
热门标签
热门文章
- 1Qt 将生成的exe文件自动复制到其它目录下
- 2Postgresql之(1)自动化脚本_pg免费脚本
- 37.4 QtabWidget多页面切换视图_tab widget在程序中怎么识别不同页面
- 4OJ刷题--[算法课动态规划]背包问题(C++完整代码)_一个背包有一定的承重w,有n件物品,每件物品都有自己的价值,记录在数组v中,也都有
- 5python找不到路径_(Python)ValueError:在路径中找不到程序点
- 6【Fastdfs】通过 docker 快速搭建集群 fastdfs 环境_fastdfs docker集群部署
- 7当思想与机器融合:脑机接口与人类的现在、困境与未来
- 8处理器及微控制器:XCZU15EG-2FFVC900I 可编程单元
- 9Mysql 面试题及答案,2024最新面试题(收藏版)
- 10探索NLP实验评估的新境界:Jury
当前位置: article > 正文
【高阶数据结构】跳表 -- 详解_跳表的概率和最高层数选择
作者:运维做开发 | 2024-07-31 14:07:49
赞
踩
跳表的概率和最高层数选择
一、什么是跳表 —— skiplist
skiplist 本质上也是一种查找结构,用于解决算法中的查找问题,跟平衡搜索树和哈希表的价值是一样的,可以作为 key 或者 key/value 的查找模型。
skiplist 是由 William Pugh 发明的,最早出现于他在 1990 年发表的论文《Skip Lists: A Probabilistic Alternative to Balanced Trees》。
skiplist 是一个 list。实际上,它是在有序链表的基础上发展起来的。如果是一个有序的链表,查找数据的时间复杂度是 O(N)。
William Pugh 开始的优化思路:
- 假如我们每相邻两个节点升高一层,增加一个指针,让指针指向下下个节点。这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半。由于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了,需要比较的节点数大概只有原来的一半。
- 以此类推,我们可以在第二层新产生的链表上,继续为每相邻的两个节点升高一层,增加一个指针,从而产生第三层链表。
- skiplist 正是受这种多层链表的想法的启发而设计出来的。实际上,按照上面生成链表的方式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似二分查找,使得查找的时间复杂度可以降低到 O(log n)。但是这个结构在插入删除数据的时候有很大的问题,插入或者删除一个节点之后,就会打乱上下相邻两层链表上节点个数严格的 2:1 的对应关系。如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这会让时间复杂度重新蜕化成 O(n)。
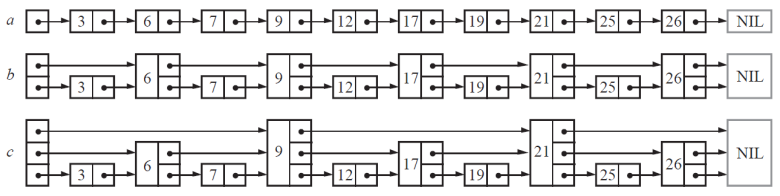
-
skiplist 的设计为了避免这种问题,做了一个大胆的处理,不再严格要求对应比例关系,而是插入一个节点的时候随机出一个层数。这样每次插入和删除都不需要考虑其他节点的层数,这样就好处理多了。细节过程入下图:
二、如何保证 skiplist 的效率
上面我们说到,skiplist 插入一个节点时随机出一个层数,听起来怎么这么随意,如何保证搜索时的效率呢?
这里首先要细节分析的是这个随机层数是怎么来的。一般跳表会设计一个最大层数 maxLevel 的限制,其次会设置一个多增加一层的概率 p。那么计算这个随机层数的伪代码如下图:

在 Redis 的 skiplist 实现中,这两个参数的取值为:
- p = 1/4
- maxLevel = 32
根据前面 randomLevel() 的伪代码,可以很容易看出,产生越高的节点层数,概率越低。定量的分析如下:
- 节点层数至少为 1。而大于 1 的节点层数,满足一个概率分布。
- 节点层数恰好等于 1 的概率为 1-p。
- 节点层数大于等于 2 的概率为 p,而节点层数恰好等于 2 的概率为 p(1-p)。
- 节点层数大于等于 3 的概率为 p^2,而节点层数恰好等于 3 的概率为 p^2*(1-p)。
- 节点层数大于等于 4 的概率为 p^3,而节点层数恰好等于 4 的概率为 p^3*(1-p)。
- ……
因此,一个节点的平均层数(也即包含的平均指针数目),计算如下:

现在很容易计算出:
- 当 p=1/2 时,每个节点所包含的平均指针数目为 2。
- 当 p=1/4 时,每个节点所包含的平均指针数目为 1.33。
跳表的平均时间复杂度为 O(logN)。
可以了解学习:Redis 内部数据结构详解 —— skiplist-CSDN博客
三、skiplist 的实现
力扣对应题目链接:1206. 设计跳表 - 力扣(LeetCode)
- //力扣AC代码
- struct SkiplistNode
- {
- int _val;
- vector<SkiplistNode*> _nextV;
-
- SkiplistNode(int val, int level)
- : _val(val)
- , _nextV(level, nullptr)
- {}
- };
-
- class Skiplist {
- typedef SkiplistNode Node;
- public:
- Skiplist()
- {
- srand(time(0));
-
- // 头节点,层数是1
- _head = new SkiplistNode(-1, 1);
- }
-
- bool search(int target)
- {
- Node* cur = _head;
- int level = _head->_nextV.size() - 1;
- while(level >= 0)
- {
- // 目标值比下一个节点值要大 -> 向右走
- if(cur->_nextV[level] && target > cur->_nextV[level]->_val)
- {
- cur = cur->_nextV[level];
- }
- // 下一个节点为空(尾)或目标值比下一个节点值要小 -> 向下走
- else if(cur->_nextV[level] == nullptr || target < cur->_nextV[level]->_val)
- {
- level--;
- }
- else
- {
- return true;
- }
- }
- return false;
- }
-
- vector<Node*> FindPrevNode(int num)
- {
- Node* cur = _head;
- int level = _head->_nextV.size() - 1;
-
- // 插入位置每一层前一个节点指针
- vector<Node*> prevV(level + 1, _head);
-
- while (level >= 0)
- {
- // 目标值比下一个节点值要大 -> 向右走
- if (cur->_nextV[level] && cur->_nextV[level]->_val < num)
- {
- cur = cur->_nextV[level];
- }
- // 下一个节点为空(尾)或目标值比下一个节点值要小 -> 向下走
- else if (cur->_nextV[level] == nullptr || cur->_nextV[level]->_val >= num)
- {
- // 更新level层前一个
- prevV[level] = cur;
- level--;
- }
- }
- return prevV;
- }
-
- void add(int num)
- {
- // 插入位置每一层的前一个节点指针
- vector<Node*> prevV = FindPrevNode(num);
-
- int n = RandomLevel();
- Node* newnode = new Node(num, n);
-
- // 如果n超过当前最大的层数,那就升高一下_head的层数
- if (n > _head->_nextV.size())
- {
- _head->_nextV.resize(n, nullptr);
- prevV.resize(n, _head);
- }
-
- // 链接前后节点
- for (size_t i = 0; i < n; ++i)
- {
- newnode->_nextV[i] = prevV[i]->_nextV[i];
- prevV[i]->_nextV[i] = newnode;
- }
- }
-
- bool erase(int num)
- {
- vector<Node*> prevV = FindPrevNode(num);
-
- // 第一层下一个不是val,说明val不在表中
- if (prevV[0]->_nextV[0] == nullptr || prevV[0]->_nextV[0]->_val != num)
- {
- return false;
- }
- else
- {
- Node* del = prevV[0]->_nextV[0];
- // del节点每一层的前后指针链接起来
- for (size_t i = 0; i < del->_nextV.size(); i++)
- {
- prevV[i]->_nextV[i] = del->_nextV[i];
- }
- delete del;
-
- // 如果删除最高层节点,把头节点的层数也降一下
- int i = _head->_nextV.size() - 1;
- while (i >= 0)
- {
- if (_head->_nextV[i] == nullptr) i--;
- else break;
- }
- _head->_nextV.resize(i + 1);
- return true;
- }
- }
-
- int RandomLevel()
- {
- size_t level = 1;
- // rand() -> [0, RAND_MAX]
- while (rand() <= RAND_MAX * _p && level < _maxLevel)
- {
- level++;
- }
- return level;
- }
-
- private:
- Node* _head; // 头节点
- size_t _maxLevel = 32;
- double _p = 0.25;
- };
-
- /**
- * Your Skiplist object will be instantiated and called as such:
- * Skiplist* obj = new Skiplist();
- * bool param_1 = obj->search(target);
- * obj->add(num);
- * bool param_3 = obj->erase(num);
- */

了解更多,可以参考:跳表 - OI Wiki (oi-wiki.org)
四、skiplist 跟平衡搜索树和哈希表的对比
skiplist 相比平衡搜索树(AVL 树和红黑树)对比,都可以做到遍历数据有序,时间复杂度也差不多。
skiplist 的优势是:
- skiplist 实现简单,容易控制。而平衡树增删查改遍历都更复杂。
- skiplist 的额外空间消耗更低。而平衡树节点存储每个值有三叉链,平衡因子/颜色等消耗。
skiplist 中当 p=1/2 时,每个节点所包含的平均指针数目为 2。
skiplist 中当 p=1/4 时,每个节点所包含的平均指针数目为 1.33。
skiplist 相比哈希表而言,就没有那么大的优势了。相比而言:
- 哈希表非极端场景下哈希冲突的平均时间复杂度是 O(1),比 skiplist 快。
- 哈希表空间消耗略多一点。
skiplist 优势如下:
- 遍历数据有序。
- skiplist 空间消耗略小一点,哈希表存在链接指针和表空间消耗。
- 哈希表扩容有性能损耗。
- 哈希表在极端场景下哈希冲突高,效率下降厉害,需要红黑树补足接力。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/运维做开发/article/detail/909258
推荐阅读
相关标签

