
- 1图解剖析,递归思想,使用二叉链建立一个二叉树并实现相关操作(数据结构)_用二叉链表建立二叉树
- 2使用docker、docker-compose部署微服务_docker部署微服务项目
- 3WebSocket使用(C++环境)(一) --- websocket++库的安装与使用_c++ websocket库
- 4Android Studio 所有历史版本下载_android studio旧版本怎么下载
- 5vue3树状图,树状关系图_vue3绘制树状图
- 6OpenCV 验证码图像增强处理 一、滤波增强_opencv 边缘增强
- 7js 通用防重复提交方法_js防止表单重复提交
- 8T113-S3-RTL8211网口phy芯片调试
- 9igraph入门教程
- 10微信小程序中使用uniCloud_微信小程序unicloud
机器学习---数据分割
赞
踩
之前的文章中写过,我们可以通过实验测试来对学习器的泛化误差进行评估并进而做出选择。
为此,需使用一个“测试集"(testing set)来测试学习器对新样本的判别能力,然后以测试集上的“测
试误差”(testing error)作为泛化误差的近似。通常我们假设测试样本也是从样本真实分布中独立同
分布采样而得。但需注意的是,测试集应该尽可能与训练集互斥。
互斥,即测试样本尽量不在训练集中出现、未在训练过程中使用过。
测试样本为什么要尽可能不出现在训练集中呢?为理解这一点,不妨考虑这样一个场景:
老师出了10道习题供同学们练习,考试时老师又用同样的这10道题作为试题,这个考试成绩能否
有效反映出同学们学得好不好呢?
答案是否定的,可能有的同学只会做这10道题却能得高分。
回到我们的问题上来,我们希望得到泛化性能强的模型,好比是希望同学们对课程学得很好、获得
了对所学知识“举一反三"的能力;训练样本相当于给同学们练习的习题,测试过程则相当于考试。
显然,若测试样本被用作训练了,则得到的将是过于“乐观”的估计结果。
可是,我们只有一个包含个样例的数据集![]()
既要训练,又要测试,怎样才能做到呢?答案是:通过对D进行适当的处理,从中产生出训练集
S和测试集T。
下面我们一起总结一下几种常见的做法:留出法、交叉验证法、自助法
1. 留出法
“留出法”(hold-ou)直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为
测试集T,即![]() 。在S上训练出模型后,用T来评估其测试误差,作为对
。在S上训练出模型后,用T来评估其测试误差,作为对
泛化误差的估计。大家在使用的过程中,需注意的是,训练/测试集的划分要尽可能保持数据分布
的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响,例如在分类任务中至少要
保持样本的类别比例相似。如果从采样(sampling)的角度来看待数据集的划分过程,则保留类别比
例的采样方式通常称为“分层采样"(stratified sampling)。
例如通过对D进行分层样而获得含70%样本的训练集S和含30%样本的测试集T。
若D包含500个正例、500个反例,则分层采样得到的S应包含350个正例、350个反例,而T则包含
150个正例和150个反例:
若S、T中样本类别比例差别很大,则误差估计将由于训练/测试数据分布的差异而产生偏差。
另一个需注意的问题是,即便在给定训练测试集的样本比例后,仍存在多种划分方式对初始数据集
D进行分割。例如在上面的例子中,可以把D中的样本排序,然后把前350个正例放到训练集中,也
可以把最后350个正例放到训练集中,这些不同的划分将导致不同的训练测试集,相应的,模型评
估的结果也会有差别。因此,单次使用留出法得到的估计结果往往不够稳定可靠,在使用留出法
时,一般要采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。
例如进行100次随机划分,每次产生一个训练/测试集用于实验评估,100次后就得到100个结果,
而留出法返回的则是这100个结果的平均。
此外,我们希望评估的是用D训练出的模型的性能,但留出法需划分训练/测试集,这就会导致一个
窘境:若令训练集S包含绝大多数样本,则训练出的模型可能更接近于用D训练出的模型,但由于T
比较小,评估结果可能不够稳定准确;若令测试集T多包含一些样本,则训练集S与D差别更大了,
被评估的模型与用D训练出的模型相比可能有较大差别,从而降低了评估结果的保真性(fidelity)。
这个问题没有完美的解决方案,常见做法是将大约2/3~4/5的样本用于训练,剩余样本用于测试。
使用Python实现留出法:
- from sklearn.model_selection import train_test_split
- #使⽤train_test_split划分训练集和测试集
- train_X , test_X, train_Y ,test_Y = train_test_split(
- X, Y, test_size=0.2,random_state=0)
在留出法中,有一个特例,叫:留一法(Leave.-One-Out,简称LOO),即每次抽取一个样本做为测
试集。显然,留一法不受随机样本划分方式的影响,因为m个样本只有唯一的方式划分为个子集一
每个子集包含个样本;
使用Python实现留一法:
- from sklearn.model_selection import LeaveOneOut
- data = [1, 2, 3, 4]
- loo = LeaveOneOut()
- for train, test in loo.split(data):
- print("%s %s" % (train, test))
- '''结果
- [1 2 3] [0]
- [0 2 3] [1]
- [0 1 3] [2]
- [0 1 2] [3]
- '''
留一法优缺点:
优点:留一法使用的训练集与初始数据集相比只少了一个样本,这就使得在绝大多数情况下,留一
法中被实际评估的模型,与期望评估的用D训练出的模型很相似。因此,留一法的评估结果往往被
认为比较准确。
缺点:留一法也有其缺陷:在数据集比较大时,训练个模型的计算开销可能是难以忍受的(例如数
据集包含1百万个祥本,则需训练1百万个模型,而这还是在未考虑算法调参的情况下。
2. 交叉验证法
“交叉验证法"(cross validation)先将数据集D划分为k个大小相似的互斥子集,即
![]() 。每个子集Di都尽可能保持数据分布的一致
。每个子集Di都尽可能保持数据分布的一致
性,即从D中通过分层抽样得到。
然后,每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集;这样就可获得k组训练/
测试集,从而可进行k次训练和测试,最终返回的是这k个测试结果的均值。
显然,交叉验证法评估结果的稳定性和保真性在很大程度上取决于k的取值,为强调这一点,通常
把交叉验证法称为“k折交叉验证"(k-fold cross validation)。k最常用的取值是10,此时称为10折交
叉验证;其他常用的k值有5、20等。下图给出了10折交叉验证的示意图。
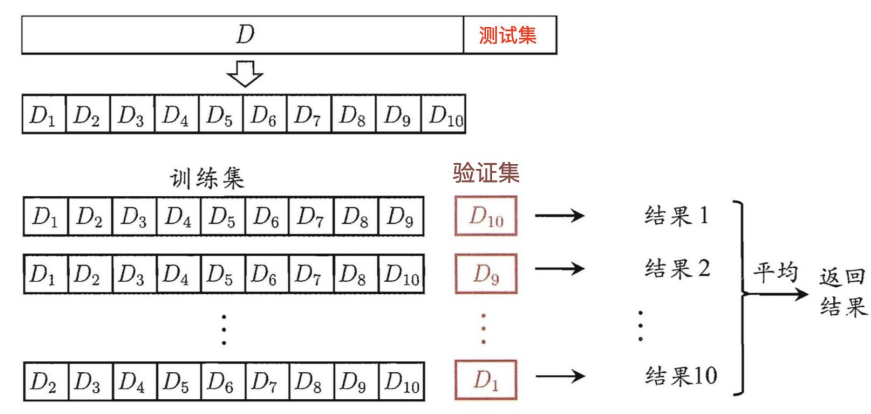
与留出法相似,将数据集D划分为k个子集同样存在多种划分方式。为减小因样本划分不同而引入
的差别,k折交叉验证通常要随机使用不同的划分重复次,最终的评估结果是这p次k折交叉验证结
果的均值,例如常见的有“10次10折交叉验证”。交叉验证实现方法,除了咱们前面讲的
GridSearchCV之外,还有KFold,StratifiedKFold
from sklearn.model_selection import KFold,StratifiedKFold用法:
将训练/测试数据集划分n_splits个互斥子集,每次用其中一个子集当作验证集,剩下的n_splits-1个
作为训练集,进行n_splits,次训练和测试,得到n_splits个结果。
StratifiedKFold的用法和Fold的区别是:SKFold是分层采样,确保训练集,测试集中,各类别样本
的比例是和原始数据集中的一致。
注意点:
对于不能均等分数据集,其前n_samples%n_splits-子集拥有n_samples∥n_splits+1个样本,其余
子集都只有n_samples∥n_splits样本
参数说明:n_splits:表示划分几等份;shuffle:在每次划分时,是否进行洗牌
①若为False时,其效果等同于random state等于整数,每次划分的结果相同
②若为True时,每次划分的结果都不一样,表示经过洗牌,随机取样的
属性:①split(X,y=None,groups:=None):将数据集划分成训练集和测试集,返回索引生成器
- import numpy as np
- from sklearn.model_selection import KFold,StratifiedKFold
- X = np.array([
- [1,2,3,4],
- [11,12,13,14],
- [21,22,23,24],
- [31,32,33,34],
- [41,42,43,44],
- [51,52,53,54],
- [61,62,63,64],
- [71,72,73,74]
- ])
- y = np.array([1,1,0,0,1,1,0,0])
- folder = KFold(n_splits = 4, random_state=0, shuffle = False)
- sfolder = StratifiedKFold(n_splits = 4, random_state = 0, shuffle = False)
- for train, test in folder.split(X, y):
- print('train:%s | test:%s' %(train, test))
- print("")
- for train, test in sfolder.split(X, y):
- print('train:%s | test:%s'%(train, test))
- print("")

结果:
- # 第⼀个for,输出结果为:
- train:[2 3 4 5 6 7] | test:[0 1]
- train:[0 1 4 5 6 7] | test:[2 3]
- train:[0 1 2 3 6 7] | test:[4 5]
- train:[0 1 2 3 4 5] | test:[6 7]
- # 第⼆个for,输出结果为:
- train:[1 3 4 5 6 7] | test:[0 2]
- train:[0 2 4 5 6 7] | test:[1 3]
- train:[0 1 2 3 5 7] | test:[4 6]
- train:[0 1 2 3 4 6] | test:[5 7]
可以看出,sfold进行4折计算时候,是平衡了测试集中,样本正负的分布的;但是fold却没有。
3. 自助法
我们希望评估的是用D训练出的模型。但在留出法和交叉验证法中,由于保留了一部分样本用于测
试,因此实际评估的模型所使用的训练集比D小,这必然会引入一些因训练样本规模不同而导致的
估计偏差。留一法受训练样本规模变化的影响较小,但计算复杂度又太高了。
有没有什么办法可以减少训练样本规模不同造成的影响,同时还能比较高效地进行实验估计呢?
“自助法"(bootstrapping)是一个比较好的解决方案,它直接以自助采样法(bootstrap sampling)为基
础。给定包含m个样本的数据集D,我们对它进行采样产生数据集D:每次随机从D中挑选一个样
本,将其拷贝放入D,然后再将该样本放回初始数据集D中,使得该样本在下次采样时仍有可能被
到;这个过程重复执行次后,我们就得到了包含个样本的数据集D',这就是自助采样的结果。
显然,D中有一部分样本会在D'中多次出现,而另一部分样本不出现。可以做一个简单的估计,样
本在次采样中始终不被采到的概率是![]() ,取极限得到
,取极限得到![]()
即通过自助采样,初始数据集D中约有36.8%的样本未出现在采样数据集D'中。于是我们可将D'用
作训练集,D\D'用作测试集;这样,实际评估的模型与期望评估的模型都使用个训练样本,而我们
仍有数据总量约1/3的、没在训练集中出现的样本用于测试。
这样的测试结果,亦称“包外估计”(out-of-bagestimate)。
自助法优缺点:
优点:自助法在数据集较小、难以有效划分训练测试集时很有用;此外,自助法能从初始数据集中
产生多个不同的训练集,这对集成学习等方法有很大的好处。
缺点:自助法产生的数据集改变了初始数据集的分布,这会引入估计偏差。因此,在初始数据量足
够时;留出法和交叉验证法更常用一些。

