
- 1kubeadm快速部署K8S
- 2Hive原理与Hive建表实例(内部表与外部表,静态与动态分区表,分桶)_完成外部表、静态分区表、动态分区表、分桶表创建实验,执行 select 查询语句
- 3TCP和UDP_tcp基于字节流 udp基于报文
- 4成功解决使用git clone下载失败的问题: fatal: 过早的文件结束符(EOF) fatal: index-pack 失败_fatal: the remote end hung up unexpectedly fatal:
- 5大数据面试题:说下Spark中的Transform和Action,为什么Spark要把操作分为Transform和Action?_spark transform
- 6git 查看email_基础Git操作与GitHub协作吐血整理,收好!| 原力计划
- 7git提交报错文件超过100M
- 8ClientCnxn: Session 0x0 for server null, unexpected error 异常解决
- 9WPA-PSK四次握手_wpa2四次握手图解
- 10Distilling the Knowledge in a Neural Network_distilling the knowledge in a neural network csdn
RAG调研——快速了解RAG技术_speculative rag
赞
踩
本文基于该篇文章,按照自己理解思路整理。
https://arxiv.org/abs/2402.19473
更详细RAG技术论文可从该链接获取。
1. RAG基础
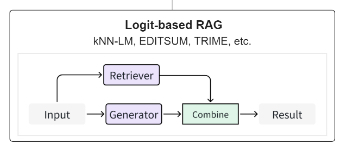
Query-based RAG 基于查询的检索增强技术
基于查询的 RAG 无缝地将用户的查询与检索信息的见解集成在一起,将其直接提供给语言模型输入的初始阶段。
一般而言,通过检索器检索得到相关数据内容后,与用户原始查询合并,形成一个复合输入序列,然后由生成器处理以创建响应。
常见的 Query-based 技术:
- REALM 使用双 bert 框架简化知识检索和继承,将预训练模型与知识提取器结合起来。
- Lewis 利用 DPR 检索信息,利用 BERT 作为生成器来增强生成。
- InContext RALM 使用 BM25 进行文档检索,并训练预测重新排序器对排名靠前的文档进行重新排序和整合。
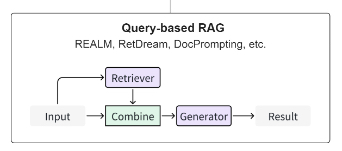
Latent Representation-based RAG 基于潜在表示的检索增强技术
在基于潜在表示的 RAG 框架中,检索到的对象被合并到生成模型中作为潜在表示。这增强了模型的理解能力并提高了生成内容的质量。
FiD 和 RETRO 是基于潜在表示的 RAG 的两个经典结构。
- FiD 通过不同的编码器处理每个检索到的段落及其标题与查询,然后合并单个解码器解码的结果潜在表示以产生最终输出。
- RETRO 为每个分段子查询检索相关信息,然后应用一个名为 Chunked Cross-Attention 的新模块将检索到的内容与每个子查询标记集成。
基于潜在表示的 RAG 在模式和任务中是通用的,合并检索器和生成器隐藏状态,尽管它需要额外的潜在空间对齐训练。这种方法允许创建复杂的、创新的算法,有效地整合检索到的信息。
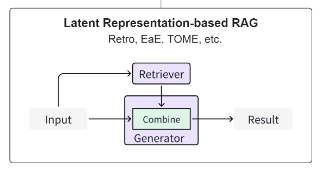
Logit-based RAG 基于 Logit 的检索增强技术
在基于 logit 的 RAG 中,生成模型在解码过程中通过 logits 集成检索信息。通常,logits 通过简单的求和或模型组合以计算逐步生成的概率。
基于 Logit 的 RAG 利用历史数据来推断当前状态并在 logit 级别合并信息,非常适合序列生成。它专注于生成器训练,并允许利用概率分布进行未来任务的新方法。
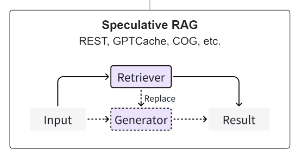
Speculative RAG 基于推测的检索增强技术
Speculative RAG 寻求使用检索而不是纯生成的机会,旨在节约资源,加快响应速度。
2. RAG 增强
基于 RAG 系统的抽象结构,可以将 RAG 增强技术分为 5 组:
- 输入增强技术
- 检索增强技术
- 生成增强技术
- 结果增强技术
- pipeline 增强技术
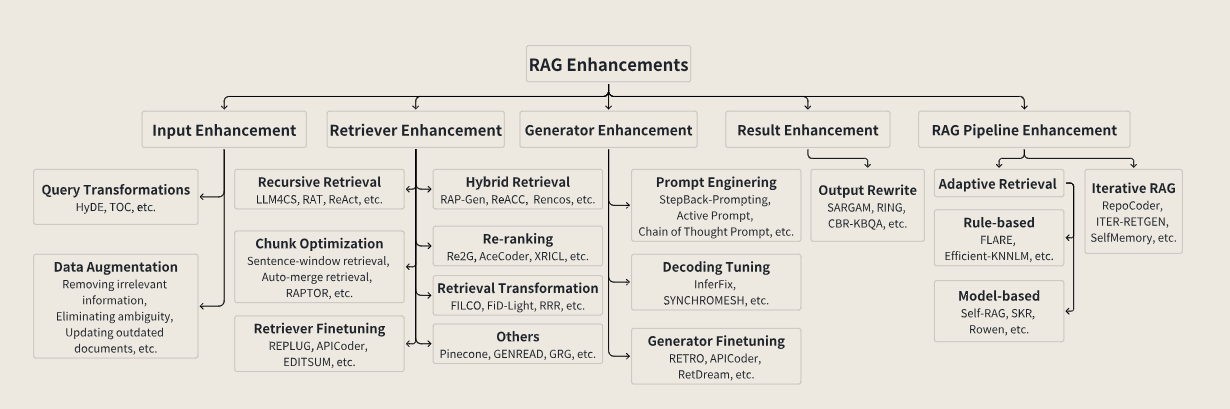
2.1 输入增强技术
2.1.1 查询转换
查询转换可以通过修改输入查询来增强检索结果。
- Query2doc 和 HyDE 使用原始查询生成伪文档,然后将其作为查询进行检索。伪文档包含更丰富的相关信息,有助于检索更准确的结果。
- TOC 利用检索到的内容将模糊查询分解为多个清晰的子查询,这些子查询被发送到 Generator 并聚合产生最终结果。
2.1.2 数据增强
数据增强在检索前改进了数据,包括去除不相关信息、消除歧义、更新过时文档
合成新数据等。
2.2 检索增强技术
2.2.1 递归检索
递归检索通过执行多次搜索以检索更丰富、更高质量的内容。
- ReACT 使用 Chain-of-Thought(CoT)将查询分解为递归检索并提供更丰富的信息。
- RATP 使用蒙特卡洛树搜索进行模拟,选择最佳检索内容,然后将其模版化并转发到生成器进行输出。
2.2.2 Chunk 优化
Chunk 优化是指调整块大小以提高检索结果。
- LlamaIndex 通过查明细粒度内容,但返回更丰富的信息。
- Sentence-window 检索获取小文本块冰返回检索到的片段周围相关句子的窗口
- Automerge 检索中,文档以树结构排列。该过程首先通过获取子节点来检索封装其子节点内容的父节点。
- RAPTOR 解决了 Automerge 上下文信息不足的缺点,通过使用文本块的递归嵌入、聚类和摘要,直到进一步的聚类变得不可行,从而构建多级树结构。
2.2.3 检索器微调
RAG 系统的核心检索器依靠熟练嵌入模型对相关内容进行聚类并输入生成器,提高系统性能。具有强表达能力的嵌入模型可以使用特定领域的或与任务相关的数据进行微调,以提高目标区域的性能。
2.2.4 混合检索
混合检索并发使用各种检索方法或从多个不同来源中提取信息。
- RetDreadm
2.2.5 重排
重排是对检索到的内容进行重新排序,以实现更大的多样性和更好的结果。
- Re2G 在传统检索器之后应用重排模型,以减少文本压缩为向量造成的信息丢失的影响。
2.2.6 检索转换
检索转换涉及改写检索到的内容以更好地激活生成器的潜力,从而提高输出。
2.2.7 其他
检索过程还存在其他优化方法。
- 元数据过滤:使用元数据(eg:时间、目的等)来过滤检索到的文档以获得更好的结果。
2.3 生成增强技术
2.3.1 提示工程
提示工程(Prompt Engineering)专注于提高 LLM 输出质量。相关技术:
- Prompt 压缩、 StepBack Prompt、 Active Prompt、 Last Prompt 等
相关论文技术: - LLMLingua 应用一个小模型压缩查询的整体长度,来加快模型推理,缓解不相关信息对模型的负面影响,减轻“ Lost in the middle”现象。
2.3.2 解码调整
解码调整涉及通过微调超参数来增强生成器控制,以增强多样性和约束输出词汇,以及其他调整。
2.3.3 生成器微调
生成器微调可以增强模型对具有更精确领域知识或更适合检索器的能力。
2.4 结果增强技术
2.4.1 输出重写
输出重写是指,在某些特定场景下,对生成器生成的内容进行重写,以满足下游任务的具体需求。
2.5 Pipeline 增强技术
Pipeline 增强指在系统级别优化 RAG 的过程,以实现更好性能结果。
2.5.1 自适应检索
一些研究表明检索并不总是增强最终结果。当模型固有的参数化只是足以回答相关问题时,过度地检索会导致资源浪费和潜在混淆。
- Rule-based 基于规则:根据一定的规则来确定 RAG 过程中是否使用检索搜索。
- Model-based 基于模型:基于生成器或者其他经过训练的模型来确定是否使用检索器进行搜索。
2.5.2 迭代 RAG
迭代 RAG 通过检索和生成阶段重复循环而不是单轮来逐步细化结果。
3. RAG 应用
4. RAG存在的一些问题
4.1 缺陷
4.1.1 检索结果中的噪声
由于项目表示和 ANN 搜索中的信息丢失,信息检索本质上存在缺陷。不可避免的噪声,表现为不相关的内容或误导性信息。
尽管提高检索精度对于 RAG 有效性似乎很直观,但最近的研究令人惊讶地发现嘈杂的检索结果可能会提高生成质量。一种可能的解释是,不同的检索结果可能有助于提示构建。
因此,检索噪声的影响尚不清楚,导致实际用途中度量选择和检索器-生成器交互混淆。
4.1.2 额外开销
虽然检索在某些情况下可以减少生成成本,但在大多数情况下会产生不可忽略的开销。检索和交互过程不可避免地会增加延迟。
当RAG与复杂的增强方法相结合时,这一点被放大,如递归检索和迭代RAG。
此外,随着检索源的规模扩大,存储和访问复杂性也会增加。这种开销阻碍了RAG在对延迟敏感的实时服务中的实用性。
4.1.3 检索器和生成器之间的差距
检索器和生成器的目标可能不对齐,它们的潜在空间可能不同,设计它们的交互需要细致的设计和优化。目前的方法要么解开检索和生成,要么将它们集成到中间阶段。虽然前者更具模块化,但后者可以从联合训练中受益,但阻碍了通用性。
4.1.4 系统复杂度增加
检索的引入不可避免地增加了系统复杂度和要调整的超参数数量。
4.1.5 上下文长度
RAG 的主要缺点之一,特别是基于查询的 RAG,它极大地延长了上下文,使得对于上下文长度有限的生成器是不可行的。
此外,延长的上下文也通常会减慢生成过程。
提示压缩和长上下文支持的研究进展部分缓解了这些挑战,尽管在准确性或成本方面有轻微的权衡。
-持续更新-

