
- 1有关神经网络的训练算法,神经网络训练过程详解_训练算法和神经网络的联系
- 2OpenHarmony开发板无法运行端云一体化项目的解决方案【坚果派-咸鱼】_replaceurl' can't support crossplatform applicatio
- 3文献学习-22-Surgical-VQLA:具有门控视觉语言嵌入的转换器,用于机器人手术中的视觉问题本地化回答
- 4NER任务语料_bosonnlp_ner_6c
- 5随身WIFI的刷机(debian系统)_随身wifi刷机
- 6excel if in函数_excel中if函数的使用技巧
- 7java中文转换拼音(HanLP)_java hanlp怎么把文字转全拼
- 8浅谈api工厂:前端Paas中台
- 9Transformer位置编码代码讲解_transformer时间戳编码
- 10一文带你了解爆火的Chat GPT_chatgpt csdn
clip_as_service学习过程(二)——clip主要的功能_clip-as-service
赞
踩
参考链接:https://clip-as-service.jina.ai/user-guides/client/#async-encoding
一、encoding()_编码
clip_client提供 encode() 函数,允许您以流和同步/异步方式将句子、图像发送到服务器。这里的编码意味着获取文本或图像的固定长度矢量表示。
encoding()接收两种类型的输入,输入不同,输出的数据类型也随之不同
1、输入可迭代的字符串类型,例如字符串列表,字符串元组,字符串生成器,对应的输出的是numpy.ndarray.
2、输入可迭代的Document数据类型,例如List[Document], DocumentArray, Generator[Document],对应的输出的数据类型是DocumentArray
1、作为文档可迭代对象的输入
类型url格式,包括相对路径,绝对路径http,url等都被视为图片数据,否则视为句子,
下面实例中的’apple.png’为本地的一张图片,'https://bpic.588ku.com/element_origin_min_pic/19/05/24/f862579f1d73afc60967a706238eac6d.jpg’是网络上的一张图片路径,
from clip_client import Client
c = Client('grpc://127.0.0.1:51000')
r = c.encode(
[
'she smiled, with pain',
'追风赶月莫停留,平芜尽处是春山!',
'apple.png',
'https://bpic.588ku.com/element_origin_min_pic/19/05/24/f862579f1d73afc60967a706238eac6d.jpg',
'data:image/gif;base64,R0lGODlhEAAQAMQAAORHHOVSKudfOulrSOp3WOyDZu6QdvCchPGolfO0o/XBs/fNwfjZ0frl3/zy7wAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACH5BAkAABAALAAAAAAQABAAAAVVICSOZGlCQAosJ6mu7fiyZeKqNKToQGDsM8hBADgUXoGAiqhSvp5QAnQKGIgUhwFUYLCVDFCrKUE1lBavAViFIDlTImbKC5Gm2hB0SlBCBMQiB0UjIQA7',
]
)
print(r)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
输出如下

2、作为文档可迭代对象的输入
此功能使用 DocArray,它作为上游依赖项一起安装。您不需要单独安装 DocArray。
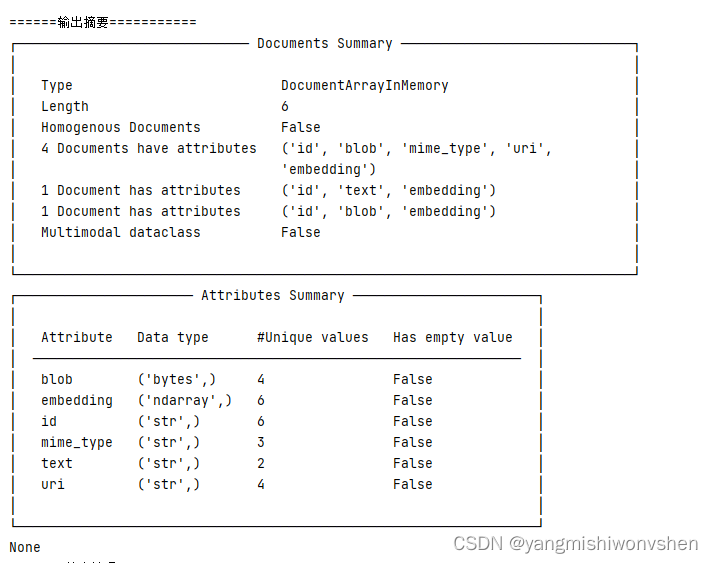
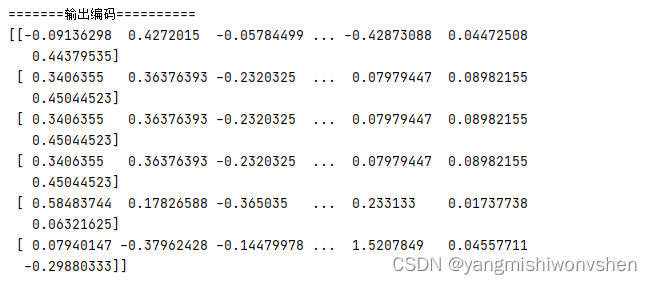
from clip_client import Client from docarray import Document c = Client('grpc://127.0.0.1:51000') da = [ Document(text='she smiled, with pain'), Document(uri='apple.png'), Document(uri='apple.png').load_uri_to_image_tensor(), Document(blob=open('apple.png', 'rb').read()), Document(uri='https://clip-as-service.jina.ai/_static/favicon.png'), Document( uri='data:image/gif;base64,R0lGODlhEAAQAMQAAORHHOVSKudfOulrSOp3WOyDZu6QdvCchPGolfO0o/XBs/fNwfjZ0frl3/zy7wAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACH5BAkAABAALAAAAAAQABAAAAVVICSOZGlCQAosJ6mu7fiyZeKqNKToQGDsM8hBADgUXoGAiqhSvp5QAnQKGIgUhwFUYLCVDFCrKUE1lBavAViFIDlTImbKC5Gm2hB0SlBCBMQiB0UjIQA7' ), ] r = c.encode(da) print("======输出摘要===========") print(r.summary()) print('=======输出编码==========') print(r.embeddings)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
输出如下
3、异步编码
import asyncio from clip_client import Client c = Client('grpc://127.0.0.1:51000') async def another_heavylifting_job(): # can be writing to database, downloading large file # big IO ops await asyncio.sleep(3) async def main(): t1 = asyncio.create_task(another_heavylifting_job()) t2 = asyncio.create_task(c.aencode(['hello world'] * 100)) await asyncio.gather(t1, t2) asyncio.run(main())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
二、ranking() _排序
这个函数的功能是给定一个句子,对多张图片进行排序或给一张图片对多个句子进行排序,此处和我的任务关系不大,就不再赘述
三、Indexing()_索引
ps:感觉像生成一个数据库,向里面存储数据,实例如下
from clip_client import Client from docarray import Document c = Client('grpc://127.0.0.1:51000') da = [ Document(text='she smiled, with pain'), Document(uri='apple.png'), Document(uri='apple.png').load_uri_to_image_tensor(), Document(blob=open('apple.png', 'rb').read()), Document(uri='https://clip-as-service.jina.ai/_static/favicon.png'), Document( uri='data:image/gif;base64,R0lGODlhEAAQAMQAAORHHOVSKudfOulrSOp3WOyDZu6QdvCchPGolfO0o/XBs/fNwfjZ0frl3/zy7wAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACH5BAkAABAALAAAAAAQABAAAAVVICSOZGlCQAosJ6mu7fiyZeKqNKToQGDsM8hBADgUXoGAiqhSvp5QAnQKGIgUhwFUYLCVDFCrKUE1lBavAViFIDlTImbKC5Gm2hB0SlBCBMQiB0UjIQA7' ), ] r = c.index(da) print(r.summary())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
现在返回结果是一个DocumentArray,我们可以得到他的摘要如下

四、Searching()_搜索
您可以设置参数(默认值为 )来控制要检索的最相似文档的数量。limit10
import asyncio from clip_client import Client from docarray import Document c = Client('grpc://127.0.0.1:51000') da = [ Document(text='she smiled, with pain'), Document(text='she smiles, with pain'), Document(uri='apple.png'), Document(uri='apple.png').load_uri_to_image_tensor(), Document(blob=open('apple.png', 'rb').read()), Document(uri='https://clip-as-service.jina.ai/_static/favicon.png'), Document( uri='data:image/gif;base64,R0lGODlhEAAQAMQAAORHHOVSKudfOulrSOp3WOyDZu6QdvCchPGolfO0o/XBs/fNwfjZ0frl3/zy7wAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACH5BAkAABAALAAAAAAQABAAAAVVICSOZGlCQAosJ6mu7fiyZeKqNKToQGDsM8hBADgUXoGAiqhSvp5QAnQKGIgUhwFUYLCVDFCrKUE1lBavAViFIDlTImbKC5Gm2hB0SlBCBMQiB0UjIQA7' ), ] r = c.index(da) result = c.search(['smile'], limit=100) print(result['@m', ['text', 'scores__cosine']])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
我的输出结果为空,和官方文档给的例子不一样,暂未找到具体原因

