
- 1Framework事件机制—Android事件处理的三种方法_android事件处理机制
- 2Centos中pip install mysqlclient失败_× getting requirements to build wheel did not run
- 3HarmonyOS基础组件的使用_关于resource是资源引用类型描述错误的是
- 4假设检验-全流程(四)_假设检验计算公式要取绝对值么
- 5Navicat 好用的原因找到了 -> 原生技术
- 6INSTALL_FAILED_INTERNAL_ERROR错误的解决办法
- 7【干货长文】详述银行业数字化转型中的敏捷变革
- 8Element-UI的table合并span-method
- 9Guitar Pro8苹果mac最新版本下载安装教程_guita pro for mac
- 10【elementUI中el-table中span-method 中传递自定义参数】_span-method传参
AI绘画 | stable-diffusion-web-ui的基本操作_clip终止层数什么意思
赞
踩
前言
我们下载安装完成stable-diffusion-web-ui以后,下载对应风格的模型,就可以开始我们的绘画操作了。进行Ai绘画操作前,我们最好先弄清楚web ui界面上的参数按钮的含义。这样我们就能更轻松的绘画出我们想要stable-diffusion-web-ui创作出我们心中所想的佳作了!,下面开始讲解web ui的基本使用,有不清楚的小伙伴们,可以再评论区留言交流,喜欢的可以一件三连,反复观看!!!
基本操作
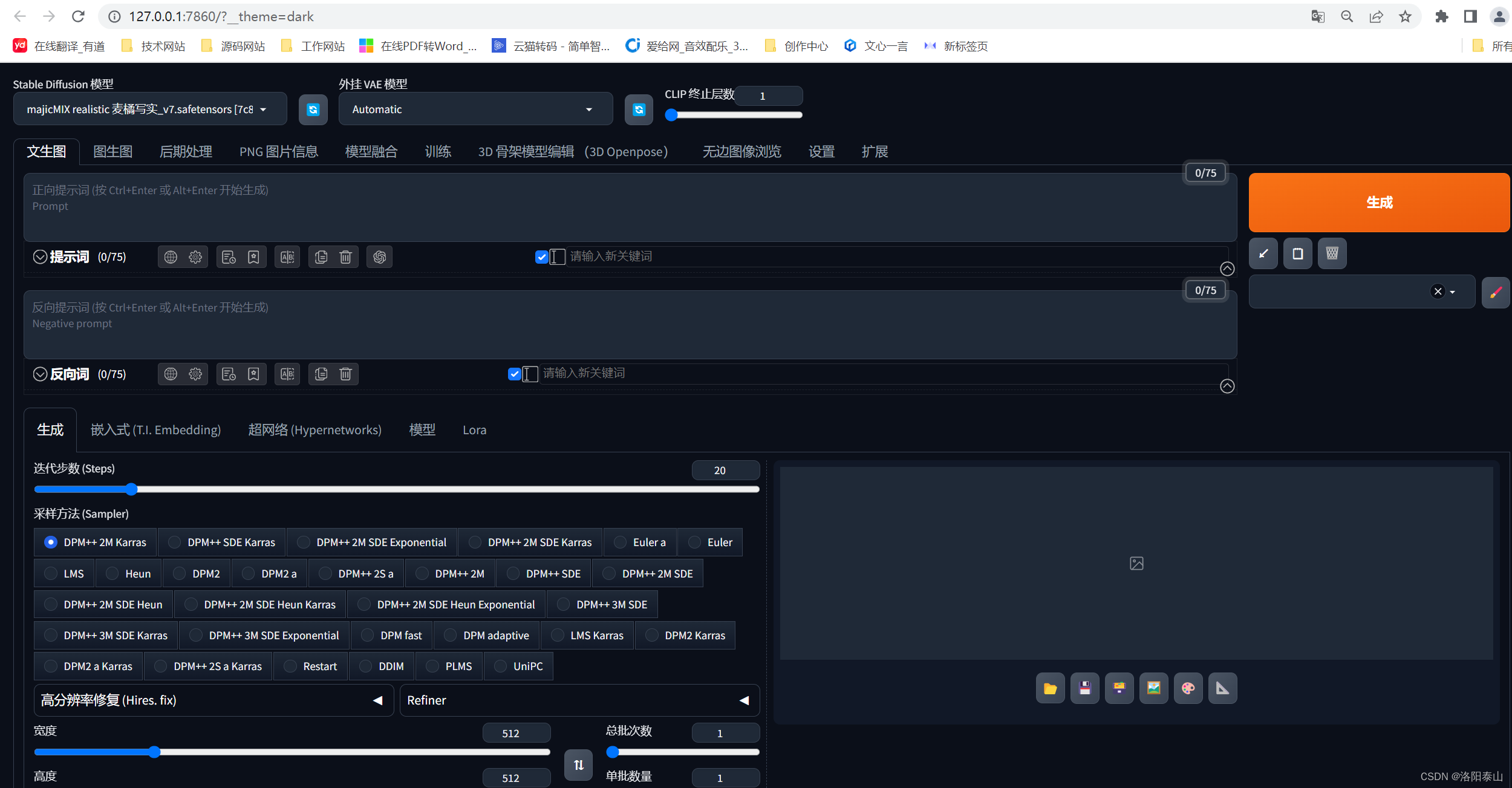
这是我们点击秋叶启动器上的一键启动按钮后,自动打开的web页面。(如何没有自动打开这个界面,可以自己打开浏览器网址栏输入 http://127.0.0.1:7860 ),stable-diffusion-web-ui的原生界面不是这样,因为秋叶的整合了中文扩展插件,和其他的web ui扩展插件。界面才有所不同。后续讲web ui的扩展插件的安装使用和用途。
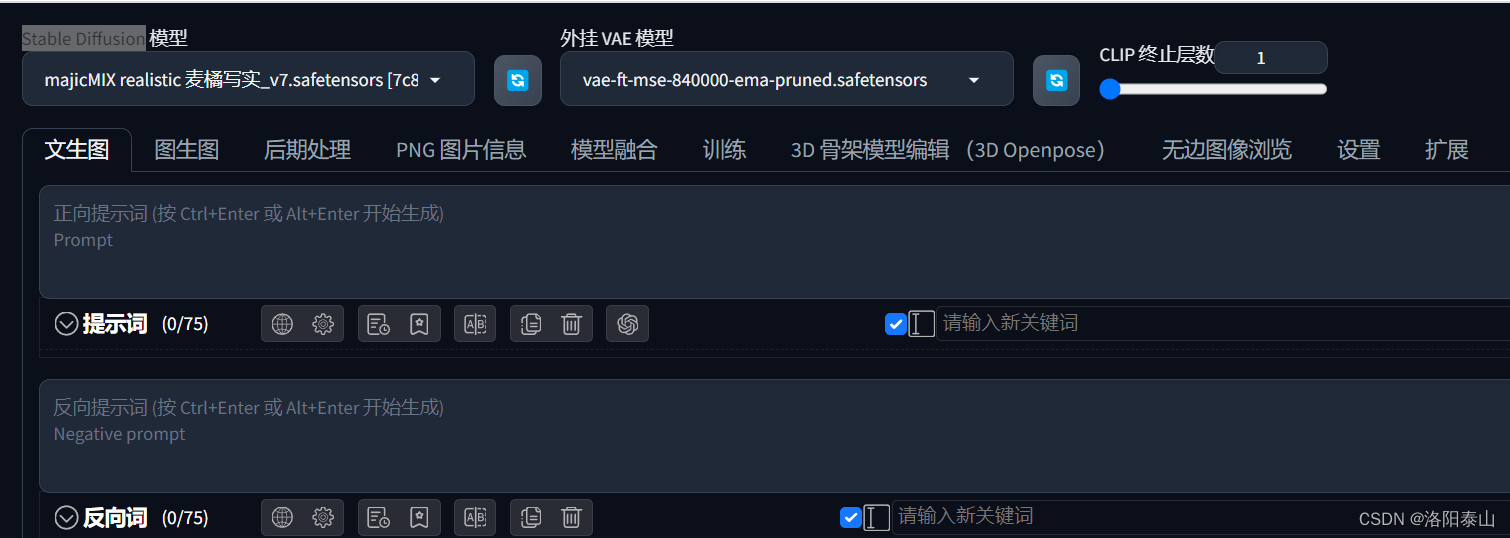
Stable Diffusion checkpoint(Stable Diffusion 模型)
通过模型网站下载我们想要的Checkpoint模型到 web ui根目录下的models\Stable-diffusion文件夹下,点击旁边的刷新按钮即可再下拉列表加载出来。下来选择自己想要使用的底模。这里我用的majicMIX realistic 麦橘写实大模型。
为什么需要这么多大模型?
Stable Diffusion官方的模型就像一个百科全书。设计的内容广泛的,但是不精细。基于Stable Diffusion官方的模型,二次训练后的模型就像是在这个百科全书的基础上,更加精细化了某个方面的内容。
SD VAE (外挂 VAE 模型)
VAE是一种生成模型,它通过编码器和解码器的组合来学习数据分布。编码器将数据编码为潜在空间中的表示,解码器则从潜在空间中恢复出原始数据。VAE的目标是最小化编码和解码之间的差异,同时保持潜在空间的表示与先验分布的一致性。
具体来说,VAE包括一个均值向量和一个协方差矩阵。均值向量可以表示潜在空间的平均位置,而协方差矩阵则可以表示潜在空间中的不确定性。在训练过程中,VAE通过最大化ELBO(证据下界)来优化其对数据分布的建模。
SD VAE可以用于各种不同的任务,如图像生成、图像修复、文本生成等。在图像生成方面,VAE可以将生成的图像与先验分布进行比较,从而评估生成的图像的质量。在图像修复方面,VAE可以通过对图像进行编码和解码来去除噪声或进行超分辨率重建。在文本生成方面,VAE可以将文本编码为潜在空间中的表示,并从该表示中生成新的文本。
秋叶整合包内自带两个VAE模型animevae.pt和vae-ft-mse-840000-ema-pruned.safetensors
animevae.pt
AnimeVAE是一种基于变分自编码器的模型,主要用于动漫风格的人脸图像合成。AnimeVAE模型的主要目标是通过将动漫风格的人脸图像编码为潜在空间中的表示,并从该表示中解码出新的动漫风格的人脸图像,来学习动漫风格的人脸图像的分布。
vae-ft-mse-840000-ema-pruned.safetensors
vae-ft-mse-840000-ema-pruned是一个经过剪枝(pruned)的变分自编码器(VAE)模型,使用了平均平方误差(MSE)损失函数,以及一个可能是指数移动平均(EMA)的权重剪枝策略。主要用于现实的模型或风格(由StabilityAI创建)
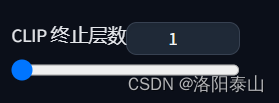
Clip skip (CLIP 终止层数)
Clip skip是指控制图像生成过程中CLIP模型的使用频率的参数。它影响了图像生成的过程中使用的CLIP模型的次数**。Clip skip的取值范围是1到12,值越小,生成的图像就越接近原始图像或输入图像。值越大,生成的图像就越偏离原始图像或输入图像,甚至可能出现黑屏或无关的人物。**
prompt(提示词)
prompt是一种提示词,用于指导AI模型生成图像。它通常是一段文本描述,包括对图像内容、风格、主题等方面的描述。通过使用prompt,用户可以告诉AI模型他们希望生成的图像类型,从而影响AI模型生成的结果。
在Stable Diffusion中,prompt的使用方式比较灵活,可以通过不同的方式来生成图像。比如,用户可以通过输入一段文本描述,告诉AI模型他们希望生成的图像内容,然后AI模型会根据用户的描述生成相应的图像。另外,用户还可以通过调整prompt中的参数来控制AI模型生成图像的样式、颜色等。
- positive prompt(正向提示词)
正向提示词主要用于正面地引导AI模型生成符合要求的图像。即我们希望AI绘画的内容出现什么! 通常包含积极的、正面的词汇和描述,旨在让AI模型能够理解并生成与这些描述相符的图像。例如,“美丽的花朵”、“壮观的日出”等都属于正向提示词。 - negative prompt(反向提示词)
反向提示词则主要用于负面地引导AI模型避免生成不合适的图像。**即我们希望AI绘画的内容不要出现什么!**通常包含消极的、负面的词汇和描述,旨在让AI模型能够识别并避免与这些描述相符的图像。例如,“不要生成包含血腥暴力内容的图像”、“不要生成具有歧视色彩的图像”等都属于反向提示词。
在使用这两种提示词时,需要注意保持用词准确、明确,以便AI模型能够正确理解并生成相应的图像。同时,根据具体需求和应用场景,可以灵活地选择使用正向提示词还是反向提示词,或者将两者结合起来使用。
Sampling steps(迭代步数)
- Sampling steps中文翻译为 采样步数又称迭代步数。
- Sampling steps是指在使用扩散模型生成图片时所进行的迭代步骤。每经过一次迭代,AI就有更多的机会去比对prompt和当前结果,并作出相应的调整。随着步数的增多,可以得到对目标更小、更精确的图像。但增加步数也会增加生成图像所需的时间,增加步数的边际收益递减。一般而言,步数在20~30步之间较为合适。
Sampling method (采样算法)
Sampling method(采样算法)是一种基于扩散模型的生成画像的方法。其过程是将一张满是噪点的图作为基准,然后一点一点地向目标(prompt)“扩散”靠近。这是一种算法,每一步之后将生成的图像与文本提示符要求的图像进行比较,并对噪声添加一些更改,直到逐渐达到与文本描述相匹配的图像。

模型下载网站,每个checkpoint模型的作者都会推荐适合自己模型的采样算法。一般模型常用的采样算法主要是DPM++ SDE Karras、Euler a\Euler。
Width/Height (宽高)
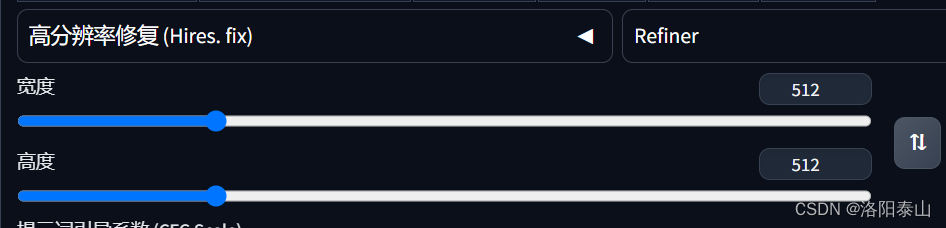
这个设置,主要作用于生成图片的宽和高的像素大小,一般推荐512512或者512768,因为大部分模型训练的图像样本都是这个大小,生成图片的大小和原图保持一直,生成的图片效果会更好,否则容易出现变形的情况,而且设置更大的尺寸,需要更大的显存和生成时间。如果想要高清的图片,我们可以用web ui 高清修复功能,让图片变得更大更清晰。
CFG Scale(提示词引导系数)
-
Stable Diffusion CFG Scale是一个控制提示词与出图相关性的数值。
-
CFG Scale可以从0-15进行调整。从日常的出图过程经验来看,CFG设置为5-10之间是最常规以及最保险的数值。过低的CFG会让出图饱和度偏低,过高的CFG则会出现粗矿的线条或过度锐化的图像,甚至于画面出现严重的崩坏。
-
设置更高的提示词引导系数需要搭配更高的迭代步数,否者图片容易出现噪点和不正常的画面。(具体原因可以了解Diffusion 模型的原理)
-
cfg scale能够增加每个tag对画面整体的影响(cfg scale越高,tag权重和先后顺序的差异表现得越明显)。
Batch count/Batch size(总批次数/单批数量)
Stable Diffusion的Batch count和Batch size是两个重要的参数,用于控制生成图像的数量和速度。
-
Batch count(总批次数)是指一次性生成图像的数量。这个参数可以影响生成图像的时间和计算资源的消耗。较大的Batch count可以加快生成速度,但需要更多的计算资源和内存。
-
Batch size(单批数量)是指每个批次并行生成的图像数量。这个参数也可以影响生成图像的速度和计算资源的消耗。较大的Batch size可以加快生成速度,但需要更多的计算资源和内存。
-
在选择Batch count和Batch size时,需要考虑您的硬件配置和生成需求。如果您的显卡内存较小,建议将Batch size设置为较小的值,以避免显存不足的问题。如果您的需求是生成大量图像,建议将Batch count设置为较大的值,以加快生成速度。
-
需要注意的是,较大的Batch count和Batch size可能会导致生成图像的质量下降或出现其他问题,因此需要根据实际情况进行调整。
Seed/Variation seed(随机种子/变异随机种子)
seed
在Stable Diffusion中,seed参数可以用于控制随机性。当未填写随机种子时,默认值为-1,此时右侧骰子点击后能快速恢复到-1状态。绿色图标点击后能获取到右侧已生成图片的随机种子(若右侧无图片,点击后则获得到-1)。

每个用Stable Diffusion生成的图片都会有一个随机种子。设置相同的随机种子,会生成几乎相同的图片,当然最终的图片也会受到提示词、checkpoint模型、vae、clip skip、迭代步数、采样算法、CFG Scale等参数的不同而有所变化,但是有些明显的特征会保留。
Variation seed
此外,点击勾选框,会出现变异随机种子的设置框。
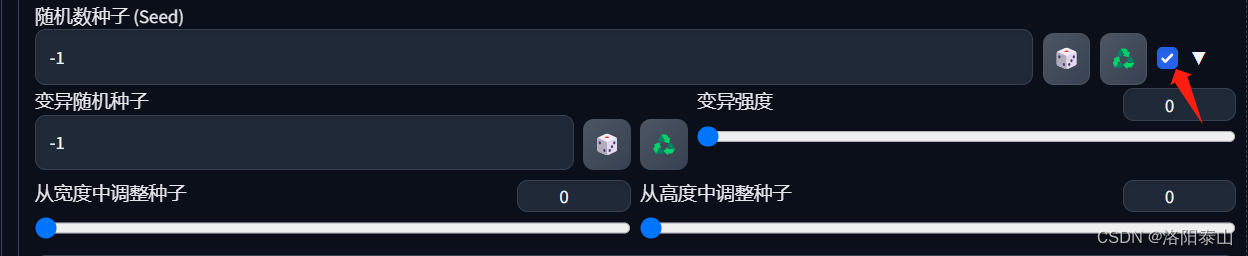
Variation seed是另一个控制随机性的参数,它与seed参数类似,但具有更高的自由度。Variation seed可以看作是额外的一个种子数,与seed数一起共同作用出图结果。这个参数可以控制差异化种子数的作用强度,从而影响生成图像的多样性和质量。
具体来说,当Variation seed为0时,差异化种子数不起作用,所以生成的图像和seed数作用的结果一样。而当Variation seed不为0时,它可以与seed数共同作用,以产生更多样化的图像。
在实际操作中,用户可以通过调整Variation seed的值来控制生成图像的多样性。例如,可以将Variation seed设置为一个固定的值,以获得相同类型的图像;也可以每次生成时随机选择一个Variation seed值,以获得更加多样化的图像。
需要注意的是,虽然Variation seed可以带来更多的自由度和多样性,但同时也可能导致生成图像的质量下降或出现其他问题。因此,在使用时需要根据实际情况进行调整,以保证生成图像的质量和多样性达到最佳的平衡。
Hires. fix(高清修复)

Stable Diffusion的Hires. fix功能是用于高分辨率修复的。这个功能可以选中,并会弹出多个算法的选择。
一些常用的算法包括:
- 4x-UltraSharp:这是目前最好用的放大算法。
- R-ESRGAN 4x+:这是基于Real ESRGAN的优化模型,针对照片效果不错。
- R-ESRGAN 4x+ Anime6B:这是基于Real ESRGAN的优化模型,二次元最佳,如果模型是动漫类的,该选项是最佳选择。
- SwinIR_4x:这个算法使用Swin Transformer思想,采用一个长距离连接,将低频信息直接传输给重建模块,这可以帮助深度特征提取模块专注于高频信息,从而稳定训练。
- LDSR:这是Latent Diffusion Super Resolution(潜在扩散超分辨率模型),是Stable Diffusion最基础的算法模型,但速度比较慢。
- 除了上述算法外,还有其他一些算法,例如BSRGAN等。重绘幅度设置为0.6-0.8也是一个不错的选择。
Refiner
Refiner中文名为精炼机器,顾名思义就是让图片的内容和画质更加的精细。

总共有两个选项,Checkpoint(模型)和 Switch at(切换时机),上图的意思是当Stable Diffusion采样过程进行到80%的时候,剩下的20%的采样切换为majicMix sombre 麦橘唯美_v1.0.safetensors模型进行采样。这样我们就可以获得两种模型画风融合的画作了。
起手式
在“生成”按钮的下方。点击“画笔”按钮可以设置一些正向提示词和方向提示词的组合为一个标签,比如生成图片的画质的提示词组合,人物的基本提示词组合,分别设为一个标签,下次画人物画的时候,可以下来多选这两个起手式,不用再重复输入提示词了。(注意:选择起手式后提示词不会出现在提示词输入框内)
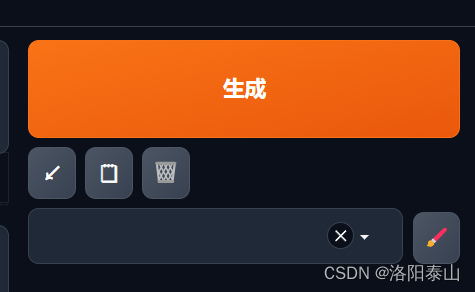
图片生成
- 生成按钮 用来点击生成图片
- 箭头按钮 用来恢复上次输入的提示词(包含正反提示词)
- 笔记按钮 用来提交正向提示词的内容,会把之前的提示词覆盖掉。
- 网格按钮 用来快速清楚正反提示词框的内容
结语
以上就是本篇文章的全部内容,大家可以尝试的设置这些参数生成一些图片了。当然你生成的图片的效果大概率不会很理想。以上所有参数中难度设置最大作用也最大的就是promts提示词了。如何才能写出更准确,更能让Ai理解的提示呢?下篇文章我会讲promts提示词的基本语法和进阶语法的使用,相信你Ai绘画的水平会得到进一步的提升。

