
- 1深度学习中的超参管理方法:argparse模块
- 2【论文阅读】A Survey of Challenges and Opportunities in Sensing and Analytics for Risk Factors of Cardiova_a survey of digital twin: integration, challenges
- 3案例23 图书管理系统的设计与实现_图书管理系统设计
- 4Gradle kts配置_android kts中,lint配置
- 5计算机SCI/EI期刊投稿经验_acm tomm期刊属于几区
- 6【JavaScript】深入理解Promise:从基础概念到进阶用法、手写promise_js promise 用法
- 7二叉树画图与求时间复杂度_二叉树插入的空间复杂度和时间复杂度计算
- 8OpenWrt 防火墙配置 /etc/config/firewall_openwrt firewall
- 9git官方文档中文版
- 10Python 文件操作详解_python写文件的操作方法
DBSCAN算法_dbscan怎么预测
赞
踩
1、DBSCAN概念
基于密度的带噪声的空间聚类应用算法,它是将簇定义为密度相连的点的大集合,能够把足够高密度的区域划分为簇,并且可在噪声的空间数据集中发现任意形状的聚类。
2、密度聚类和距离聚类
密度聚类:只要临近区域的密度、对象、或者数据点的数目超过耨个阈值,就继续聚类,可以根据与周伟特点进行聚类
kmeans和分层聚类都是基于距离进行聚类,只能发现球状的簇,五发现其他形式的簇
3、其他概念
- 01密度:空间中任意一点的密度是以该点为圆形,以Eps为半径的圆区域内包含的点数目。
- 02 领域: 空间中任意一点的领域是以该点为圆心、以Eps为半径的圆区域内包含的点数目。
- 03 核心点:空间某一点的密度,如果大于某一给定阈值MInPts,则称为边界点。
- 04 噪声点:数据集中不属于核心点,也不属于边界点的点,也就是密度值为1的点
4、聚类方法
model=sklearn.cluster.DBSCAN(eps,min_samples)
eps 领域的大小,使用圆的半径表示
min_samples 点的个数的阈值
model.fit_predict(data)
data 数据
训练模型并且进行预测的方法
- 1
- 2
- 3
- 4
- 5
- 6
5、案例
2.1 示例
核心参数
def init(self, eps=0.5, min_samples=5, metric=‘euclidean’,
metric_params=None, algorithm=‘auto’, leaf_size=30, p=None,
n_jobs=1):
metric 可指定计算距离的方式
返回值
core_sample_indices_ : 核心点的索引,因为labels_不能区分核心点还是边界点,所以需要用这个索引确定核心点
components_:训练样本的核心点
labels_:每个点所属集群的标签,-1代表噪声点
import numpy as np from sklearn.cluster import DBSCAN X = np.array([[1, 2], [2, 2], [2, 3], [-25, -80], [8, 7], [8, 8], [25, 80], [6, 8]]) clustering = DBSCAN(eps=3, min_samples=2).fit(X) print(clustering.labels_) # [ 0 0 0 -1 1 1 -1 1] 异常点被标记为-1 index = clustering.core_sample_indices_ # 核心对象的下标 print(index) # [0 1 2 4 5 7] core_sample = X[index] # 核心对象 print(core_sample) # [[1 2] # [2 2] # [2 3] # [8 7] # [8 8] # [6 8]] print(clustering.components_) # 核心对象,同上 # [[1 2] # [2 2] # [2 3] # [8 7] # [8 8] # [6 8]]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
2.2 导入数据
我们对data的分布用seaborn进行查看。
#!/usr/bin/python
# -*- coding:utf-8 -*-
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn import metrics
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv('hql_sql.csv', header=None)
data.columns=['x','y']
sns.relplot(x="x",y="y",data=data)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
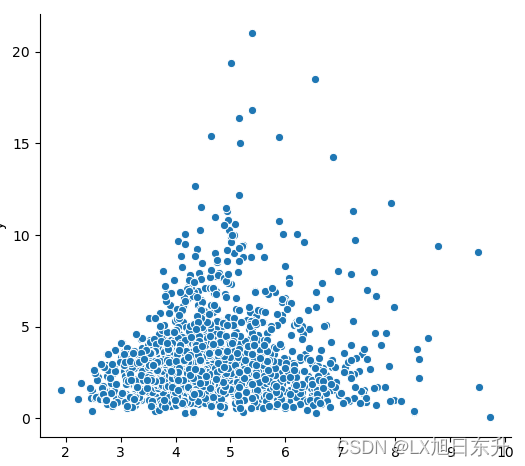
建立一个简单的模型
db = DBSCAN(eps=0.5, min_samples=3).fit(data) #DBSCAN聚类方法 还有参数,matric = ""距离计算方法
data['labels'] = db.labels_ #和X同一个维度,labels对应索引序号的值 为她所在簇的序号。若簇编号为-1,表示为噪声,我们把标签放回到data数据集中方便画图
labels = db.labels_
raito = data.loc[data['labels']==-1].x.count()/data.x.count() #labels=-1的个数除以总数,计算噪声点个数占总数的比例
print('噪声比:' + format(raito, '.2%')) #噪声比,噪声比越小越好
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) # 获取分簇的数目
print('分簇的数目: %d' % n_clusters_)
print("轮廓系数: %0.3f" % metrics.silhouette_score(data, labels)) #轮廓系数评价聚类的好坏=>此系数评价聚类的好坏,值越大越好,值越大
sns.relplot(x="x",y="y", hue="labels",data=data)
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
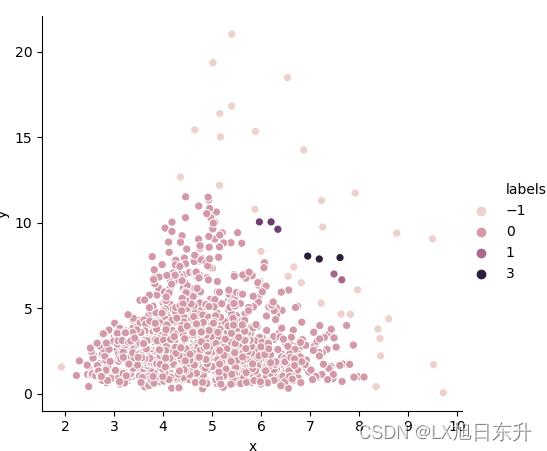
参考资料:
官网:https://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html
DBSCAN密度聚类算法:https://www.cnblogs.com/pinard/p/6208966.html
用scikit-learn学习DBSCAN聚类:https://www.cnblogs.com/pinard/p/6217852.html
详解DBSCAN聚类:https://zhuanlan.zhihu.com/p/185623849
DBSCAN 算法:https://www.jianshu.com/p/e594c2ce0ac0

