
- 1CMake系列(十) CMake include的使用_utils.cmake
- 2关于QGraphicsPixmapItem背景透明和无法拖曳问题_qgraphicspixmapitem 透明度
- 3蓝桥杯刷题--python-12
- 4Linux网络配置_linux /etc/sysconfig/network-scripts/ifcfg-ens32 d
- 5SE-Net网络详解
- 6无法从“3.11.3 (全局)”环境源解析导入“PIL”_无法从源解析导入
- 7动态规划之解码方法【LeetCode】
- 8AI 大模型面试指南(含答案)大放送!
- 9机器学习实战:带你进入AI世界!
- 10AIGC启示录:深度解析AIGC技术的现代性与系统性的奇幻旅程_通往aigc之路
【AI简报20210618期】AI高仿你的笔迹只需1个词、与你共享300 + 开源模型
赞
踩

RT-AK新进展
RT-AK开源在K210平台的适配插件
原文:https://mp.weixin.qq.com/s/UMED8uHOiURJEhyJ_cLtBA
应广大开发者要求,本周RT-AK推出了支持的第二个插件:RT-AK 之 k210 插件。
支持基于 K210 芯片的一些开发板,目前RT-AK已经能够在嘉楠堪智的 KD233 和亚博 YB-DKA01 上正常工作。
其他基于K210芯片的开发板(可能需要定制BSP),批量需求可联系我们定制,请邮件至:business@rt-thread.com

AI热点
Jeff Dean领衔AI助力芯片设计效率革命!6小时内完成布局设计,新一代TPU已用上
原文:https://www.jiqizhixin.com/articles/2021-06-10-2
论文:https://www.nature.com/articles/s41586-021-03544-w
一直以来,微芯片设计的成败在很大程度上取决于布局规划和布局步骤,这些布局步骤决定了内存和逻辑元件在芯片上的位置。反过来,位置又会强烈影响芯片设计是否能够满足包括处理速度和电源效率在内的操作要求。
现在,随着 AI 技术深入到芯片设计领域,一场效率革命可能要再次席卷而来。来自由 Jeff Dean 领衔的谷歌大脑团队以及斯坦福大学计算机科学系的科学家们,在一项联合研究中证明,一种基于深度强化学习的芯片布局规划方法,能够生成可行的芯片设计方案。
在不到 6 小时的时间内,由该方法自动生成的芯片平面图在所有关键指标上(包括功耗、性能和芯片面积等参数)都优于或与人类专家生成的设计图效果相当,而人类工程师往往需要数月的紧张努力才能达到如此效果。

最强Transformer发布!谷歌大脑提出ViT-G:缩放视觉Transformer,高达90.45%准确率
原文:https://mp.weixin.qq.com/s/tdQSGnApkYGmmz7ZWyssZw
论文:https://arxiv.org/abs/2106.04560
本文作者谷歌大脑 (苏黎世) 改进了ViT的架构和训练,减少了内存消耗并提高了模型的准确性!最终成功训练了一个具有20亿参数的ViT模型:ViT-G,在ImageNet上达到了90.45%的Top-1准确率。
视觉Transformer(ViT)等基于注意力的神经网络最近在许多计算机视觉基准测试中取得了最先进的结果。比例是获得出色结果的主要因素,因此,了解模型的scaling属性是有效设计的关键。虽然已经研究了扩展Transformer语言模型的规律,但尚不清楚Vision Transformers如何扩展。为了解决这个问题,作者向上和向下扩展ViT模型和数据,并描述错误率、数据和计算之间的关系。在此过程中,作者改进了ViT的架构和训练,减少了内存消耗并提高了结果模型的准确性。结果,作者成功地训练了一个具有20亿个参数的ViT模型,该模型在ImageNet上达到了90.45%的Top-1准确率。该模型在小样本学习上也表现良好,例如,在ImageNet上每类只有10个examples的情况下可以达到84.86%的Top-1准确率。

AI高仿你的笔迹只需1个词,Deepfake文字版来了,网友:以假乱真太可怕
原文:https://mp.weixin.qq.com/s/rmJSazmGu94R6o6BYgBNyw
很多人小学时的梦想被AI实现了!只需要拍下自己的笔记,AI就能帮你誊抄英语作业,画风“完全一致”的那种:

帮别人抄作业也毫无问题……直接秒杀某宝上只能仿手写、价格还动辄成百上千的“作业神器”.

在实际使用过程中,TextStyleBrush真的就是个格式刷,哪里需要刷哪里。它真正厉害的就是模拟手写字体。只需输入一段文本内容,加上你的笔迹,1个单词即可,它就能生成“手写版”。

但是作业还是得好好做啊!这可不是给你用来抄作业的。
NAACL21 最佳论文!罗切斯特大学&腾讯:视频辅助的无监督句法分析
原文:https://mp.weixin.qq.com/s/bzh7lbcEzfwzRsDmOA1GsQ
论文:https://arxiv.org/pdf/2104.04369.pdf
代码:https://github.com/Sy-Zhang/MMC-PCFG
世界自然语言处理方向三大顶会之一NAACL 2021(另外两个是ACL和EMNLP) 已经于2021年6月6日至11日以在线会议的形式成功举办。来自罗切斯特大学&腾讯 AI Lab合作的《Video-aided Unsupervised Grammar Induction》一文获得了最佳长论文,并于2021年6月9日在NAACL 2021上宣讲。
文章提出了Multi-Modal Compound PCFGs (MMC-PCFG)用于视频辅助的无监督句法分析 ,框架如下。与VC-PCFG [3]不同的是,文章中提出的模型以视频作为输入,并融合了视频多种模态的信息,是VC-PCFG [3] 在视频上的泛化。对于每个视频作者首先在时间上等间隔抽取包括物体,动作,场景,声音,字符,人脸,语音在内的共M种特征。文章还借鉴了多模态transformer [4]来计算视频和文本片段之间的相似度。
文章在三个数据集(DiDeMo, YouCook2, MSRVTT)上做了实验。因为这些数据集没有语法标注,作者用一个监督学习的方法 [5]预测出来的结果当作reference tree。对于物体和动作特征,作者还用不同模型提取了多种不同的特征,包括物体(ResNeXt-101,SENet-154)和动作(I3D,R2P1D,S3DG)。每组实验都跑10个epoch并用不同的种子跑了4次。

通过表1中的实验结果,可以得出文章提出的MMC-PCFG在所有三个数据集中性能都达到了最好的结果,说明模型可以有效利用所有特征的信息,以及验证了不同特征对不同的句法结构贡献不同。
跳舞手脚不协调?没关系,微视用AI打造你我的舞林大会,一张照片就可以
原文:https://mp.weixin.qq.com/s/Xw83qSLH89UkwOy1XKHEIQ
论文:https://arxiv.org/pdf/2012.01158.pdf
近日,腾讯微视 APP 上线的「照片会跳舞」新特效玩法实现了人体姿态迁移技术的真正落地,让不会跳舞的你也能在手机上舞动起来。
玩法非常简单,用户只需下载微视 APP,上传单人 / 多人全身正面照,系统即自动对照片进行 3D 建模,生成以假乱真的虚拟形象;接着选择舞种,通过技术能力使虚拟形象按照选定的舞蹈模板「舞动」起来,模拟效果十分逼真,动作也流畅自然。
QQ 影像中心技术团队经过对人体 3D 重建技术、GAN 网络的不断挖掘与优化,最后实现了使用单张用户图,就能达到业界需要复杂技术方可实现的人体姿态迁移效果。同时还支持更高分辨率的输出,解决了动作僵硬等问题,既保证了舞蹈素材的动作准确性,也使动作更加连贯自然。

AI工具
Keras正式从TensorFlow分离:结束API混乱与耗时编译
2019年6月,TensorFlow与Keras合并,但看似双赢的决定,很多开发者却不买账。API 的混乱与割裂不仅令开发者不知所措,也加大了开发者寻找教程的难度。近日,Keras 之父 Francois Chollet 在其推特宣布一项重要决定:他们已经将 Keras 的代码从 TensorFlow 代码库中分离出来,移回到了自己的 repo。

对于 Keras 从 TensorFlow 分离后有哪些好处?Francois 表示:「这将提升开源贡献者的开发体验。对于用户而言,这将使他们可以在本地运行测试,不再需要编译 TF 来测试 Keras 了,并且还将改善 CI 时间。」
变更之后,当前 TensorFlow 代码库中的 Keras 部分将很快被删除。这意味着:
Keras 开源代码库的访问地址将发生变更;
原地址:https://github.com/tensorflow/tensorflow
新地址:https://github.com/keras-team/keras
经过许可之后,原代码库中 Keras 部分的相关 PR 将被手动合并到新代码库中。Keras 团队成员将在内部进行同步和合并,相关作者无需进行任何操作。但如果 PR 已经打开很长时间且没有作者的活动,Keras 团队可能会关闭它;
任何在先前代码库中未解决的 Keras 相关活跃问题将在现有的 ticket 线程中处理,并将通过提交到新代码库进行修复;
与原代码库相关的陈旧问题将被关闭。如果你认为仍然是有价值的问题,请随时在新代码库中重新打开该问题;
新 Keras 代码库在此次变更前未完成的任何 PR/issue 都被认为是陈旧的,将被关闭。
AI开源项目
上交大找到「换脸」新方式:无惧死亡打光、直男视角
原文:https://mp.weixin.qq.com/s/g2ihCfs4-g8LENVG8wE9aw
论文:https://arxiv.org/abs/2106.06340
代码:https://github.com/neuralchen/SimSwap
DeepFakes等一众换脸神器对此纷纷表示:就这?但要是从网上的电影场景中,随意抓一把人物图像丢进去呢?如果要换的这张脸正好在死亡角度,还做了个特别夸张的表情(或者干脆就是个表情包)呢?

水就有点深了哈。
这时,由上交大和腾讯一起搞出来的换脸框架SimSwap表示:让我来,我把握得住!
任意人脸都能换:
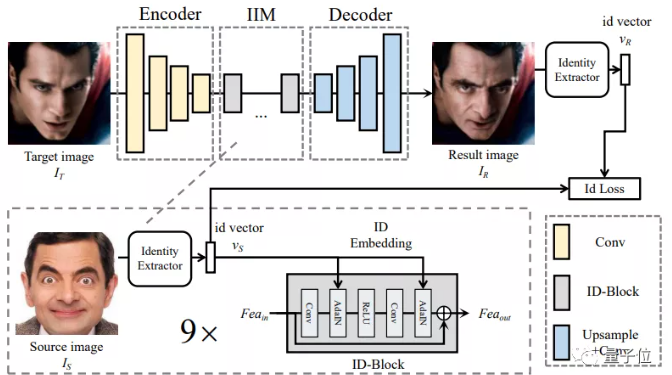
SimSwap提出了一种ID注入模块(IIM),在特征层面将源脸的身份信息迁移到目标脸,消除了原图特征信息与解码器的权重之间的相关性。这样,就将特定人脸互换算法的结构扩展到了任意人脸互换框架。也就像我们在开头展示的那样,不用精挑细选“正脸”或“中性表情,直接从网上抓一把人物图片,也能够完美换脸。
死亡角度、夸张表情也不怕:
除了泛化到任意人脸变换之外,SimSwap也能更好地保存原图的脸部表情和角度。不管是表情嘴巴嘟嘟,还是目标图和原图一侧一正两个角度,都能完美换脸。就算是自下而上的死亡打光图,SimSwap也表现得更好。
60.6 AP!打破COCO记录!微软提出DyHead:将注意力与目标检测Heads统一
原文:https://mp.weixin.qq.com/s/uYPUqVXwNau71VAYW3bYIA
论文:https://arxiv.org/abs/2106.08322
代码:https://github.com/microsoft/DynamicHead
目标检测中定位与分类合并的复杂性衍生出了各式各样的算法,然而这些方法从不同的角度出发进行目标检测性能的提升,难以从一个统一的角度进行分析度量。本文提出一种新颖的动态头框架,它采用注意力机制将不同的目标检测头进行统一。通过特征层次之间的注意力机制用于尺度感知,空间位置之间的注意力机制用于空间感知,输出通道内的注意力机制用于任务感知,该方法可以在不增加计算量的情况显著提升模型目标检测头的表达能力。
COCO数据集上实验验证了所提方案的有效性与高效性。以ResNeXt-101-DCN为骨干,我们将目标检测的性能提升到了54.0AP,取得了一个新的高度;更进一步,采用最新的Transformer骨干与额外数据,我们可以将COCO的指标推到一个新记录:60.6AP。

基于强化学习的自动化剪枝模型
原文:https://mp.weixin.qq.com/s/IOlz6R9cKbhgEjfKURmjZA
代码:https://github.com/freefuiiismyname/cv-automatic-pruning-transformer
目前的强化学习工作很多集中在利用外部环境的反馈训练agent,忽略了模型本身就是一种能够获得反馈的环境。本项目的核心思想是:将模型视为环境,构建附生于模型的 agent ,以辅助模型进一步拟合真实样本。
大多数领域的模型都可以采用这种方式来优化,如cv/多模态等。它至少能够以三种方式工作:
1.过滤噪音信息,如删减语音或图像特征;
2.进一步丰富表征信息,如高效引用外部信息;
3.实现记忆、联想、推理等复杂工作,如构建重要信息的记忆池。
这里推出一款早期完成的裁剪机制transformer版本(后面称为APT),实现了一种更高效的训练模式,能够优化模型指标;此外,可以使用动态图丢弃大量的不必要单元,在指标基本不变的情况下,大幅降低计算量。

文末福利
这个repo,绝对是伸手党的福音,共享300+开源模型!
链接: https://github.com/PaddlePaddle/PaddleHub
进入github中,首屏发现 5 大亮点:
1、中英文双语文档:绝对国内开发者福音。
2、教程文档丰富:快速开始、教程文档、模型搜索、演示 Demo,绝对开源项目顶配。
3、专业 icon:专业性一目了然。
4、300 + 开源模型:涵盖 CV、NLP、Audio、Video、工业应用主流五大品类的 300+ 预训练模型,没有看错,全部开源离线可运行。基本上是每个月都保持 10-20 个更新。
5、易用性做到极致:一键预测、一键服务化、十行代码迁移,技术门槛足够降低。

AB32VG1 RISC-V评估板正式现货发售,RT-Thread联合中科蓝讯回馈小伙伴的支持,售价大折扣49元包邮,数量有限售完即止。
????????????
点击阅读原文购买开发板
你可以添加微信17775982065为好友,注明:公司+姓名,拉进 RT-Thread 官方微信交流群!

???????????? 点击阅读原文购买开发板

