
- 12000年 数模国赛 b题 钢管订购与运输_2000年国赛数学建模b题
- 2浏览器下载文件的方法总结_a.setattribute('target', '_blank')
- 3点餐系统的Python实现_用python编写一个点餐app
- 4数据结构-双向链表
- 5深度学习框架Keras(1)_keras中文网址
- 6最全 Java 8 讲解【建议收藏,反复研读】_java8
- 7【SpringBoot】spring-retry(重试机制)_springboot retry
- 82021-10-19(树形dp)_给定一棵包含n个结点的树,树的每条边的长度均为1。求这棵树的所有长度在l-r之间的
- 9在PPC上安装pythonce
- 10华为OD感受:我不敢和朋友说,我入职华为OD了,2023年5月新文更新_2023华为od涨薪太少
【机器学习】随机森林预测并可视化特征重要性_随机森林可视化
赞
踩
今天需要用到特征重要性的分析,所以干脆就写一下使用随机森林是如何做建模并基于随机森林做特征重要性的分析。顺带给出了编码方式、随机森林、特征重要性可视化的完整Python代码,都是可以直接运行的。
目 录
实验环境:
Window 10
PyCharm 2021.2.2(Community Edition)
实验说明:
data:数据集(我的数据包含27个特征,1个目标变量)
!!!数据集是预处理过后数据,其中的分类型特征已被编码。若数据集未编码,可以使用以下方式对分类型特征编码!!!
1 分类型特征编码
1.1 LabelEncoder编码
LabelEncoder编码会将分类型特征按照1、2、3、4...的方式编码
- # 导入LabelEncoder包
- from sklearn.preprocessing import LabelEncoder
-
- # 选出分类型特征
- bool_features = ['有阳台', '有厨房', '有地窖', '有电梯', '有花园', '是新建筑', '上传日期', '可带宠物']
-
- for i in bool_features:
- le = LabelEncoder()
- le = le.fit(data[i])
- data[i] = le.transform(data[i])
- #data[i] = LabelEncoder().fit_transform(train[i])
- print(f'{i}处理成功~')
1.2 独热编码(One-Hot Encoding)
独热编码会将分类型数据按照(1,0,0)、(0,1,0)、(0,0,1)的方式编码,这种编码方式会扩增特征维数,具体来说,假设你的“可带宠物”包含3类,那么独热编码后就会使得该特征变为3列
- from sklearn.preprocessing import OneHotEncoder
-
- # 创建OneHotEncoder对象
- encoder = OneHotEncoder(categories='auto', sparse=False)
-
- # 对需要进行One-Hot编码的特征进行编码
- encoded_data = encoder.fit_transform(data[bool_features])
-
- # 获取编码后特征的名称并根据原始特征的取值进行命名
- feature_names = []
- for feature, categories in zip(bool_features, encoder.categories_):
- for category in categories:
- feature_names.append(f"{feature}_{category}")
- # 将编码后的特征转化为DataFrame,并使用新的特征名称进行命名
- encoded_data = pd.DataFrame(encoded_data, columns=feature_names)
-
- # 将编码后的特征替换原始数据集中的特征
- data.drop(bool_features, axis=1, inplace=True)
- train = pd.concat([data, pd.DataFrame(encoded_data)], axis=1)
上述代码会删掉编码前的特征列,并在最后加入编码后的特征列
2 随机森林回归模型
2.1 随机森林回归模型建立
变量解释:
y_test:验证集的真实值,Series类型y_test_t:验证集的真实集,ndarray类型
y_pred:验证集的预测值,ndarray类型
- # 导入必要的库
- from sklearn.ensemble import RandomForestRegressor
- from sklearn.model_selection import train_test_split
- import pandas as pd
- import numpy as np
- # 用于保存和提取模型
- import joblib
- import matplotlib.pyplot as plt # 绘图库
- # 解决画图中文字体显示的问题
- plt.rcParams['font.sans-serif'] = ['KaiTi', 'SimHei', 'Times New Roman'] # 汉字字体集
- plt.rcParams['font.size'] = 12 # 字体大小
- plt.rcParams['axes.unicode_minus'] = False
- # 忽略警告
- import warnings
- warnings.filterwarnings('ignore')
-
- # 读取数据集
- data = pd.read_csv('./data.csv', encoding='gbk')
-
- # 特征
- X = data.drop('房屋租金', axis=1)
- # 目标变量
- y = data['房屋租金']
-
- # 数据集拆分出训练集和验证集
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=2023)
-
- # 定义一个默认随机森林回归模型
- RF = RandomForestRegressor(n_jobs=-1)
- # 训练模型
- RF.fit(X_train, y_train)
-
- # 保存模型
- joblib.dump(RF, r'./RF.pkl')
- # 读取模型
- RF = joblib.load(r'./RF.pkl')
-
- # 模型预测
- y_pred = RF.predict(X_test)
-
- # 绘制线图
- # 前200条预测结果的可视化
- plt.figure(figsize=(20, 6))
- y_tesy_t = np.asarray(y_test)
- plt.plot(y_tesy_t[:200], label='True Values')
- plt.plot(y_pred[:200], label='Predicted Values')
- plt.xlabel('Index')
- plt.ylabel('Value')
- plt.legend()
- plt.savefig('./前200条预测结果图.jpg', dpi=400, bbox_inches='tight')
- plt.show()
使用模型预测验证集,得到前200条数据的可视化结果如下:
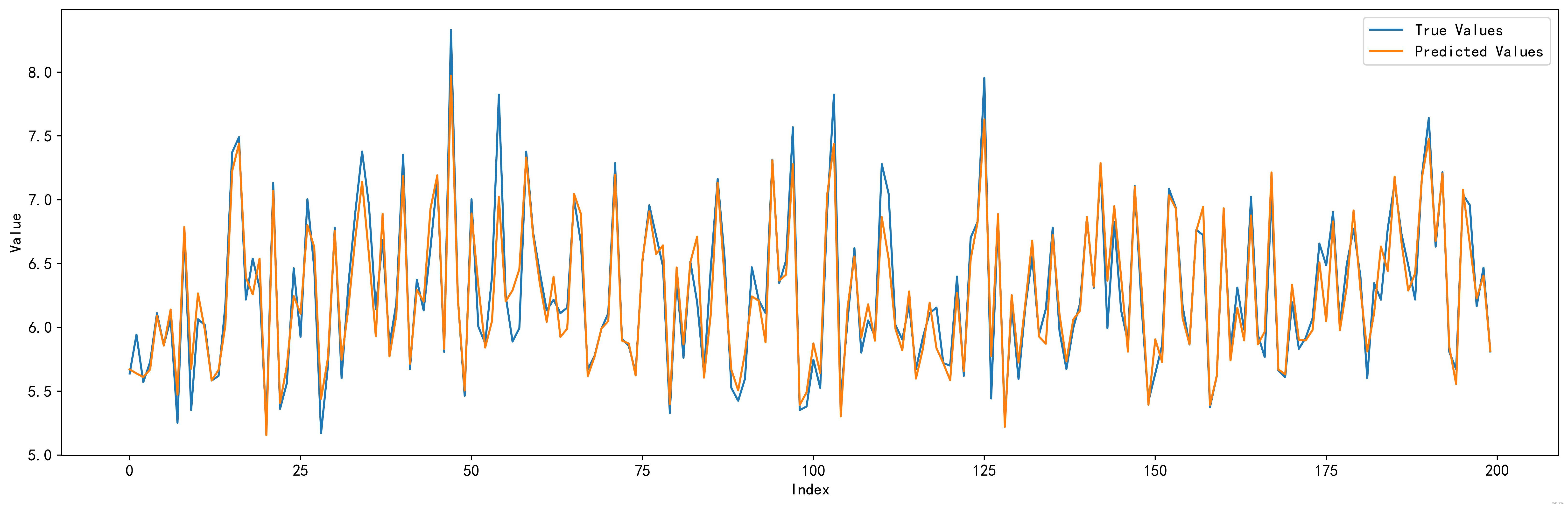
可以看到模型的预测结果和验证集的真实值还是非常接近的 。
(当然这里是预测验证集,所以是会有True Values的。通常来说测试集的标签值我们是不知道的,所以对于测试集而言我们只能做预测,没办法做对比,也就是只能画出图上的Predicted Values那一条线)
2.2 模型评价指标
对于机器学习中的回归模型,我们一般使用但不局限于以下4个指标:
- 均方误差、均方根误差、平均绝对误差:误差当然是越小说明模型拟合的效果越好
:拟合优度,通常情况下取值在0~1之间,越接近1说明模型的效果越好,越接近0模型越差。
- import numpy as np
- from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
-
- # 模型评估
- # 计算均方误差(MSE)
- mse = mean_squared_error(y_test, y_pred)
- print("均方误差(MSE):", mse)
-
- # 计算均方根误差(RMSE)
- rmse = np.sqrt(mse)
- print("均方根误差(RMSE):", rmse)
-
- # 计算平均绝对误差(MAE)
- mae = mean_absolute_error(y_test, y_pred)
- print("平均绝对误差(MAE):", mae)
-
- # 计算决定系数(R²)
- r2 = r2_score(y_test, y_pred)
- print("决定系数(R²):", r2)
随机森林回归模型的评价指标结果:
| 均方误差(MSE): | 0.04583461034583555 |
| 均方根误差(RMSE): | 0.2140901920822987 |
| 平均绝对误差(MAE): | 0.14870750835532767 |
| 决定系数( | 0.8649912651874802 |
我们以MAE和作为评价指标。可以看出来平均绝对误差0.14,这说明预测值和真实值的平均误差在
0.14左右,预测效果良好。决定系数的值为0.865,说明模型的性能还是很好的。
3 基于随机森林的特征重要性可视化
使用解释:
- feature_importances_df:这个变量就是特征的重要性得分
- 特征重要性一般是为了筛选出对目标变量影响较大的因素,所以使用到的数据集是整个数据集,而不是拆分出来的训练集。(可用于影响因素那部分的研究中)
- 下面代码中一些注释可以根据自己需要解开,使用到的中文字体为宋体,数字字体是Time New Roman
- # 导入必要的库
- from sklearn.ensemble import RandomForestRegressor
- import pandas as pd
- import numpy as np
- import matplotlib.pyplot as plt # 绘图库
- # 解决画图中文字体显示的问题
- plt.rcParams['font.sans-serif'] = ['SimSun', 'Times New Roman'] # 汉字字体集
- plt.rcParams['font.size'] = 10 # 字体大小
- plt.rcParams['axes.unicode_minus'] = False
- # 忽略警告
- import warnings
- warnings.filterwarnings('ignore')
-
- # 读取数据集
- data = pd.read_csv('./数据集.csv', encoding='gbk')
- # Split data into features and target
- X = data.drop('房屋租金', axis=1)
- y = data['房屋租金']
- # 定义一个随机森林回归模型
- RF = RandomForestRegressor(n_jobs=-1)
- # 训练模型
- RF.fit(X, y)
- # 获取特征重要性得分
- feature_importances = RF.feature_importances_
- # 创建特征名列表
- feature_names = list(X.columns)
- # 创建一个DataFrame,包含特征名和其重要性得分
- feature_importances_df = pd.DataFrame({'feature': feature_names, 'importance': feature_importances})
- # 对特征重要性得分进行排序
- feature_importances_df = feature_importances_df.sort_values('importance', ascending=False)
-
- # 颜色映射
- colors = plt.cm.viridis(np.linspace(0, 1, len(feature_names)))
-
- # 可视化特征重要性
- fig, ax = plt.subplots(figsize=(10, 6))
- ax.barh(feature_importances_df['feature'], feature_importances_df['importance'], color=colors)
- ax.invert_yaxis() # 翻转y轴,使得最大的特征在最上面
- ax.set_xlabel('特征重要性', fontsize=12) # 图形的x标签
- ax.set_title('随机森林特征重要性可视化',fontsize=16)
- for i, v in enumerate(feature_importances_df['importance']):
- ax.text(v + 0.01, i, str(round(v, 3)), va='center', fontname='Times New Roman', fontsize=10)
-
- # # 设置图形样式
- # plt.style.use('default')
- ax.spines['top'].set_visible(False) # 去掉上边框
- ax.spines['right'].set_visible(False) # 去掉右边框
- # ax.spines['left'].set_linewidth(0.5)#左边框粗细
- # ax.spines['bottom'].set_linewidth(0.5)#下边框粗细
- # ax.tick_params(width=0.5)
- # ax.set_facecolor('white')#背景色为白色
- # ax.grid(False)#关闭内部网格线
-
- # 保存图形
- plt.savefig('./特征重要性.jpg', dpi=400, bbox_inches='tight')
- plt.show()
我认为这个可视化还是非常美观的,从布局以及配色的过渡上都是很符合学术规范的^_^
特征重要性可视化结果:

图示说明对于目标变量房屋租金而言,影响较大的是居住面积>价格趋势>服务费>区域2。这表明在房屋租金的定价中,大的面积、上升的房价趋势、更高的服务费缴纳、地处更发达的市区会使得房屋租金更高,房东可以制定更高的租金!
就想到这里啦!等小白后面想到什么再补充吧!

