
- 1mac下如何通过putty生成证书_puttygen mac
- 2GPT:清华ChatGLM-6B中文对话模型部署_chatglm-6b-int4
- 3光伏并网逆变器学习1-simulink_simulink光伏并网振荡
- 4Halcon执行手眼标定, 发那科机器人三点法标定_fanuc机器人 标定矩阵
- 5Python学习笔记—数据表的透视方法(pivot_table)_python中pivottable的用法
- 6在Linux中安装g++/gdb/vim配置_配置linux g++ 支持tr24733
- 7延迟约束
- 8大模型の升级与设计_大模型的gmask
- 9Acunetix安装及使用_acunetix使用_acunetix使用说明
- 10计算机网络经典面试题:在浏览器中输入URL并按下回车后会发生什么?_在浏览器地址栏键入url,按下回车之后会经历什么
yolov10代码阅读
赞
踩
一 数据处理
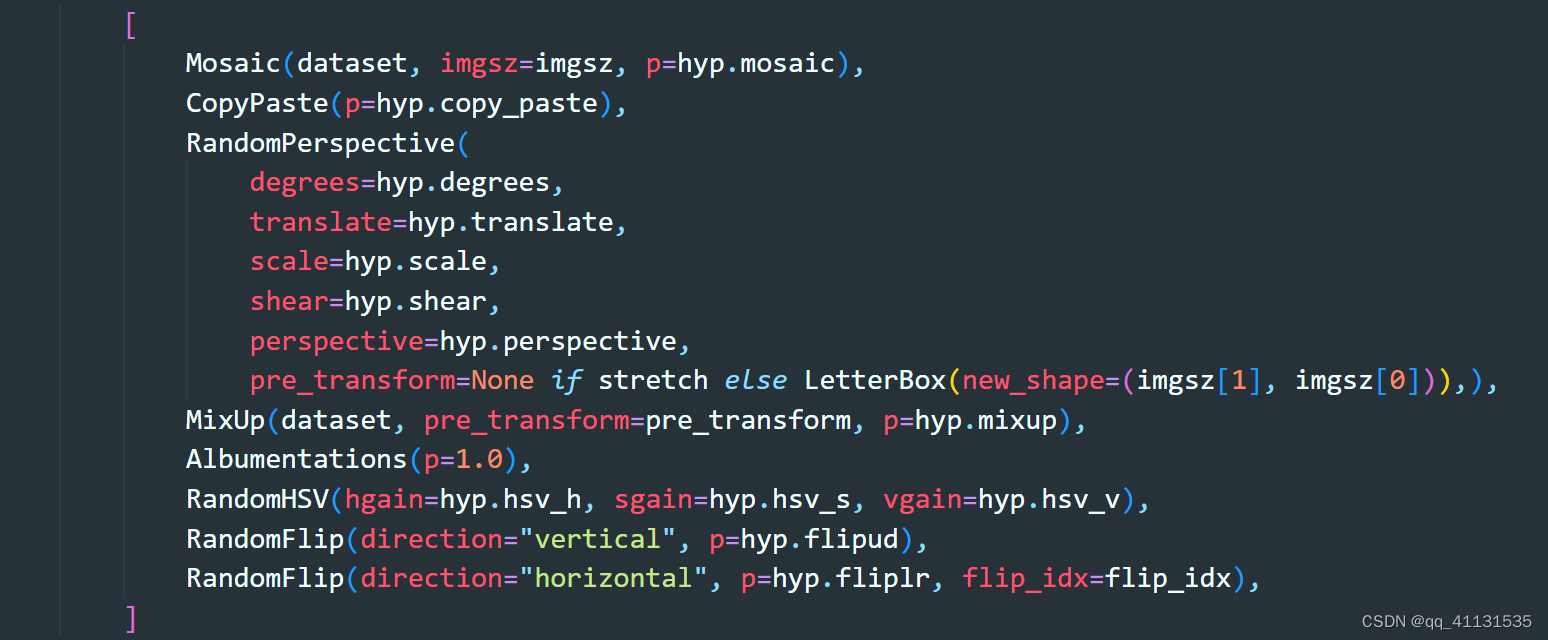
- 在v8之后,v9和v10都是参考v8的数据增强处理,主要有以下,具体其中一些增强并未用到,可以参考具体配置
二 模型结构
-
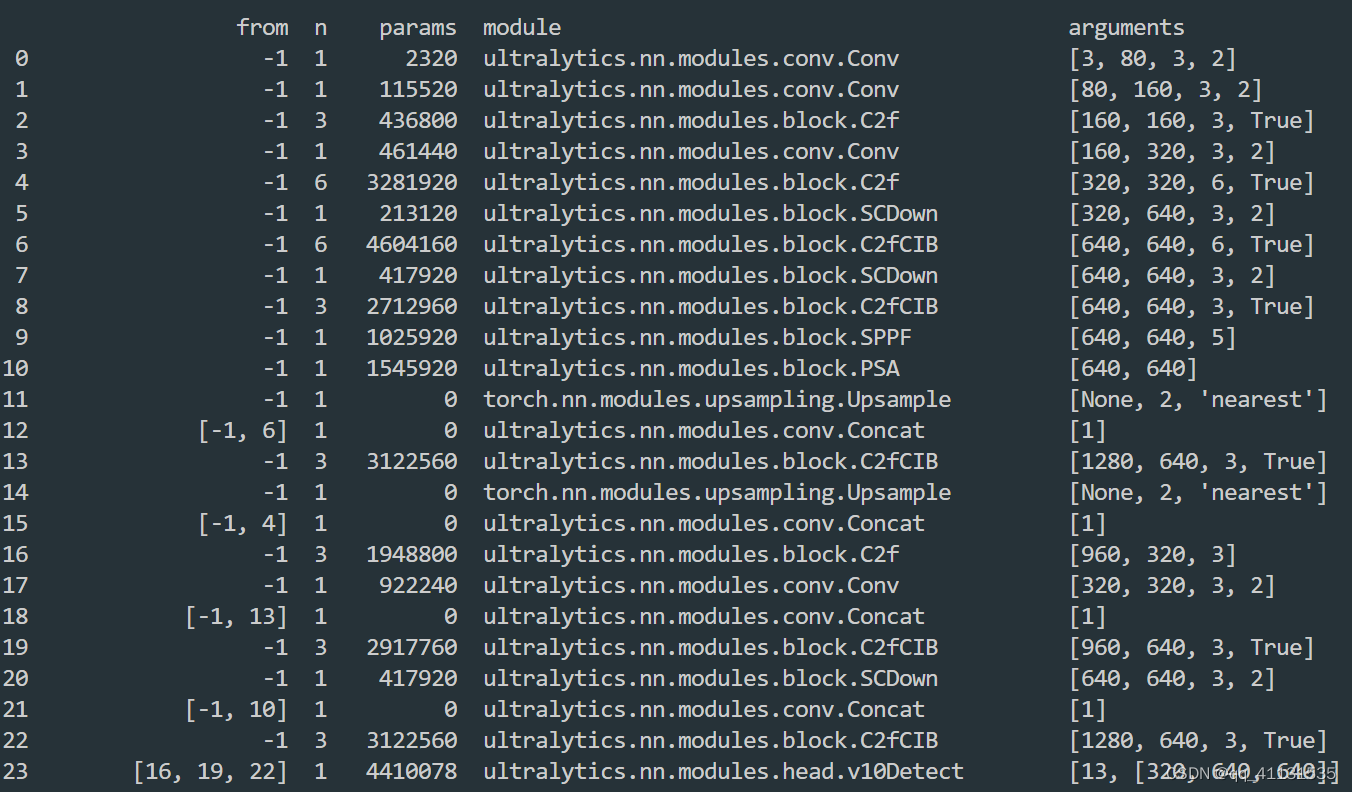
以yolov10x为例子,整个模型结构如下
a. 对于SCDown,是 Spatial-channel decoupled downsampling,主要是针对原始的下采样Conv2d(C,2C,kernel=3,stride=2)的下采集,进行修改成 Conv2d(C,2C,kernel=1,stride=1)加上一个组卷积 Conv2d(2C,2C,kernel=3,stride=2,group=2C);对于原始的下采样计算量是 H ∗ W ∗ 3 ∗ 3 ∗ C ∗ 2 C / ( 2 ∗ 2 ) H*W*3*3*C*2C/(2*2) H∗W∗3∗3∗C∗2C/(2∗2),对应参数是 3 ∗ 3 ∗ C ∗ 2 C 3*3*C*2C 3∗3∗C∗2C,修改后的计算量是 H ∗ W ∗ C ∗ 2 C + H ∗ W ∗ 3 ∗ 3 ∗ 2 C / ( 2 ∗ 2 ) H*W*C*2C+H*W*3*3*2C/(2*2) H∗W∗C∗2C+H∗W∗3∗3∗2C/(2∗2),对应参数是 C ∗ 2 C + 3 ∗ 3 ∗ 2 C C*2C+3*3*2C C∗2C+3∗3∗2C
b. CIB是放在C2f模块中,主要是针对 3 ∗ 3 3*3 3∗3的卷积都替换成了组卷积(depthwise convolution),对于小模型会采用 7 ∗ 7 7*7 7∗7的组卷积
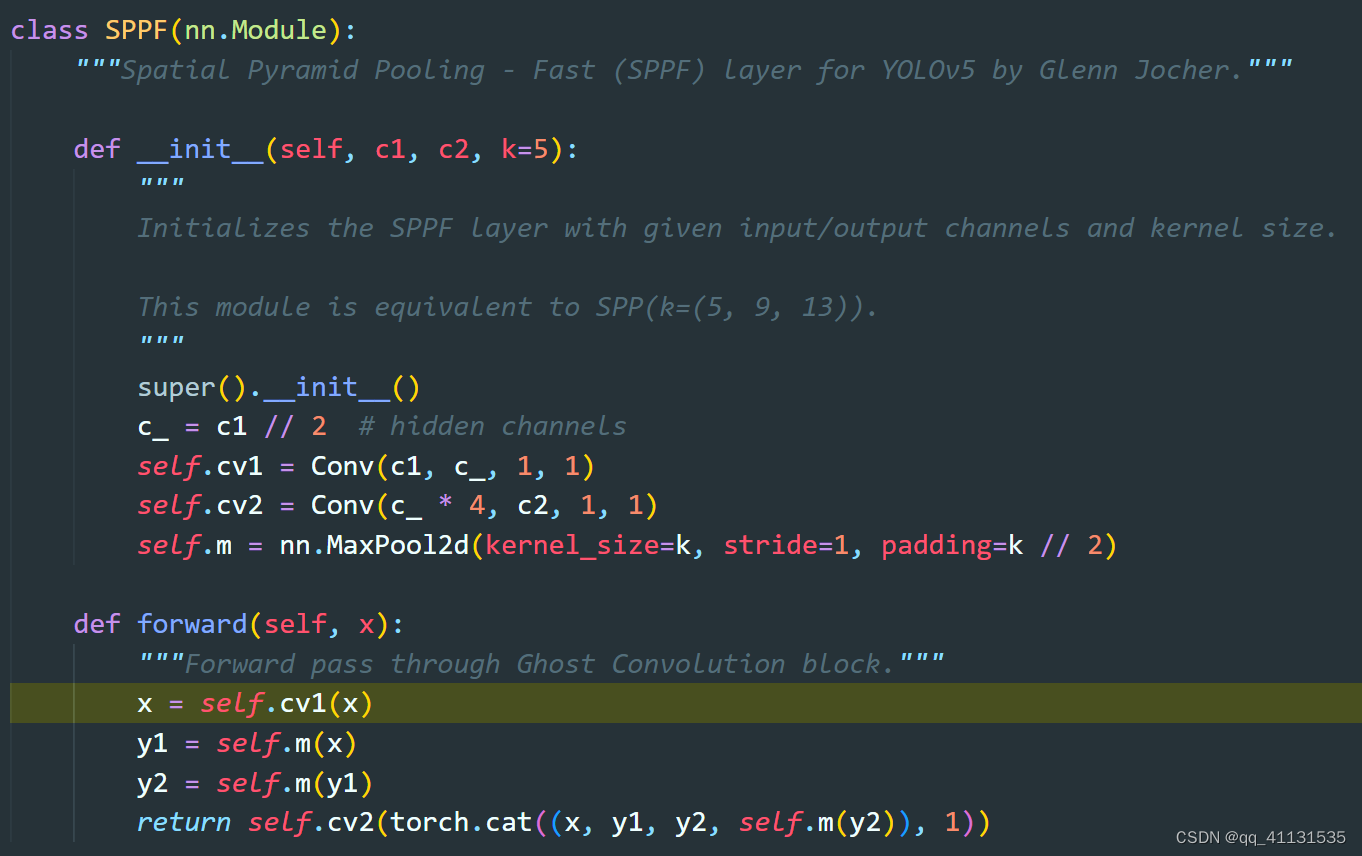
c. SPPF,是将maxpool(k=5,9,13)和原始输入叠加到一起,在走一个卷积,得到最终输出,其中采用简化算法,就是走多次maxpool(k=5),替换maxpool(k=9,13)
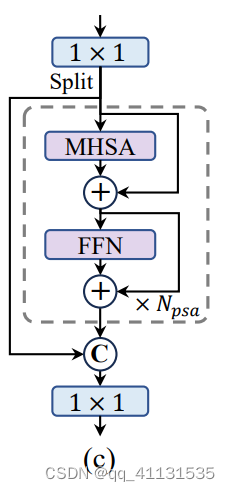
d. PSA,是加了个自注意力机制模块,主要做的修改是,将输入根据channel拆分成2份,其中一份做self-attention,然后和另一份做融合
e. V10Detect,在head部分,经过实验发现,分类头比框回归头参数多,但是重要性不如框回归头,所以对分类头,进行depthwise卷积,降参数;主要3个损失,分类采用的BCELoss(没有采用varifocal_loss),回归box是CIou Loss和DFL loss
f. V10Detect,采用one2one和one2many,两种匹配策略,one2many是和以前yolo一样,一个gt框会对应选择10个预测框去做loss,one2one就是一个gt框只选择一个预测框去做loss,同时在inference的时候只走one2one阶段,去掉nms后处理的耗时;对于one2one采用的head是deepcopy了一份,同时计算出来的梯度只更新V10Detect head,不回传到backbone和PAN阶段
g. 对于最后inference,作者提出特别对于小模型,one2many+nms的ap要比one2one的要好,二者之间还是有差距

