
- 11.3了解分布式系统(通俗易懂)_分布式计算现实生活的案例
- 2分析 BAT 互联网巨头在大数据方向布局及大数据未来发展趋势_腾讯及阿里2012-2019年投资项目轮次分布(个)图
- 3C++常见经典面试题及详解_c++面试题
- 4大数据python论文毕设项目选题答疑
- 5Go 语言中常量和变量的定义、使用
- 6基于Java+SpringBoot+vue+elementui药品商城采购系统详细设计实现_java+vue商城项目
- 7谷歌浏览器安装JSON格式化插件简单教程_chrome 安装 json 转化插件
- 8web前端简易制作之HTML_web前端做网站含代码
- 9集合各实现类的底层实现原理_集合实现类的底层原理
- 10Redis实现延迟队列_redis延时队列
pyspark读取csv_pyspark玩转大数据
赞
踩
数据领域有小样本和大数据之分,适用的技术架构有一些不同。
几万条数据的规模,使用pandas可以处理得很好,但是当数据规模达到百万量级时,数据处理和模型可能根本就跑不起来。
对于熟悉python的小伙伴,此时可以使用pyspark的架构。pyspark2.x版本以后主要接口采用了dataframe,而且支持单机跑,所以可以用自己的小本本快速搞一下玩起来。
pyspark概览
说起大数据,不能不提hadoop。但是hadoop采用的是硬盘存储中间文件,而这么多年来硬盘技术没有太大发展,反而是内存技术飞速猛进,想想现在16G内存都是笔记本主流配置了,于是spark作为一种采用内存进行交互的技术飞速发展起来。
Spark 诞生于加州大学伯克利分校的 AMPLab 实验室,该实验室致力于数据密集型计算的研究。AMPLab 研究人员与大型互联网公司合作,研究如何解决数据和 AI 问题,然后发现那些拥有海量数据的公司也面临同样的问题。于是,他们开发了一个新引擎来处理这些新兴的工作负载,同时又能够让开发人员轻松地使用大数据处理 API。
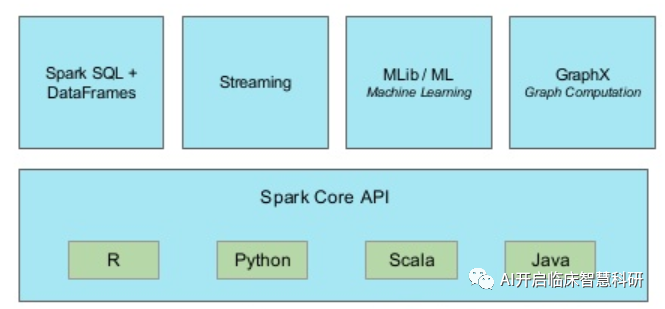
很快,社区开始参与贡献,对 Spark 进行了扩展,在流、Python 和 SQL 方面带来了新功能,成为数据处理、数据科学、机器学习和数据分析工作负载事实上的引擎,并且支持R、Python、Scala、Java多个接口。
大数据主要需求有:
- 历史数据清洗建模,需要用到复杂的批量处理,时间长,跨度为10min~N hr
- 历史数据为基础的交互式查询,时间通常为10sec~N min
- 实时数据为基础的流式数据,时间通常为N ms~N sec
针对于此,Spark的架构可以完美契合这些需求:
- SQL+DataFrame可以处理历史数据
- Streaming可以处理实时流数据
- 使用ML进行机器学习模型(MLib用于RDD数据,DataFrame数据主要使用ML中的函数)。
pyspark初始化和DataFrame
在 spark1.x 中,SparkContext 是 spark 的主要切入点,由于 RDD 作为主要的 API,我们通过 SparkContext 来创建和操作 RDD, 这个问题在于不同的应用中,需要使用不同的context:
- 在 Streaming 中需要使用 StreamingContext
- 在 sql 中需要使用 sqlContext
- 在 hive 中需要使用 hiveContext
随着 DataSet 和 DataFrame API 逐渐成为标准 API,需要为他们创建接入点,即 SparkSession。
SparkSession 是 spark2.x 引入的新概念,SparkSession 为用户提供统一的切入点,字面理解是创建会话,或者连接 spark SparkSession。
SparkSession实际上封装了SparkContext,比如可以调用spark.sparkContext.addPyFile("sparkxgb.zip")来加载xgboost模型, 另外也封装了 SparkConf、sqlContext,随着版本增加,功能可能会更多。所以我们尽量使用 SparkSession ,如果发现有些 API 不在 SparkSession 中,也可以通过 SparkSession 拿到 SparkContext 和其他 Context再调用相关的API。
不管输入是什么数据,都可以读入为DataFrame,这对熟悉pandas的小伙伴是非常友好的。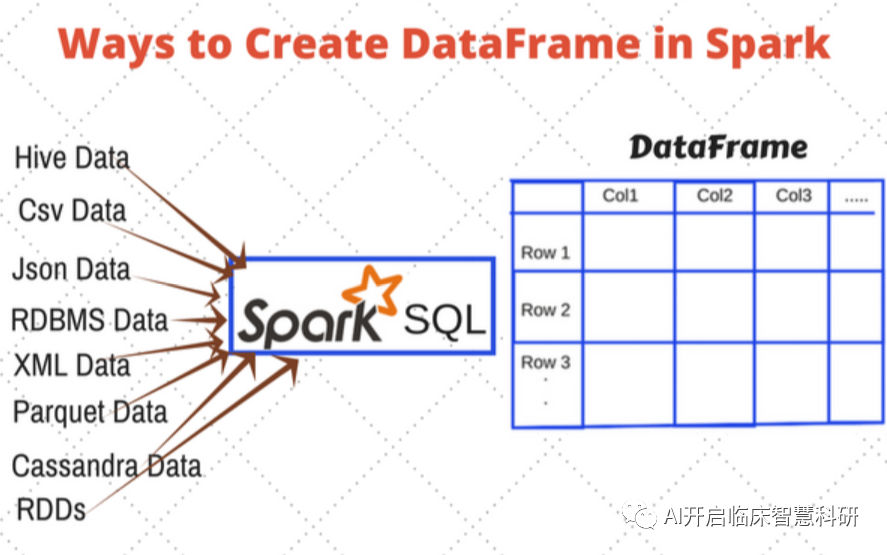
一段初始化并从csv读入的代码如下:
# 初始化import osos.environ['JAVA_HOME'] = '/usr/lib/jdk/jdk1.8.0_191'# 如果是单机跑spark(不用集群),需要指定master为local。spark = SparkSession\ .builder\ .appName("PySpark XGBOOST Titanic")\ .master('local') \ .getOrCreate() # 读入csv文件df = spark.read.csv('births_transformed.csv.gz', header=True, inferSchema='true')DataFrame的应用很多,有select、filter、fillna、collect、count, column、corr、cov、describe、distinct等等,熟练操作后行云流水玩转数据,详细操作参考:http://spark.apache.org/docs/latest/api/python/_modules/pyspark/sql/functions.html
pyspark自带分类模型demo
pyspark.ml package的函数很丰富: 我们来看一个使用二分类模型的例子,通常分为以下几步:
我们来看一个使用二分类模型的例子,通常分为以下几步:
- 读取数据
- 分类变量转换成onehot编码
#col_list is list of category featuresindexers = [StringIndexer(inputCol=c, outputCol=f'{c}_indexed').setHandleInvalid("keep") for c in col_list]encoder = [OneHotEncoder( inputCol=f'{c}_indexed, outputCol=f'{c}_vec') for c in col_list]- 多变量合并成一个变量
featuresCreator = VectorAssembler( inputCols = numeric_cols + [ec.getOutputCol() for ec in encoder], outputCol='features')#将所有定义好的transformer组合成一个pipelinepipeline = Pipeline(stages=encoder + [featuresCreator])- train&test split
df_train, df_test = df.randomSplit([0.7, 0.3], seed=666)- 生成weight列
y_dist = df_train.groupBy('label').count().orderBy('label')# 计算权重y_dist = y_dist.collect()w = y_dist[1][1] / y_dist[0][1]# 在train中新增一列weightdf_train = df_train.withColumn('weight', F.udf(lambda dt: 1 if dt == 0 else w)(F.col('label')).cast('float'))df_train.select('label', 'weight').show(5)- 创建模型
# random forestrf = RandomForestClassifier()- 创建交叉验证+网格调参
grid = tune.ParamGridBuilder() \ .addGrid(rf.maxDepth, [2, 4, 8]) \ .addGrid(rf.maxBins, [16, 32, 16]) \ .addGrid(rf.numTrees, [16,20,24]) \ .build()cv = tune.CrossValidator( estimator=rf, estimatorParamMaps=grid, evaluator=evaluator, numFolds=5)- 模型训练和预测
# data transformdata_transformer = pipeline.fit(df_train)train_data = data_transformer.transform(df_train)test_data = data_transformer.transform(df_test)# fit & predictmodel_results = {}# fitcvModel = cv.fit(train_data)# predicttest_model = cvModel.transform(test_data)- 模型性能评估
evaluator = ev.BinaryClassificationEvaluator( rawPredictionCol='probability', labelCol='label')auroc = evaluator.evaluate(cvModel, {evaluator.metricName: 'areaUnderROC'})aupr = evaluator.evaluate(cvModel, {evaluator.metricName: 'areaUnderPR'})print('model: {}'.format(k))print('测试集AUROC: %4.3f' % (auroc))print('测试集AUPR: %4.3f\n' % (aupr))- 模型可解释性(特征重要性和shap)
# 获得特征重要性fea_imp = cvModel.bestModel.featureImportances.toArray().tolist() # shapimport shapshap.initjs()explainer = shap.TreeExplainer(cvModel)X =df_train.toPandas()shap_values = explainer.shap_values(X)expected_values = explainer.expected_value # visualize the first prediction's explainationshap.force_plot(explainer.expected_value, shap_values[0, :], X.iloc[0, :])# visualize the training set predictionsshap.force_plot(explainer.expected_value, shap_values, X)注意:shap不能处理分类变量,否则会报错。另外,虽然可以直接调用pyspark的模型,但是shap_values还得通过pandas的dataframe接口。如果数据量较大,不能转换为pandas,还需要考虑比较复杂的word around方案。此处可以参考shap的github:https://github.com/slundberg/shap/issues/38
pyspark+xgboost
pyspark官方没有xgboost,但可以通过加载包的方式使用:
from pyspark.ml.feature import VectorAssembler, StringIndexer, OneHotEncoder, StandardScalerfrom pyspark.ml import Pipelinespark.sparkContext.addPyFile("sparkxgb.zip") # read xgboost pyspark client libfrom sparkxgb import XGBoostClassifierassembler = VectorAssembler( inputCols=numeric_cols, outputCol="features")xgboost = XGBoostClassifier( objective="reg:logistic", maxDepth=3, missing=float(0.0), featuresCol="features", labelCol="label", )
