
热门标签
热门文章
- 1llama2模型下载
- 22022-2027年中国仓储物流机器人行业发展前景及投资战略咨询报告_2022-2023年仓储物流机器人行业洞察报告ppt csdn
- 3mysql数据库查询sql异常_SQL异常总结
- 4从零开始利用MATLAB进行FPGA设计(五)详解双口RAM_matlab仿真fpga
- 5Java中的抽象类和接口_接口 父类 抽象类
- 6【Linux驱动开发】011 gpio子系统
- 7RabbitMQ--基础--06--界面说明_rabbitmq页面怎么看
- 8cpp-httplib: 轻量级、高性能的C++ HTTP/HTTPS客户端和服务器库
- 9Java中的优先级队列 PriorityQueue 与 堆
- 10如何在Mac电脑上调整日期和时间?如何高效管理时间?_mac一体机如何调整日期显示
当前位置: article > 正文
中文分词多领域语料库_中文分词语料库
作者:菜鸟追梦旅行 | 2024-04-29 15:11:49
赞
踩
中文分词语料库
各位NLPer,大家好!
如果你还在从事中文分词领域的相关研究,你一定会发现,随着时间推移,中文分词的研究越来越少,BERT出现后,以字为粒度的方法盛行,有关中文分词的论文已经很少出现在期刊、顶会之中。
研究领域小众是常事,科研也从不应该盲目扎堆于热点技术之中,但是目前中文分词相关研究,已经许久没有新数据可用,旧数据也逐渐坏链,github频频登陆失败,更别提下载语料,这些都让神经网络相关研究无从下手。
因此,我总结了目前公开的可用于分词的语料库,将其分享出来,以供各位学者参考。
特别感谢:@何晗 本文原始数据皆出自其论文的github,使用请谨遵要求,标明出处。
[1] He H , Wu L , Yan H , et al. Effective Neural Solution for Multi-Criteria Word Segmentation[C]. Proceedings of the Second International Conference on Smart Computing and Informatics, 2018
语料来自:
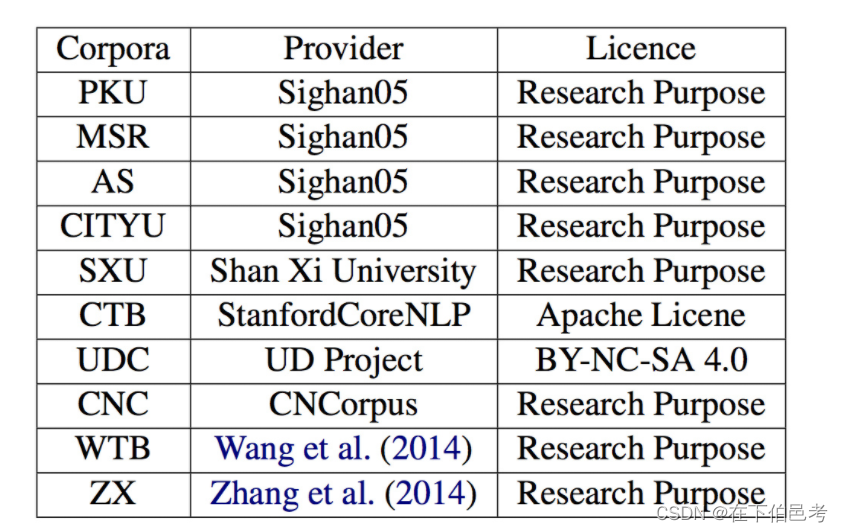
数据处理
由于语料库来自五湖四海,数据格式并不同,还有两个语料库为繁体,也有许多命名实体识别或词性标注的标签(NER恐成序列标注类任务唯一拿得出手的任务,CWS和POS感觉都没人研究了),我做了统一处理,操作如下:
- 使用正则表达式将所有的英文单词、数字串替换为x、0(常规操作)
- 繁体转简体
- 半角转全角
- 去重
- 全部统一为每行一个样本,词间使用空格分隔
- 按长度灵活切割(由于有些句子过长,输入神经网络单纯截断有些浪费语料,因此我编写了脚本,以标点符号分割为短句,相邻短句长度达到一定长度后分割样本,这样就保持每个样本的句长在固定长度上下,本文为40)
下载链接:
链接:https://pan.baidu.com/s/1CFJ_u173pT5WIi8Q_KJHEg?pwd=5fj3
提取码:5fj3
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

