
- 1VPCFormer:一个基于transformer的多视角指静脉识别模型和一个新基准
- 2MathType2024MAC苹果电脑版本下载安装图文教程_mathtype mac
- 3MySQL 8.0 修改密码的那些折腾事_update user set plugin='caching_sha2_password' whe
- 4IBM SPSS Statistics:提升数据处理效率的利器
- 5Android Notification通知使用(从基本到高级)
- 6数理统计————思维导图(上岸必备)_数理统计思维导图
- 7Android获取手机内部存储路径-包含SD卡(通过挂载点)_android获取挂载设备名称
- 8微软牵手OpenAI劲敌!Mistral最新顶级大模型不再开源_mistral ai le chat猫
- 9批量梯度下降 | 随机梯度下降 | 小批度梯度下降_参数分批次下降
- 10IDEA系列:如何在Idea中去配置Gradle_idea配置gradle
危!我用python克隆了女朋友的声音!
赞
踩
今天,给大家介绍一个算法。
AI 算法 5 秒钟,就能克隆你的声音,你信吗?
听听这段音频,猜猜看是 AI 合成音,还是真人录音?
答案是:AI 合成。
这个人的原始声音在这里:
你给这个 AI 克隆声音的算法打几分?
上述两个音频,算法运行起来的效果:
录制一段音频,就可以根据输入的文字,5s 即可自动生成对应的合成音。
突然有个大胆的想法,你说女朋友要是哪天突然不承认自己说过了某句话,我就给她造一份!
兄弟们,我做的对吗?
MockingBird
这个算法是基于比较著名的 Real Time Voice Cloning 实现的。
MockingBird 是最近开源的中文版。
论文的名字是:
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
简单介绍下:
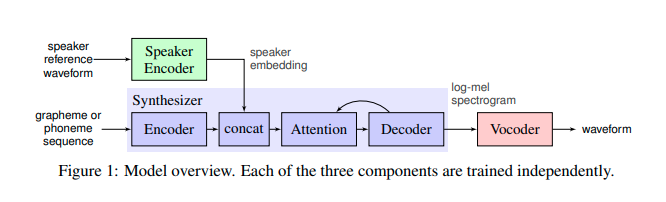
算法分为三个模块:encoder模块、systhesis模块、vocoder模块。
encoder模块将说话人的声音转换成人声的数字编码(speaker embedding)
synthesis 模块将文本转换成梅尔频谱(mel-spectrogram)
vocoder模块将梅尔频谱(mel-spectrogram)转换成(波形)waveform
具体的算法原理,大家可以先看论文:
https://arxiv.org/pdf/1806.04558.pdf
论文还没详细看,等我研究好后,后面有机会再发吧。
今天主要聊聊,这个算法怎么玩。
项目地址:https://github.com/babysor/MockingBird
有深度学习基础的话,这个应该不难。
就是部署环境,分四步:
Anaconda 配置 Pytorch 开发环境
根据项目 requirements.txt 安装第三方库依赖
下载权重文件
下载训练集,这个几十G,有点大
具体的配置方法,直接看这里:
https://github.com/babysor/MockingBird/blob/main/README-CN.md
都搞定了,就可以运行代码了。
有两种模式可以启动,Web 模式和工具箱模式。
在项目根目录运行:
python web.py即可开启 Web ,打开地址 http://localhost:8080 就能操作了。
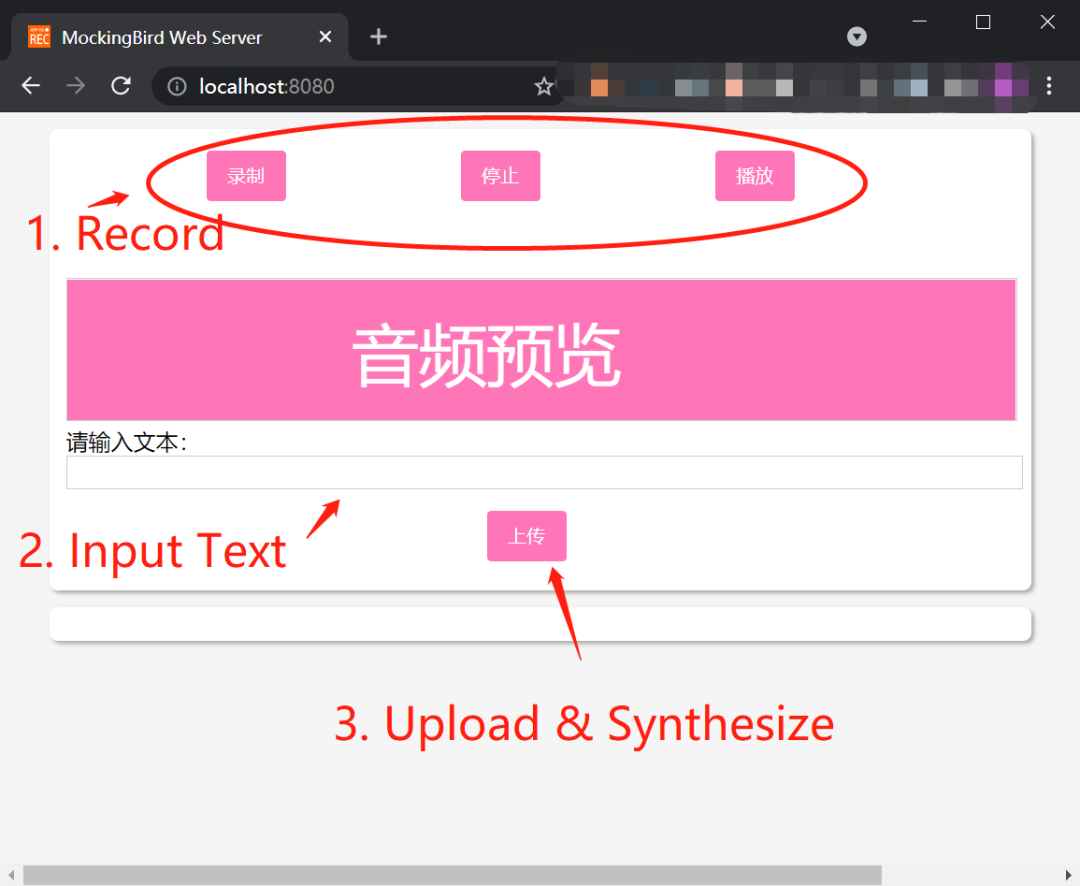
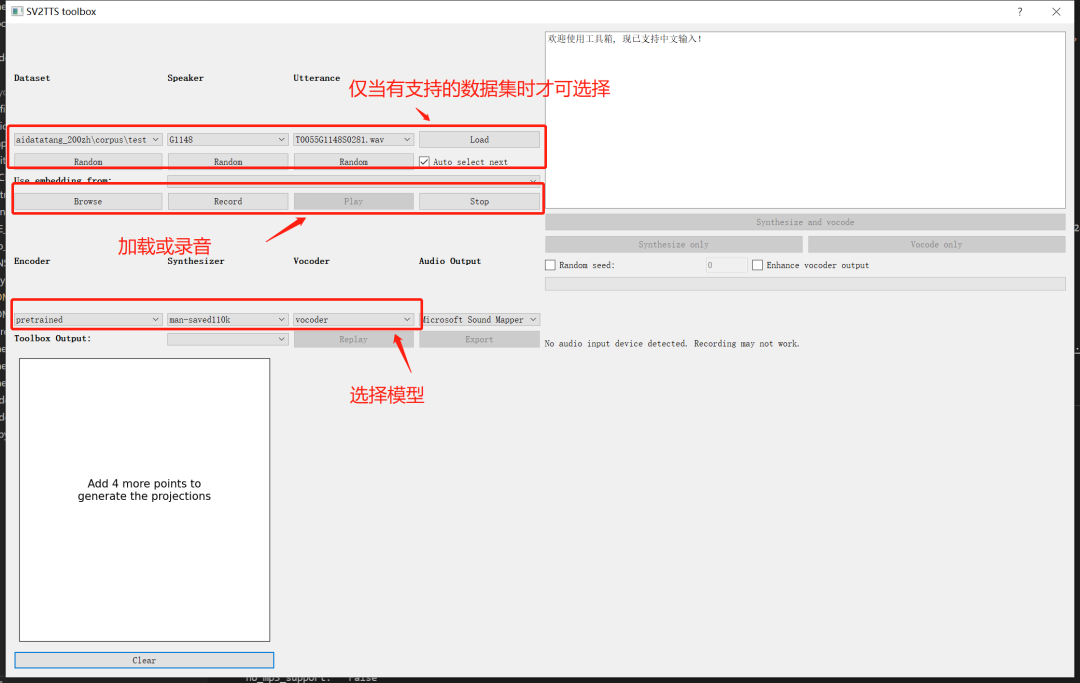
这个界面比较简陋,建议使用工具箱模式。
python demo_toolbox.py -d <datasets_root>datasets_root就是下载好的数据集的地址。
总结
Enjoy it!
喜欢的话,来个再看喽~
如果人多的话,后面我再出个详细的算法原理剖析和训练教程。

E N D

各位伙伴们好,詹帅本帅搭建了一个个人博客和小程序,汇集各种干货和资源,也方便大家阅读,感兴趣的小伙伴请移步小程序体验一下哦!(欢迎提建议)
推荐阅读


