
- 1使用pip install 时报错:“Fatal error in launcher: Unable to create process using ‘....”_pip install jieba 出现fatal error in launcher
- 2Kafka集群扩容_kafka集群随着扩大之后会发生什么?
- 3职场生存法则和处世之道
- 4使用conda创建虚拟环境,指定python版本,报错,该如何解决_conda create -n python 3.7报错
- 5unity学习笔记 Restsharp 使用心得_unity restsharp
- 6uniapp通过custom-tab-bar 自定义tabbar导航栏(主要用于微信小程序)_uniapp自定义导航栏custom
- 7【UE4 UE5】UE设置屏幕分辨率 全屏、窗口设置的方法_ue5设置分辨率
- 8基于Flink流处理的动态实时电商实时分析系统_基flink的电商销售数据实时分析处理系统的设计与实现
- 9什么是DCMM模型数据管理能力成熟度评估_dcmm数据成熟度模型
- 10狼搜索算法(WSA):利用狼的社交和狩猎策略进行优化_wolf search algorithm
基于Transformer的翻译模型(英->中)_transformer模型英汉互译
赞
踩
基于Transformer的翻译模型(英->中)
Transformer结构
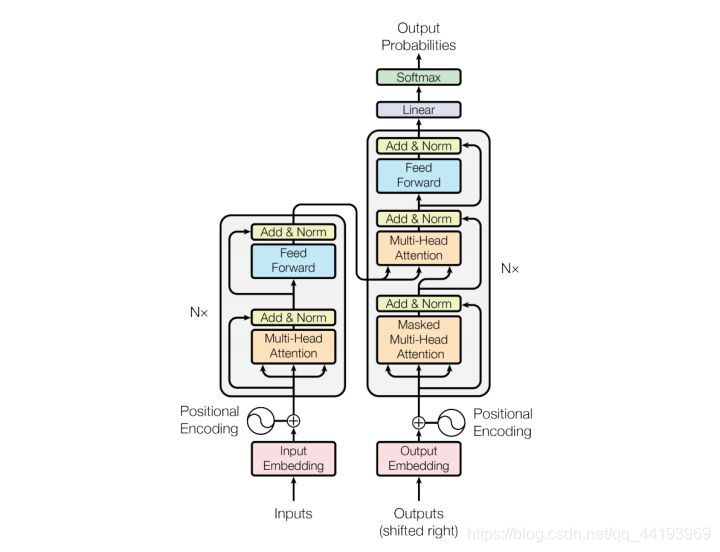
具体原理可以参考这篇文章Transformer
数据格式

因为我们的中文数据是繁体字,因此需将其转换为简体:
import copy import math import matplotlib.pyplot as plt import numpy as np import os import seaborn as sns import time import torch import torch.nn as nn import torch.nn.functional as F from collections import Counter from langconv import Converter from nltk import word_tokenize from torch.autograd import Variable def cht_to_chs(sent): sent = Converter("zh-hans").convert(sent) sent.encode("utf-8") return sent

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
转换完数据之后,我们需要将每句话按字粒度切分开,并构建词表,然后将单词映射为索引,并按照数据长度划分批次
class PrepareData: def __init__(self, train_file, dev_file): # 读取数据、分词 self.train_en, self.train_cn = self.load_data(train_file) self.dev_en, self.dev_cn = self.load_data(dev_file) # 构建词表 self.en_word_dict, self.en_total_words, self.en_index_dict = \ self.build_dict(self.train_en) self.cn_word_dict, self.cn_total_words, self.cn_index_dict = \ self.build_dict(self.train_cn) # 单词映射为索引 self.train_en, self.train_cn = self.word2id(self.train_en, self.train_cn, self.en_word_dict, self.cn_word_dict) self.dev_en, self.dev_cn = self.word2id(self.dev_en, self.dev_cn, self.en_word_dict, self.cn_word_dict) # 划分批次、填充、掩码 self.train_data = self.split_batch(self.train_en, self.train_cn, BATCH_SIZE) self.dev_data = self.split_batch(self.dev_en, self.dev_cn, BATCH_SIZE) def load_data(self, path): """ 读取英文、中文数据 对每条样本分词并构建包含起始符和终止符的单词列表 形式如:en = [['BOS', 'i', 'love', 'you', 'EOS'], ['BOS', 'me', 'too', 'EOS'], ...] cn = [['BOS', '我', '爱', '你', 'EOS'], ['BOS', '我', '也', '是', 'EOS'], ...] """ en = [] cn = [] with open(path, mode="r", encoding="utf-8") as f: for line in f.readlines(): sent_en, sent_cn = line.strip().split("\t") sent_en = sent_en.lower() sent_cn = cht_to_chs(sent_cn) sent_en = ["BOS"] + word_tokenize(sent_en) + ["EOS"] # 中文按字符切分 sent_cn = ["BOS"] + [char for char in sent_cn] + ["EOS"] en.append(sent_en) cn.append(sent_cn) return en, cn def build_dict(self, sentences, max_words=5e4): """ 构造分词后的列表数据 构建单词-索引映射(key为单词,value为id值) """ # 统计数据集中单词词频 word_count = Counter([word for sent in sentences for word in sent]) # 按词频保留前max_words个单词构建词典 # 添加UNK和PAD两个单词 ls = word_count.most_common(int(max_words)) total_words = len(ls) + 2 word_dict = {w[0]: index + 2 for index, w in enumerate(ls)} word_dict['UNK'] = UNK word_dict['PAD'] = PAD # 构建id2word映射 index_dict = {v: k for k, v in word_dict.items()} return word_dict, total_words, index_dict def word2id(self, en, cn, en_dict, cn_dict, sort=True): """ 将英文、中文单词列表转为单词索引列表 `sort=True`表示以英文语句长度排序,以便按批次填充时,同批次语句填充尽量少 """ length = len(en) # 单词映射为索引 out_en_ids = [[en_dict.get(word, UNK) for word in sent] for sent in en] out_cn_ids = [[cn_dict.get(word, UNK) for word in sent] for sent in cn] # 按照语句长度排序 def len_argsort(seq): """ 传入一系列语句数据(分好词的列表形式), 按照语句长度排序后,返回排序后原来各语句在数据中的索引下标 """ return sorted(range(len(seq)), key=lambda x: len(seq[x])) # 按相同顺序对中文、英文样本排序 if sort: # 以英文语句长度排序 sorted_index = len_argsort(out_en_ids) out_en_ids = [out_en_ids[idx] for idx in sorted_index] out_cn_ids = [out_cn_ids[idx] for idx in sorted_index] return out_en_ids, out_cn_ids def split_batch(self, en, cn, batch_size, shuffle=True): """ 划分批次 `shuffle=True`表示对各批次顺序随机打乱 """ # 每隔batch_size取一个索引作为后续batch的起始索引 idx_list = np.arange(0, len(en), batch_size) # 起始索引随机打乱 if shuffle: np.random.shuffle(idx_list) # 存放所有批次的语句索引 batch_indexs = [] for idx in idx_list: """ 形如[array([4, 5, 6, 7]), array([0, 1, 2, 3]), array([8, 9, 10, 11]), ...] """ # 起始索引最大的批次可能发生越界,要限定其索引 batch_indexs.append(np.arange(idx, min(idx + batch_size, len(en)))) # 构建批次列表 batches = [] for batch_index in batch_indexs: # 按当前批次的样本索引采样 batch_en = [en[index] for index in batch_index] batch_cn = [cn[index] for index in batch_index] # 对当前批次中所有语句填充、对齐长度 # 维度为:batch_size * 当前批次中语句的最大长度 batch_cn = seq_padding(batch_cn) batch_en = seq_padding(batch_en) # 将当前批次添加到批次列表 # Batch类用于实现注意力掩码 batches.append(Batch(batch_en, batch_cn)) return batches
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
模型结构
好了,接下来正式进入transformer部分
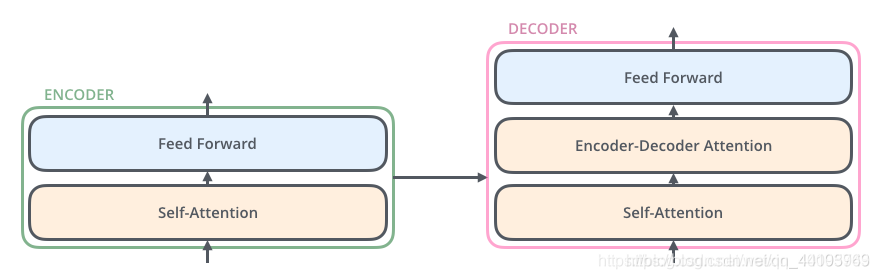

首先我们把输入的单词转为词向量,它包括token embedding和position embedding两层,编码之后的词向量再分别的流向encoder里面的两层网络。
Embedding
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
# Embedding层
self.lut = nn.Embedding(vocab, d_model)
# Embedding维数
self.d_model = d_model
def forward(self, x):
# 返回x的词向量(需要乘以math.sqrt(d_model))
return self.lut(x) * math.sqrt(self.d_model)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
位置编码
首先一个问题,为啥要进行位置编码呢。原因在于self-attention,将任意两个字之间距离缩小为1,丢失了字的位置信息,故我们需要加上这一信息。我们也可以想到两种方法
1.固定编码。
Transformer采用了这一方式,通过奇数列cos函数,偶数列sin函数方式,利用三角函数对位置进行固定编码。
固定编码方式简洁,不需要训练。且不受embedding table维度影响,理论上可以支持任意长度文本。(但要尽量避免预测文本很长,但训练集文本较短的case)
2.动态训练。
BERT采用了这种方式。先随机初始化一个embedding table,然后训练得到table 参数值。predict时通过embedding_lookup找到每个位置的embedding。这种方式和token embedding类似。
动态训练方式,在语料比较大时,准确度比较好。但需要训练,且最致命的是,限制了输入文本长度。当文本长度大于position embedding table维度时,超出的position无法查表得到embedding(可以理解为OOV了)。这也是为什么BERT模型文本长度最大512的原因。
Position Encoding
position encoding直接采用了三角函数。对偶数列采用sin,奇数列采用cos。
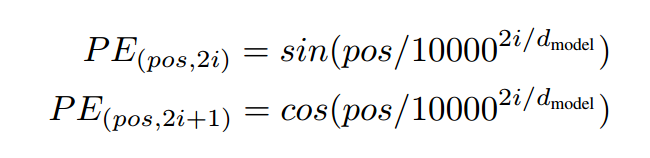
class PositionalEncoding(nn.Module): def __init__(self, d_model, dropout, max_len=5000): super(PositionalEncoding, self).__init__() self.dropout = nn.Dropout(p=dropout) # 位置编码矩阵,维度[max_len, embedding_dim] pe = torch.zeros(max_len, d_model, device=DEVICE) # 单词位置 position = torch.arange(0.0, max_len, device=DEVICE) position.unsqueeze_(1) # 使用exp和log实现幂运算 div_term = torch.exp(torch.arange(0.0, d_model, 2, device=DEVICE) * (- math.log(1e4) / d_model)) div_term.unsqueeze_(0) # 计算单词位置沿词向量维度的纹理值 pe[:, 0 : : 2] = torch.sin(torch.mm(position, div_term)) pe[:, 1 : : 2] = torch.cos(torch.mm(position, div_term)) # 增加批次维度,[1, max_len, embedding_dim] pe.unsqueeze_(0) # 将位置编码矩阵注册为buffer(不参加训练) self.register_buffer('pe', pe) def forward(self, x): # 将一个批次中语句所有词向量与位置编码相加 # 注意,位置编码不参与训练,因此设置requires_grad=False x += Variable(self.pe[:, : x.size(1), :], requires_grad=False) return self.dropout(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
Encoder 结构
Self-Attention
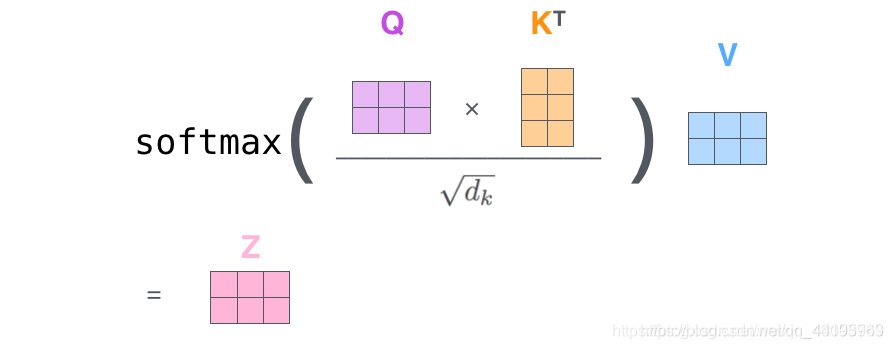
def attention(query, key, value, mask=None, dropout=None): """ Scaled Dot-Product Attention """ # q、k、v向量长度为d_k d_k = query.size(-1) # 矩阵乘法实现q、k点积注意力,sqrt(d_k)归一化 scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k) # 注意力掩码机制 if mask is not None: scores = scores.masked_fill(mask==0, -1e9) # 注意力矩阵softmax归一化 p_attn = F.softmax(scores, dim=-1) # dropout if dropout is not None: p_attn = dropout(p_attn) # 注意力对v加权 return torch.matmul(p_attn, value), p_attn
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
Multi-Head Attention
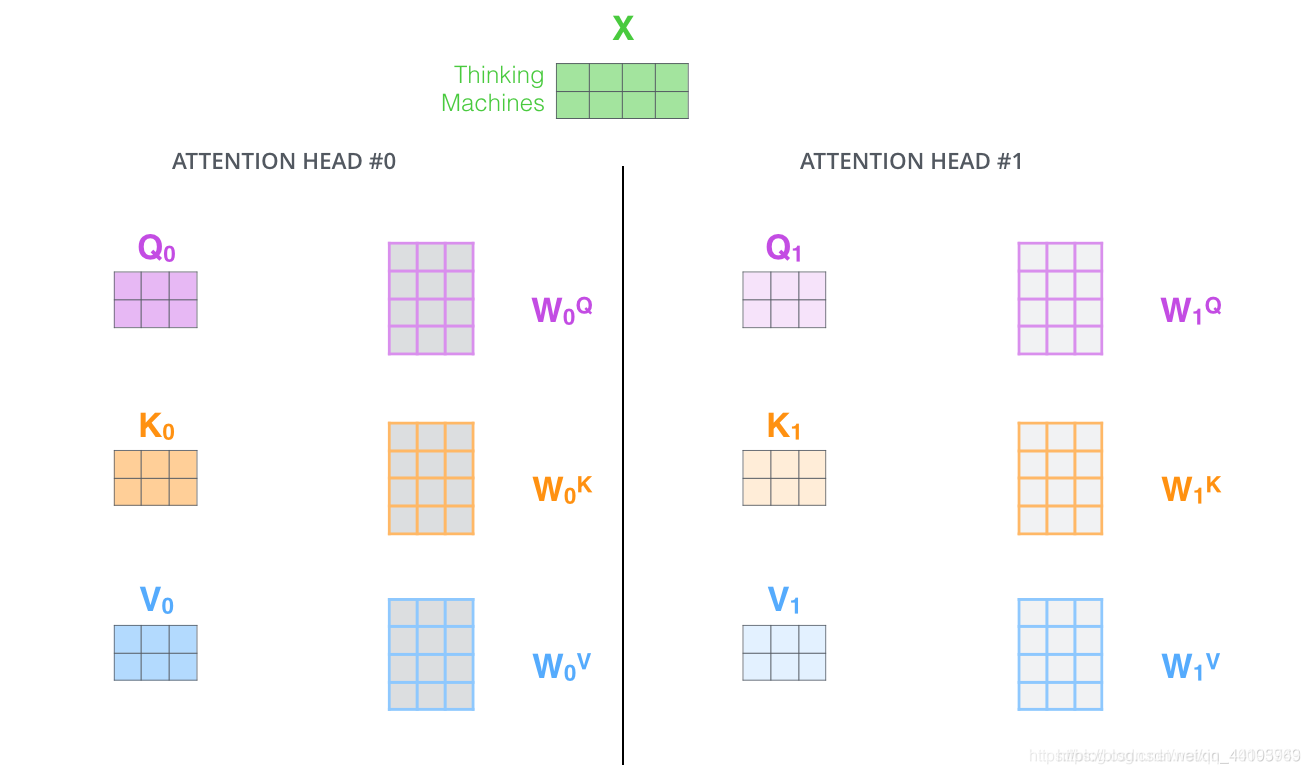
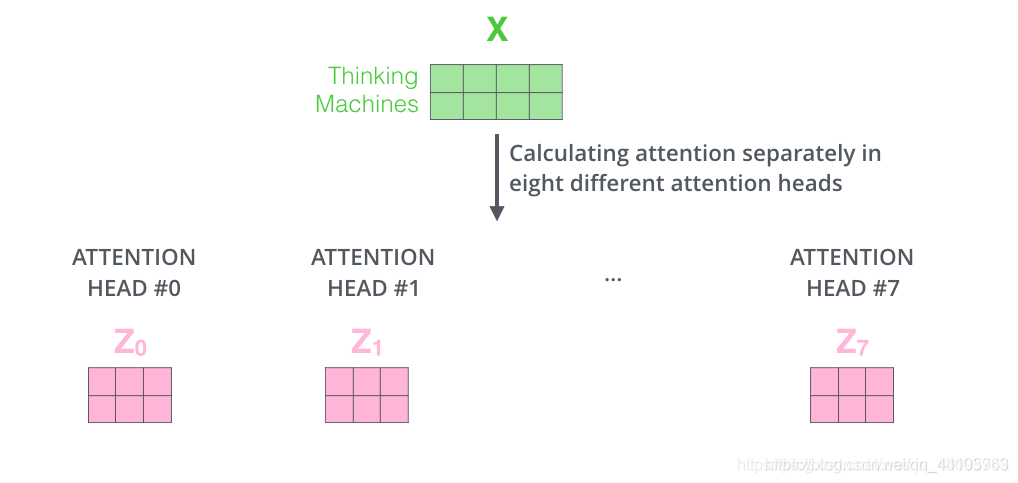
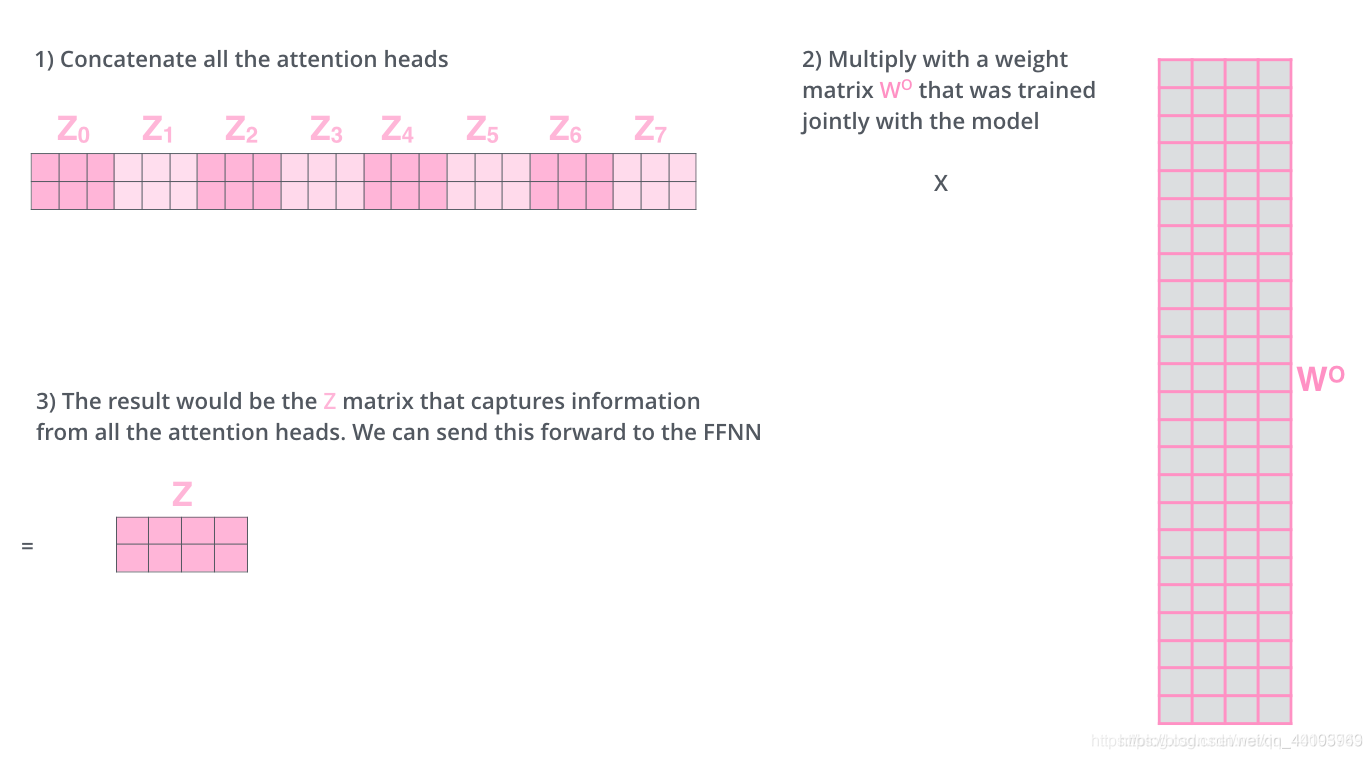
MultiHeadedAttention采用多头self-attention。它先将隐向量切分为h个头,然后每个头内部进行self-attention计算,最后再concat再一起。
这样做是为了获取语义的多层信息,最后再拼接到一起,得到的输出就包含了输入的多层信息。
def clones(module, N): """ 克隆基本单元,克隆的单元之间参数不共享 """ return nn.ModuleList([ copy.deepcopy(module) for _ in range(N) ]) class MultiHeadedAttention(nn.Module): """ Multi-Head Attention """ def __init__(self, h, d_model, dropout=0.1): super(MultiHeadedAttention, self).__init__() """ `h`:注意力头的数量 `d_model`:词向量维数 """ # 确保整除 assert d_model % h == 0 # q、k、v向量维数 self.d_k = d_model // h # 头的数量 self.h = h # WQ、WK、WV矩阵及多头注意力拼接变换矩阵WO self.linears = clones(nn.Linear(d_model, d_model), 4) self.attn = None self.dropout = nn.Dropout(p=dropout) def forward(self, query, key, value, mask=None): if mask is not None: mask = mask.unsqueeze(1) # 批次大小 nbatches = query.size(0) # WQ、WK、WV分别对词向量线性变换,并将结果拆成h块 query, key, value = [ l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2) for l, x in zip(self.linears, (query, key, value)) ] # 注意力加权 x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout) # 多头注意力加权拼接 x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k) # 对多头注意力加权拼接结果线性变换 return self.linears[-1](x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
Add & Norm
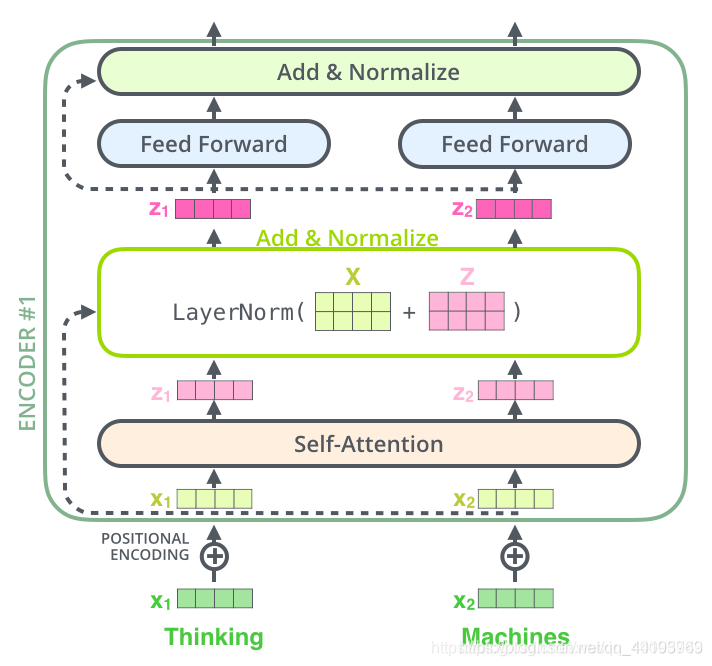
Add & Norm 层由 Add 和 Norm 两部分组成,其计算公式如下:

其中 X表示 Multi-Head Attention 或者 Feed Forward 的输入,MultiHeadAttention(X) 和 FeedForward(X) 表示输出 (输出与输入 X 维度是一样的,所以可以相加)。
Add指 X+MultiHeadAttention(X),是一种残差连接,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在 ResNet 中经常用到。

Norm指 Layer Normalization,通常用于 RNN 结构,Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
class SublayerConnection(nn.Module): """ 通过层归一化和残差连接,连接Multi-Head Attention和Feed Forward """ def __init__(self, size, dropout): super(SublayerConnection, self).__init__() self.norm = LayerNorm(size) self.dropout = nn.Dropout(dropout) def forward(self, x, sublayer): # 层归一化 x_ = self.norm(x) x_ = sublayer(x_) x_ = self.dropout(x_) # 残差连接 return x + x_
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
Feed Forward
Feed Forward 层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,对应的公式如下:
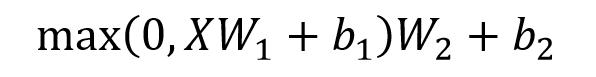
X是输入,Feed Forward 最终得到的输出矩阵的维度与 X 一致。
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.w_1(x)
x = F.relu(x)
x = self.dropout(x)
x = self.w_2(x)
return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Encoder Layer
通过上面描述的 Multi-Head Attention, Feed Forward, Add & Norm 就可以构造出一个 Encoder block,Encoder block 接收输入矩阵 X(n×d),并输出一个矩阵 O(n×d)。通过多个 Encoder block 叠加就可以组成 Encoder。
第一个 Encoder block 的输入为句子单词的表示向量矩阵,后续 Encoder block 的输入是前一个 Encoder block 的输出,最后一个 Encoder block 输出的矩阵就是 编码信息矩阵 C,这一矩阵后续会用到 Decoder 中。
class EncoderLayer(nn.Module): def __init__(self, size, self_attn, feed_forward, dropout): super(EncoderLayer, self).__init__() self.self_attn = self_attn self.feed_forward = feed_forward # SublayerConnection作用连接multi和ffn self.sublayer = clones(SublayerConnection(size, dropout), 2) # d_model self.size = size def forward(self, x, mask): # 将embedding层进行Multi head Attention x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask)) # attn的结果直接作为下一层输入 return self.sublayer[1](x, self.feed_forward)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
Encoder
class Encoder(nn.Module): def __init__(self, layer, N): """ layer = EncoderLayer """ super(Encoder, self).__init__() # 复制N个编码器基本单元 self.layers = clones(layer, N) # 层归一化 self.norm = LayerNorm(layer.size) def forward(self, x, mask): """ 循环编码器基本单元N次 """ for layer in self.layers: x = layer(x, mask) return self.norm(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
Decoder 结构
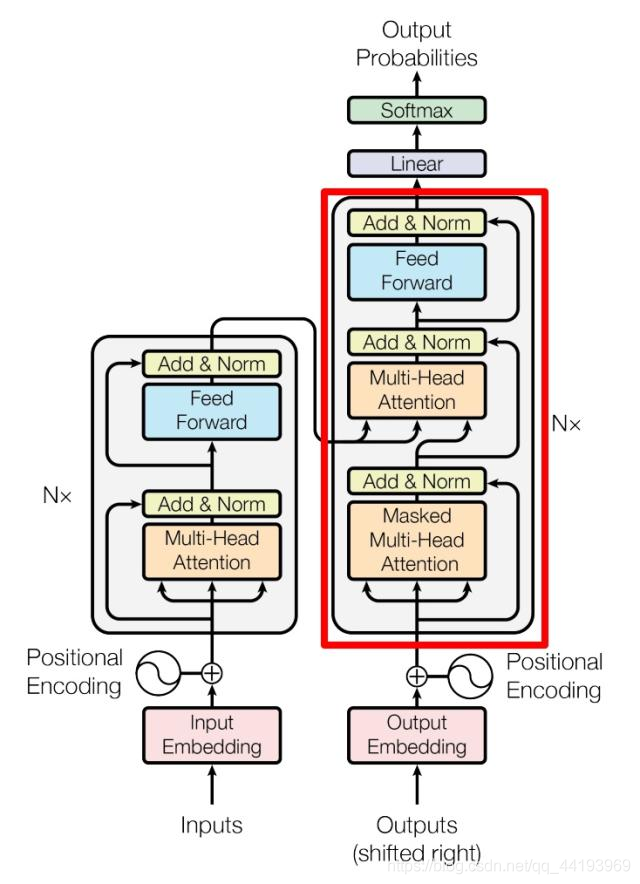
上图红色部分为 Transformer 的 Decoder block 结构,与 Encoder block 相似,但是存在一些区别:
- 包含两个 Multi-Head Attention 层。
- 第一个Masked Multi-Head Attention 层采用了 Masked 操作。
- 第二个 Multi-Head Attention 层的 K, V 矩阵使用 Encoder 的编码信息矩阵 C 进行计算,而 Q 使用上一个 Decoder block 的输出计算。
- 最后有一个 Softmax 层计算下一个翻译单词的概率。
第一个Masked Multi-Head Self-Attention
Decoder block 的第一个 Masked Multi-Head Self-Attention 采用了 Masked 操作,因为在翻译的过程中是顺序翻译的,即翻译完第 i 个单词,才可以翻译第 i+1 个单词。通过 Masked 操作可以防止第 i 个单词知道 i+1 个单词之后的信息。下面以 “我有一只猫” 翻译成 “I have a cat” 为例,了解一下 Masked 操作。
下面的描述中使用了类似 Teacher Forcing 的概念,不熟悉 Teacher Forcing 的童鞋可以参考以下上一篇文章Seq2Seq 模型详解。在 Decoder 的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示。首先根据输入 “” 预测出第一个单词为 “I”,然后根据输入 " I" 预测下一个单词 “have”。

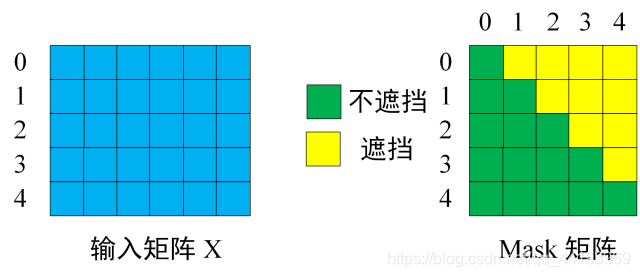
Decoder 可以在训练的过程中使用 Teacher Forcing 并且并行化训练,即将正确的单词序列 ( I have a cat) 和对应输出 (I have a cat ) 传递到 Decoder。那么在预测第 i 个输出时,就要将第 i+1 之后的单词掩盖住,注意 Mask 操作是在 Self-Attention 的 Softmax 之前使用的,下面用 0 1 2 3 4 5 分别表示 < Begin > I have a cat < end >。
第一步:是 Decoder 的输入矩阵和 Mask 矩阵,输入矩阵包含 " I have a cat" (0, 1, 2, 3, 4) 五个单词的表示向量,Mask 是一个 5×5 的矩阵。在 Mask 可以发现单词 0 只能使用单词 0 的信息,而单词 1 可以使用单词 0, 1 的信息,即只能使用之前的信息。
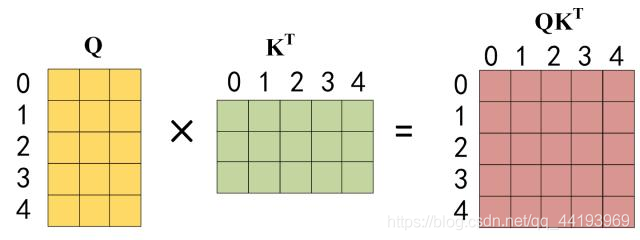
第二步:接下来的操作和之前的 Self-Attention 一样,通过输入矩阵 X计算得到 Q, K, V 矩阵。然后计算 Q 和 KT 的乘积 QKT。
第三步:在得到 QKT 之后需要进行 Softmax,计算 attention score,我们在 Softmax 之前需要使用 Mask矩阵遮挡住每一个单词之后的信息,遮挡操作如下:
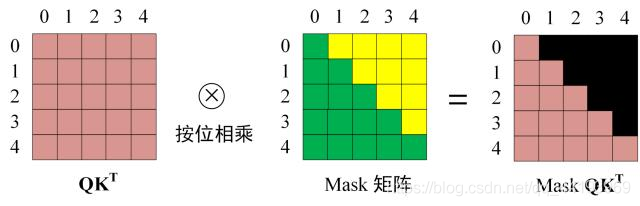
得到 Mask QKT 之后在 Mask QKT 上进行 Softmax,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的 attention score 都为 0。
第四步:使用 Mask QKT 与矩阵 V相乘,得到输出 Z,则单词 1 的输出向量 Z1 是只包含单词 1 信息的。
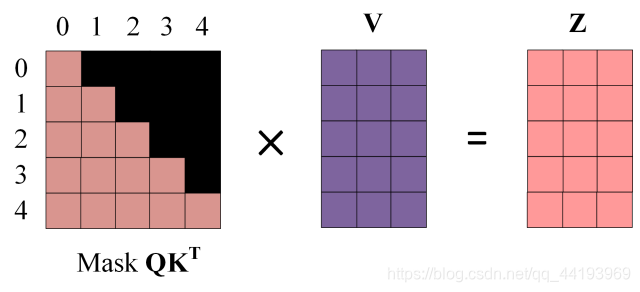
第五步:通过上述步骤就可以得到一个 Mask Multi-Head Self-Attention 的输出矩阵 Zi,然后和 Encoder 类似,通过 Multi-Head Self-Attention 拼接多个输出 Zi 然后计算得到第一个 Mask Multi-Head Self-Attention 的输出 Z,Z与输入 X 维度一样。
def subsequent_mask(size):
"Mask out subsequent positions."
# 设定subsequent_mask矩阵的shape
attn_shape = (1, size, size)
# 生成一个右上角(不含主对角线)为全1,左下角(含主对角线)为全0的subsequent_mask矩阵
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')
# 返回一个右上角(不含主对角线)为全False,左下角(含主对角线)为全True的subsequent_mask矩阵
return torch.from_numpy(subsequent_mask) == 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
第二个 Multi-Head Self-Attention
Decoder block 第二个 Multi-Head Attention 变化不大, 主要的区别在于其中 Self-Attention 的 K, V矩阵不是使用 上一个 Decoder block 的输出计算的,而是使用 Encoder 的编码信息矩阵 C 计算的。
根据 Encoder 的输出 C计算得到 K, V,根据上一个 Decoder block 的输出 Z 计算 Q (如果是第一个 Decoder block 则使用输入矩阵 X 进行计算),后续的计算方法与之前描述的一致。
这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 。
Decoder Layer
class DecoderLayer(nn.Module): def __init__(self, size, self_attn, src_attn, feed_forward, dropout): super(DecoderLayer, self).__init__() self.size = size # 自注意力机制 self.self_attn = self_attn # 上下文注意力机制 self.src_attn = src_attn self.feed_forward = feed_forward self.sublayer = clones(SublayerConnection(size, dropout), 3) def forward(self, x, memory, src_mask, tgt_mask): # memory为编码器输出隐表示 m = memory # 自注意力机制,q、k、v均来自解码器隐表示 x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask)) # 上下文注意力机制:q为来自解码器隐表示,而k、v为编码器隐表示 x = self.sublayer[1](x, lambda x: self.self_attn(x, m, m, src_mask)) return self.sublayer[2](x, self.feed_forward)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
Decoder
class Decoder(nn.Module):
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
"""
循环解码器基本单元N次
"""
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
Linear 与 Softmax
class Generator(nn.Module):
"""
解码器输出经线性变换和softmax函数映射为下一时刻预测单词的概率分布
"""
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
# decode后的结果,先进入一个全连接层变为词典大小的向量
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
# 然后再进行log_softmax操作(在softmax结果上再做多一次log运算)
return F.log_softmax(self.proj(x), dim=-1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
Transformer
class Transformer(nn.Module): def __init__(self, encoder, decoder, src_embed, tgt_embed, generator): super(Transformer, self).__init__() self.encoder = encoder self.decoder = decoder self.src_embed = src_embed self.tgt_embed = tgt_embed self.generator = generator def encode(self, src, src_mask): return self.encoder(self.src_embed(src), src_mask) def decode(self, memory, src_mask, tgt, tgt_mask): return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask) def forward(self, src, tgt, src_mask, tgt_mask): # encoder的结果作为decoder的memory参数传入,进行decode return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask) def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1): c = copy.deepcopy # 实例化Attention对象 attn = MultiHeadedAttention(h, d_model).to(DEVICE) # 实例化FeedForward对象 ff = PositionwiseFeedForward(d_model, d_ff, dropout).to(DEVICE) # 实例化PositionalEncoding对象 position = PositionalEncoding(d_model, dropout).to(DEVICE) # 实例化Transformer模型对象 model = Transformer( Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout).to(DEVICE), N).to(DEVICE), Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout).to(DEVICE), N).to(DEVICE), nn.Sequential(Embeddings(d_model, src_vocab).to(DEVICE), c(position)), nn.Sequential(Embeddings(d_model, tgt_vocab).to(DEVICE), c(position)), Generator(d_model, tgt_vocab)).to(DEVICE) # This was important from their code. # Initialize parameters with Glorot / fan_avg. for p in model.parameters(): if p.dim() > 1: # 这里初始化采用的是nn.init.xavier_uniform nn.init.xavier_uniform_(p) return model.to(DEVICE)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
Label Smoothing
为了防止模型在训练时过于自信地预测标签,改善模型的泛化能力,我们可以增加一个label smoothing的操作
class LabelSmoothing(nn.Module): """ 标签平滑 """ def __init__(self, size, padding_idx, smoothing=0.0): super(LabelSmoothing, self).__init__() self.criterion = nn.KLDivLoss(reduction='sum') self.padding_idx = padding_idx self.confidence = 1.0 - smoothing self.smoothing = smoothing self.size = size self.true_dist = None def forward(self, x, target): assert x.size(1) == self.size true_dist = x.data.clone() true_dist.fill_(self.smoothing / (self.size - 2)) true_dist.scatter_(1, target.data.unsqueeze(1), self.confidence) true_dist[:, self.padding_idx] = 0 mask = torch.nonzero(target.data == self.padding_idx) if mask.dim() > 0: true_dist.index_fill_(0, mask.squeeze(), 0.0) self.true_dist = true_dist return self.criterion(x, Variable(true_dist, requires_grad=False))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
总结
- Transformer 与 RNN 不同,可以比较好地并行训练。
- Transformer 中 Multi-Head Attention 中有多个 Self-Attention,可以捕获单词之间多种维度上的相关系数 attention score。
- 由于 self-attention 没有循环结构,Transformer 需要一种方式来表示序列中元素的相对或绝对位置关系。Position Embedding (PE) 就是该文提出的方案。但在一些研究中,模型加上 PE 和不加上 PE 并不见得有明显的差异
全部代码和数据都已经上传github transformer-english2Chinese

