然后创建一个没有激活函数的SimpleRNNCell(因为我们希望在线性操作之后但在激活函数之前执行层归一化)。然后构造函数创建LayerNormalization层,最后获取所需的激活函数。 -
call()方法首先应用simpleRNNCell,它计算当前输入和先前隐藏状态的线性组合,并返回结果两次(实际上,在SimpleRNNCell中,输出就等于隐藏状态:换句话说,new_states[0]等于outputs,因此我们可以在call()方法的其余部分安全地忽略new_states)。接下来,call()方法应用层归一化,然后是激活函数。最后,它将输出返回两次:一次作为输出,一次作为新的隐藏状态。要使用此自定义细胞,我们只需要创建一个tf.keras.layers.RNN层,将其传递给一个细胞实例:
custom_ln_model = tf.keras.Sequential([
tf.keras.layers.RNN(LNSimpleRNNCell(32), return_sequences=True,
input_shape=[None, 5]),
tf.keras.layers.Dense(14)
])
- 1
- 2
- 3
- 4
- 5
同样,您可以创建一个自定义细胞,在每个时间步之间应用 dropout。但有一个更简单的方法:Keras 提供的大多数循环层和细胞都有dropout和recurrent_dropout超参数:前者定义要应用于输入的 dropout 率,后者定义隐藏状态之间的 dropout 率,即时间步之间。因此,在 RNN 中不需要创建自定义细胞来在每个时间步应用 dropout。
通过这些技术,您可以缓解不稳定梯度问题,并更有效地训练 RNN。现在让我们看看如何解决短期记忆问题。
提示
在预测时间序列时,通常有必要在预测中包含一些误差范围。为此,一种方法是使用 MC dropout,介绍在第十一章中:在训练期间使用recurrent_dropout,然后在推断时通过使用model(X, training=True)来保持 dropout 处于活动状态。多次重复此操作以获得多个略有不同的预测,然后计算每个时间步的这些预测的均值和标准差。
解决短期记忆问题
由于数据在经过 RNN 时经历的转换,每个时间步都会丢失一些信息。过一段时间后,RNN 的状态几乎不包含最初输入的任何痕迹。这可能是一个停滞不前的问题。想象一下多莉鱼试图翻译一句长句子;当她读完时,她已经不记得它是如何开始的。为了解决这个问题,引入了各种具有长期记忆的细胞类型。它们已经被证明非常成功,以至于基本细胞不再被广泛使用。让我们首先看看这些长期记忆细胞中最受欢迎的:LSTM 细胞。
LSTM 细胞
长短期记忆(LSTM)细胞是由 Sepp Hochreiter 和 Jürgen Schmidhuber 于 1997 年提出的,并在多年来逐渐得到了几位研究人员的改进,如 Alex Graves,Haşim Sak 和 Wojciech Zaremba。如果将 LSTM 细胞视为黑匣子,它可以被用作基本细胞,只是它的性能会更好;训练会更快收敛,并且它会检测数据中更长期的模式。在 Keras 中,您可以简单地使用LSTM层而不是SimpleRNN层:
model = tf.keras.Sequential([
tf.keras.layers.LSTM(32, return_sequences=True, input_shape=[None, 5]),
tf.keras.layers.Dense(14)
])
- 1
- 2
- 3
- 4
或者,您可以使用通用的tf.keras.layers.RNN层,将LSTMCell作为参数传递给它。但是,当在 GPU 上运行时,LSTM层使用了优化的实现(请参阅第十九章),因此通常最好使用它(RNN层在定义自定义细胞时非常有用,就像我们之前做的那样)。
那么 LSTM 细胞是如何工作的呢?其架构显示在图 15-12 中。如果不看盒子里面的内容,LSTM 细胞看起来与常规细胞完全相同,只是其状态分为两个向量:h[(t)]和c[(t)](“c”代表“cell”)。您可以将h[(t)]视为短期状态,将c[(t)]视为长期状态。
图 15-12. LSTM 单元
现在让我们打开盒子!关键思想是网络可以学习将什么存储在长期状态中,什么丢弃,以及从中读取什么。当长期状态c[(t–1)]从左到右穿过网络时,您可以看到它首先经过一个遗忘门,丢弃一些记忆,然后通过加法操作添加一些新的记忆(通过输入门选择的记忆)。结果c[(t)]直接发送出去,没有进一步的转换。因此,在每个时间步骤,一些记忆被丢弃,一些记忆被添加。此外,在加法操作之后,长期状态被复制并通过 tanh 函数传递,然后结果由输出门过滤。这产生了短期状态h[(t)](这等于此时间步骤的单元输出y[(t))。现在让我们看看新记忆来自哪里以及门是如何工作的。
首先,当前输入向量x[(t)]和先前的短期状态h[(t–1)]被馈送到四个不同的全连接层。它们各自有不同的作用:
-
主要层是输出g[(t)]的层。它通常的作用是分析当前输入x[(t)]和先前(短期)状态h[(t–1)]。在基本单元中,除了这一层外没有其他内容,其输出直接发送到y[(t)]和h[(t)]。但在 LSTM 单元中,这一层的输出不会直接输出;相反,其最重要的部分存储在长期状态中(其余部分被丢弃)。
-
其他三个层是门控制器。由于它们使用逻辑激活函数,输出范围从 0 到 1。正如您所看到的,门控制器的输出被馈送到逐元素乘法操作:如果它们输出 0,则关闭门,如果它们输出 1,则打开门。具体来说:
-
遗忘门(由f[(t)]控制)控制着应该擦除长期状态的哪些部分。
-
输入门(由i[(t)]控制)控制着应该将g[(t)]的哪些部分添加到长期状态中。
-
最后,输出门(由o[(t)]控制)控制着长期状态的哪些部分应该在此时间步骤被读取并输出,既输出到h[(t)],也输出到y[(t)]。
-
简而言之,LSTM 单元可以学习识别重要的输入(这是输入门的作用),将其存储在长期状态中,保留它直到需要(这是遗忘门的作用),并在需要时提取它。这解释了为什么这些单元在捕捉时间序列、长文本、音频记录等长期模式方面取得了惊人的成功。
方程 15-4 总结了如何计算单元的长期状态、短期状态以及每个时间步骤的输出,针对单个实例(整个小批量的方程非常相似)。
方程 15-4. LSTM 计算
i (t) = σ ( W xi ⊺ x (t) + W hi ⊺ h (t-1) + b i ) f (t) = σ ( W xf ⊺ x (t) + W hf ⊺ h (t-1) + b f ) o (t) = σ ( W xo ⊺ x (t) + W ho ⊺ h (t-1) + b o ) g (t) = tanh ( W xg ⊺ x (t) + W hg ⊺ h (t-1) + b g ) c (t) = f (t) ⊗ c (t-1) + i (t) ⊗ g (t) y (t) = h (t) = o (t) ⊗ tanh ( c (t) )
在这个方程中:
-
W[xi]、W[xf]、W[xo]和W[xg]是每个四层的权重矩阵,用于它们与输入向量x[(t)]的连接。
-
W[hi]、W[hf]、W[ho]和W[hg]是每个四层的权重矩阵,用于它们与先前的短期状态h[(t–1)]的连接。
-
b[i]、b[f]、b[o]和b[g]是每个四层的偏置项。请注意,TensorFlow 将b[f]初始化为一个全为 1 的向量,而不是 0。这可以防止在训练开始时忘记所有内容。
LSTM 单元有几个变体。一个特别流行的变体是 GRU 单元,我们现在将看一下。
GRU 单元
门控循环单元 (GRU)单元(见图 15-13)由 Kyunghyun Cho 等人在2014 年的一篇论文中提出,该论文还介绍了我们之前讨论过的编码器-解码器网络。
图 15-13. GRU 单元
GRU 单元是 LSTM 单元的简化版本,看起来表现同样出色(这解释了它日益增长的受欢迎程度)。这些是主要的简化:
-
两个状态向量合并成一个单一向量h[(t)]。
-
一个单一的门控制器z[(t)]控制遗忘门和输入门。如果门控制器输出 1,则遗忘门打开(= 1),输入门关闭(1 - 1 = 0)。如果输出 0,则相反发生。换句话说,每当必须存储一个记忆时,将首先擦除将存储它的位置。这实际上是 LSTM 单元的一个常见变体。
-
没有输出门;完整状态向量在每个时间步输出。然而,有一个新的门控制器r[(t)],控制哪部分先前状态将被显示给主层(g[(t)])。
方程 15-5 总结了如何计算每个时间步的单个实例的单元状态。
方程 15-5. GRU 计算
z (t) = σ ( W xz ⊺ x (t) + W hz ⊺ h (t-1) + bz ) r (t) = σ ( W xr ⊺ x (t) + W hr ⊺ h (t-1) + br ) g (t) = tanh W xg ⊺ x (t) + W hg ⊺ ( r (t) ⊗ h (t-1) ) + bg h (t) = z (t) ⊗ h (t-1) + ( 1 - z (t) ) ⊗ g (t)
Keras 提供了一个tf.keras.layers.GRU层:使用它只需要将SimpleRNN或LSTM替换为GRU。它还提供了一个tf.keras.layers.GRUCell,以便根据 GRU 单元创建自定义单元。
LSTM 和 GRU 单元是 RNN 成功的主要原因之一。然而,虽然它们可以处理比简单 RNN 更长的序列,但它们仍然有相当有限的短期记忆,并且很难学习 100 个时间步或更多的序列中的长期模式,例如音频样本、长时间序列或长句子。解决这个问题的一种方法是缩短输入序列;例如,使用 1D 卷积层。
使用 1D 卷积层处理序列
在第十四章中,我们看到 2D 卷积层通过在图像上滑动几个相当小的卷积核(或滤波器),产生多个 2D 特征图(每个卷积核一个)。类似地,1D 卷积层在序列上滑动多个卷积核,每个卷积核产生一个 1D 特征图。每个卷积核将学习检测单个非常短的连续模式(不超过卷积核大小)。如果使用 10 个卷积核,则该层的输出将由 10 个 1D 序列组成(长度相同),或者您可以将此输出视为单个 10D 序列。这意味着您可以构建一个由循环层和 1D 卷积层(甚至 1D 池化层)组成的神经网络。如果使用步幅为 1 和"same"填充的 1D 卷积层,则输出序列的长度将与输入序列的长度相同。但是,如果使用"valid"填充或大于 1 的步幅,则输出序列将短于输入序列,因此请确保相应调整目标。
例如,以下模型与之前的模型相同,只是它以一个 1D 卷积层开始,通过步幅为 2 对输入序列进行下采样。卷积核的大小大于步幅,因此所有输入都将用于计算该层的输出,因此模型可以学习保留有用信息,仅丢弃不重要的细节。通过缩短序列,卷积层可能有助于GRU层检测更长的模式,因此我们可以将输入序列长度加倍至 112 天。请注意,我们还必须裁剪目标中的前三个时间步:实际上,卷积核的大小为 4,因此卷积层的第一个输出将基于输入时间步 0 到 3,第一个预测将是时间步 4 到 17(而不是时间步 1 到 14)。此外,由于步幅,我们必须将目标下采样一半:
conv_rnn_model = tf.keras.Sequential([
tf.keras.layers.Conv1D(filters=32, kernel_size=4, strides=2,
activation="relu", input_shape=[None, 5]),
tf.keras.layers.GRU(32, return_sequences=True),
tf.keras.layers.Dense(14)
])
longer_train = to_seq2seq_dataset(mulvar_train, seq_length=112,
shuffle=True, seed=42)
longer_valid = to_seq2seq_dataset(mulvar_valid, seq_length=112)
downsampled_train = longer_train.map(lambda X, Y: (X, Y[:, 3::2]))
downsampled_valid = longer_valid.map(lambda X, Y: (X, Y[:, 3::2]))
[...] # compile and fit the model using the downsampled datasets
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
如果您训练和评估此模型,您会发现它的性能优于之前的模型(略有优势)。事实上,实际上可以仅使用 1D 卷积层并完全放弃循环层!
WaveNet
在2016 年的一篇论文,¹⁶ Aaron van den Oord 和其他 DeepMind 研究人员介绍了一种名为WaveNet的新颖架构。他们堆叠了 1D 卷积层,每一层的扩张率(每个神经元的输入间隔)都加倍:第一个卷积层一次只能看到两个时间步,而下一个卷积层则看到四个时间步(其感受野为四个时间步),下一个卷积层看到八个时间步,依此类推(参见图 15-14)。通过加倍扩张率,较低层学习短期模式,而较高层学习长期模式。由于加倍扩张率,网络可以非常高效地处理极大的序列。
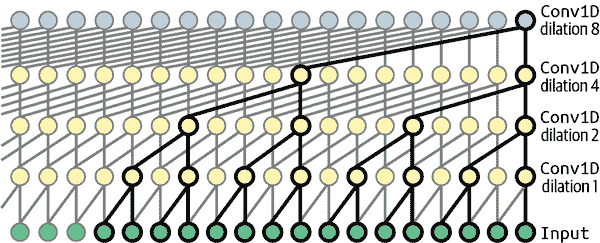
图 15-14。WaveNet 架构
论文的作者实际上堆叠了 10 个具有 1、2、4、8、…、256、512 扩张率的卷积层,然后他们又堆叠了另一组 10 个相同的层(扩张率也是 1、2、4、8、…、256、512),然后再次堆叠了另一组相同的 10 层。他们通过指出,具有这些扩张率的单个 10 个卷积层堆栈将像具有大小为 1,024 的卷积核的超高效卷积层一样(速度更快,更强大,参数数量显著减少)。他们还在每一层之前用与扩张率相等的零填充输入序列,以保持整个网络中相同的序列长度。
以下是如何实现一个简化的 WaveNet 来处理与之前相同的序列的方法:¹⁷
wavenet_model = tf.keras.Sequential()
wavenet_model.add(tf.keras.layers.Input(shape=[None, 5]))
for rate in (1, 2, 4, 8) * 2:
wavenet_model.add(tf.keras.layers.Conv1D(
filters=32, kernel_size=2, padding="causal", activation="relu",
dilation_rate=rate))
wavenet_model.add(tf.keras.layers.Conv1D(filters=14, kernel_size=1))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这个Sequential模型从一个明确的输入层开始——这比仅在第一层上设置input_shape要简单。然后,它继续使用“因果”填充的 1D 卷积层,这类似于“相同”填充,只是零值仅附加在输入序列的开头,而不是两侧。这确保了卷积层在进行预测时不会窥视未来。然后,我们添加使用不断增长的扩张率的类似对层:1、2、4、8,再次是 1、2、4、8。最后,我们添加输出层:一个具有 14 个大小为 1 的滤波器的卷积层,没有任何激活函数。正如我们之前看到的那样,这样的卷积层等效于具有 14 个单元的Dense层。由于因果填充,每个卷积层输出与其输入序列相同长度的序列,因此我们在训练期间使用的目标可以是完整的 112 天序列:无需裁剪或降采样。
我们在本节讨论的模型对乘客量预测任务提供了类似的性能,但它们在任务和可用数据量方面可能会有很大差异。在 WaveNet 论文中,作者在各种音频任务(因此该架构的名称)上实现了最先进的性能,包括文本转语音任务,在多种语言中产生令人难以置信的逼真声音。他们还使用该模型逐个音频样本生成音乐。当您意识到一秒钟的音频可能包含成千上万个时间步时,这一壮举就显得更加令人印象深刻——即使是 LSTM 和 GRU 也无法处理如此长的序列。
警告
如果您在测试期间评估我们最佳的芝加哥乘客量模型,从 2020 年开始,您会发现它们的表现远远不如预期!为什么呢?嗯,那时候是 Covid-19 大流行开始的时候,这对公共交通产生了很大影响。正如前面提到的,这些模型只有在它们从过去学到的模式在未来继续时才能很好地工作。无论如何,在将模型部署到生产环境之前,请验证它在最近的数据上表现良好。一旦投入生产,请确保定期监控其性能。
有了这个,您现在可以处理各种时间序列了!在第十六章中,我们将继续探索 RNN,并看看它们如何处理各种 NLP 任务。
练习
-
您能想到一些序列到序列 RNN 的应用吗?序列到向量 RNN 和向量到序列 RNN 呢?
-
RNN 层的输入必须具有多少维度?每个维度代表什么?输出呢?
-
如果您想构建一个深度序列到序列 RNN,哪些 RNN 层应该具有
return_sequences=True?序列到向量 RNN 呢? -
假设您有一个每日单变量时间序列,并且您想要预测接下来的七天。您应该使用哪种 RNN 架构?
-
在训练 RNN 时主要的困难是什么?您如何处理它们?
-
您能勾画出 LSTM 单元的架构吗?
-
为什么要在 RNN 中使用 1D 卷积层?
-
您可以使用哪种神经网络架构来对视频进行分类?
-
为 SketchRNN 数据集训练一个分类模型,该数据集可在 TensorFlow Datasets 中找到。
-
下载巴赫赞美诗数据集并解压缩。这是由约翰·塞巴斯蒂安·巴赫创作的 382 首赞美诗。每首赞美诗长 100 至 640 个时间步长,每个时间步长包含 4 个整数,其中每个整数对应于钢琴上的一个音符的索引(除了值为 0,表示没有播放音符)。训练一个模型——循环的、卷积的,或两者兼而有之——可以预测下一个时间步长(四个音符),给定来自赞美诗的时间步长序列。然后使用这个模型生成类似巴赫的音乐,一次一个音符:您可以通过给模型提供赞美诗的开头并要求它预测下一个时间步长来实现这一点,然后将这些时间步长附加到输入序列并要求模型预测下一个音符,依此类推。还要确保查看谷歌的 Coconet 模型,该模型用于关于巴赫的一个不错的谷歌涂鸦。
这些练习的解决方案可在本章笔记本的末尾找到,网址为https://homl.info/colab3。
¹ 请注意,许多研究人员更喜欢在 RNN 中使用双曲正切(tanh)激活函数,而不是 ReLU 激活函数。例如,参见 Vu Pham 等人的2013 年论文“Dropout Improves Recurrent Neural Networks for Handwriting Recognition”。基于 ReLU 的 RNN 也是可能的,正如 Quoc V. Le 等人的2015 年论文“初始化修正线性单元的循环网络的简单方法”中所示。
² Nal Kalchbrenner 和 Phil Blunsom,“循环连续翻译模型”,2013 年经验方法自然语言处理会议论文集(2013):1700–1709。
³ 芝加哥交通管理局的最新数据可在芝加哥数据门户上找到。
⁴ 有其他更有原则的方法来选择好的超参数,基于分析自相关函数(ACF)和偏自相关函数(PACF),或最小化 AIC 或 BIC 指标(在第九章中介绍)以惩罚使用太多参数的模型并减少过拟合数据的风险,但网格搜索是一个很好的起点。有关 ACF-PACF 方法的更多详细信息,请查看 Jason Brownlee 的这篇非常好的文章。
⁵ 请注意,验证期从 2019 年 1 月 1 日开始,因此第一个预测是 2019 年 2 月 26 日,八周后。当我们评估基线模型时,我们使用了从 3 月 1 日开始的预测,但这应该足够接近。
⁶ 随意尝试这个模型。例如,您可以尝试预测接下来 14 天的公交和轨道乘客量。您需要调整目标,包括两者,并使您的模型输出 28 个预测,而不是 14 个。
⁷ César Laurent 等人,“批量归一化循环神经网络”,IEEE 国际声学、语音和信号处理会议论文集(2016):2657–2661。
⁸ Jimmy Lei Ba 等人,“层归一化”,arXiv 预印本 arXiv:1607.06450(2016)。
⁹ 更简单的方法是继承自SimpleRNNCell,这样我们就不必创建内部的SimpleRNNCell或处理state_size和output_size属性,但这里的目标是展示如何从头开始创建自定义单元。
¹⁰ 动画电影海底总动员和海底奇兵中一个患有短期记忆丧失的角色。
¹¹ Sepp Hochreiter 和 Jürgen Schmidhuber,“长短期记忆”,神经计算 9,第 8 期(1997 年):1735–1780。
¹² Haşim Sak 等,“基于长短期记忆的大词汇语音识别循环神经网络架构”,arXiv 预印本 arXiv:1402.1128(2014 年)。
¹³ Wojciech Zaremba 等,“循环神经网络正则化”,arXiv 预印本 arXiv:1409.2329(2014 年)。
¹⁴ Kyunghyun Cho 等,“使用 RNN 编码器-解码器学习短语表示进行统计机器翻译”,2014 年经验方法自然语言处理会议论文集(2014 年):1724–1734。
¹⁵ 请参阅 Klaus Greff 等的“LSTM:搜索空间奥德赛”,IEEE 神经网络与学习系统交易 28,第 10 期(2017 年):2222–2232。这篇论文似乎表明所有 LSTM 变体表现大致相同。
¹⁶ Aaron van den Oord 等,“WaveNet:原始音频的生成模型”,arXiv 预印本 arXiv:1609.03499(2016 年)。
¹⁷ 完整的 WaveNet 使用了更多技巧,例如类似于 ResNet 中的跳过连接和类似于 GRU 单元中的门控激活单元。有关更多详细信息,请参阅本章的笔记本。

