
- 1windows下搭建Redis群集,实现主从复制 和 故障转移_redis在windows上故障转移
- 21.1 微信Native支付 - 接入指引与支付安全
- 3考研系列-数据结构第七章:查找(下)_b树和b+树
- 4朝阳医院2018年销售数据 数据分析与可视化
- 5微信部署ChatGPT机器人/bot_chatgpt for wechat
- 6粤嵌gec6818开发板-播放视频、音频文件(管道文件控制)_6818开发版视频播放
- 7算法导论笔记:13-04红黑树以及其他平衡树_加权平衡树
- 82023年2月可用的免费图床_图床链接生成器
- 9热门开源项目推荐
- 10FPGA之JESD204B接口——总体概要 尾片_204b映射关系
Stable Diffusion结构解析-以图像生成图像!_stable diffusion 图生图
赞
踩
手把手教你入门绘图超强的AI绘画,用户只需要输入一段图片的文字描述,即可生成精美的绘画。给大家带来了全新保姆级教程资料包 (文末可获取)
AIGC专栏3——Stable Diffusion结构解析-以图像生成图像(图生图,img2img)为例
- 学习前言
- 源码下载地址
- 网络构建
-
- 一、什么是Stable Diffusion(SD)
- 二、Stable Diffusion的组成
- 三、img2img生成流程
-
- 1、输入图片编码
- 2、文本编码
- 3、采样流程
-
- a、生成初始噪声
- b、对噪声进行N次采样
- c、单次采样解析
-
- I、预测噪声
- II、施加噪声
- d、预测噪声过程中的网络结构解析
-
- I、apply_model方法解析
- II、UNetModel模型解析
- 4、隐空间解码生成图片
- 图像到图像预测过程代码
学习前言
用了很久的Stable Diffusion,但从来没有好好解析过它内部的结构,写个博客记录一下,嘿嘿。

源码下载地址
https://github.com/bubbliiiing/stable-diffusion
喜欢的可以点个star噢。
网络构建
一、什么是Stable Diffusion(SD)
Stable Diffusion是比较新的一个扩散模型,翻译过来是稳定扩散,虽然名字叫稳定扩散,但实际上换个seed生成的结果就完全不一样,非常不稳定哈。
Stable Diffusion最开始的应用应该是文本生成图像,即文生图,随着技术的发展Stable Diffusion不仅支持image2image图生图的生成,还支持ControlNet等各种控制方法来定制生成的图像。
Stable Diffusion基于扩散模型,所以不免包含不断去噪的过程,如果是图生图的话,还有不断加噪的过程,此时离不开DDPM那张老图,如下:
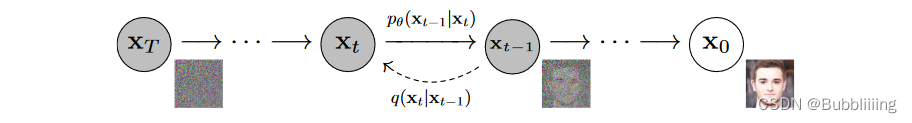
Stable Diffusion相比于DDPM,使用了DDIM采样器,使用了隐空间的扩散,另外使用了非常大的LAION-5B数据集进行预训练。
直接Finetune Stable Diffusion大多数同学应该是无法cover住成本的,不过Stable Diffusion有很多轻量Finetune的方案,比如Lora、Textual Inversion等,但这是后话。
本文主要是解析一下整个SD模型的结构组成,一次扩散,多次扩散的流程。
大模型、AIGC是当前行业的趋势,不会的话容易被淘汰,hh。
txt2img的原理如博文
Diffusion扩散模型学习2——Stable Diffusion结构解析-以文本生成图像(txt2img)为例
所示。
二、Stable Diffusion的组成
Stable Diffusion由四大部分组成。
1、Sampler采样器。
2、Variational Autoencoder (VAE) 变分自编码器。
3、UNet 主网络,噪声预测器。
4、CLIPEmbedder文本编码器。
每一部分都很重要,我们以图像生成图像为例进行解析。既然是图像生成图像,那么我们的输入有两个,一个是文本,另外一个是图片。
三、img2img生成流程

生成流程分为四个部分:
1、对图片进行VAE编码,根据denoise数值进行加噪声。
2、Prompt文本编码。
3、根据denoise数值进行若干次采样。
4、使用VAE进行解码。
相比于文生图,图生图的输入发生了变化,不再以Gaussian noise作为初始化,而是以加噪后的图像特征为初始化,这样便以图像的方式为模型注入了信息。
详细来讲,如上图所示:
- 第一步为对输入的图像利用VAE编码,获得输入图像的Latent特征;然后使用该Latent特征基于DDIM Sampler进行加噪,此时获得输入图片加噪后的特征。假设我们设置denoise数值为0.8,总步数为20步,那么第一步中,我们会对输入图片进行0.8x20次的加噪声,剩下4步不加,可理解为打乱了80%的特征,保留20%的特征。
- 第二步是对输入的文本进行编码,获得文本特征;
- 第三步是根据denoise数值对 第一步中获得的 加噪后的特征 进行若干次采样。还是以第一步中denoise数值为0.8为例,我们只加了0.8x20次噪声,那么我们也只需要进行0.8x20次采样就可以恢复出图片了。
- 第四步是将采样后的图片利用VAE的Decoder进行恢复。
with torch.no_grad(): if seed == -1: seed = random.randint(0, 65535) seed_everything(seed) # ----------------------- # # 对输入图片进行编码并加噪 # ----------------------- # if image_path is not None: img = HWC3(np.array(img, np.uint8)) img = torch.from_numpy(img.copy()).float().cuda() / 127.0 - 1.0 img = torch.stack([img for _ in range(num_samples)], dim=0) img = einops.rearrange(img, 'b h w c -> b c h w').clone() ddim_sampler.make_schedule(ddim_steps, ddim_eta=eta, verbose=True) t_enc = min(int(denoise_strength * ddim_steps), ddim_steps - 1) z = model.get_first_stage_encoding(model.encode_first_stage(img)) z_enc = ddim_sampler.stochastic_encode(z, torch.tensor([t_enc] * num_samples).to(model.device)) # ----------------------- # # 获得编码后的prompt # ----------------------- # cond = {"c_crossattn": [model.get_learned_conditioning([prompt + ', ' + a_prompt] * num_samples)]} un_cond = {"c_crossattn": [model.get_learned_conditioning([n_prompt] * num_samples)]} H, W = input_shape shape = (4, H // 8, W // 8) if image_path is not None: samples = ddim_sampler.decode(z_enc, cond, t_enc, unconditional_guidance_scale=scale, unconditional_conditioning=un_cond) else: # ----------------------- # # 进行采样 # ----------------------- # samples, intermediates = ddim_sampler.sample(ddim_steps, num_samples, shape, cond, verbose=False, eta=eta, unconditional_guidance_scale=scale, unconditional_conditioning=un_cond) # ----------------------- # # 进行解码 # ----------------------- # x_samples = model.decode_first_stage(samples) x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cpu().numpy().clip(0, 255).astype(np.uint8)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44

