
热门标签
热门文章
- 1【华为笔试题汇总】2024-04-24-华为春招笔试题-三语言题解(Python/Java/Cpp)_华为4.24笔试
- 2【持续更新】NebulaGraph详细学习文档
- 3Docker 环境下运行 Fast_LIO 进行三维建模的前/后处理设置_fast 、lio
- 4Docker容器使用问题:Failed to get D-Bus connection: Operation not permitted
- 5python写sparksql_使用PySpark编写SparkSQL程序查询Hive数据仓库
- 6华为ensp模拟校园网/企业网实例(同城灾备及异地备份中心保证网络安全)_ensp网络安全协议配置ssl案例
- 7我们来说说蹿红的AIGC到底是什么?ChatGPT又是什么?
- 8计算机毕设大数据毕业设计Hadoop项目Spark项目_基于hadoop的毕业设计
- 9HR招聘人才测评,如何考察候选人的内驱力?
- 10SparkMLlib:机器学习在Spark中的应用_spark mllib应用
当前位置: article > 正文
机器学习之贝叶斯算法_贝机器学习贝叶斯公式
作者:菜鸟追梦旅行 | 2024-04-29 05:59:33
赞
踩
贝机器学习贝叶斯公式
机器学习算法,就是基于大量经验数据对某个问题进行预测的算法;
1、机器学习分类
从训练特点,可以分为监督学习、无监督学习、半监督学习;
从解决问题,可以分为分类算法,聚类算法,回归分析算法,推荐算法;
2、数学基础
向量: 就是一串数字,代表现实中某个事物的一系列特征和特征值

相似度:
用欧几里得距离来衡量相似度:
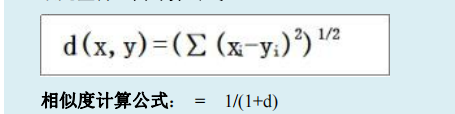
用余弦相似度衡量:

概率入门:
联合概率 P(A^B) :多件事情都发生的可能性!
条件概率 P(A | B) = P(A^B)/ P(B) : B条件下A发生的概率
贝叶斯公式 P(B | A) = P(A | B) *P(B) / P(A)

朴素贝叶斯:就是把各种情况出现的概率提前算好,用的时候,将依据算好的概率进行处理,得到结论。
3、评论语义分类实现:
1、加载样本数据
2、朴素贝叶斯模型训练器
package cn.doitedu.ml.comment.classify
import java.util
import com.hankcs.hanlp.HanLP
import com.hankcs.hanlp.seg.common.Term
import org.apache.spark.ml.classification.{NaiveBayes, NaiveBayesModel}
import org.apache.spark.ml.feature.{HashingTF, IDF}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* 评论样本数据的朴素贝叶斯模型训练器
*/
object NaiveBayesTrain {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("商品评论数据集的朴素贝叶斯分类模型训练")
.master("local")
.getOrCreate()
import spark.implicits._
val general = spark.read.textFile("userprofile/data/comment_sample/general")
val good = spark.read.textFile("userprofile/data/comment_sample/good")
val poor = spark.read.textFile("userprofile/data/comment_sample/poor")
// 加上类别标签: 差评:0 中评:1 好评:2
val labeledPoor = poor.map(s => (0.0, s))
val labeledGeneral = general.map(s => (1.0, s))
val labeledGood = good.map(s => (2.0, s))
// 将三类评论合并在一起
val sample: Dataset[(Double, String)] = labeledPoor.union(labeledGeneral).union(labeledGood)
// 加载停止词字典
val stopWords = spark.read.textFile("userprofile/data/comment_sample/stopwords").collect().toSet
val bc = spark.sparkContext.broadcast(stopWords)
// 对样本数据进行分词
val wordsDS: DataFrame= sample.map(tp=>{
// 从广播变量中获取停止词字典
val stpwds = bc.value
val label = tp._1
val terms: util.List[Term] = HanLP.segment(tp._2)
import scala.collection.JavaConversions._
val words: Array[String] = terms.map(term=>term.word).toArray.filter(!stpwds.contains(_))
(label,words)
}).toDF("label","words")
// 利用hashingTF算法,将词数组转为 TF特征值向量
val hashingTF = new HashingTF()
.setInputCol("words")
.setOutputCol("tfvec")
.setNumFeatures(1000000)
val tfvecDF: DataFrame = hashingTF.transform(wordsDS)
// 将TF特征值向量 转成 TF-IDF特征值 向量 ,利用的算法是: IDF
val idf = new IDF()
.setInputCol("tfvec")
.setOutputCol("tfidfvec")
val idfModel = idf.fit(tfvecDF)
val tfidfVecDF: DataFrame = idfModel.transform(tfvecDF).drop("words","tfvec")
// 将样本集,拆分成80% 和 20% 两部分,80%的作为训练集, 20%的作为测试集
val array: Array[DataFrame] = tfidfVecDF.randomSplit(Array(0.8, 0.2))
val trainSet = array(0)
val testSet = array(1)
// 训练朴素贝叶斯分类算法模型
val naiveBayes = new NaiveBayes()
.setLabelCol("label")
.setFeaturesCol("tfidfvec")
.setSmoothing(0.01)
val model = naiveBayes.fit(trainSet)
model.save("userprofile/data/comment_sample/model")
// val model1 = NaiveBayesModel.load("userprofile/data/comment_sample/model")
val result = model.transform(testSet)
result.show(100,false)
spark.close()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
4、特征值离散化:可能性是有限的,比如说职业、收入水平
根据离散计算出轨:
package cn.doitedu.ml.bayes
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.classification.NaiveBayes
import org.apache.spark.ml.linalg
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.SparkSession
import scala.collection.mutable
object ChuguiTrainner {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache").setLevel(Level.WARN)
val spark = SparkSession
.builder()
.appName("出轨预测")
.master("local")
.getOrCreate()
val df = spark.read.option("header",true).csv("userprofile/data/chugui/sample")
df.createTempView("df")
val featuresDF = spark.sql(
"""
|
|select
|name,
|case
| when job='老师' then 1.0
| when job='程序员' then 2.0
|else 3.0
|end as job,
|
|case
| when cast(income as double) <10000 then 1.0
| when cast(income as double) between 10000 and 20000 then 2.0
| else 3.0
|end as income ,
|
|case
| when age='青年' then 1.0
| when age='中年' then 2.0
|else 3.0
|end as age,
|
|if(sex ='男',1.0,2.0) as sex,
|if(label='出轨',0.0,1.0) as label
|
|from df
|
|""".stripMargin)
featuresDF.show(100,false)
featuresDF.createTempView("ft")
// 将原生 特征数组,变成 mllib中要求的Vector类型
val arr2Vec = (arr:mutable.WrappedArray[Double])=>{
// Vector是一个接口,它有两个实现,一个是DenseVector,一个是SparseVector
val vector: linalg.Vector = Vectors.dense(arr.toArray)
vector
}
spark.udf.register("arr2vec",arr2Vec)
val vec = spark.sql(
"""
|
|select
|name,
|label,
|arr2vec(array(cast(job as double),cast(income as double),cast(age as double), cast(sex as double))) as features
|
|from ft
|""".stripMargin)
/**
* 构造算法,训练模型
*/
val nvb = new NaiveBayes()
.setFeaturesCol("features")
.setSmoothing(0.01)
.setLabelCol("label")
val model = nvb.fit(vec)
model.save("userprofile/data/chugui/model")
spark.close()
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/菜鸟追梦旅行/article/detail/506279
推荐阅读
相关标签

