
- 1【开卷数据结构 】 树与二叉树_锡兰cc博客
- 2cgroup:Linux的资源控制机制
- 3共筑云计算新生态 | 云轴科技ZStack启动鲲鹏原生开发
- 4three.js 制作3D相册_three.js 相册
- 5网络安全策略是什么_网络安全威胁的识别和防范策略_新手网安记录贴
- 6spring利用注解@Value获取properties属性为null_value注解取properties list属性报错
- 7AI学习第一步:Python环境搭建_如何搭建一个简单的ai学习
- 8大盘点!22项开源NeRF SLAM顶会方案整理!(下)_大盘点!22项开源nerf slam顶会方案整理!(中)
- 9漫途城市管网污水监测方案,让污水管网不再“沉默”
- 10Bert系列:基于Huggingface预训练模型微调,实现中文实体链接分类_huggingface使用bert做分类
#python学习笔记#使用python爬取拉勾网职位信息(二):爬取数据_python爬取拉勾网详情页
赞
踩
将python环境配置好后,接下来就可以开始动手coding了!
1.创建excel并插入头部数据:
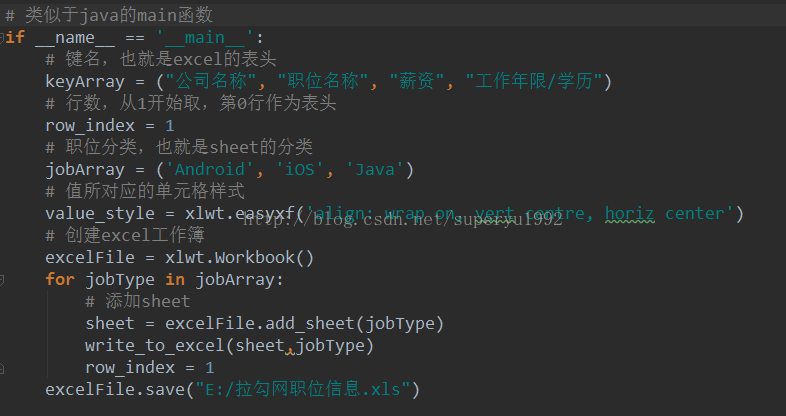
这里的30是总页数,可以从网页中获得,这里为了简便,就暂时写了一个固定值。

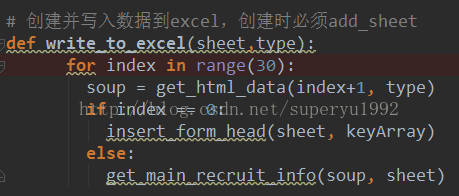
2.获取网页数据
获取网页数据需要用到python自带的urllib(type为分类,如:Android,iOS等;index为页数),然后我们可以把获得的data,转成soup用于解析:
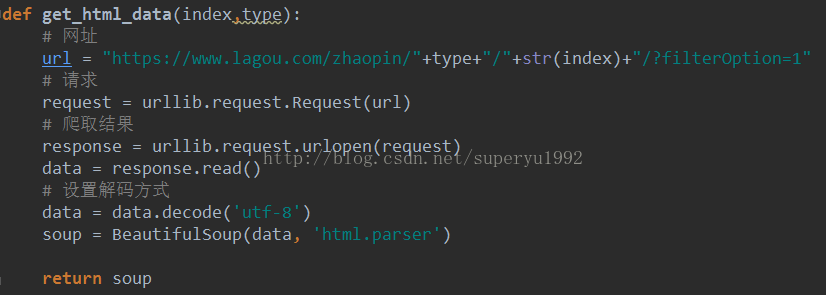
可以通过print(data),查看获取到的结果。
3.解析网页数据
通过打印出来的数据可以发现,每个class为“con_list_item default_list”的<li>标签都对应一条职位信息,其中的data-company(公司名称),data-positionname(职位名称),data-salary(薪资)等几个属性正是我们需要的,因此我们需要通过soup去取得这个标签,拿到这些值:
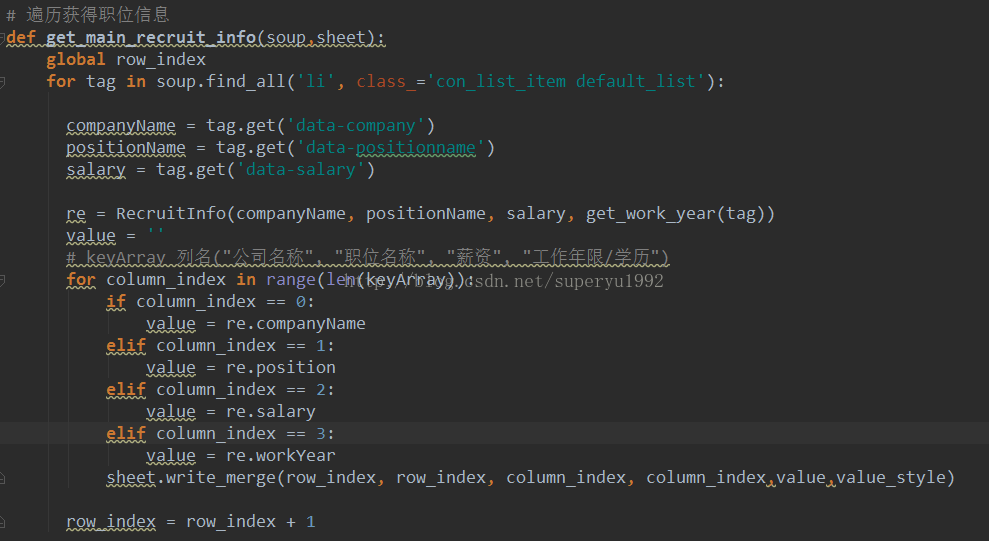
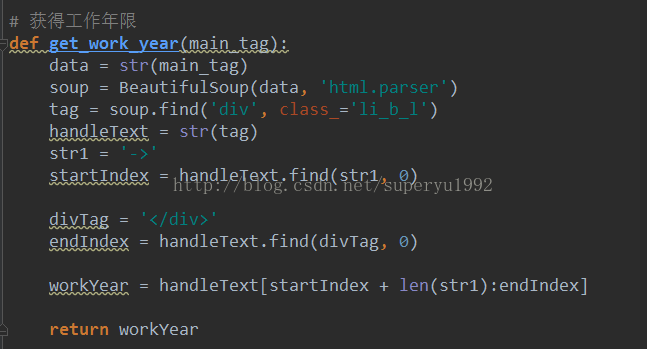
好了,到这里整个爬虫就好了。运行一下应该就可以看到效果了!通过标签获取网页上的数据是爬虫的一种方式,还可以通过json去获取,那就需要一些网络方面的知识了,如抓包等等,有空再来研究一下。
PS:写到这里,鄙人刚想运行一下截个图,就发现拉勾所有的页面,请求下来都变成了这个样子。。。
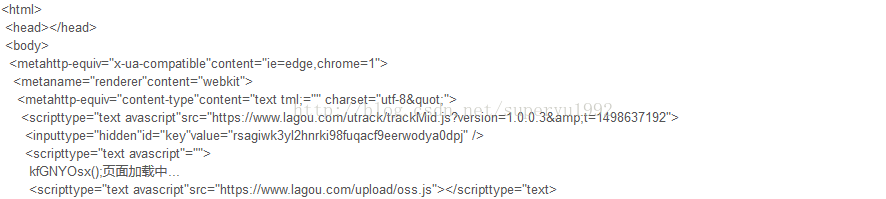
真的是欲哭无泪啊!!!
7.10更新:
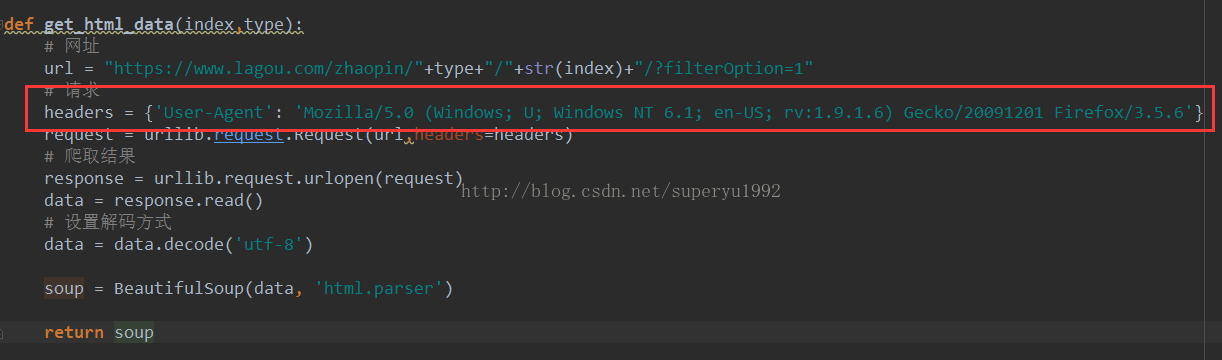
终于找到了上面问题的原因!原来是网站拒绝了此类访问(我在抓智联数据的时候,它提醒我错误502,我才想起是这个原因,拉钩对502这个错误做了处理,真的很心机啊!),ok既然找到了问题,接下来解决就好,我发现在浏览器上依然是可以通过网址打开网页的,因此想通过python获取网页数据,就必须通过设置headers来伪装成浏览器就好了:
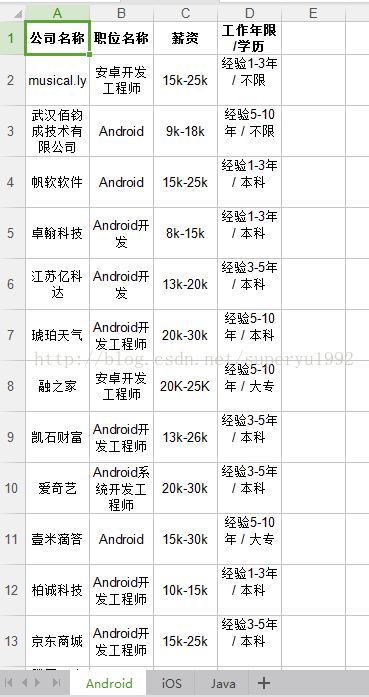
抓到的部分数据如下:
Demo下载链接:点我下载(审核通过后更新)

